
异构数据源离线同步工具之DataX的安装部署
🍅程序员小王的博客:程序员小王的博客
🍅 欢迎点赞 👍 收藏 ⭐留言 📝
🍅 如有编辑错误联系作者,如果有比较好的文章欢迎分享给我,我会取其精华去其糟粕
🍅java自学的学习路线:java自学的学习路线
🍅该博客参考文献:阿里云DataX,DataX官网,尚硅谷大数据研究院
一、DataX概述
1、什么是DataX
DataX是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle,DB2 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。在阿里巴巴集团内被广泛使用的离线数据同步工具
- DataX开源地址:https://github.com/alibaba/DataX

2、DataX的设计
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源,当需要接入一个新的数据源的时候,只需要将数据源对接到DataX,便能跟已有的数据源做到无缝数据同步了!
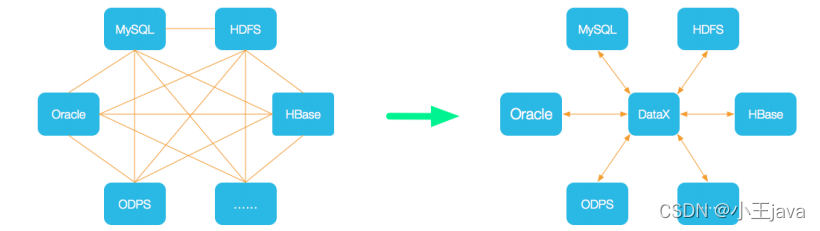
3、支持的数据源
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
类型数据源Reader(读)Writer(写)文档RDBMS 关系型数据库MySQL√√读 、写Oracle√√读 、写OceanBase√√读 、写SQLServer√√读 、写PostgreSQL√√读 、写DRDS√√读 、写通用RDBMS(支持所有关系型数据库)√√读 、写阿里云数仓数据存储ODPS√√读 、写ADS√写OSS√√读 、写OCS√写NoSQL数据存储OTS√√读 、写Hbase0.94√√读 、写Hbase1.1√√读 、写Phoenix4.x√√读 、写Phoenix5.x√√读 、写MongoDB√√读 、写Hive√√读 、写Cassandra√√读 、写无结构化数据存储TxtFile√√读 、写FTP√√读 、写HDFS√√读 、写Elasticsearch√写时间序列数据库OpenTSDB√读TSDB√√读 、写
4、DataX框架设计
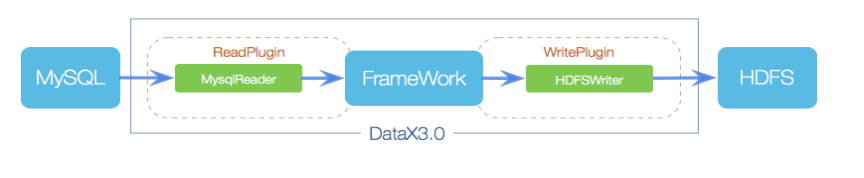
- **Reader:**数据采集模块,负责采集数据源的数据,将数据发送给FrameWork
- Writer:数据写入模块,负责不断向FrameWork取数据,并将数据写入到目的端
- FrameWork:用于连接Reader,writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题
5、运行原理
(1)运行原理
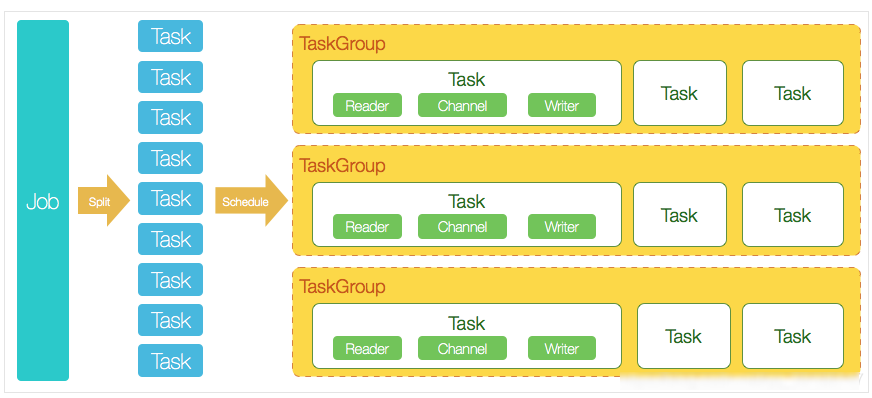
- Job:单个作业的管理节点,负责数据清洗,子任务划分,TaskGroup监控管理
- **Task:**由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作
- Schedule(计划表):将Task组成TaskGroup,单个TaskGroup的并发量为5
- **TaskGroup:**负责启动Task
(2)举例:
用户提交了一个DataX作业,并且配置20个并发,目的是将一个100张分表的mysql数据同步到ods里面。
DataX的调度决策思路是:
- DataX的Job根据分库分表切分成100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task.
