
时刻记住自己要成为什么样的人。——你
flink入门基础

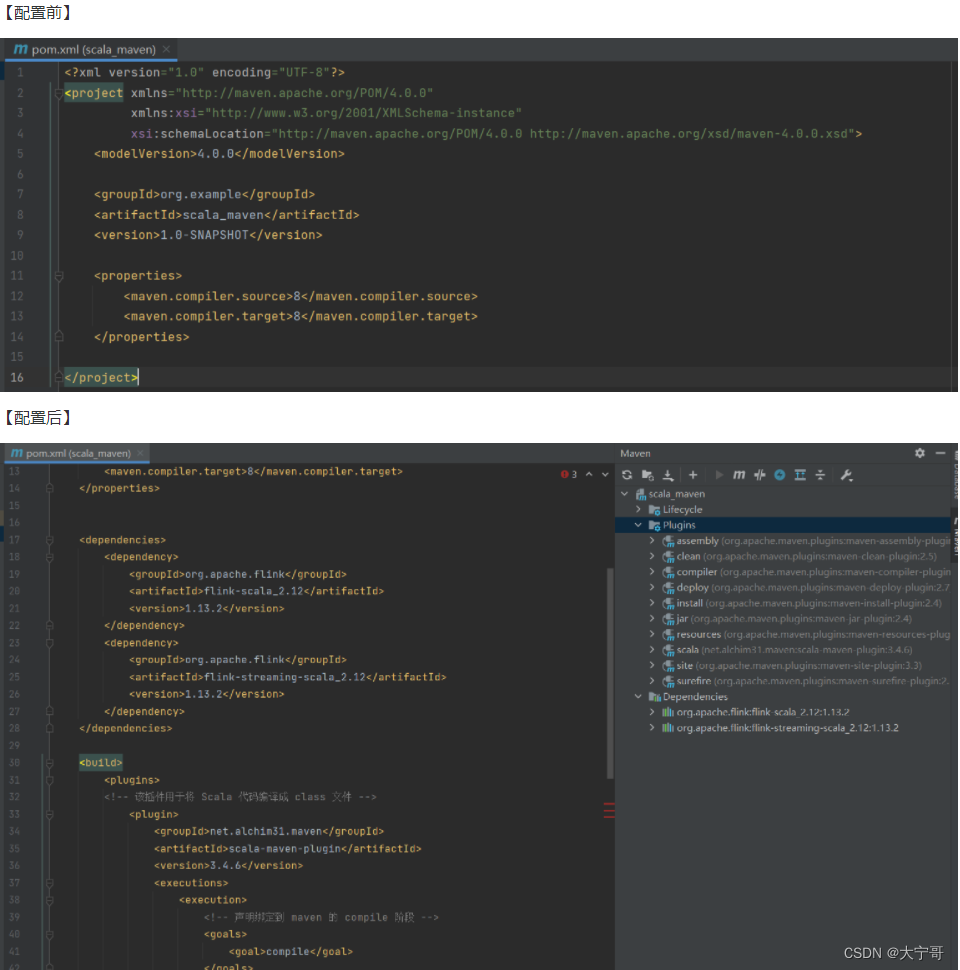
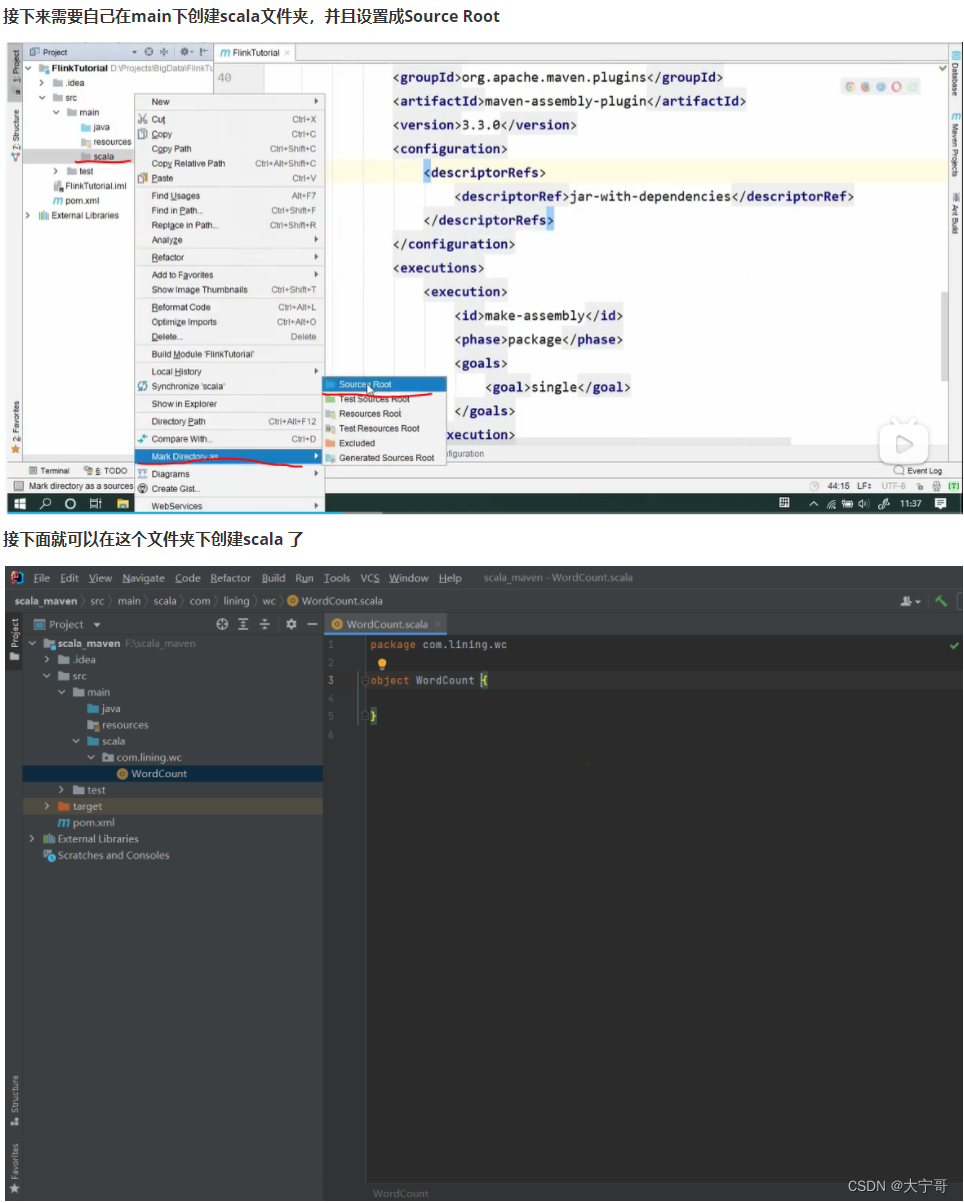
1.项目前提:设置maven【配置pom.xml文件】
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>1.13.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>1.13.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.13.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.13.2</version></dependency></dependencies><build><plugins><!-- 该插件用于将 Scala 代码编译成 class 文件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><!-- 声明绑定到 maven 的 compile 阶段 --><goals><goal>compile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
#查看flink 版本 : flink -v

2.WordCount批处理(例)
packagecom.lining.wc//注意,scala开发引用的api都是flink.api.scala.下的,flink.api.java下的不用importorg.apache.flink.api.scala.ExecutionEnvironment
importorg.apache.flink.api.scala._
/* 批处理的Word Count
* 下面著名数据类型为了更好的学习,scala也可以不著名类型
