
**Spark编程基础 **[参考Spark大数据技术与应用(第二版)]

从存储系统中创建RDD的使用方法
在Apache Spark中,创建RDD(弹性分布式数据集)主要有两种方式:
从集合中创建RDD:
使用parallelize方法:将本地集合转换为分布式集合。例如,val rdd = sc.parallelize(Array(1, 2, 3, 4, 5, 6))。
使用makeRDD方法:底层实现与parallelize相同,可以指定分区数量。例如,val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), numSlices=3)。
从外部存储中创建RDD:
使用textFile方法:读取文本文件,例如,val lines = sc.textFile("/path/to/file.txt")。
使用其他方法:如通过JDBC访问数据库表或读取HDFS上的文件等。
这两种方式分别对应了将本地数据集并行化以及从外部数据源读取数据的场景。在创建RDD时,可以选择合适的方法来满足需求,并可以通过调整分区数量来优化数据处理效率。
总结:
【内部】makeRDD()、parallelize()
【外部】textFile()
转换操作和行动操作
转换操作通过某种函数将一个RDD 转换为一个新的RDD , 但是转换操作是懒操作,不会立刻执行计算。行动操作是用于触发转换操作的操作,这个时候才会真正开始进行计算。
常用的【转换】操作有
map()转换
filter()过滤
flatMap()切分
union()合并
groupByKey()分组
常用的【行动】操作有
reduce(func)通过函数func聚集数据集中的所有元素。func函数接收两个参数,返回一个值
collect()将数据转化成数组
count()返回数据集中所有元素
first()返回数据集中的第一个元素
take()获取前n个元素
saveAsTextFile()保存路径
foreach(func)对数据集中的每个元素都执行函数func
•filter()、union()、distinct()
filter()方法是一种转换操作,用于过滤RDD中的元素。
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。
distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
•subtract()
subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。
distinct()方法和subtract()方法的区别:
distinct是不同的意思,即RDD中相同的去掉,不同的留下。
subtract是减去的意思,两个RDD求某一RDD的范围内的补集。
代码
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object text02 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("YY")//主机,名字
