
ElasticSearch入门到进阶
初识ElasticSearch
ElasticSearch是一个搜索服务器
说到搜索,大家第一时间想到的是什么?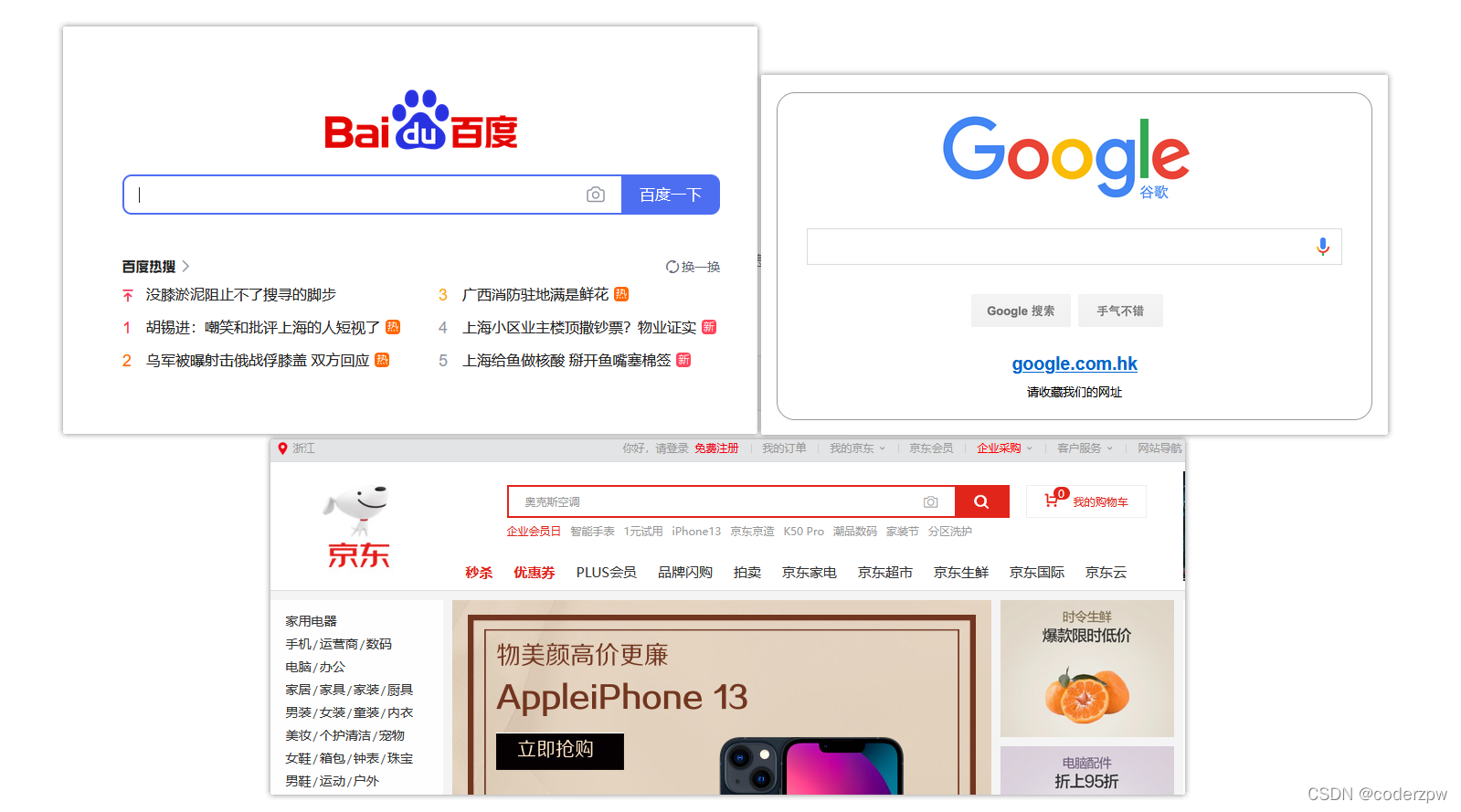
百度、谷歌、商城的搜索功能…
其实搜索就是查询。
select * from xxx where xxx like %xxx%
-> 关系型数据库
那么像上面 百度、谷歌、商城的搜索功能是使用关系型数据库来实现的吗? 答: 不是
为什么不是呢,那我们来说一下关系型数据库查询的问题
基于关系型数据库查询的问题
以下表为例
1、查询 title 中包含 ‘手机’ 的信息?
SELECT * FROM goods title like '%手机%'
该语句从语义上来说确实是没有问题的。
但是我们都知道,在使用模糊查询,左边有通配符情况下,是不会走索引的,会全表扫描,性能低
2、查询 title 中包含 ‘华为’ 或者 ‘手机’ 的信息?
SELECT * FROM goods title like '%华为手机%'
其实我们想要查询的是 包含华为 或者 包含手机 的信息,那么我们用上述的SQL语句肯定是查询不出来的。
我们 在京东上搜一下“华为手机” 看一下效果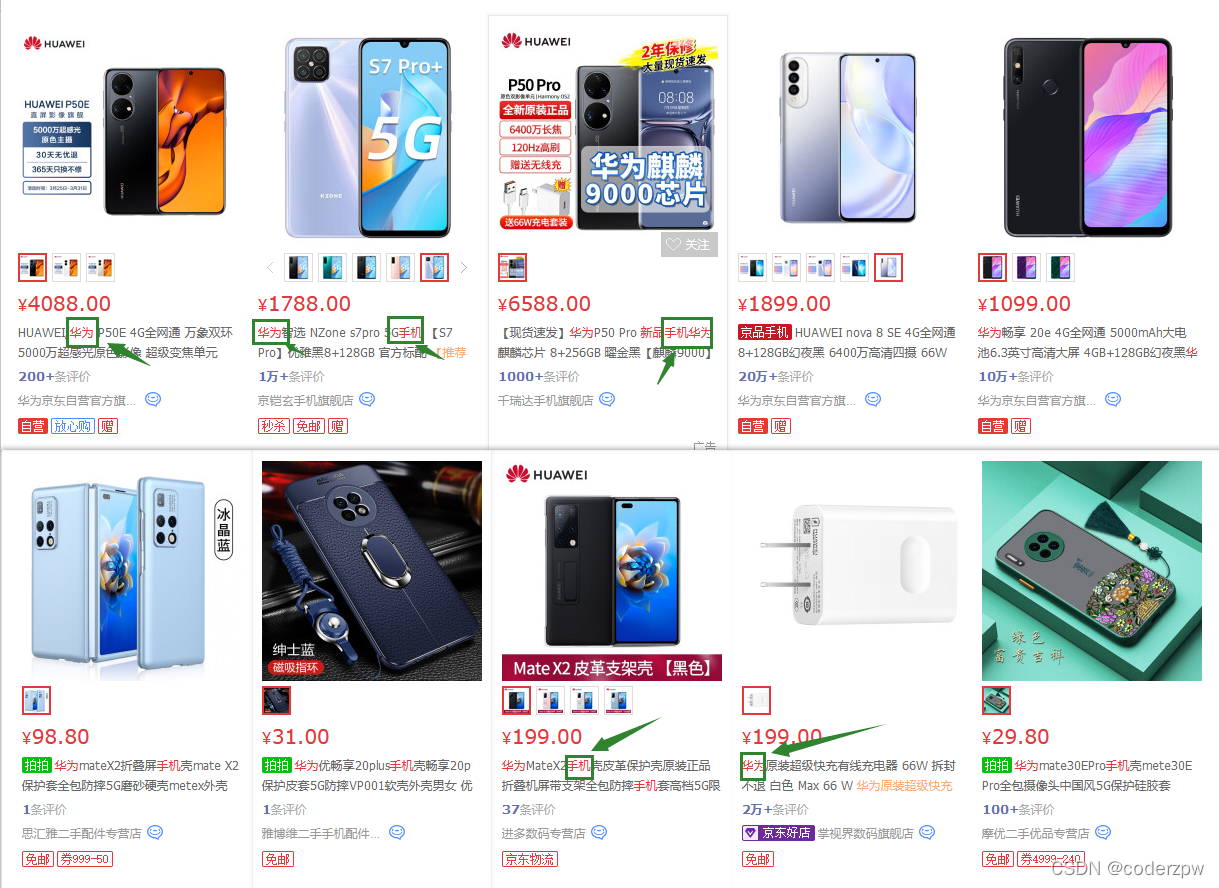
我们会发现搜索出来的内容有 包含
华为
或者
手机
或者
华为手机
这几个关键字的信息
但是如果我们使用关系型数据库,进行模糊查询的话,是比较难实现这个功能的(可以实现,但是相对来说比较复杂)
所以使用关系型数据来实现的查询, 功能是比较弱的
正是因为在海量的数据中执行搜索功能时,使用关系型数据库会出现性能弱、功能低的问题。我们的ElasticSearch就应用而生了。
ElasticSearch - 概念介绍
概念:
ElasticSearch是一个基于Lucene的搜索服务器(Lucene:提供一套搜索的API,包含各种jar包、代码)- 是一个分布式、高扩展、高实时的搜索与数据分析引擎
- 基于RESTful web接口
- ElasticSearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎
- 官网:https://www.elastic.co/
应用场景:
- 搜索:海量数据的查询
- 日志数据分析
- 实时数据分析
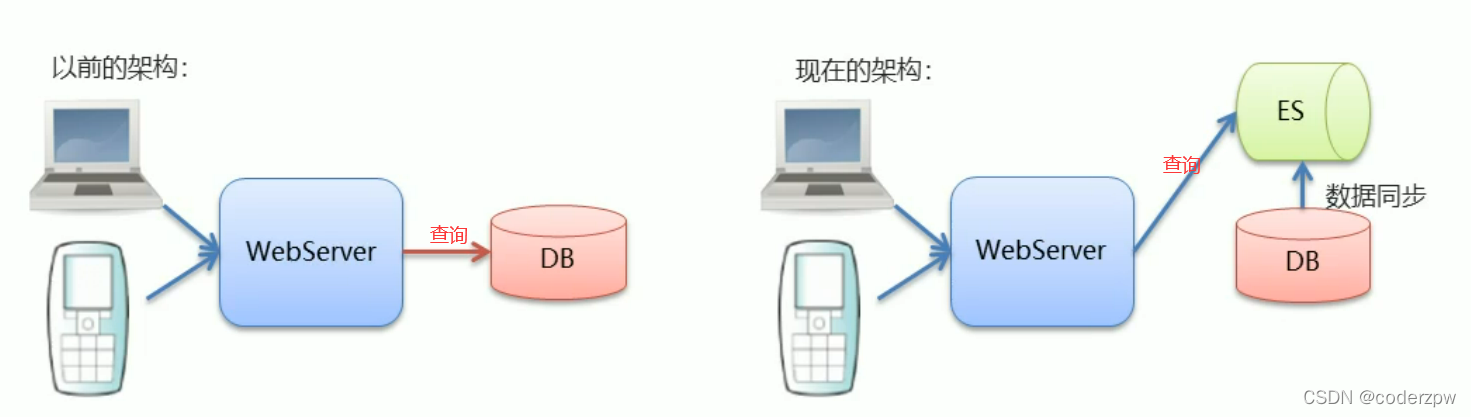
ElasticSearch 与 MySQL
- MySQL有事务性,而ElasticSearch 没有事务性,所以你删了的数据是无法恢复的
- ElasticSearch 没有物理外键的这个特性,如果你的数据强一致性要求比较高,还是建议慎用
- ElasticSearch 和 MySQL分工明确,MySQL负责存储数据,ElasticSearch 负责搜索数据
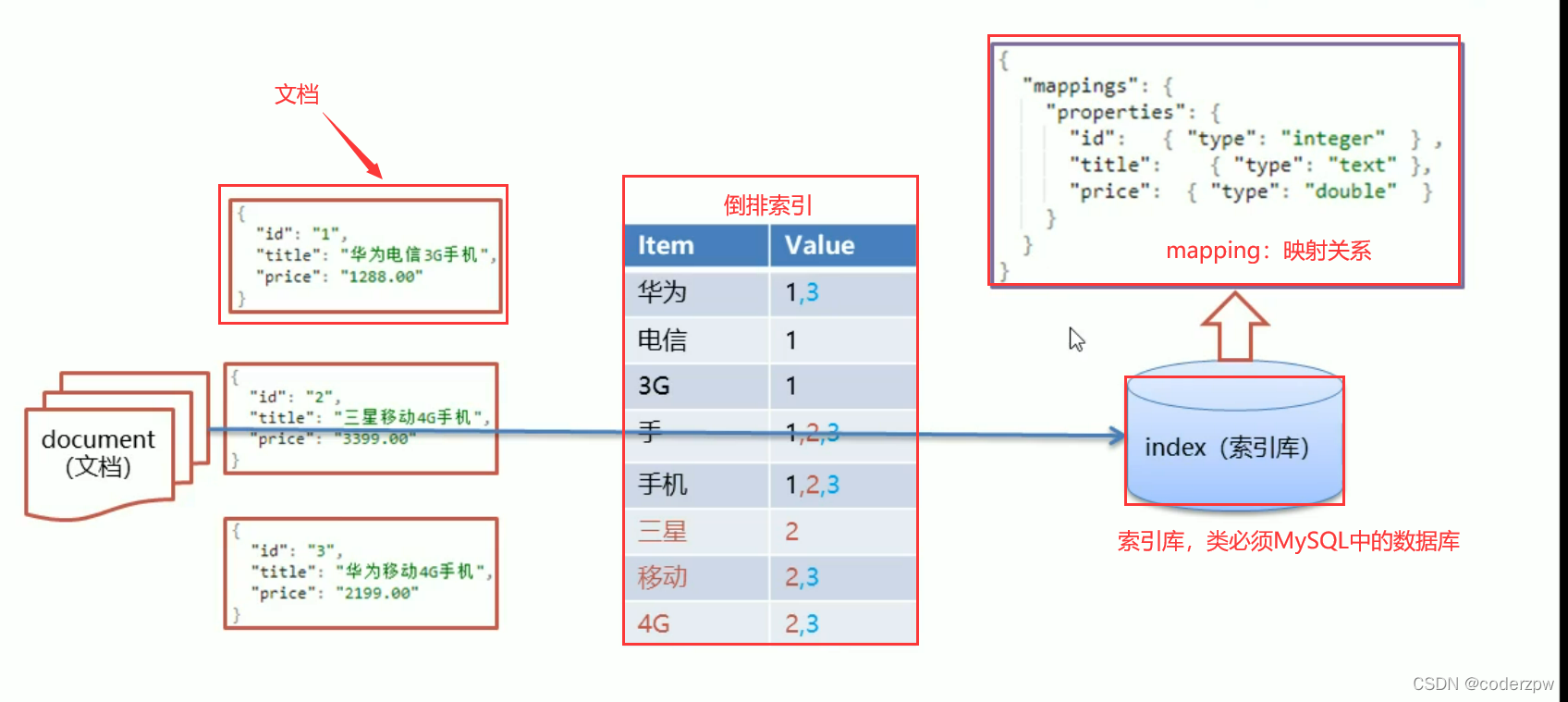
ElasticSearch - 倒排索引
正向索引:
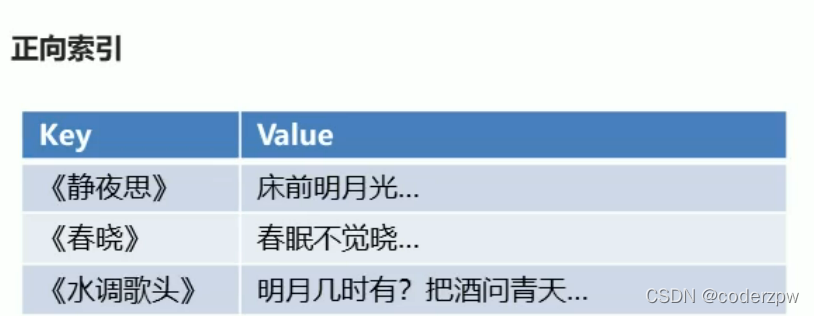
key存储唯一标识符 ,value就存储对应的值
倒排索引:
倒排索引:将各个文档中的内容,进行分词,形成词条。然后记录词条和数据唯一标识(id)的对应关系,形成的产物。
**就是将我们存储的数据进行
分词
,然后将文本按照一定的规则,拆分为不同的词条(term)**
例如, “床前明月光”、“明月几时有” 这两个诗句,按照倒排索引来存储
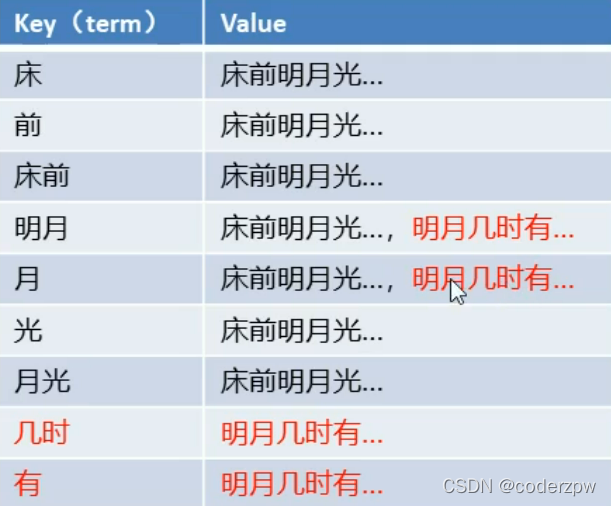
但实际是我们的value值并非存储的是实际的值,一般是对应的唯一标识(这里我们的唯一标识是题目)
ElasticSearch - 存储和查询的原理
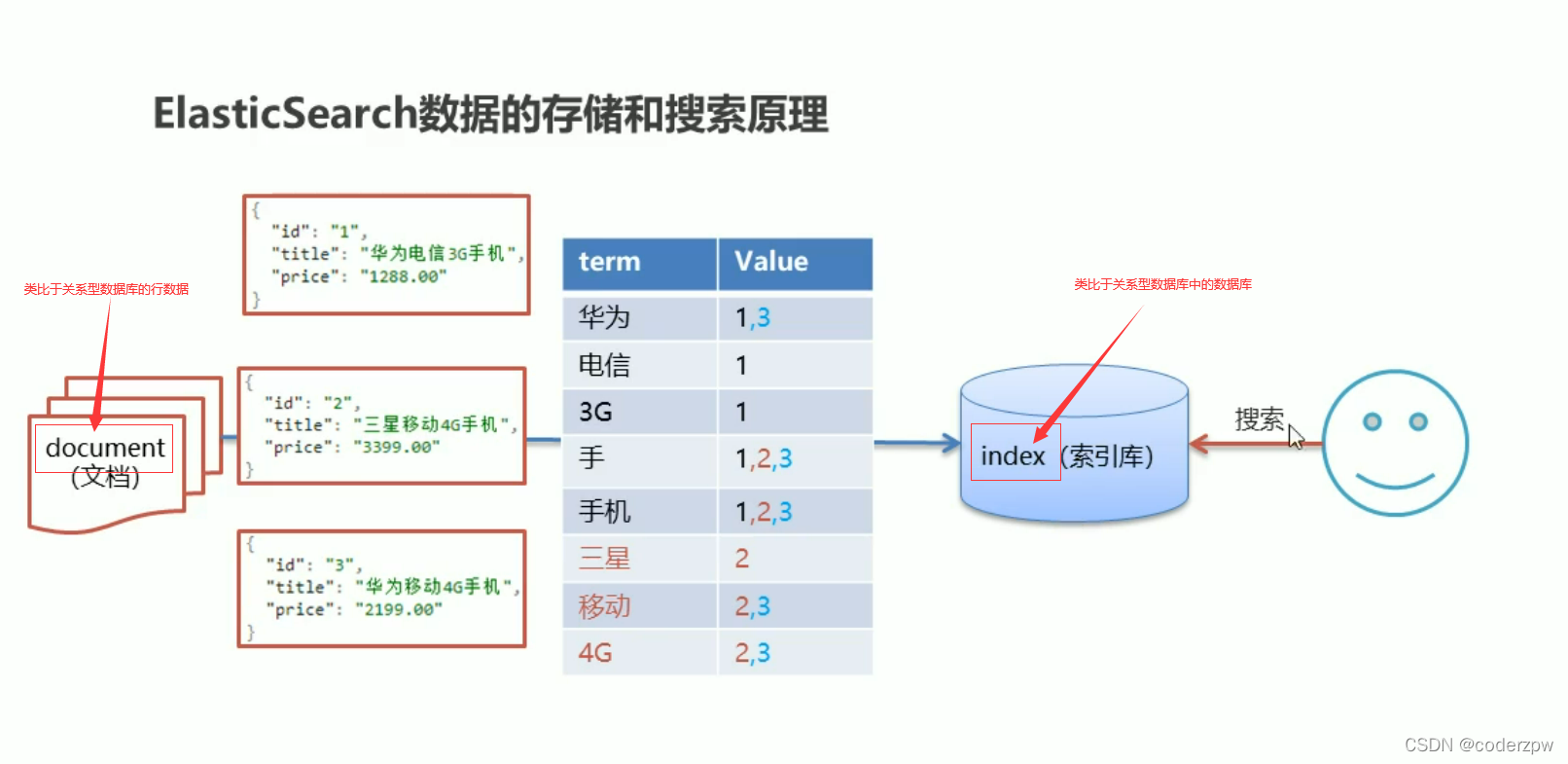
