
GitHub仓库地址:https://github.com/sjmshsh/go-deadletter-delayletter-demo/tree/master
为什么要使用消息队列?
流量削峰
举个例子,如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
应用解耦
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在 这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障,提升系统的可用性。
异步处理
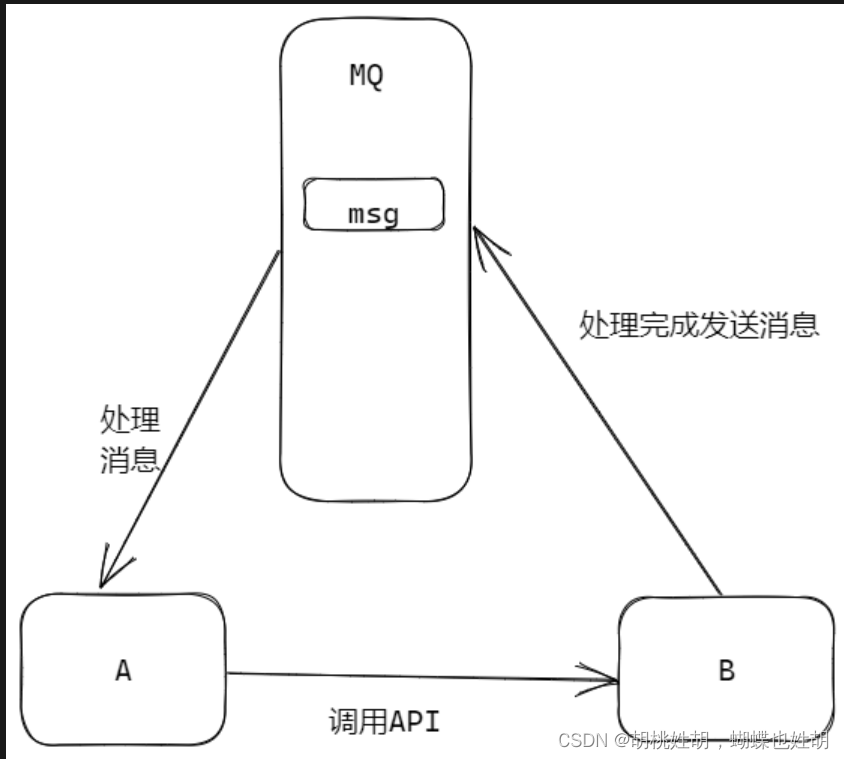
有些服务间调用是异步的,例如 A 调用 B,B 需要花费很长时间执行,但是 A 需要知道 B 什么时候可以执行完。
以前一般有两种方式,A 过一段时间去调用 B 的查询 api 查询。或者 A 提供一个 callback api,B 执行完之后调用 api 通知 A 服务。这两种方式都不是很优雅。
使用消息总线,可以很方便解决这个问题, A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样 B 服务也不用做这些操作,A 服务还能及时的得到异步处理成功的消息。
 ]
]
RabbitMQ架构设计
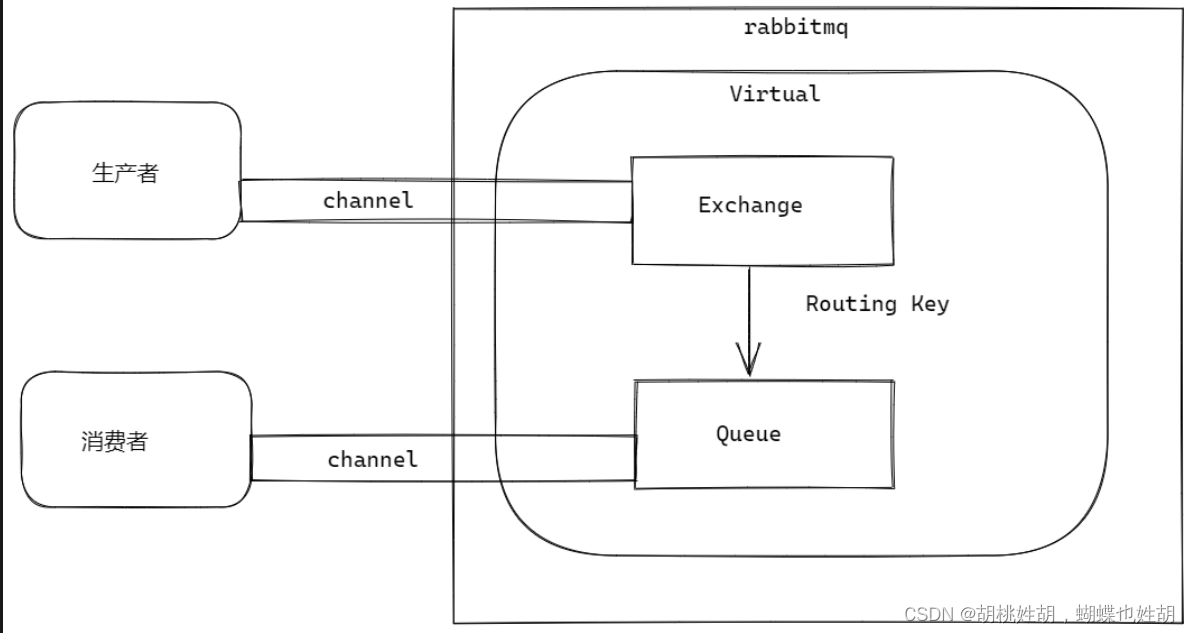
RabbitMQ基本用法
懂Topic模式其他所有的模式就都懂了。
https://www.rabbitmq.com/tutorials/tutorial-five-go.html
以上是RabbitMq官方文档Topic模式的链接。
顺便贴一下我自己的代码:
目录结构:
consumer.go:
funcmain(){
rabbitMQTopics := RabbitMq_Demo.NewRabbitMQTopics("gopher","exchangeTopics","lxy.1314.top")
rabbitMQTopics.ConsumeTopics()}
publish.go:
funcmain(){
rabbitMQTopics := RabbitMq_Demo.NewRabbitMQTopics("gopher","exchangeTopics","lxy.1314.top")for i :=0; i <10; i++{
rabbitMQTopics.PublishTopics(strconv.Itoa(i)+"rabbitMQTopics生产的消息")
time.Sleep(time.Second *1)
fmt.Println(i)}}
rabbitmq.go:
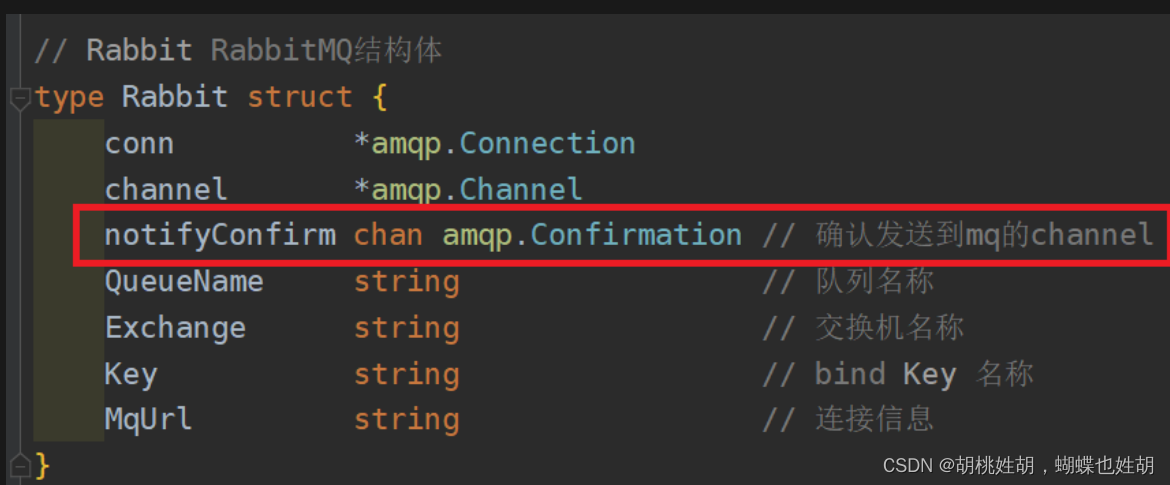
// 连接信息amqp://用户名:密码@ip/Virtual Hostsconst rmqURL ="amqp://guest:[email protected]:5672/lxy"// Rabbit RabbitMQ结构体type Rabbit struct{
conn *amqp.Connection
channel *amqp.Channel
notifyConfirm chan amqp.Confirmation // 确认发送到mq的channel
QueueName string// 队列名称
Exchange string// 交换机名称
Key string// bind Key 名称
MqUrl string// 连接信息}// NewRabbitMQ 创建Rabbit结构体实例funcNewRabbitMQ(queueName, exchange, key string)*Rabbit {return&Rabbit{
QueueName: queueName,
Exchange: exchange,
Key: key,
MqUrl: rmqURL,}}// Destroy 断开channel和connectionfunc(r *Rabbit)Destroy()error{
err := r.channel.Close()
err = r.conn.Close()return err
}// 错误处理函数func(r *Rabbit)failOnErr(err error, msg string){if err !=nil{
log.Fatal(msg, err)}}// NewRabbitMQTopics 创建Topics模式下RabbitMQ实例funcNewRabbitMQTopics(queueName, exchangeName, routingKey string)*Rabbit {
