
文章目录
一、准备工作
配置hadoop模板虚拟机(学习篇)
CentOS7安装jdk
centos7 安装hadoop
二、配置ssh免密登录
首先使用以下命令在家目录下是否有.ssh目录
ls -lah
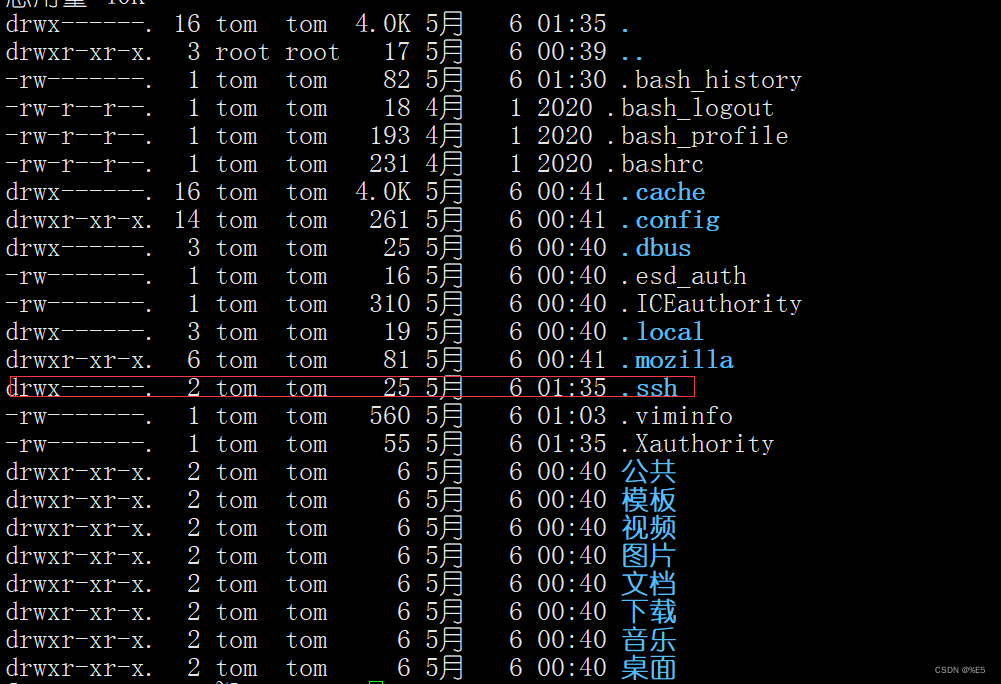
如果没有,可以使用
ssh localhost
然后进入这个文件
cd .ssh
生成密钥
ssh-keygen -t rsa
输入上面的代码后回车四次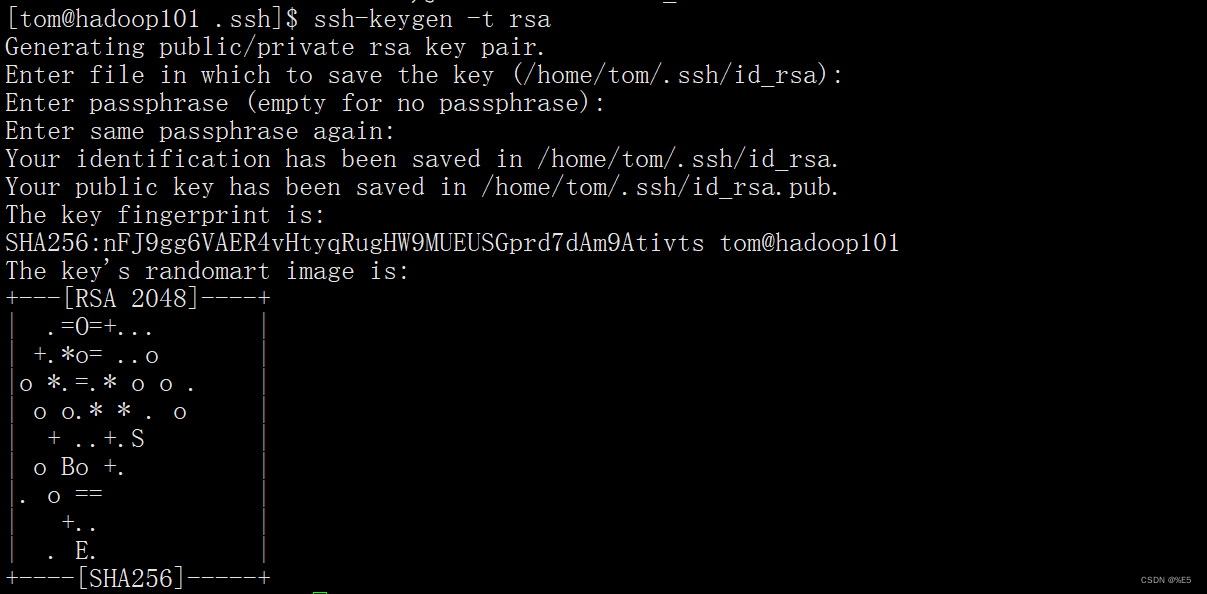
把公钥拷贝到本台虚拟机上面去
ssh-copy-id 192.168.90.105
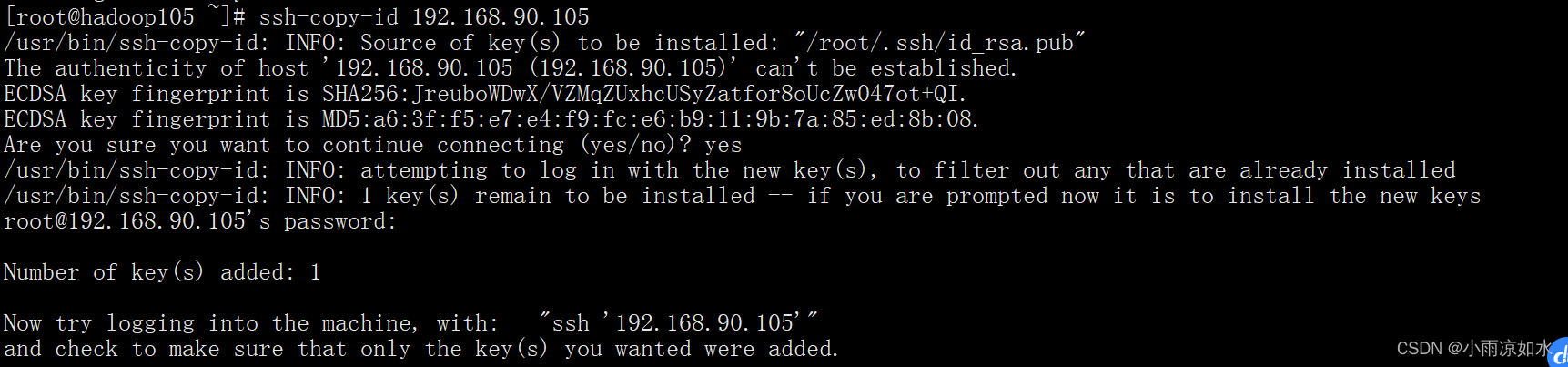
到此我们的免密登录就算是配置完成了。
验证一下是否需要密码
ssh localhost

三、修改hadoop的配置文件
注意:这里需要的配置文件都在$HADOOP_HOME/etc/hadoop里,就是安装路径/hadoop3.x/etc/hadoop
下面是我们这里需要修改配置的几个文件
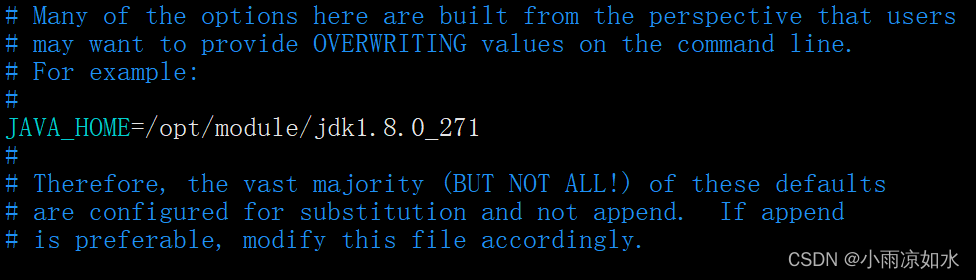
1.配置hadoop-env.sh⽂件
vim hadoop-env.sh
把java_home的地址给写上去。
按 i 插入
2.配置core-site.xml
vim core-site.xml
按 i 插入
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop105:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.3.5/data</value></property></configuration>
:wq
保存文件
3.配置hdfs-site.xml⽂件
vim hdfs-site.xml
按 i 插入
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property></configuration>
:wq
保存文件
配置说明:
dfs.replication: ⽤于指定⽂件块的副本数量。HDPS特别适合于存储⼤⽂件,它会将⼤⽂件切分成每128MB⼀块,存储到不同的DataNode节点上,且默认将每⼀块备份2份,共3份,即此配置的默认值为3,最⼤为512MB。由于我们只有⼀个DataNode节点,所以这⾥将⽂件副本数量修改为1。
dfs.permissions.enabled:访问时是否检查安全,默认为tue。为了⽅便访问,暂时修改为false
4.配置mapred-site.xml⽂件
vim mapred-site.xml
按i插入
<configuration><name>mapreduce.framework.name</name><value>yarn</value></configuration>
:wq
保存
配置说明:
mapreduce.framework.name:⽤于指定调试⽅式。这⾥指定使⽤YARN作为任务调⽤⽅式。
5.配置yarn-site.xml⽂件
hadoop classpath
会出现一大片的东西,准备备用
vim yarn-site.xml
按i插入
下面的claspath插入上面生成的东西
<configuration><property><name>yarn.resourcemanager.hostname</name><value>hadoop105</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.application.classpath</name><value>
/opt/module/hadoop-3.3.5/etc/hadoop:/opt/module/hadoop-3.3.5/share/hadoop/common/lib/*:/opt/module/hadoop-3.3.5/share/hadoop/common/*:/opt/module/hadoop-3.3.5/share/hadoop/hdfs:/opt/module/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.3.5/share/hadoop/hdfs/*:/opt/module/hadoop-3.3.5/share/hadoop/mapreduce/*:/opt/module/hadoop-3.3.5/share/hadoop/yarn:/opt/module/hadoop-3.3.5/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.3.5/share/hadoop/yarn/*
