
💌前一篇博客中,我们学习了spark代码的执行过程,其中涉及到了逻辑执行计划和物理执行计划,今天我们主要来学习spark的资源调度的内容,对往期内容感兴趣的同学可以参考如下内容👇:
- 上一篇: spark学习之执行计划explain.
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🐡说到spark的资源调度,我们主要关心的是执行计算任务节点的资源调度的设置,如单个Executor的核数、单个节点Executor的个数、单个Executor的内存大小等,接下来将会对这些进行详细的介绍。
本文目录
1. 总体资源
我们这里假设单台服务器的内存大小为128g,32个线程。
1.1 Executor的核数
executor-cores的个数决定任务的并行度,也就是同时执行task的个数,一般情况下,executor-cores的个数设置为3~6个之间比较合适。
1.2 Executor的个数
这里的Executor的个数是指整个集群的Executor的个数个数,所以:
总
的
e
x
e
c
u
t
o
r
个
数
=
每
个
节
点
的
e
x
e
c
u
t
o
r
数
∗
w
o
r
k
节
点
数
总的 executor个数= 每个节点的 executor 数 * work 节点数
总的executor个数=每个节点的executor数∗work节点数
那么单个节点的Executor个数如何计算,单个节点所能接受的最大Executor个数和yarn给的资源和Executor的核数有关,关系如下:
每
个
n
o
d
e
的
e
x
e
c
u
t
o
r
数
=
单
节
点
y
a
r
n
总
核
数
每
个
e
x
e
c
u
t
o
r
的
最
大
c
p
u
核
数
每个 node 的 executor 数 = \dfrac{单节点 yarn 总核数}{每个 executor 的最大 cpu 核数}
每个node的executor数=每个executor的最大cpu核数单节点yarn总核数
考虑到系统基础服务和 HDFS 等组件的余量,yarn的nodemanager资源配置为:28,参数 executor-cores 的值为:4,那么每个 node 的 executor 数 = 28/4 = 7,假设集群节点为 10,那么 num-executors = 7 * 10 = 70
1.3 Executor的内存
每个Executor的内存的大小也和yarn分配的资源有关系:
e
x
e
c
u
t
o
r
内
存
大
小
=
y
a
r
n
总
内
存
大
小
每
个
节
点
的
e
x
e
c
u
t
o
r
数
量
executor内存大小= \dfrac{yarn总内存大小}{每个节点的 executor 数量}
executor内存大小=每个节点的executor数量yarn总内存大小
例如:单个节点的 yarn 的参数配置为 100G,那么每个 Executor 大概就是 100G/7≈14G,同时要注意yarn 配置中每个容器允许的最大内存是否匹配,一般情况yarn默认配置的每个容器的内存大小范围为[1g,8g].
2. 内存资源
我们先来看一下spark的内存划分: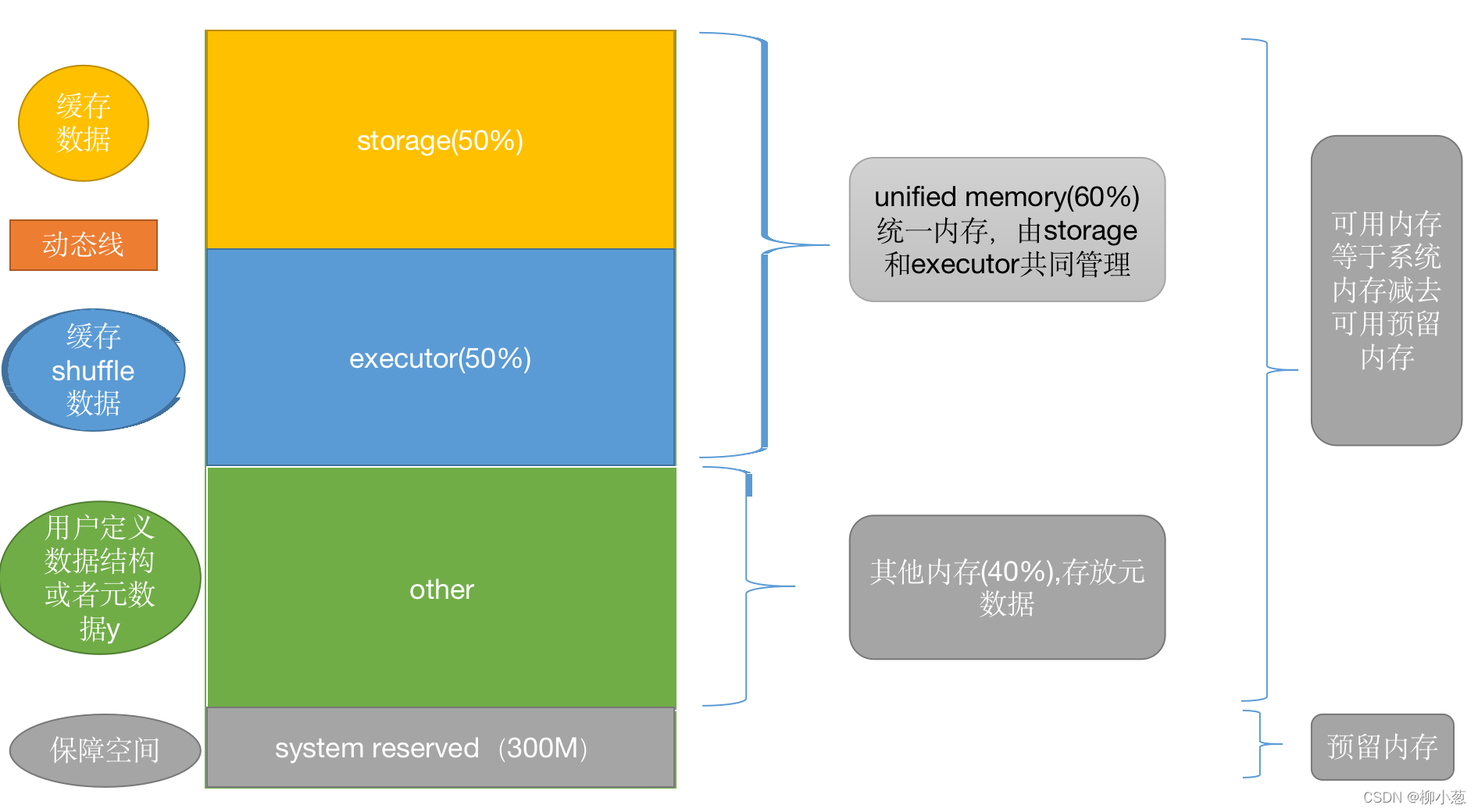
- storage空间:用来存放cache、persist和广播变量的缓存数据 。(Storage 内存 = 广播变量 + cache/Executor 数量)