6、当前现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
7、DataX与Sqoop的对比
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。

二、DataX
1、官方地址
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com
源码地址:https://github.com/alibaba/DataX
2、前置条件
- Linux(我使用的是阿里云)
阿里云参考我的另外一篇博客:阿里云部署javaWeb项目依赖软件(jdk、tomcat、Mariadb数据库)的安装_程序员小王的博客-CSDN博客
- JDK(1.8 以上,推荐 1.8)
- Python(使用的是 Python2.7.5X)
- 4、datax-web(项目地址:https://github.com/WeiYe-Jing/datax-web)
3、安装部署DataX
(1)访问官网下载安装包
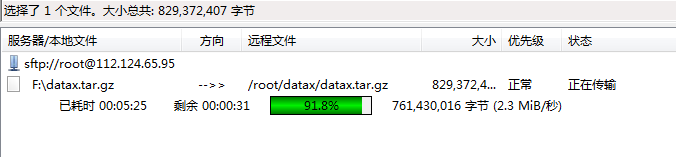
(2)使用filezilla上传安装包到服务器(阿里云)datax节点
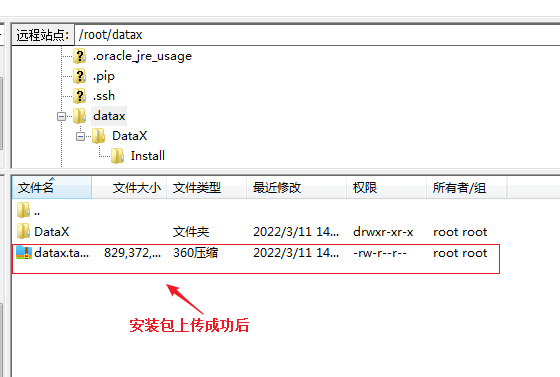
(3)解压安装包
- 将安装到
/root/datax/路径下
tar -zxvf datax.tar.gz
- 安装成功后

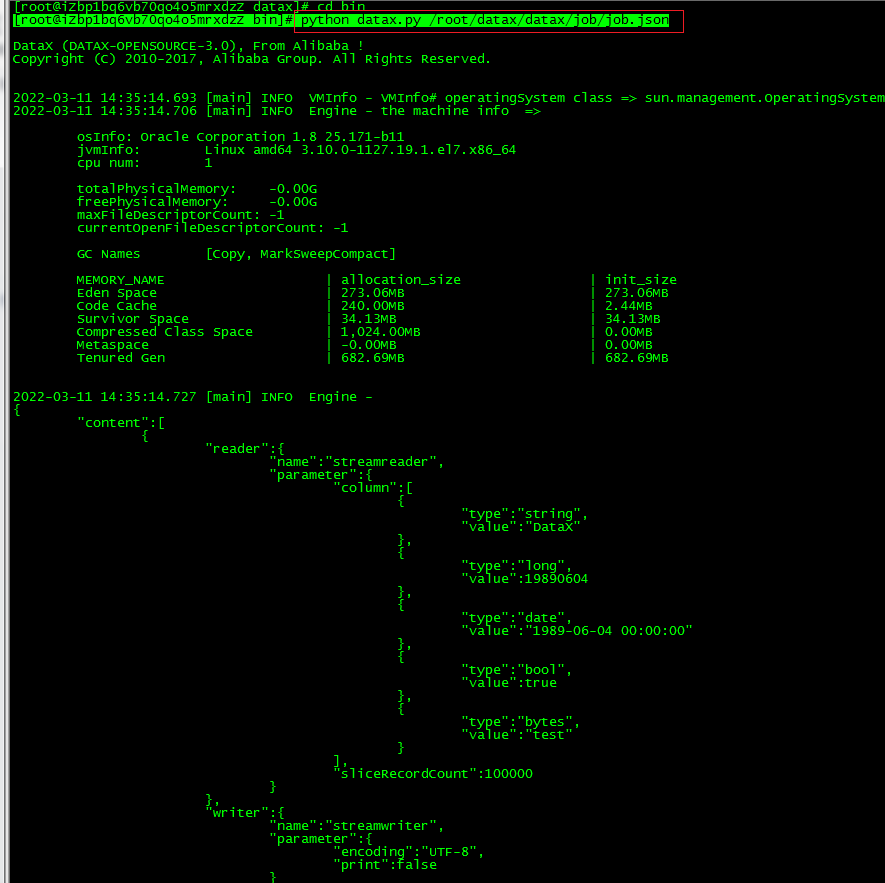
(4)运行自检脚本测试(需要在bin下启动)
python datax.py /root/datax/datax/job/job.json
三、DataX实战案例之从 stream 流读取数据并打印到控制台
(1)查看配置模板
python datax.py -r streamreader -w streamwriter