</value></property></configuration>
:wq
保存
配置说明:
yarn.resourcemanager.hostname:⽤于指定ResourceManager的运⾏主机,默认0.0.0.0,即本机。
yarn.nodemanager.aux-services:⽤于指定执⾏计算的⽅式为mapreduce_shuffle。
yarn.application.classpath:⽤于指定运算时的类加载⽬录。
6.配置workers⽂件
workers⽂件之前的版本叫slaves,但功能⼀样。主要⽤于在启动时同时启动DataNode和NodeManager。
workers在$HADOOP_HOME/hadoop-3.x/etc/hadoop/workers
vim workers
改成当前节点的hostname,我的是hadoop105
四、格式化namenode节点,启动hdfs,启动yarn
注意这里不能⽤root账号启动进程,需要在环境变量中配置
vim /etc/profile
exportHDFS_NAMENODE_USER=root
exportHDFS_DATANODE_USER=root
exportHDFS_SECONDARYNAMENODE_USER=root
exportYARN_RESOURCEMANAGER_USER=root
exportYARN_NODEMANAGER_USER=root
source /etc/profile
执行
格式化namenode
hdfs namenode -format
执行
start-dfs.sh
start-yarn.sh
再执行
jps
像这样就算是完成了。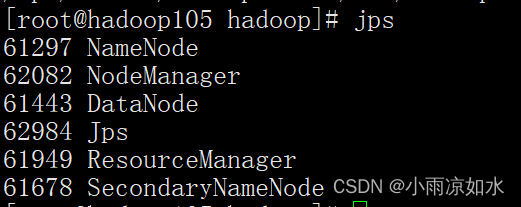
到此为止,我们配置完了hadoop伪分布式安装
版权归原作者 小雨凉如水 所有, 如有侵权,请联系我们删除。