
- 实验目的
- 了解Flume的基本功能
- 掌握Flume的使用方法,学会按要求编写相关配置文件
- 实验平台
- 操作系统:windows 10
- Flume版本:1.11.0
- Kafka版本:2.4.0
- MySQL版本:8.0
- Hadoop版本:3.1.3
- JDK版本:17.0.2→1.8.0
实验步骤
Kafka生产者生产消息
- 启动zookeeper和kafka服务
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
.\bin\windows\kafka-server-start.bat .\config\server1.properties
- 创建一个新主题flumetopic
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flumetopic
- flume采集信息并将信息发送到HDFS
- 创建flume的配置文件k2h.conf
写入内容如下:
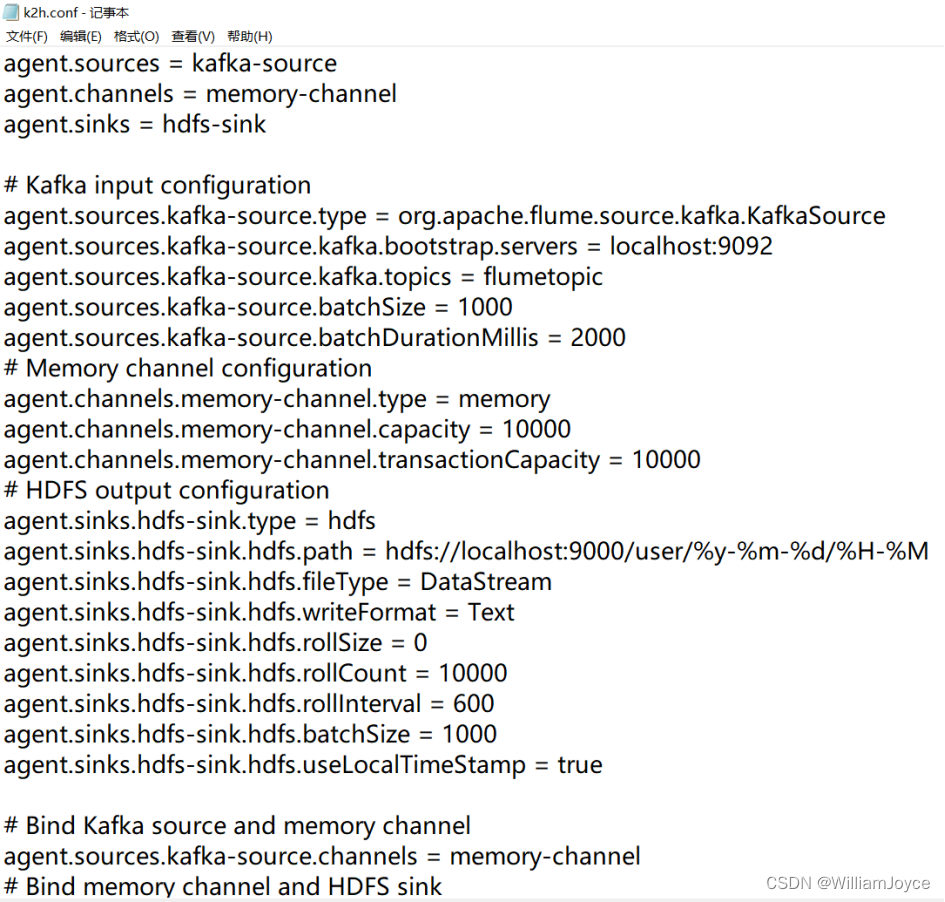
agent.sources = kafka-source #指定数据源类型为Kafka
agent.channels = memory-channel #指定通道类型为内存通道
agent.sinks = hdfs-sink #指定输出插件类型为HDFS
Kafka input configuration
#指定数据源类型为Kafka,使用Flume自带的KafkaSource插件
agent.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafka-source.kafka.bootstrap.servers = localhost:9092 #指定Kafka集群的地址和端口号
agent.sources.kafka-source.kafka.topics = flumetopic #指定从哪个Kafka主题中读取数据
agent.sources.kafka-source.batchSize = 1000
agent.sources.kafka-source.batchDurationMillis = 2000
Memory channel configuration
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
HDFS output configuration
agent.sinks.hdfs-sink.type = hdfs #指定输出插件类型为HDFS
agent.sinks.hdfs-sink.hdfs.path = hdfs://localhost:9000/user/%y-%m-%d/%H-%M #指定输出路径为HDFS上的/user目录
