
1.2 同步发送
一、前言
为了避免出现消息丢失从而造成巨大的损失,有如下方法可以最大限度避免消息的丢失
在避免出现消息丢失情况出现之前,首先要知道kafka消息发送和接受过程,才能更加清楚的知道消息丢失的原因,从而避免
二、kafka消息发送与接收的过程
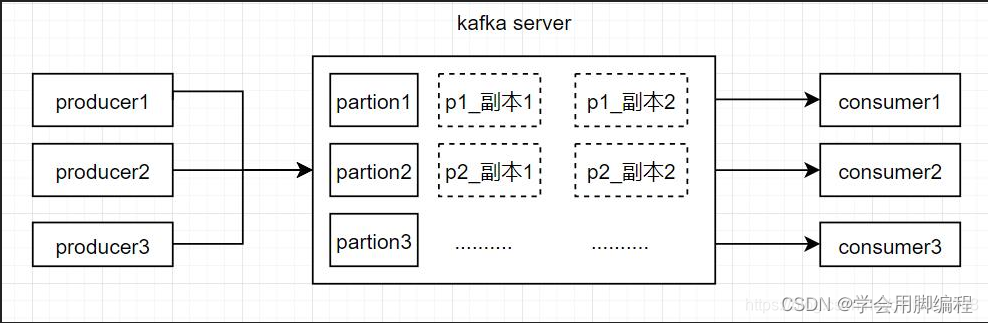
1、kafka 在producer 端产生消息,调用kafka producer client send方法发送消息
2、kafka producer client 使用一个单独的线程,异步的将消息发送给kafka server
3、kafka server收到消息以后,保存数据,并同步至副本
4、消息保存完成以后,返回给kafka producer client 端 【消息发送成功】
5、kafka consumer client 调用poll 方法,循环 从kafka server 端获取消息列表
6、kafka consumer 端 从kafka server获取到消息以后,开始消费消息
7、kafka consumer 消费消息完毕以后,向kafka server(topic为 _offset_consumer的消息队列) 发送偏移量
在上述的整个流程中,消息丢失的情况分为以几种可能性:
1、producer 端 发送消息给kafka server 端,中间网络出现问题,消息无法送达
2、kafka server端 在收到消息以后,保存消息时发生异常,异常分为三种
(1)可重试错误,通过重试来解决
(2) 网络连接错误
(3)无主(no leader)错误
3、consumer 在消费消息时发生异常,导致consumer端消费失败
注:当然这里还可能发生另一种错误,就是在producer发送消息到kafka server端时,消息体过大,producer client 直接抛出异常,导致发送失败
如何解决
1、producer 端的发送方式优化
我们先来了解一下,producer端发送消息的方式:
1.1 简单发送,无需关心结果
ProducerRecord<String,String> record = new ProducerRecord<>(
"topicName","key","value"
);
try{
//这里只是把消息放进了一个缓冲区中,然后使用单独的线程将消息发送到服务端
producer.send(record);
}
catch(Exception){
e.printStackTrace();
}
1.2 同步发送
ProducerRecord<String,String> record = new ProducerRecord<>(
"topicName","key","value"
);
try{
//send方法返回的是Future<RecordMetaData> 对象,然后我们可以调用get()方法等待响应
Future<RecordMetaData> future = producer.send(record);
future.get();
