
原文地址:KIP-382: MirrorMaker 2.0 - Apache Kafka - Apache Software Foundation
译者:对于Kafka高可用的课题,我想每个公司都有自己的方案及思考,这是一个仁者见仁智者见智的命题,而社区给出了一个较大的特性,即MirrorMaker 2.0,不论是准备做高可用还是单纯的数据备份,都不能绕过这个重大特性。而关于MirrorMaker 2.0的文章,网络上真是多如牛毛,质量也是参差不齐,而能够将这个特性完整描述出来的,非社区的此篇设计稿莫属,也因此有了翻译此文的初衷。ps: 有任何kafka问题欢迎评论、私信交流。 本人VX: likangning9
背景/动机
MirrorMaker(1.0) 被用在大规模的生产环境已经好多年了,但是其依旧存在一些明显的问题
- Topic在目标集群的创建操作,使用的是默认配置,通常我们需要手动修改其分区
- ACL以及配置信息的变更不会同步至目标集群,这使得管理多集群同步变得非常困难
- 消息使用
DefaultPartitioner策略进行二次分区,分区的语义可能丢失 - 任何配置的修改都需要是双向的。这些操作可能是非常频繁的,例如将topic添加至白名单中
- 没有提供在镜像集群之间迁移producers、consumer的机制
- 没有提供精准一次的支持,在镜像集群拷贝期间,消息记录可能重复
- 集群之间无法做到互为镜像,例如不支持 active/active 模式
- Rebalancing会导致数据延迟,从而触发更多的rebalances
基于上述原因,MirrorMaker(1.0) 不足以满足许多应用场景,包括:数据自动备份、灾难恢复、故障转移等。我们已经写了一些工具来解决其中的一些限制,不过Apache Kafka迄今为止还没有完备的复制策略,此外因为Kafka本身没有提供解决方案,使得多集群的环境构建通用工具变得很困难
我建议使用Connect框架来构建一个新的多集群、跨数据中心的复制引擎MirrorMaker 2.0 (MM2),来取代MirrorMaker(1.0)。新引擎将在许多方面与传统MirrorMaker1.0 有根本的不同,也会替换现有的部署
MM2设计的亮点包括:
- 利用 Kafka Connect 框架和生态系统
- 同时囊括 Source connector 及 Sink connector
- 包括一个高级驱动来管理集群中的connectors
- 自动检测发现新topic、partition
- 在集群中自动同步topic配置
- 管理下游集群中的topic ACL
- 支持 "active/active" 的集群对儿,以及任何数量的active集群
- 支持跨数据中心的复制、聚合和其他复杂拓扑
- 提供新的指标,包括跨多个数据中心/集群的端到端复制延迟等
- 在集群之间发射消费位点(offset),用于consumer的迁移
- 位点(offset)转换工具
- 兼容MirrorMaker(1.0)
- 没有consumer的重平衡操作 译者:使得整个迁移过程更加稳定
公共接口
新类及接口包含:
- MirrorSourceConnector, MirrorSinkConnector, MirrorSourceTask, MirrorSinkTask
- MirrorCheckpointConnector, MirrorCheckpointTask
- MirrorHeartbeatConnector, MirrorHeartbeatTask.
- MirrorConnectorConfig, MirrorTaskConfig classes.
- ReplicationPolicy interface. DefaultReplicationPolicy and LegacyReplicationPolicy classes.
- Heartbeat, checkpoint, offset sync topics and associated schemas.
- RemoteClusterUtils and MirrorClient classes 用来查询远端集群的可达性及消息滞后值, 以及用于在两个集群之间传递消费偏移量
- MirrorMaker 驱动类,里面存放了main方法
- MirrorMakerConfig used by MirrorMaker driver.
