
1.写在前面
本文针对物联网数据存储提供解决方案的思路,项目特点:结构化数据、传感器节点多(>100)、传感器类型多(>30)、采样频率高(1HZ),在此背景下,一般的关系型数据库已经不能够支撑数据存储,基于免费开源的软件完成数据存储工作,提高数据的读写能力。
2.物联网数据特点
1)多源异构
物联网数据来源于各种传感器设备,包括温度、风向风速、路灯信号、视频等等,设备厂家还不一定一致,导致形成数据源多源异构的局面,其通信协议还包括很多中,包括TCP、UDP、串口等等。
2)节点多
物联网大多服务于智慧城市、智慧交通,传感器节点能达到成千上万
3)采样频率高
物联网节点的数据生成频率高,如地震数据200HZ的采样,其他传感器也能达到秒级采样,另外传感器节点多数处于全时工作状态,数据流源源不断。
3.项目说明
传感器的采样频率普遍在1HZ,1个月数据量60*60*24*30=259.2万条,一个传感器的半年数据量即可达到1500万条。同时也有8HZ采样传感器,一个月数据2000万条,12个月差不多2.4亿条。
其实传感器种类多,相对可以多设计相应的表即可,不存在影响数据库性能。节点多,针对不同节点也可设计相应的节点表进行存储,故也可不考虑
目前需要数据库能长期稳定的运行,另DBA的专注方向主要在MySQL、免费开源
4.方案思考
4.1.初始方案MySQL
第一次遇到的同学,一般不信邪,单机MySQL撸
尤其对于部分宽表而言,这里的宽表并不是数据仓库中冗余的宽表,而是字段多,一张表涉及几百上千各字段。时间久了,数据库查询性能会受到极大影响,慢查询增多。
通过个人实测,不一定具有代表性,常规表1000万行以下,性能优异
1000万-3000万性能下降,但是不明显,查询依旧可以在1s内响应
3000-5000万性能下降明显,查询时间2-10s不等
1亿条,查询时间普遍>10s
针对物联网的时序数据,采样没达到1HZ,MySQL是可以对付一两年的,没什么问题
4.2 MyCat+MySQL集群
既然单机MySQL已经满足不了,那第一个想到的是分库分表,利用集群来分摊MySQL的压力。
其实同样是计算题,即通过分摊尽量将单台MySQL的单表控制在3000万行以下
这里可以理解资源来支撑,例如,将分库分表部署在10台机器,那单表总行数在3亿条之前没什么问题(前提:切片合理),另外可能丢失部分原有的MySQL指令功能,MyCat在做分库分表中,子查询功能会部分确实。如果考虑高可用的话,资源还需要翻倍。具体配置方法可参照:
教小白30分钟实现分库分表_数据库分表怎么实现_百老的博客-CSDN博客
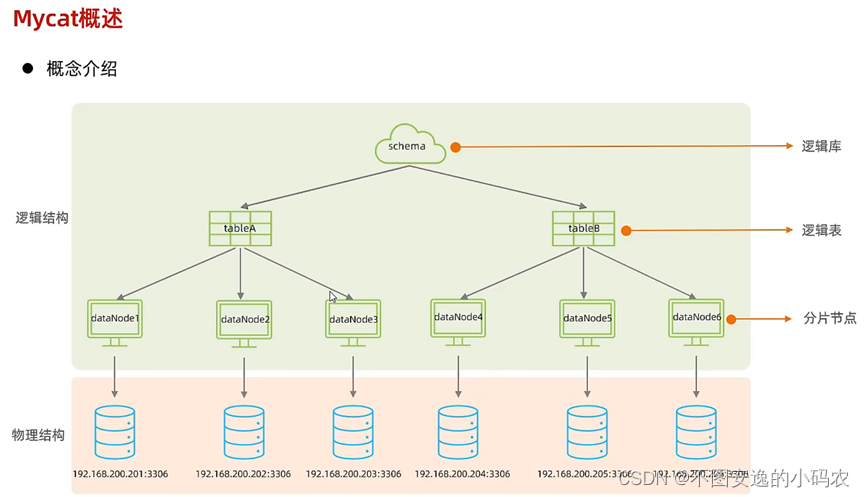
分库分表分为垂直分库、垂直分表、水平分库、水平分表
时序数据大多以水平分表为主
- 将一张表的数据按照某种规则分到不同的数据库中
- 需确定分片的规则
- 使用分片的字段查询时,科确定实体库,其他字段查询,查询所有表
优点:
- 解决了单库大数据、高并发的性能瓶颈
- 拆分规则封装好,对应用端几乎透明,开发人员无需关心拆分细节
- 提高了系统的稳定性和负载能力
缺点:
- 拆分规则很难抽象
- 分片事务一致性难以解决
- 二次扩展时,数据迁移、维护难度大
4.3 开源时序数据库
事物的发展总是从一个未知向已知发展的过程,在经历关系型数据库MySQL解决不了物联网时序数据的时候,下一步的方案往往是时序数据库。下图2022年12月排名

TDengine已经霸榜很久了,物联网的数据是结构化的,因此TDengine采取的是结构化存储,而不是流行的KV存储。物联网场景里,每个数据采集点的数据源是唯一的,数据是时序的,而且用户关心的往往是一个时间段的数据,而不是某个特殊时间点。基于这些特点,TDengine要求对每个采集设备单独建表。如果有1000万个设备,就需要建1000万张表。
基于这样的设计,任何一台设备采集的数据在存储介质里可以是一块一块连续的存放的,而且按照时间排序。因此查询单个设备一个时间段的数据,查询性能就有数量级的提升。另外一方面,虽然不同设备由于网络的原因,到达服务器的时间无法控制,是完全乱序的,但对于同一个设备而言,数据点的时序是保证的。一个设备一张表,就保证了一张表插入的数据是有时序保证的,这样数据插入操作就变成了一个简单的追加操作,插入性也能大幅度提高。
很多单位结合时序数据库存储时序数据,关系型数据库存储业务数据已经能够很好的解决碰到的大部分场景。
4.4 离线数仓
(Hive+HBase+Kettle+Kylin+Azkaban)+MySQL
时序数据不仅有实时可视化场景,同时也具备长周期趋势分析,而针对长周期的数据查询,对于任何数据库来说,都是比较棘手的。这时候离线数仓的优势就比较明显了,通过数据仓库的分层思想,可以提前将数据进行预处理.
同时Apache Kylin令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
1)定义数据集上的一个星形或雪花形模型
2)在定义的数据表上构建cube
3)使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果

Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析。
基于此,对于时序数据的长周期分析可以使用数仓方案。
写在最后:*正熵表示更无序,负熵表示更有序。 熵增和熵减只指趋向无序和趋向有序的过程。 一切*事物都会自然“熵增”——趋向无序的过程。需要各位的智慧让复杂多变的条件来完成趋于有序的需求。**
版权归原作者 百老 所有, 如有侵权,请联系我们删除。