
1. Zookeeper节点信息
指定服务端,启动客户端命令:
bin/zkCli.sh -server 服务端主机名:端口号
1)ls / 查看根节点下面的子节点
ls -s / 查看根节点下面的子节点以及根节点详细信息

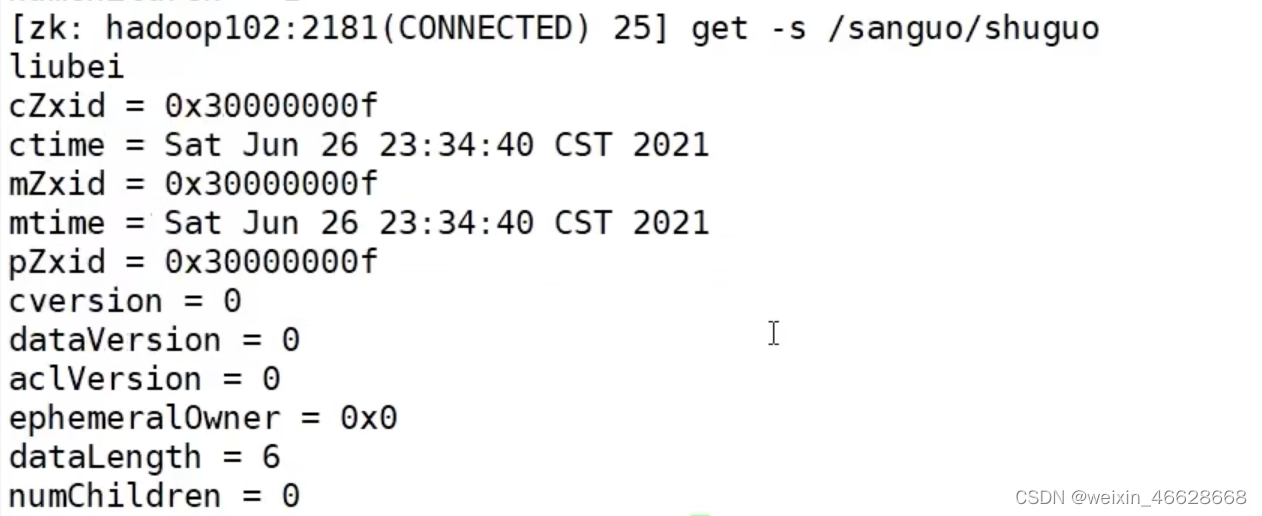
其中,cZxid是创建节点的事务id,每次修改Zookeeper的状态都会产生一个事务id;
ctime是节点被创建的毫秒数(从1970年开始),这里是zookeeper自带的默认节点,其ctime就是0;mZxid是节点最后被更新的事务id;
mtime是节点最后修改的毫秒数;pZxid是最后更新的子节点的事务id;ephemeralOwner如果是临时节点则表示拥有这个节点的s
ession id,如果不是临时节点则为0;
dataLength是该节点的数据长度;
numChildren是该节点的子节点数量。
2. Zookeeper节点类型
持久节点:客户端和服务端断开连接后,创建的节点不删除
短暂/临时节点:客户端和服务端断开连接后,创建的节点删除
上面两种节点还可以继续分为带序号和不带序号的,如果带序号,节点名称后面会接一个数值,顺序递增,由父节点维护。

创建永久节点:create path "val"


(注意,ls命令后面的路径不能以/结尾,这里跟Linux不一样)
查询节点的值:get -s path

创建带序号的永久节点:create -s path "val"

以相同的路径再次创建同名节点,带序号的节点会自动序号加1,不带序号的节点创建报错

以上是永久节点,退出客户端之后这些节点依然存在
创建临时节点:create -e path "val"

创建带序号的临时节点只需加上-s即可

因为已经有shuguo,weiguo,wuguo,所以新创建的带序号的临时节点的序号为3。
断开客户端之后,上面创建的临时节点wuguo会被删除。
修改节点的值:set path "newVal"

3. 监听原理

监听主要是通过getChildren和getData来实现,表面上是获取节点子节点或者节点数据的方法,但是第二个参数表示是否监听,一般为true(第二个参数也可以传一个自定义的监听器),所以实现了监听,当子节点发生增减或者节点数据发生变化时,就会通知客户端,触发process方法。getChildren和getData是Java API监听方式,稍后介绍,这里先介绍命令行监听。
命令行开启监听节点数据:get -w path

在另一个会话端修改sanguo的节点值,在本端会产生事件通知:

再次在另一个会话端修改sanguo的节点值,在本端不会产生事件通知,因为监听只生效一次,要想再次监听,需要再次注册,即执行get -w path。
监控子节点变化:ls -w path
再另一个会话端创建一个子节点,在本端会产生一个事件通知