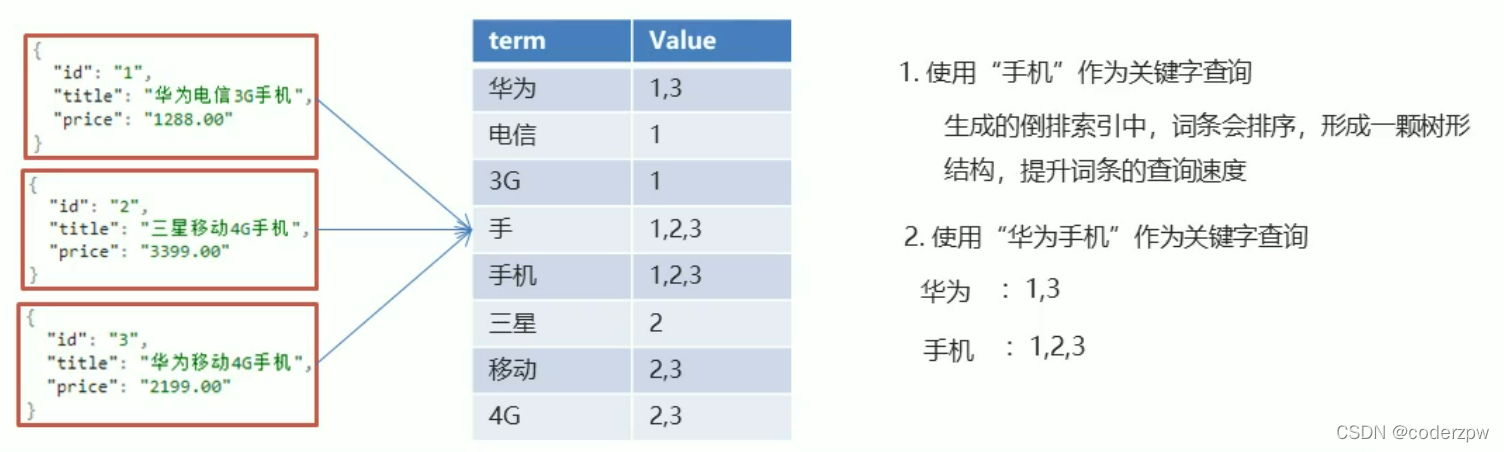
安装ElasticSearch
安装ElasticSearch
有一点需要强调,ElasticSearch是由Java开发的,而且内置有jdk,所有你部署的服务器最好是一个没有配置jdk的机器,否则会出现版本不一致等错误 或者 一些奇葩的错误
官网下载网址:
https://www.elastic.co/cn/downloads/?elektra=home&storm=hero
根据自己的需求下载不同的版本
下载完成后将,将下载后的xxx.tar.gz文件 上传到Linux服务器上(一般存放在/opt目录下)
解压安装包
tar -zxvf elasticsearch-7.16.2-linux-x86_64.tar.gz
elasticsearch相关的配置
解压完成之后,我们还需要修改一些配置
进入/opt/elasticsearch-7.16.2/config目录
vi elasticsearch.yml
将如下配置添加到elasticsearch.yml文件的尾部
cluster.name: my-elasticSearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
cluster.name:配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称
node.name: 节点名,elasticsearch会默认随机指定一个名字,建议指定一个有意义的名字,方便管理
network.host: 设置0.0.0.0允许外网访问
http.port: elasticsearch的http访问端口
cluster.initial_master_nodes: 初始化新的集群时需要此配置来选举master
创建用户、切换用户
es为了安全考虑,是不允许root用户来启动es,否则启动会报错
创建用户:
useradd es_coderzpw # 新增xxx用户passwd es_coderzpw # 为xxx用户设置密码
将elasticsearch的文件 授权给xxx用户:
chown -R es_coderzpw:es_coderzpw elasticsearch-7.16.2/
由于新创建的用户最大可创建文件数太小,虚拟机内存太小,我们来添加如下配置:
1、设置最大可创建文件大小
编辑limits.conf文件:
vi /etc/security/limits.conf
尾部添加如下内容:
es_coderzpw soft nofile 65536
es_coderzpw hard nofile 65536
编辑20-nproc.conf文件:
vi /etc/security/limits.d/20-nproc.conf
尾部添加如下内容:
es_coderzpw soft nofile 65536
es_coderzpw hard nofile 65536
* hard nproc 4096
2、设置最大虚拟机内存大小
编辑sysctl.conf文件:
vi /etc/sysctl.conf
尾部添加如下内容:
vm.max_map_count=655360
重新加载配置文件
sysctl -p
这些都修改完成之后,切换到es_coderzpw用户
su es_coderzpw # 切换用户
启动elasticsearch
进入到/opt/elasticsearch-7.16.2/bin目录
cd /opt/elasticsearch-7.16.2/bin
查看目录:
启动该服务
./elasticsearch
会有如下界面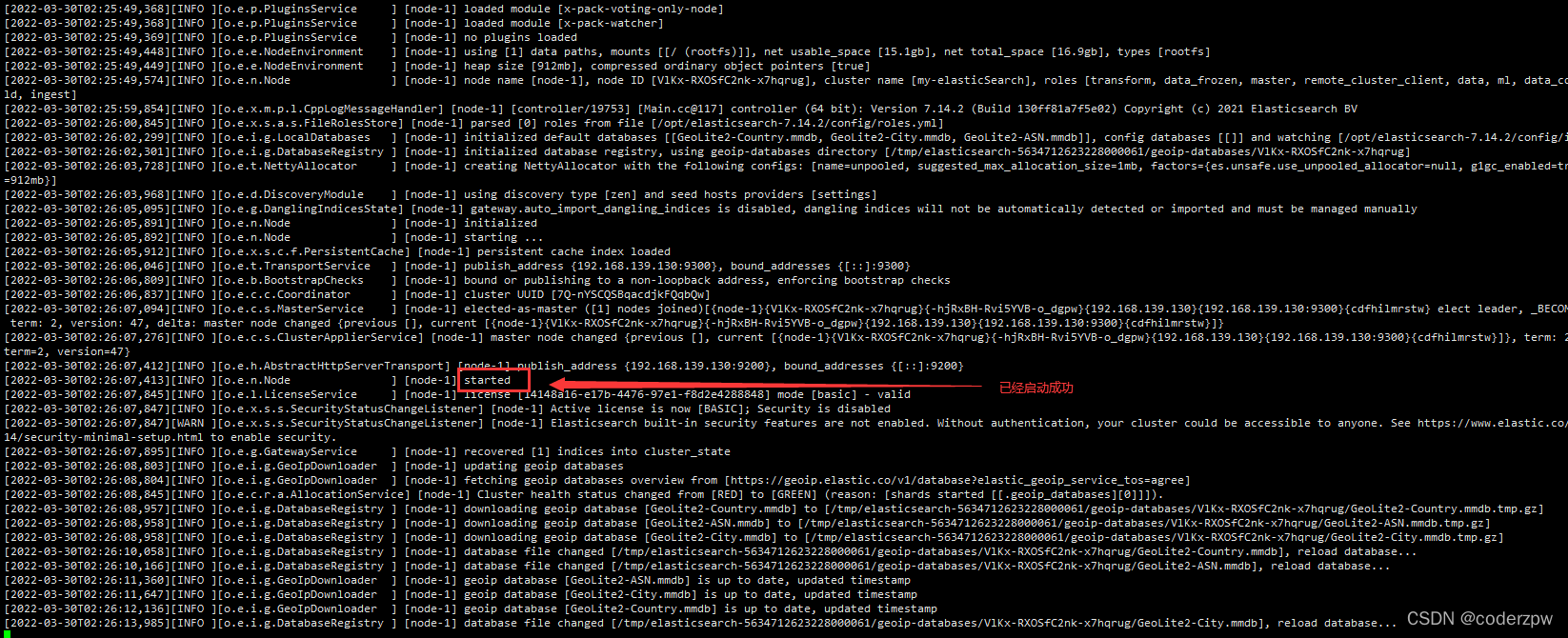
如果没报错,然后浏览器上访问:http://192.168.139.130:9200/
若出现如下信息,则启动成功
若访问不成功,查看一下是否是自己的服务器的防火墙未关闭的原因
安装Kibana
什么是Kibana?