}
catch(Exception){
e.printStackTrace();
}
1.3 异步发送
private class DemoProducerCallback implements Callback{
@override
public void onCompletion(RecordMetadata recordMetadata,Exception e){
//发生错误的回调方法,可以写入日志,或写入DB通过其它线程重重试,保证最终的数据送达
}
}
ProducerRecord<String,String> record = new ProducerRecord<>(
"topicName","key","value"
);
producer.send(record,new DemoProducerCallback()))
总结:从以上的三种发送方式中,我们可以知道,采用第一种方式发送时,消息丢失时我们的应用程序是无感知的,如果需要保证消息的不丢失,那么必须要选择第二种或者第三种(需要配合下一节中讲到的acks 参数),当然这里更推荐第三方种方式。
ACK
什么是ack
如果要想理解这个acks参数的含义,首先就得搞明白kafka的高可用架构原理。
比如下面的图里就是表明了对于每一个Topic,我们都可以设置他包含几个Partition,每个Partition负责存储这个Topic一部分的数据。
然后Kafka的Broker集群中,每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上。
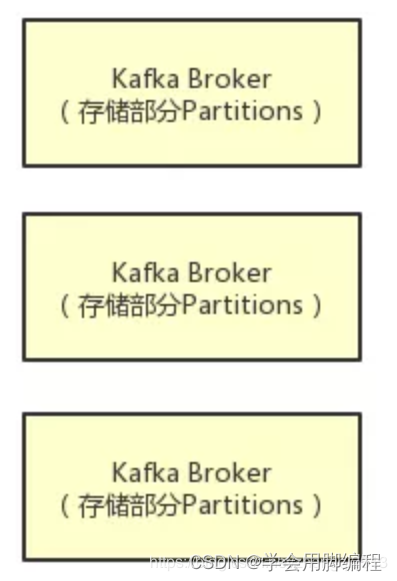
但是有一个问题,万一 一个Kafka Broker宕机了,此时上面存储的数据不就丢失了吗?
没错,这就是一个比较大的问题了,分布式系统的数据丢失问题,是他首先必须要解决的,一旦说任何一台机器宕机,此时就会导致数据的丢失。
(2)多副本冗余的高可用机制
所以如果大家去分析任何一个分布式系统的原理,比如说zookeeper、kafka、redis cluster、elasticsearch、hdfs,等等,其实他都有自己内部的一套多副本冗余的机制,多副本冗余几乎是现在任何一个优秀的分布式系统都一般要具备的功能。
在kafka集群中,每个Partition都有多个副本,其中一个副本叫做leader,其他的副本叫做follower,如下图。
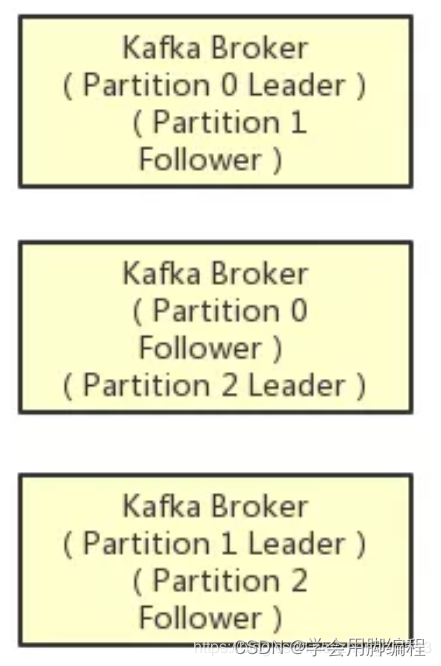
如上图所示,假设一个Topic拆分为了3个Partition,分别是Partition0,Partiton1,Partition2,此时每个Partition都有2个副本。
比如Partition0有一个副本是Leader,另外一个副本是Follower,Leader和Follower两个副本是分布在不同机器上的。
这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。
(3)多副本之间数据如何同步?
