
- 网络栈
3.1 WebKit的网络设施
WebKit的资源加载其实是交由各个移植来实现的,所以WebCore其实并没有什么特别的基础设施,每个移植的网络实现是非常不一样的。
从WebKit的代码结构中可以看出,网络部分代码的确比较少的,它们都在目录“WebKit/Source/WebCore/platform/network”中。主要是一些HTTP消息头、MIME消息、状态码等信息的描述和处理,没有实质的网络连接和各种针对网络的优化。
3.2 Chromium网络栈
(1)“net“所包含的主要子目录,是chromium网络栈的主要模块。要实现一些基础的部分,如 HTTP 协议、DNS 解析等模块,还包括一些为了减少网络时间而引入的新技术(如 SPDY、QUIC 等)。

(2)网络栈结构
在“Net”目录下的子目录,包含了主要的子模块,如下图描述了从URLRequest类到Socket类之间的调用过程。以HTTP协议为例,图中列出了建立TCP的Socket连接过程中涉及的类。

- URLRequest类被上层调用并启动请求的时候,它会根据URL的“scheme”来决定需要创建什么类型的请求,“scheme”也就是URL的协议类型,如:“http://"、“file://”·,也可以是自定义的scheme,例如Andriod系统的”file://andriod_asset/“。URLRequest对象创建的是一个URLRequestJob子类的一个对象,例如图形的中的URLRequestHttpJob类。为了支持自定义的scheme处理方式,Chromium使用工厂模式。URLRequestJob类和它的工厂类URLRequestJobFactory的管理工作都由URLRequestJobManager类负责。基本思路是,用户可以在该类中注册多个工厂,当有URLRequest请求时,先由工厂检查它是否需要处理该类“scheme”,如果没有,工厂管理类继续交给下一个工厂类来处理。最后,如果没有任何工厂能够处理,Chromium则交给内置的工厂来检查和处理是否为“http://”、“f'tp://”或者“file://”等。
- 当URLRequestHttpJob对象被创建后,该对象首先从Cookie管理器中获取与该URL相关的信息。之后,它同样借助于HttpTransactionFactory对象创建一个HttpTransaction对象来表示开启一个HTTP连接的事务(当然这里的概念不同于数据库中的事务概念)。通常情况下,HttpTransactionFactory对象对应的是一个它的子类HttpCache对象。HttpCache类使用本地磁盘缓存机制,如果该请求对应的回复已经在磁盘缓存中,那么Chromium无需再建立HttpTransaction来发起连接,而是直接从磁盘中获取即可。如果磁盘中没有该URL的缓存,同时如果目前该URL请求对应的HttpTransaction已经建立,那么只要等待它的回复即可。当这些条件都不满足的时候,Chromium实际上才会真正创建HttpTransaction对象、

