
思维导图
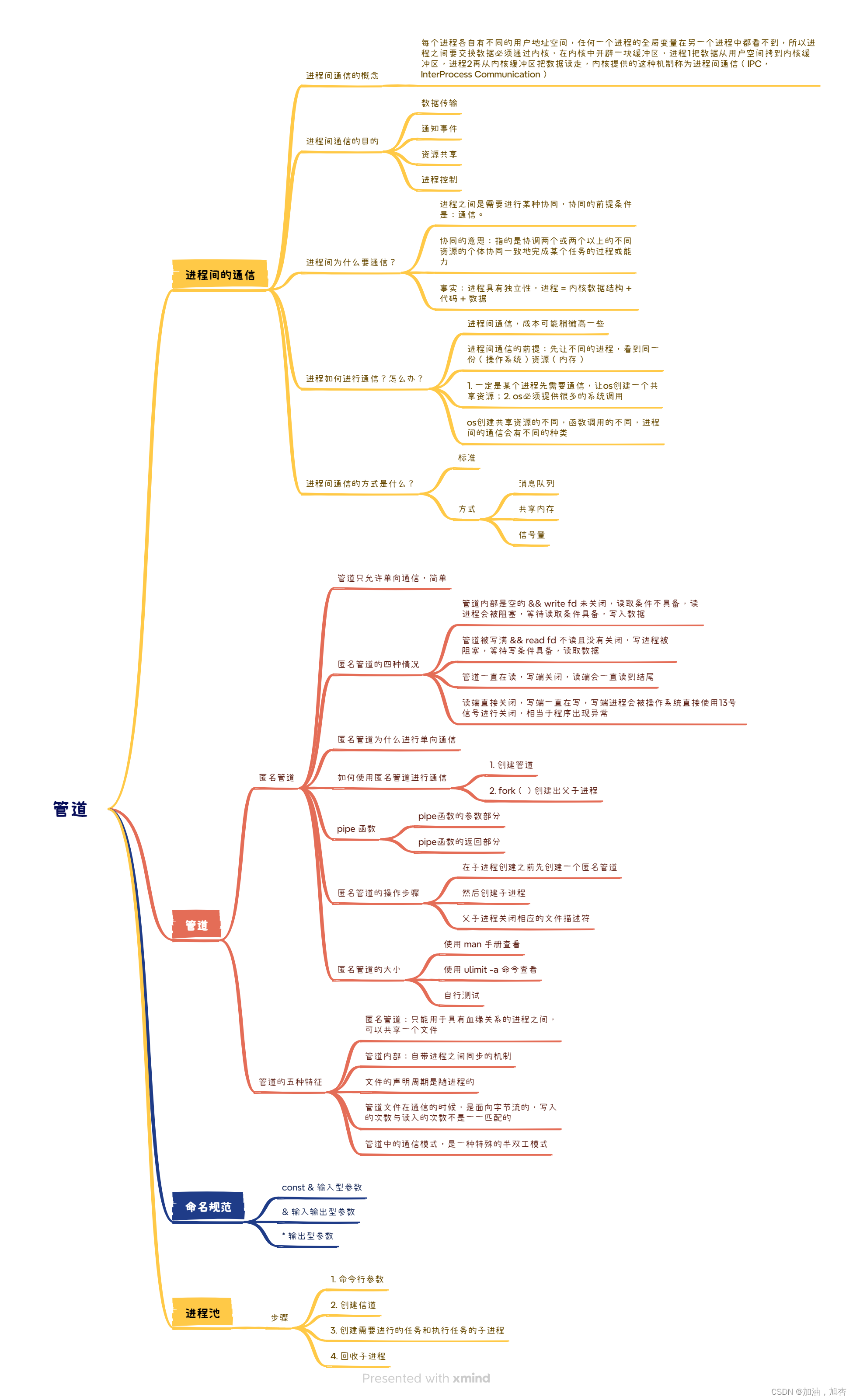
学习内容
进程间通信的一些知识点:是什么、为什么和怎么办??之后就是理解管道中的匿名管道的一些知识点:会创建匿名管道、匿名管道的四种情况……最后,就是进程池的代码编写,也是最难的一部分。
学习目标
过上面的学习目标,我们可以列出要学习的内容:
- 进程间通信是什么
- 进程间通信为什么
- 进程间通信怎么办
- 匿名管道是什么
- 匿名管道如何进行创建
- 匿名管道的四种情况
- 管道的五大特征
- 进程池的编写
一、进程间通信
1.1 进程间通信的概念
**每个进程各自有不同的用户地址空间**,**任何一个进程的全局变量在另一个进程中都看不到**,所以进程之间要交换数据必须通过**内核**,在**内核中开辟一块缓冲区**,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,InterProcess Communication)
一些易错的知识点:
- 进程之间具有独立性,拥有自己的虚拟地址空间,因此无法通过各自的虚拟地址进行通信(A的地址经过B的页表映射不一定映射在什么位置)
- 进程间的通信除了内核中的缓冲区之外还有文件以及网络通信的方式可以实现
1.2 进程间通信的作用
- 数据传输:一个进程需要将它的数据发送给另一个进程。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 资源共享:多个进程之间共享同样的资源。为了做到这一点,需要内核提供互斥和同步机制。
- 进程控制:有些进程希望完全控制另一个进程的执行(如 Debug 进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
1.3 进程间通信的本质
进程间通信的本质是:**让不同的进程看到同一份资源**。进程是具有**独立性**的,我们每一个进程不能看到其他进程的代码和数据,**进程 = 内核数据结构 + 代码 + 数据**。因此,我们需要借助第三方资源实现进程间的通信。