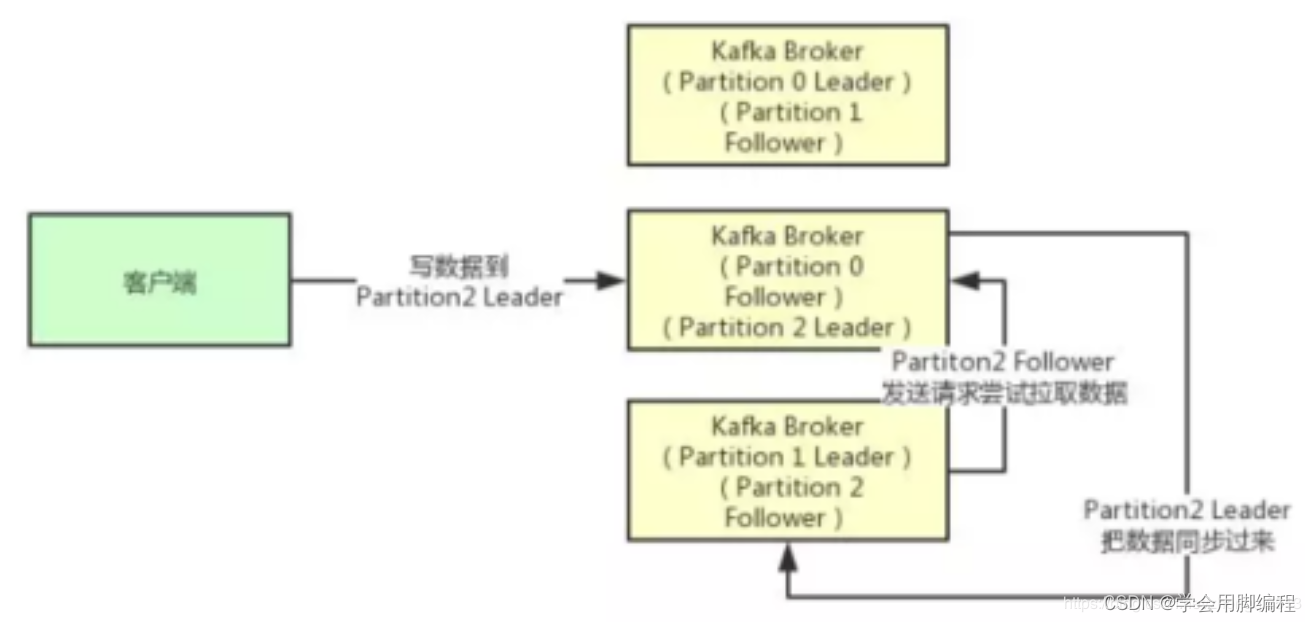
接着我们就来看看多个副本之间数据是如何同步的?其实任何一个Partition,只有Leader是对外提供读写服务的
也就是说,如果有一个客户端往一个Partition写入数据,此时一般就是写入这个Partition的Leader副本。
然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。如下图所示:
(4)ISR到底指的是什么东西?
既然大家已经知道了Partiton的多副本同步数据的机制了,那么就可以来看看ISR是什么了。
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。
大家可以想一下 ,如果说某个Follower所在的Broker因为JVM FullGC之类的问题,导致自己卡顿了,无法及时从Leader拉取同步数据,那么是不是会导致Follower的数据比Leader要落后很多?
所以这个时候,就意味着Follower已经跟Leader不再处于同步的关系了。但是只要Follower一直及时从Leader同步数据,就可以保证他们是处于同步的关系的。
所以每个Partition都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的Follower,也会在ISR里。
(5)acks参数的含义
铺垫了那么多的东西,最后终于可以进入主题来聊一下acks参数的含义了。
