
一、大数据概论
1.大数据的概念
指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决海量数据的采集、存储和分析计算问题。
顺序存储单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
1Byte=8bit,1KB=1024Byte,1MB=1024KB......
2.大数据的特点
①Volume(大量):典型个人计算机硬盘容量为TB量级,一些大型企业可以达到EB量级。
②Velocity(高速):根据IDC的数字宇宙报告,预计2025年,全球数据使用量可以达到163ZB。
③Variety(多样):数据可以分为结构化数据和非结构化数据。结构化数据主要以便于存储的数据库/文本为主;非结构化数据包含了网络日志、音频、视频、图片、地理位置信息等多类型数据,对于数据的处理能力具有更高要求。
④Value(低价值密度):价值密度的高低与数据总量大小成反比。快速对有价值数据“提纯”成为目前大数据背景下待解决的难题。
3.大数据应用场景
抖音、电商广告推荐、零售策略、保险(海量数据挖掘及风险预测...)、金融(多维体现用户推荐)、人工智能5G物联网方面等。
二、Hadoop概述
1.Hadoop定义
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题。
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
2.Hadoop发展历史
①Hadoop创始人Doug Cutting,为实现Google类似的全文搜索功能,在Lucene框架基础上进行优化升级,查询引擎和索引引擎。
②2001年底Lucene成为Apache基金会的一个子项目。
③对于海量数据的场景,Lucene框架面对与Google同样的困难:存储海量数据困难,检索海量速度慢。
④学习和模仿Google解决这些问题的办法:微型版Nutch。
⑤Google是Hadoop的思想源泉
⑥2003-2004年,Google公开GFs和MapReduce思想细节,Doug Cutting等人使用两年时间实现,使Nutch性能飙升。
⑦Hadoop作为Lucene子项目Nutch一部分正式引入Apache。
⑧2006年Map-Reduce和Nutch Distributed FileSystem纳入Hadoop项目,Hadoop正式诞生。
3.Hadoop发行版本
Apache(2006)、Cloudera(2008)、Hortonworks(2011)。
4.Hadoop优势
①高可靠性:Hadoop底层维护多个数据副本,即使Hadoop某个计算元素或存储出现故障,也不会导致数据丢失。
②高扩展性:在集群间分配任务数据,可方便的扩展数以千计的结点。可动态增加和删除服务器。
③高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。可以实现集群工作。
④高容错性:能够自动将失败的任务重新分配。就是在执行过程中,如果遇到任务无法执行,将会把这个失败的任务重新分配到其他服务器,这个被分配的服务器需要具有相关资源。
5.Hadoop1.x/2.x/3.x
①Hadoop1.x组成:
- MapReduce(计算+资源调度)
- HDFS(数据存储)
- Common(辅助工具)
②Hadoop2.x组成:
- MapReduce(计算)
- Yarn(资源调度)
- HDFS(数据存储)
- Common(辅助工具)
③Hadoop3.x组成:组成上和2.x相同,但是细节方面存在差异。
- MapReduce(计算)
- Yarn(资源调度)
- HDFS(数据存储)
- Common(辅助工具)
6.HDFS架构
Hadoop Distributed File System简称HDFS,是一个分布式文件系统。
①NameNode(nn):存储文件的元数据,如文件名、文件目录、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
②DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
③Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
7.Yarn架构
Yet Anothor Resource Negotiator简称YARN,是一种资源协调者,是Hadoop的资源管理器。
①ResourceManage(rm):整个集群资源(内存、CPU等)的总负责。
②NodeManager(nm):单个节点服务器资源总和。
③ApplicationMaster(am):单个任务运行的总和。
④Container:容器,相当于一台独立服务器,里面封装了任务运行所需要的资源,比如内存、CPU、磁盘、网络等。一个Container可以运行1-8g内存。
Tips:客户端可以有多个;集群上可以运行多个ApplicationMaster;每个NodeManager可以有多个Container执行。
过程:client提交作业给ResourceManager,ResourceManager进行节点服务器分配,在ResourceManager中创建Container,在Container里面运行任务。
8.MapReduce架构
MapReduce将计算过程分为两个阶段:Map和Reduce。
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总。
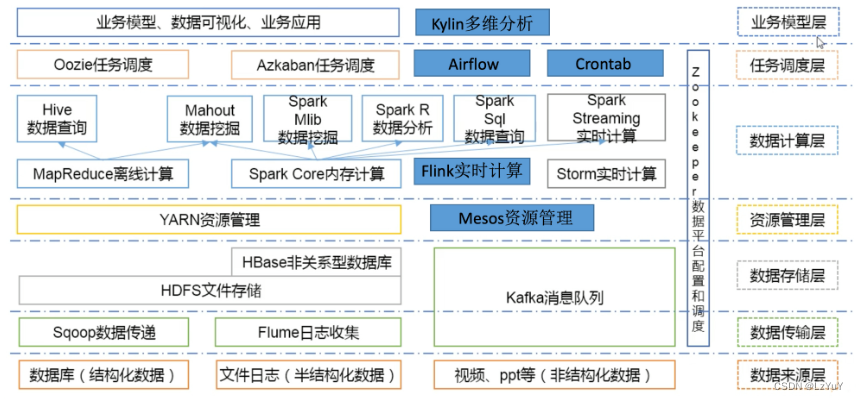
9.大数据技术生态体系
- 数据库(结构化数据)→Sqoop数据传递→HDFS文件传输→Yarn资源管理...
- 文件日志(半结构化数据)→Flume日志收集→HDFS文件传输→HBase非关系型数据库→Yarn资源管理...
- 视频、PPT等(非结构数据)→Kafka消息队列...
版权归原作者 LzYuY 所有, 如有侵权,请联系我们删除。