* */object WordCount {def main(args: Array[String]):Unit={//创建一个执行环境:批处理val env:ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment;//注意这里引用的是flink.api.scala下的ExecutionEnvironment//从文件中读取数据val inputPath:String="F:\\scala_maven\\src\\main\\resources\\hello.txt";val inputDataSet:DataSet[String]= env.readTextFile(inputPath)//按照word进行分组,再进行聚合val resultDataSet = inputDataSet
.flatMap(_.split(" ")).map((_,1)).groupBy(0)//以第一个元素进行分组.sum(1)//以第二个值进行求和统计
resultDataSet.print()}}

结果
3.WordCount流处理(例)
packagecom.lining.wc//注意,scala开发引用的api都是flink.api.scala.下的,flink.api.java下的不用importorg.apache.flink.api.scala._
importorg.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/* 流处理Word Count
* 下面著名数据类型为了更好的学习,scala也可以不著名类型
* */object StreamWordCount {def main(args: Array[String]):Unit={//创建一个执行环境:流处理val env = StreamExecutionEnvironment.getExecutionEnvironment;//接收一个socket文本流val inputDataStream = env.socketTextStream("127.0.0.1",7777);//监听一个主机端口 发送过来的socket数据//按照word进行分组,再进行聚合/*
* 流处理里面没有groupBy 好好想想原因。
*
*/val resultDataStream = inputDataStream