如果大家没看明白前面的那些副本机制、同步机制、ISR机制,那么就无法充分的理解acks参数的含义,这个参数实际上决定了很多重要的东西。
首先这个acks参数,是在KafkaProducer,也就是生产者客户端里设置的
也就是说,你往kafka写数据的时候,就可以来设置这个acks参数。然后这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
第一种选择是把acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。
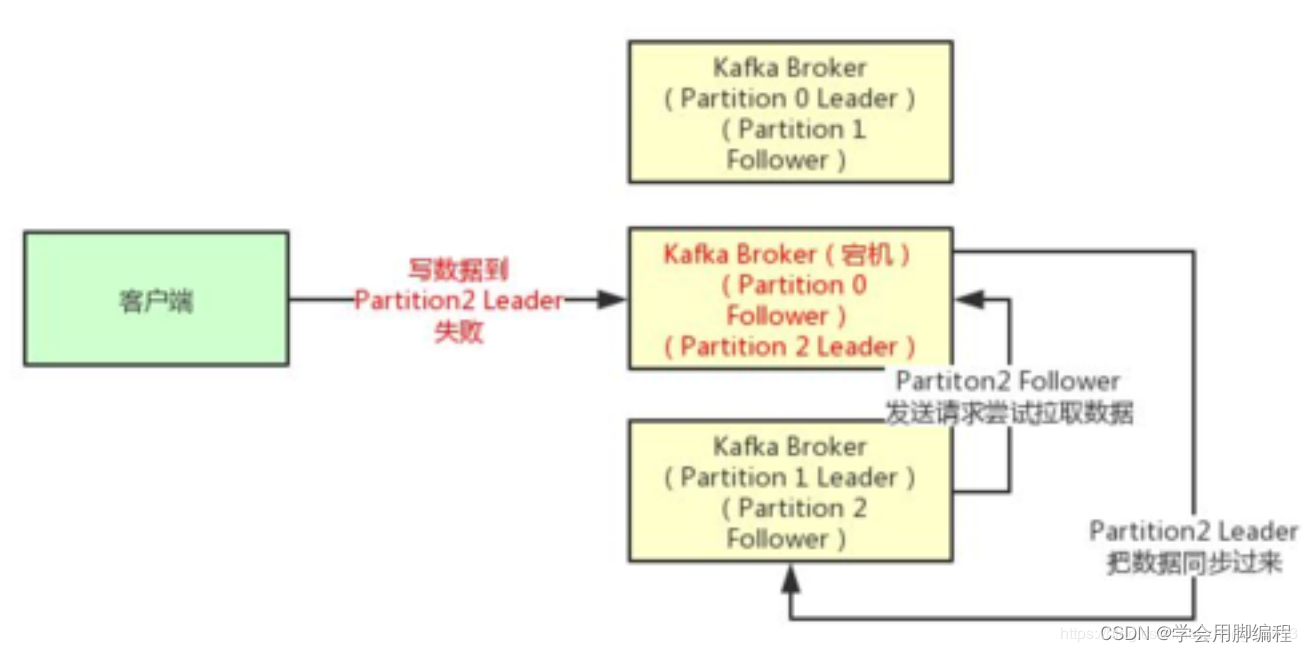
第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
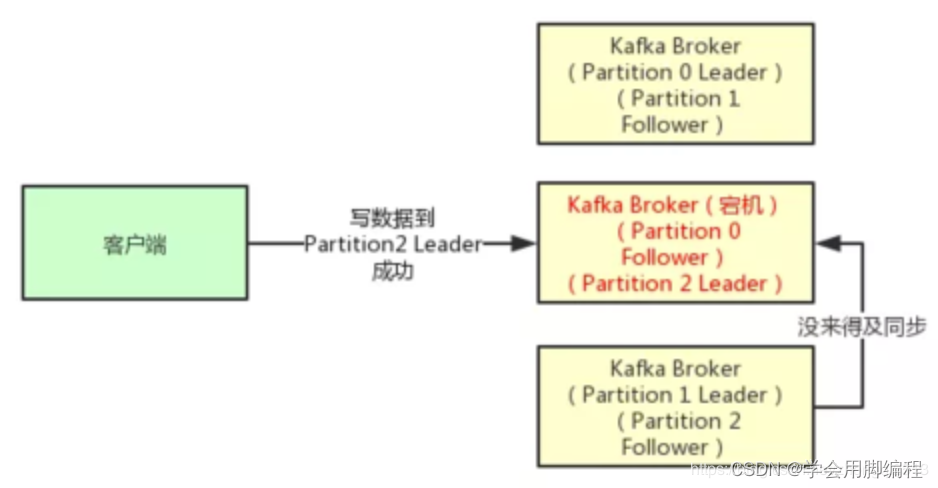
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
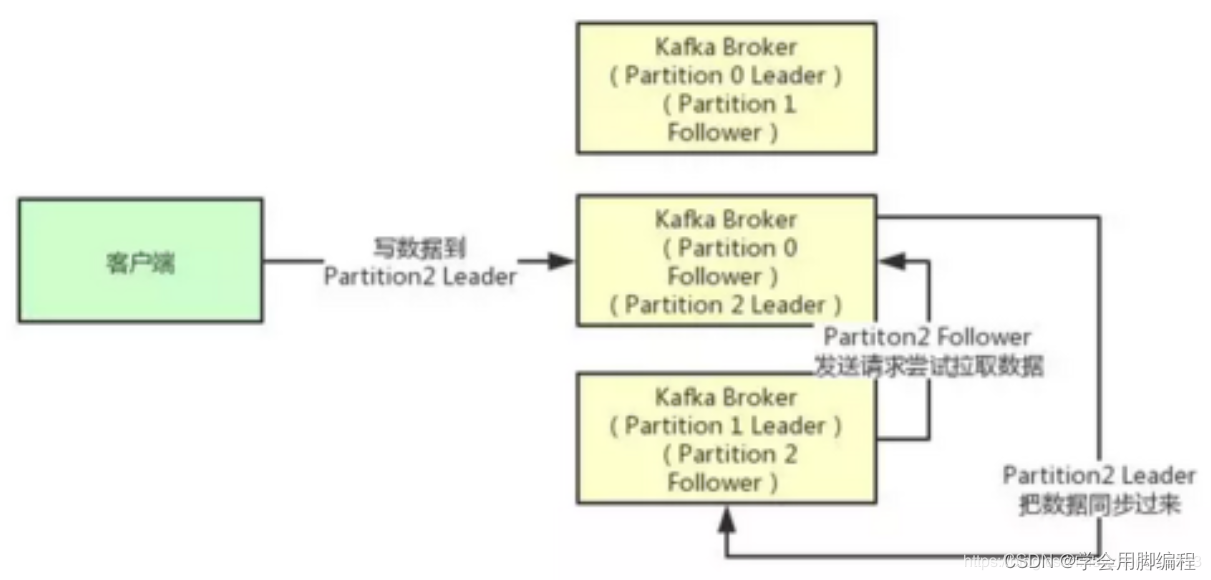
最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了。
(6)最后的思考
acks=all 就可以代表数据一定不会丢失了吗?
当然不是,如果你的Partition只有一个副本,也就是一个Leader,任何Follower都没有,你认为acks=all有用吗?
当然没用了,因为ISR里就一个Leader,他接收完消息后宕机,也会导致数据丢失。
所以说,这个acks=all,必须跟ISR列表里至少有2个以上的副本配合使用,起码是有一个Leader和一个Follower才可以。
这样才能保证说写一条数据过去,一定是2个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。
所以希望大家把这篇文章好好理解一下,对大家出去面试,或者工作中用kafka都是很好的一个帮助。
buffer.memory:生产端 缓冲区的大小设置
compression type:生产端采用的数据压缩方式,取值 snappy,gzip,lz4,默认不会压缩。(启用压缩意味着,需要producer 和kafka server要占用更多的cpu资源)
retries:生产端发送消息到kafka server时,发生临时性错误以后,生产者发送消息到kafka server端重试的次数。如果重试超过该次数,则发生异常
batch.size: 当多个消息被发送至同一分区时,生产者会把它们发送到同一批。该参数指定了同一批次可以使用的内存大小,按字节数计算(而不是消息条数)。
linger.ms:该参数指定了生产者在发送批次之前等待更多消息加入批次的时间,producer client 会在批次填满(batch.size) 或linger.ms 到上限时,将消息发送至kafka server.
