
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀**对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于大数据的学习成绩可视化系统
设计思路
一、课题背景与意义
随着信息技术的快速发展和教育数据的积累,大量的学生学习成绩数据被收集和存储。然而,这些数据往往以原始的形式存在,难以直观地理解和分析。因此,开发一个基于大数据的学习成绩可视化系统具有重要的意义。该系统可以通过可视化方式展示学生的学习情况、学科间的关联性和学生群体的表现,帮助教育工作者和决策者更好地理解学生的学习状况,提供个性化的教育支持和决策依据,促进教育质量的提升。
二、算法理论原理
2.1 网络爬虫
数据网络爬虫是一项强大的技术,它通过自动化地访问网页、提取数据和存储数据,为我们获取和分析大量的信息提供了便利。通过数据网络爬虫,我们可以快速而准确地收集各种类型的数据,包括文本、图像、视频等。这些数据可以用于市场调研、商业智能、科学研究等领域,帮助我们了解市场趋势、发现潜在机会和挑战,以及支持决策制定过程。数据网络爬虫是一种自动化工具,用于通过网络收集数据。它通过发送HTTP请求到目标网站,并解析网页内容,提取所需的数据。数据爬虫可以帮助我们获取大量的数据,并为后续的数据分析和处理提供基础。
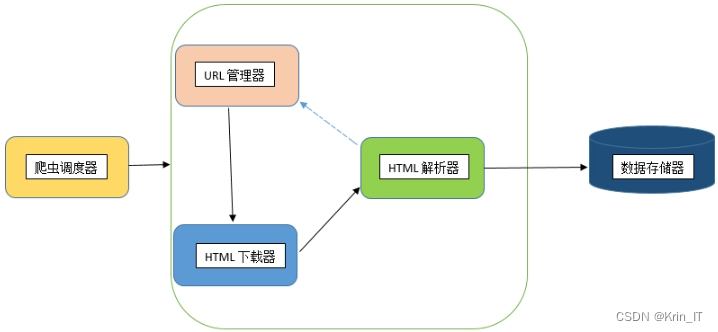
数据的采集过程包括数据爬取、数据清洗、数据分析和数据展示。数据挖掘技术通过网络爬虫从特定页面中获取完整的数据,并使用BS4框架提取页面的主题和标记。数据清洗阶段对采集到的数据进行初步加工和整理,剔除不合格的数据。数据处理利用已有的Spark运算符对清洗后的数据进行各种计算和操作,最终将结果存储在数据库中。数据展示部分使用Spring Boot框架,通过控制层、服务层和数据层对数据进行访问,并提供可视化的反馈。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
# 创建SparkSession
spark = SparkSession.builder.appName("DataProcessing").getOrCreate()
# 读取数据集
df = spark.read.csv("students_scores.csv", header=True, inferSchema=True)
# 数据清洗和转换
# 假设需要过滤掉分数小于60的学生
df_cleaned = df.filter(col("score") >= 60)
# 进行各种计算和操作
# 假设需要计算平均分数和及格人数
average_score = df_cleaned.agg({"score": "avg"}).collect()[0][0]
pass_count = df_cleaned.count()
# 打印结果
print("Average Score:", average_score)
print("Pass Count:", pass_count)
# 将结果存储到数据库
df_cleaned.write.format("jdbc").option("url", "jdbc:mysql://localhost:3306/mydatabase").option("dbtable", "processed_data").option("user", "username").option("password", "password").save()
2.2 随机森林算法
