
文章目录
本套教程针对Flink 1.12.0版本的核心模块进行源码级讲解,从任务提交流程、通讯过程、Task调度、内存模型四大方面入手,庖丁解牛逐行分析源码,手术刀级别剖析Flink内核架构!
任务提交流程
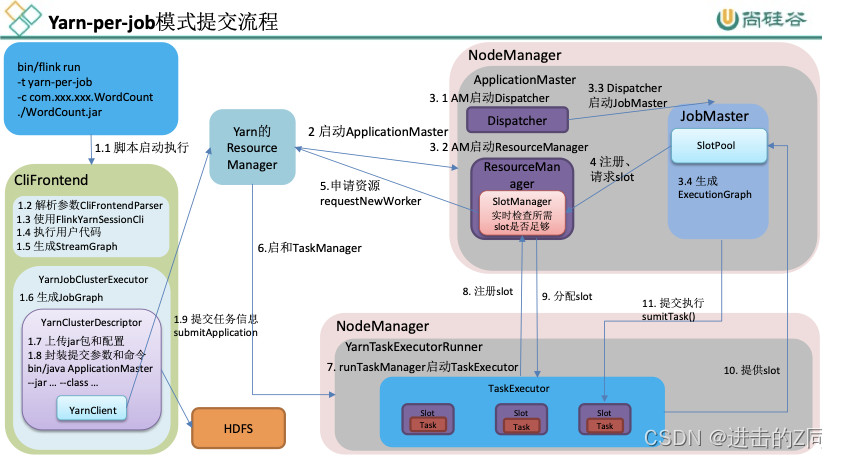
实例以yarn-per-job为例。
flink提交作业是通过flink run进行提交的,可以从提交脚本中看到启动类即程序的入口是:
org.apache.flink.client.cli.CliFrontend
查看其中的main方法,执行的逻辑简单总结如下:
- 获取flink的conf目录的路径
- 根据conf路径,加载配置
- 封装命令行接口:按顺序Generic、Yarn、Default
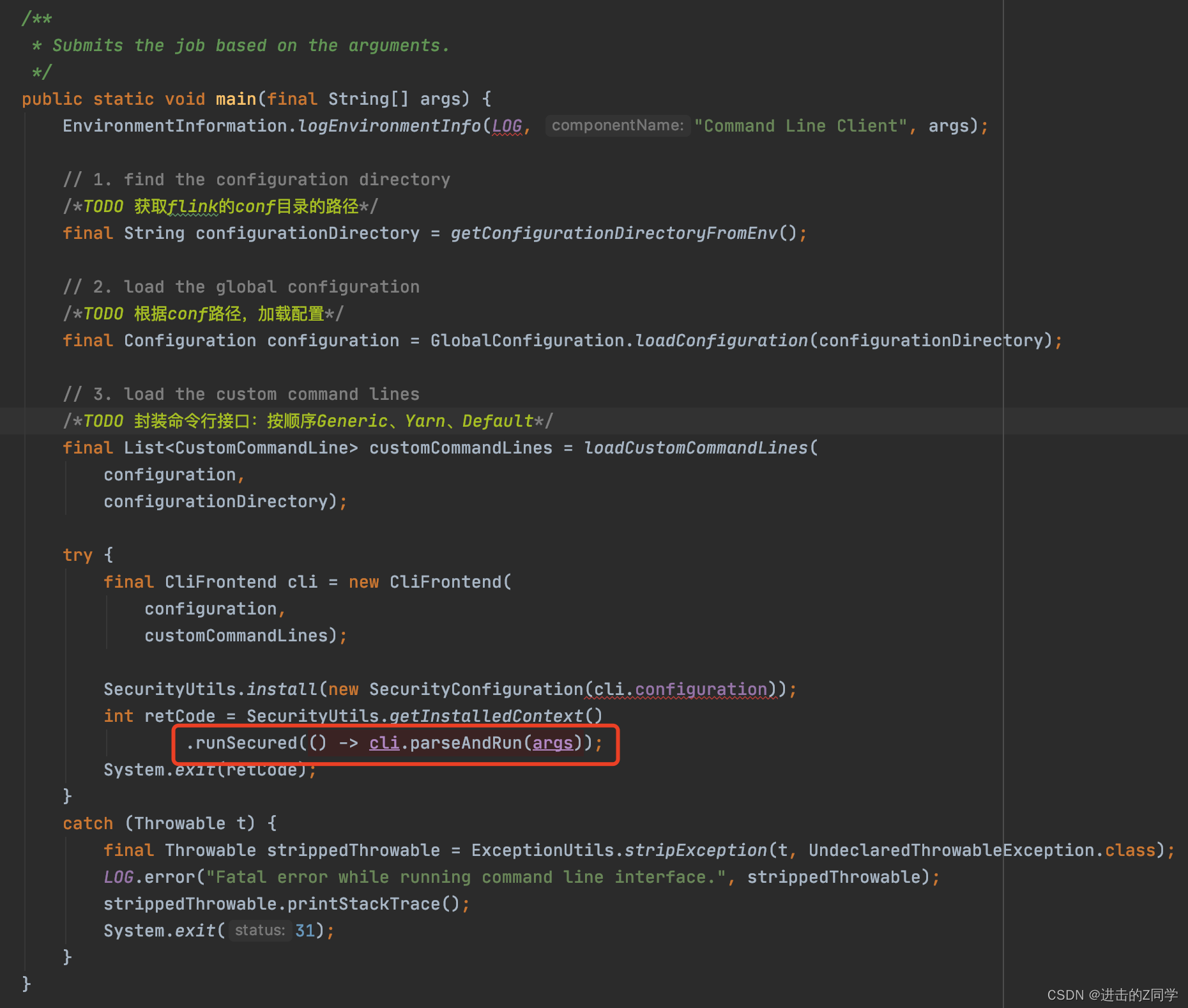
完成配置加载后,真正解析之行flink任务的是下午中的
cli.parseAndRun(args)
:
点进去可以看到里面对应的多种操作,是取第一个参数进行判断,提交时我们用的是
flink run
,明显对应下图run的位置: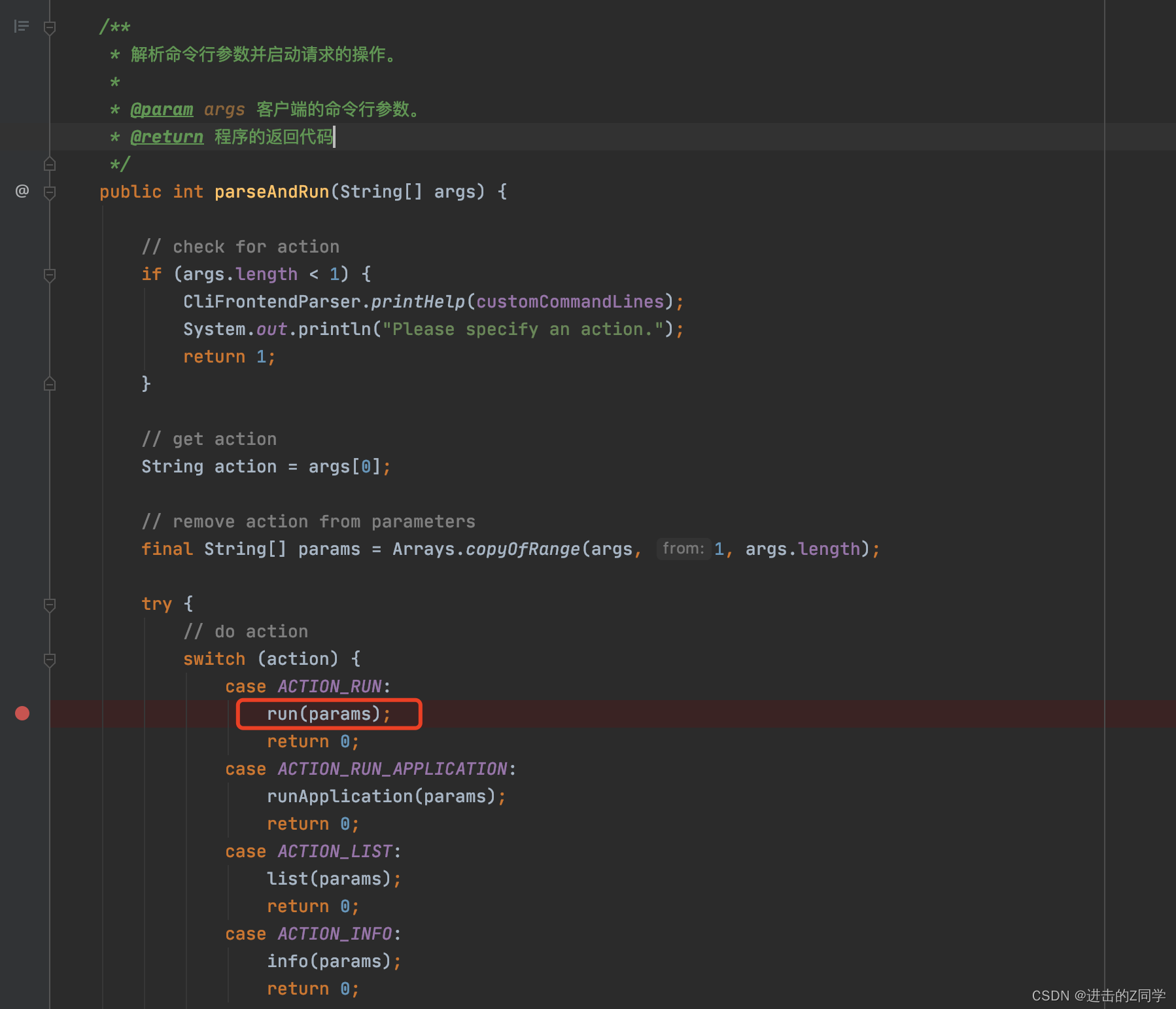
简单看下run方法:
/**
* 执行run操作。
*
* @param args 运行操作的命令行参数。
*/protectedvoidrun(String[] args)throwsException{
LOG.info("Running 'run' command.");/*TODO 获取run动作,默认的配置项*/finalOptions commandOptions =CliFrontendParser.getRunCommandOptions();/*TODO 根据用户指定的配置项,进行解析 例如-t -p -c等*/finalCommandLine commandLine =getCommandLine(commandOptions, args,true);// evaluate help flagif(commandLine.hasOption(HELP_OPTION.getOpt())){CliFrontendParser.printHelpForRun(customCommandLines);return;}/*TODO 根据之前添加的顺序,挨个判断是否active:Generic、Yarn、Default*/finalCustomCommandLine activeCommandLine =validateAndGetActiveCommandLine(checkNotNull(commandLine));finalProgramOptions programOptions =ProgramOptions.create(commandLine);/*TODO 获取 用户的jar包和其他依赖*/finalList<URL> jobJars =getJobJarAndDependencies(programOptions);/*TODO 获取有效配置:HA的id、Target(session、per-job)、JobManager内存、TaskManager内存、每个TM的slot数...*/finalConfiguration effectiveConfiguration =getEffectiveConfiguration(
activeCommandLine, commandLine, programOptions, jobJars);
LOG.debug("Effective executor configuration: {}", effectiveConfiguration);finalPackagedProgram program =getPackagedProgram(programOptions, effectiveConfiguration);try{/*TODO 执行程序*/executeProgram(effectiveConfiguration, program);}finally{
program.deleteExtractedLibraries();}}
在判断是否active的地方可以进去查看isActive方法:
@OverridepublicbooleanisActive(CommandLine commandLine){finalString jobManagerOption = commandLine.getOptionValue(addressOption.getOpt(),null);/*TODO ID是固定的字符串 "yarn-cluster"*/finalboolean yarnJobManager = ID.equals(jobManagerOption);/*TODO 判断是否存在 Yarn Session对应的 AppID*/finalboolean hasYarnAppId = commandLine.hasOption(applicationId.getOpt())|| configuration.getOptional(YarnConfigOptions.APPLICATION_ID).isPresent();finalboolean hasYarnExecutor =YarnSessionClusterExecutor.NAME.equalsIgnoreCase(configuration.get(DeploymentOptions.TARGET))||YarnJobClusterExecutor.NAME.equalsIgnoreCase(configuration.get(DeploymentOptions.TARGET));/*TODO -m yarn-cluster || yarn有appID,或者命令行指定了 || 执行器是yarn的 这三个条件满足一个就走yarn*/return hasYarnExecutor || yarnJobManager || hasYarnAppId;}
