
一.群起集群
1.配置workers
进入目录 cd /opt/module/hadoop-3.1.3/etc/hadoop
注意不要加空格!!!
分发所有节点配置文件
/home/atguigu/bin/xsync workers
2.启动集群
(1)集群初始化
第一次启动集群需要进行一次初始化。
需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)

(2)启动HDFS(Hadoop102)
集群命令位于


(3) 检查启动情况(HADOOP)
jps检查
hadoop102: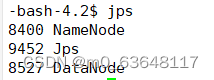
hadoop103: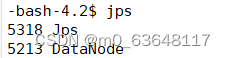
hadoop104: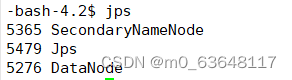
Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
(4)启动YARN(Hadoop103)

(5)检查启动情况(YARN)
集群启动完毕!!!
Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
二.集群测试
1.上传文件到集群

Namenode在安全模式:
检查是否在安全模式 : hdfs dfsadmin -safemode get
如果输出结果为
Safe mode is ON
,则表示NameNode当前处于安全模式。
离开安全模式 : hdfs dfsadmin -safemode leave
小文件:
创建文件夹wcinput

可在web页面中查看 
把本地文件word.txt传到创建的文件夹中 
在web页面中查看
2.文件存放位置
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1436128598-192.168.10.102-1610603650062/current/finalized/subdir0/subdir0
在core-site.xml中:
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
是作为文件的存储位置
3.执行计算任务
wodcount是计算指令,该命令的意思是统计wcinput文件中的词频并将结果存到 wcouput中。

可以查看到历史记录

查看结果

本文转载自: https://blog.csdn.net/m0_63648117/article/details/136291526
版权归原作者 m0_63648117 所有, 如有侵权,请联系我们删除。
版权归原作者 m0_63648117 所有, 如有侵权,请联系我们删除。