随机森林算法在学习成绩可视化系统中的应用十分广泛。它可以通过利用历史学生成绩数据和其他相关因素(如出勤率、作业完成情况等)建立预测模型,帮助教育者及时发现学生可能面临的困难,并采取相应的干预措施。此外,随机森林算法还能确定学生成绩的主要影响因素,通过构建模型并评估特征的重要性,找出对学生成绩具有最大影响的因素。它还可以对学生成绩进行分类,训练一个分类器用于对新的学生成绩进行分类,帮助教育工作者评估和分类学生的学术表现,并为他们提供相应的反馈和支持。同时,随机森林算法可为学习成绩可视化系统提供数据分析和可视化的支持,通过将算法结果与可视化技术结合,以图表、图形等形式呈现学生成绩数据,使教育者和学生更直观地理解和分析成绩数据。
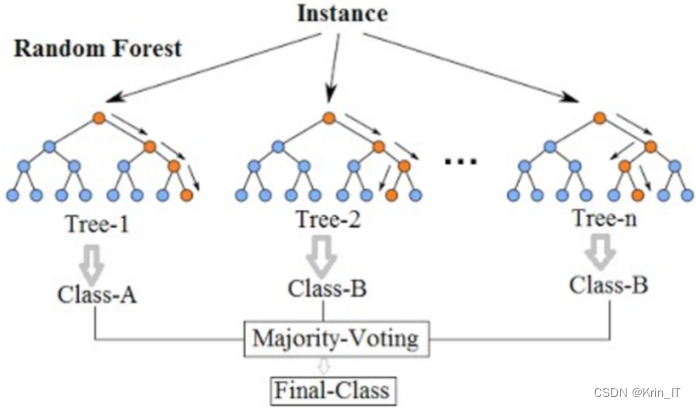
随机森林算法的基本原理是通过构建多个决策树,并利用这些决策树的集体智慧进行预测。每个决策树都是独立构建的,且每个决策树都是在随机选择的特征子集上进行训练的。这种随机性的引入使得每棵树都具有差异性,减少了过拟合的风险。在构建随机森林时,首先从原始数据集中随机选择一个样本集,称为自助采样集。然后,基于这个自助采样集构建一个决策树,并重复这个过程多次,形成多棵决策树。在构建每棵决策树的过程中,每个节点的分裂特征都是从一个随机选择的特征子集中选取的。最后,通过集体智慧,将所有决策树的预测结果进行综合,得出最终的预测结果或分类结果。
三、检测的实现
3.1 数据集
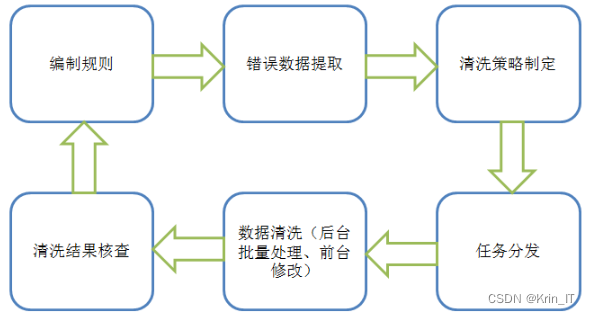
由于网络上没有现有的合适的数据集,我决定自己进行网络爬取来收集相关数据。通过爬取教育平台和学校网站,我获取了大量学生的学习成绩数据,并进行了整理和清洗。这个自制的数据集包含了学生的课程成绩、学科评价、学习时长等信息。通过网络爬取,我能够获得真实的学生学习数据,使得我的研究更具准确性和可靠性。
3.2 可视化分析
学习成绩可视化系统主要包括数据爬取、数据预处理、数据分析和可视化这四个关键部分。数据爬取阶段涉及从学校管理系统、在线学习平台等数据源中提取学生学习成绩数据的过程。随后,进行数据预处理,包括缺失值处理、异常值处理、数据转换和特征选择等,以确保数据的质量和准确性。接下来,进行数据分析,通过描述性统计、相关性分析、趋势分析和群体比较等方法,提取学生学习表现的洞察和信息。最后,利用可视化技术,将学习成绩数据以条形图、折线图、饼图等形式呈现,使教育者、学生和家长能够更直观地理解和分析数据。通过这些主要步骤,学习成绩可视化系统能够为教育者提供有价值的学生数据分析和决策支持。
相关代码示例:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 假设你已经准备好了特征和目标变量的数据集
X = # 特征数据
y = # 目标变量数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器
rf_classifier = RandomForestClassifier()
# 在训练集上训练分类器
rf_classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = rf_classifier.predict(X_test)
# 打印分类报告
print(classification_report(y_test, y_pred))
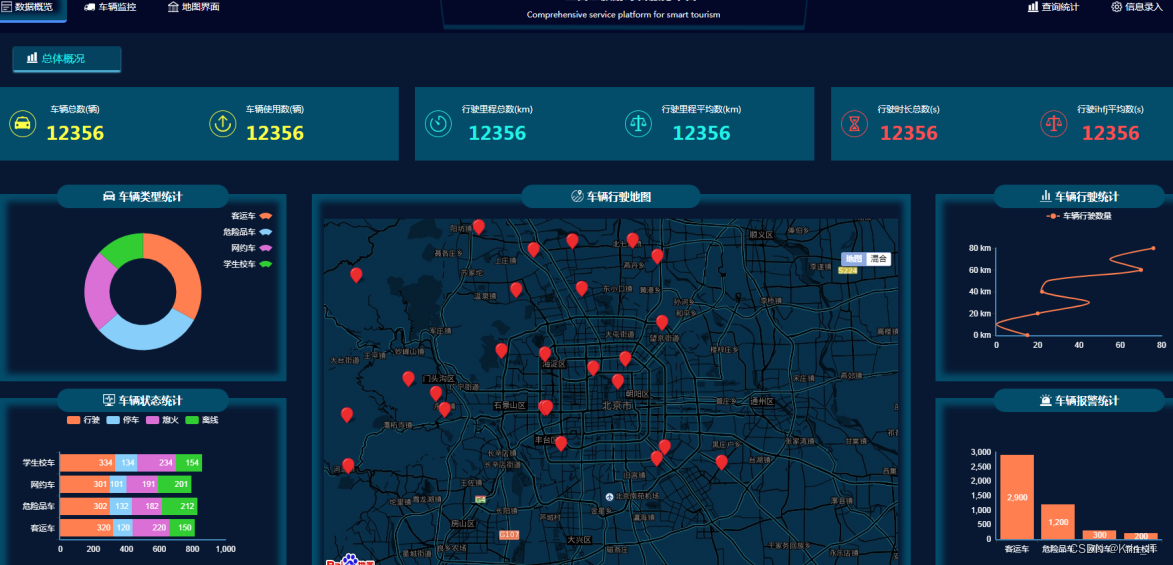
实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/136968211
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。