
自动化爬虫Selenium
这篇文章, 我们将要学习自动化爬虫的知识啦。
目录
1.Selenium的基本操作
2.用Selenuim获取数据
3.当当网数据获取
4.实战
一、Selenium的基本操作
首先, 我们在使用Selenium之前, 需要做两件事情。第一件事情, 就是安装第三方库, 第二件事情, 就是下载对应的驱动。
1.安装第三方库:
pip install selenium==4.0.0
2.下载对应驱动
每个浏览器的驱动, 都不一样, 要看自己一会儿用的是什么浏览器进行自动化爬虫。
edge:
https://developer.microsoft.com/zh-cn/microsoft-edge/tools/webdriver?form=MA13LH
谷歌:
https://registry.npmmirror.com/binary.html?path=chrome-for-testing/
火狐:
https://github.com/mozilla/geckodriver/releases
那我们这边, 就以谷歌浏览器为例。
我们需要先知道我们谷歌浏览器的版本, 点击右上角三个点的地方。
再找到帮助, 再点开关于Google Chrome。
然后再找到关于里面的信息, 里面就有写着版本号。
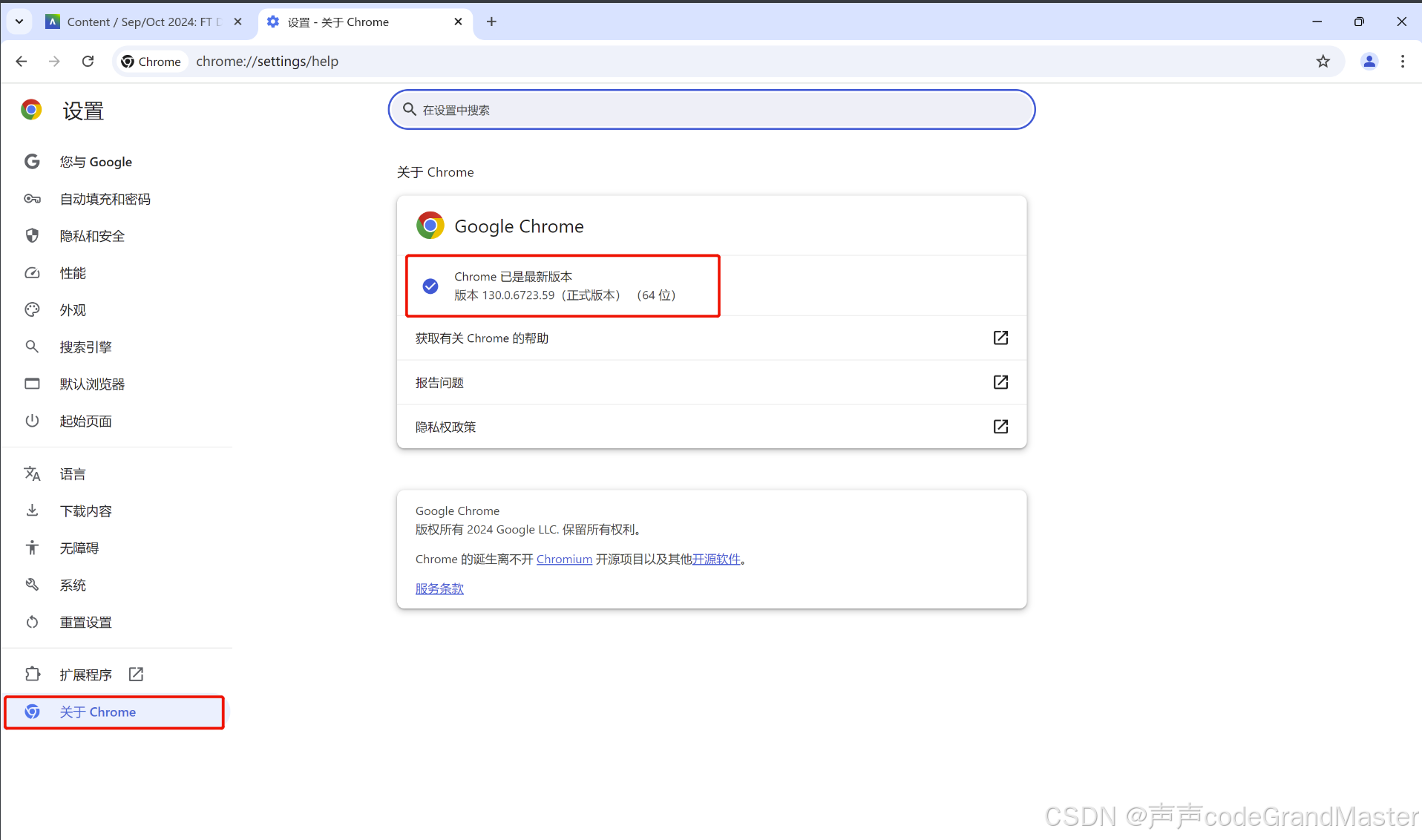
我的浏览器的版本号是130.0.6723.59。
那我们打开谷歌浏览器需要的自动化爬虫的驱动。
url是https://registry.npmmirror.com/binary.html?path=chrome-for-testing/
然后我们快捷键Ctrl+F, 快速搜索, 然后输入130.0.6723
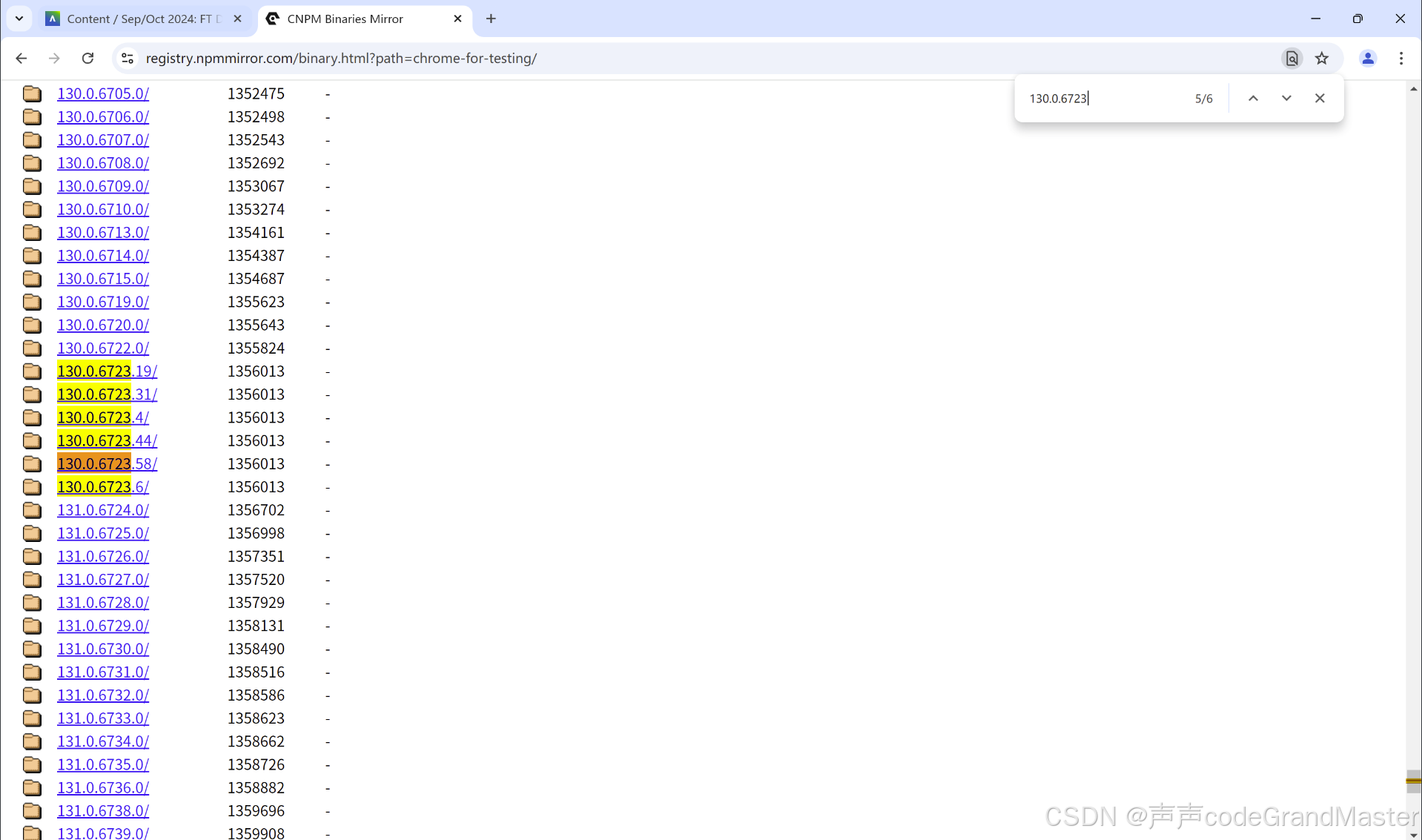
找到和我们浏览器版本号最靠近的。那我这里选择130.0.6723.58这个版本号。
我们点进去:
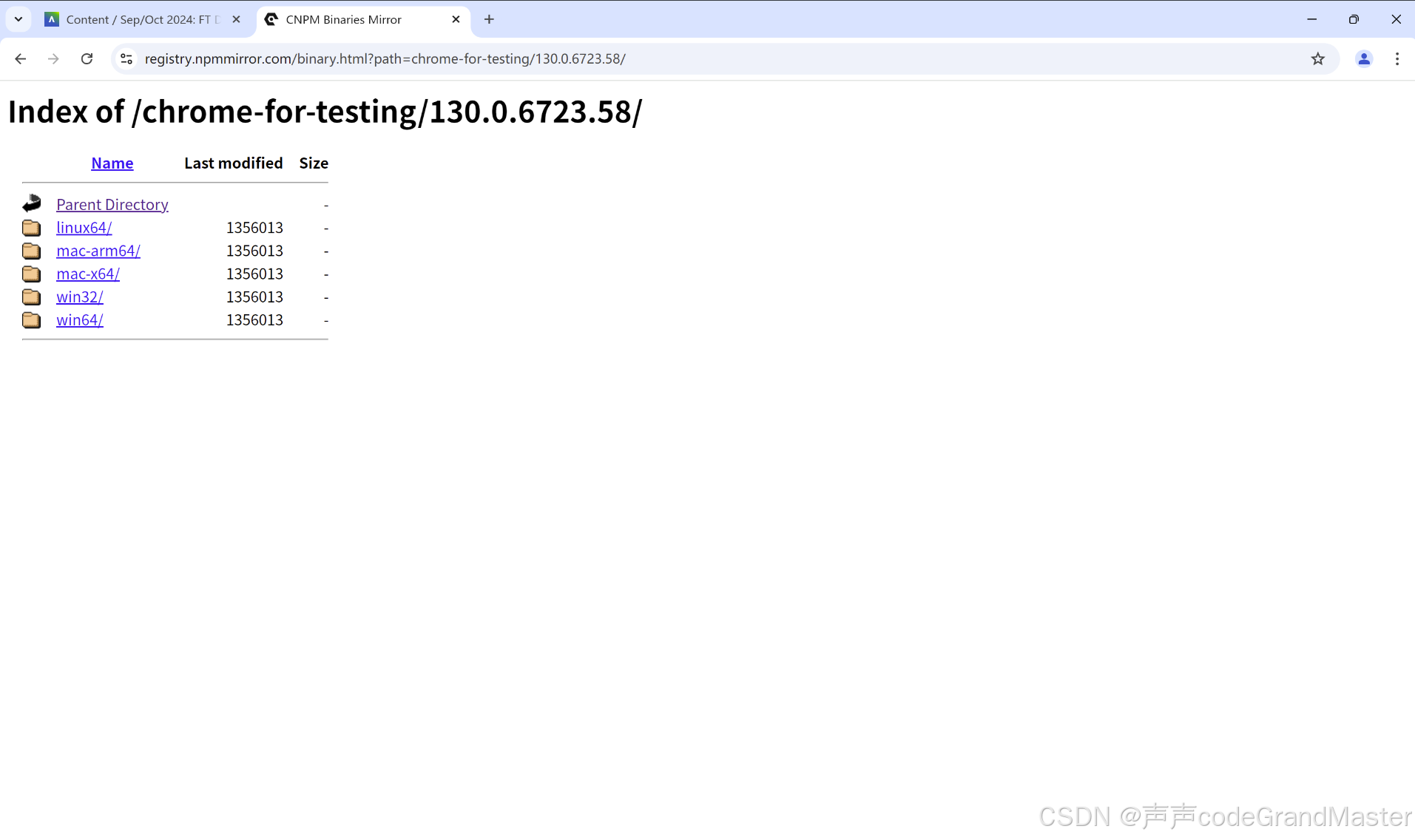
然后这里, 就按照自己电脑的操作系统来决定到底选择哪个驱动。
我是windows11电脑, 64位, 所以这里我们点击最下面的win64。
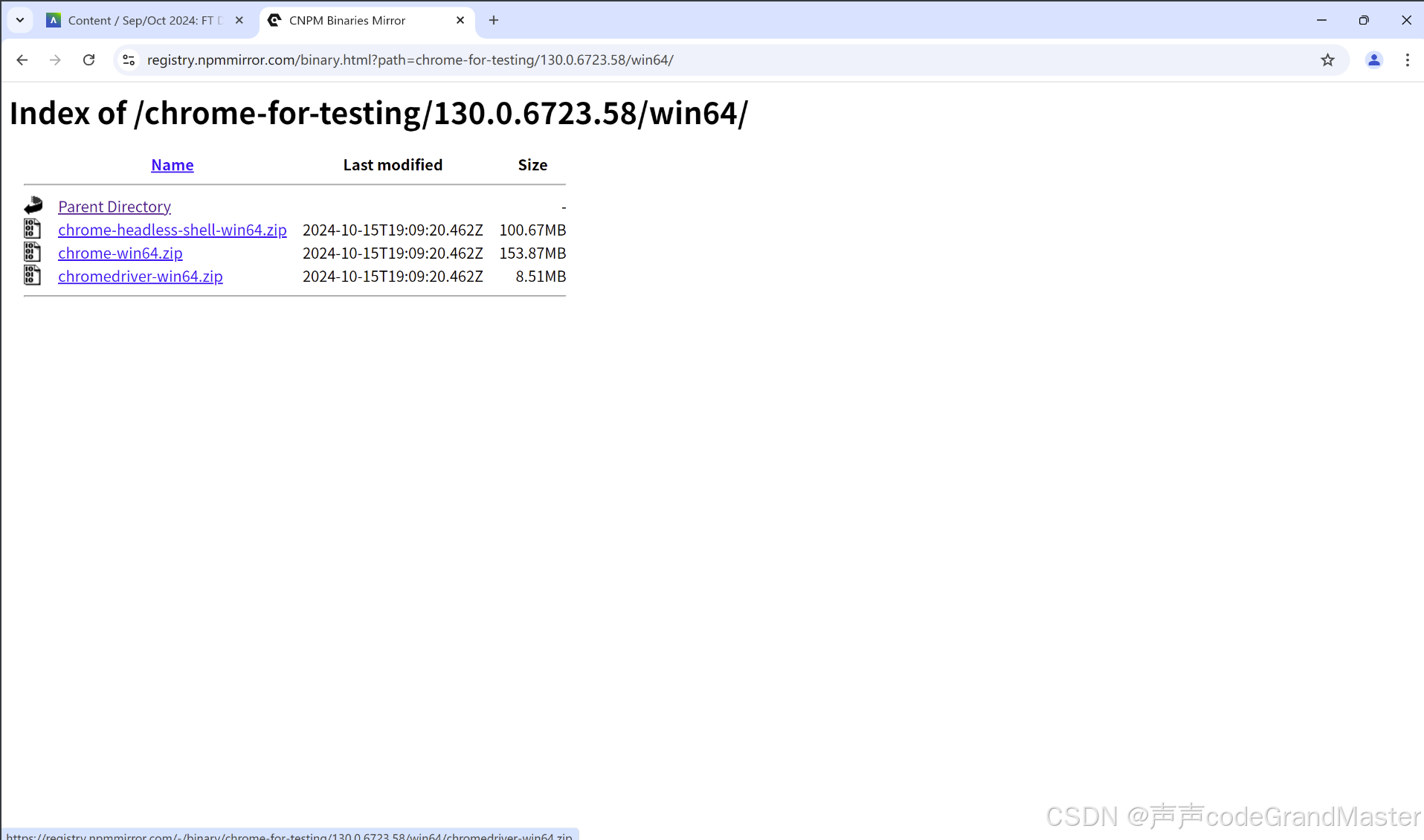