可以知道session模式的化会指定好applicationId。
如果yarn的不符合,就只能走default,DefaultCLI的isActive逻辑直接返回true。
yarn-per-job新老版本写法:
老版本(<=1.10):flink run -m yarn-cluster -c xxxxx xxx.jar
新版本(>=1.11):flink run -t yarn-per-job -c xxxxx xxx.jar
提交流程-执行用户代码
前面说了client提交的大概流程,我们知道程序开始执行其实是执行
StreamExecutionEnvironment.execute()
开始的。这里会生成StreamGraph:
publicJobExecutionResultexecute(String jobName)throwsException{Preconditions.checkNotNull(jobName,"Streaming Job name should not be null.");/*TODO 获取StreamGraph,并接着执行*/returnexecute(getStreamGraph(jobName));}
层层进去可以到
AbstractJobClusterExecutor.execute
,这里将streamGraph转换为jobGragh:
@OverridepublicCompletableFuture<JobClient>execute(@NonnullfinalPipeline pipeline,@NonnullfinalConfiguration configuration,@NonnullfinalClassLoader userCodeClassloader)throwsException{/*TODO 将 流图(StreamGraph) 转换成 作业图(JobGraph)*/finalJobGraph jobGraph =PipelineExecutorUtils.getJobGraph(pipeline, configuration);/*TODO 集群描述器:创建、启动了 YarnClient, 包含了一些yarn、flink的配置和环境信息*/try(finalClusterDescriptor<ClusterID> clusterDescriptor = clusterClientFactory.createClusterDescriptor(configuration)){finalExecutionConfigAccessor configAccessor =ExecutionConfigAccessor.fromConfiguration(configuration);/*TODO 集群特有资源配置:JobManager内存、TaskManager内存、每个Tm的slot数*/finalClusterSpecification clusterSpecification = clusterClientFactory.getClusterSpecification(configuration);finalClusterClientProvider<ClusterID> clusterClientProvider = clusterDescriptor
.deployJobCluster(clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID "+ jobGraph.getJobID());returnCompletableFuture.completedFuture(newClusterClientJobClientAdapter<>(clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));}}
继续往里走可以发现会在
YarnClusterClientFactory.getClusterDescriptor
中创建
yarnclient
,这里是根据
conf/flink-conf.yaml
里的配置制定使用对应的工厂创建(standalone、yarn、k8s等),从这段代码可以看出,是先生成了applicaitonId,后启动AM:
privateYarnClusterDescriptorgetClusterDescriptor(Configuration configuration){/*TODO 创建了YarnClient*/finalYarnClient yarnClient =YarnClient.createYarnClient();finalYarnConfiguration yarnConfiguration =newYarnConfiguration();/*TODO 初始化、启动 YarnClient*/
yarnClient.init(yarnConfiguration);
yarnClient.start();returnnewYarnClusterDescriptor(
configuration,
yarnConfiguration,
yarnClient,YarnClientYarnClusterInformationRetriever.create(yarnClient),false);}
执行到
YarnClusterDescriptor.deployInternal
可以看到这里会开始提交任务到yarn上:
/**
* 此方法将阻塞,直到ApplicationMaster/Jobmanager已在yarn上部署为止。
*
* @param clusterSpecification Initial cluster specification for the Flink cluster to be deployed
* @param applicationName name of the Yarn application to start
* @param yarnClusterEntrypoint Class name of the Yarn cluster entry point.