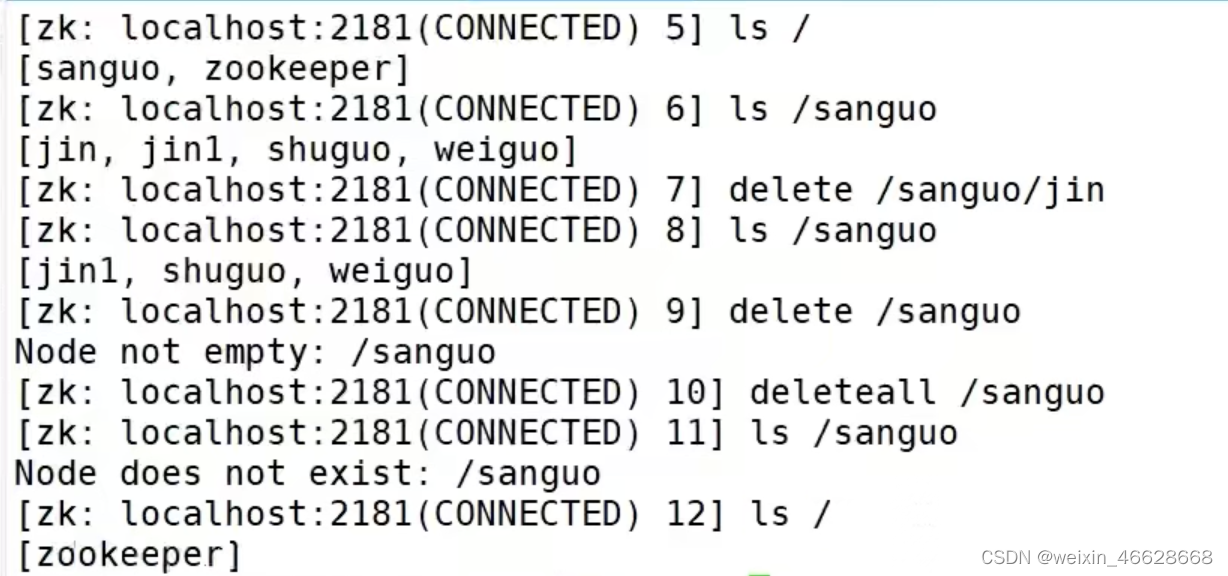
节点删除:delete path
删除节点及其下面的子节点:deleteall path
查看节点状态:stat path
4. Java API
添加pom依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
建立Zookeeper连接:
Zookeeper zk = new Zookeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
})
其中connectString是主机地址,如果有多个主机,用逗号隔开,中间不能有空格。sessionTimeout是超时时间,单位是微秒。第三个参数是监听器,里面一般是根据事件类型以及事件路径来做相应的处理,也可在里面继续调用getChildren或者getData方法实现持续监听。
一旦连接上Zookeeper之后就会调用到process方法,里面一般会根据事件类型来对某个countDownLatch变量进行减1操作,在主线程中会等待这个变量为0,即等待Zookeeper连接上。
创建节点:
String node = zk.create(path, data, ZooDfs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
监控子节点的增删(注册监听):
List<String> children = zk.getChildren(path, true)
for (String child : children) {
System.out.println(child);
}
要想验证对子节点增删的监听,首先在java主线程中添加一个睡眠的函数,使其持续运行不至于很快结束,然后在process回调中添加相应的打印代码(比如继续getChildren,打印子节点信息),这样手动去添加节点,会执行到process函数中的打印信息。
判断节点是否存在:
Stat stat = ck.exists(path, false);
System.out.println(stat == null ? "not exist" : "exist");
5. 写数据原理
1)写请求直接发给Leader

其中,只要有半数节点写完,就可以发送ack给客户端,其他没写的服务端稍后再写。
- 写请求发给Follower

这里也是半数节点写完就发送ack给客户端,所不同的是由接受写请求的Follower发送给客户端,而不是Leader,因为客户端最开始建立连接的是Follower。
6. 服务器动态上下线监听案例