[root@iZbp1bq6vb70qo4o5mrxdzZ bin]# python datax.py -r streamreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
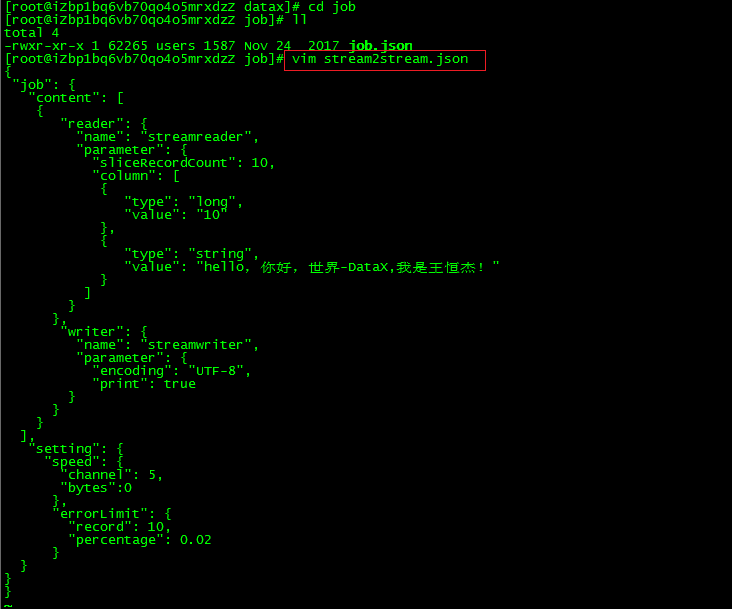
(2)根据模板编写配置文件
record: 出错记录数超过record设置的条数时,任务标记为失败.percentage: 当出错记录数超过percentage百分数时,任务标记为失败.channel表示任务并发数。bytes表示每秒字节数,默认为0(不限速)。
-在job目录下创建文件:
vim stream2stream.json
- 运行
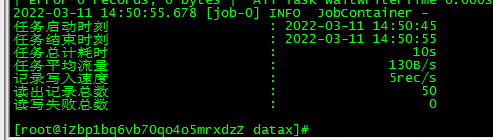
-在datax执行命令:
[root@iZbp1bq6vb70qo4o5mrxdzZ datax]# python bin/datax.py job/stream2stream.json

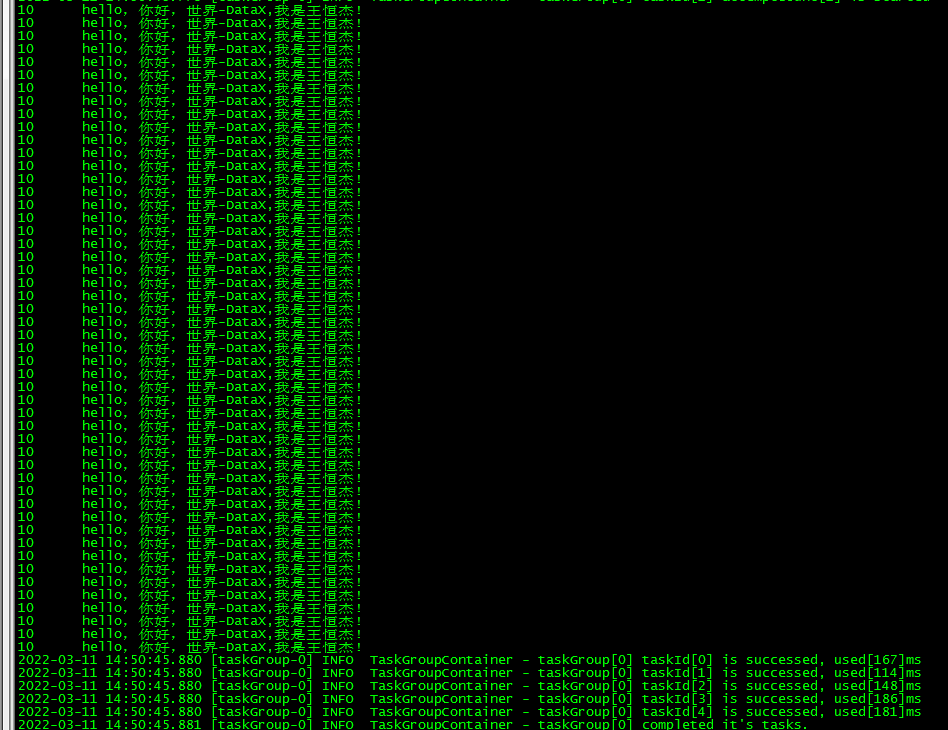
(3)观察控制台输出结果
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
10 hello,你好,世界-DataX,我是王恒杰!
四、最后的话
因为DataX内容较多,预计将分五部份完成DataX博客的专栏,分别是
- 【1】异构数据源离线同步工具之DataX的安装部署
- 【2】异构数据源离线同步工具之DataX的可视化工具DataX-Web
- 【3】读取 MySQL 中的数据Oracle 数据库
- 【4】读取 Oracle中的数据Mysql数据库
- 【5】读取 Oracle中的数据DB2数据库
- 【6】读取DB2中的数据Mysql数据库
版权归原作者 小王java 所有, 如有侵权,请联系我们删除。