- HeartbeatMessageFormatter, CheckpointMessageFormatter
- ./bin/connect-mirror-maker.sh and ./config/mirror-maker.properties 可参考的配置样例
新指标包含
- replication-latency-ms(-avg/-min/-max): timespan between each record's timestamp and downstream ACK
- record-bytes(-avg/-min/-max): size of each record being replicated
- record-age-ms(-avg/-min/-max): age of each record when consumed
- record-count: number of records replicated
- checkpoint-latency-ms(-avg/-min/-max): timestamp between consumer group commit and downstream checkpoint ACK
这些指标的key将会为
kafka.mirror.connect:type=MirrorSourceConnect,target=([.\w]+),topic=([.\w]+),partition=([.\d]+)
或
kafka.mirror.connect:type=MirrorCheckpointConnector,target=([.\w]+),source=([.\w]+),group=([.\w]+)
提议变更
远端Topics、Partition
此设计引入了远端topics的概念,远端topics指通过将source集群中的topic加上其集群的名称作为前缀而定义的。例如远端topic:
us-west.topic1
topic1
指的是source集群中的topic的命名,而
us-west
指的是source集群的别名。
而远端topic中的任何partition,均为远端partition,且与source topic拥有相同的partition:
- source topic 与 remote topic 有着相同的分区以及同序的消息记录
- source topic 与 remote topic 它们的partition一致
- 一个远端topic只对应以一个source topic
- 一个远端partition只对应一个source partition
- 远端partition i 就是source partition i 的副本
MM2将topics从source cluster拷贝至对应的目标集群中,这样,复制就不会导致partition合并或无序。此外,topic的重命名策略默认启动"active/active"进行复制:
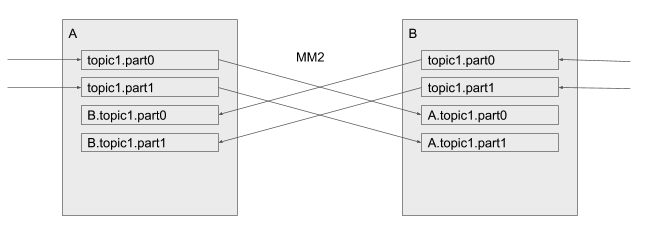
"active/active" replication
MirrorMaker1.0 并不支持此功能(没有自定义处理器)-- 消息记录将会被无限期地来回复制,并且在集群中传递的这些topic将会被不一致地进行合并。MM2通过将远端topic进行重命名从而达到区分本地及远端记录来避免这些问题。在上述的任何一个集群中,topic1中只包含本地生产的消息,而同样的B.topic1中则只会包含集群B生产的消息。
译者:此处需要留意了,只有本地集群的producer才能向本地topic中写入消息,而这个topic如果被拷贝至了远端topic,那么远端topic中的消息也只会有source集群的消息记录,这点保证了消息的一致性,MM2不会对消息进行归并
同样的,consumer也只会消费本地集群的消息,它们就像平时一样去订阅topic。如果它们想订阅一个远端集群的topic,consumer需要订阅远端topic,例如 B.topic1
此约定可扩展适用于任意数量的集群
聚合(Aggregation)
下游集群的consumers可以通过同时订阅本地topic及对应多个远端topic来实现消息的聚合。而订阅远端topic可使用正则表达式或者添加前缀的方式,例如:topic1, us-west.topic1, us-east.topic1…
Topics永远都不会被合并或者重新分配partition,相反,合并操作是放在了consumer端。这与MirrorMaker1.0 形成了鲜明的对比,MirrorMaker1.0 习惯性地将多个集群topic的数据合并为一个
同样地,consumer完全可以通过只消费local topic的方式来选择不聚合,例如只消费topic1
这种方式消除了特定目的的集群聚合功能,但是却没有丢失任何能力及稳定性
循环检测
将两个集群配置为相互拷贝的模式(active/active)是可行的,在这种模式下,所有的消息记录会同时存在于2个集群中,从而均可被consumer看到。为了防止无限递归,带有“us-west”前缀的topic将不会被拷贝至us-west集群中
这个规则适用于所有的topic而不考虑拓扑结构。一个集群可能会被拷贝至多个下游的集群,它们可能会被继续拷贝,从而产生诸如
us-west.us-east.topic1
这样的topic。由于循环检测,相同的集群别名不会在topic中出现两次
采用这种模式的话,任何一种集群的拓扑结构都能支持,不局限于DAG结构
配置、ACL同步
MM2的监视器将会一直监视源集群中的topic,源集群topic的任何变化,将会被传播至远端topic中,而任何丢失的分区也会被自动创建
远端topic除了被 source connector 或 sink connector 写入外,不应该被其他程序写入任何消息。译者:其实也就是保证远端topic中的消息跟源topic的消息是一模一样的 Producers也只能将消息写入至本地topic中,然后这个topic的消息可能会被MM2复制到其他任何一个集群。为了强制执行这个策略,MM2向下游的集群的topic中设置了ACL的策略:
- 可以读取源topic,那么也就可以读取远端topic
- 除了MM2,没有人可以将消息写入至远端topic中
内置Topics
heartbeat topic
MM2向每个源集群中发射了一个内置的心跳topic(heartbeat topic),这个topic将会被MM2进行复制,以展示连通性。下游的consumers可以使用这个topic做如下验证:
- MM2在工作
- 对应的源集群可达
心跳通过 source connector 及 sink connector 连接传播,诸如像
backup.us-west.us-east.heartbeat
这样的链是可能存在的。循环检测防止无限递归

heartbeats topic 在2个集群中的流转
heartbeats topic 的元数据包含:
- target cluster (String): 发出心跳的集群
- source cluster (String): 执行发射动作的connector(MM2)对应的源集群
- timestamp (long): 心跳消息生成的时间戳
checkpoints topic
此外,connectors会定期在目标集群发出checkpoints,checkpoints包含源集群中每个group对应的消费位点。connectors会定期查询源集群中的所有group对应的已提交位点,然后只保留那些需要复制给目标集群的topic,然后在目标集群中发射消息,topic的名称诸如
us-west.checkpoints.internal
。消息体包含如下字段:
- consumer group id (String)