rabbitMQ :=NewRabbitMQ(queueName, exchangeName, routingKey)// 创建RabbitMQ实例var err error
rabbitMQ.conn, err = amqp.Dial(rabbitMQ.MqUrl)// 获取connection
rabbitMQ.failOnErr(err,"failed to connect rabbitmq!")
rabbitMQ.channel, err = rabbitMQ.conn.Channel()// 获取channel
rabbitMQ.failOnErr(err,"failed to open a channel")
err = rabbitMQ.channel.Confirm(false)if err !=nil{
log.Println("this.Channel.Confirm ", err)}
rabbitMQ.notifyConfirm = rabbitMQ.channel.NotifyPublish(make(chan amqp.Confirmation,1))go rabbitMQ.listenConfirm()return rabbitMQ
}func(r *Rabbit)listenConfirm(){for ret :=range r.notifyConfirm {if ret.Ack {
log.Println("confirm: 消息发送成功")}else{
log.Println("confirm: 消息发送失败")}}}// PublishTopics Topics模式 生产者func(r *Rabbit)PublishTopics(msg string){// 1.尝试创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,// 交换机名字"topic",// 交换机类型,这里使用topic类型,即: Topics模式true,// 是否持久化false,// 是否自动删除false,// true表示这个exchange不可以被client用来推送消息,仅用来进行exchange和exchange之间的绑定false,// 是否阻塞处理nil,// 额外的属性)
r.failOnErr(err,"Failed to declare an exchange")// 2.发送消息
err = r.channel.Publish(
r.Exchange,
r.Key,// Topics模式这里要指定keyfalse,// 如果为true,根据自身exchange类型和routekey规则无法找到符合条件的队列会把消息返还给发送者false,// 如果为true,当exchange发送消息到队列后发现队列上没有消费者,则会把消息返还给发送者
amqp.Publishing{
DeliveryMode: amqp.Persistent,
ContentType:"text/plain",
Body:[]byte(msg),},)if err !=nil{
log.Println(err)}}// ConsumeTopics Topics模式 消费者func(r *Rabbit)ConsumeTopics(){// 1.试探性创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,// 交换机名字"topic",// 交换机类型,这里使用topic类型,即: Topics模式true,// 是否持久化false,// 是否自动删除false,// true表示这个exchange不可以被client用来推送消息,仅用来进行exchange和exchange之间的绑定false,// 是否阻塞处理nil,// 额外的属性)
r.failOnErr(err,"Failed to declare an exchange")// 2.试探性创建队列,这里注意队列名称不要写
queue, err := r.channel.QueueDeclare(
r.QueueName,// 随机生产队列名称true,// 是否持久化false,// 是否自动删除false,// 是否具有排他性false,// 是否阻塞处理nil,// 额外的属性)
r.failOnErr(err,"Failed to declare a queue")// 3.绑定队列到exchange中
err = r.channel.QueueBind(
queue.Name,// 队列名
r.Key,// 路由参数,如果匹配消息发送的时候指定的路由参数,消息就投递到当前队列(在Topics模式下,这里的key要指定)