max.in.flight.requests.per.connection:该参数指定了生产者在收到kafka server 的成功响应之前,可以发送多少消息。(可以利用该配置让kafka server中的消息变得有序)
max.request.size:该参数用来控制生产者发送单个请求的数据大小。对于消费端也有相同的配置(message.max.bytes),建议两边设置相同。
总结:我们的问题,可以通过设置配置项 acks 、retries 来保证数据的不丢失。acks=1时,lead节点只要收到消息就会告诉producer消息接收成功,假如此时lead 挂掉了开始重新选主,选主成功后之前lead收到的那条消息就会丢失,如果需要保证消息的绝对不丢失,建议设置 acks =all
3、kafka server
这里需要补充一个知识点,kafka的server端同一个topic下有多个分区,单个分区会有不同的副本。如果producer 发送消息么kafka server端,leader收到了消息以后,告诉producer 发送成功,此时再同步消息到多个副本,但由于某一个副本同步较慢,此时leader挂了,需要选主,选主的过程中,一旦那个较慢的副本成为新的leader,那么新的leader中就不包含了原leader收到的那条最新数据,导致消息丢失。
broker中的配置项,unclean.leader.election.enable = false,表示不允许非ISR中的副本被选举为首领,以免数据丢失。
ISR:是指与leader保持一定程度(这种范围是可通过参数进行配置的)同步的副本和 leader 共同被称为ISR
OSR:与leader同步时,滞后很多的副本(不包括leader)被称为OSR
AR,分区中所有的副本统称为AR。AR = ISR + OSR
4、kafka consumer端的优化
kafka consumer的配置中,默认的enable.auto.commit = true,表示在kafka consumer 通过poll方法 获取到消息以后,每过5秒(通过配置项可修改)会自动获取poll中得到的最大的offset, 提交给kafka server 中的_offset_consumer(存储 offset 的特定topic )
如果enable.auto.commit = false时,则关闭了自动提交,你可以手动的通过应用程序代码进行提交,这里我来梳理一下,consumer 消费消息的整个流程
consumer端循环向kafka server请求获取信息
如果kafka server中的分区中没有消息,则阻塞指定秒数(consumer端配置)后,返回给consumer端
如果 kafka server中有消息 或是在阻塞等待的过程中有消息写入,则立即返回给consumer端
consumer开始消费消息
consumer消费消息完毕以后,提交偏移量到topic为 _offset_consumer(kafka server端) 的消息队列
我们来看一下,enale.auto.commit = false时,如何手动提交的
public void consumerMsg(){
while(true){
//这里的poll(100)指的是kafka server端没有消息时,连接等待的时间,超过该时间立即返回空给consumer
ConsumerRecords<String,String> records = consomer.poll(100);
for(ConsumerRecord<String,String> record : records){
// 这里是消费消息的逻辑(简单逻辑输入到控制台)
System.out.printIn(record.value));
//提交偏移量
try{
consumer.commitSync(); //同步提交 如果异步的话,可以使用 consumer.commitAsync();
}
catch(CommitFailedException ex){
log.error("commit fail");
}
}
}
}
consumer端消息丢失的情况分为两种:
consumer 端启用了 enable.auto.commit= true,在消费消息时发生了异常
consumer 端 enable.auto.commit= false,但是在消息消费之前,提交了offset
针对这两种丢失的情况,我们做以下处理:
1、设置 enable.auto.commit = false
2、在consumer端消费消息操作完成以后 再提交 offset,类似于上文中的代码示例
写在最后:
以上的我们从producer 、 kafka server、 consumer 端出发,通过相关的优化手段保证消息的不丢失,当然业界还有一些其它的办法,比如在三种 send 的 调用方式中,callback时将消息写入到mysql 或日志中,当consumer 消费消息成功以后,我们从mysql 或 日志中删除消息,未成功消费的消息,可以启动一个线程,将消息重新入队让consumer收到消息以后重新消费(rabbit mq中 可以 利用死信队列和备用交换机来完成)
版权归原作者 学会用脚编程 所有, 如有侵权,请联系我们删除。