agent.sinks.hdfs-sink.hdfs.fileType = DataStream #指定输出文件类型为DataStream,即以数据流的形式写入文件
agent.sinks.hdfs-sink.hdfs.writeFormat = Text #指定输出文件格式为文本格式
agent.sinks.hdfs-sink.hdfs.rollSize = 0
agent.sinks.hdfs-sink.hdfs.rollCount = 10000
agent.sinks.hdfs-sink.hdfs.rollInterval = 600
agent.sinks.hdfs-sink.hdfs.batchSize = 1000
agent.sinks.hdfs-sink.hdfs.useLocalTimeStamp = true
Bind Kafka source and memory channel
agent.sources.kafka-source.channels = memory-channel
Bind memory channel and HDFS sink
agent.sinks.hdfs-sink.channel = memory-channel
(2)启动hadoop的HDFS
sbin\start-dfs.cmd
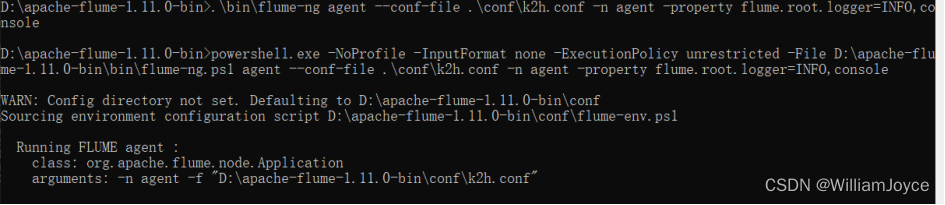
(3)执行如下命令启动flume
.\bin\flume-ng agent --conf-file .\conf\k2h.conf -n agent -property flume.root.logger=INFO,console
(4)创建一个生产者来产生消息并输入任意内容
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 -topic flumetopic

在offset explorer上可看到kafka主题中已产生数据
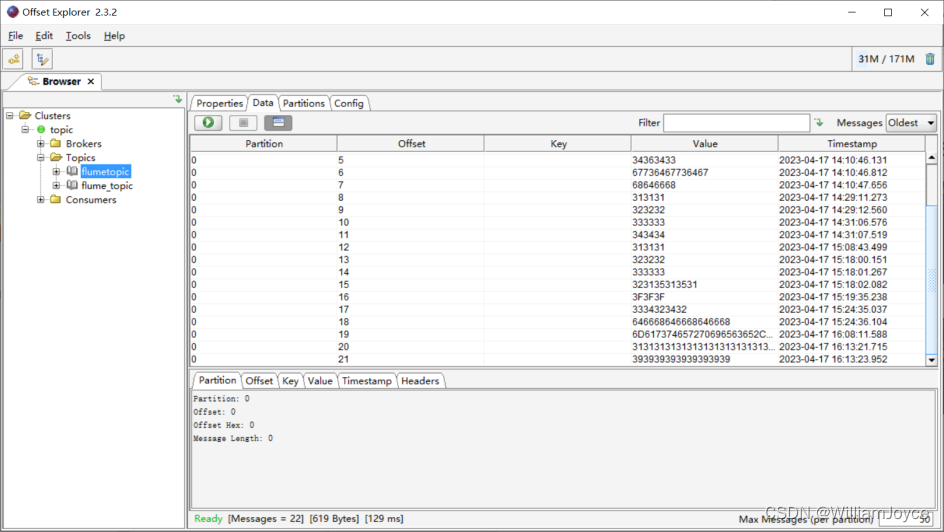
然而,HDFS并未接收到任何来自kafka的信息,以下是一些常见的问题和解决方法:
1.检查Flume配置文件是否正确,特别是Kafka和HDFS的配置是否正确,比如Kafka的地址和端口号、HDFS的路径和权限等。可以通过查看Flume日志或者使用Flume命令行工具来检查配置文件是否正确。
2.检查Kafka主题是否存在数据,如果Kafka主题中没有数据,那么Flume也无法将数据发送到HDFS。可以通过Kafka消费者端来检查Kafka主题中是否存在数据。