.flatMap(_.split(" ")).map((_,1)).keyBy(0)//流处理里面的分组用keyBy.sum(1)//以第二个值进行求和统计
resultDataStream.print()/*上面代码只是相当于定义任务,还没执行任务。流处理是事件驱动。
* 如果不写启动执行,相当于在运行定义,执行就啥也没跑 *///启动执行任务
env.execute("Socket stream word count");}}

4.从外部命令中传入参数
方法又很多。
方法1:args
方法2:flink给提供了patamTool ,这个是flink单独提供的。
例子 : 流处理——从外部传入 主机名和端口号
packagecom.lining.wc//注意,scala开发引用的api都是flink.api.scala.下的,flink.api.java下的不用importorg.apache.flink.api.java.utils.ParameterTool
importorg.apache.flink.api.scala._
importorg.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/* 流处理Word Count
* 下面著名数据类型为了更好的学习,scala也可以不著名类型
* */object StreamWordCount {def main(args: Array[String]):Unit={//创建一个执行环境:流处理val env = StreamExecutionEnvironment.getExecutionEnvironment;//接收一个socket文本流val paramTool = ParameterTool.fromArgs(args);val host = paramTool.get("host");val port = paramTool.getInt("port");val inputDataStream = env.socketTextStream(host, port);//val inputDataStream = env.socketTextStream("127.0.0.1", 7777); //监听一个主机端口 发送过来的socket数据//按照word进行分组,再进行聚合/*