- HttpNetworkTransaction类使用HttpNetworkSession类来管理连接会话。HttpNetworkSession类通过它的成员HttpStreamFactory对象来建立TCPSocket连接,之后Chromium创建HttpStream对象。HttpStreamFactory对象将和网络之间的数据读写交给自己新创建的一个HttpStream子类的对象来处理。
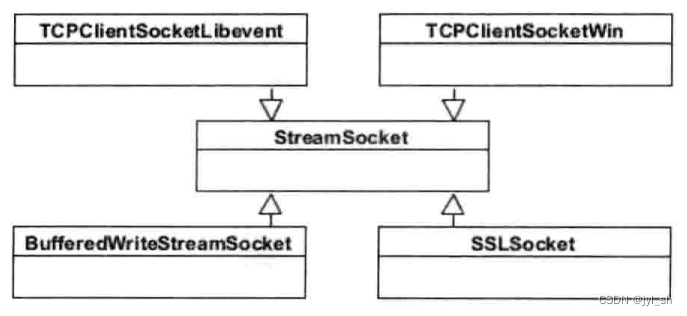
- 套接字的建立,Chromium中与服务器建立连接的套接字是StreamSocket类,它是一个抽象类,在POSIX系统和Windows系统上有着分别不同的实现。同时为了支持SSL机制,StreamSocket类还有一个子类----SSLSocket。
(3)代理
用户代理由以下几个类来处理:
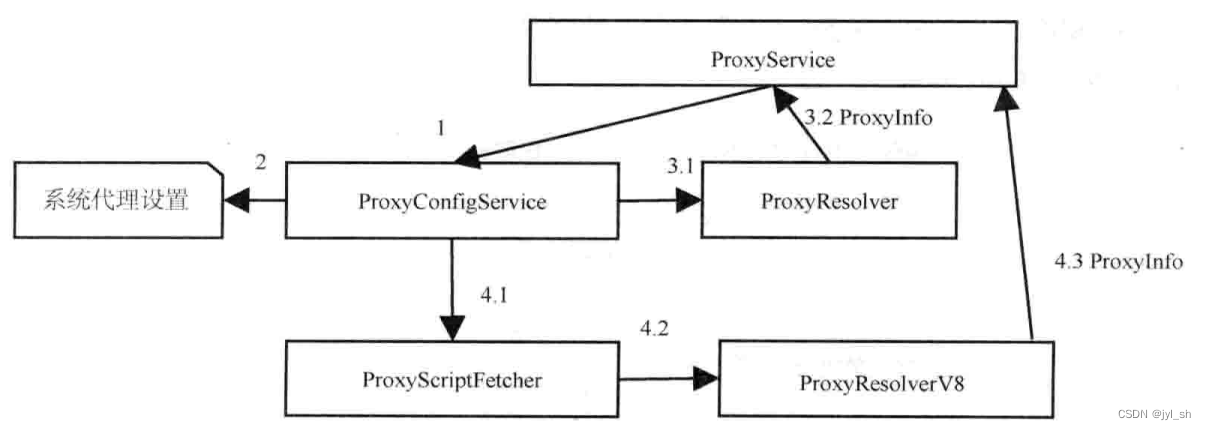
- Proxy Service:对于一个URL,HttpStreamFactory类使用ProxyService类来获取代理信息。ProxyService类首先会检查当前代理设置不是最新的。如果不是,它依赖ProxyConfigService来重新获取代理信息。该类不处理实际任务,而是使用ProxyReslover类来做实际代理工作。
- Proxy Config Service:获取代理信息的类,可获得平台上的代理设置,在Linux】Windows上有不同的实现。
- ProxyScriptFetcher:Chromium支持代理的JavaScript脚本,该类负责从代理的URL中获取该脚本。
- Proxy Resolver:实际负责代理的解释和执行,通常启用新的线程来处理,因为当前可能会被域名的解析所阻碍。
- ProxyResolverV8:ProxyResolver的子类,使用V8引擎来解析和执行脚本。
(4)域名解析(DNS)
通常情况下,用户都是使用域名来访问网络资源的,所以在建立TCP连接前需要解析域名。Chromium中使用HostResolverImpl类来解析域名,具体调用的函数时“getaddrinfo()”,该函数是一个阻塞式的函数,所以Chromium理所当然使用单独的线程来处理它,这是Chromium的原则之一。
为了保证效率,使用HostCache类来保存解析后的域名,最多时会有多达1000个域名和地址映射关系会被存储起来。
3,3 磁盘本地缓存
浏览器的缓存机制能够提高网页的加载速度。
(1)特性
- 虽然需要缓存的资源可能很多,但磁盘空间不是无限大的,所以必须要有相应的机制来移除合适的缓存资源,以便加入新的资源。