- topic (String) – 包含源集群的前缀
- partition (int)
- upstream offset (int): 源集群中最近一次提交的位点
- downstream offset (int): 源集群最近一次提交的位点其对应的目标集群的位点
- metadata (String)
- timestamp
与
__consumer_offsets
类似,checkpoints topic的类型也是compacted的,只会保留最近一次位点提交的记录,其使用的组合key为
topic-partition-group
。如果这个topic不存在的话,那么会被connectors自动创建
offset sync topic
最后,是一个 offset sync 的topic,它主要存储了集群---集群之间partition的位点映射,这个topic存储的消息内容包括
- topic (String): 远端topic的名称
- partition (int)
- upstream offset (int): 源集群的位点信息
- downstream offset (int): 目标集群中对应的位点
译者:topic进行复制的时候,目标集群对应的topic的offset并不会同步复制于源集群,而是会将其当做一个全新的topic进行存储,这样的话就可能存在源topic的offset与目标集群的offset不一致,还好有这个内置topic让我们可以将2个集群的位点信息进行映射关联
与
__consumer_offsets
类似,heartbeat、checkpoint、 offset sync 这3个topic的定义如下:
public class Checkpoint {
public static final String TOPIC_KEY = "topic";
public static final String PARTITION_KEY = "partition";
public static final String CONSUMER_GROUP_ID_KEY = "group";
public static final String UPSTREAM_OFFSET_KEY = "upstreamOffset";
public static final String DOWNSTREAM_OFFSET_KEY = "offset";
public static final String METADATA_KEY = "metadata";
--->%---
public Checkpoint(String consumerGroupId, TopicPartition topicPartition, long upstreamOffset,
long downstreamOffset, String metadata) ...
public String consumerGroupId() ...
public TopicPartition topicPartition() ...
public long upstreamOffset() ...
public long downstreamOffset() ...
public String metadata() ...
public OffsetAndMetadata offsetAndMetadata() ...
--->%---
public class Heartbeat {
public static final String SOURCE_CLUSTER_ALIAS_KEY = "sourceClusterAlias";
public static final String TARGET_CLUSTER_ALIAS_KEY = "targetClusterAlias";
public static final String TIMESTAMP_KEY = "timestamp";
--->%---
public Heartbeat(String sourceClusterAlias, String targetClusterAlias, long timestamp) ...
public String sourceClusterAlias() ...
public String targetClusterAlias() ...
public long timestamp() ...
--->%---
public class OffsetSync {
public static final String TOPIC_KEY = "topic";
public static final String PARTITION_KEY = "partition";
public static final String UPSTREAM_OFFSET_KEY = "upstreamOffset";
public static final String DOWNSTREAM_OFFSET_KEY = "offset";
--->%---
public OffsetSync(TopicPartition topicPartition, long upstreamOffset, long downstreamOffset) ...
public TopicPartition topicPartition() ...
public long upstreamOffset() ...
public long downstreamOffset() ...
远端集群工具
工具类
RemoteClusterUtils
将会利用上述内置topic的信息来计算可达性、集群同步的积压情况以及offset位点的转换。不过它不可能转换任意给定的位点信息,因为在数据流转中,并不会捕获全量的位点信息。不过对于一个指定的consumer group来说,找到HW(high water mark)肯定是没问题的。这点对于集群间consumer的迁移、故障切换等是非常有用的
接口部分方法如下
// Calculates the number of hops between a client and an upstream Kafka cluster based on replication heartbeats.
// If the given cluster is not reachable, returns -1.
int replicationHops(Map<String, Object> properties, String upstreamClusterAlias)
// Find all heartbeat topics, e.g. A.B.heartbeat, visible from the client.
Set<String> heartbeatTopics(Map<String, Object> properties)
// Find all checkpoint topics, e.g. A.checkpoint.internal, visible from the client.
Set<String> checkpointTopics(Map<String, Object> properties)
// Find all upstream clusters reachable from the client
Set<String> upstreamClusters(Map<String, Object> properties)
// Find the local offsets corresponding to the latest checkpoint from a specific upstream consumer group.