进程间的通信成本较高,我们需要先将某一个进程需要通信,在OS操作系统中创建一个共享资源,OS操作系统必须提供很多的系统调用,由于OS操作系统创建的共享资源的不同,函数调用的不同,进程间通信会有不同的类型。**让不同的进程看到同一份(操作系统)资源(内存)**。
1.4 进程间为什么要进行通信??
进程之间是需要进行某种**协同**的,而协同的前提条件是通信。**通信时的数据是有类别的:通知就绪的数据,控制相关信息的数据,单纯地传递给我的数据……**
事实上:进程是具有独立性的,在进程间通信的本质中说到:进程间通信的本质是什么?以及进程 = 内核数据结构 + 代码 + 数据。
协同的意思:
协同是指协调的两个或者两个以上的不同资源的个体协同一致地完成某个任务的过程或能力。
二、管道
2.1 什么是管道
一说到管道,我们可能想到的是下水道的管道,但是这里讲的管道是计算机中的管道,在详细一点,是Linux操作系统中的管道,那么管道到底是什么呢??
管道技术还是比较重要的,我们每天都可以用到。在计算机中,由于**进程之间是相互独立**的,信息无法进行交互。而计算机中的管道,就是一种**解决进程间信息交互的手段**。
2.2 匿名管道
为什么叫匿名管道呢??因为**不需要文件路径和文件名**。
2.2.1 解释一种现象,为什么父子进程向同一个显示器终端打印数据??
进程会默认打开三种标准输入和输出,**0,1,2 三个文件描述符代表的是标准输入端,标准输出端和标准错误流**。我们可以通过bash来进行理解,bash如果打开了3端口,那么bash其所有的子进程都会默认打开3端口。
2.2.2 匿名管道的工作原理
匿名管道仅用于具有血缘关系的进程之间的通信,只允许单向通信。
为什么管道要单向通信??? 因为简单。
进程间通信的本质是,让不同的进程看到同一份资源,使用匿名管道实现父子进程间通信的原理是,让两个父子进程先看到同一份被打开的文件资源,然后父子进程就可以对该文件进行写入或读取操作,进而实现父子进程间的通信。

理解一种现象:为什么父子进程会向同一个显示器打印数据???
进程默认会打开三个标准输入输出流:0,1,2。 bash打开,bash的子进程默认也就打开了,因为标准输入输出流都是bash的子进程,所以会默认打开。为什么我们主动关闭子进程0,1,2文件描述符,不会影响父进程继续使用显示器文件??
