
练习爬虫项目时,遇到问题
在跟着别人练习爬虫项目时,遇到了’NoneType’ object has no attribute ‘find_all’ 问题,具体报错如下
import requests
from bs4 import BeautifulSoup
url ='https://movie.douban.com/top250?start=0&filter='
res= requests.get(url)
html = res.text
soup = BeautifulSoup(html,'html.parser')
bs = soup.find('ol',class_='grid_view')#序号1的电影名和序号
numbers = bs.find_all('li')print(type(numbers))
结果如下
Traceback (most recent call last):
File "C:/Users/My/PycharmProjects/uitest/douban_movie.py", line 14,in<module>
numbers = bs.find_all('li')
AttributeError:'NoneType'object has no attribute 'find_all'
直接报错了,NoneType的问题,那我们往上找一下原因,打印一下bs看看结果是什么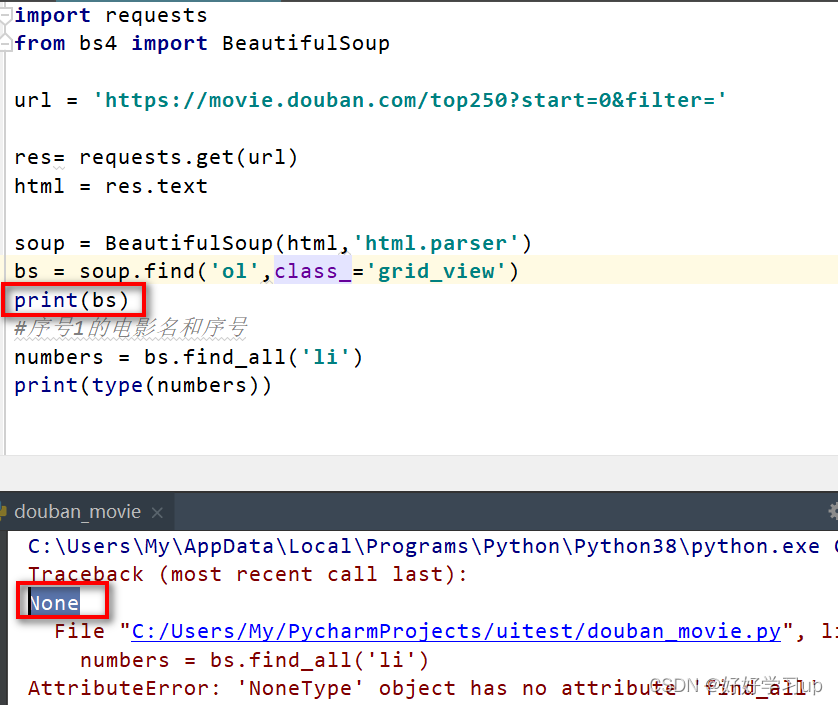
这次结果直接是None,说明在定位‘ol’的时候就已经找不到内容了。但是在网页中查看代码了,定位的没有问题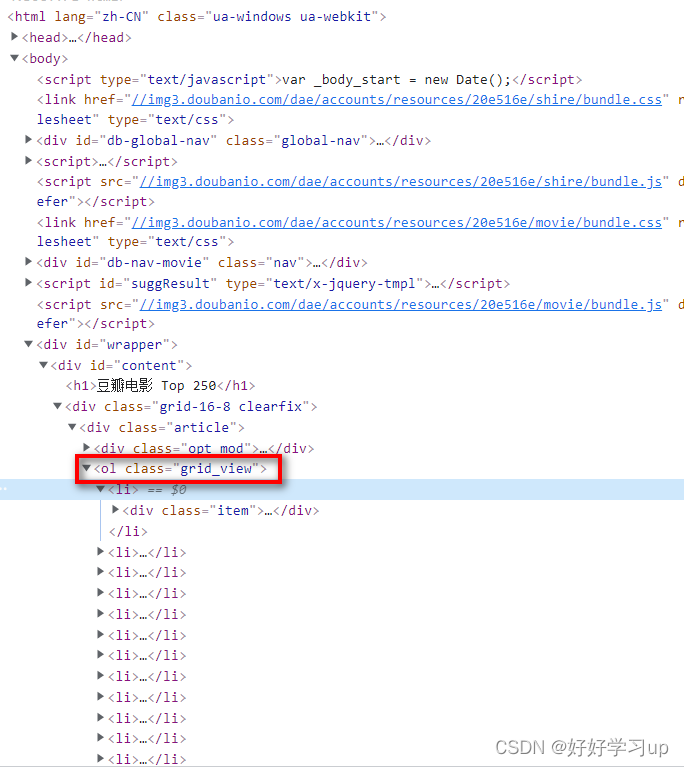
解决办法
提示:这里描述项目中遇到的问题:
后来查询了一番,找到了解决办法。原因是因为我们爬取的网站爬取的次数太多,网站有了反爬机制。这时候想要获取信息成功,需要添加header信息,把header信息添加到requests中,请求就可以执行成功了。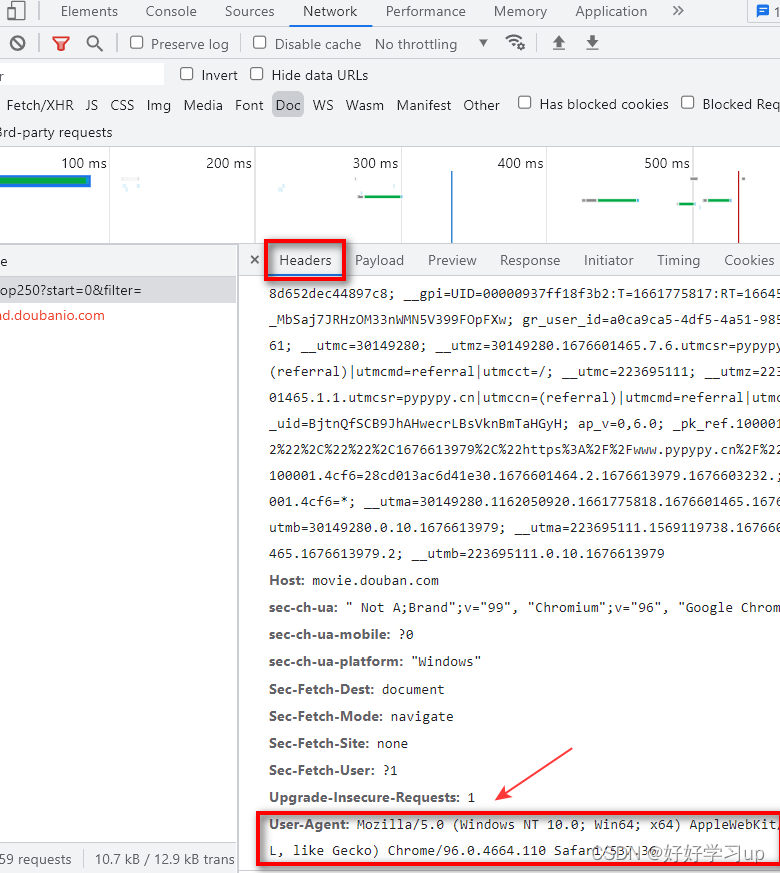
header ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"}
res= requests.get(url,headers = header)
<class'bs4.element.Tag'><class'bs4.element.ResultSet'>
到此结束,请求处理成功。
本文转载自: https://blog.csdn.net/L_xuewuzhijing/article/details/128615159
版权归原作者 好好学习up 所有, 如有侵权,请联系我们删除。
版权归原作者 好好学习up 所有, 如有侵权,请联系我们删除。