r.Exchange,// 交换机名字,需要跟消息发送端定义的交换器保持一致false,// 是否阻塞处理nil,// 额外的属性)// 4.消费消息
msgs, err := r.channel.Consume(
queue.Name,// 队列名称"",// 用来区分多个消费者false,// 是否自动应答false,// 是否独有false,// 设置为true,表示不能将同一个Connection中生产者发送的消息传递给这个Connection中的消费者false,// 队列是否阻塞nil,// 额外的属性)
r.failOnErr(err,"Failed to Consume")// 5.启用协程处理消息
forever :=make(chanbool)// 开个channel阻塞住,让开启的协程能一直跑着gofunc(){for delivery :=range msgs {// 消息逻辑处理,可以自行设计逻辑
fmt.Println("Received a message:",string(delivery.Body))// delivery.Ack(false)}}()
fmt.Println(" [*] Waiting for messages.")<-forever
}
Tips:
- mandatory和immediate参数建议两个都填充成false。原因是经过大量测试,这里很容易出现不明所以的bug,其次就是我们有更好的解决方法,后面会讲。
消息限流机制
在实际项目中使用RabbitMQ的时候,由于消费者自身处理消息的效率并不高,如果说这个时候生产者还是不断的在生产消息,一直推送消息到消费者,那么很容易引起消费者的宕机。
rabbitmq 提供了一个限流机制,用于限制一次性推送到消费者客户端的消息数量,让消费者都处理完了消息之后,生产者再推送新的消息过来。
//消费者流控 防止数据库爆库//消息的消费需要配合Qos
r.channel.Qos(//每次队列只消费一个消息 这个消息处理不完服务器不会发送第二个消息过来//当前消费者一次能接受的最大消息数量1,//服务器传递的最大容量0,//如果为true 对channel可用 false则只对当前队列可用false,)
限流用于消费者流控。
消息TTL机制
TTL,全称是 Time to Live,也就是过期时间。RabbitMQ 可以对消息或者队列设置过期时间。通过设置过期时间,如果消息没有消费,到期了就会被处理掉。这样在一个程度上就可以防止 MQ 的消息堆积问题。
- 给队列设置过期时间,那就是队列中所有消息都有相同的过期时间,不管是早入队的消息,还是晚入队的消息,只要队列的过期时间一到,消息都会被处理掉。即队列没有被消费者连着的消息的保留时间
- 给消息设置过期时间,那就是每条消息的过期时间就都不一样了。(不推荐,因为会遇到消息惰性过期问题,所以最好给队列设置过期时间,到期统一过期,用于订单服务等业务场景)
- 给队列或者消息都设置过期时间,那过期的时间就以这两个时间中较小的为准。队列没到期,某条消息到期了,那这条消息被处理掉。队列到期,那就是覆巢之下焉有完卵了。
那到期了,消息是怎么被处理掉的?它们会变成 “死信”(死亡的消息,Dead Message),放到死信队列中,消费者默认就无法再收到这消息。但死信也是可以被取出来消费的。
默认情况下,如果不设置 TTL,消息就永不过期。如果 TTL 设置为 0,那表示消息要直接投递给消费者,否着消息就会被丢弃掉。
死信队列与延迟队列
通俗来讲,无法被正常消费的消息,我们可以称之为死信。我们将其放入死信队列,单独处理这部分异常消息。
当消息符合以下的一个条件时,将会被称之为死信:
- 消息被拒绝,不重新放回队列(使用basic.reject / basic.nack 方法拒绝消息,并且这两个方法的参数 requeue = false)
- 消息TTL过期
- 队列达到最大长度
应用
- 当消费者无法正常消费消息、消息发生异常时,为了保证数据不丢失,将异常的消息置为死信,放入死信队列。在死信队列中的消息,将启动单独的消费程序特殊处理。
- 通过死信队列模拟延时队列的场景
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gdBdJrws-1669636121831)(D:\A\图片\板书\死信队列.excalidraw.png)]
这里有几个大家很容易疑惑的点,这里来逐一解释以下:
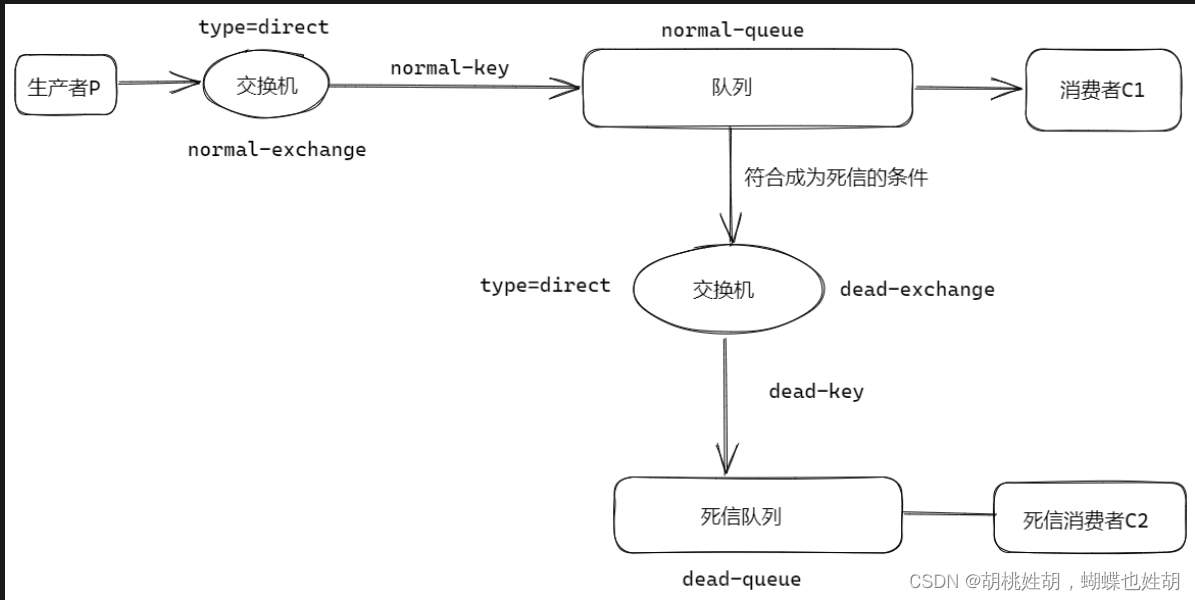
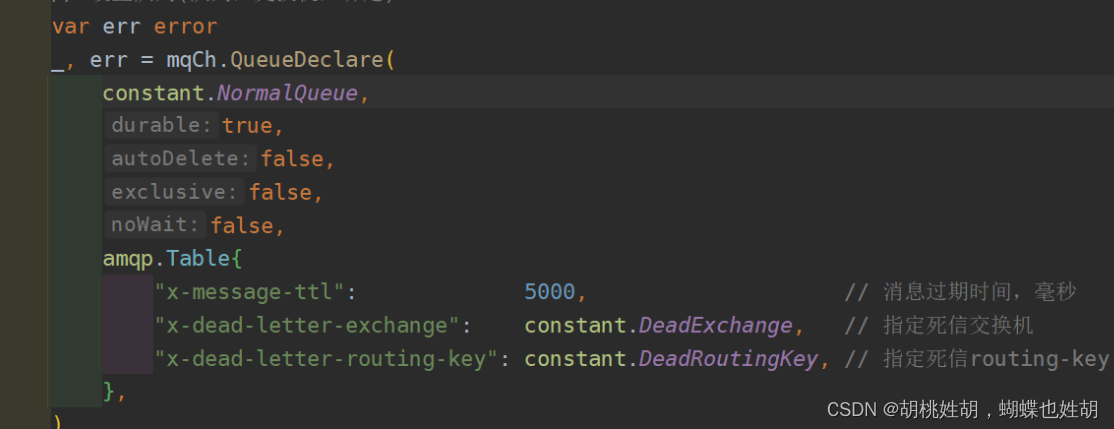