3.检查Flume是否正常运行,如果Flume崩溃或者出现其他问题,也会导致数据无法发送到HDFS。可以通过查看Flume日志或者使用Flume命令行工具来检查Flume是否正常运行。
4.检查HDFS是否正常运行,如果HDFS出现故障或者权限问题,也会导致数据无法写入HDFS。可以通过查看HDFS日志或者使用HDFS命令行工具来检查HDFS是否正常运行。
- 检查HDFS的空间是否足够,如果HDFS的空间不足,也会导致数据无法写入HDFS。可以通过HDFS命令行工具来查看HDFS的空间使用情况。
查看Flume日志,发现以下四个报错:
1.Channel memory-channel has no components connected and has been removed.:这条警告表示内存通道memory-channel没有连接到任何组件,并且已经被移除。这可能是由于配置文件中没有正确配置通道的原因导致的
2.Agent configuration for 'agent' has no configfilters.:这条警告表示代理agent的配置中没有配置任何过滤器。过滤器可以用来过滤或者修改数据,如果没有配置过滤器,那么所有数据都会被传输到下一个组件
3.Source kafka-source has been removed due to an error during configuration java.lang.InstantiationException: Incompatible source and channel settings defined. source's batch size is greater than the channels transaction capacity. Source: kafka-source, batch size = 1000, channel memory-channel, transaction capacity = 100:这条错误信息表示Kafka数据源kafka-source被移除,原因是配置文件中定义的批量大小batch size大于通道memory-channel的事务容量transaction capacity。这意味着Kafka数据源的批量大小超出了通道的处理能力范围,需要调整配置文件中的参数
4.Sink hdfs-sink has been removed due to an error during configuration java.lang.InstantiationException: Incompatible sink and channel settings defined. sink's batch size is greater than the channels transaction capacity. Sink: hdfs-sink, batch size = 1000, channel memory-channel, transaction capacity = 100:这条错误信息表示HDFS输出插件hdfs-sink被移除,原因是配置文件中定义的批量大小batch size大于通道memory-channel的事务容量transaction capacity。