- executor空间:主要负责执行计算过程中的内存开销,比如shuffle过程需要的内存。(Executor 内存 = 每个 Executor 核数 * (数据集大小/并行度))
- other空间:自定义的数据结构和元数据,(Other 内存 = 自定义数据结构*每个 Executor 核数)
3. 持久化和序列化
我们先来介绍一下持久化和序列化在spark中的含义:
- 持久化:在不同操作间,持久化(或缓存)一个数据集在内存中。当你持久化一个RDD,每一个结点都将把它的计算分块结果保存在内存中,并在对此数据集(或者衍生出的数据集)进行的其它动作中重用。这将使得后续的动作(action)变得更加迅速(通常快10倍)。
- 序列化:序列化是将对象的状态信息转换为可以存储或传输的形式的过程,主要目的有两个:1. 存储到磁盘; 2. 通过网络进行传输;而在spark中,算子相关的操作在Excutor上执行,算子之外的代码在Driver端执行,在执行有些算子的时候,需要只用到Driver里面定义的数据,这就涉及到了跨进程或着跨节点之间的通讯,所以要求传递给Excutor中的数组所属的类型必须实现Serializable接口。
3.1 RDD
我们使用rdd持久化时,默认 cache 缓存级别(memory_only),如果此时存储内存较小,可以采用kryo+序列化缓存,可以优化存储内存占用。
3.2 Dataset和Dataframe
我们使用dataset持久化时,默认cache缓存级别(memory_and_disk),即内存不够磁盘来凑,如果采用序列化的方式,实际效果和未序列化差别不大,因为Dataset和Dataframe是被优化过的rdd,所以开发中直接使用cache缓存即可。
总体来说,如果使用RDD进行持久化,建议采用kryo序列化+持久化的操作,如果使用Dataset和Dataframe直接使用cache持久化即可。从性能上来讲,DataSet,DataFrame 优于 RDD,建议开发中使用 DataSet、DataFrame。
4. CPU资源
首先来了解几个非常容易搞混的概念:
4.1 并行度
并行度指的就是task的数量,或者说分区数量
- rdd的控制方法:spark.default.parallelism,根据算子计算决定
- sql的控制方法:spark.sql.shuffle.partitions,默认200
4.2 并发度
并发度指的可同时执行的最大task数量,那这和并行度有何区别,首先并行度是指一个任务需要多少个分区,比如groupby之后产生了200个分区(200task),但是我们的executor只有2个核,即我们最多同时执行2个task,那么这个任务的并发度就是2,并行度是200。每次执行2个task,执行完后换上下一个task,一直到执行完200个。
4.3 合理利用CPU
下面两种情况会导致CPU效率过低:
- 并行度较低、数据分片较大容易导致 CPU 线程挂起(处理数据量大)
- 并行度过高、数据过于分散会让调度开销更多(task数量过多)
根据经验:一般会将并行度(task 数)设置成并发度 (vcore 数)的 2 倍到 3 倍。
这一部分的详细内容可参考: spark学习之并行度、并发、core数和分区的关系.
5. 总结
本博客主要介绍了spark运行过程中的一些资源调度的情况,以及如何配置资源调度使spark的运行效率得到提高,主要从内存、持久化、cpu资源等方面进行了介绍。
6. 参考文章
- 《尚硅谷大数据技术之 Spark 调优》
- 《spark权威指南》
- 链接: spark持久化.
- 链接: 序列化的定义.
版权归原作者 柳小葱 所有, 如有侵权,请联系我们删除。