Map<TopicPartition, OffsetAndMetadata> translateOffsets(Map<String, Object> properties,
String targetClusterAlias, String consumerGroupId, Duration timeout)
不过需要注意,这个工具是以 DefaultReplicationPolicy 传输策略作为基础的,如果备份策略不是它,那么这个工具也就不能使用
MirrorClient
RemoteClusterUtils
工具类其实是包装了MirrorClient,它的一些方法如下
MirrorClient(Map<String, Object> props) ...
void close() ...
ReplicationPolicy replicationPolicy() ...
int replicationHops(String upstreamClusterAlias) ...
Set<String> heartbeatTopics() ...
Set<String> checkpointTopics() ...
// Finds upstream clusters, which may be multiple hops away, based on incoming heartbeats.
Set<String> upstreamClusters() ...
// Find all remote topics on the cluster
Set<String> remoteTopics() ...
// Find all remote topics from the given source
Set<String> remoteTopics(String source) ...
// Find the local offsets corresponding to the latest checkpoint from a specific upstream consumer group.
Map<TopicPartition, OffsetAndMetadata> remoteConsumerOffsets(String consumerGroupId,
String remoteClusterAlias, Duration timeout) ...
复制策略及过滤器
所谓复制策略,其实就是需要定义什么是远端topic,以及如何解释它。这个策略应该在一个组织中应该是保持一致的
/** Defines which topics are "remote topics", e.g. "us-west.topic1". */
public interface ReplicationPolicy {
/** How to rename remote topics; generally should be like us-west.topic1. */
String formatRemoteTopic(String sourceClusterAlias, String topic);
/** Source cluster alias of given remote topic, e.g. "us-west" for "us-west.topic1".
Returns null if not a remote topic.
*/
String topicSource(String topic);
/** Name of topic on the source cluster, e.g. "topic1" for "us-west.topic1".
Topics may be replicated multiple hops, so the immediately upstream topic
may itself be a remote topic.
Returns null if not a remote topic.
*/
String upstreamTopic(String topic);
/** The name of the original source-topic, which may have been replicated multiple hops.
Returns the topic if it is not a remote topic.
*/
String originalTopic(String topic);
/** Internal topics are never replicated. */
boolean isInternalTopic(String topic);
}
默认的复制策略DefaultReplicationPolicy将本文档中的定义使用<source>.<topic>这样的描述转换过来。而LegacyReplicationPolicy则模仿MM1的行为
此外,有几个过滤器在高级别上控制了MM2的行为,包括哪些topics应该被复制。
DefaultTopicFilter
、
DefaultGroupFilter
、
DefaultConfigPropertyFilter
这几个类通过正则表达式支持白名单、黑名单的模式
/** Defines which topics should be replicated. */
public interface TopicFilter {
boolean shouldReplicateTopic(String topic);
}
/** Defines which consumer groups should be replicated. */
public interface GroupFilter {
boolean shouldReplicateGroup(String group);
}
/** Defines which topic configuration properties should be replicated. */
public interface ConfigPropertyFilter {
boolean shouldReplicateConfigProperty(String prop);
}
MirrorMaker Clusters
演练:运行MirrorMaker 2.0
有4种方式可以运行MM2
- 作为专用的 MM2 集群运行
- 作为分布式connect集群中的连接器
- 作为一个独立的Connect进行工作
- 使用现有MirrorMaker脚本,兼容运行MM1
运行专用的 MM2 集群
在这种模式下,MM2并不需要一个已有的connect集群,相反,用一个高级的驱动程序来管理一组connect工作器
首先,指定kafka集群的相关配置信息
# mm2.properties
clusters = us-west, us-east
us-west.bootstrap.servers = host1:9092
us-east.bootstrap.servers = host2:9092
可以覆写默认的MM2配置信息
topics = .*
groups = .*
emit.checkpoints.interval.seconds = 10
同时可覆写指定的集群及connectors
us-west.offset.storage.topic = mm2-offsets
us-west->us-east.emit.heartbeats.enabled = false
然后可以启动一个或多个MM2节点
$ ./bin/connect-mirror-maker.sh mm2.properties
兼容性、弃用及迁移计划
略
未来工作
- 将RemoteClusterUtils的功能命令行化,记录跨集群迁移过程
- Broker及Consumer支持明确的远端topic命名
- 增加复制工作相关的一些指标
- 支持不重启修改配置
- 精准一次语义支持
- 防止重复流,出现菱形问题
被拒的备选方案
略
版权归原作者 昔久 所有, 如有侵权,请联系我们删除。