最后, 我们找到最下面的chromedriver-win64.zip这个压缩包, 点击它等它下载完。
下载完之后, 可以给它放到别的磁盘中, 再解压。
解压缩之后, 文件夹点进去, 有个exe文件, 将这个exe文件, 放到我们的pycharm里面去。
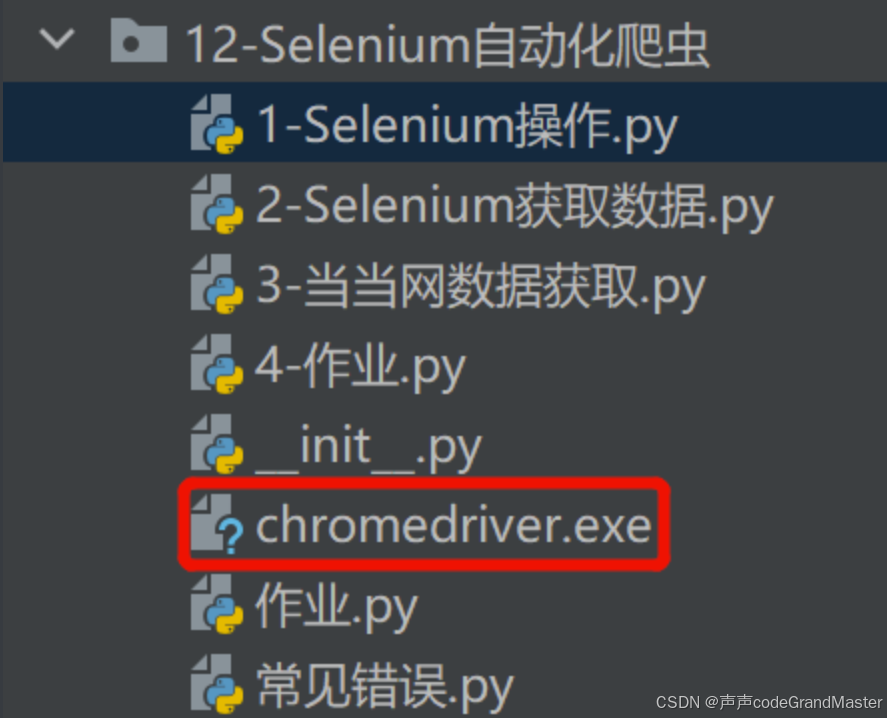
接下来, 我们就要开始写代码了。
我们首先, 要导入第三方模块:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
```
然后我们需要创建服务对象, 指定驱动的路径:
```python
service = Service(r'chromedriver.exe')# 相对路径
这个chromedriver.exe就是我们刚才放到pycharm项目的文件夹下面的exe文件。除了写相对路径, 也可以写绝对路径。
创建浏览器对象:
web = webdriver.Chrome(service=service)
打开页面 不需要区分get和post 放入目标页面的url(浏览器地址栏的url):
web.get('https://registry.npmmirror.com/binary.html?path=chromedriver/106.0.5249.21/')
设置窗口最大化:
web.maximize_window()
同时也有设置窗口最小化的写法: web.minimize_window()。
完整代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 创建服务对象 指定驱动的路径# Service(r'D:\爬虫_38\chromedriver.exe') 绝对路径
service = Service(r'chromedriver.exe')# 相对路径# 创建浏览器对象
web = webdriver.Chrome(service=service)# 打开页面 不需要区分get和post 放入目标页面的url(浏览器地址栏的url)
web.get('https://registry.npmmirror.com/binary.html?path=chromedriver/106.0.5249.21/')# 设置窗口最大化