* 流处理里面没有groupBy 好好想想原因。
*
*/val resultDataStream = inputDataStream
.flatMap(_.split(" ")).map((_,1)).keyBy(0)//流处理里面的分组用keyBy.sum(1)//以第二个值进行求和统计
resultDataStream.print()/*上面代码只是相当于定义任务,还没执行任务。流处理是事件驱动。
* 如果不写启动执行,相当于在运行定义,执行就啥也没跑 *///启动执行任务
env.execute("Socket stream word count");}}

启动
方法1:命令行 scala xxxx --host 127.0.0.1 --port 7777 (猜的)
方法2:再IJ上配置 run ——>Edit Config ——下图
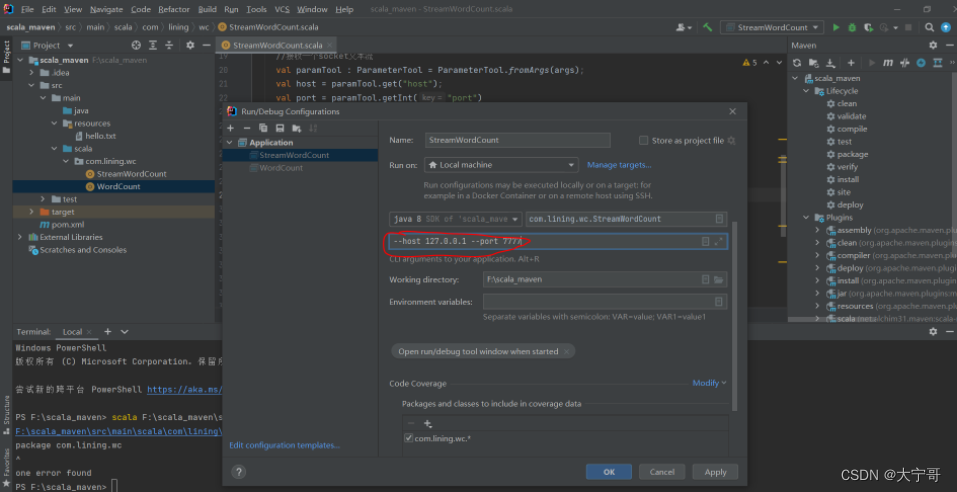
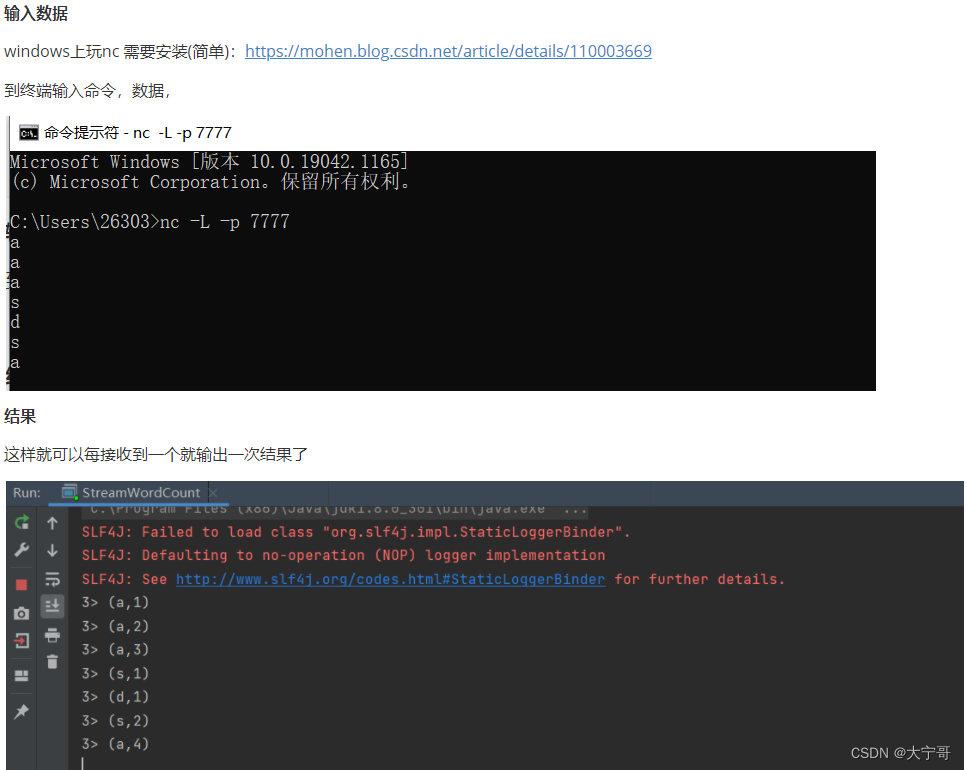
接下来和流处理的测试方式一样。

4.批、流处理wordcount区别总结
/*创建执行环境不同*///批处理环境ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();//流处理环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();/*读取的数据*///批DataSet或DataSource<String> inputDataSet = env.readTextFile(input_path);//流DataStreamSource<String> inputDataSet = env.readTextFile(input_path);/*分组*///批groupby()//流keyby()//原因是groupby分组 必须是所有数据都到才能分组,流处理过程并不是所有数据都到。keyby()是指定key,根据不同的key进行划分。/*事件触发*///批处理不需要事件触发//流处理需要事件触发
env.execute();/*输出情况*///批处理