val sc = new SparkContext(conf)//固定搭配
val rdd1 = sc.parallelize(List(('a',67),('b',100),('c',99),('d',121)))
rdd1.filter(_._2>=100).collect.foreach(println)//filter()过滤
rdd1.filter(x => x._2>100).collect.foreach(println)
val rdd2 = sc.parallelize(List(('e',11),('f',55)))
rdd1.union(rdd2).collect.foreach(println)//union()合并
val rdd3 = sc.parallelize(List(('a',67),('a',67),('b',100),('d',121)))
rdd3.filter(_._2>=100).distinct().collect().foreach(println)//先filter()过滤再distinct()去重
}
}
运行结果
如上图,不难看出第9行和第10行的代码功效是一样的,都是用于过滤的,但过滤的条件不一样,第9行用于过滤rdd1中第二个元素大于等于100
第10行用于过滤rdd1中第二个元素大于100

如上图,为union()合并操作结果

如上图,为union()合并操作结果
•intersection()
intersection()方法用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。
•collect()
collect()方法是一种行动操作,可以将RDD中所有元素转换成数组并返回到Driver端,适用于返回处理后的少量数据。
代码
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object test03 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Y")
val sc = new SparkContext(conf)
val rdd01 = sc.parallelize(List(('a', 1), ('b', 1), ('c', 1)))
val rdd02 = sc.parallelize(List(('d', 1), ('e', 1), ('c', 1)))
rdd01.subtract(rdd02).collect().foreach(println)
rdd02.subtract(rdd01).collect().foreach(println)
}
}
第10行运行结果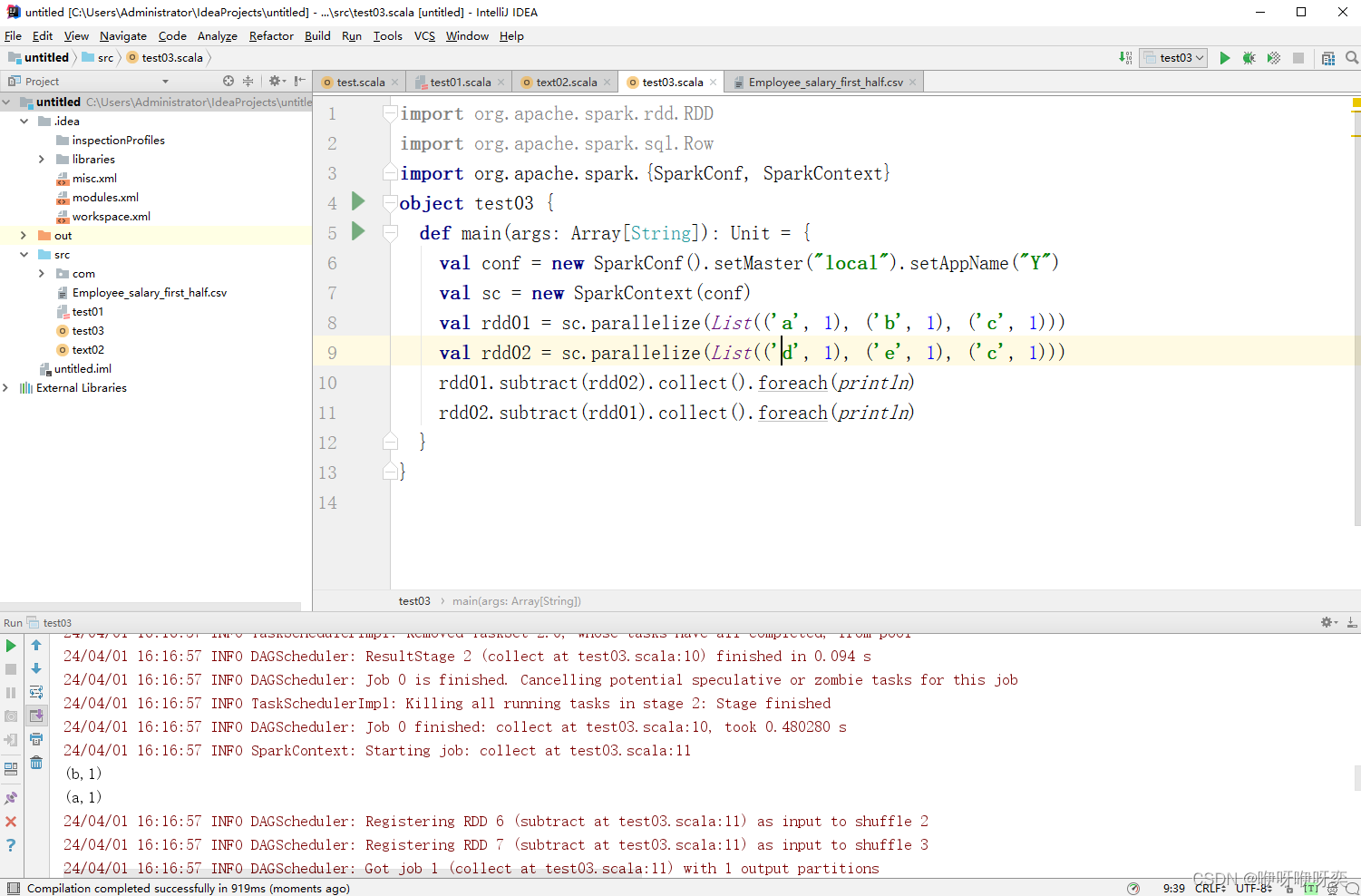
第11行运行结果

•cartesian()
