
1.背景&现状
在大数据领域也已经工作了多年,无论所待过的大公司还是小公司,都会遇到集群升级迁移过程中据搬迁等相关工作,经常会碰到搬迁之后,搬迁的数据是不是能对的上呢?两边数据究竟是不是一致的呢?如果不一致,那又有哪些差异呢?能不能更快地找到差异解决问题呢?
之前经常每个开发的同学自己写一些SQL 脚本进行去比对的,而且也没有一个评估标准。这样的话效率比较低下。
其实在《阿里巴巴大数据之路》这本其实有提到这样一个平台,但是由于没有对外使用,所以书中介绍比较简单。因此根据以往的工作经历,开发了一个大数据比对平台,用来辅助验证数据,命名为dataCompare。
主要解决如下几个问题:
(1)验证数据、数据比对,浪费极大的人力成本,一张表数据从对比数据到找差异数据可能要花1-2小时时间,如果再乘以表的数量,时间成本基本上就是2H*N(N为表的数量)
(2)没有一套标准,验证的结果难以评估,每个对比的同学对比标准也不支持,有的可能看看数据量对上就行了,但是其实数据并不一定能对的上
(3)经常是写一大段复杂的SQL,通过查看SQL运行的结果来进行判断是否有问题,通常还需要去调试SQL保证SQL能正常运行
2.目标
为了解决上述问题因此开发了一个大数据对比平台——dataCompare
(1)采用界面交互、勾选的方式或者低代码的方式即可实现自动化数据校验对比,避免复杂SQL调试
(2)建立一套统一的数据校验标准,避免不同开发同学选取的标准不一致,比如:量级对比、一致性对比
(3)提升数据团队的验数比对效率,至少提升50%左右
3.系统核心功能介绍
目前dataCompare 已经完成了如下功能:
(1)界面级交互数据对比任务配置,低代码少量配置快速生成对比任务
(2)量级对比、一致性对比、自动化差异case发现
(3)目前已经支持MySQL、Hive、Doris 等JDBC 数据库
对比流程如下:
(1)新建库信息