web.maximize_window()# 设置窗口最小化# web.minimize_window()
结果:
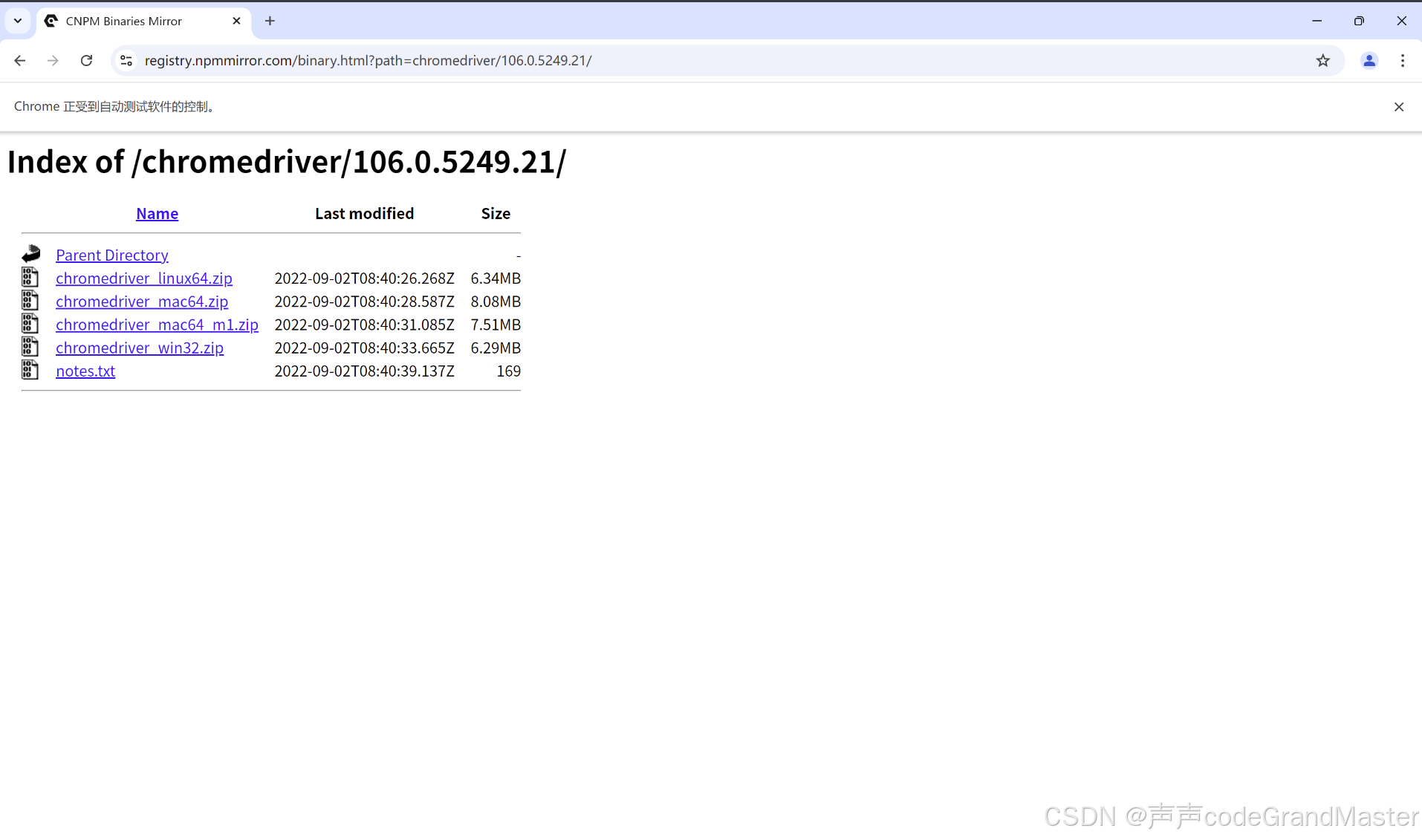
运行结果就是, 自动打开了对应的url网页。
二、用Selenuim获取数据
我们先用Selenuim打开百度
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'chromedriver.exe')# 相对路径# 创建浏览器对象
web = webdriver.Chrome(service=service)# 设置窗口最大化
web.maximize_window()
web.get('https://www.baidu.com/')
结果:
获取网页源代码(看到的是什么拿到的就是什么 所见即所得):
print(web.page_source)
解析数据:
'''
1- 基于html源码 可以利用xpath bs4
2- Selenium提供了自带的解析数据的方式
'''
通过标签的id属性获取到标签对象:
# 比如:<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">这样的标签# 浏览器对象.find_element(By.ID,'id的值') 根据id=值 从页面中获取到标签对象print(web.find_element(By.ID,'kw'))print(web.find_elements(By.ID,'kw'))# 返回值为列表,列表中保存的是根据规则获取到的标签对象
获取标签, 往文本标签内输入文字(标签对象.send_keys(内容)):
input_tag = web.find_element(By.ID,'kw')
input_tag.send_keys('python')
通过标签的class属性值获取标签对象:
tag = web.find_element(By.CLASS_NAME,'s_ipt')
tag.send_keys('python')
通过标签的name属性值获取标签对象:
tag = web.find_element(By.NAME,'wd')
tag.send_keys('python')
通过标签名获取标签对象 如果通过标签名获取标签对象,最好是用find_elements 拿所有:
tag = web.find_element(By.TAG_NAME,'input')# 只会获取当前页面第一个input标签
tag.send_keys('python')
通过xpath语法获取标签对象:
tag = web.find_element(By.XPATH,'//input[@id="kw"]')
tag.send_keys('python')
通过css选择器获取标签对象:
# 比如id=kw, 那我们再find_element的第二个参数那里要写#kw
tag = web.find_element(By.CSS_SELECTOR,'#kw')
tag.send_keys('python')
三、当当网数据获取
我们这个案例, 分为4部分操作:
"""
1- 打开当当网
2- 在搜索框内输入要搜索的内容
3- 点击放大镜
4- 解析 (先要拿到标签对象,才可以获取文本,获取属性,实现点击,实现输入...)
"""
第一、打开当当网。
代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
service = Service(r'chromedriver.exe')# 相对路径# 创建浏览器对象
web = webdriver.Chrome(service=service)# 设置窗口最大化
web.maximize_window()
web.get('https://www.dangdang.com/')
第二、在搜索框内输入要搜索的内容。
第三、点击放大镜。
我将这两个内容放在一起去讲解。
代码:
# name = input('请输入你想要查询的商品')
name ='python'# 获取搜索框的标签
input_tag = web.find_element(By.ID,'key_S')
input_tag.send_keys(name)# 获取放大镜标签
but_tag = web.find_element(By.CLASS_NAME,'button')# 实现点击的操作 标签对象.click()
but_tag.click()
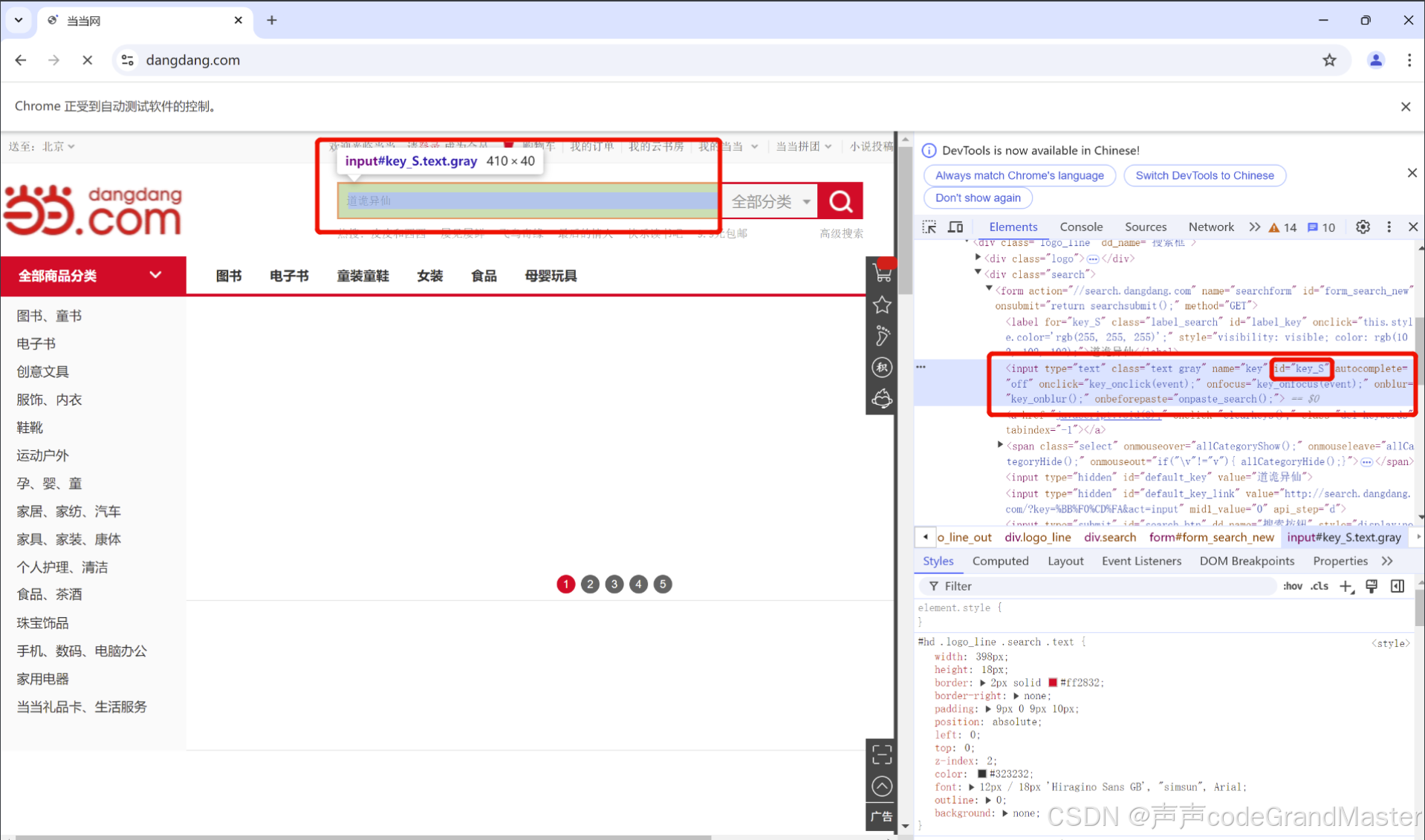
