
MapReduce序列化之统计各部门员工薪资总和
文章目录
1.1 实验目的
通过MapReduce的序列化方法统计各个部门员工薪水总和。
1.2 实验环境
- 搭建IDEA+Maven开发环境
- VMwarePro16+Centos7+xshell7+Xftp7
- Hadoop2.7.7
1.3 需求描述
员工的数据如下:
各字段描述如下:

7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,,20
7839,KING,PRESIDENT,,1981/11/17,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,,20
7900,JAMES,CLERK,7698,1981/12/3,950,,30
7902,FORD,ANALYST,7566,1981/12/3,3000,,20
7934,MILLER,CLERK,7782,1982/1/23,1300,,10
将此文件保存在hdfs,作为输入文件。
hdfs dfs -put emp.csv /input_emp
(改为自己的文件目录)
1.4 实验步骤
1.4.1 采用IDEA创建一个Maven工程
在本地运行时需要添加以下依赖jar包;若不在本地运行,这里可以不添加依赖,Linux系统布署的hadoop已经有这些jar包了。(注:我的本地windows系统没有安装hadoop,所以并没有在本地运行)
修改pom.xml,增加节点,代码如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.serial</groupId><artifactId>serialsalarytol</artifactId><version>1.0-SNAPSHOT</version><name>serialsalarytol</name><!-- FIXME change it tothe project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.7</maven.compiler.source><maven.compiler.target>1.7</maven.compiler.target></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.7.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.7</version></dependency></dependencies><build><pluginManagement><!-- lock down plugins versions toavoid using Maven defaults (may be moved toparent pom)--><plugins><!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle --><plugin><artifactId>maven-clean-plugin</artifactId><version>3.1.0</version></plugin><!--default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging--><plugin><artifactId>maven-resources-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.0</version></plugin><plugin><artifactId>maven-surefire-plugin</artifactId><version>2.22.1</version></plugin><plugin><artifactId>maven-jar-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-install-plugin</artifactId><version>2.5.2</version></plugin><plugin><artifactId>maven-deploy-plugin</artifactId><version>2.8.2</version></plugin><!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle --><plugin><artifactId>maven-site-plugin</artifactId><version>3.7.1</version></plugin><plugin><artifactId>maven-project-info-reports-plugin</artifactId><version>3.0.0</version></plugin></plugins></pluginManagement></build></project>
1.4.2 自己动手开发Java程序
(1)编写Emplyee.java类,代码如下:
importorg.apache.hadoop.io.Writable;importjava.io.DataInput;importjava.io.DataOutput;importjava.io.IOException;publicclassEmployeeimplementsWritable{privateint empno;privateString ename;privateString job;privateint mgr;privateString hiredate;privateint sal;privateint comm;privateint deptno;@Overridepublicvoidwrite(DataOutput dataOutput)throwsIOException{//案例三:序列化
dataOutput.writeInt(this.empno);
dataOutput.writeUTF(this.ename);
dataOutput.writeUTF(this.job);
dataOutput.writeInt(this.mgr);
dataOutput.writeUTF(this.hiredate);
dataOutput.writeInt(this.sal);
dataOutput.writeInt(this.comm);
dataOutput.writeInt(this.deptno);}@OverridepublicvoidreadFields(DataInput dataInput)throwsIOException{//反序列化this.empno = dataInput.readInt();this.ename = dataInput.readUTF();this.job = dataInput.readUTF();this.mgr = dataInput.readInt();this.hiredate = dataInput.readUTF();this.sal = dataInput.readInt();this.comm = dataInput.readInt();this.deptno = dataInput.readInt();}publicintgetEmpno(){return empno;}publicvoidsetEmpno(int empno){this.empno = empno;}publicStringgetEname(){return ename;}publicvoidsetEname(String ename){this.ename = ename;}publicStringgetJob(){return job;}publicvoidsetJob(String job){this.job = job;}publicintgetMgr(){return mgr;}publicvoidsetMgr(int mgr){this.mgr = mgr;}publicStringgetHiredate(){return hiredate;}publicvoidsetHiredate(String hiredate){this.hiredate = hiredate;}publicintgetSal(){return sal;}publicvoidsetSal(int sal){this.sal = sal;}publicintgetComm(){return comm;}publicvoidsetComm(int comm){this.comm = comm;}publicintgetDeptno(){return deptno;}publicvoidsetDeptno(int deptno){this.deptno = deptno;}}
(2)编写SalaryTotalMapper.java类,并继承父类Mapper,代码如下:
importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjava.io.IOException;publicclassSalaryTotalMapperextendsMapper<LongWritable,Text,IntWritable,Employee>{@Overrideprotectedvoidmap(LongWritable key1,Text value1,Context context)throwsIOException,InterruptedException{//模式匹配String data = value1.toString();//分词String[] words = data.split(",");//创建员工对象Employee e =newEmployee();//设置员工属性
e.setEmpno(Integer.parseInt(words[0]));//员工号
e.setEname(words[1]);//姓名
e.setJob(words[2]);//职位try{
e.setMgr(Integer.parseInt(words[3]));//老板号}catch(Exception ex){
e.setMgr(-1);}
e.setHiredate(words[4]);//入职日期
e.setSal(Integer.parseInt(words[5]));//月薪try{
e.setComm(Integer.parseInt(words[6]));//奖金}catch(Exception ex){
e.setComm(0);}
e.setDeptno(Integer.parseInt(words[7]));//部门号//输出:k2部门号 v2员工对象