(2)选择需要对比数据信息

(3)执行对比任务

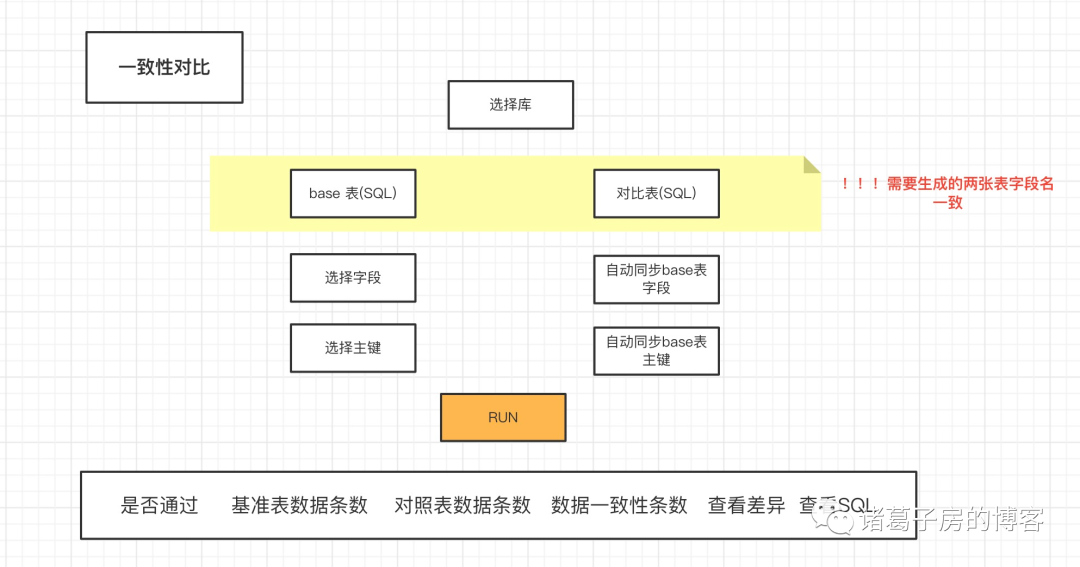
(4)差异发现
自动筛选出差异case,便于排查问题
4.系统架构设计
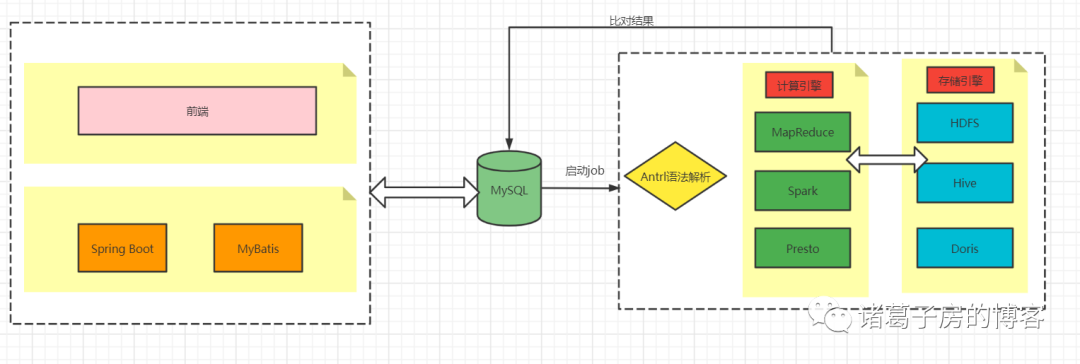
前端主要是针对数据校验对比选择表和字段,生成校验任务。
后端主要是采用spring boot、Mybatis 将前端的配置数据写入MySQL表里,然后启动MapReduce或者Spark 任务来进行校验,目前支持的引擎包括:MapReduce、Spark,数据存储包括:HDFS、Hive等,后续考虑扩展更多的数据引擎和存储引擎。
5.系统功能演示
(1)主页
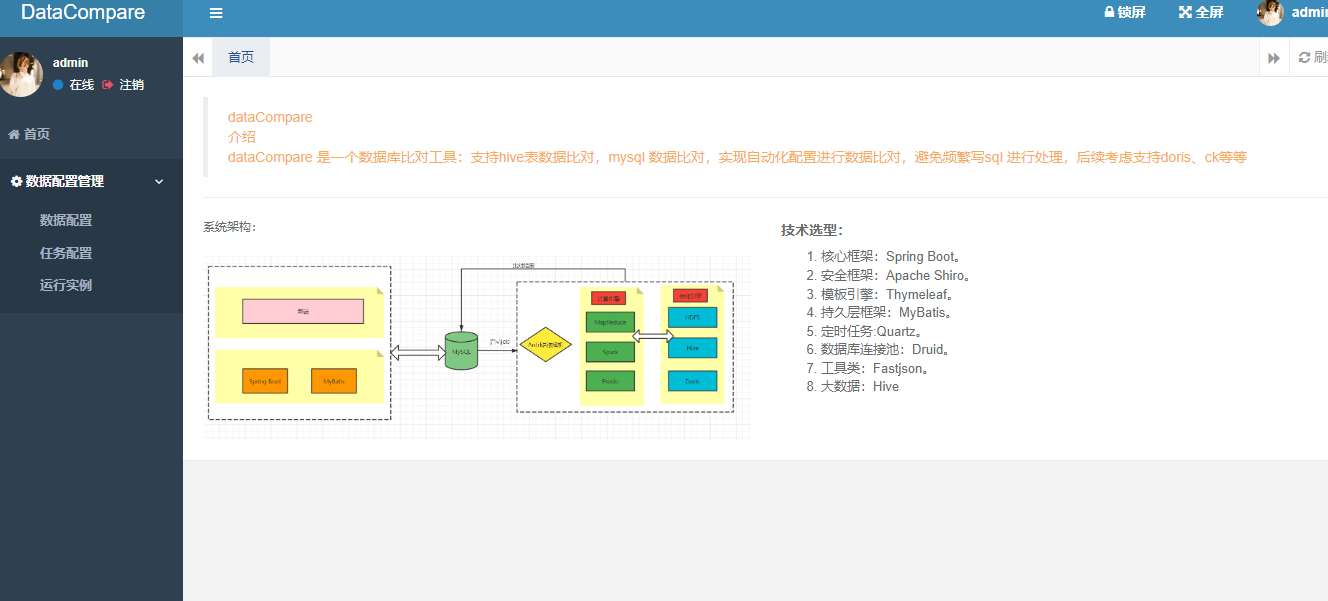
(2)数据库配置页