因为struct file 是通过内存级的**引用计数**,在主动关闭子进程0,1,2文件描述符,会使struct file 的引用计数减一。当引用计数为0时,才会释放struct file。
注意:
- 这里父子进程看到的同一份文件资源是由操作系统来维护的,所以当父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝。父子进程对于文件系统是浅拷贝。
- 管道虽然用的是文件的方案,但操作系统一定不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率,而且也没有必要。也就是说,这种文件是一批不会把数据写到磁盘当中的文件,换句话说,磁盘文件和内存文件不一定是一一对应的,有些文件只会在内存当中存在,而不会在磁盘当中存在。
2.2.3 pipe函数
#include <unisted.h>
int pipe(int pipefd[2])
pipe()函数的参数部分是一个大小为2的数组类型的指针,该函数成功时返回0,并将一对打开的文件描述符值填入pipefd参数指向的数组。该函数失败时返回-1。
通过pipe函数创建的这两个文件描述符 fd[0] 和 fd[1] 分别构成管道的两端,往 fd[1] 写入的数据可以从 fd[0] 读出。并且**fd[1] 一端只能进行写操作**,**fd[0] 一端只能进行读操作**,不能反过来使用。要实现双向数据传输,可以使用两个管道。
pipe函数的参数部分
pipe函数的参数是输出型参数,数组pipefd[2]表示的是对于一个管道的**读端**和**写端**的文件描述符。
数组元素数组元素中代表的含义pipefd[0]管道读端的文件描述符pipefd[1]管道写端的文件描述符
这里有一个小扩展:
pipe函数的返回部分
当pipe函数**成功调用时返回 0**,pipe函数**调用失败后返回 -1**。
2.2.4 匿名管道的使用步骤
一般都是结合**fork()函数**进行使用,由于匿名管道需要在创建子进程之前创建,因为只有这样才能复制到管道的操作句柄,与具有亲缘关系的进程实现访问同一个管道通信。所以我们需要先在创建子进程之前,利用**pipe()函数**创建一个匿名管道。