- 能够保证在浏览器崩溃时不破坏磁盘文件,至少能够保护原先在磁盘中的数据。
- 能够高效和快速地访问磁盘中现有的数据结构,支持同步和异步两种访问方式。
- 能够避免同时存储两个相同的资源。
- 能够很方便地从磁盘中删除一个项,同时可以在操作一个项的时候不受其他请求的影响。
- 磁盘不支持多线程访问,所以需要把所有磁盘缓存的操作放入单独的一个线程。
- 升级版本时,如果磁盘缓存的内部存储结构发生改变,Chromium仍然能够支持老版本的结构。
(2)结构
实现上主要有两个类,**Backend**(整个磁盘缓存) 和 **Entry**(表中的表项)。至少需要一个索引文件和四个数据文件。索引文件用来索引,数据文件又称块文件。缓存通常是一个表,对于整个表的操作作用在 Backend 类上,包括创建表中的一个个项,每个项由关键字来唯一个确定,这个关键字就是资源的 URL。对于项目内的操作包括读写都是由 Entry 类来处理。
Backend 类表示整个磁盘缓存,是所有磁盘缓存操作的主入口,表示一个缓存表。
Entry 类指的是表中的表项,表项的结构分为两个部分。
表和表项如何组织和存储在磁盘上:至少有一个索引文件和四个数据文件(块文件),每个块文件的大小是固定的,当资源文件超过某个块的大小就会为其分配多个块来解决,但最多不能超过四个块,超过四个块能存储的时候会建立单独的文件来保存。如果一个表项需要分配四个块则这些块在文件中的索引位置是对齐的(起始块的位置是4 的倍数)索引文件:用来检索存放在数据文件中的众多索引项,用来索引表项,包括一个索引头部和索引地址表。直接将文件映射到内存地址。头部用来表示该索引文件的信息,如索引文件版本号、索引项数量、文件大小等。索引地址表:保存各个表项对应的索引地址。该索引文件直接将文件映射到内存地址,这样可以快速地找到表项的索引地址。
struct NET_EXPORT_PRIVATEIndex Header{ uint32 magic; uint32 version; int32 num_entries; //nuimuber entries currently stored. int32 num_bytes; //Total size of the stored data. int32 last_file; //Last external file created. int32 this_id; //Id for all entries being changed (dirty flag). CacheAddr status; //Storage for usage data. int32 table_len; //Actual size of the table(0==kIndexTablesize), int32 crash; //Signals a previous crash. int32 