input_tag = web.find_element(By.ID, ‘key_S’)这行代码相当于找到了当当网的input的输入框。而input_tag.send_keys(name)这行代码, 就是在输入框要输入的内容, 也就是我们想要查询的内容。

同理, but_tag = web.find_element(By.CLASS_NAME, ‘button’)这行代码就是获取放大镜那个搜索按钮。通过but_tag.click()这行代码来实现点击搜索按钮去搜索内容。
这一步操作, 相当于我们人为在输入框里面输入我们想要查询的内容, 然后再点击搜索按钮进行查询, 从而查到我们想要查到的内容。
四、解析 (先要拿到标签对象,才可以获取文本,获取属性,实现点击,实现输入…)。
我们需要获取列表中的书名、价格、作者、出版日期、出版社、评论数。
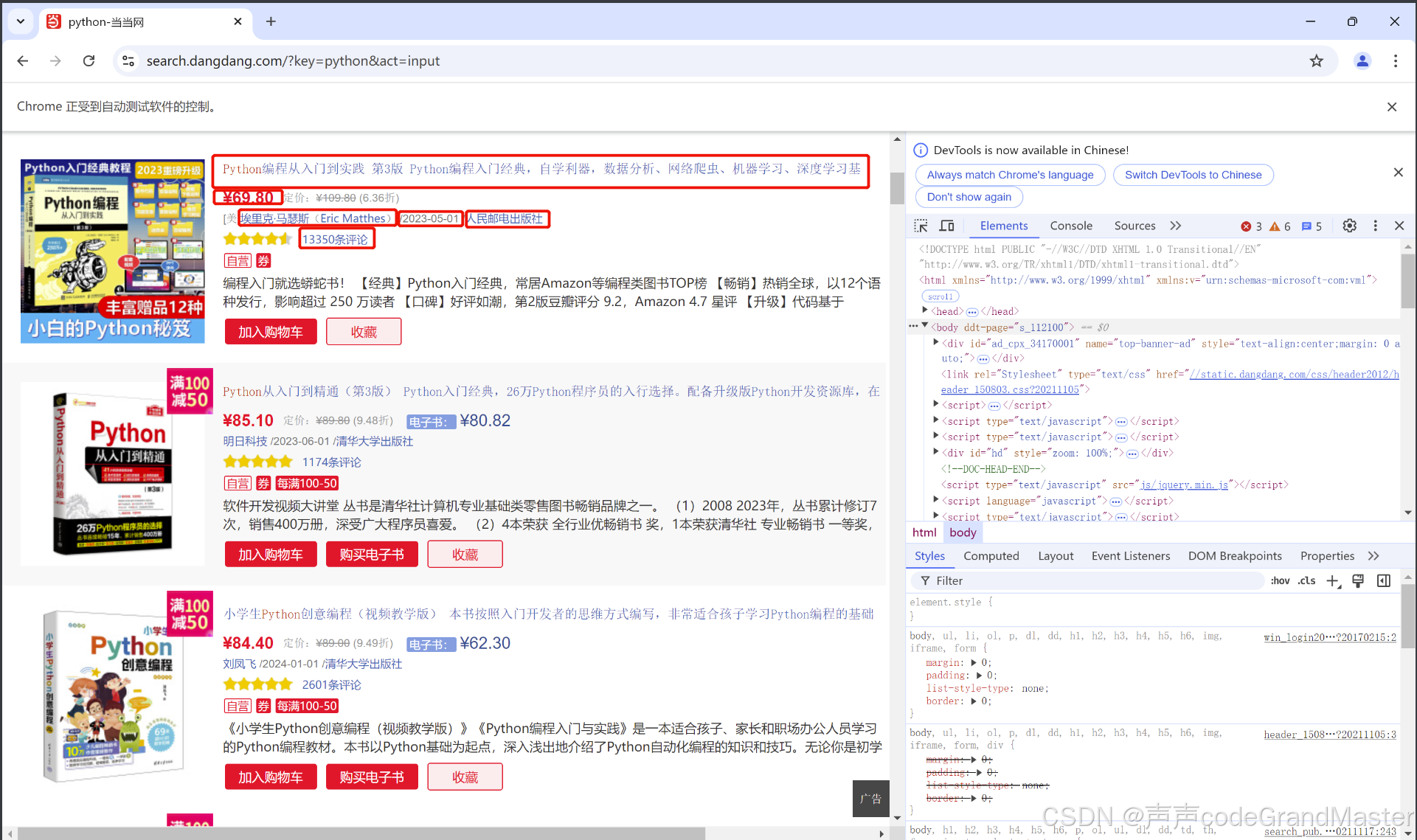
代码:
lis = web.find_elements(By.XPATH,'//ul[@class="bigimg"]/li')# 基于每一个li标签获取需要的信息
count =1for li in lis:# li = 第一个li标签对象# 书名# 获取标签的文本内容:通过标签对象.text# book_name = li.find_element(By.NAME,'itemlist-title').text# 获取标签的属性值:标签对象.get_attribute(标签名)
book_name = li.find_element(By.NAME,'itemlist-title').get_attribute('title')# 价格
price = li.find_element(By.CLASS_NAME,'search_now_price').text
# 有些书籍没有作者,没有出版日期,没有出版社# 作者try:
author = li.find_element(By.NAME,'itemlist-author').get_attribute('title')except:
author ='无'# 出版日期 [2]代表获取第二个标签try:
date = li.find_element(By.XPATH,'//p[@class="search_book_author"]/span[2]').text
except:
date ='无'# 出版社try:
cbs = li.find_element(By.XPATH,'//p[@class="search_book_author"]/span[3]/a').text
except:
cbs ='无'# 评论数try:
comment_num = li.find_element(By.CLASS_NAME,'search_comment_num').text
except:
comment_num =0print(count, book_name, price, author, date, cbs, comment_num)
count +=1
这里的代码, 就是获取我们想要的数据, 写法其实和之前学习的html解析中的xpath内容有关联, 可以回头翻一翻我以前写过的数据解析的那几篇博客。在Selenuim操作中, 多了些操作, 比如通过name, class name等方法, 来获取我们想要的数据。
完整代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
service = Service(r'chromedriver.exe')# 相对路径# 创建浏览器对象
web = webdriver.Chrome(service=service)# 设置窗口最大化
web.maximize_window()
web.get('https://www.dangdang.com/')# name = input('请输入你想要查询的商品')
name ='python'# 获取搜索框的标签
input_tag = web.find_element(By.ID,'key_S')
input_tag.send_keys(name)# 获取放大镜标签
but_tag = web.find_element(By.CLASS_NAME,'button')# 实现点击的操作 标签对象.click()
but_tag.click()# 获取数据# 获取每本书的整体标签 因为每个li标签身上都有不同的属性值# 所以基于父级ul标签拿所有的子标签li
lis = web.find_elements(By.XPATH,'//ul[@class="bigimg"]/li')# 拿多个# web.find_element() # 拿一个# print(len(lis))# 基于每一个li标签获取需要的信息