直接输出最终结果
//流处理
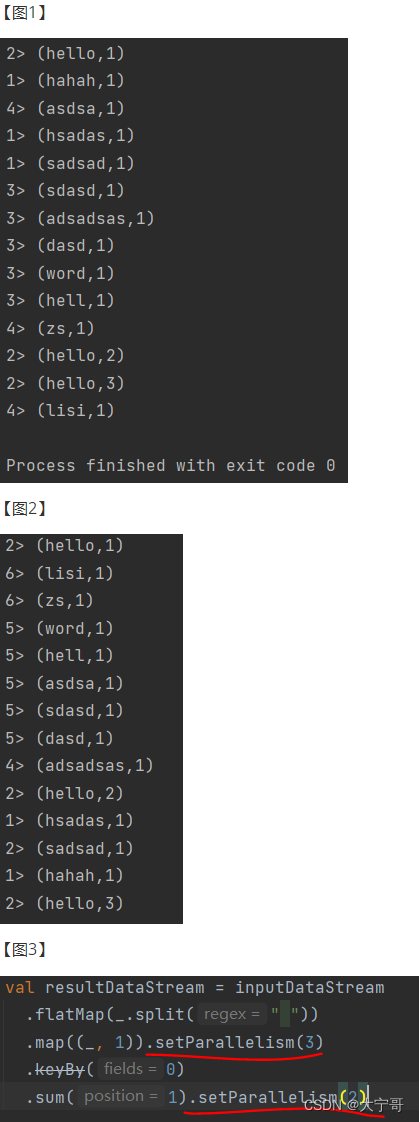
流处理输出的结果是“叠加态”, 如下【图1】:
【图1】前面的数字(“1>,2>,...”)是干嘛的?因为flink执行在一个分布式的环境下做分布式计算,但我们在本地启动的话实际上是模拟多线程,所以可以表示当前线程的编号。如果真在分布式flink上运行的话可以表示运行分区的编号。 为什么只有1,2,3,4只有4个呢?因为在开发环境下默认并行度=机器核心数(我笔记本是4核的), 这个并行度可以设置(代码中设置):env.setParallelism(6); 设置并行度为6,再次运行【图2】。 具体分到哪一个线程,work求hash,然后除以线程数字,求余数。
flink设置并行读是非常灵魂的。可以细到每一个步骤。(每个算子是独立的),如【图3】。这种设置比较少,因为既然我们又这个资源我们为什么给调小呢? 但是有个特里,就是最后打印输出的时候,或者写入文件的时候使用.setParallelism(1) 这样方式出现并行写入 担心冲突或者错误。
5.flink-提交Job
step1:将程序打包成jar
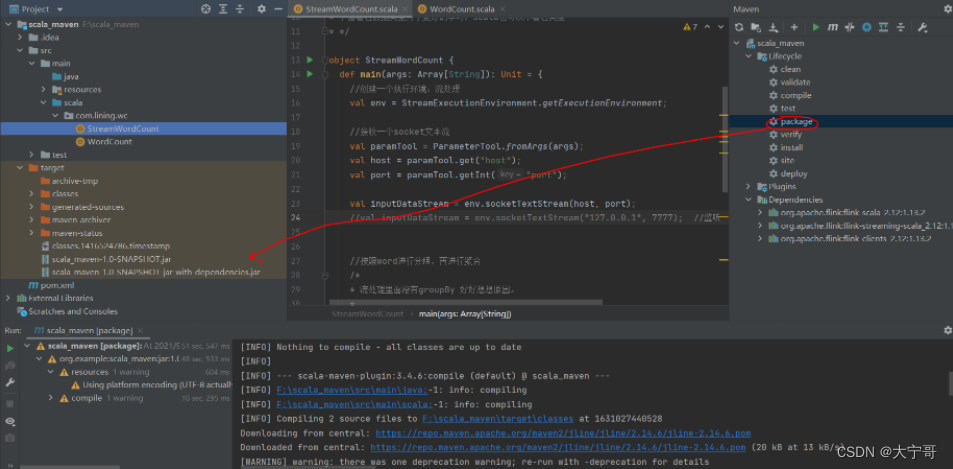
step2:上传,并且配置。
配置:
#Entry Class 入口类#parallelism 并行度(并行度优先级:代码中定义的 > 提交时候设定的 > 配置文件的)#programArgs 参数(代码中需要设定的参数)#savepointPath 手动存盘,(重点,不常用)
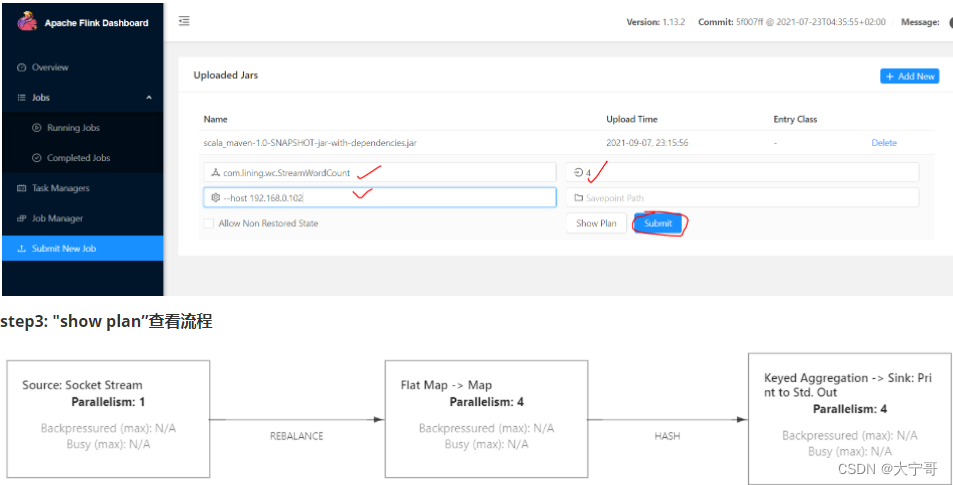
step4 : 提交,运行
实验是流式计算wordcount, 注意先启动传数据的端口 ”nc -lk 端口号“。 然后提交。再然后通过socket传数据,接下来就运行计算了。
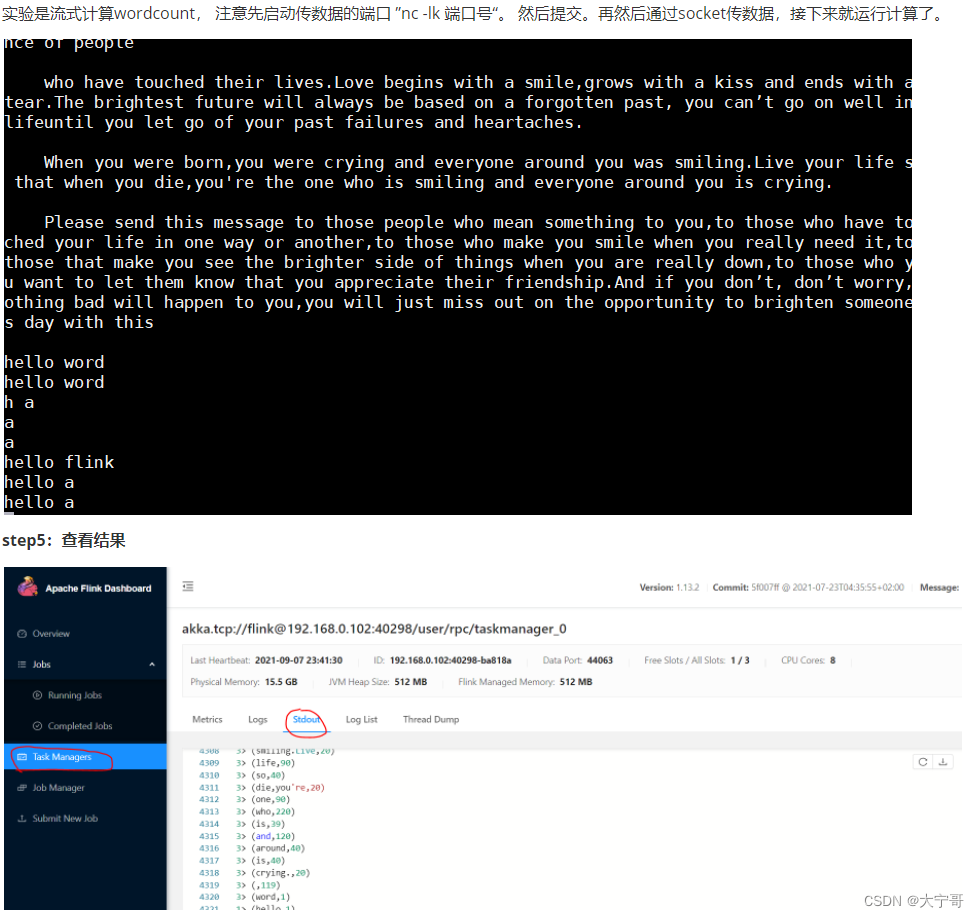
6.flink 命令行提交Job
简单的提交命令
依然使用【5】的例子。只不过这次使用命令来执行
flink/bin/flink run \
-c com.lining.wc.StreamWordCount \
-p 2\