之后创建一个子进程,将子进程和父进程对应的读端或者写端关闭。因为匿名管道只支持半双工通信,因此,匿名管道只能有一个读端和一个写端。将对应的读端或写端的文件描述符进行关闭。
创建一个读端和一个写端的函数进行通信即可。
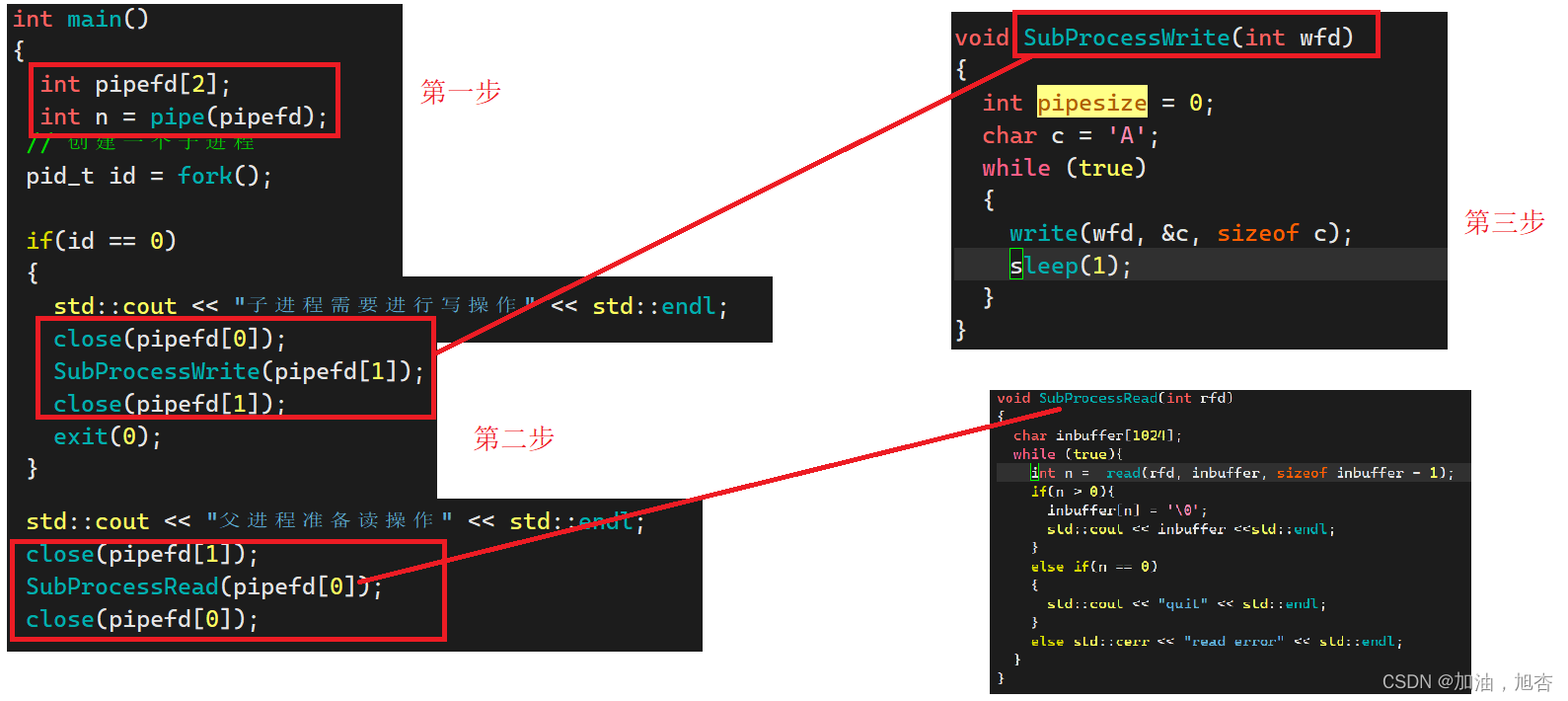
下面来进行详细地介绍过程:
在创建子进程之前将匿名管道创建完成。

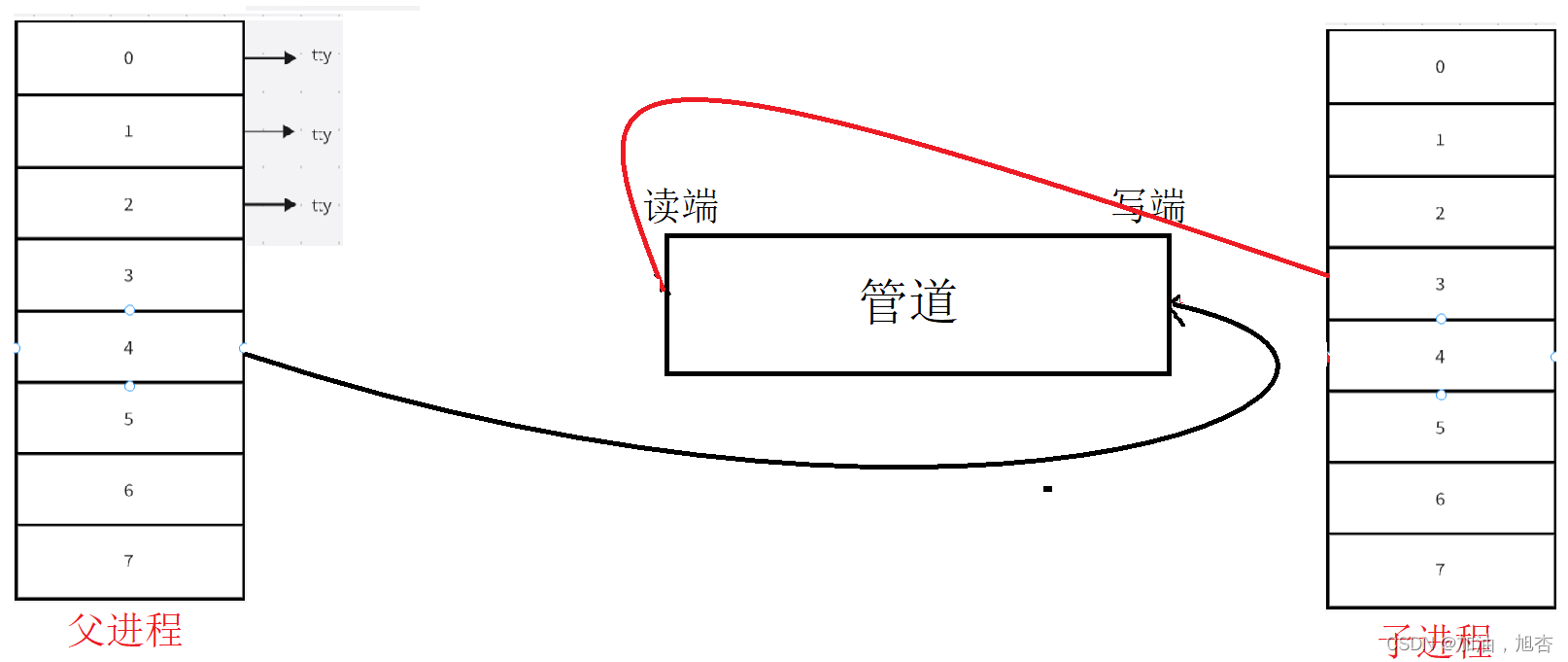
创建子进程,将父子进程看到同一份文件缓冲区,进而进行通信。

父进程关闭fd[0],子进程关闭fd[1]。
**创建读端的相关操作。 **
利用read()函数来进行读出操作,注意read()函数的用法。
read()函数用于从文件描述符(通常是套接字、文件等)读取数据。
#include <unisted.h> ssize_t read(int fd, void *buf, size_t count);read()函数的fd参数:
- 是文件描述符,可以是套接字、文件等。
read()函数的buf参数:
- 是一个指向要读取数据的缓冲区的指针。
read()函数的count参数
- 是要读取的字节数。
read()函数的返回值为:
- 如果成功,返回读取字符的长度(可能为0,表示读到文件的结尾)
- 如果时报,则返回-1,并设置errno表示读取失败的原因

创建写端的相关操作。
利用write()函数来进行写入操作,注意write()函数的用法。
wrtie()函数用于将数据写入文件描述符(通常是套接字、文件等)。
#include <unisted.h> ssize_t write(size_t fd, void* buf, int count);write()函数的fd参数:
- 是文件描述符,可以是套接字、文件等。
write()函数的buf参数:
- 是一个指向要读取数据的缓冲区的指针。
write()函数的count参数:
- 是要读取的字节数。
write()函数的返回值:
如果成功,返回读取字符的长度(可能为0,表示读到文件的结尾)