context.write(newIntWritable(e.getDeptno()),e);}}
(3)编写SalaryTotalReducer.java类,并继承父类Reducer,代码如下:
importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.mapreduce.Reducer;importjava.io.IOException;publicclassSalaryTotalReducerextendsReducer<IntWritable,Employee,IntWritable,IntWritable>{//对v3中的每个员工进行工资求和@Overrideprotectedvoidreduce(IntWritable k3,Iterable<Employee> v3,Context context)throwsIOException,InterruptedException{int total =0;for(Employee e:v3){
total = total + e.getSal();}
context.write(k3,newIntWritable(total));}}
(4)写主类,让程序能够运行起来,代码如下:
importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importorg.apache.log4j.BasicConfigurator;importjava.io.IOException;publicclassSalaryTotalMain{publicstaticvoidmain(String[] args)throwsException{Job job =Job.getInstance(newConfiguration());
job.setJarByClass(SalaryTotalMain.class);//指定job的mapper和输出类型 k2 v2
job.setMapperClass(SalaryTotalMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Employee.class);//指定job的reducer和输出类型 k4 v4
job.setReducerClass(SalaryTotalReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);//指定job的输入输出的路径FileInputFormat.setInputPaths(job,newPath(args[0]));FileOutputFormat.setOutputPath(job,newPath(args[1]));
job.waitForCompletion(true);}}
以上工作完成之后,打jar包,使用maven时,将以下工作目录改成自己的本地目录。
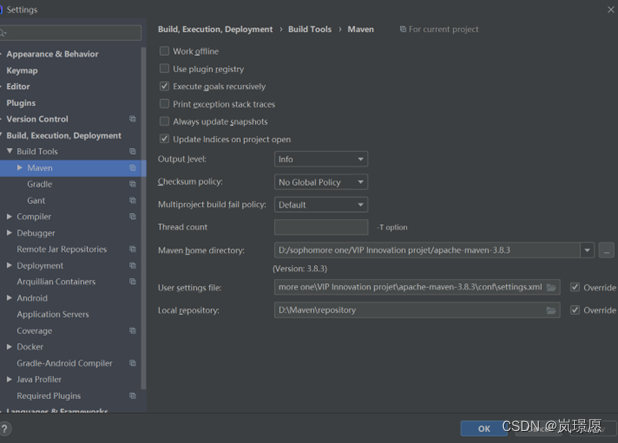
1.4.3 使用maven生命周期package打jar包
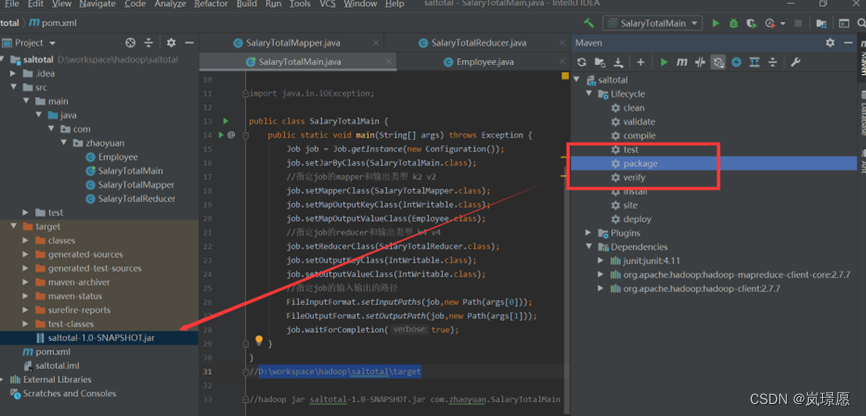
1.4.4 通过xftp将jar包上传到linux系统
1.4.5 在hadoop环境运行jar包
通过命令:**“hadoop jar jar包名 包名.主类名 输入数据文件地址(前面将emp.csv传到HDFS的位置) 输出数据文件地址(自己不用创建,会自动创建,不能重复)”**在linux系统运行。
hadoop jar saltotal-1.0-SNAPSHOT.jar 自己写的包名.SalaryTotalMain /input1_emp /output_emp2
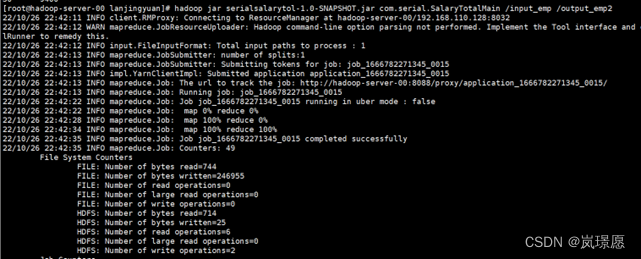
出现map 100% reduce 100%即运行成功。
1.4.6 查看输出结果
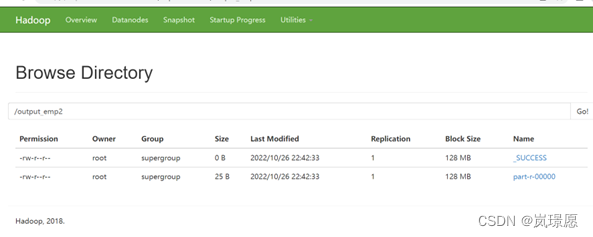

或者直接使用shell命令查看。

1.5 实验中遇到的问题总结
实验过程中遇到了很多问题,不过都解决了,下面是问题小结:
1.5.1 问题描述
(1)emp.csv 数据源导入错误,第一行少了部分数据,导致运行时数据类型转换错误。
(2)Browse Directory 下载输出结果报错。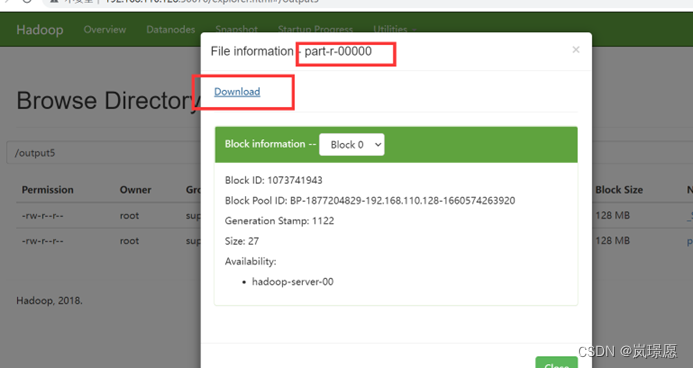
(3)Reducer 处理过程写错了,统计成各部门Mgr(直接领导的员工ID),造成统计数据结果错误。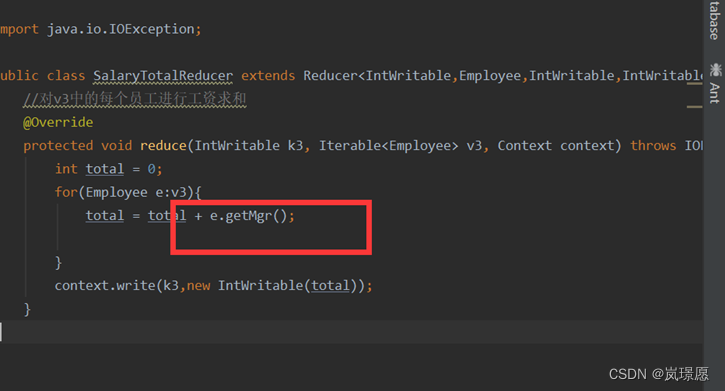

1.5.2 问题分析
当发现输出结果出现偏差时,需要认真检查自己写的程序代码和源数据。
1.5.3 解决方法
(1)Browse Directory 下载输出结果报错,采取了CSDN给出的解决方法:在本地配置主机映射。
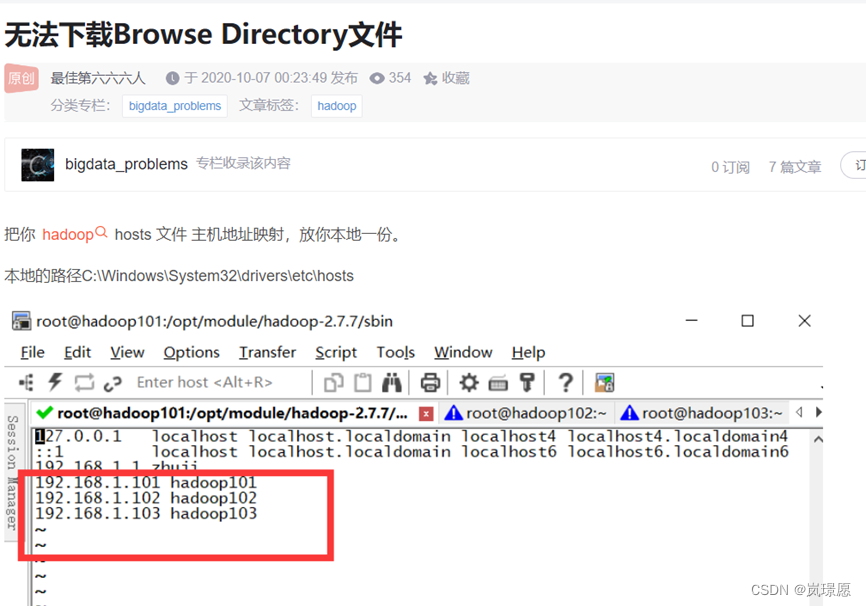
如果还有其它问题,欢迎大家评论交流~~~
本文转载自: https://blog.csdn.net/m0_52331159/article/details/127547970
版权归原作者 桑榆嗯 所有, 如有侵权,请联系我们删除。
版权归原作者 桑榆嗯 所有, 如有侵权,请联系我们删除。