count =1for li in lis:# li = 第一个li标签对象# 书名# 获取标签的文本内容:通过标签对象.text# book_name = li.find_element(By.NAME,'itemlist-title').text# 获取标签的属性值:标签对象.get_attribute(标签名)
book_name = li.find_element(By.NAME,'itemlist-title').get_attribute('title')# 价格
price = li.find_element(By.CLASS_NAME,'search_now_price').text
# 有些书籍没有作者,没有出版日期,没有出版社# 作者try:
author = li.find_element(By.NAME,'itemlist-author').get_attribute('title')except:
author ='无'# 出版日期 [2]代表获取第二个标签try:
date = li.find_element(By.XPATH,'//p[@class="search_book_author"]/span[2]').text
except:
date ='无'# 出版社try:
cbs = li.find_element(By.XPATH,'//p[@class="search_book_author"]/span[3]/a').text
except:
cbs ='无'# 评论数try:
comment_num = li.find_element(By.CLASS_NAME,'search_comment_num').text
except:
comment_num =0print(count, book_name, price, author, date, cbs, comment_num)
count +=1
结果:
过一会儿, 就会从当当网里面的输入框里面自动输入python并搜索查询内容。


我们在返回pycharm里面, 看看控制台输出的结果:
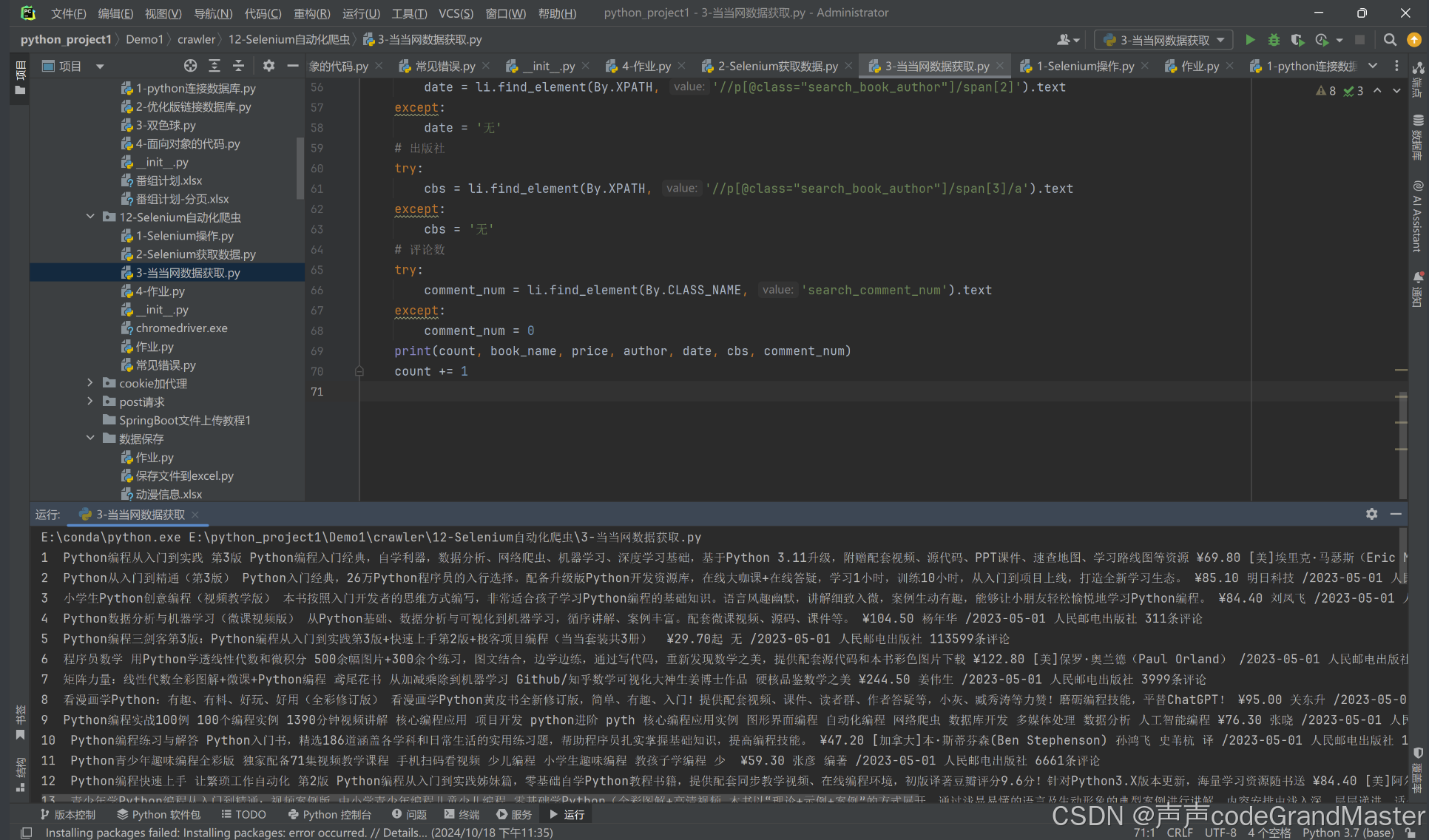
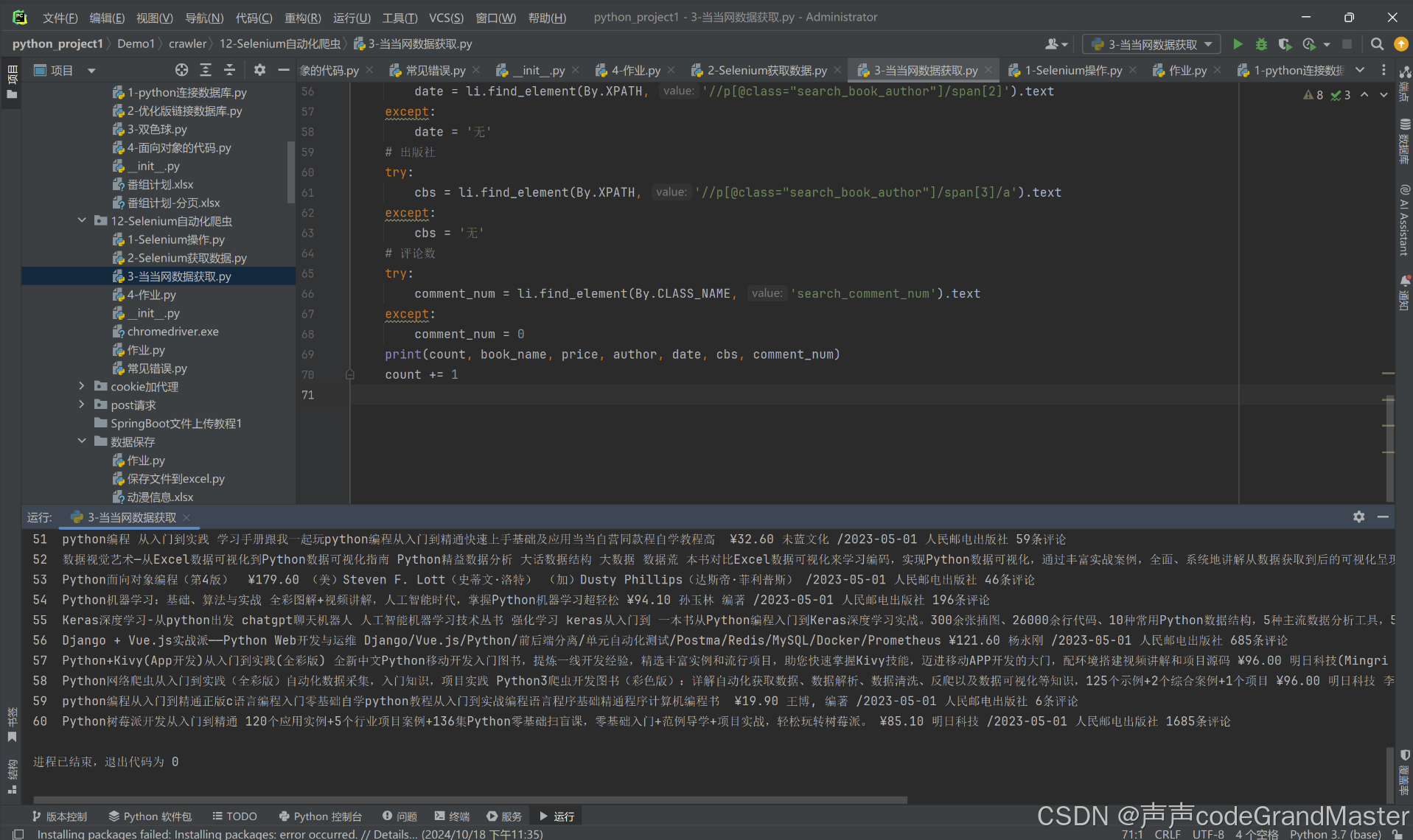