x-message-ttl,x-dead-letter-exchange,x-dead-letter-routing-key这三个字段我们是设置在普通队列上的,为什么要设置在普通队列上呢?因为你在普通队列上设置之后,就代表与死信交换机进行了绑定,当你x-message-ttl达到之后,这个普通队列会把消息往我设置好的死信交换机x-dead-letter-exchange进行发送,那么发送的消息肯定是有路由规则的,那么路由规则是什么呢,路由规则由x-dead-letter-routing-key来进行指定。- 测试死信队列和延迟队列。我同时启动consumer和dead_consumer的时候,不会触发死信队列和延迟队列的机制,原因是我有consumer对消息进行消费,无法达成条件,除非你主动reject或者消息爆满了。还有一种情况就是我如果没有ACK,大家想的可能是没有对消息进行处理,从而触发。但其实不会,经过测试后发现,如果没有ACK,那么消息的形式就是UnACK,实际上这样rabbitmq也当作我已经处理过了,只是消费者它没有确认回复而已。
但是这样实现的死信队列是有一个明显的缺陷的:
rabbitmq的消息是惰性过期的。
例如我队列里面的第一条数据过期时间是5分钟,第二条数据的过期时间是1分钟。那么当RabbitMq取第一条数据的时候发现过期时间是5分钟,就算此时已经过去了一分钟了,RabbitMq也不会管,而是把时间记录下来之后就懒得管了。5分钟之后,把第一个元素消费之后,发现第二个元素的过期时间是1分钟,早就超时了,这个RabbitMq才会把数据取走。也就是说延迟的效果并不是精确的。
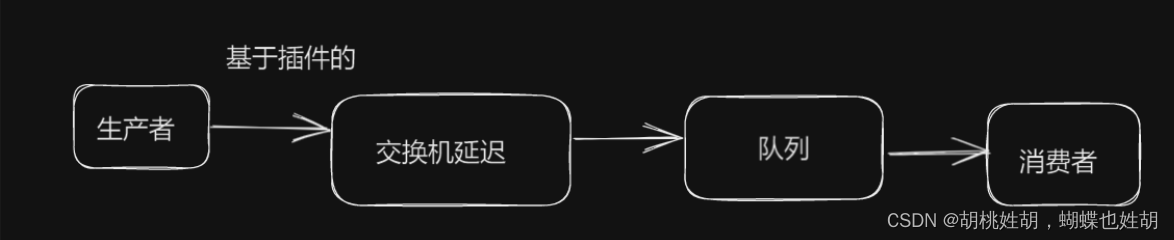
为了针对这种机制,我们需要下载一个插件,来进行优化。
可以按照这篇文章来进行下载。
https://www.cnblogs.com/isunsine/p/11572457.html
这个插件的原理是将消息在交换机处暂存在一个mnesia(一个分布式系统)表中,延迟投递到队列中,等到消息到期再投递到队列中。
所以上面的架构图实际上变成了这个样子:
代码全部在GitHub里面。
如何处理重复消息(消息幂等性的处理)?
消息幂等性:其任意多次执行所产生的影响均与一次执行的影响相同
- 利用数据库的唯一约束实现幂等。有
INSERT IF NOT EXIST语义的都可以。MySQL可以实现redis的SETNEX也可以。 - 为更新的数据设置前置条件。另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。例如:“将账户 X 的余额增加 100 元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果账户 X 当前的余额为 500 元,将余额加100 元”,这个操作就具备了幂等性。对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢?更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。
- 记录并检查操作。也叫做Token机制或者GUID(全局唯一ID)机制,实现思路很简单,在执行数据更新操作之前,先检查一下是否执行过这个更新操作。体的实现方法是,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。原理和实现是不是很简单?其实一点儿都不简单,在分布式系统中,这个方法其实是非常难实现的。首先,给每个消息指定一个全局唯一的 ID 就是一件不那么简单的事儿,方法有很多,但都不太好同时满足简单、高可用和高性能,或多或少都要有些牺牲。更加麻烦的是,在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。比如说,对于同一条消息:“全局 ID 为 8,操作为:给 ID 为 666 账户增加 100 元”,有可能出现这样的情况:- t0 时刻:Consumer A 收到条消息,检查消息执行状态,发现消息未处理过,开始执行“账户增加 100 元”- t1 时刻:Consumer B 收到条消息,检查消息执行状态,发现消息未处理过,因为这个时刻,Consumer A 还未来得及更新消息执行状态。这样就会导致账户被错误地增加了两次 100 元,这是一个在分布式系统中非常容易犯的错误,一定要引以为戒。t0 时刻:Consumer A 收到条消息,检查消息执行状态,发现消息未处理过,开始执行“账户增加 100 元”;t1 时刻:Consumer B 收到条消息,检查消息执行状态,发现消息未处理过,因为这个时刻,Consumer A 还未来得及更新消息执行状态。
如何保证消息的有序性?
如何处理消息堆积?
消息堆积的一个直接原因是在系统中的某个部分出现了性能问题,来不及处理上游发送的消息,才会导致消息积压。
优化性能来避免消息积压
消费端性能优化
消息积压了该如何处理?
RabbitMQ如何实现数据100%不丢失?