/root/scala_maven-1.0-SNAPSHOT-jar-with-dependencies.jar --host 192.168.0.102 --port 7777#-c 入口类#-p 并行读#参数依然用 --#注意:上面的命令是“前台命令”,不可以用 Ctrl+c取消。 如果想取消,输入以下命令:
flink/bin/flink cancel [Job_id值]#如:flink/bin/flink cancel 337db94c10644438c2889b412ab17c7b#查看当前运行的Job
flink/bin/flink list
#查看所有的(运行的,运行完的,失败的 。。。)
flink/bin/flink list -a
flink命令集
run
-c,–class 指定的main方法类-C,–classpath 向每个用户代码添加url,他是通过UrlClassLoader加载。url需要指定文件的schema如(file://)-d,–detached在后台运行-n,–allowNonRestoredState跳过无法恢复的savepoint数据-p,–parallelism job需要指定env的并行度-py,–python 针对python脚本。指定脚本路径-pyarch,–pyArchives 指定一个压缩文件供python 函数使用,目前仅支持zip文件-pyexec,–pyExecutable 指定用于执行python UDF工作器的python解释器的路径-pyfs,–pyFiles 为作业附加自定义文件。 标准的资源文件后缀,如.py/.egg/.zip-pym,–pyModule Python模块与程序入口点, 结合pyFiles使用-pyreq,–pyRequirements 指定一个requirements.txt文件来定义第三方依赖项。 这些依赖项将被安装并添加到python UDF工作器的PYTHONPATH中-s,–fromSavepoint 基于savepoint保存下来的路径,进行恢复-sae,–shutdownOnAttachedExit如果是前台的方式提交,当客户端中断,集群执行的job任务也会shutdown
Generic CLI