* @param jobGraph A job graph which is deployed with the Flink cluster, {@code null} if none
* @param detached True if the cluster should be started in detached mode
*/privateClusterClientProvider<ApplicationId>deployInternal(ClusterSpecification clusterSpecification,String applicationName,String yarnClusterEntrypoint,@NullableJobGraph jobGraph,boolean detached)throwsException{finalUserGroupInformation currentUser =UserGroupInformation.getCurrentUser();if(HadoopUtils.isKerberosSecurityEnabled(currentUser)){boolean useTicketCache = flinkConfiguration.getBoolean(SecurityOptions.KERBEROS_LOGIN_USETICKETCACHE);if(!HadoopUtils.areKerberosCredentialsValid(currentUser, useTicketCache)){thrownewRuntimeException("Hadoop security with Kerberos is enabled but the login user "+"does not have Kerberos credentials or delegation tokens!");}}/*TODO 部署前检查:jar包路径、conf路径、yarn最大核数....*/isReadyForDeployment(clusterSpecification);// ------------------ Check if the specified queue exists --------------------/*TODO 检查指定的yarn队列是否存在*/checkYarnQueues(yarnClient);// ------------------ Check if the YARN ClusterClient has the requested resources --------------/*TODO 检查yarn是否有足够的资源*/// Create application via yarnClient/*获取生成applicationId*/finalYarnClientApplication yarnApplication = yarnClient.createApplication();finalGetNewApplicationResponse appResponse = yarnApplication.getNewApplicationResponse();Resource maxRes = appResponse.getMaximumResourceCapability();finalClusterResourceDescription freeClusterMem;try{
freeClusterMem =getCurrentFreeClusterResources(yarnClient);}catch(YarnException|IOException e){failSessionDuringDeployment(yarnClient, yarnApplication);thrownewYarnDeploymentException("Could not retrieve information about free cluster resources.", e);}finalint yarnMinAllocationMB = yarnConfiguration.getInt(YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB,YarnConfiguration.DEFAULT_RM_SCHEDULER_MINIMUM_ALLOCATION_MB);if(yarnMinAllocationMB <=0){thrownewYarnDeploymentException("The minimum allocation memory "+"("+ yarnMinAllocationMB +" MB) configured via '"+YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB
+"' should be greater than 0.");}finalClusterSpecification validClusterSpecification;try{
validClusterSpecification =validateClusterResources(
clusterSpecification,
yarnMinAllocationMB,
maxRes,
freeClusterMem);}catch(YarnDeploymentException yde){failSessionDuringDeployment(yarnClient, yarnApplication);throw yde;}
LOG.info("Cluster specification: {}", validClusterSpecification);finalClusterEntrypoint.ExecutionMode executionMode = detached ?ClusterEntrypoint.ExecutionMode.DETACHED
:ClusterEntrypoint.ExecutionMode.NORMAL;
flinkConfiguration.setString(ClusterEntrypoint.EXECUTION_MODE, executionMode.toString());/*TODO 开始启动AM*/ApplicationReport report =startAppMaster(
flinkConfiguration,
applicationName,
yarnClusterEntrypoint,
jobGraph,
yarnClient,
yarnApplication,
validClusterSpecification);// print the application id for user to cancel themselves.if(detached){finalApplicationId yarnApplicationId = report.getApplicationId();logDetachedClusterInformation(yarnApplicationId, LOG);}setClusterEntrypointInfoToConfig(report);return()->{try{returnnewRestClusterClient<>(flinkConfiguration, report.getApplicationId());}catch(Exception e){thrownewRuntimeException("Error while creating RestClusterClient.", e);}};}