cartesian()方法可将两个集合的元素两两组合成一组,即求笛卡儿积。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object test04 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Y")
val sc = new SparkContext(conf)
val rdd01 = sc.makeRDD(List(1,3,5,3))
val rdd02 = sc.makeRDD(List(2,4,5,1))
rdd01.cartesian(rdd02).collect().foreach(println)
}
}
运行第10行运行结果
•创建键值对RDD
键值对RDD有多种创建方式。很多键值对类型的数据在读取时可以直接返回一个键值对RDD。当需要将一个普通的RDD转化为一个键值对RDD时,可以使用map()方法进行操作。
•reduceByKey()、groupByKey()
reduceByKey()方法用于合并具有相同键的值,作用对象是键值对,并且只对键的值进行处理。
groupByKey()方法用于对具有相同键的值进行分组,可以对同一组的数据进行计数、求和等操作。
代码
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object test05{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Y")
val sc = new SparkContext(conf)
// 创建RDD
val rdd = sc.parallelize(List("this is a test","how are you","I am fine","can you tell me"))
// 建立键值对RDD
val words = rdd.map(x => (x.split(" ")(0),x))
// 查看键值对RDD数据
words.collect().foreach(println)
// 创建RDD
val rdd_1 = sc.parallelize(List(('a',1),('a',2),('b',1),('c',1),('c',1)))
// 使用reduceByKey()方法将值相加
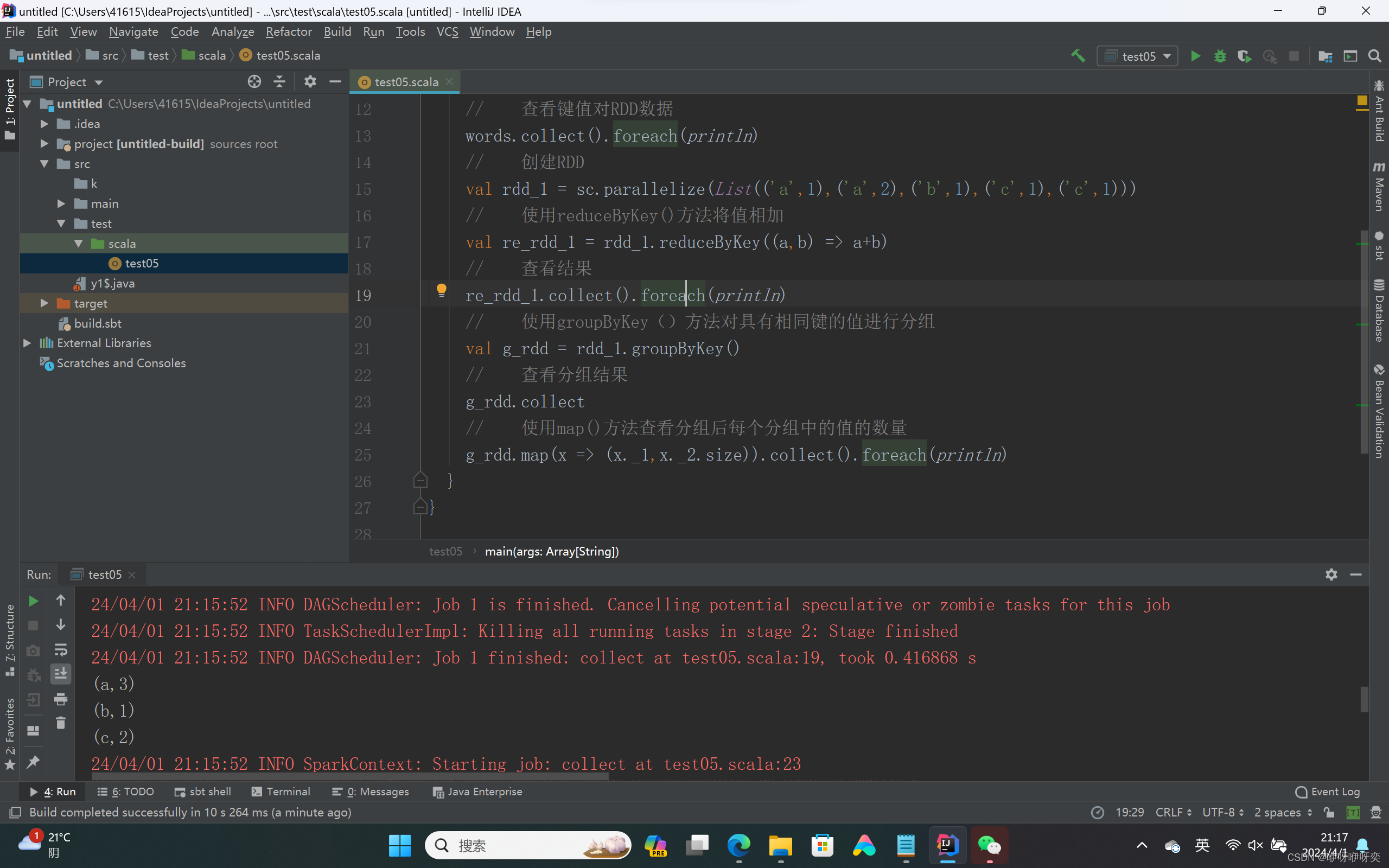
val re_rdd_1 = rdd_1.reduceByKey((a,b) => a+b)
// 查看结果
re_rdd_1.collect().foreach(println)
// 使用groupByKey()方法对具有相同键的值进行分组
val g_rdd = rdd_1.groupByKey()
// 查看分组结果
g_rdd.collect
// 使用map()方法查看分组后每个分组中的值的数量
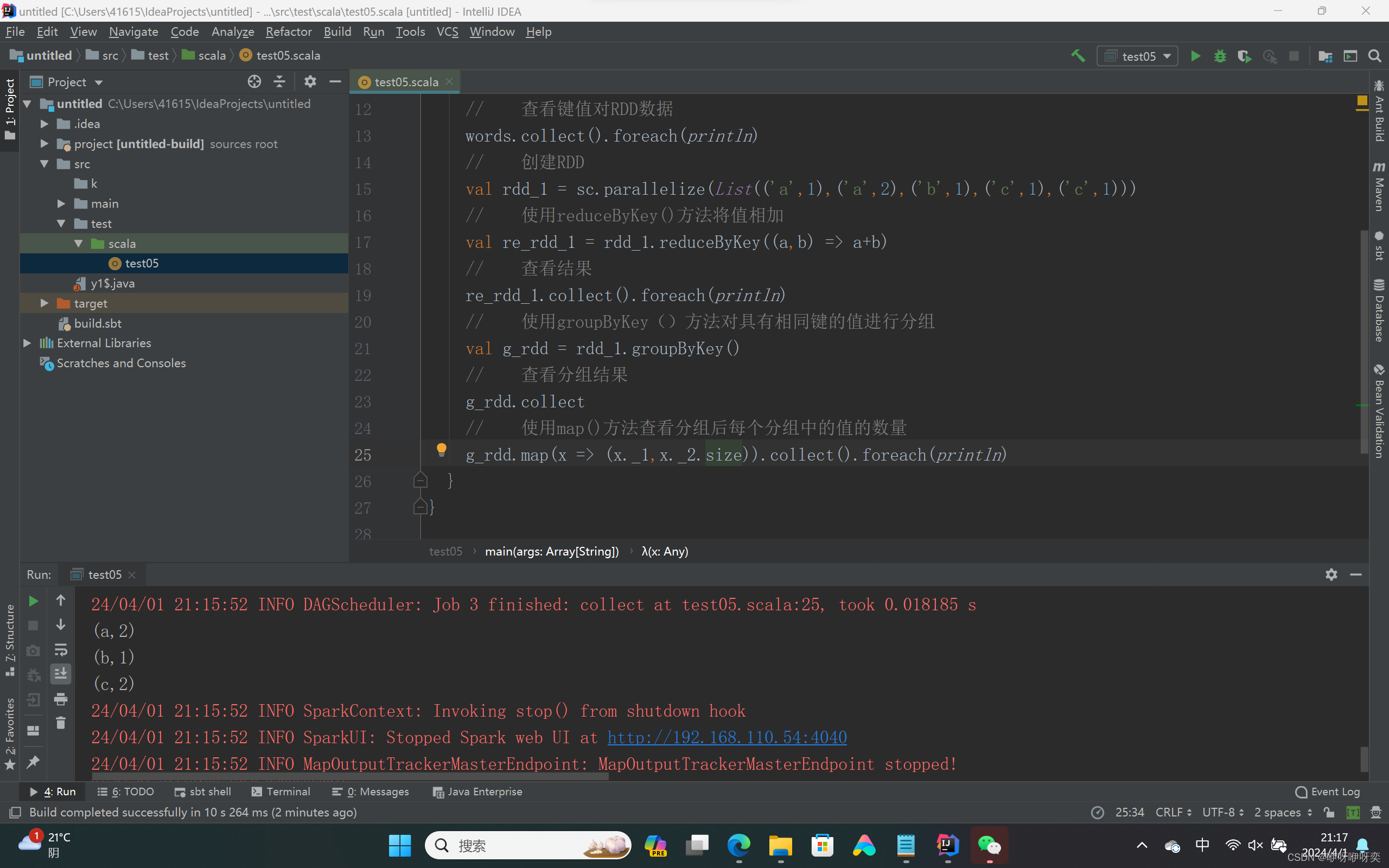
g_rdd.map(x => (x._1,x._2.size)).collect().foreach(println)
}