Kibana是一个针对于ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示
Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示ElasticSearch查询动态。
下载安装
首先下载Kibana文件,并上传到Linux服务器上,一般放到/opt目录下
官网下载网址:
https://www.elastic.co/cn/downloads/?elektra=home&storm=hero
一般放入/opt目录下
解压kibana:
tar -zxvf kibana-7.16.2-linux-x86_64.tar.gz
修改kibana配置:
切换到kibana-7.16.2-linux-x86_64/config目录
cd /opt/kibana-7.16.2-linux-x86_64/config

编辑kibana.yml文件
vi kibana.yml
尾部添加如下内容:
server.port: 5601
server.host: "0.0.0.0"
server.name: "my-kibana"
elasticsearch.hosts: ["http://127.0.0.1:9200"]
elasticsearch.requestTimeout: 99999
启动Kibana服务
进入到/kibana-7.16.2-linux-x86_64/bin目录
cd /opt/kibana-7.16.2-linux-x86_64/bin

如果在root用户下启动其实还是会有问题的
但如果非要在root用户下启动也不是不可以,执行:
./kibana --allow-root
没报错,并出现如下提示就算是启动成功了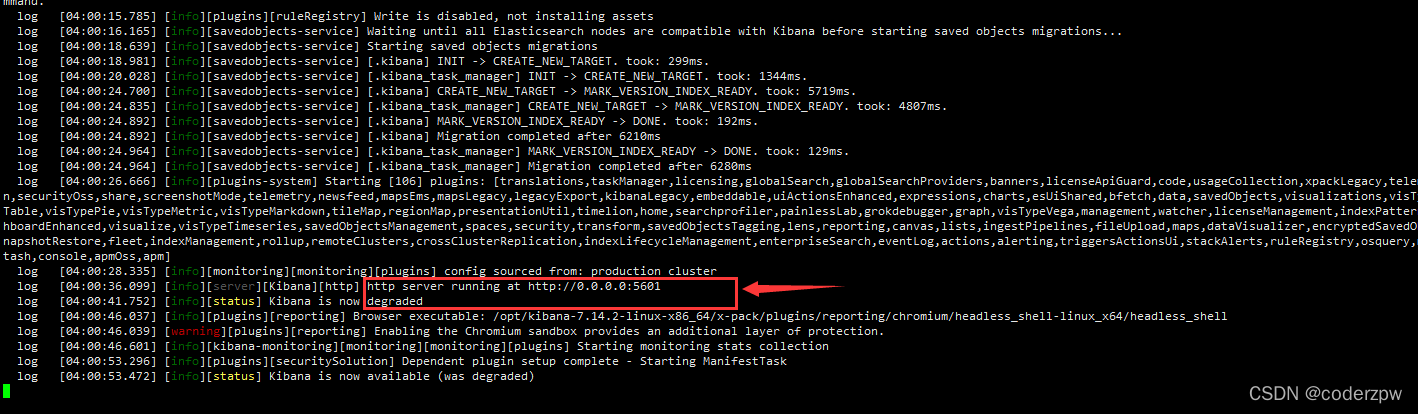
紧接着我们在浏览器上访问一下:http://192.168.139.130:5601/
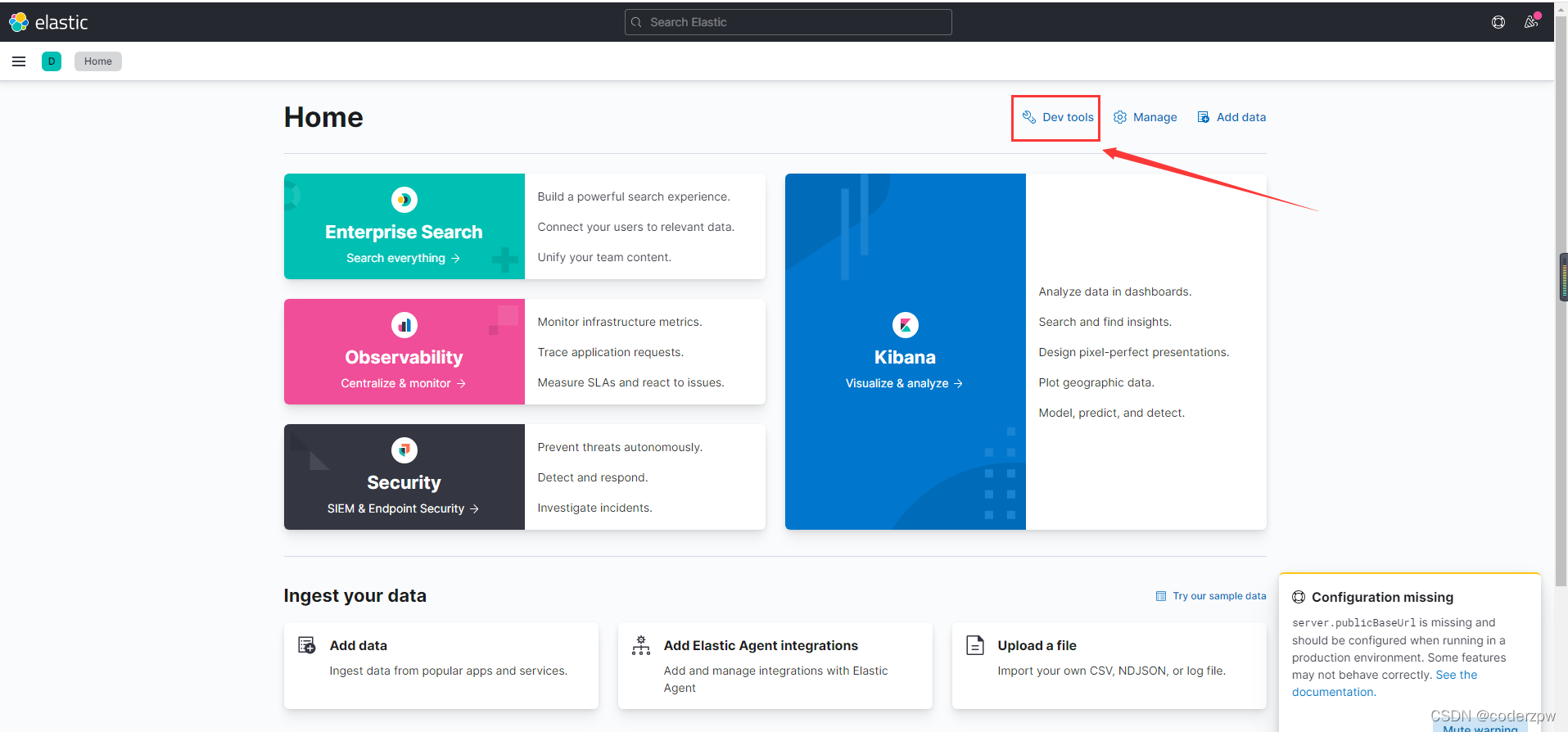
访问成功,然后点击箭头处的小扳手图标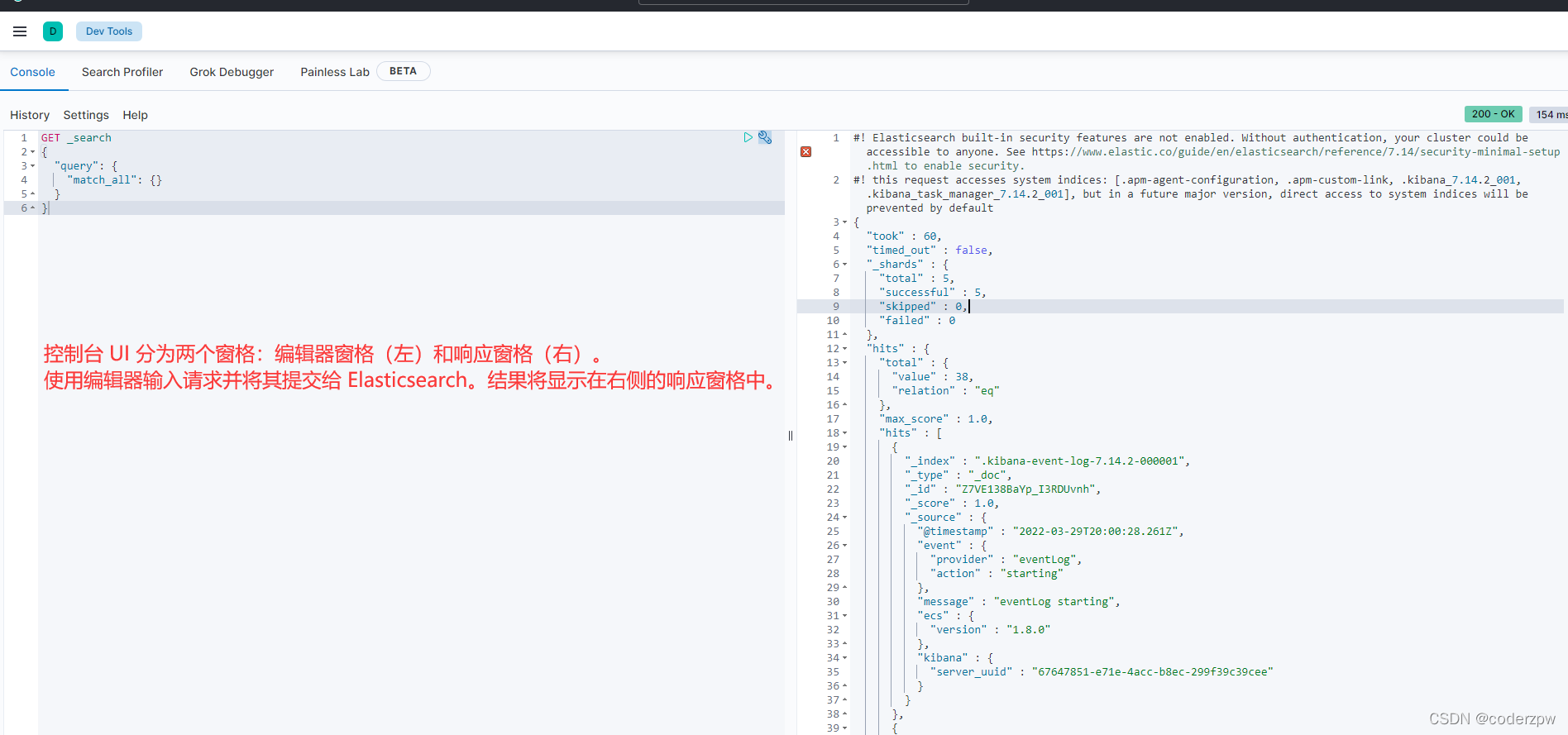
ElasticSearch核心概念
- 索引(index):ElasticSearch存储数据的地方,可以理解成关系型数据库中的数据库概念
- 映射(mapping):mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构
- 文档(document):ElasticSearch中的最小数据单元,常以json格式显示。一个document相当于关系型数据库中的一行数据
- 倒排索引:一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档id列表
- 类型(type):一种type就像一类表。如用户表、角色表等。在ElasticSearch7.X默认type为_doc - ES 5.x中一个index可以有多种type- ES 6.x中一个index只能有一种type- ES 7.x以后,将逐步移除type这个概念,现在的操作已经不再使用,默认_doc
操作ElasticSearch
RESTful风格介绍
REST(Representational State Transfer),表述性状态转移,是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或者设计就是RESTful。就是一组定义接口的规范。
满足要求:
- 可以使用XML格式定义或者JSON格式定义。
- 每一个URI代表一种资源
- 客户端使用GET、POST、PUT、DELETE4个表示操作方式的动词对服务端资源进行操作: - GET: 用来获取资源- POST:用来新建资源(也可以用于更新资源)- PUT:用来更新资源- DELETE:用来删除资源
脚本操作ES - 操作索引
添加索引
添加索引:
PUT 索引名称

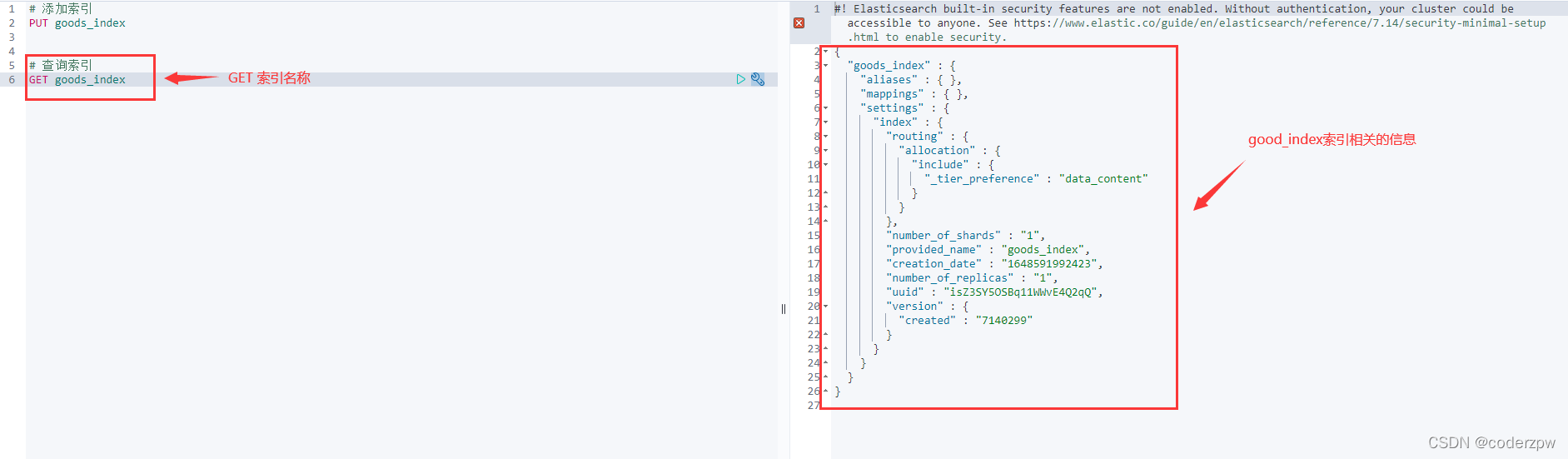
查询索引
查询索引:
GET 索引名称
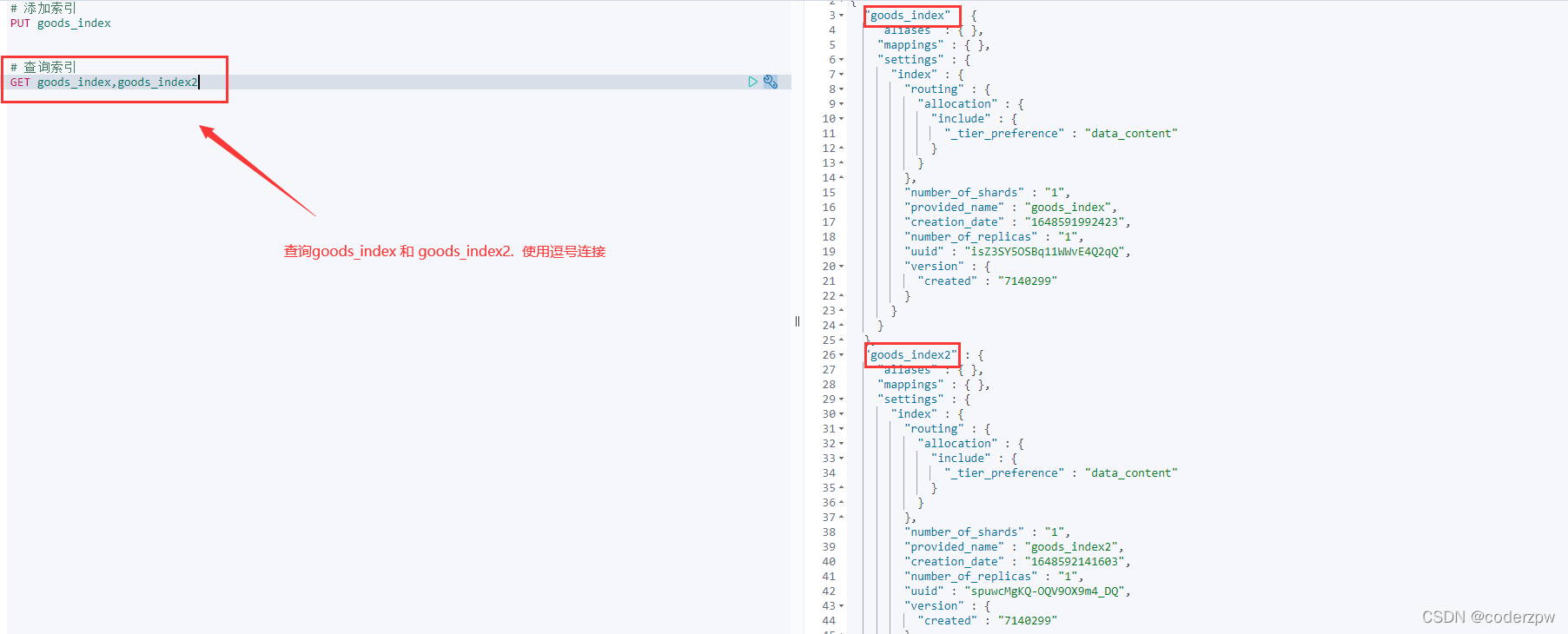
查询多个索引信息:
GET index1,index2
查询所有索引:
GET _all
一般以 _ 下划线开头的都是ES中的关键字
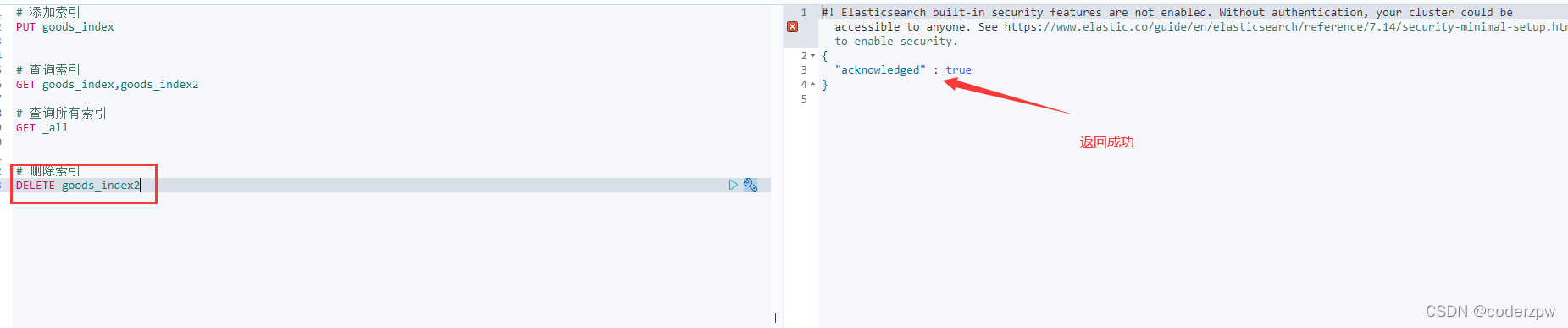
删除索引
删除索引:
DELETE 索引名称
脚本操作ES - 操作映射 - 数据类型
简单数据类型:
- 字符串 - text: 会分词(例如存储,“华为手机”,实际上存储“华为、手机”),不支持聚合- keyword: 不会分词(例如存储,“华为手机”,存储的就是“华为手机”),将全部内容作为一个词条,支持聚合
- 数值 - long: 带符号的64位整数- integer: 带符号的32位整数- short: 带符号的16位整数- byte: 带符号的8位整数- double: 双精度的64位小数- float: 单精度的32位小数- half_float:半精度的16位小数- scaled_float:由a支持的有限浮点数long,由固定double比例因子缩放
- 布尔 - boolean
- 二进制 - binary
- 范围类型 - integer_range、float_range、long_range、double_range、date_range
- 日期 - date
复杂数据类型:
- 数组:[]
- 对象:{}
脚本操作ES - 操作映射
添加映射
添加映射(索引已存在的情况):
PUT person/_mapping
{"properties":{"name":{"type":"keyword"},