如果时报,则返回-1,并设置errno表示读取失败的原因
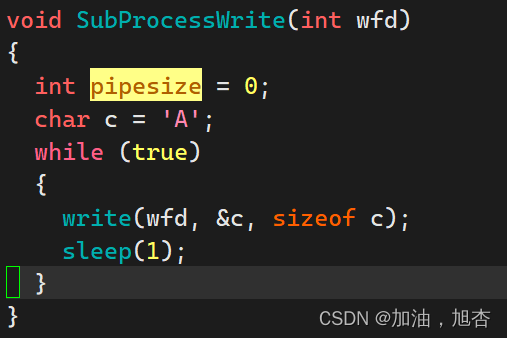
父子既然要关闭不需要的id,为什么刚开始要打开呢??可以不关闭吗??
为了使子进程继承下去。也可以不关闭不需要的id。文件描述符数组中的文件描述符是有限的,而且还会导致文件描述符泄漏,但是还是建议关闭,万一误写!!!!!
2.3 管道的四种情况
情况一:管道内部是空的 && write fd 未关闭,读取条件不具备,读进程会被阻塞,等待读取条件具备,写入数据
情况二:管道被写满 && read fd 不读且没有关闭,写进程被阻塞,等待写条件具备,读取数据
情况三:管道一直在读,写端关闭,读端会一直读到结尾
情况四:读端直接关闭,写端一直在写,写端进程会被操作系统直接使用13号信号进行关闭,相当于程序出现异常
其中前面两种情况就能够很好的说明,管道是自带同步与互斥机制的,读端进程和写端进程是有一个步调协调的过程的,不会说当管道没有数据了读端还在读取,而当管道已经满了写端还在写入。读端进程读取数据的条件是管道里面有数据,写端进程写入数据的条件是管道当中还有空间,若是条件不满足,则相应的进程就会被挂起,直到条件满足后才会被再次唤醒。 第三种情况也很好理解,读端进程已经将管道当中的所有数据都读取出来了,而且此后也不会有写端再进行写入了,那么此时读端进程也就可以执行该进程的其他逻辑了,而不会被挂起。 第四种情况也不难理解,既然管道当中的数据已经没有进程会读取了,那么写端进程的写入将没有意义,因此操作系统直接将写端进程杀掉。而此时子进程代码都还没跑完就被终止了,属于异常退出,那么子进程必然收到了某种信号。
2.4 管道的五种特征
匿名管道:只能用于具有血缘关系的进程之间,可以共享一个文件
管道内部:自带进程之间同步的机制
文件的声明周期是随进程的
管道文件在通信的时候,是面向字节流的,写入的次数与读入的次数不是一一匹配的
管道中的通信模式,是一种特殊的半双工模式
2.5 管道的大小
管道是一个文件,既然是一个文件,必然会有容量的大小,那么管道的大小是多少呢??当管道容量变满后,会进行阻塞。那么如何计算出管道的大小呢?