}
第13行运行结果

第19行运行结果
第25行运行结果
【任务实现】
【3.2.6 任务实现】
查询上半年实际薪资排名前3的员工信息,需要对上半年的实际薪资进行排序,而创建RDD时,textFile()方法是将每一行数据作为一条记录存储的,所以在排序前需要先对数据进行转换,实现步骤如下。
(1)读取CSV文件,将第一行字段名称删除。
(2)将数据按分隔符","分隔,取出第2列员工姓名和第7列实际薪资数据,并将实际薪资数据转换成Int类型数据。
(3)通过sortBy()方法根据实际薪资进行降序排列。
(4)通过take()方法获取上半年实际薪资排名前3的员工信息。

【3.3.5 任务实现】
输出上半年或下半年实际薪资大于20万元的员工姓名,首先需要过滤出两个RDD中实际薪资大于20万元的员工姓名,再将两个RDD得到的员工姓名合并到一个RDD中,对员工姓名进行去重,即可得到上半年或下半年实际薪资大于20万元的员工姓名。

【3.4.6 任务实现】
在读取上、下半年员工薪资数据并将其转换为RDD的过程中,已经将数据转换成键值对RDD。统计每位员工2020年的总实际薪资,首先需要将数据合并到一个RDD中,通过相同的键对同一个员工的上半年实际薪资和下半年实际薪资进行累加,实现步骤如下。
(1)获取上、下半年员工薪资数据并将其转换为RDD,分别为split_first和split_second。
(2)使用union方法将两个RDD合并成一个新的RDD。
(3)通过reduceByKey()方法统计员工实际薪资并输出结果。

代码
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object test02 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Y")
val sc = new SparkContext(conf)
// 创建RDD
val first_half = sc.textFile("C:\\Users\\41615\\IdeaProjects\\untitled\\src\\test\\scala\\Employee_salary_first_half.csv")
// 去除首行数据
val drop_first = first_half.mapPartitionsWithIndex((ix,it) => {
if (ix == 0) it.drop(1)
it
})
// 分割RDD,并取出第2列员工姓名和第7列实际薪资数据
val split_first = drop_first.map(line => {val data = line.split(",");
(data(1),data(6).toInt)})
// 使用sortBy()方法根据实际薪资降序排序
val sort_first = split_first.sortBy(x => x._2,false)
// 取出上半年实际薪资排名前3的员工信息
sort_first.take(3).foreach(println)
}