"age":{"type":"integer"}}}
创建索引、同时添加映射:
PUT person
{"mappings":{"properties":{"name":{"type":"keyword"},
"age":{"type":"integer"}}}}
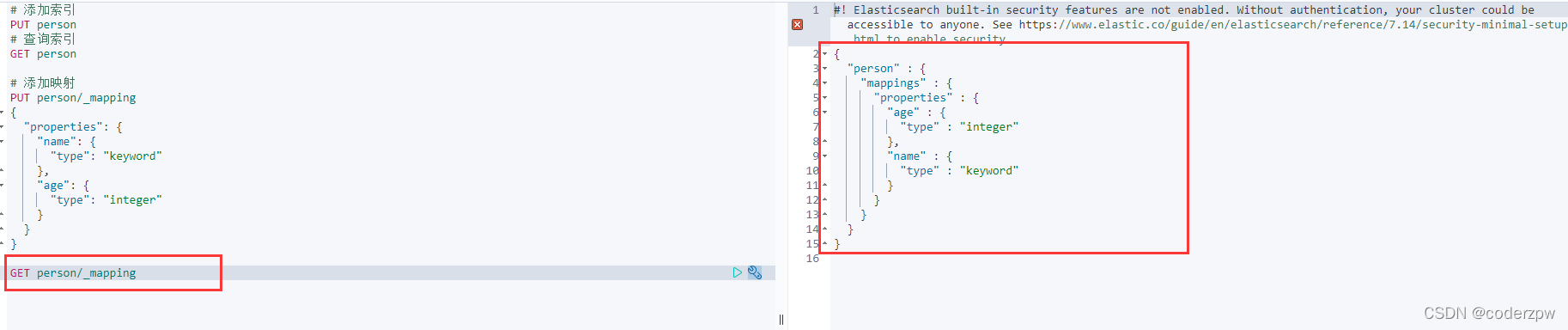
查询映射
查询映射:
GET person/_mapping
添加字段
为person的映射新增一个字段address
PUT person/_mapping
{"properties":{"address":{"type":"text"}}}
脚本操作ES - 操作文档
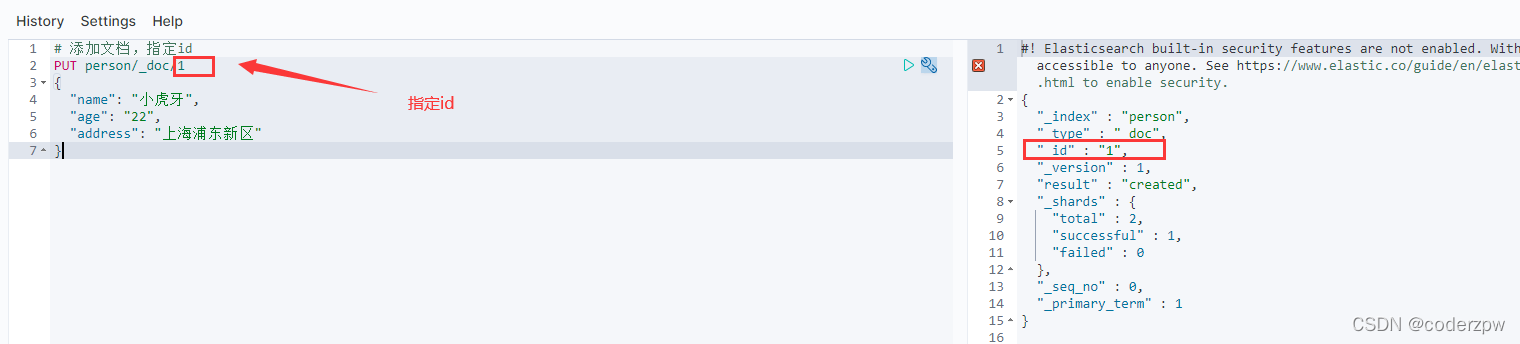
添加文档
# 添加文档,指定id
PUT person/_doc/1
{"name":"小虎牙",
"age":"22",
"address":"上海浦东新区"}
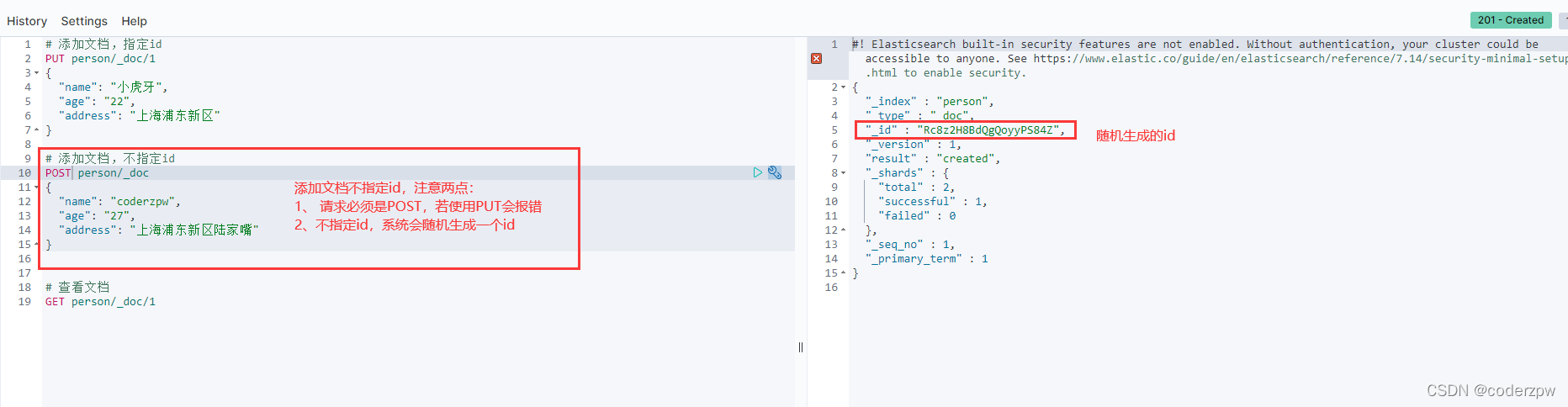
# 添加文档,不指定id
POST person/_doc
{"name":"coderzpw",
"age":"27",
"address":"上海浦东新区陆家嘴"}
查询文档
# 查看文档
GET person/_doc/1

# 查询所有文档
GET person/_search
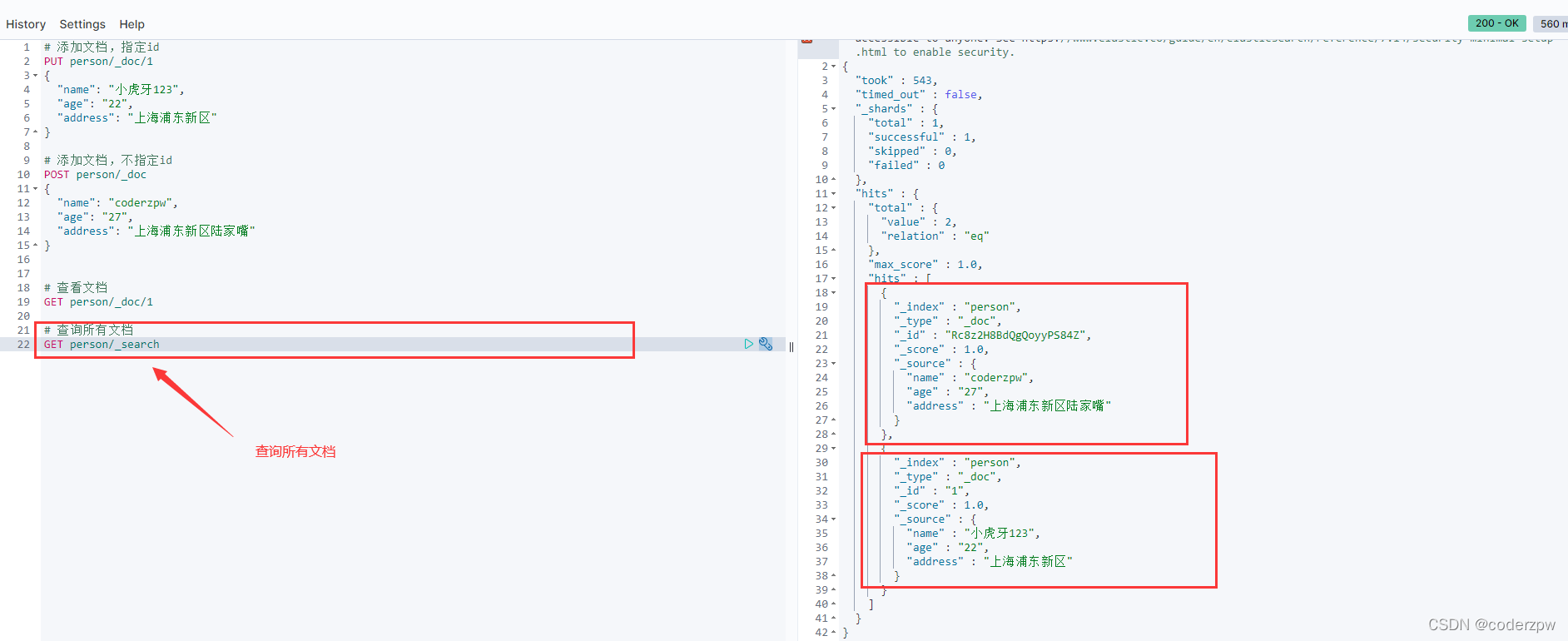
修改文档
修改其实很简单,还是之前的PUT命令 ,id存在的话就是修改
例如将id为1的name改成 “小虎牙123”
PUT person/_doc/1
{"name":"小虎牙123",
"age":"22",
"address":"上海浦东新区"}
删除文档
# 根据id删除文档
DELETE person/_doc/Rc8z2H8BdQgQoyyPS84Z
删除id为“Rc8z2H8BdQgQoyyPS84Z”的文档
分词器
ES的数据存到索引库之前需要先分词,形成分词、形成词条、形成倒排索引。
分词器(Analyzer):将一段文本,按照一定逻辑,分析成多个词语的一种工具。
如:华为手机 -> 华为、手、手机
- ElasticSearch内置分词器 - Standard Analyzer - 默认分词器,按词切分,小写处理 - Simple Analyzer - 按照非字母切分(符号被过滤),小写处理 - Stop Analyzer - 小写处理,停用词过滤(this,a,is) - 等
ElasticSearch内置分词器对中文很不友好,处理方式为:一个字一个词
接下来我们来测试一下,使用内置分词器对中文的分词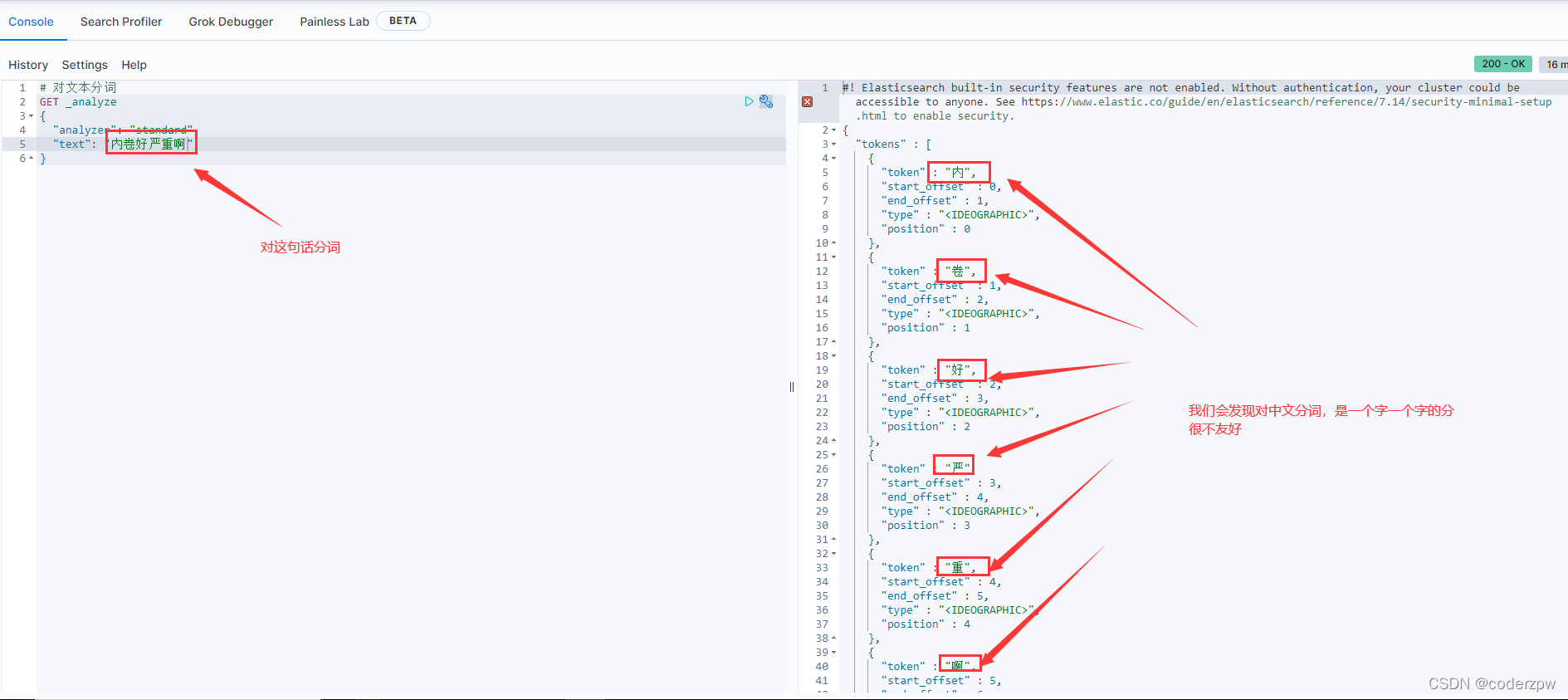
那么这样的东西呢,我们肯定不能在我们中文的环境下去使用了,很不方便。
我们要用的话,就需要安装一些中文的分词器,例如:IK分词器
IK分词器:
- IKAnalyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包
- 是一个基于Maven构建的项目
- 具有60万字/秒的高速处理能力
- 支持用户词典扩展定义
- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik
分词器 - IK分词器安装
1、环境准备
ElasticSearch要使用ik,就要先构建ik的jar包,这里要用到maven包管理工具,而maven需要Java环境,而ElasticSearch内置了jdk,所以可以将JAVA_HOME设置为ElasticSearch内置的jdk
设置JAVA_HOME
vi /etc/profile
#在文件末尾添加jdk的环境变量exportJAVA_HOME=/opt/elasticsearch-7.16.2/jdk
exportPATH=$PATH:${JAVA_HOME}/bin
#保存退出后,重新加载profilesource /etc/profile
下载maven安装包并解压
maven官网下载地址:https://maven.apache.org/download.cgi

MAVEN_HOME配置
编辑文件
vi /etc/profile.d/maven.sh
将下面的内容复制到文件,保存
exportMAVEN_HOME=/opt/apache-maven-3.8.5
exportPATH=${MAVEN_HOME}/bin:${PATH}
设置好Maven的路径之后,需要运行下面的命令使其生效
source /etc/profile.d/maven.sh
验证maven是否安装成功
mvn -v
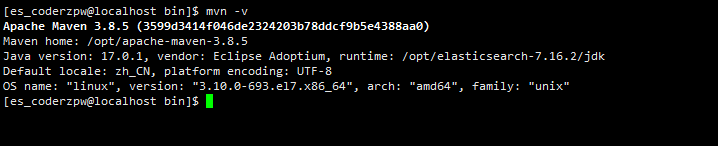
maven 安装成功
2、下载IK分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
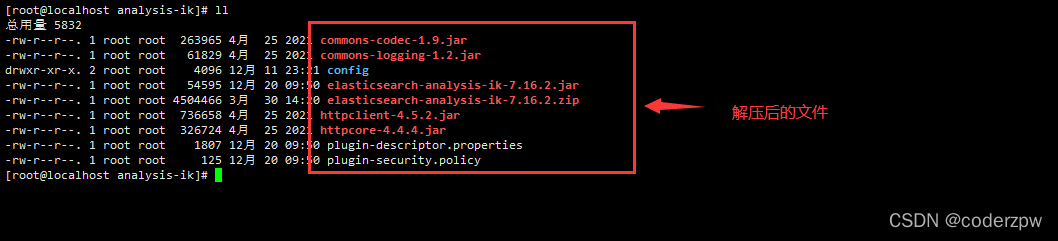
将安装包上传到Linux服务器,然后把zip包放到elasticsearch/plugins目录下创建的目录analysis-ik,并解压
然后解压ik分词器,因为ik分词器是zip包,所以需要使用unzip命令解压,如下图:
unzip elasticsearch-analysis-ik-7.16.2.zip
3、拷贝词典
解压之后需要把ik的config目录中的所有内容复制到elasticsearch-7.16.2的config配置文件中:
cp ./config/* /opt/elasticsearch-7.16.2/config
最后一定要重启 ElasticSearch!!!