提交流程-启动AM
上面代码的
YarnClusterDescriptor.startAppMaster
方法开始启动AM,简单流程如下:
- 初始化、创建 Hadoop的 FileSystem
- 上传:用户jar包、flink的依赖、flink的配置文件
- 创建Map,用来存储 AM的环境变量和类路径
- 将之前封装的 Map(AM的环境信息、类路径),设置到容器里
- 前面做了很多上传、环境配置,终于可以提交应用了 -
yarnClient.submitApplication(appContext);- 这里就是yarn的源码了,和flink无关。 - 注意上面是异步提交,下面有个while循环,一直靠appId去获取提交状态 -
report = yarnClient.getApplicationReport(appId);- 只有状态变为 RUNNING 或者 FINISHED 时才返回,表示提交成功(AM启动成功)
AM启动后程序的执行入口类是
YarnJobClusterEntrypoint
,可以查看其中的main方法,最终调用的主要防范为
ClusterEntrypoint.runCluster
,主要的流程如下:
- 初始化服务:Rpc相关(Akka)
- 创建和启动 JobManager里的组件:Dispatcher、ResourceManager(注意和yarn的不一样,这个是JM里的)、JobMaster - 创建 ResourceManager:Yarn模式的 ResourceManager- 创建和启动 Dispatcher => dispatcher会创建和启动JobMaster - 启动 dispatcher服务- 创建JobMaster- 启动JobMaster - 启动心跳服务:taskmanager、resourcemanager- 启动 slotpool- 与ResourceManager建立连接(JM维护了一个监听器),slotpool开始请求资源- 启动 ResourceManager - 创建了Yarn的RM和NM的客户端,初始化并启动 - 创建Yarn的ResourceManager的客户端,并且初始化和启动,同时注册AM- 创建yarn的 NodeManager的客户端,并且初始化和启动- 通过选举服务,启动ResourceManager- 启动心跳服务:TaskManager、JobMaster- 启动slotManager
此时JobManager(也是AM)的三大组件就都启动好了。
提交流程-SlotPool向RM申请资源
- JobMaster启动时,启动SlotPool,向ResourceManager注册
- SlotPool 申请 slot,由ResourceManager里的SlotManager处理请求
- ResourceManager内部的 slotManager去向 Yarn的ResourceManager申请资源 > 这里会有区分如果SlotManager中有资源的话(如session模式已经预分配了资源)会直接分配资源给JM的SlotPool启动task,资源不够的话才和Yarn的ResourceManager申请资源。
提交流程-启动TaskManager
- 通过Rpc服务,启动 TaskExecutor,找 它的 onStart()方法
- 启动 TaskExecutor服务
- 向ResoueceManager注册Slot(是向slotmanager注册)
- 回到上面的JM的SlotPool向RM申请资源,RM中的SlotManager会分配slot给JM,分配完之后,通知TM提供Slot给JM。 - TM根据RM的命令,分配自己的slot- 与JM建立连接,向JM提供slot- JM向接受到的slot分配task(
SlotPool.offsetSlot)
总结:
flink run per-job提交后启动的主要进程:
flink run -t yarn-per-job -c .... xxx.jar
CliFrontend
参数解析
封装CommandLine:三个,依次添加
配置的封装
执行用户代码: execute()
生成StreamGraphExecutor:生成JobGraph
集群描述器:上传jar包、配置, 封装提交给yarn的命令
yarnclient提交应用
YarnJobClusterEntryPoint:AM执行的入口类
1、Dispatcher的创建和启动
2、ResourceManager的创建、启动:里面有一个 slotmanager(真正管理资源的、向yarn申请资源)
3、Dispatcher启动JobMaster:生成ExecutionGraph(里面有一个slotpool,真正去发送请求的)
4、slotpool向slotmanager申请资源, slotmanager向yarn申请资源(启动新节点)
YarnTaskExecutorRunner:Yarn模式下的TaskManager的入口类
1、启动 TaskExecutor2、向ResourceManager注册slot
3、ResourceManager分配slot
4、TaskExecutor接收到分配的指令,提供offset给JobMaster(slotpool)
5、JobMaster提交任务给TaskExecutor去执行
这里注意理解:AM的整体进程我们可以理解为JobManager,里面又有三个组件:Dispatcher、JobMaster(有时候也叫JobManager)、ResourceManager。
通信组件
Flink内部节点之间的通信是用Akka,比如JobManager和TaskManager之间的通信。而operator之间的数据传输是利用Netty。
Flink通过Akka进行的分布式通信的实现,在0.9版中采用。使用Akka,所有远程过程调用现在都实现为异步消息。这主要影响组件JobManager,TaskManager 和JobClient。 将来,甚至有可能将更多的组件转换为参与者,从而允许它们发送和处理异步消息。
RPC框架是Flink任务运行的基础,Flink整个RPC框架基于Akka实现,并对Akka中的ActorSystem、Actor进行了封装和使用,Flink整个通信框架的组件主要由RpcEndpoint、RpcService、RpcServer、AkkaInvocationHandler、AkkaRpcActor等构成。RpcEndpoint定义了一个Actor的路径;RpcService提供了启动RpcServer、执行代码体等方法;RpcServer/AkkaInvocationHandler提供了与Actor通信的接口;AkkaRpcActor为Flink封装的Actor。下面分析Flink底层RPC通信框架的实现和相关流程。
Akka与Actor 模型
Akka是一个开发并发、容错和可伸缩应用的框架。它是Actor Model的一个实现,和Erlang的并发模型很像。在Actor模型中,所有的实体被认为是独立的actors。actors和其他actors通过发送异步消息通信。Actor模型的强大来自于异步。它也可以显式等待响应,这使得可以执行同步操作。但是,强烈不建议同步消息,因为它们限制了系统的伸缩性。每个actor有一个邮箱(mailbox),它收到的消息存储在里面。另外,每一个actor维护自身单独的状态。一个Actors网络如下所示:
Akka是一个开发并发、容错和可伸缩应用的框架。它是Actor Model的一个实现,和Erlang的并发模型很像。在Actor模型中,所有的实体被认为是独立的actors。actors和其他actors通过发送异步消息通信。Actor模型的强大来自于异步。它也可以显式等待响应,这使得可以执行同步操作。但是,强烈不建议同步消息,因为它们限制了系统的伸缩性。每个actor有一个邮箱(mailbox),它收到的消息存储在里面。另外,每一个actor维护自身单独的状态。一个Actors网络如下所示: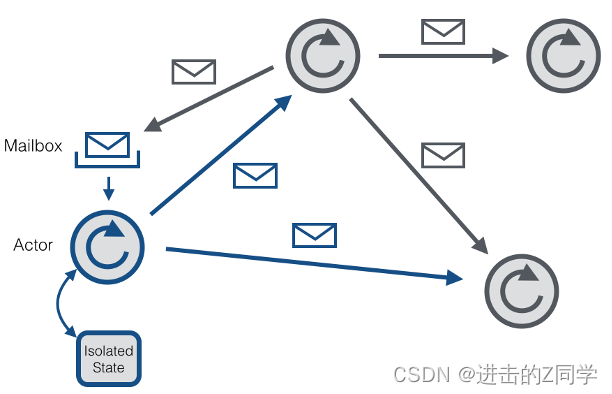
每个actor是一个单一的线程,它不断地从其邮箱中poll(拉取)消息,并且连续不断地处理。对于已经处理过的消息的结果,actor可以改变它自身的内部状态或者发送一个新消息或者孵化一个新的actor。尽管单个的actor是自然有序的,但一个包含若干个actor的系统却是高度并发的并且极具扩展性的。因为那些处理线程是所有actor之间共享的。这也是我们为什么不该在actor线程里调用可能导致阻塞的“调用”。因为这样的调用可能会阻塞该线程使得他们无法替其他actor处理消息。
Actor系统
一个Actor系统包含了所有存活的actors。它提供的共享服务包括调度、配置和日志等。Actor系统同时包含一个线程池,所有actor从这里获取线程。
多个Actor系统可以在一台机器上共存。如果一个Actor系统通过RemoteActorRefProvider启动,它就可以被其他机器上的Actor系统发现。Actor系统能够自动识别消息是发送给本地机器还是远程机器的Actor系统。在本地通信的情况下,消息通过共享存储器高效的传输。在远程通信的情况下,消息通过网络栈发送。
所有Actors都是继承来组织的。每个新创建的actor将其创建的actor视作父actor。继承被用来监督。每个父actor对自己的子actor负责监督。如果在一个子actor发生错误,父actor将会收到通知。如果这个父actor可以解决这个问题,它就重新启动这个子actor。如果这个错误父actor无法处理,它可以把这个错误传递给自己的父actor。
第一个actor通过系统创建,由/user 这个actor负责监督。详细的Actor的继承制度可以参考https://doc.akka.io//docs/akka/snapshot/general/supervision.html。
Flink中的Actors
Actor是一个包含状态和行为的容器。actor线程顺序处理收到的消息。这样就让用户摆脱锁和线程管理的管理,因为一次只有已给线程对一个actor有效。但是,必须确保只有这个actor线程可以处理其内部状态。Actor的行为由receive函数定义,该函数包含收到的消息的处理逻辑。
Flink系统由3个分布式组件构成:JobClient,JobManager和TaskManager。JobClient从用户处得到Flink Job,并提交给JobManager。JobManager策划这个job的执行。首先,它分配所需的资源,主要就是TaskManagers上要执行的slot。
在资源分配之后,JobManager部署单独的任务到响应的TaskManager上。一旦收到一个任务,TaskManager产生一个线程用来执行这个任务。状态的改变,比如开始计算或者完成计算,将被发送回JobManager。基于这些状态的更新,JobManager将引导这个job的执行直到完成。一旦一个job被执行完,其结果将会被发送回JobClient。Job的执行图如下所示: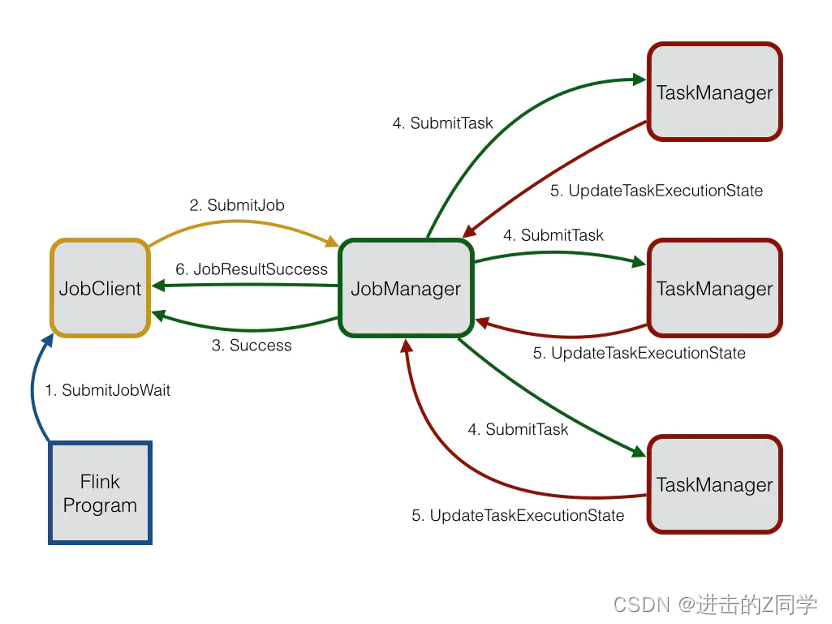
异步 vs 同步消息
在任何地方,Flink尝试使用异步消息和通过Futures(用来获取异步的响应)来处理响应。Futures和很少的几个阻塞调用有一个超时时间,以防操作失败。这是为了防止死锁,当消息丢失或者分布式组件crash。但是,如果在一个大集群或者慢网络的情况下,超时可能会使得情况更糟。因此,操作的超时时间可以通过“akka.timeout.timeout”来配置。
在两个actor可以通信之前,需要获取一个ActorRef。这个操作的查找同样需要一个超时。为了使得系统尽可能快速的失败,如果一个actor还没开始,超时时间需要被设置的比较小。为了以防经历查询超时,可以通过“akka.lookup.timeout”配置增加查询时间。
Akka的另一个特点是限制发送的最大消息大小。原因是它保留了同样数据大小的序列化buffer和不想浪费空间。如果你曾经遇到过传输失败,因为消息超过了最大大小,你可以增加“akka.framesize”配置来增加大小。
使用Akka
Akka部分后面补充
…
Actor路径
获取Actor
与Actor通信
Akka有两种核心的异步通信方式:tell和ask。
tell方式
当使用tell方式时,表示仅仅使用异步方式给某个Actor发送消息,无需等待Actor的响应结果,并且也不会阻塞后续代码的运行…
ask方式
当我们需要从Actor获取响应结果时,可使用ask方法,ask方法会将返回结果包装在scala.concurrent.Future中,然后通过异步回调获取返回结果。
…
上面主要介绍了Akka中的ActorSystem、Actor,及与Actor的通信;Flink借此构建了其底层通信系统。
RPC
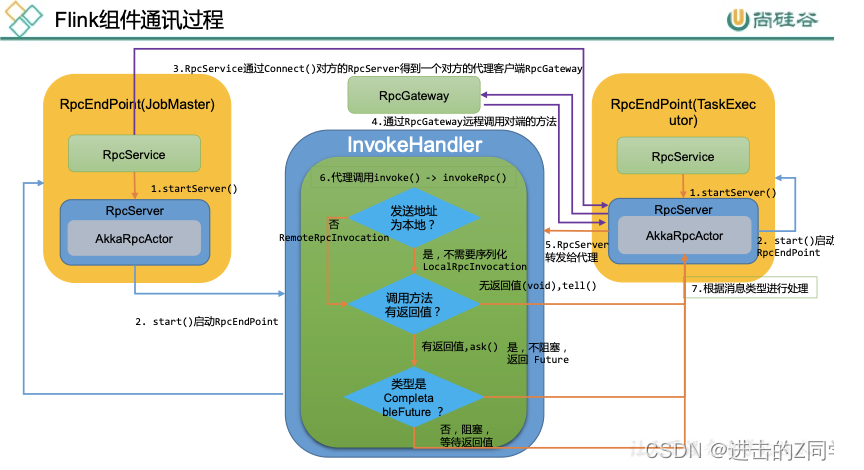
…
RpcGateway
Flink的RPC协议通过RpcGateway来定义,主要定义通信行为;用于远程调用RpcEndpoint的某些方法,可以理解为对方的客服端代理。
若想与远端Actor通信,则必须提供地址(ip和port),如在Flink-on-Yarn模式下,JobMaster会先启动ActorSystem,此时TaskExecutor的Container还未分配,后面与TaskExecutor通信时,必须让其提供对应地址。
…
RpcEndpoint
RpcEndpoint是通信终端,提供RPC服务组件的生命周期管理(start、stop)。每个RpcEndpoint对应了一个路径(endpointId和actorSystem共同确定),每个路径对应一个Actor
…
RpcService 和 RpcServer
RpcService 和 RpcServer是RpcEndPoint的成员变量。
…
AkkaRpcActor
AkkaRpcActor是Akka的具体实现,主要负责处理如下类型消息:
- 本地Rpc调用LocalRpcInvocation 会指派给RpcEndpoint进行处理,如果有响应结果,则将响应结果返还给Sender。
- RunAsync & CallAsync 这类消息带有可执行的代码,直接在Actor的线程中执行。
- 控制消息ControlMessages 用来控制Actor行为,START启动,STOP停止,停止后收到的消息会丢弃掉。
RPC交互过程
RPC通信过程分为请求和响应。
RPC请求发送
RPC请求响应
Flink任务调度机制