2.5.1 使用man手册
根据man手册,在2.6.11之前的Linux版本中,管道的最大容量与系统页面大小相同,从Linux 2.6.11往后,管道的最大容量是65536字节。
2.5.2 使用ulimit命令
我们可以使用 ulimit -a 命令来查看当前资源限制的设定。

根据显示,管道的最大容量是 512 × 8 = 4096 512\times8=4096512×8=4096 字节。
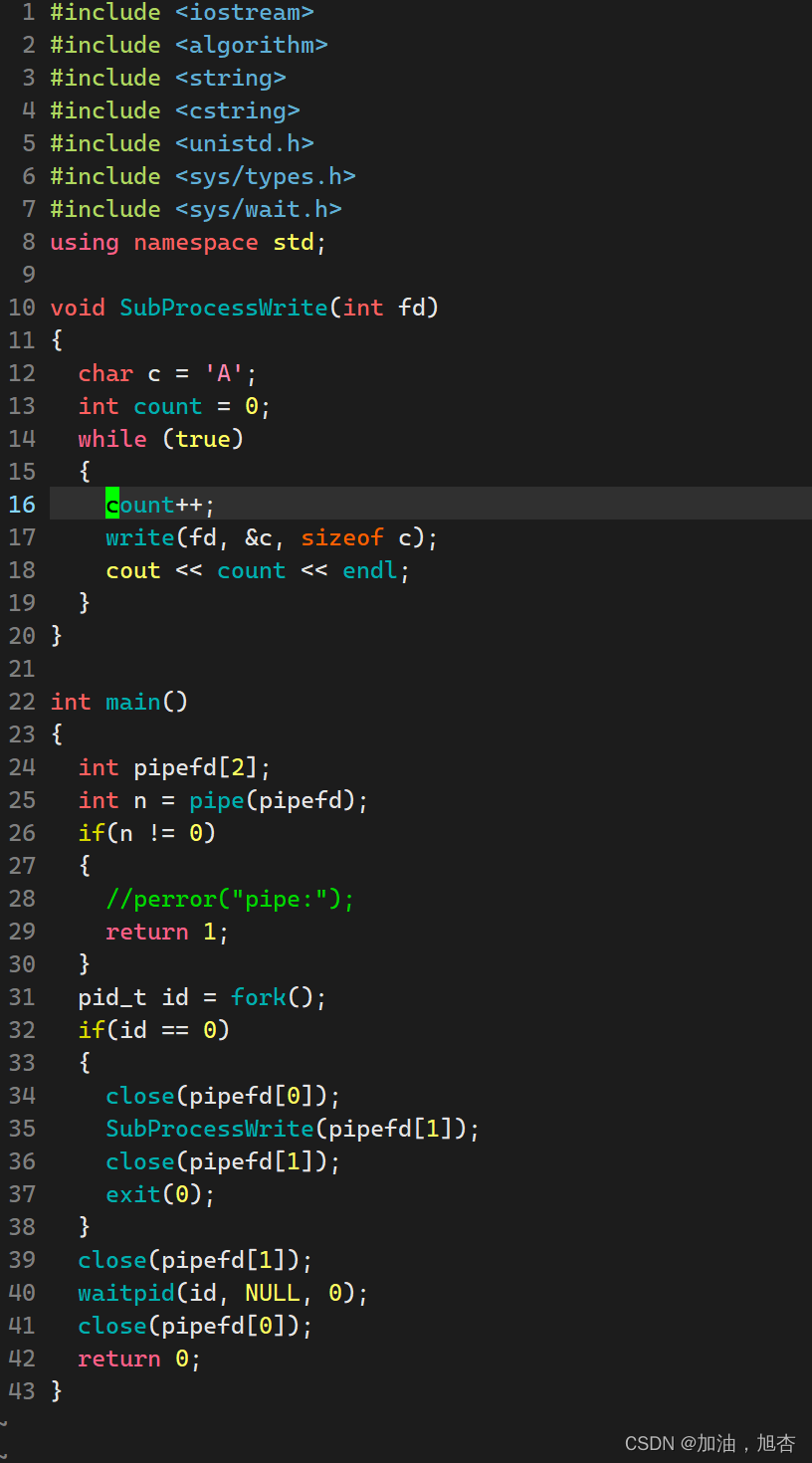
2.5.3 自行测试
我们可以将写端的文件描述符打开,一直进行写入操作,知道管道满为止。由图,我们可以知道我的管道的容量大小是65536。

代码如下:
版权归原作者 加油,旭杏 所有, 如有侵权,请联系我们删除。