RabbitMQ一条消息从生产端到消费端共经过3个步骤:
- 生产端发送消息到RabbitMQ
- RabbitMQ发送消息到消费端
- 消费端消费这一条消息
这里面每一个步骤都有损失消息的可能性,因此我们只需要保证生产端可靠的发送给了RabbitMQ,RabbitMQ可靠的把消息发送给消费者就实现了整个系统的可靠性。
生产端投递消息可靠性
生产端投递消息丢失的原因有很多,例如消息在传输过程中发生网络故障,RabbitMQ宕机等等。我们使用RabbitMQ的一些机制来处理。
事务消息处理机制
使用事务保证消息的强一致性,但是性能太低,不推荐使用。
confirm消息确认机制
生产端投递的消息投递到RabbitMQ后,RabbitMQ将发送一个确认消息给到生产端,让生产端知晓我已收到消息,否则这条消息就可能丢失了,需要生产端再次发起消息投递。
实际上我们上面的demo里面就已经柔和了confirm消息确认机制了,我们来看一下:
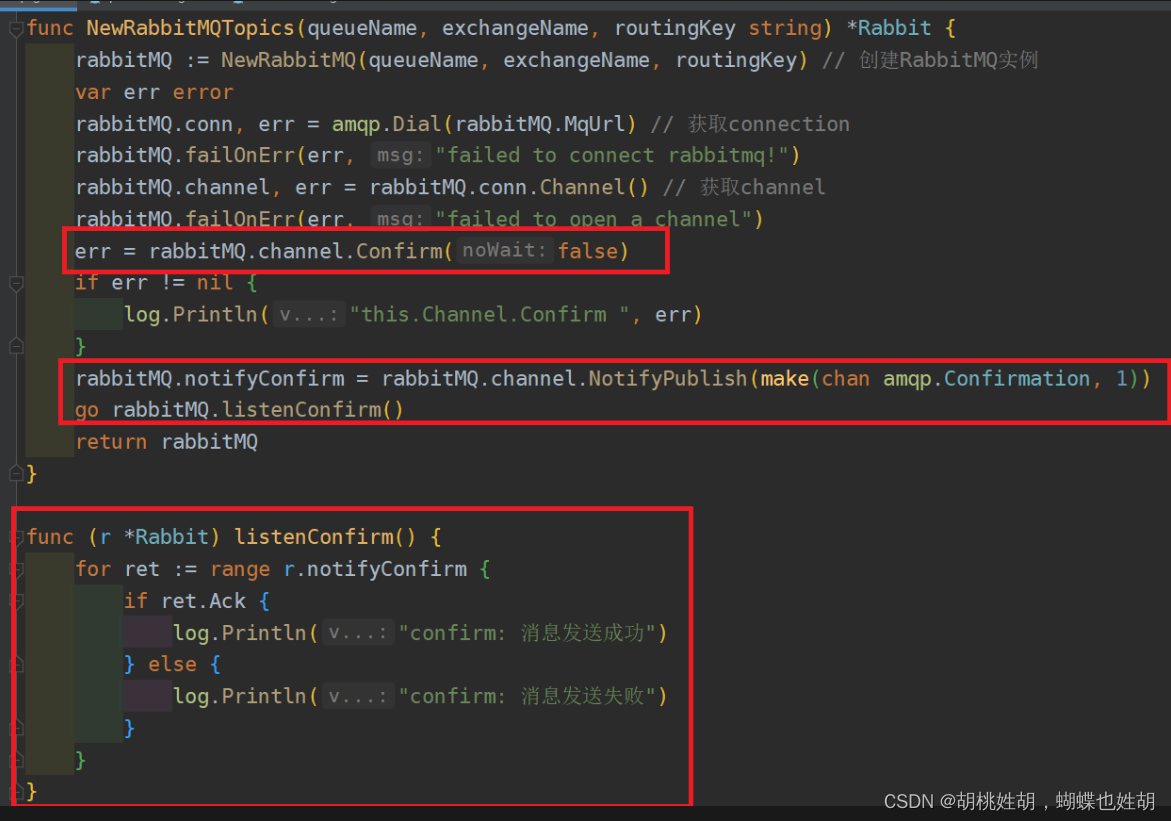
假如我们的消息发送失败了,那么我们可以使用一些补充机制,例如把发送失败的消息再次发送给队列,或者发送到另一个队列里面统一处理,这个要结合具体的业务场景。
RabbitMQ内部消息可靠性
持久化
假如我们的消息已经发到了RabbitMq当中,但是RabbitMq此时宕机了,消息就会丢失,所以我们需要在RabbitMq中做消息的持久化。
RabbitMQ收到消息后是暂存到内存当中,此时若RabbitMQ挂了,重启服务将会导致数据丢失,所以我们应当将相关数据持久化到硬盘中,这样RabbitMQ重启后依然可以到硬盘中取数据恢复。
消息到达RabbitMQ后先到达exchange交换机,然后路由到queue队列,最后发给消费端。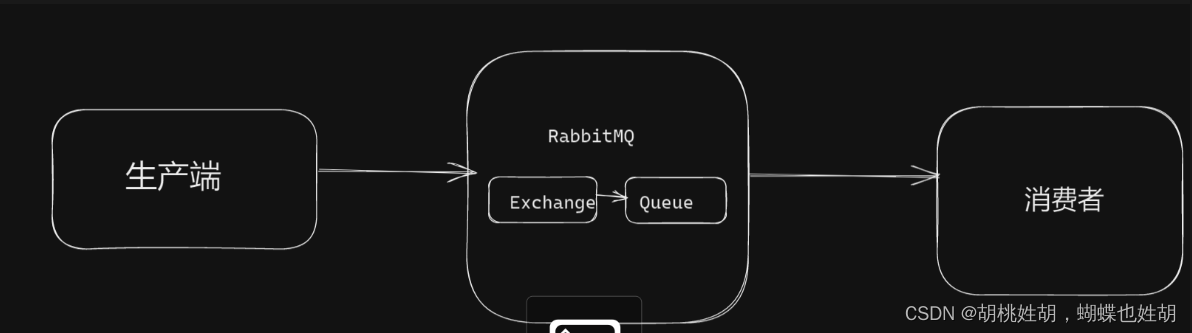
所以我们需要对exchange,queue和消息本身,message都做持久化。
我们的demo中也都已经体现了,下面来看一下:
exchange持久化
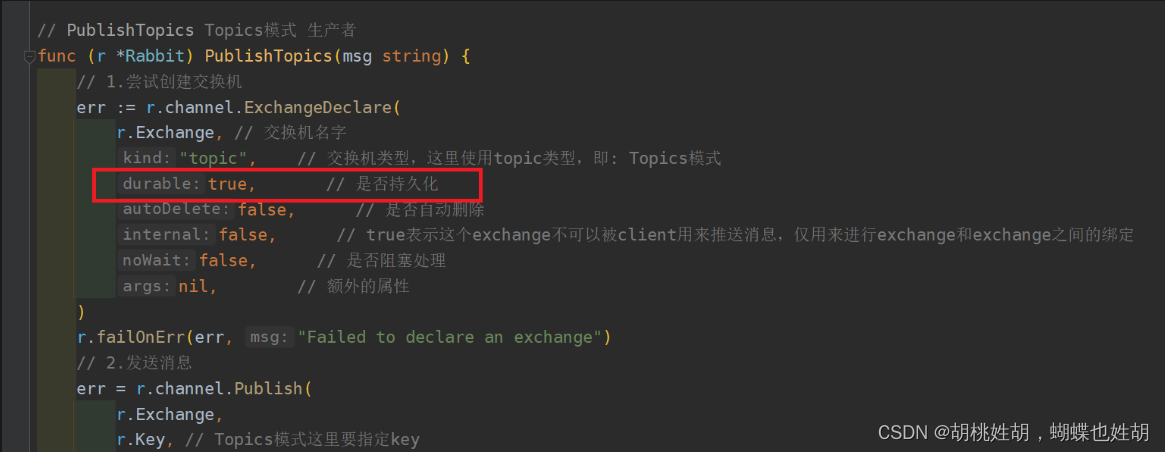
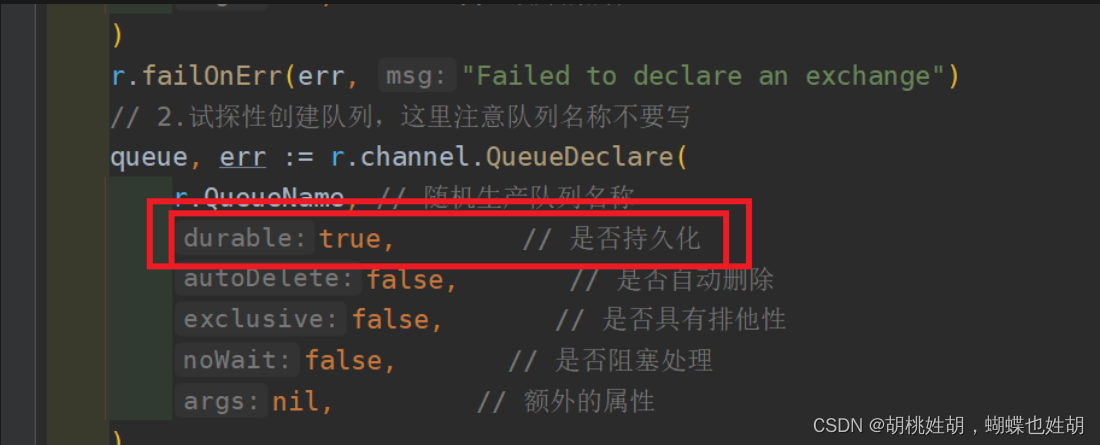
queue持久化
消息本身的持久化
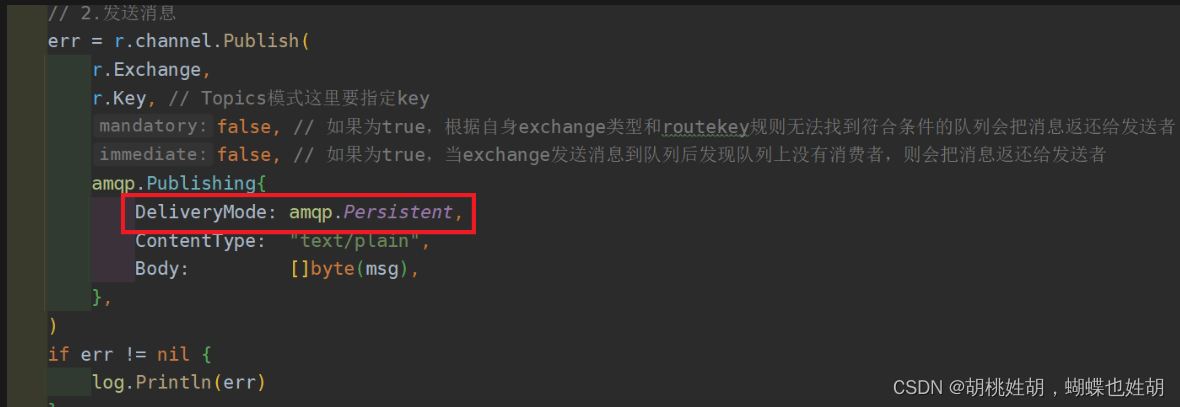