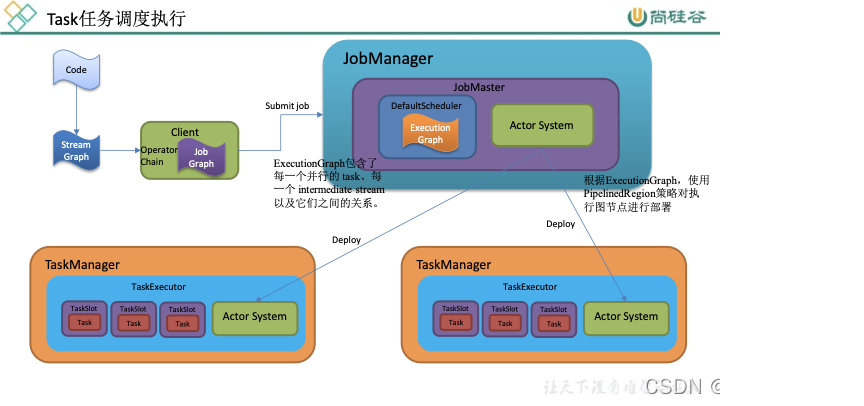
Graph 的概念
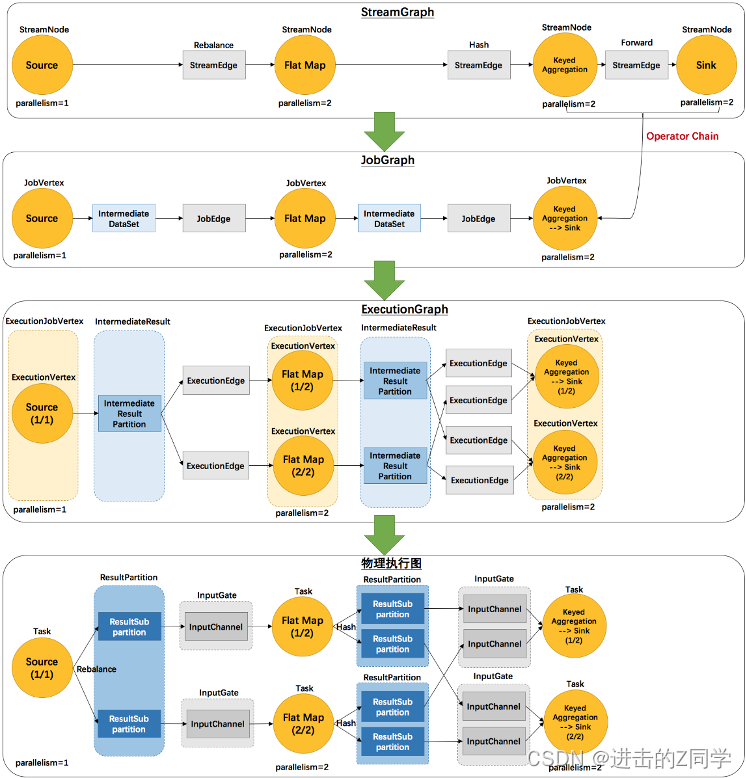
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
例如example里的SocketTextStreamWordCount并发度为2(Source为1个并发度)的四层执行图的演变过程如下图所示:
publicstaticvoidmain(String[] args)throwsException{// 检查输入finalParameterTool params =ParameterTool.fromArgs(args);...// set up the execution environmentfinalStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// get input dataDataStream<String> text =
env.socketTextStream(params.get("hostname"), params.getInt("port"),'\n',0);DataStream<Tuple2<String,Integer>> counts =// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(newTokenizer())// group by the tuple field "0" and sum up tuple field "1".keyBy(0).sum(1);
counts.print();// execute program
env.execute("WordCount from SocketTextStream Example");}
名词解释:(后面补充…)
StreamGraph 在 Client 生成
JobGraph 在 Client 生成
ExecutionGraph 在 JobManager 生成
物理执行图(Task 的调度和执行)
调度
调度器是Flink作业执行的核心组件,管理作业执行的所有相关过程,包括JobGraph到ExecutionGraph的转换、作业生命周期管理(作业的发布、取消、停止)、作业的Task生命周期管理(Task的发布、取消、停止)、资源申请与释放、作业和Task的Failover等。
调度有几个重要的组件:
- 调度器:SchedulerNG及其子类、实现类
- 调度策略:SchedulingStrategy及其实现类
- 调度模式:ScheduleMode包含流和批的调度,有各自不同的调度模式
调度器
调度器作用:
- 作业的生命周期管理,如作业的发布、挂起、取消
- 作业执行资源的申请、分配、释放
- 作业的状态管理,作业发布过程中的状态变化和作业异常时的FailOver等
- 作业的信息提供,对外提供作业的详细信息
…
调度行为
调度模式
ScheduleMode决定如何启动ExecutionGraph中的Task。Flink提供3中调度模式:
- Eager调度适用于流计算。一次性申请需要的所有资源,如果资源不足,则作业启动失败。
- 分阶段调度LAZY_FROM_SOURCES适用于批处理。从SourceTask开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游Task执行完毕后开始调度执行下游的Task,读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的Task,依次进行调度,直到作业完成。
- 分阶段Slot重用调度LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST适用于批处理。与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作业,但是需要确保在本阶段的作业执行中没有Shuffle行为。 目前视线中的Eager模式和LAZY_FROM_SOURCES模式的资源申请逻辑一样,LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST是单独的资源申请逻辑。
调度策略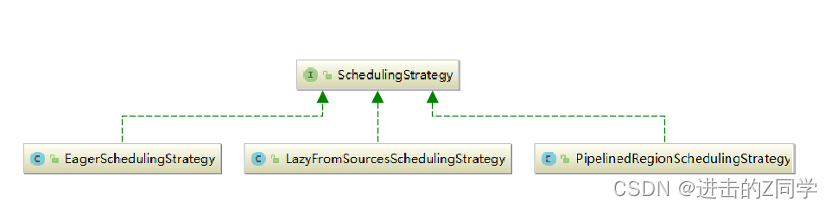
调度策略有三种实现:
- EagerSchedulingStrategy:适用于流计算,同时调度所有的task
- LazyFromSourcesSchedulingStrategy:适用于批处理,当输入数据准备好时(上游处理完)进行vertices调度。
- PipelinedRegionSchedulingStrategy:以流水线的局部为粒度进行调度
Flink内存管理
目前,大数据计算引擎主要用 Java 或是基于 JVM 的编程语言实现的,例如 Apache Hadoop、Apache Spark、Apache Drill、Apache Flink等。Java语言的好处在于程序员不需要太关注底层内存资源的管理,但同样会面临一个问题,就是如何在内存中存储大量的数据(包括缓存和高效处理)。Flink使用自主的内存管理,来避免这个问题。
JVM内存管理的不足:
- Java 对象存储密度低。Java的对象在内存中存储包含3个主要部分:对象头、实例数据、对齐填充部分。例如,一个只包含 boolean 属性的对象占16byte:对象头占8byte,boolean 属性占1byte,为了对齐达到8的倍数额外占7byte。而实际上只需要一个bit(1/8字节)就够了。
- Full GC 会极大地影响性能。尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
- OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
- 缓存未命中问题。CPU进行计算的时候,是从CPU缓存中获取数据。现代体系的CPU会有多级缓存,而加载的时候是以Cache Line为单位加载。如果能够将对象连续存储,这样就会大大降低Cache Miss。使得CPU集中处理业务,而不是空转。(Java对象在堆上存储的时候并不是连续的,所以从内存中读取Java对象时,缓存的邻近的内存区域的数据往往不是CPU下一步计算所需要的,这就是缓存未命中。此时CPU需要空转等待从内存中重新读取数据。)
Flink 并不是将大量对象存在堆内存上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做 MemorySegment,它代表了一段固定长度的内存(默认大小为 32KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法,很多运算可以直接操作二进制数据,不需要反序列化即可执行。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
内存模型

JobManager内存模型
JobManagerFlinkMemory.java
由堆内和堆外两部分组成。
在1.10中,Flink 统一了 TM 端的内存管理和配置,相应的在1.11中,Flink 进一步对JM 端的内存配置进行了修改,使它的选项和配置方式与TM 端的配置方式保持一致。