我们发现, 在控制台里面输出了我们想要获取的数据(书名、价格、作者、出版日期、出版社、评论数)。也就是我们所爬取到的内容。
四、实战
url是https://www.mi.com/shop/category/list
要求: 爬取所有分类名。
需要爬取左边圈出来的那些文字(也就是所有的分类名)。
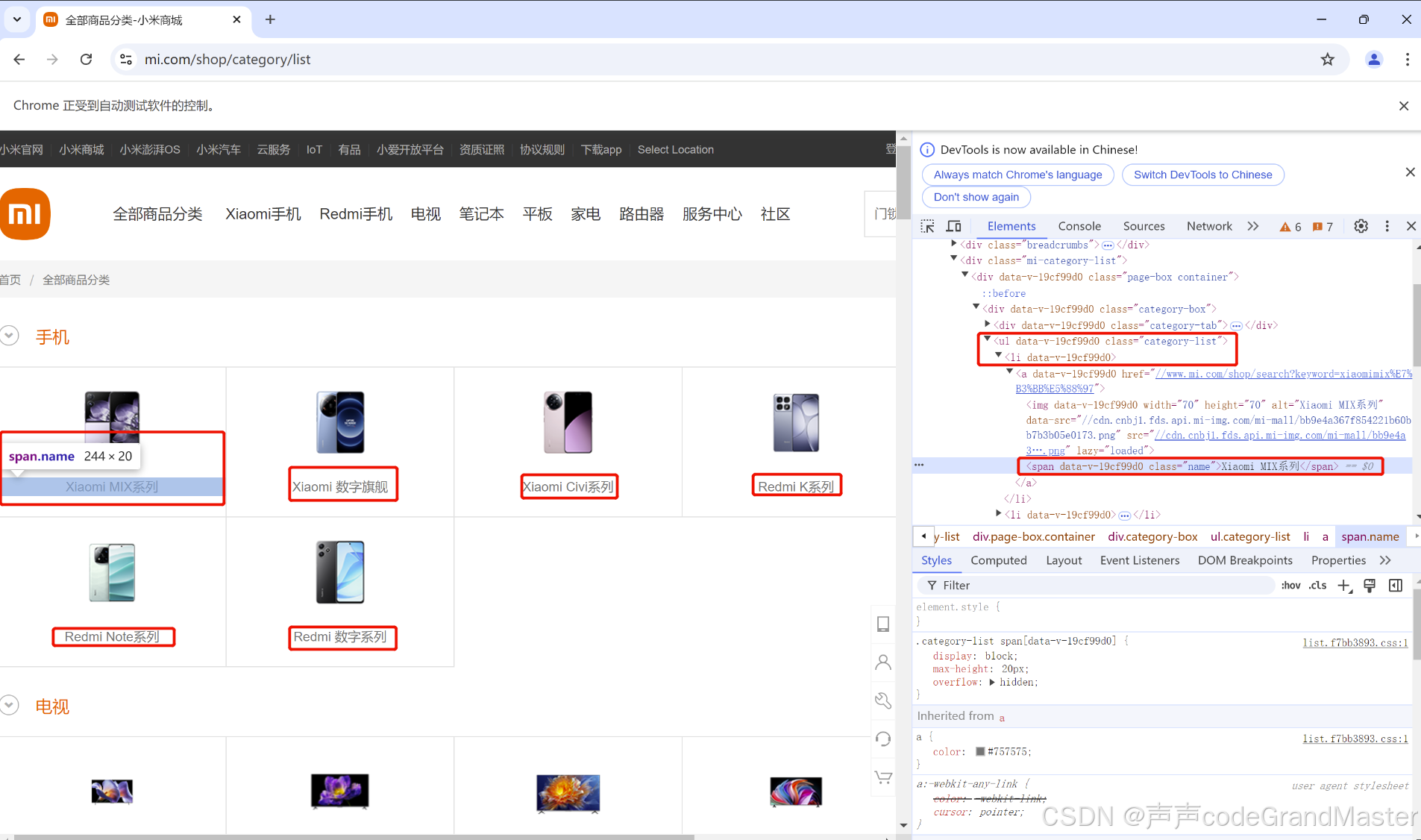
这些分类名, 在ul>li>span里面。
先自己尝试的用selenuim做一做, 作完后再对答案。
参考答案:
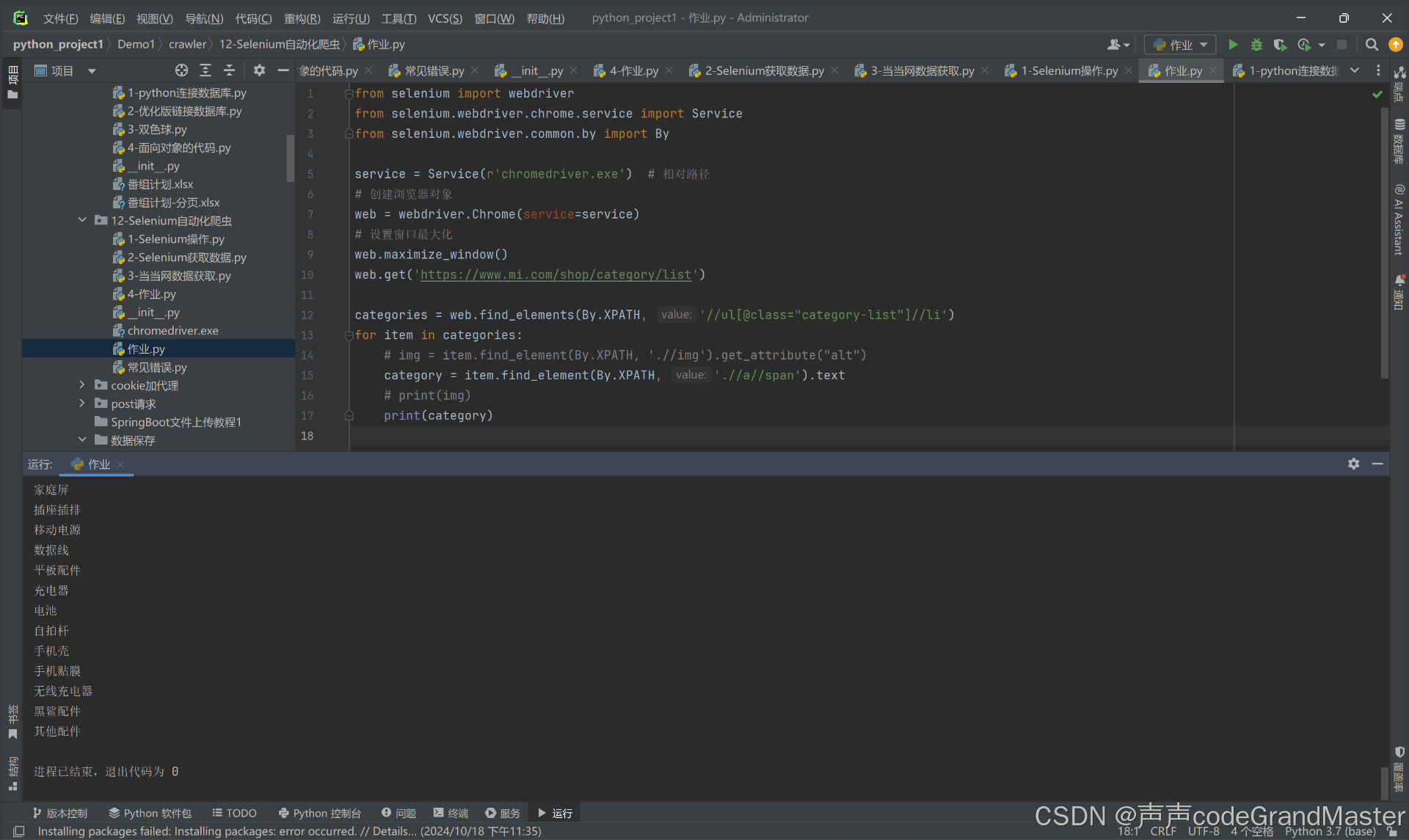
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
service = Service(r'chromedriver.exe')# 相对路径# 创建浏览器对象
web = webdriver.Chrome(service=service)# 设置窗口最大化
web.maximize_window()
web.get('https://www.mi.com/shop/category/list')
categories = web.find_elements(By.XPATH,'//ul[@class="category-list"]//li')for item in categories:# img = item.find_element(By.XPATH, './/img').get_attribute("alt")
category = item.find_element(By.XPATH,'.//a//span').text
# print(img)print(category)
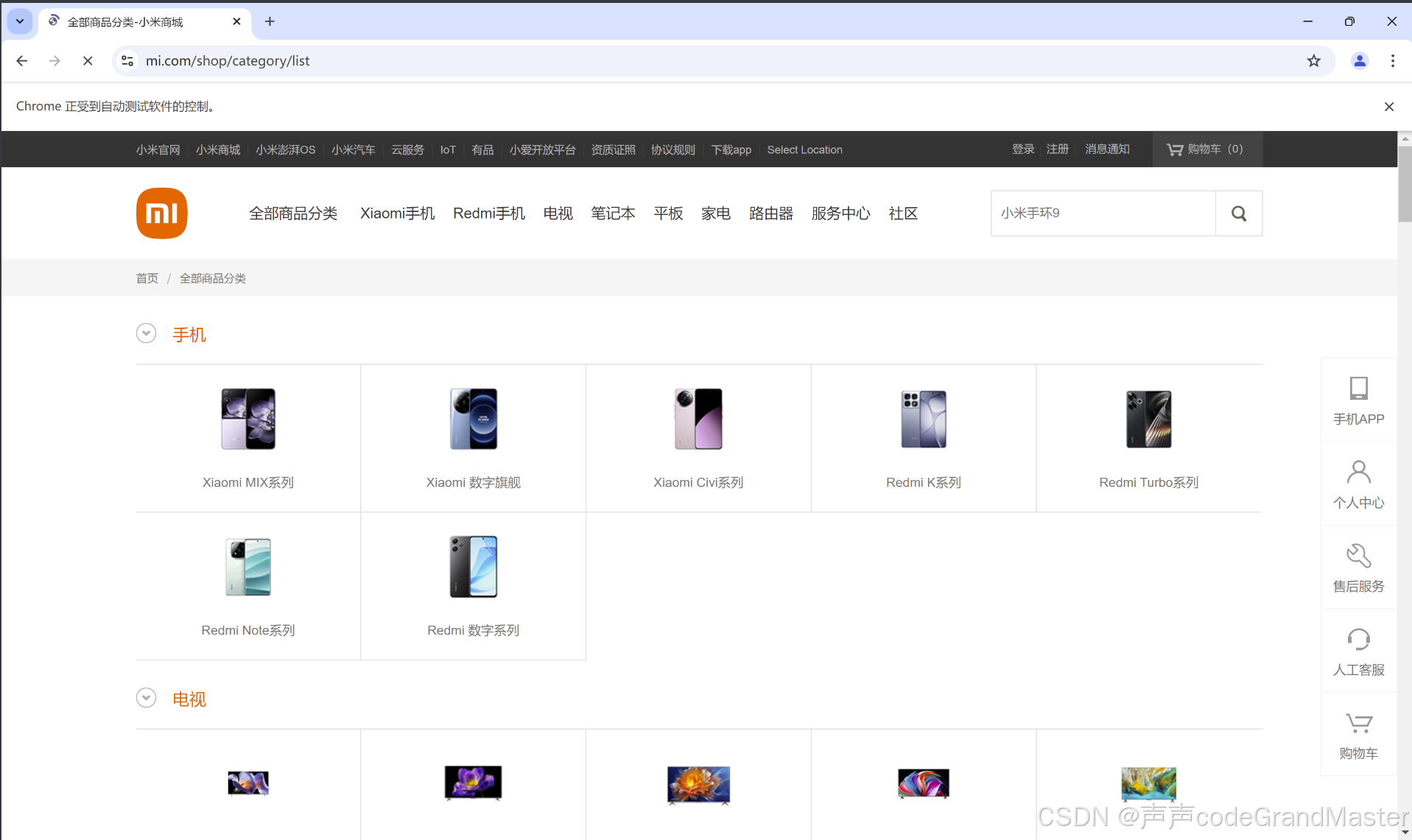
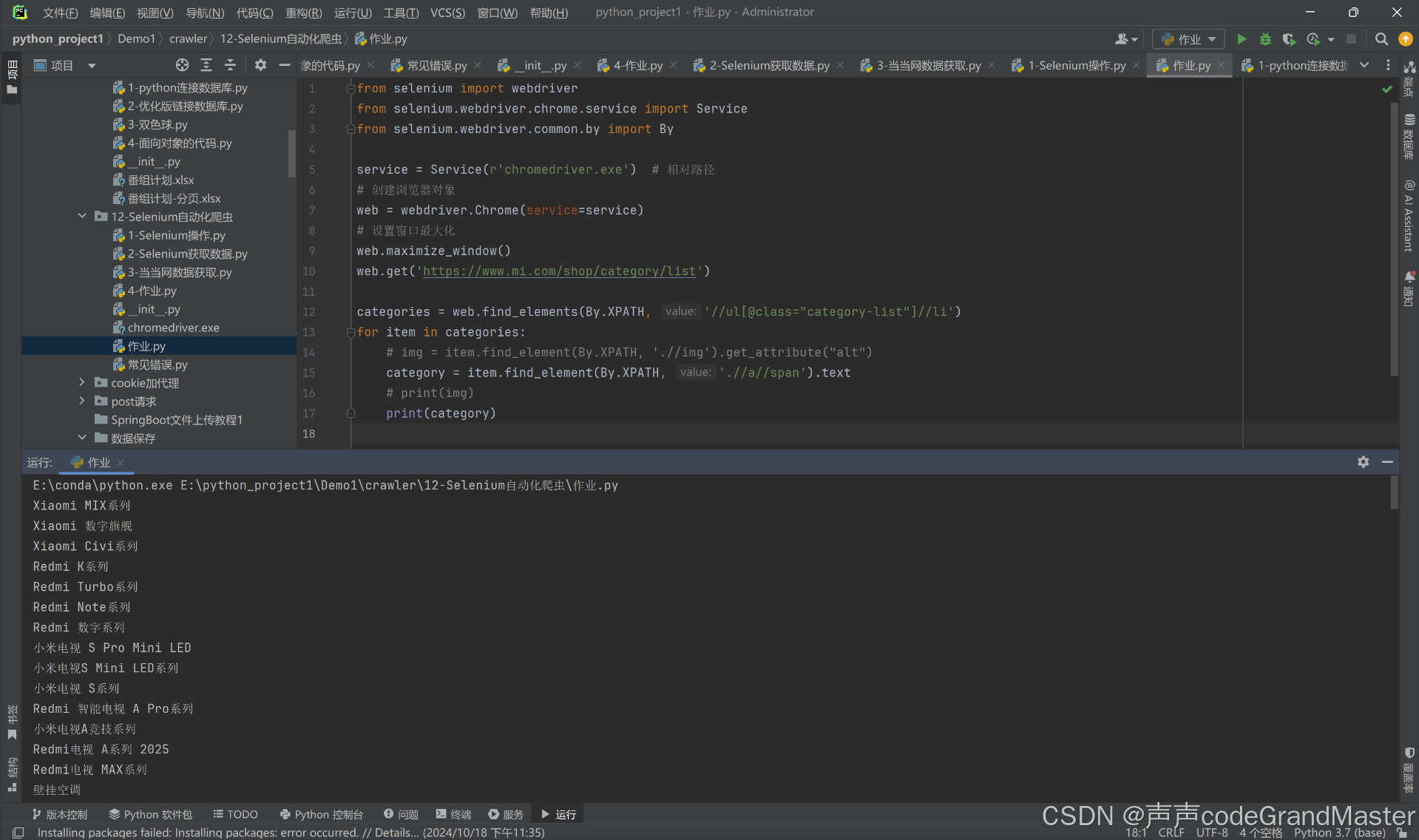
结果:
打开了小米网站:
然后这是在控制台输出的内容:
这道实战题, 你写出来了吗? 如果写出来的话, 给自己鼓掌哦👏
以上就是自动化爬虫Selenium的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!
版权归原作者 声声codeGrandMaster 所有, 如有侵权,请联系我们删除。