experiment; //Id of an ongoing test. uint64 create_time; //Creation time for this set of files. int32 pad[52]; LruData lru; //Eviction control data. }; strunct Index { // The structure of the whole index file. IndexHeader header; CacheAddr table[kIndexTablesize] ; //Default size Actual size controlled by header.table_len. };数据文件:块文件,有很多不同大小的块,用于快速检索,这些数据块的内容是表项,包括 HTTP 文件头、请求数据和资源数据。资源文件大小超过一定值的时候,Chromium会捡来单独的文件来保存它们,而不是将它们放入四个数据文件中。这些单独存储的文件中并没有元数据信息,只是资源文件的内容,其文件名形如“f_xxxx,xxxx是0-9A-F是十六进制数来表示编号。
表项的结构也分为两个部分:
第一部分用于标记自己,包括各种元数据信息和自身的内容,较少变动
第二部分主要为表项的回收算法服务,经常发生变动,里面保存了回收算法所需要的信息
struct EntryStore {
uint32 hash; //Full hash of the key. CacheAddr next; //Next entry with the same hash or bucket. CacheAddr rankings_node; //Rankings node for this entry. int32 reuse_count; //How often is this entry used. int32 refetch_count; //How often is this fetched from the net. int32 state; //Current state uint64 creation_time; int32 key_len; CachedAddr long_key; //Optional adddress of a long key. int32 data_size[4]; //We can store up to 4 data streams for each CacheAddr data_add[4]; //entry uint32 flags; //Any Combination of EntryFlags. int32 pad[4]; uint32 self_hash; // The hash of EntryStore up to this point. char key[256-24*4]; //null terminated };