分词器 - IK分词器使用
**IK分词器有两种分词模式:
ik_max_word和
ik_smart模式。**
1. ik_smart
这个分词模式的颗粒度比较粗,如下图: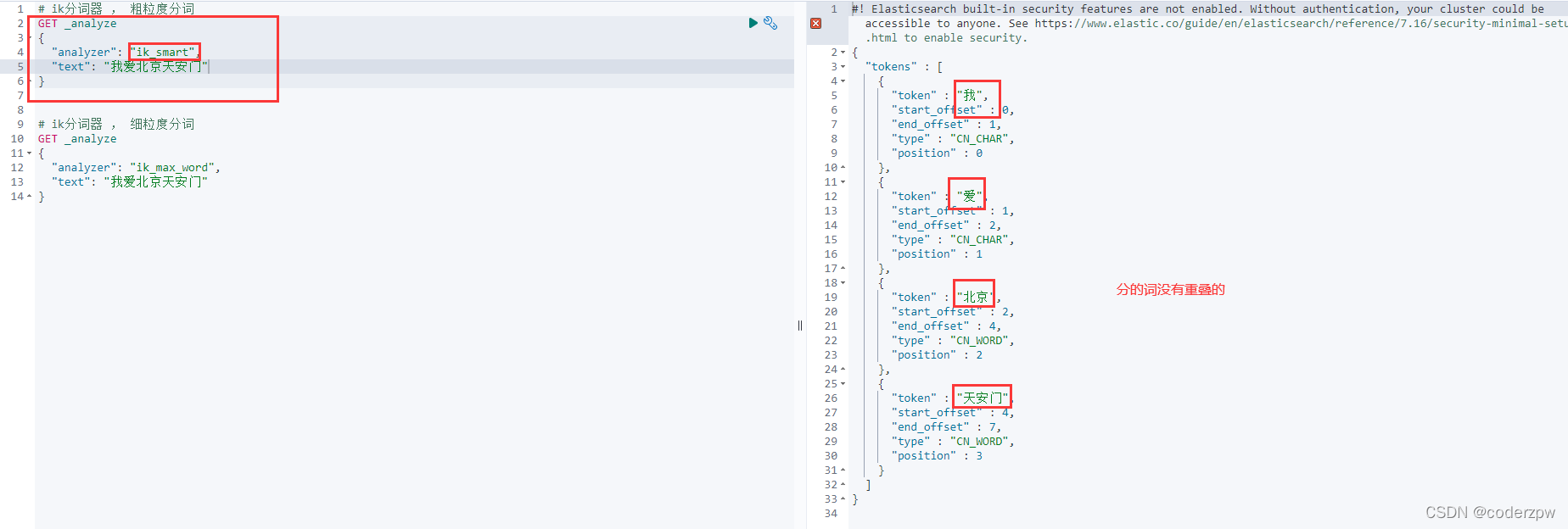
2. ik_max_word
这个分词模式的颗粒度比较细,如下图:
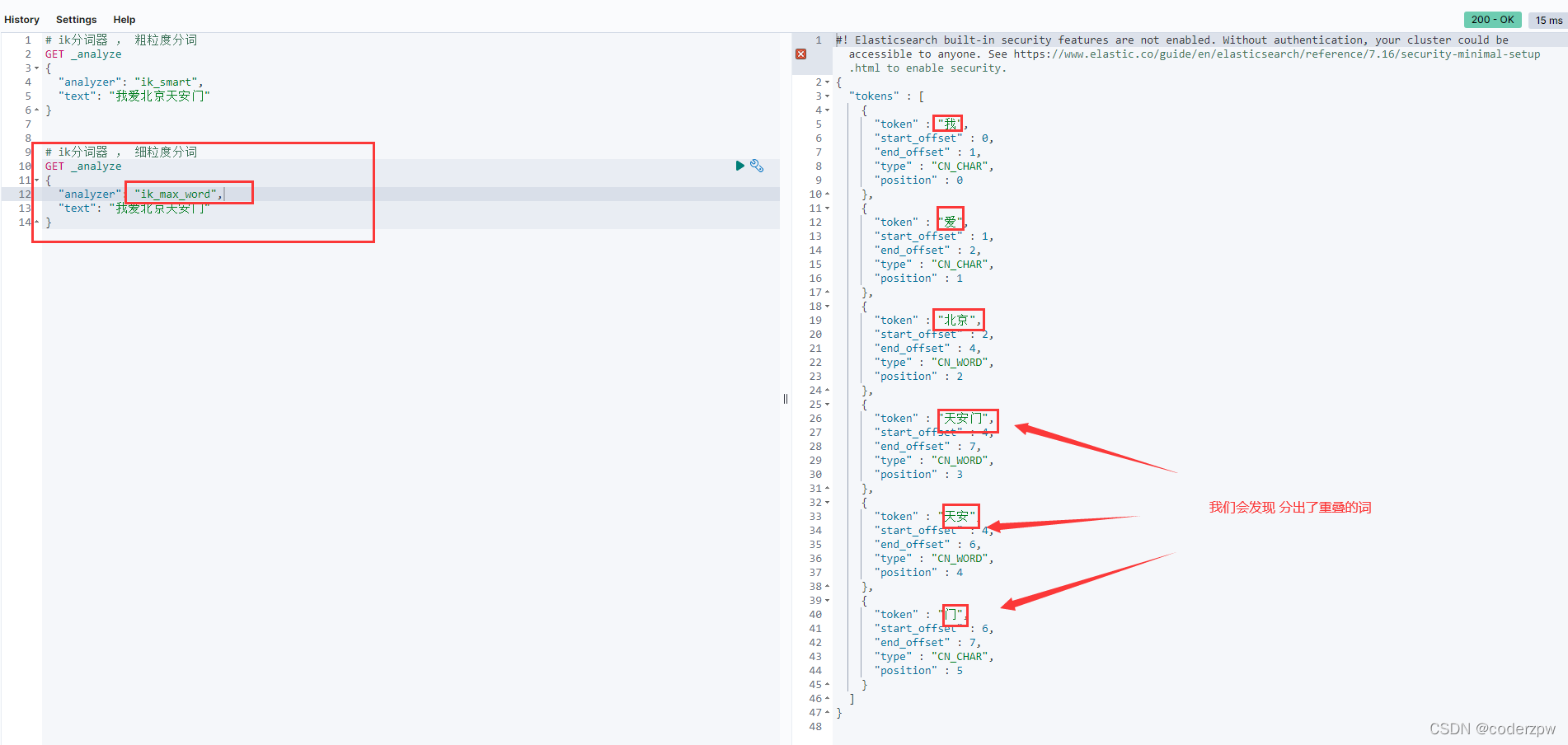
查询文档
创建索引,添加映射,指定使用IK分词器
# 创建索引,添加映射,指定使用IK分词器
PUT person
{"mappings":{"properties":{"name":{"type":"keyword"},
"address":{"type":"text",
"analyzer":"ik_max_word"}}}}
添加数据
# 添加文档
PUT person/_doc/1
{"name":"李四",
"address":"北京朝阳区"}
PUT person/_doc/2
{"name":"张三",
"address":"华为5G手机"}
PUT person/_doc/3
{"name":"麻子",
"address":"北京海淀区"}
PUT person/_doc/4
{"name":"王五",
"address":"上海昌平区"}
词条查询(term):词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才会搜索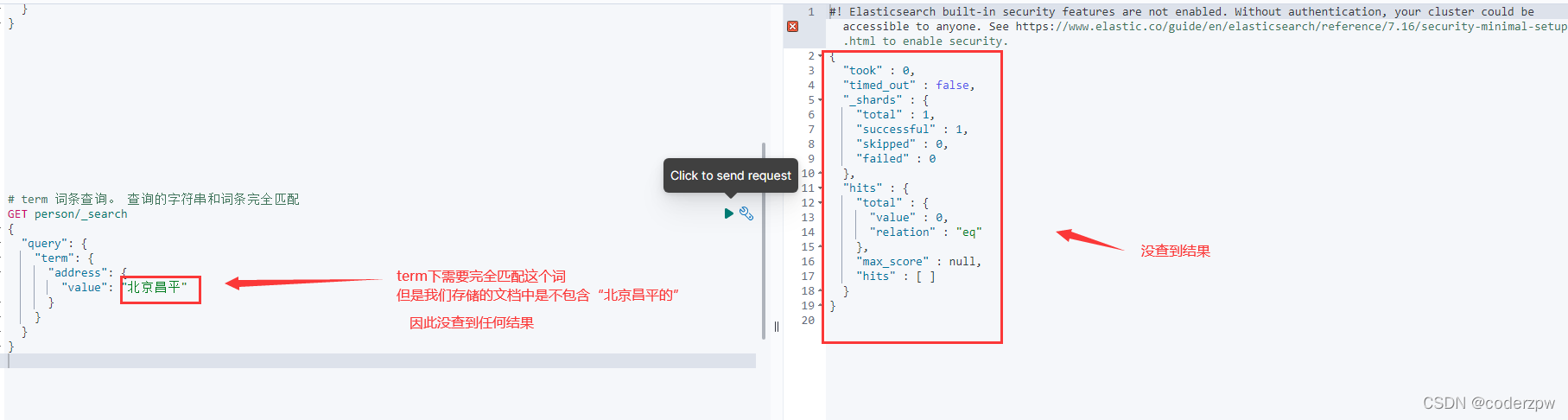
全文查询(match):全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集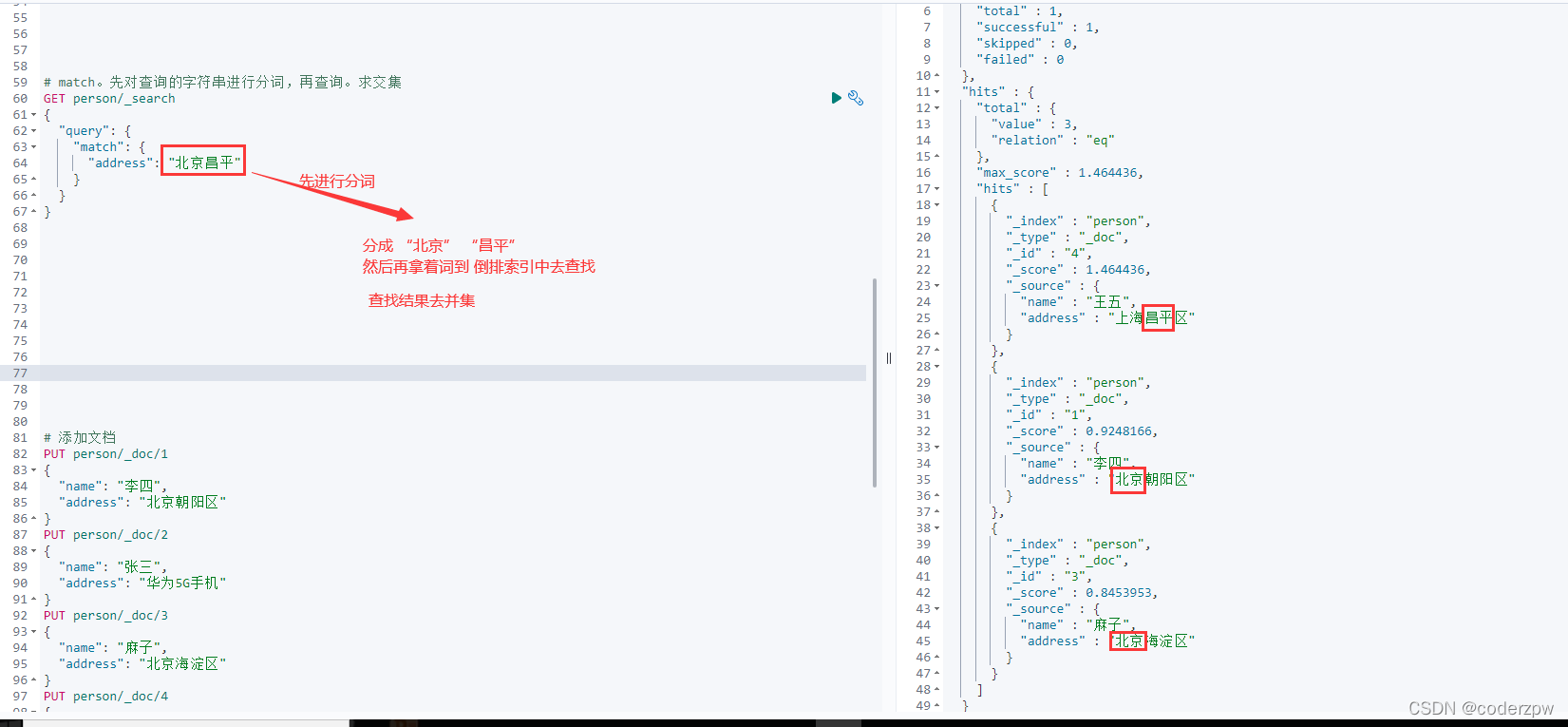
ElasticSearch JavaAPI
SpringBoot整合ElasticSearch
引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
配置客户端
@ConfigurationpublicclassElasticSearchConfigextendsAbstractElasticsearchConfiguration{@Override@BeanpublicRestHighLevelClientelasticsearchClient(){finalClientConfiguration clientConfiguration =ClientConfiguration.builder().connectedTo("192.168.139.130:9200")// ElasticSearch服务的ip端口号.build();returnRestClients.create(clientConfiguration).rest();}}
配置完这些后,就已经向spring容器中注入一个
RestHighLevelClient
的bean对象,后面我们可以通过该对象操作ES
Java API - 操作索引
首先在测试类中注入elasticsearchClient这个bean
@SpringBootTestclassSpringbootElasticsearchApplicationTests{@AutowiredprivateRestHighLevelClient elasticsearchClient;}
添加索引
创建索引:
/**
* 添加索引
*/@TestpublicvoidaddIndex()throwsIOException{// 1、通过elasticsearchClient获取操作索引的对象IndicesClient indices = elasticsearchClient.indices();// 2、具体操作,获取返回值CreateIndexRequest createRequest =newCreateIndexRequest("index1");CreateIndexResponse createIndexResponse = indices.create(createRequest,RequestOptions.DEFAULT);// 3、根据返回值判断结果System.out.println(createIndexResponse.isAcknowledged());}
我们到界面查询一下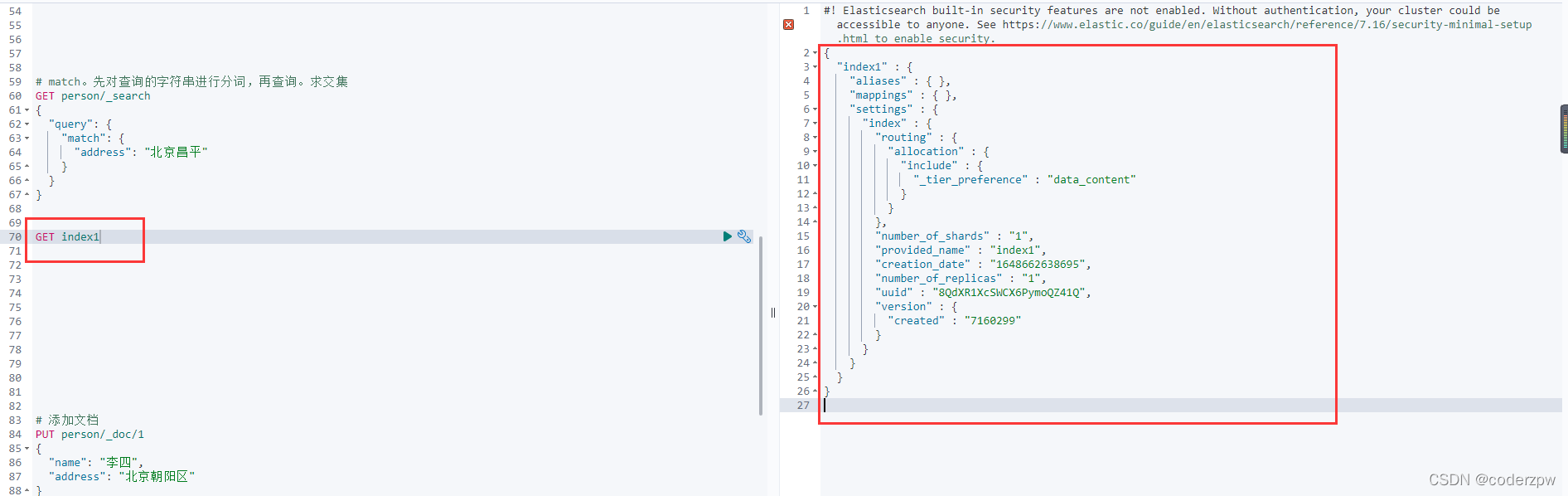
创建索引的同时设置映射信息:
/**
* 添加索引的同时 添加映射
*/@TestpublicvoidaddIndexAndMapping()throwsIOException{// 1、通过elasticsearchClient获取操作索引的对象IndicesClient indices = elasticsearchClient.indices();// 2、具体操作,获取返回值CreateIndexRequest createRequest =newCreateIndexRequest("index2");// 映射json字符串, 跟在Kibana 语法格式一致, 因此可以现在Kibana上写好 再粘贴过来String mapping =" {\n"+" \"properties\": {\n"+" \"name\": {\n"+" \"type\": \"keyword\"\n"+" },\n"+" \"address\": {\n"+" \"type\": \"text\",\n"+" \"analyzer\": \"ik_max_word\"\n"+" }\n"+" }\n"+" }";
createRequest.mapping(mapping,XContentType.JSON);CreateIndexResponse createIndexResponse = indices.create(createRequest,RequestOptions.DEFAULT);// 3、根据返回值判断结果System.out.println(createIndexResponse.isAcknowledged());}
界面查询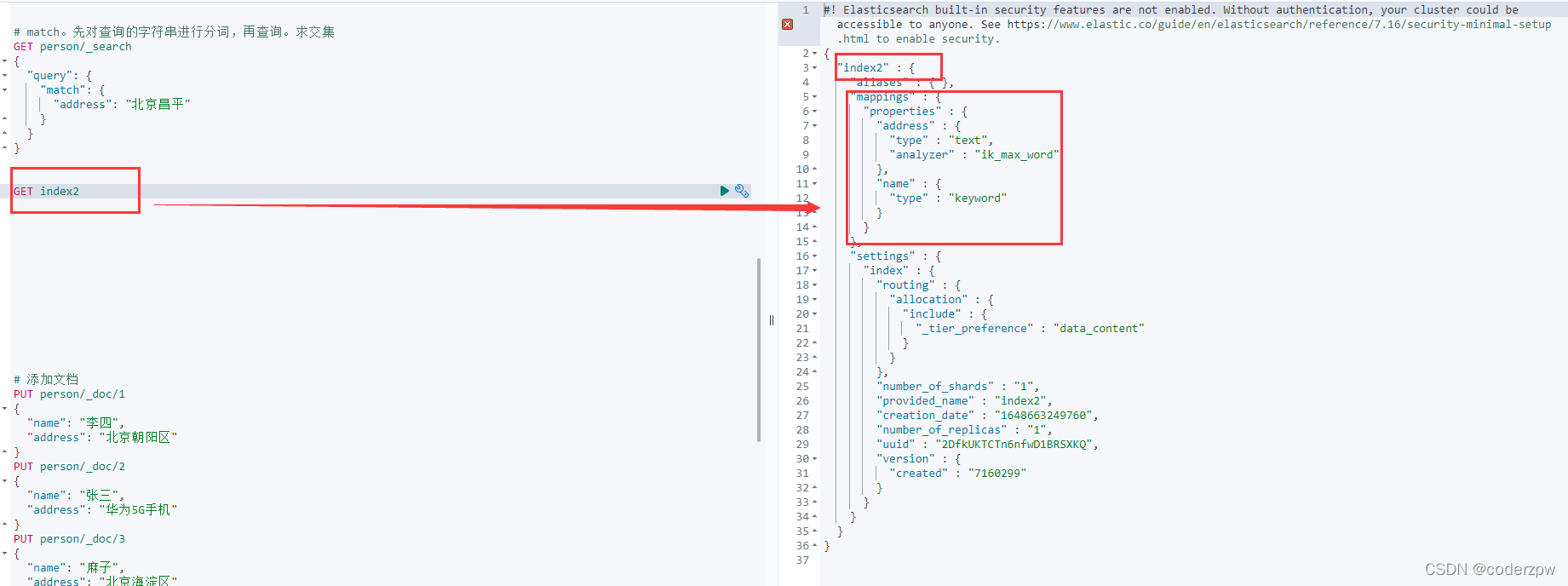
查询索引
/**
* 查询索引
*/@TestpublicvoidqueryIndex()throwsIOException{// 1、通过elasticsearchClient获取操作索引的对象IndicesClient indices = elasticsearchClient.indices();GetIndexRequest getRequest =newGetIndexRequest("index1");GetIndexResponse response = indices.get(getRequest,RequestOptions.DEFAULT);// 这里我们获取该索引对应的映射Map<String,MappingMetadata> mappings = response.getMappings();}
删除索引
/**
* 删除索引
*/@TestpublicvoiddeleteIndex()throwsIOException{// 1、通过elasticsearchClient获取操作索引的对象IndicesClient indices = elasticsearchClient.indices();DeleteIndexRequest deleteRequest =newDeleteIndexRequest("index1");AcknowledgedResponseResponse= indices.delete(deleteRequest,RequestOptions.DEFAULT);System.out.println(Response.isAcknowledged());}
判断索引是否存在
/**
* 判断索引是否存在