但是这样的三个持久化不可以完全保证消息可靠性投递到RabbitMQ中,比如极端情况:RabbitMQ收到消息还没来得及将消息持久化到硬盘时,RabbitMQ挂掉了,此时消息仍然丢失了;或者RabbitMQ在发送确认消息给生产端的过程中,由于网络故障导致生产端没有收到确认消息,导致生产端不知道RabbitMq是否收到消息,依然不好处理接下来的业务。
因此,我们可以在上述基础商考虑一些消息补偿机制,比如消息入库
消息入库
我们可以考虑将要发送的消息保存到数据库中,标注一个状态字段status=0,标识生产端将消息发送给RabbitMQ但还没收到确认回复。在生产端收到RabbitMQ确认回复后,将status设为1,表示RabbitMQ已收到消息。
考虑到前面提到的极端情况,我们可以在生产端开设一个定时器,定时检索消息表,将status=0并且超过固定期限后还没收到确认的消息内容取出重发(此时消费端要考虑消息重复情况,提前做好幂等性设置),并设定重发最大次数,超限做单独的特殊处理。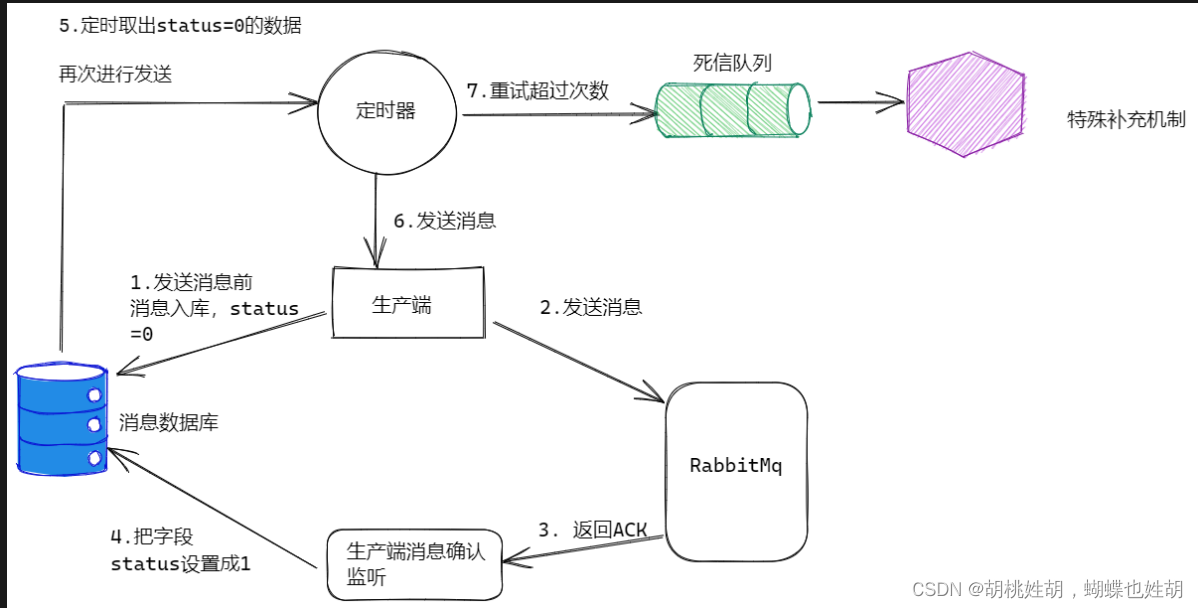
当然这个消息数据库可以是redis,MySQL,mongodb,这个取决于具体的业务需求和架构设计。
这个特殊补偿机制可以创建专门的死信消费者对死信进行处理,或者进行人工补偿。
这个图里面只画了消息数据库,实际上还有业务数据需要落库。
现在来阐述一下具体的步骤:
- 比如我们要发送一条订单消息,首先把业务数据也就是订单信息进行入库,然后生成一条消息,把消息也进行入库,这条消息应该包含消息状态属性,并设置初始值比如为0,表示消息创建成功正在发送中,这种方式缺陷在于我们要对数据库进行持久化两次。
- 首先要保证第一步消息都存储成功了,没有出现任何异常情况,然后生产端再进行消息发送。如果失败了就进行快速失败机制。
- MQ把消息收到的结果应答
(confirm)给生产端 - 生产端有一个
Confirm Listener,去异步的监听Broker回送的响应,从而判断消息是否投递成功,如果成功,去数据库查询该消息,并将消息状态更新为1,表示消息投递成功。 - 假设第二步OK了,在第三步回送响应时,网络突然出现了闪断,导致生产端的Listener就永远收不到这条消息的confirm应答了,也就是说这条消息的状态就一直为0了。