-D <property=value>允许指定多个通用配置选项-e,–executor 已经弃用-t,–target 给定应用程序的部署目标,相当于“执行”
yarn-cluster
-d,–detached在后台运行-m,–jobmanager yarn-cluster集群-yat,–yarnapplicationType 设置yarn应用的类型-yD <property=value>使用给定属性的值-yd,–yarndetached后台运行-yh,–yarnhelpyarn help命令-yid,–yarnapplicationId job依附的applicationId-yj,–yarnjar Flink jar文件的路径-yjm,–yarnjobManagerMemory jobmanager的内存-ynl,–yarnnodeLabel 为YARN应用程序指定YARN节点标签-ynm,–yarnname application的名称-yq,–yarnquery查询出yarn里面可用的资源,内存 核数-yqu,–yarnqueue 指定yarn队列-ys,–yarnslots 分配的slots个数-yt,–yarnship 指定一个传输文件-ytm,–yarntaskManagerMemory taskmanager的内存-yz,–yarnzookeeperNamespace 创建ha的zk子路径的命名空间-z,–zookeeperNamespace 创建ha的zk子路径的命名空间
default
-D <property=value>允许指定多个泛型配置选项-m,–jobmanager yarn-cluster集群-z,–zookeeperNamespace 创建ha的zk子路径的命名空间
7.所有的任务流都可以看成三部分
#所有的任务流都可以看成三部分, source(数据来源) ——>transfrom(数据处理转换)——>sink(数据结果,输出)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zsiPFrrR-1664463344354)(大数据组件的安装&使用.assets/image-20210911133031151.png)]
8.任务链合并与断开