*/@TestpublicvoidexistIndex()throwsIOException{// 1、通过elasticsearchClient获取操作索引的对象IndicesClient indices = elasticsearchClient.indices();GetIndexRequest getRequest =newGetIndexRequest("index1");boolean exists = indices.exists(getRequest,RequestOptions.DEFAULT);System.out.println(exists);}
操作文档
添加文档
添加map数据
/**
* 添加文档 - map类型数据
*/@TestpublicvoidaddDoc()throwsIOException{// 数据对象 mapHashMap<String,Object> data =newHashMap<>();
data.put("name","李星云");
data.put("address","苗疆");// 1、 获取操作文档的对象IndexRequest request =newIndexRequest("person")// 指定添加在哪个索引中.id("8")// 指定id.source(data);// 添加数据,获取结果IndexResponse response = elasticsearchClient.index(request,RequestOptions.DEFAULT);// 打印响应结果System.out.println(response.getId());}
添加json数据
/**
* 添加文档 - json字符串类型数据
*/@TestpublicvoidaddDoc2()throwsIOException{// 数据对象 json字符串Person person =newPerson();
person.setName("袁天罡");
person.setAddress("不良人,藏兵谷");// Javabean -> json字符串String data = JSON.toJSONString(person);// 1、 获取操作文档的对象IndexRequest request =newIndexRequest("person")// 指定添加在哪个索引中.id("9")// 指定id.source(data,XContentType.JSON);// 添加数据,获取结果IndexResponse response = elasticsearchClient.index(request,RequestOptions.DEFAULT);// 打印响应结果System.out.println(response.getId());}
修改文档
修改文档: 添加文档时,若id存在则修改,id不存在则添加(这里就不做演示了)
查询文档
/**
* 根据id查询文档
*/@TestpublicvoidfindDocById()throwsIOException{GetRequest getRequest =newGetRequest("person","9");// 获取person索引库下 id为9的文档GetResponse response = elasticsearchClient.get(getRequest,RequestOptions.DEFAULT);System.out.println(response.getSourceAsString());// getSourceAsString(): 获取数据对应的json}
删除文档
/**
* 根据id删除文档
*/@TestpublicvoiddeleteDocById()throwsIOException{DeleteRequest deleteRequest =newDeleteRequest("person","9");// 获取person索引库下 id为9的文档DeleteResponse response = elasticsearchClient.delete(deleteRequest,RequestOptions.DEFAULT);System.out.println(response.getId());}
ElasticSearch高级操作
批量操作
Bulk批量操作是将文档的增删改查一系列操作,通过一次请求全都做完。减少网络传输的次数。
批量操作 - 脚本

示例:
# 批量操作# 1. 删除5号记录# 2. 添加8号记录# 3. 修改2号记录 名称为“二号”
POST _bulk
{"delete":{"_index":"person", "_id":"5"}}{"create":{"_index":"person", "_id":"8"}}{"name":"上官婉儿", "address":"大唐王朝"}{"update":{"_index":"person", "_id":"2"}}{"doc":{"name":"二号"}}
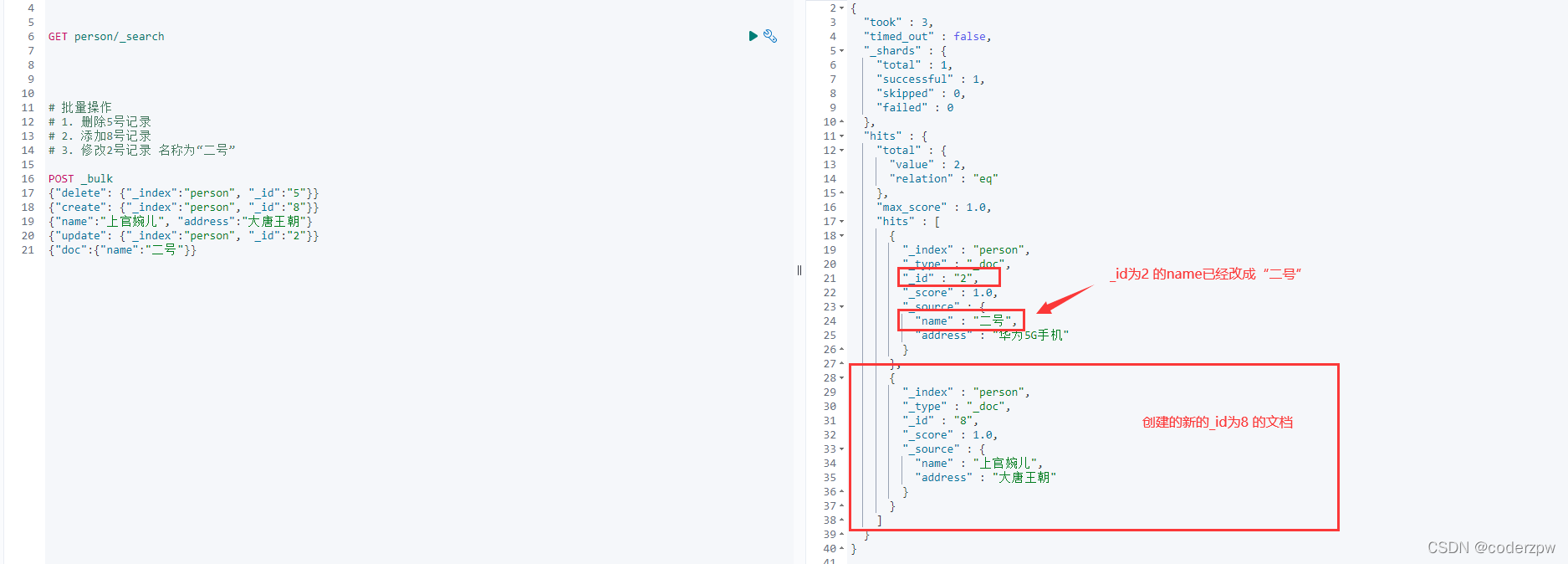
批量操作 - JavaAPI
/**
* 批量操作 bulk
*/@TestpublicvoidtestBulk()throwsIOException{// 一、创建bulkrequest对象,整合所有操作BulkRequest bulkRequest =newBulkRequest();/*
# 1、删除2号记录
# 2、添加6号记录
# 3、修改8号记录, 名称为"三号"
*/// 1、删除2号记录DeleteRequest deleteRequest =newDeleteRequest("person","2");// 2、添加6号记录HashMap<String,Object> map1 =newHashMap<>(); map1.put("六号","华夏");IndexRequest indexRequest =newIndexRequest("person").id("6").source(map1);// 3、修改8号记录, 名称为"八号"HashMap<String,Object> map2 =newHashMap<>(); map2.put("name","八号");UpdateRequest updateRequest =newUpdateRequest("person","8").doc(map2);// 二、把上面三个请求 添加到bulkRequest对象中
bulkRequest.add(deleteRequest);
bulkRequest.add(indexRequest);
bulkRequest.add(updateRequest);// 三、通过elast客户端发送请求icsearchClient
elasticsearchClient.bulk(bulkRequest,RequestOptions.DEFAULT);}
查看结果:
导入数据
目标: 将mysql中goods表中的数据导入到ES中
goods表结构: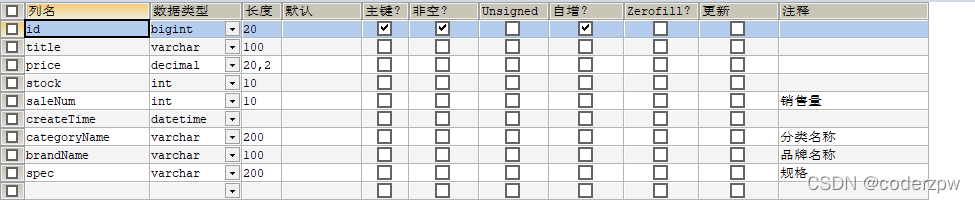
表数据:
根据表结构在ES中创建对应索引:
PUT goods
{"mappings":{"properties":{"title":{"type":"text","analyzer":"ik_smart"},"price":{"type":"double"},"createTime":{"type":"date"},"categoryName":{"type":"keyword"},"brandName":{"type":"keyword"},"spec":{"type":"object"},"saleNum":{"type":"integer"},"stock":{"type":"integer"}}}}
创建对应的domain类:
publicclassGoods{privateint id;privateString title;privatedouble price;privateint stock;privateint saleNum;privateDate createTime;privateString categoryName;privateString brandName;privateMap spec;@JSONField(serialize =false)// 使用fastjosn在转换json时 ,会忽略该字段privateString specStr;publicintgetId(){return id;}publicvoidsetId(int id){this.id = id;}publicStringgetTitle(){return title;}publicvoidsetTitle(String title){this.title = title;}publicdoublegetPrice(){return price;}publicvoidsetPrice(double price){this.price = price;}publicintgetStock(){return stock;}publicvoidsetStock(int stock){this.stock = stock;}publicintgetSaleNum(){return saleNum;}publicvoidsetSaleNum(int saleNum){this.saleNum = saleNum;}publicDategetCreateTime(){return createTime;}publicvoidsetCreateTime(Date createTime){this.createTime = createTime;}publicStringgetCategoryName(){return categoryName;}publicvoidsetCategoryName(String categoryName){this.categoryName = categoryName;}publicStringgetBrandName(){return brandName;}publicvoidsetBrandName(String brandName){this.brandName = brandName;}publicMapgetSpec(){return spec;}publicvoidsetSpec(Map spec){this.spec = spec;}publicStringgetSpecStr(){return specStr;}publicvoidsetSpecStr(String specStr){this.specStr = specStr;}@OverridepublicStringtoString(){return"Goods{"+"id="+ id +", title='"+ title +'\''+", price="+ price +", stock="+ stock +", saleNum="+ saleNum +", createTime="+ createTime +", categoryName='"+ categoryName +'\''+", brandName='"+ brandName +'\''+", spec="+ spec +", specStr='"+ specStr +'\''+'}';}}
查询Goods表数据,并导入:
@AutowiredprivateGoodsMapper goodsMapper;@AutowiredprivateRestHighLevelClient elasticsearchClient;@TestpublicvoidimportData()throwsIOException{// 1、 查询所有数据List<Goods> goods = goodsMapper.findAll();// 2、bulk导入BulkRequest bulkRequest =newBulkRequest();// 2.1 循环goods ,创建IndexRequest添加数据for(Goods item: goods){// 2.2 将 sepc 这属性导入进去
item.setSpec(JSON.parseObject(item.getSpecStr(),Map.class));IndexRequest indexRequest =newIndexRequest("goods");// 2.3 将good对象导入到es
indexRequest
.id(item.getId()+"")// 指定id.source(JSON.toJSONString(item),XContentType.JSON);// 将对象转成json字符串
bulkRequest.add(indexRequest);}
elasticsearchClient.bulk(bulkRequest,RequestOptions.DEFAULT);}
数据库操作这一块儿,我使用的是mybatis,这里就详细介绍了
执行测试方法之后,查看ES库:
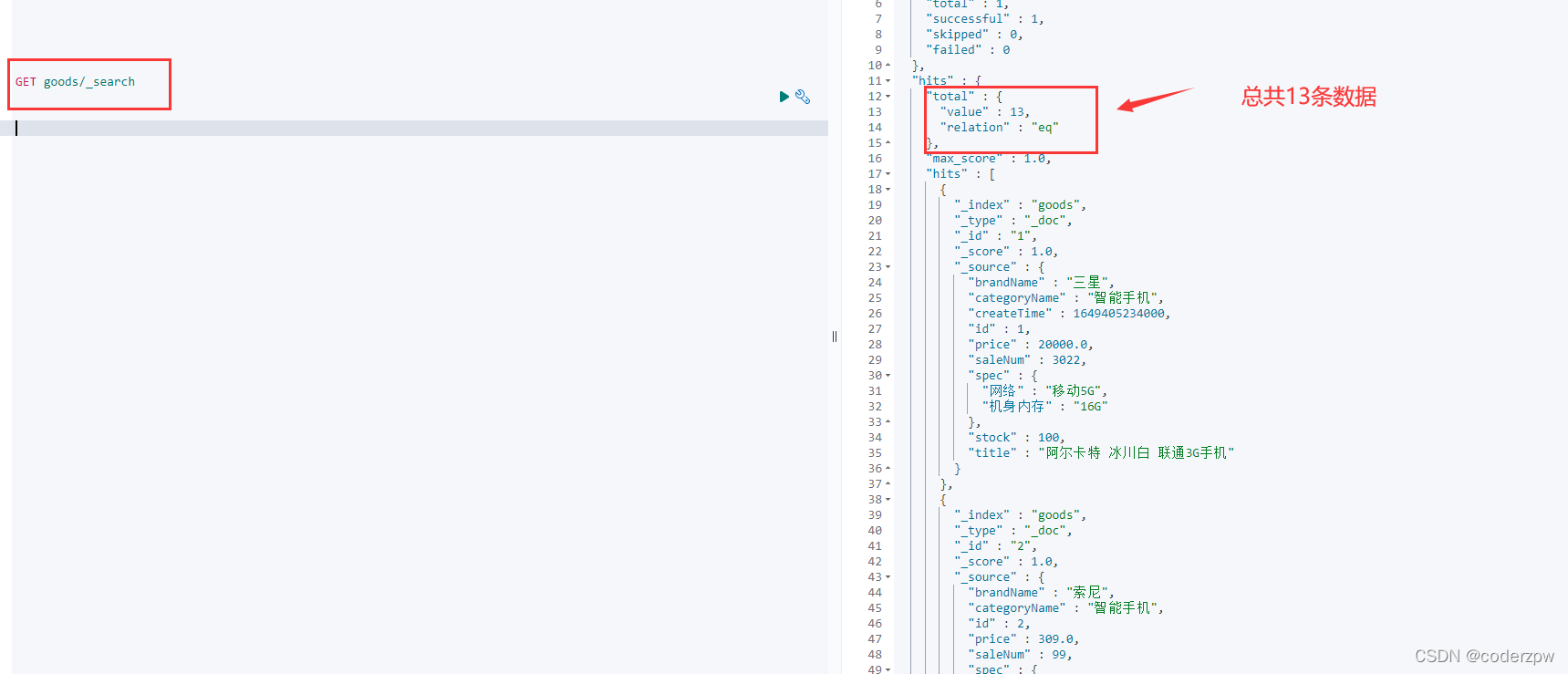
各种查询
matchAll 查询
matchAll 查询 - 脚本:
matchAll查询:查询所有文档
语法
GET 索引名称/_search
{"query":{"match_all":{}}}
默认情况下,es一次展示10条数据

可以通过
from
和
size
来控制分页
GET goods/_search
{"query":{"match_all":{}},
"from":0,
"size":2}

咱们来分析一下结果:

matchAll 查询 - JavaAPI:
/**
* 查询所有
* 1. matchAll
* 2. 将查询结果封装为Goods对象,装载到List中
* 3. 分页操作。 默认显示10条
*/@TestpublicvoidmatchAll()throwsIOException{// 2. 构建查询search请求对象。指定查询的索引名称SearchRequest searchRequest =newSearchRequest("goods");// 4. 创建查询条件构造器 searchBuilderSearchSourceBuilder sourceBuilder =newSearchSourceBuilder();// 6. 查询条件MatchAllQueryBuilder query =QueryBuilders.matchAllQuery();// 查询所有文档// 5. 指定查询条件
sourceBuilder.query(query);// 8. 添加分页信息
sourceBuilder.from(0);
sourceBuilder.size(8);// 3. 添加查询条件构建器对象
searchRequest.source(sourceBuilder);// 1. 查询SearchResponse searchResponse = elasticsearchClient.search(searchRequest,RequestOptions.DEFAULT);// 7.获取命中对象 SearchHitsSearchHits searchHits = searchResponse.getHits();// 7.1 获取总记录数long total = searchHits.getTotalHits().value;// 7.2 获取Hits数据 数组SearchHit[] hits = searchHits.getHits();List<Goods> goodsList =newArrayList<>();for(SearchHit hit: hits){// 获取json字符串格式的数据String jsonStr = hit.getSourceAsString();Goods goods = JSON.parseObject(jsonStr,Goods.class);
goodsList.add(goods);}for(Goods good: goodsList){System.out.println(good);}}
查询结果:
term 查询
term 查询 - 脚本:
term查询: 不会对查询条件再拆分
# term查询
GET 索引名称/_search
{"query":{"term":{"字段名称":{"value":"查询条件"}}}}
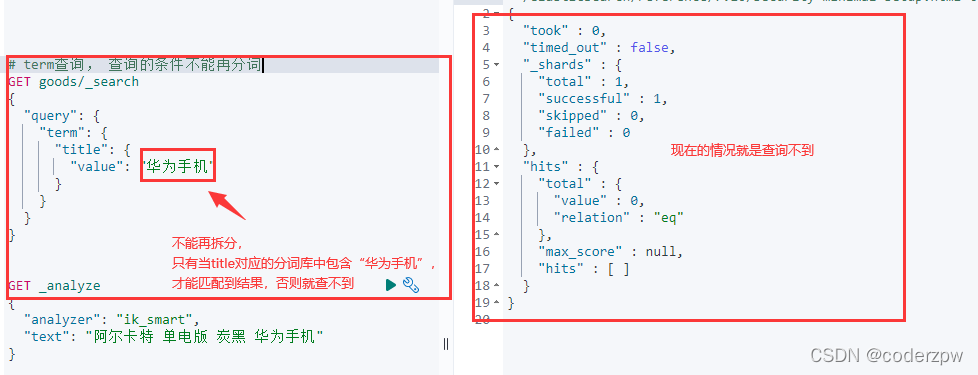
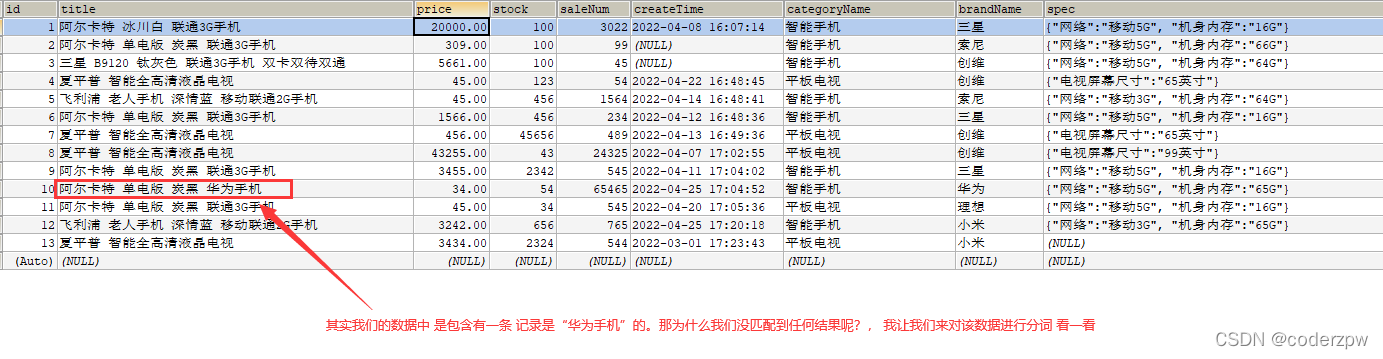
其实我们的数据是一条记录是包含 “华为手机”的, 那么为什么刚刚没有匹配到任何结果呢?