}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object test01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Y")
val sc = new SparkContext(conf)
// 创建RDD
val first_half = sc.textFile("C:\\Users\\41615\\IdeaProjects\\untitled\\src\\test\\scala\\Employee_salary_first_half.csv")
val second_half = sc.textFile("C:\\Users\\41615\\IdeaProjects\\untitled\\src\\test\\scala\\Employee_salary_second_half.csv")
// 删除首行字段名称数据
val drop_first = first_half.mapPartitionsWithIndex((ix,it) => {
if(ix == 0) it.drop(1)
it
})
val drop_second = second_half.mapPartitionsWithIndex((ix,it) => {
if (ix == 0) it.drop(1)
it
})
// 分割RDD,并取出第2列员工姓名和第7列实际薪资数据
val split_first = drop_first.map(
line => {val data = line.split(",");(data(1),data(6).toInt)})
val split_second = drop_second.map(
line => {val data = line.split(",");(data(1),data(6).toInt)})
// 筛选出上半年或下半年实际薪资大于20万元的员工姓名
val filter_first = split_first.filter(x => x._2 > 200000).map(x =>x._1)
val filter_second = split_second.filter(x => x._2 > 200000).map(x =>x._1)
// 合并两个RDD并去重后输出结果
val name = filter_first.union(filter_second).distinct()
name.collect().foreach(println)
//使用union()方法合并
val all_salary = split_first.union(split_second)
//使用reduceByKey()方法统计员工总实际薪资
val salary = all_salary.reduceByKey((a,b) => a+b)
salary.collect().foreach(println)
}
}
版权归原作者 咿呀咿呀奕 所有, 如有侵权,请联系我们删除。