磁盘缓存的存储结构如下:
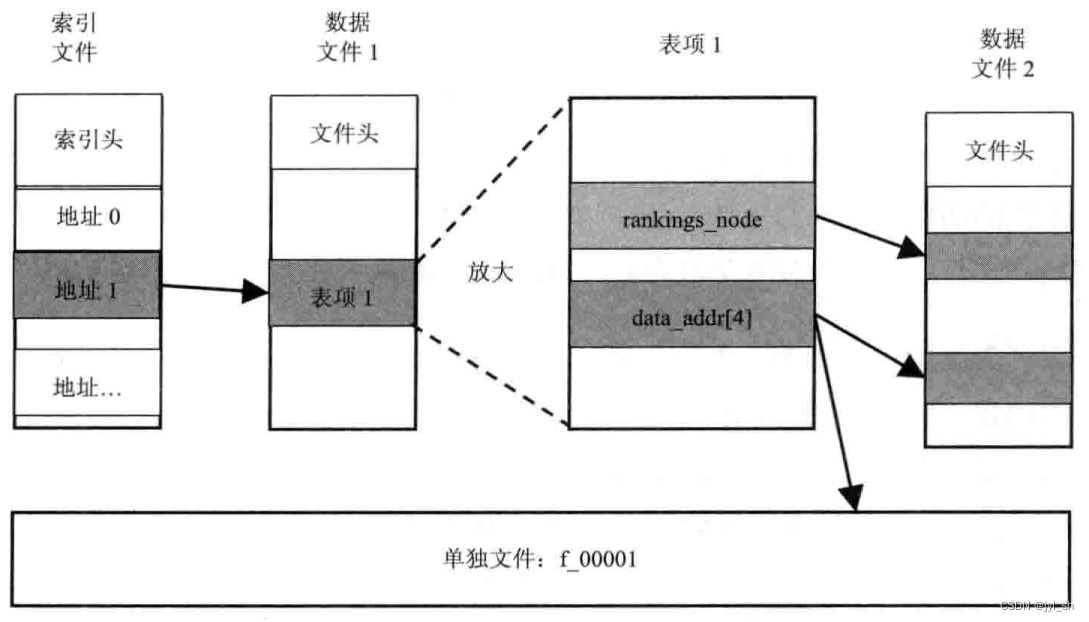
Chomium使用LRU算法来回收表项,因为磁盘存储的空间是有限的,不能无限的增长下去,所以对于很少使用到的表项,可以回收这一部分磁盘空间。
3.4 Cookie机制
Cookie就是一系列的“关键字+值”对。
test1=webkit;test2=chromium;Expires=Sun,30 Oct 2016 21:35:00 GMT;Domain.myweb.com;
test1,test2 自定义的关键字
Expires、Domain:为预定义的关键字,表示的是该Cookie的失效时间和该Cookie对应的域。
一个网页的 Cookie 只能被该网页(或者说是该域的网页)访问。根据 Cookie 的时效性可以将 Cookie 分成两种类型,第一种是会话型 Cookie(Session Cookie),这些 Cookie 只是保存在内存中,当浏览器退出的时候即清除这些 Cookie。如果 Cookie 没有设置失效时间,就是会话型 Cookie。第二中是持续型 Cookie(Persistent Cookie),也就是当浏览器退出的时候,仍然保留 Cookie 的内容。该类型的 Cookie 有一个有效期,在有效期内,每次访问该 Cookie 所属域的时候,都需要将该 Cookie 发送个服务器,这样服务器就能够追踪用户的行为。
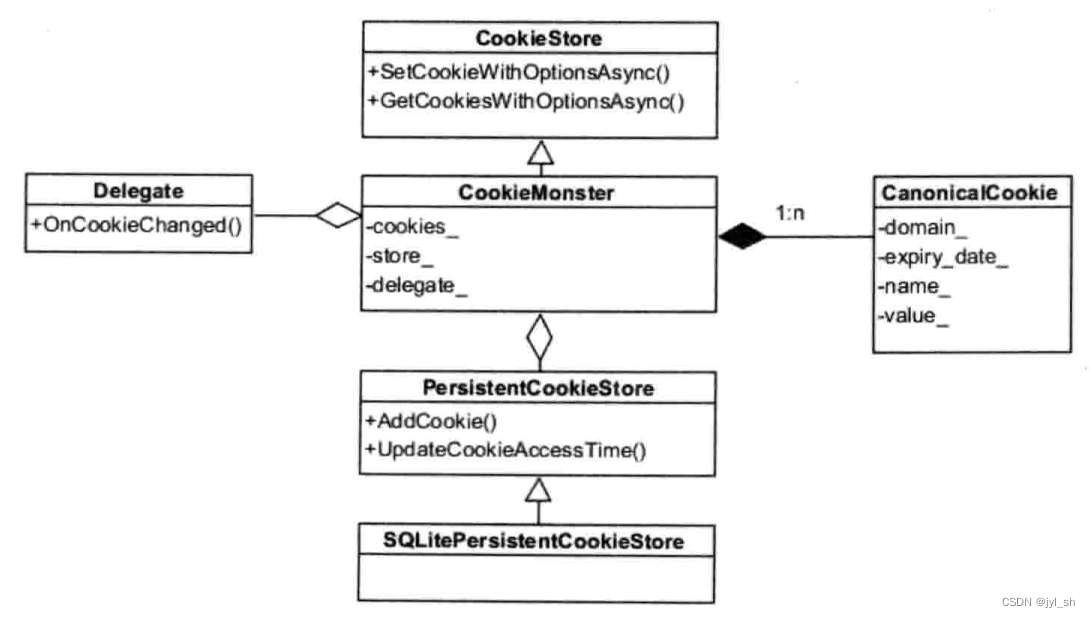
Chromium中支持Cookie的机制也较为简单和清晰,CookieMonster是Cookie机制中最重要的类,实际上相当于Cookie的管理器,它包括几个作用:
实现CookieStore的接口,它是对外的接口,调用者可以设置和获得Cookie。
报告各种Cookie的事件,如更新信息等,主要使用Delegate类。
Cookie对象的集合,也就是CanonicalCookie的集合,每个CanonicalCookie对象表示一个域的Cookie集合。
持续型Cookie的存储
以上的是在内存中保存的,当需要存储到磁盘的时候使用PersistentCookieStore,具体由SQLLitePersistenCookieStore类负责实际的存储动作。
3.5 安全机制
HTTP是一种使用明文来传输数据的应用层协议。构建建在SSL之上的HTTPS提供了安全的网络传输机制。支持一种新的标准 HSTS 协议(HTTP Strict Transport Security):能够让网络服务器声明它只支持 HTTPS 协议。浏览器能够理解服务器的声明,发送基于 HTTPS 的连接和请求。通常情况下,浏览器的用户不会输入“scheme(http://),l浏览器的补齐功能通常会加入该“scheme”,但是,服务器可能需要”https://",在这样的情况下,该协议就显得非常有用。一般情况次啊,服务在返回的消息头中加入以下信息表明它支持该标准。