- 此时我们需要设置一个规则,比如说消息在入库时候设置一个临界值timeout,5分钟之后如果还是0的状态那就需要把消息抽取出来。这里我们使用的是分布式定时任务,去定时抓取DB中距离消息创建时间超过5分钟的且状态为0的消息。
- 把抓取出来的消息进行重新投递
(Retry Send),也就是从第二步开始继续往下走 - 当然有些消息可能就是由于一些实际的问题无法路由到Broker,比如routingKey设置不对,对应的队列被误删除了,那么这种消息即使重试多次也仍然无法投递成功,所以需要对重试次数做限制,比如限制3次,如果投递次数大于三次,那么就将消息状态更新为2,表示这个消息最终投递失败。
RabbitMQ到消费端信息不丢失
正常情况下,以下三种情况会导致消息丢失
- 在RabbitMQ将消息发出后,消费端还没有接收到消息前发生网络故障,消费端与RabbitMQ断开连接,此时消息会丢失;
- 在RabbitMQ将消息发出后,消费端还没有接收到消息前消费端挂了,此时消息会丢失;
- 消费端准备接收到消息后,但在处理消息过程中发生异常或宕机,消息会丢失。 综合上述三种情况,都是因为RabbitMQ的自动ack机制,即RabbitMQ默认在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完,导致消费端消息丢失时,RabbitMQ也没有该消息了。因此就需要将自动ack机制改为手动ack机制。消费端手动确认消息:
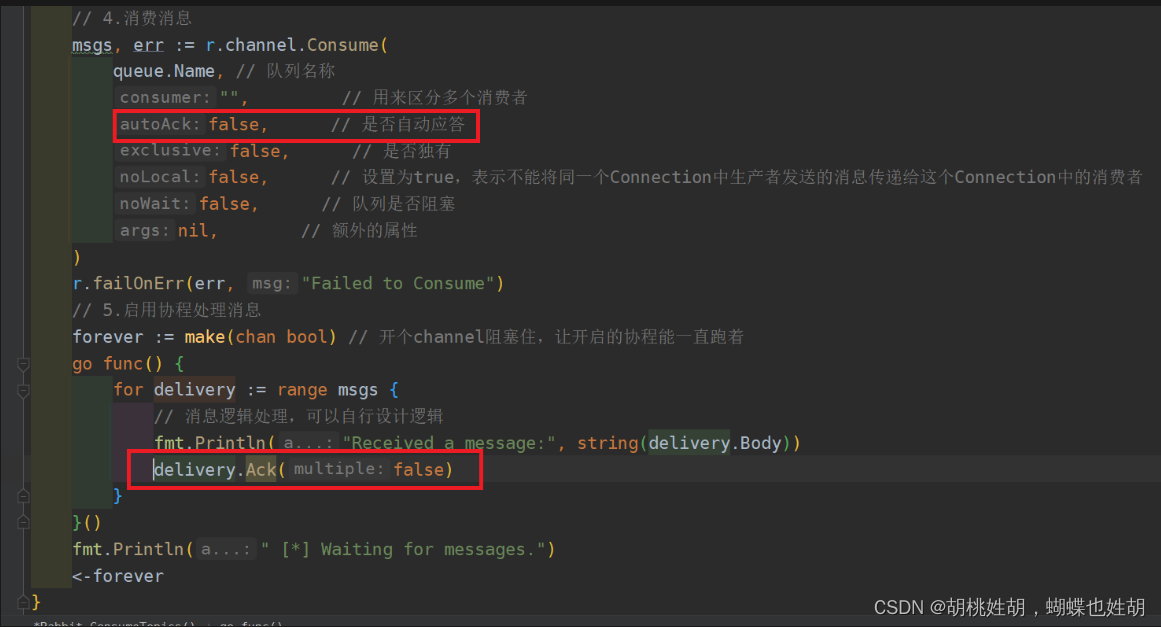
如果RabbitMQ一直没有接收到消费端的确认信号,且消费端已经断开链接或者宕机,此时RabbitMQ会将此消息重新放入队列,等待下次投递。因此消费端也需要做好消息幂等性的设置,确保消息重复处理机制。
总结:消息落库 + 定时任务 + 幂等性保证 + 重试机制 + 人工补偿
在事务之外执行消息发送,通过发送端confirm机制保证消息发送成功。
消费端消费消息,消费完成后进行手动ack, 这里也会出现ack时消息队列server突然宕机的情况,这时就需要保证消费端消费消息需要实现幂等(因为消息会被重发)。消息消费成功后将消息表中的消息状态设置为完成。
定时任务,定时扫描未处理的消息,进行消息重发,重发超过一定次数后标记为失败,转人工处理。
但是在互联网大厂中实际上还存在第二种常见的作法:
延迟投递,做二次确认,回调检查