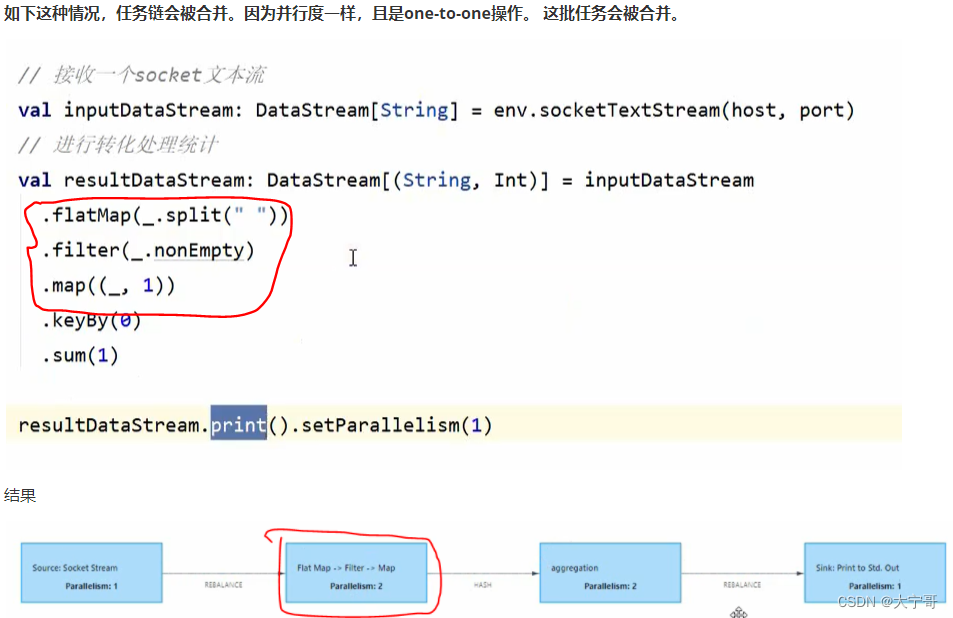
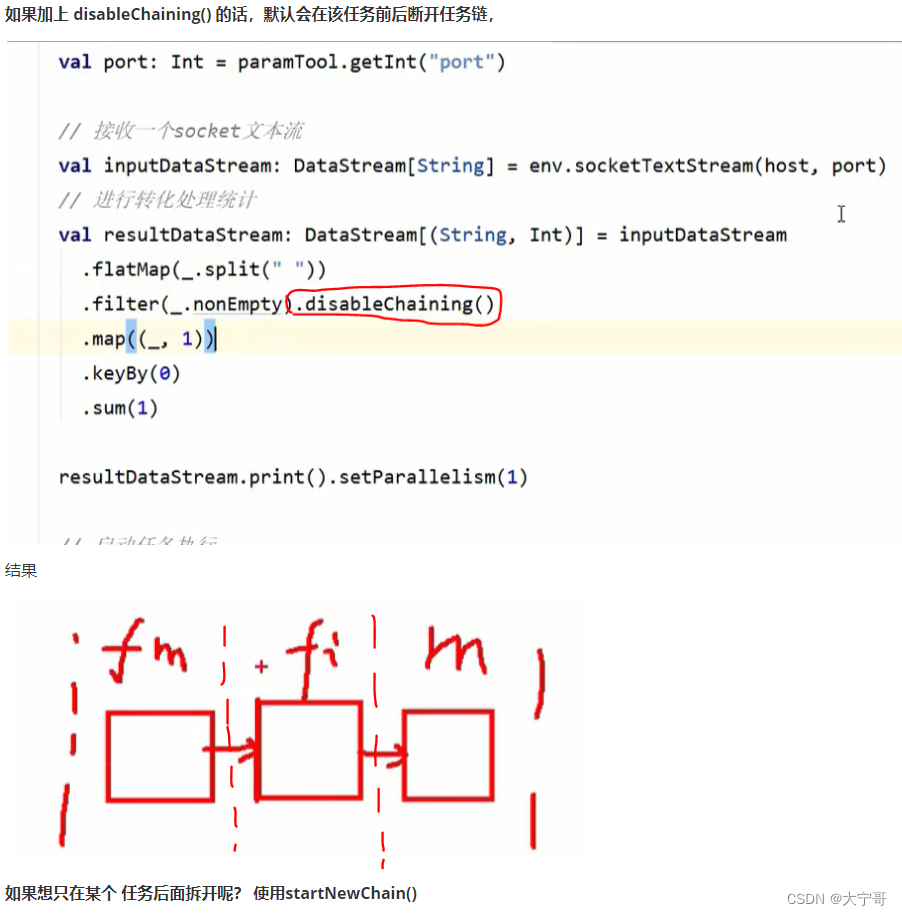
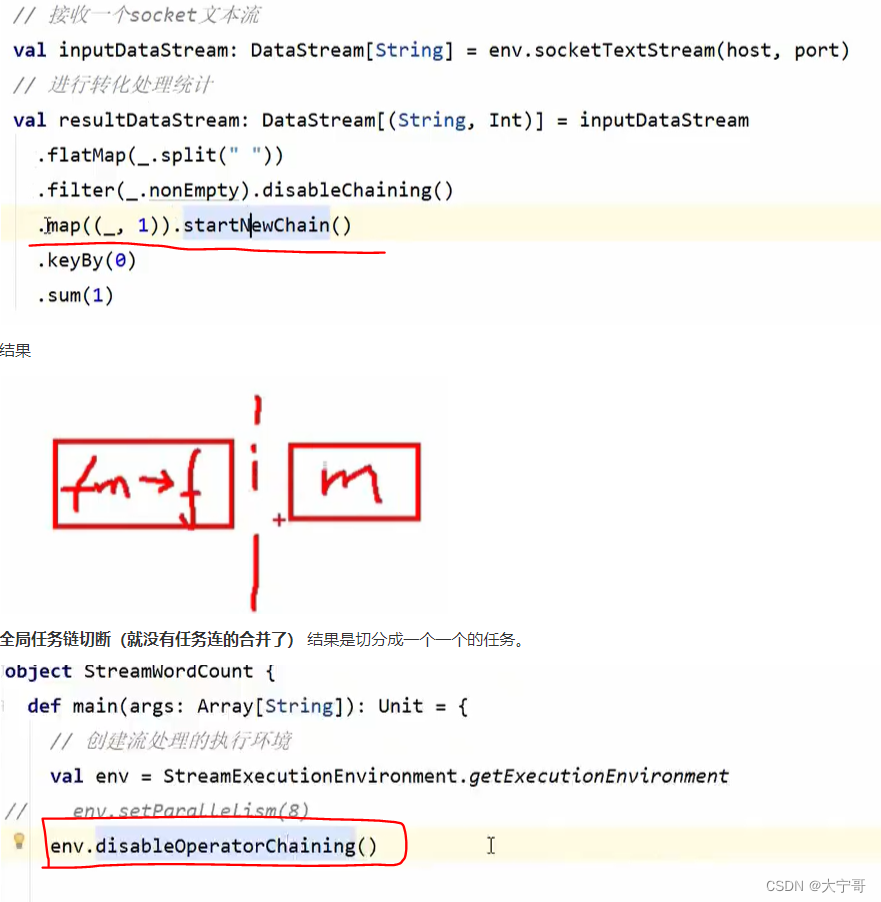
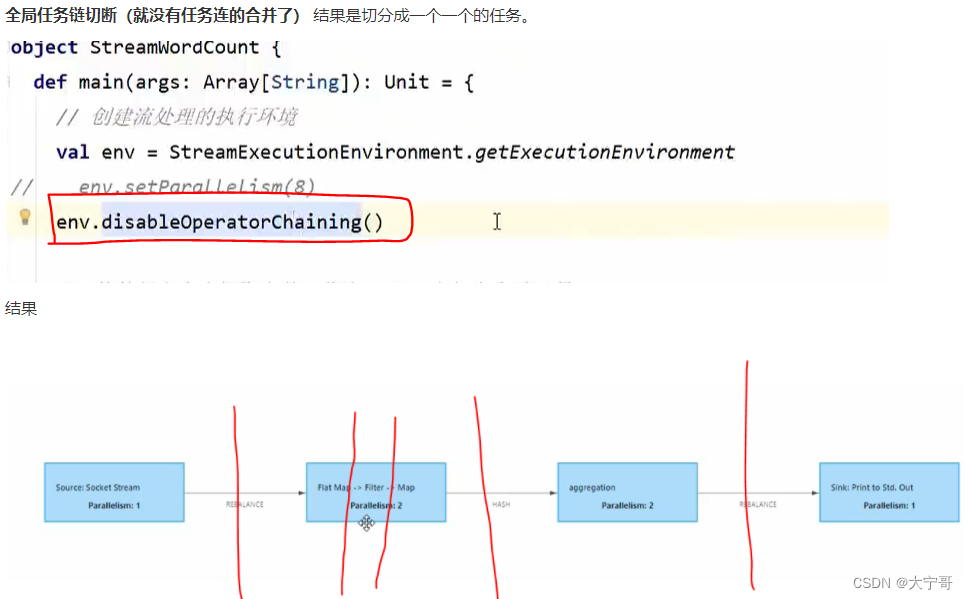
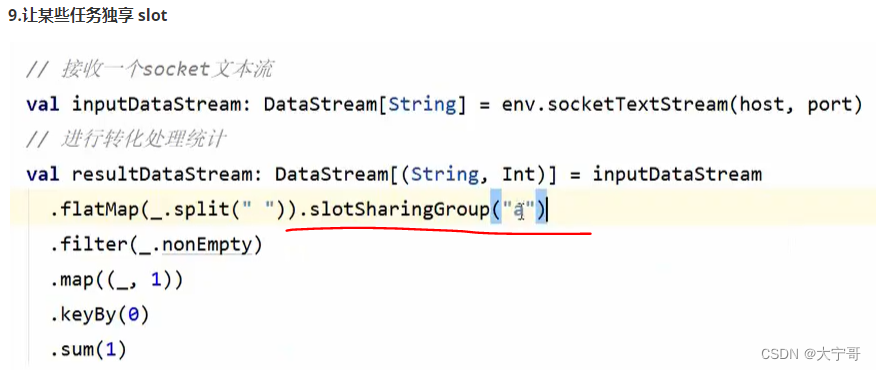
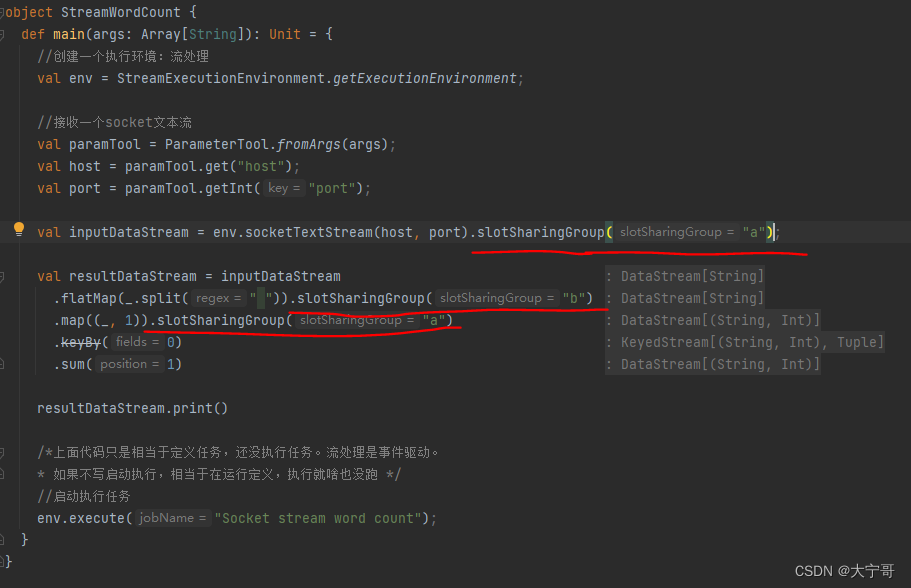
#因为默认(不设置共享组)情况下,整套流程都在一个”slot共享组“里面
注意1 #从设置共享组的这个任务开始,往下的任务都在这个”slot共享组“里面,如果想不在该共享组里面 那就需要设置为其他共享组。 那么假如我们只想要flatMap在一个”slot共享组“里面 怎么设置? --> 那么只需在整个流程开始位置设置”slot共享组A“,在需要单独共享组的flatMap地方设置”slot共享组B“,再在下一步任务处设置回”slot共享组A“即可。 具体操作如下图1。
注意2 #不同slot组是单独占用slot的。(例如slot组A包含slot1,slot2 , 而slot组B包含slot3, slot4, slot5)
注意3 #整个流程的并行度是 每个slot组中最大并行度之和。(好理解)
【图1】
10.IDEA使用的快捷键tip
https://blog.csdn.net/weixin_34168700/article/details/91803102* ctrl+Q 可以看到光标所在函数的基本信息
* ctrl + shitf + I 看到光标函数的定义信息
* F4 看到光标所在函数的详细信息
* ctrl + I : 先找到需要实现的方法。
.
.
.
.
.
.

至此,flink的入门学习已经完毕。本章简单易懂,后面会给大家更新初级、中级、高级知识点。希望大家在学习的路上坚持不懈,时刻记住自己要成为一个什么样的人。
赋诗一首:
《归来少年》
大宁
少年不惧岁月长,蓬勃向上挣荣光。
乘风破浪八千里,落日晚霞不回头。
举杯邀月同共饮,开怀大笑梦神游。
人间本是虚拟地,奈何深情留永恒。
版权归原作者 大宁哥 所有, 如有侵权,请联系我们删除。