Strict-Transport-Security:max-age=16070400;includesSubDomains
3.6 高性能网络栈
Chromium的网络模块有两个重要目标,其一是安全,其二是速度。
(1)DNS 预取和 TCP 预连接:
- DNS 预取就是利用现有的 DNS 机制,提前解析网页中可能的网络连接。当用户正在浏览当前网页的时候,Chromium 提取网页中的超链接,将域名抽取出来,利用比较少的 CPU 和网络带宽来解析这些域名和 IP 地址,这样一来,用户根本感觉不到这一过程。当用户单击这些链接的时候,可以节省不少时间,特别在域名解析比较慢的时候,效果特别明显。
- DNS预取技术直接利用系统的域名解析机制,不会阻碍当前网络栈的工作,DNS预取技术针对多个域名采取并行处理的方式,每个域名的解析须由新开启一个线程来处理,结束后此线程即退出。
- 网页的开发者可以显示指定预取那些域名来让Chromium解析,这非常直接了当,特别对于那些需要重定向的域名,具体做法如下:<link rel="dns-prefetch" href="http://this-is-a-dns-prefetch-example.com">。当然,DNS预取技术不仅应用于网页中的超链接,在用户敲下回车键获取网页之前,Chromium 就已经开始用 DNS 预解析技术解析该域名。
- 可以通过在地址栏中输入“chrome://dns/”查看Chromium的DNS预取的域名。
- Chromium使用追踪技术来获取用户从什么网页跳转到另一个网页,可以利用这些数据、一些启发式规则和其他一些暗示来预测用户下面会单击什么超链接,当有足够的把握时,它便先DNS预取,更进一步,还可以预先建立TCP连接。
- 同DNS预取技术一样,追踪技术不仅应用于网页中的超链接,当用户在地址栏输入地址,如候选项同输入的地址很匹配,则在用户敲下回车键获取该网页之前,Chromium就已经开始尝试建立TCP连接了。
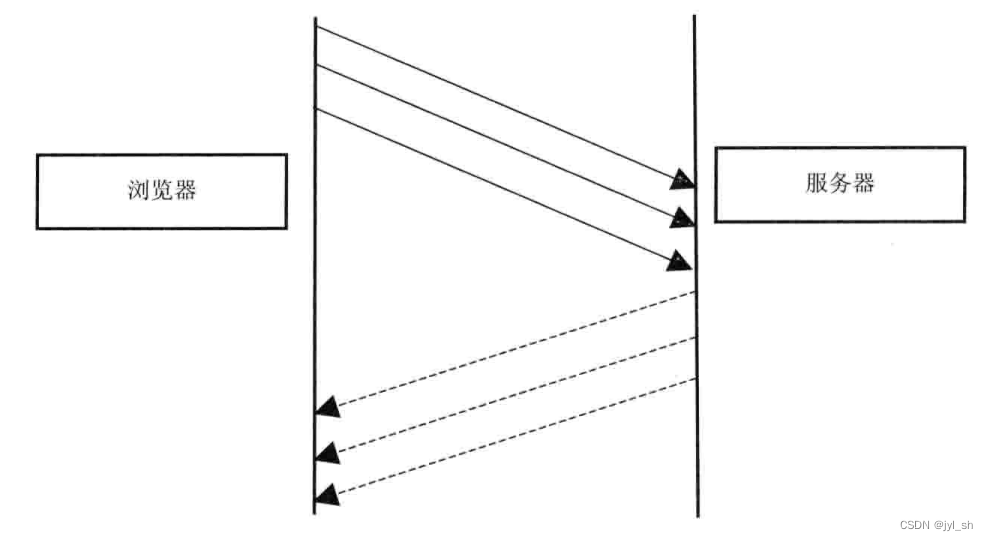
(2)支持 HTTP 管线化技术(Pipelining):
HTTP 1.1 中新增的管线化技术:将多个 HTTP 请求一次性提交给服务器,可能将多个 HTTP 请求填充在 TCP 数据包内(相当于 HTTP 权威指南中串行事务处理中的管道化连接),HTTP管线化需要在网络上传较少的TCP数据包,因此减少了网络的负载。
请求结果的管线化使得HTML网页加载时间动态提升,特别在具体有高延迟的连接环境下,管线化机制需要通过永久连接(Persistent Connection)完成,并且只有 GET 和 HEAD 等幂等请求可以进行管线化。使用场景有很大的限制。
(3) SPDY