分析:客户端监听服务器的上下线,本质是监听子节点的增删,服务器启动时会去Zookeeper集群注册(临时)子节点,使用的是create操作,而客户端监听则是get操作。注意这里的服务器和客户端对于Zookeeper集群来说都是客户端。
于是,代码主要分两部分,服务器创建子节点和客户端监听子节点。
// 服务器
private Zookeeper zk;
public static void main(String[] args) throws Exception {
// 创建本类(服务器类)的对象
DistributeServer server = new DistributeServer();
// 建立Zookeeper连接
server.getConnect();
// 注册,即创建子节点
server.register(args[0]);
// 服务端业务逻辑(睡觉)
server.business();
}
private void business() throws Exception {
Thread.sleep(Long.MAX_VALUE);
}
private void register(String hostName) throws Exception {
String create = zk.create("/servers/" + hostName, hostName.getBytes(), ZooDef.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMRAL_SEQUENTIAL);
System.out.println(hostName + "is online");
}
private void getConnect() throws Exception {
zk = new Zookeeper("xxx", 2000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent){
}
});
}
// 客户端
private Zookeeper zk;
public static void main(String[] args) throws Exception {
// 创建本类(服务器类)的对象
DistributeClient client = new DistributeClient();
// 建立Zookeeper连接
client.getConnect();
// 注册,即创建子节点
client.getServerList();
// 客户端业务逻辑(睡觉)
client.business();
}
private void business() throws Exception {
Thread.sleep(Long.MAX_VALUE);
}
private void getServerList() throws Exception {
List<String> children = zk.getChildren("/servers", true);
List<String> servers = new ArrayList<>;
for (String child : children) {
byte[] data = zk.getData("/servers/" + child, false, null);
servers.add(new String(data));
}
System.out.println(servers);
}
private void getConnect() throws Exception {
zk = new Zookeeper("xxx", 2000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent){
getServerList();
}
});
}
验证时,可以先验证客户端功能,服务端可以先用create -e -s 来代替,如果客户端功能ok,再继续验证服务端功能。
7. 分布式锁案例

分析:进程用客户端表示,每个客户端进程会去Zookeeper中创建一个临时带序号的子节点,如果子节点序号最小,则表示获取到锁,否则监听前一个序号更小的节点,持有锁执行完业务之后,会删除节点,表示释放锁,后面的节点/进场即可获取到锁。

private Zookeeper zk;
private String waitPath;
private String currentNode;
private CountDownLatch connectLatch = new CountDownLatch(1);
private CountDownLatch waitLatch = new CountDownLatch(1);
public DistributeClient() throws Exception {
// 创建本类(服务器类)的对象
DistributeClient client = new DistributeClient();
// 建立Zookeeper连接
getConnect();
connectLatch.await();
}
// 加锁,创建临时节点,并判断是否是序号最小的节点,如果是则获取到锁,处理业务,如果不是,则监听前一个序号较小的节点
public void lock() throws Exception {
// currentNode是全路径名
String currentNode = zk.create("/locks/seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAGE, CreateMode.EPHEMETAL_SEQUENTIAL);
List<String> children = zk.getChildren("locks", false);
if (children.size() == 1) {
return;
} else {
Collections.sort(children);
String thisNode = currentNode.substring("/locks/".length());
int index = children.indexOf(thisNode);
if (index == -1) {
System.out.println("数据异常");
} else if (index == 0) {
return;
} else {
// 监听前一个节点
waitPath = "/locks/" + children.get(index -1);
zk.getData(waitPath, true, null);
waitLatch.await();
}
}
}
public void unlock() throws Exception {
zk.delete(currentNode, -1);
}
private void getConnect() throws Exception {
zk = new Zookeeper("xxx", 2000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (watchedEvent.getType() == Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
if (watchedEvent.getType() == Event.EventType.NodeDeleted && Event.getPath.equals(waitPath)) {
waitLatch.countDown();
}
}
});
}
测试步骤:建立两个线程,每个线程起一个客户端去加锁解锁(加日志打印),加锁解锁之间有睡眠,运行这两个线程,可以看到最终只有1个客户端去持有锁
8. Curator框架
上述分布式锁的案例中,有如下缺点:
1)会话印布链接,需要自己使用CountDownLatch处理
2)监听需要重复注册
3)代码较复杂
4)不支持多节点删除与创建
因此引入Curator框架,添加pom依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>4.3.0</version>
</dependency>
public static void main(String[] args) {
// 获取分布式锁1
InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework, "/locks");
// 获取分布式锁2
InterProcessMutex lock2 = new InterProcessMutex(getCuratorFramework, "/locks");
// 启动两个线程,分别加锁释放锁,该锁可重入
// 加锁: lock1.acquire(); 释放锁: lock1.release();
}
private static CuratorFramework getCuratorFramework() {
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(3000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("xxx").connectionTimeoutMs(2000).sessionTimeoutMs(2000).retryPolicy(retry).build();
client.start();
System.out.println("客户端启动成功");
return client;
}
9. 面试题


版权归原作者 weixin_46628668 所有, 如有侵权,请联系我们删除。