这意味着HDFS输出插件的批量大小超出了通道的处理能力范围,需要调整配置文件中的参数
综上所述,在k2h.conf中修改了transaction capacity的最大值
agent.channels.memory-channel.transactionCapacity = 10000
重启flume,产生新的错误
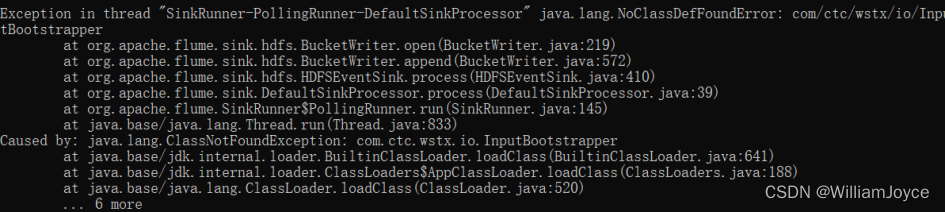
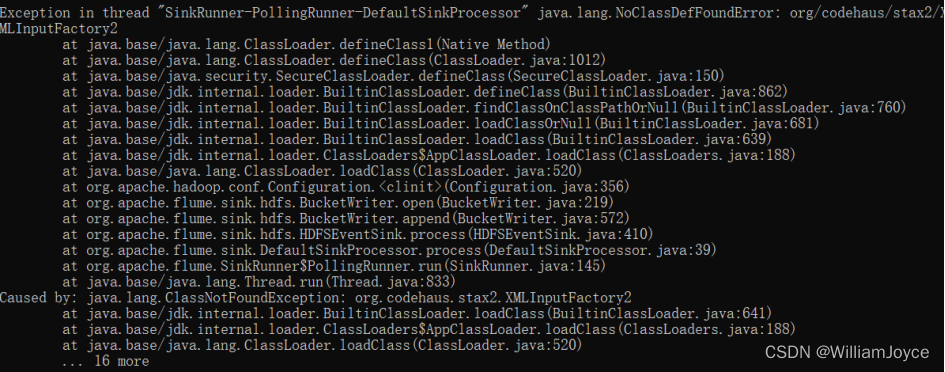
java.lang.NoClassDefFoundError: com/ctc/wstx/io/InputBootstrapper:表示在运行时找不到名为com.ctc.wstx.io.InputBootstrapper的类
java.lang.NoClassDefFoundError: org/codehaus/stax2/XMLInputFactory2:这是一个Java异常,表示在运行时找不到名为org.codehaus.stax2.XMLInputFactory2的类。
根据异常信息分析,可能是因为缺少com.ctc.wstx.io.InputBootstrapper类和org.codehaus.stax2.XMLInputFactory2类导致的异常。可以尝试在Flume的classpath中添加该类所在的jar包。
将hadoop目录下的woodstox-core-5.0.3.jar和stax2-api-3.1.4.jar包复制到flume/bin路径下,重启flume
查看flume.log
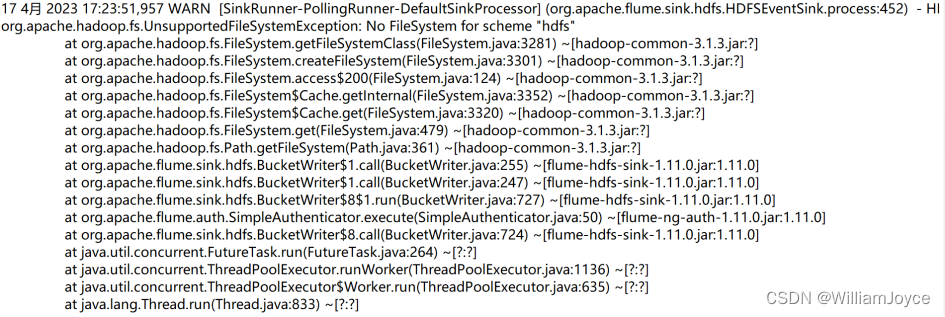
又是一个新的错误,我们来进行分析:
WARN [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.HDFSEventSink.process:452) - HDFS IO error:这是一个警告信息,表示Flume在进行HDFS输出时出现了IO错误
org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "hdfs":这是一个Java异常,表示在获取HDFS文件系统时出现了不支持的文件系统异常