1.10版本
# The heap size for the JobManager JVM
jobmanager.heap.size:1024m
1.11版本及以后
# The total process memory size for the JobManager.
#
# Notethis accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.
jobmanager.memory.process.size:1600m
TaskManager内存模型
Flink 1.10 对TaskManager的内存模型和Flink应用程序的配置选项进行了重大更改,让用户能够更加严格地控制其内存开销。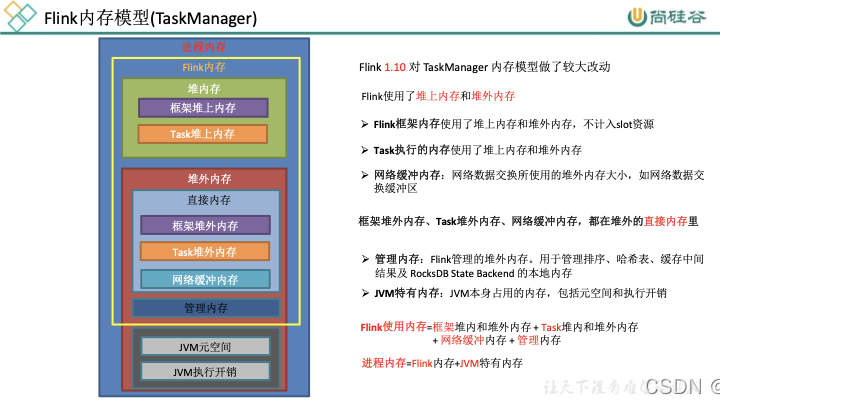
TaskExecutorFlinkMemory.java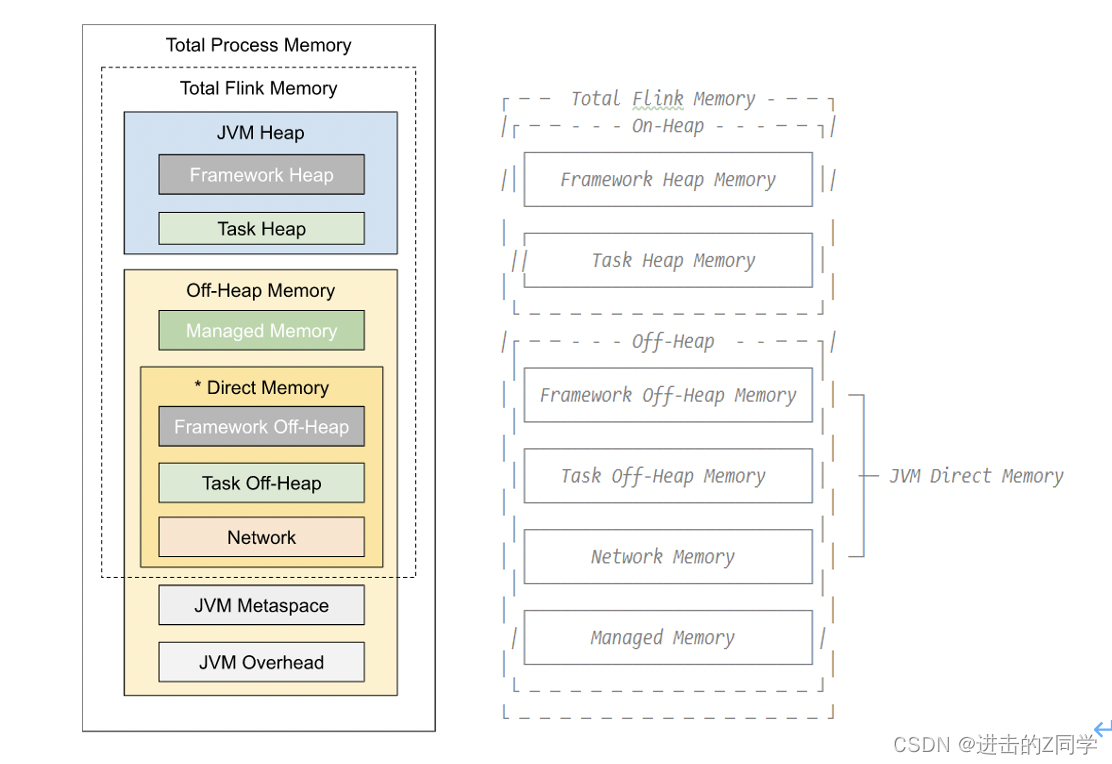
JVM Heap:JVM堆上内存
- Framework Heap Memory:Flink框架本身使用的内存,即TaskManager本身所占用的堆上内存,不计入Slot的资源中。 配置参数:taskmanager.memory.framework.heap.size=128MB,默认128MB
- Task Heap Memory:Task执行用户代码时所使用的堆上内存。 配置参数:taskmanager.memory.task.heap.size
Off-Heap Mempry:JVM堆外内存
- DirectMemory:JVM直接内存 - Framework Off-Heap Memory:Flink框架本身所使用的内存,即TaskManager本身所占用的对外内存,不计入Slot资源。 配置参数:taskmanager.memory.framework.off-heap.size=128MB,默认128MB- Task Off-Heap Memory:Task执行用户代码所使用的对外内存。 配置参数:taskmanager.memory.task.off-heap.size=0,默认0- Network Memory:网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区 配置参数:
taskmanager.memory.network.fraction:0.1taskmanager.memory.network.min:64mbtaskmanager.memory.network.max:1gb - Managed Memory:Flink管理的堆外内存,用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。 配置参数:
taskmanager.memory.managed.fraction=0.4taskmanager.memory.managed.size
JVM specific memory:JVM本身使用的内存
- JVM metaspace:JVM元空间
- JVM over-head执行开销:JVM执行时自身所需要的内容,包括线程堆栈、IO、编译缓存等所使用的内存。 配置参数:
taskmanager.memory.jvm-overhead.min=192mbtaskmanager.memory.jvm-overhead.max=1gbtaskmanager.memory.jvm-overhead.fraction=0.1
总体内存
- 总进程内存:Flink Java应用程序(包括用户代码)和JVM运行整个进程所消耗的总内存。 总进程内存 = Flink使用内存 + JVM元空间 + JVM执行开销 配置项:
taskmanager.memory.process.size: 1728m - Flink总内存:仅Flink Java应用程序消耗的内存,包括用户代码,但不包括JVM为其运行而分配的内存 Flink使用内存:框架堆内外 + task堆内外 + network + manage 配置项:
taskmanager.memory.flink.size: 1280m
说明:配置项详细信息查看链接
内存分配
略
内存数据结构
内存段
内存段在 Flink 内部叫 MemorySegment,是 Flink 中最小的内存分配单元,默认大小32KB。它即可以是堆上内存(Java的byte数组),也可以是堆外内存(基于Netty的DirectByteBuffer),同时提供了对二进制数据进行读取和写入的方法。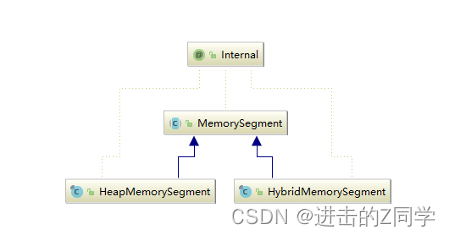
- HeapMemorySegment:用来分配堆上内存
- HybridMemorySegment:用来分配堆外内存和堆上内存,2017年以后的版本实际上只使用了HybridMemo`rySegment。
如下图展示一个内嵌型的Tuple3<Integer,Double,Person> 对象的序列化过程:
可以看出这种序列化方式存储密度是相当紧凑的。其中 int 占4字节,double 占8字节,POJO多个一个字节的header,PojoSerializer只负责将header序列化进去,并委托每个字段对应的serializer对字段进行序列化。
内存页
内存页是MemorySegment之上的数据访问视图,数据读取抽象为DataInputView,数据写入抽象为DataOutputView。使用时就无需关心MemorySegment的细节,会自动处理跨MemorySegment的读取和写入。
Buffer
Task算子之间在网络层面上传输数据,使用的是Buffer,申请和释放由Flink自行管理,实现类为NetworkBuffer。1个NetworkBuffer包装了1个MemorySegment。同时继承了AbstractReferenceCountedByteBuf,是Netty中的抽象类。
Buffer资源池
BufferPool用来管理Buffer,包含Buffer的申请、释放、销毁、可用Buffer通知等,实现类是LocalBufferPool,每个Task拥有自己的LocalBufferPool。
BufferPoolFactory用来提供BufferPool的创建和销毁,唯一的实现类是NetworkBufferPool,每个TaskManager只有一个NetworkBufferPool。同一个TaskManager上的Task共享NetworkBufferPool,在TaskManager启动的时候创建并分配内存。
内存管理器
MemoryManager用来管理Flink中用于排序、Hash表、中间结果的缓存或使用堆外内存的状态后端(RocksDB)的内存。
1.10之前版本,负责TaskManager所有内存。
1.10版本开始,管理范围是Slot级别。
堆外内存资源申请:
MemoryManager.java
publicvoidallocatePages(Object owner,Collection<MemorySegment> target,int numberOfPages)throwsMemoryAllocationException{......