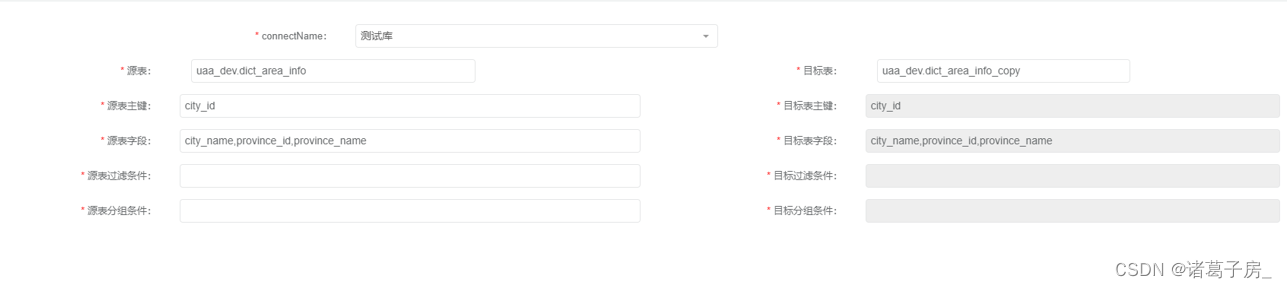
(3)对比信息配置
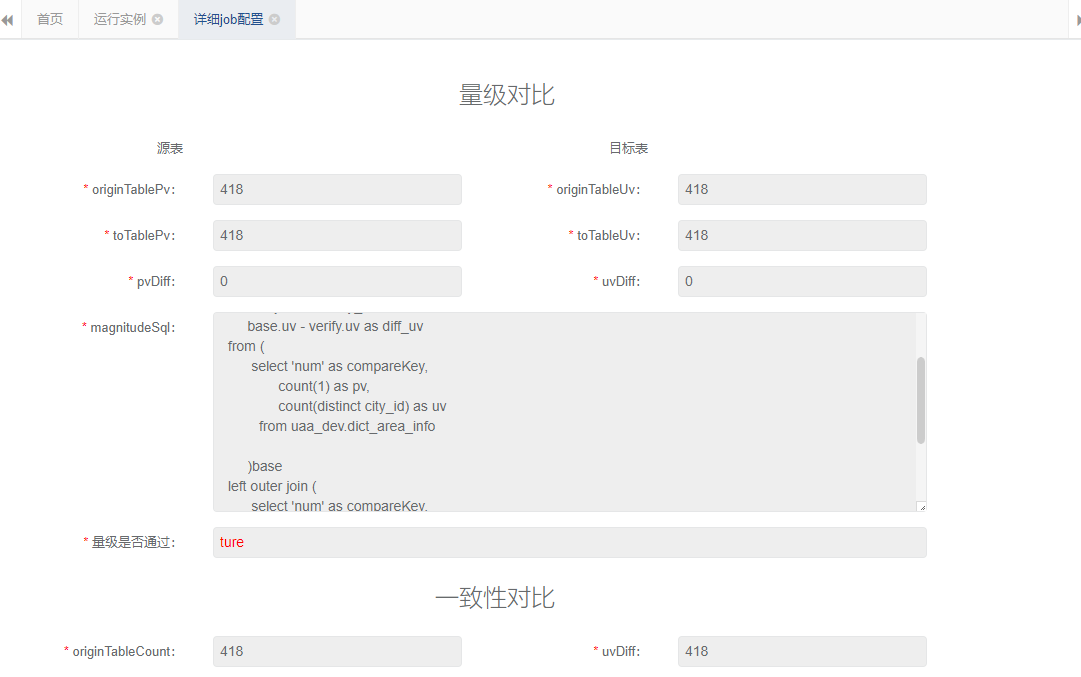
(4)对比结果展示

(5)差异case自动发现

6.后续规划
(1)陌生表数据探测,包括:枚举值探测、范围值探测、主键hash 探测
(2)对比任务定时自动调度,对比结果报告自动发送至邮箱等多个渠道
(3)异源数据对比,目前本项目已经实现了同源数据对比功能,后续考虑扩展异源项目对比
7.核心代码开源
版权归原作者 诸葛子房_ 所有, 如有侵权,请联系我们删除。