以上两条报错,可能是因为Flume配置中没有正确指定Hadoop的文件系统类型或者没有正确配置Hadoop的相关参数,导致Flume无法识别和连接Hadoop的文件系统。具体的原因需要根据具体的配置和环境来分析,可以检查以下几个方面:
1.Flume配置文件中是否正确指定了Hadoop的文件系统类型和相关参数,例如指定了hdfs://作为文件系统前缀。
2.是否正确安装和配置了Hadoop集群,包括配置了Hadoop的core-site.xml、hdfs-site.xml等相关配置文件。
3.是否正确配置了Flume和Hadoop的环境变量和类路径,例如HADOOP_HOME、HADOOP_CONF_DIR、FLUME_CLASSPATH等。
而其他报错则可能是因为Flume的classpath中缺少Hadoop相关的jar包,需要检查classpath是否正确,另外也可能是flume版本与hadoop版本不匹配导致jar包不匹配的原因
经过检查,应该是hadoop版本与jdk版本不匹配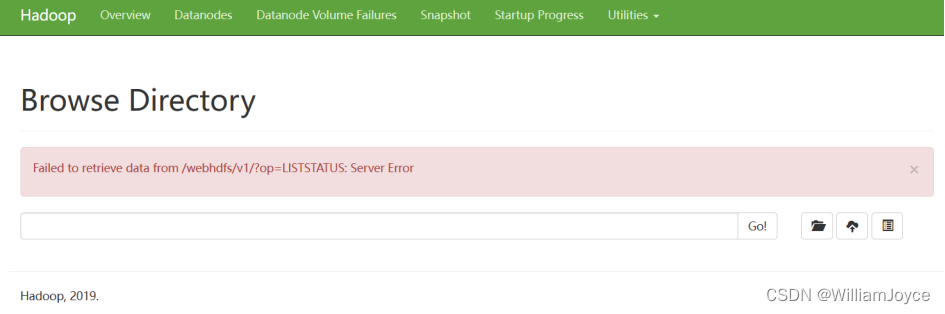
我当前的jdk版本为17.0.2,hadoop官网建议最好为jdk8或jdk11
下载jdk8并配置环境后,重启上述服务,Browse Directory已正常运行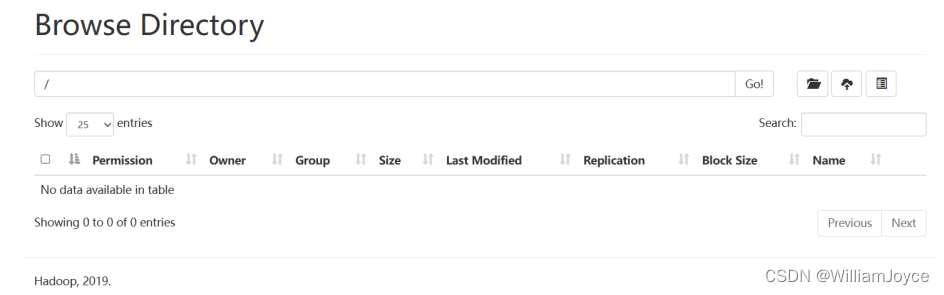
然而flume.log中仍能看到org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "hdfs"异常,这次我们将hadoop里hdfs的所有jar包都复制到flume/bin下,包括:hadoop-hdfs-x.x.x.jar,hadoop-hdfs-client-x.x.x.jar,hadoop-hdfs-httpfs-x.x.x.jar,hadoop-hdfs-native-client-x.x.x.jar,hadoop-hdfs-nfs-x.x.x.jar,hadoop-hdfs-rbf-x.x.x.jar
然后在kafka生产者端输入内容
这次可在Browse Directory中看到一个新文件,查看它的tmp日志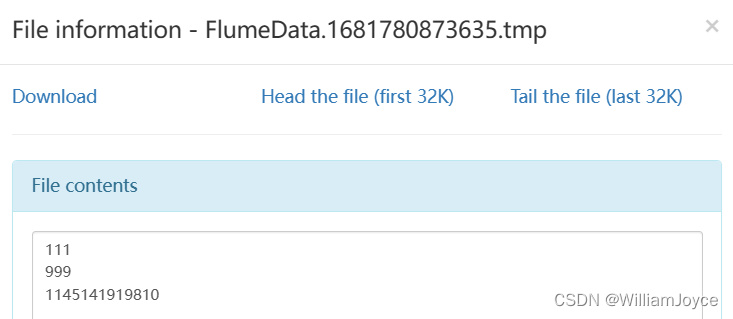
实验步骤已全部完成
- 总结
- 如果信息接收端无法获取信息时,逐一检查信息发出端、传输端(flume)、信息接收端相关配置是否出现问题。一般来说错误都发送在传输端,检查flume日志可以清晰地查看错误信息
- 信息发出端、传输端(flume)、信息接收端的jar包应该相互匹配且能调用
- jdk版本也应匹配信息发出端、传输端(flume)、信息接收端,最好不要使用最新版本的jdk,因为它将不会再支持部分API
- 遇到无法解决的问题?试着询问ChatGPT!
版权归原作者 WilliamJoyce 所有, 如有侵权,请联系我们删除。