解决 HTTP 管线技术的使用限制。SPDY 协议是一种新的会话层协议,定义在 HTTP 协议和 TCP 协议之间。核心思想是多路复用,仅使用一个连接来传输一个网页中的众多资源,没有改变 HTTP 协议,将 HTTP 协议头通过 SPDY 来封装和传输,服务器只需要从 SPDY 的消息头中获取各个资源的 HTTP 头即可。SPDY 的工作方式有以下四个特征:

- 利用一个 TCP 连接来传输不限个数的资源请求的读写数据流。
- 根据资源请求的特性和优先级, SPDY 可以调整这些资源请求的优先级。
- 只对 https 请求使用压缩技术,可以大大减少需要传输的字节数。
- 当用户需要浏览某个网页,支持 SPDY 的服务器在发送网页内容时可以发送一些信息给浏览器告诉后面可能需要哪些资源,浏览器可以提前知道并决定是否需要下载。更极端的情况是,服务器可以主动发送资源。
下图是是基于SPDY协议的网络栈结构
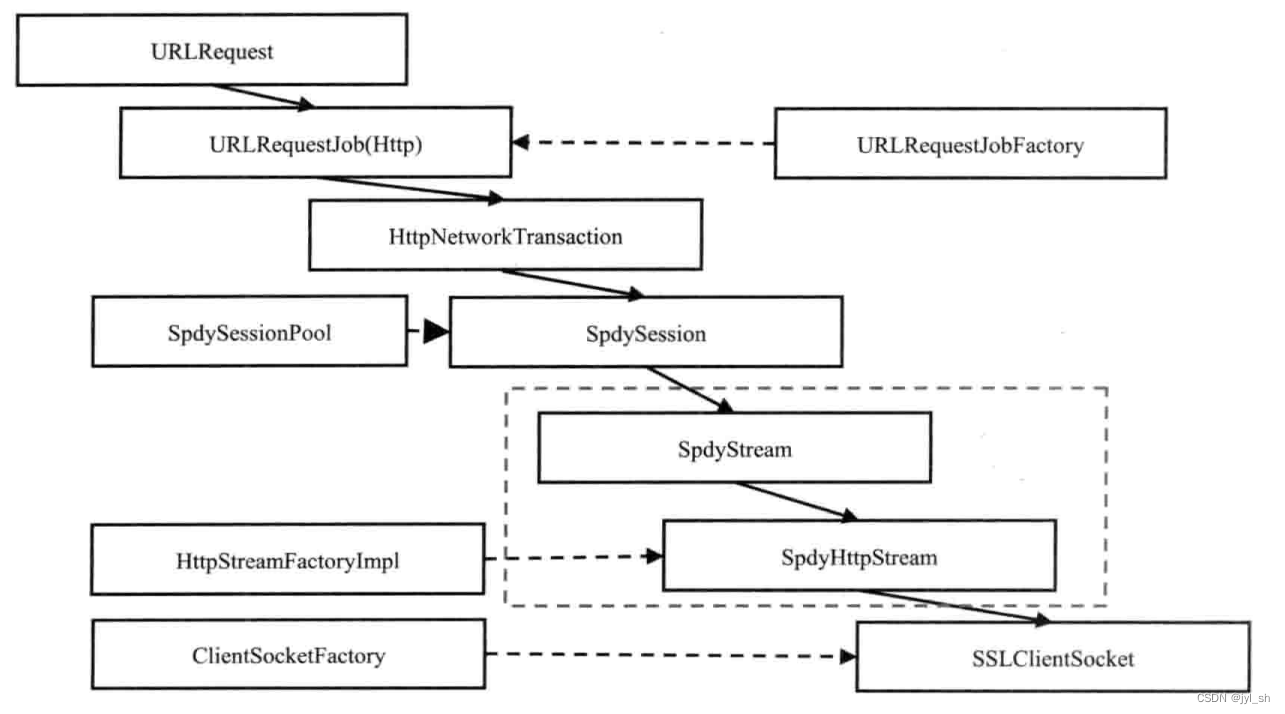
与前面的调用栈结构有三点不同:
- 虚线框表示可能有多个SpdyStream和SpdyHttpStream对象,也就是多个流使用一个SpdySession会话,同时使用一个socket连接。多多个Stream对象的管理、删除、创建、数量限制等都是由SpdySession来处理。
- 对于之前的一些类,Spdy有专门的实现,因为需要支持新协议的关系。
- SpdyHttpStream类继承自之前的HttpStream类会对应一个SpdyStream并将Spdy协议部分等实际工作交给SpdyStream类来做
(4)QUIC
新的网络传输协议,改进 UDP 数据协议的能力。同SPDY建立传输层之上不同,QUIC所要解决的问题就是传输层的传输效率,并提供了数据加密。所以,SPDY可以在QUIC上工作。
3.7 实践:chromium网络工具和信息
Chromium提供了网路信息工具Chrome://net-internals.可以看到Capture、Export、Import、Proxy、Events、Timeline、DNS、Sockets、SPDY、QUIC、Pipelining、擦车、SPIs、Tests、HSTS、Bandwidth、Prerender等类别。
首先是Events类别,该类别记录了所有网络栈完成的工作和传送消息。记录ID、对象类。其中有些以_JOB结尾的类,表示一个个的任务,这些任务可能是连接、域名解析等。它们不负责具体的工作,只起到一层桥接和封装的作用,任务完成后就直接结束了,当用户单击表中一项的时候,当前页面会给当前对象从过去到现在发生的各个操作,或者叫事件。
其次是类别“Timeline”.它的含义就是一个按照时间绘制的图,图中记录在各个时间点Chromium 使用网络资源。
版权归原作者 jyl_sh 所有, 如有侵权,请联系我们删除。