回想第一种方案,生产段既要对业务数据入库,又要对消息数据入库,进行了两次入库持久化操作,这种设计在高并发场景下存在性能瓶颈。在核心链路上(注意,这里是核心链路,也就是上游服务,这个方法的落库总次数没有减少,只是上游服务的落库次数减少,服务性能高一点,用户体验感更好),每一次持久化都是要很精心考量的,持久化一次就要花费100 - 200毫秒,这在高并发场景下是无法忍受的。这个时候我们就需要第二种方案了:
其实我们在核心链路中只需要对业务进行入库就可以了,消息就没有必要入库了,我们可以做消息的延迟投递,做二次确认,回调检查。
所以这一种方案的本质目的是减少数据库操作,提高并发量。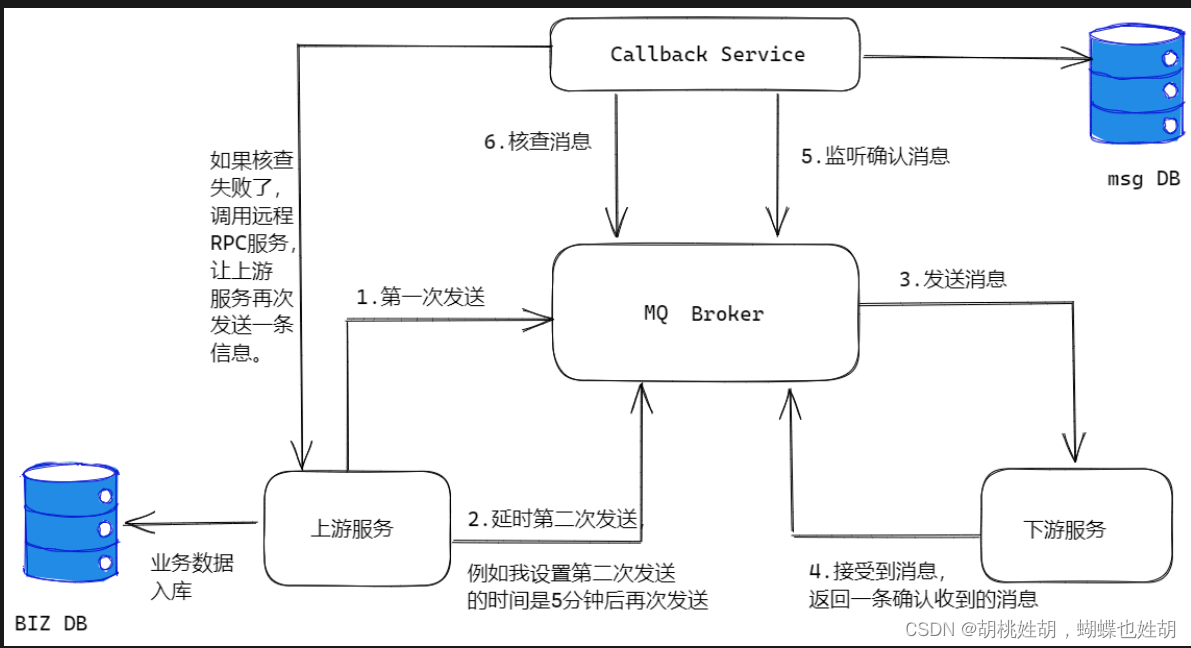
来阐述一下步骤:
- 先将业务消息进行入库,然后生产端将消息发送出去,注意一定是等数据库操作完成以后再去发送消息。
- 在发送消息之后,紧接着生产端再次发送一条消息
(Second Send Delay Check),即延迟消息投递检查,这里需要设置一个延迟时间,比如5分钟之后进行投递 - 消费端去监听指定队列,将收到的消息进行处理。
- 处理完成之后,发送一个
confirm消息,也就是回送响应,但是这里响应不是正常的ACK,而是重新生成一条消息,投递到MQ中。 - 上面的
Callback service是一个单独的服务,其实它扮演了第一种方案的存储消息的DB角色,它通过MQ去监听下游服务发送的confirm消息,如果Callback service收到confirm消息,那么就对消息做持久化存储,即将消息持久化到DB中。 - 5分钟之后延迟消息发送到MQ了,然后
Callback service还是去监听延迟消息所对应的队列,收到Check消息后去检查DB中是否存在消息,如果存在,则不需要做任何处理,如果不存在或者消费失败了,那么Callback service就需要主动发起RPC通信给上游服务,告诉它延迟检查的这条消息我没有找到,你需要重新发送,生产端收到信息后就会重新查询业务消息然后将消息发送出去。
这样做的目的是让上游服务少做一次DB的存储,下游服务做一下无所谓,因为我削峰了。而且不要求实时性,典型的就是订单这个业务场景。
当然,针对分布式系统本身的一些问题,我们通过搭建集群解决,搭建集群导致的另外一些问题这里不详细展开谈。
代码实现我会放在GitHub上面。
版权归原作者 胡桃姓胡,蝴蝶也姓胡 所有, 如有侵权,请联系我们删除。