allocatedSegments.compute(owner,(o, currentSegmentsForOwner)->{Set<MemorySegment> segmentsForOwner = currentSegmentsForOwner ==null?newHashSet<>(numberOfPages): currentSegmentsForOwner;for(long i = numberOfPages; i >0; i--){MemorySegment segment =allocateOffHeapUnsafeMemory(getPageSize(), owner, pageCleanup);
target.add(segment);
segmentsForOwner.add(segment);}return segmentsForOwner;});......}
MemorySegmentFactory.java
publicstaticMemorySegmentallocateOffHeapUnsafeMemory(int size,Object owner,Runnable customCleanupAction){long address =MemoryUtils.allocateUnsafe(size);ByteBuffer offHeapBuffer =MemoryUtils.wrapUnsafeMemoryWithByteBuffer(address, size);MemoryUtils.createMemoryGcCleaner(offHeapBuffer, address, customCleanupAction);returnnewHybridMemorySegment(offHeapBuffer, owner);}
RocksDB自己负责内存申请和释放
RocksDBOperationUtils.java
publicstaticOpaqueMemoryResource<RocksDBSharedResources>allocateSharedCachesIfConfigured(RocksDBMemoryConfiguration memoryConfig,MemoryManager memoryManager,double memoryFraction,Logger logger)throwsIOException{......try{if(memoryConfig.isUsingFixedMemoryPerSlot()){assert memoryConfig.getFixedMemoryPerSlot()!=null;
logger.info("Getting fixed-size shared cache for RocksDB.");return memoryManager.getExternalSharedMemoryResource(
FIXED_SLOT_MEMORY_RESOURCE_ID, allocator, memoryConfig.getFixedMemoryPerSlot().getBytes());}else{
logger.info("Getting managed memory shared cache for RocksDB.");return memoryManager.getSharedMemoryResourceForManagedMemory(MANAGED_MEMORY_RESOURCE_ID, allocator, memoryFraction);}}......}
MemoryManager.java
public<TextendsAutoCloseable>OpaqueMemoryResource<T>getExternalSharedMemoryResource(String type,LongFunctionWithException<T,Exception> initializer,long numBytes)throwsException{// This object identifies the lease in this request. It is used only to identify the release operation.// Using the object to represent the lease is a bit nicer safer than just using a reference counter.finalObject leaseHolder =newObject();finalSharedResources.ResourceAndSize<T> resource =
sharedResources.getOrAllocateSharedResource(type, leaseHolder, initializer, numBytes);// 创建资源释放函数finalThrowingRunnable<Exception> disposer =()-> sharedResources.release(type, leaseHolder);returnnewOpaqueMemoryResource<>(resource.resourceHandle(), resource.size(), disposer);}
网络传输中的内存管理
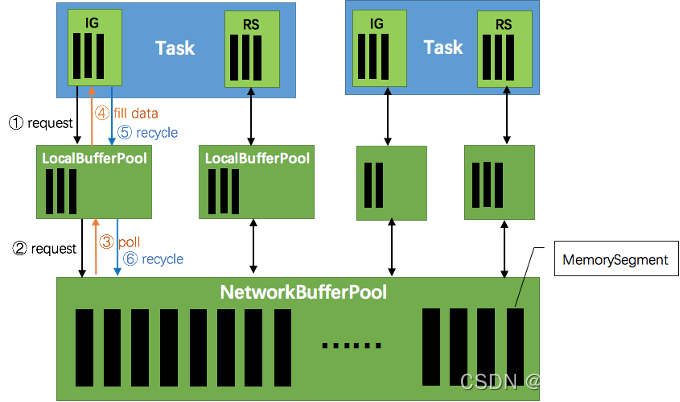
网络上传输的数据会写到 Task 的 InputGate(IG) 中,经过 Task 的处理后,再由 Task 写到 ResultPartition(RS) 中。每个 Task 都包括了输入和输入,输入和输出的数据存在 Buffer 中(都是字节数据)。Buffer 是 MemorySegment 的包装类。
- TaskManager(TM)在启动时,会先初始化NetworkEnvironment对象,TM 中所有与网络相关的东西都由该类来管理(如 Netty 连接),其中就包括NetworkBufferPool。根据配置,Flink 会在 NetworkBufferPool 中生成一定数量(默认2048)的内存块 MemorySegment,内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共享的,每个 TM 只会实例化一个。
- Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG)和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment(内存块)数量。IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存块数量与 RP 中的 ResultSubpartition 数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用起那部分闲置的内存块。
- 在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中,InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的②)并交给 InputChannel 填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者 NetworkBufferPool 也没有可用内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
- 当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注册的 Task 导致该池子容量变小),则LocalBufferPool会将该内存块回收给 NetworkBufferPool(上图中的⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
反压的过程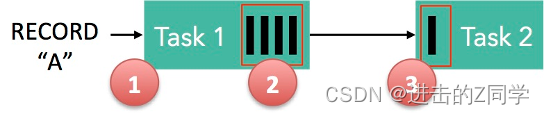
- 记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
- 记录被序列化到 buffer 中。
- 该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录。
记录能被 Flink 处理的前提是:必须有空闲可用的 Buffer。
结合上面两张图看:Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
注意两个场景:
- 本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
- 远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制来保证不往网络中写入太多数据。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个 Task 之间的数据传输自然地扩展到更复杂的 pipeline 中,保证反压机制可以扩散到整个 pipeline。
版权归原作者 进击的Z同学 所有, 如有侵权,请联系我们删除。