让我们对该数据用分词器进行分词看看结果: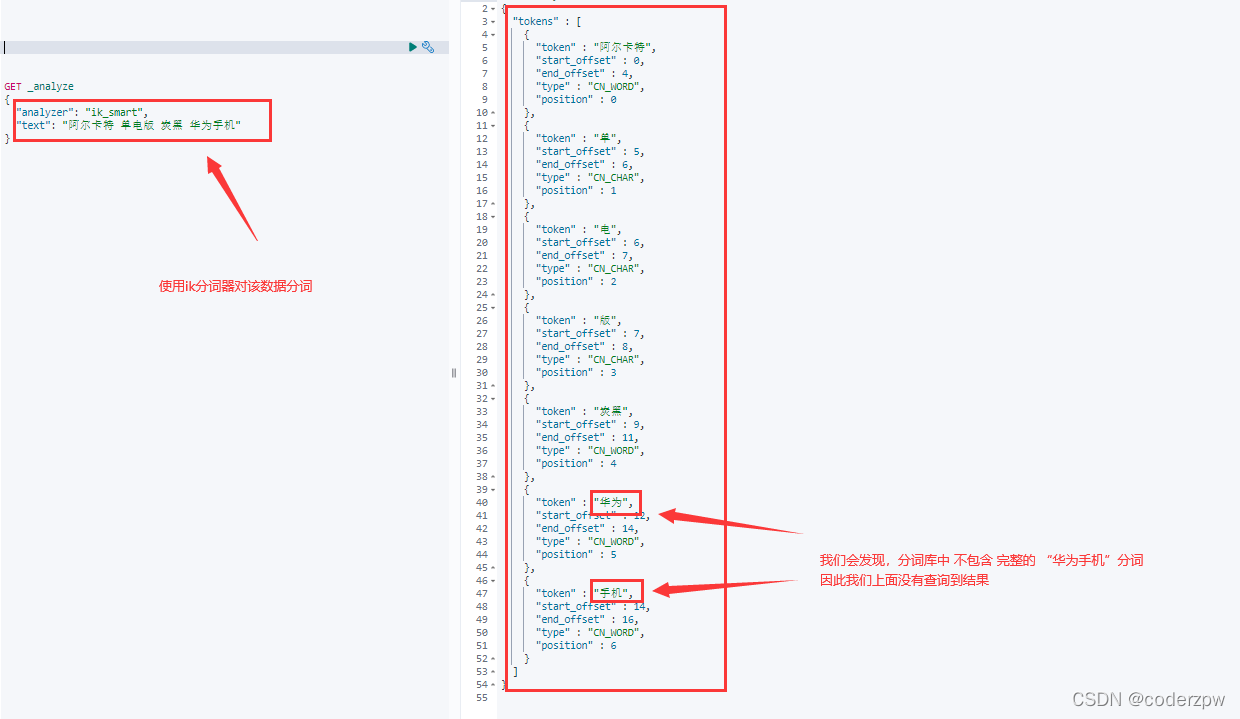
我们会发现,分词库中 不包含 完整的 “华为手机”分词,因此我们上面没有查询到结果。
接下来我们查询“华为”: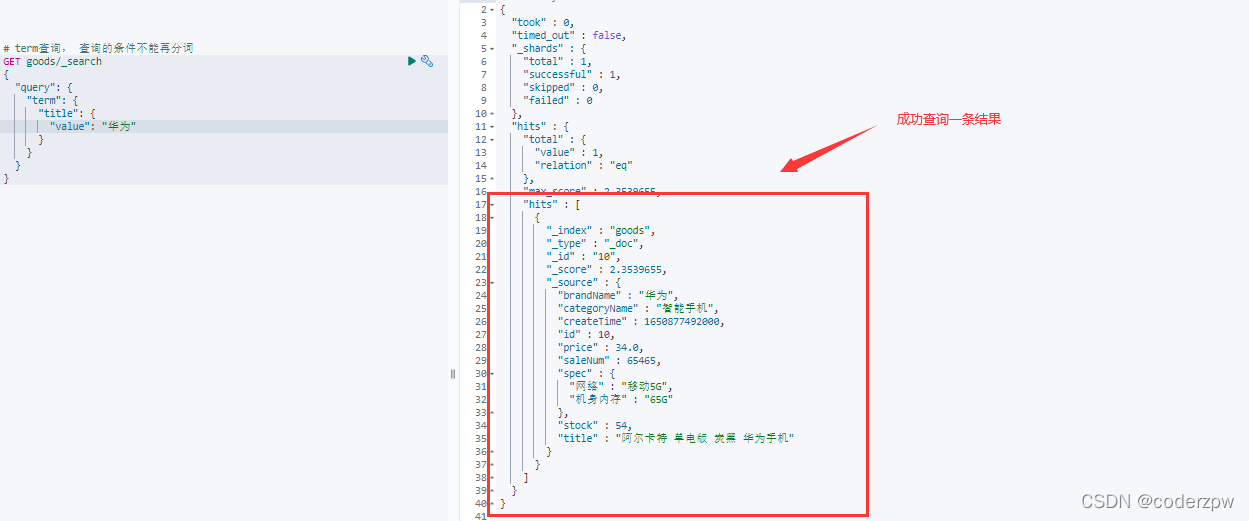
term 查询 - JavaAPI:
@TestpublicvoidtestTermQuery()throwsIOException{SearchRequest searchrequest =newSearchRequest("goods");SearchSourceBuilder sourceBuilder =newSearchSourceBuilder();// match查询QueryBuilder query =QueryBuilders.termQuery("title","华为");// term词条查询
sourceBuilder.query(query);
searchrequest.source(sourceBuilder);SearchResponse searchResponse = elasticsearchClient.search(searchrequest,RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();// 获取记录数SearchHit[] hits = searchHits.getHits();List<Goods> goodsList =newArrayList<>();for(SearchHit hit: hits){// 获取json字符串格式的数据String jsonStr = hit.getSourceAsString();Goods goods = JSON.parseObject(jsonStr,Goods.class);
goodsList.add(goods);}for(Goods good: goodsList){System.out.println(good);}}
查询结果:
match 查询
match查询 - 脚本:
match查询:
- 会对查询条件进行分词
- 然后将分词后的查询条件和词条进行等值匹配
- 默认取并集(OR)
语法1:
GET 索引名称/_search
{"query":{"match":{"查询字段":"查询条件"}}}
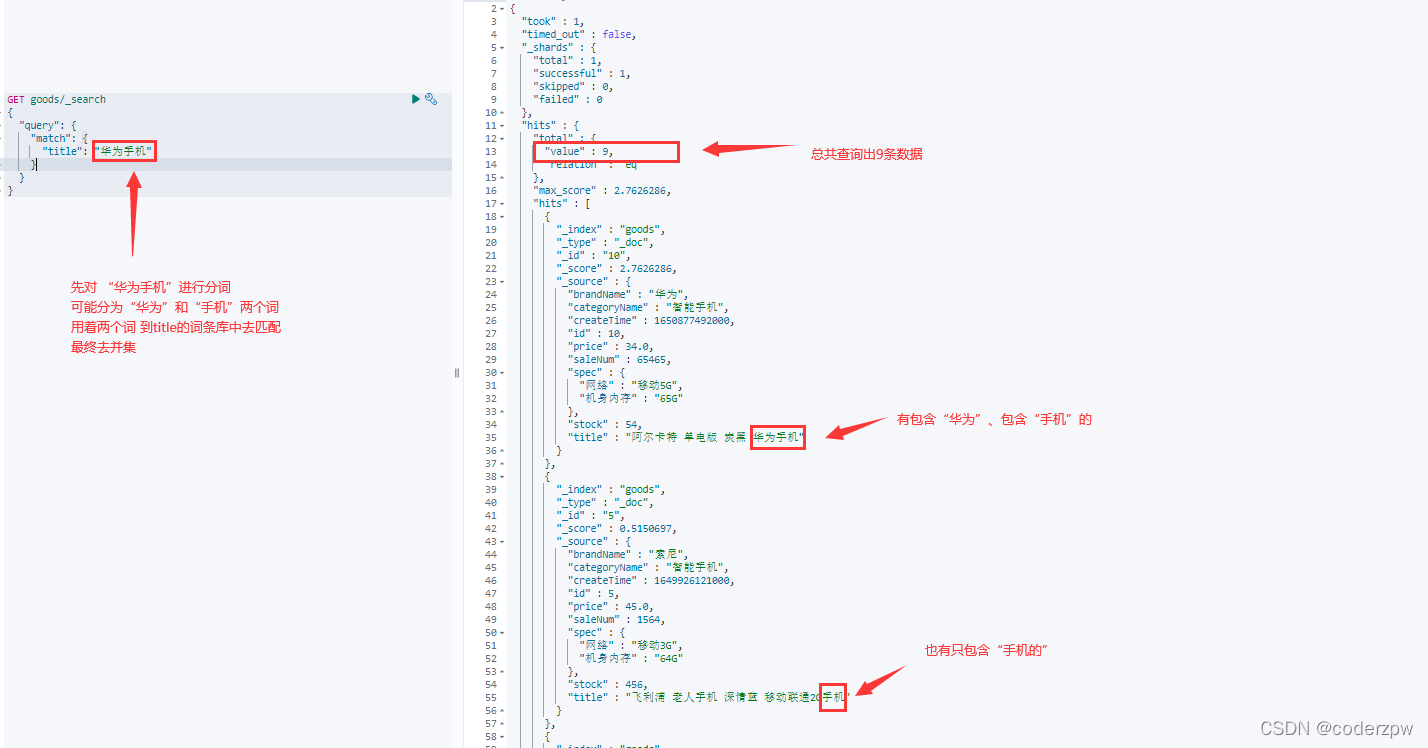
语法2:
GET 索引名称/_search
{"query":{"match":{"查询字段":{"query":"查询条件","operator":"操作(or 或者 and),即 并集 获取 交集"}}}}
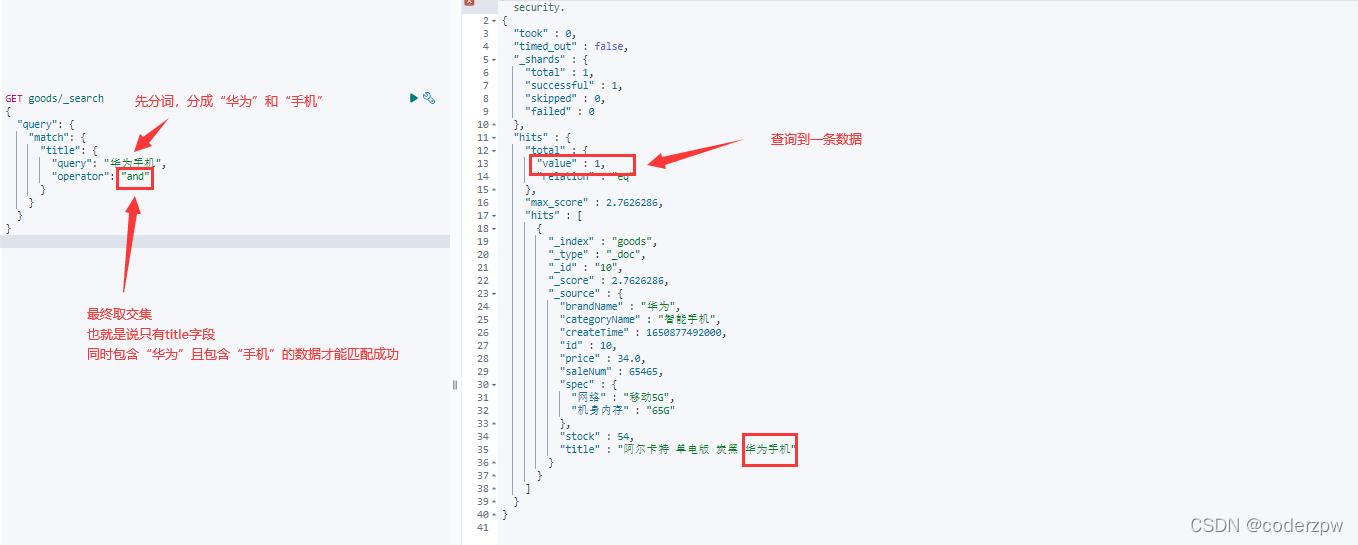
match查询 - JavaAPI:
@TestpublicvoidtestmatchQuery()throwsIOException{SearchRequest searchrequest =newSearchRequest("goods");SearchSourceBuilder sourceBuilder =newSearchSourceBuilder();// match查询MatchQueryBuilder query =QueryBuilders.matchQuery("title","华为手机");
query.operator(Operator.AND);// 求并集
sourceBuilder.query(query);
searchrequest.source(sourceBuilder);SearchResponse searchResponse = elasticsearchClient.search(searchrequest,RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();// 获取记录数SearchHit[] hits = searchHits.getHits();List<Goods> goodsList =newArrayList<>();for(SearchHit hit: hits){// 获取json字符串格式的数据String jsonStr = hit.getSourceAsString();Goods goods = JSON.parseObject(jsonStr,Goods.class);
goodsList.add(goods);}for(Goods good: goodsList){System.out.println(good);}}
查询结果:

模糊查询
模糊查询 - 脚本:
- wildcard查询:会对查询条件进行分词。还可以使用通配符? (任意单个字符) 和 * (0个或多个字符)
- regexp查询:正则查询
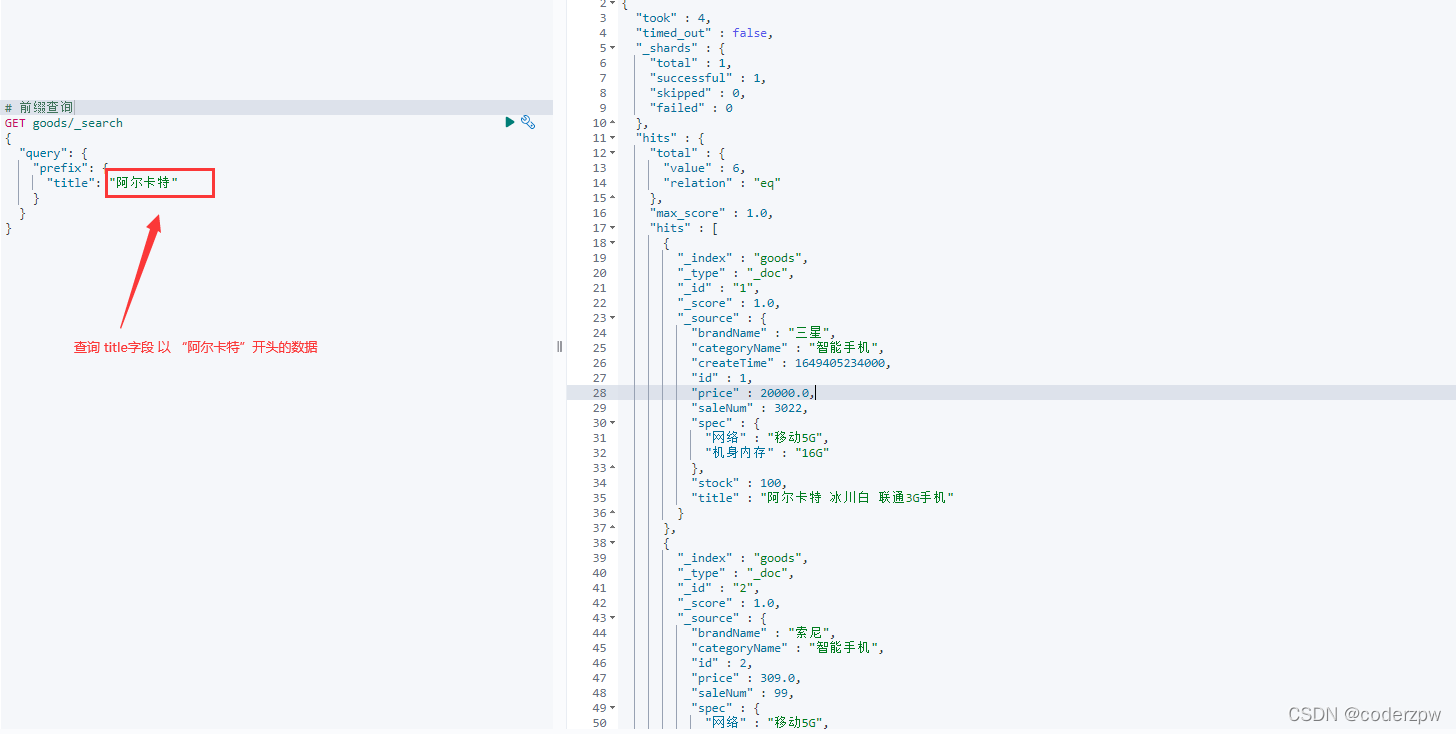
- prefix:前缀查询
wildcard查询: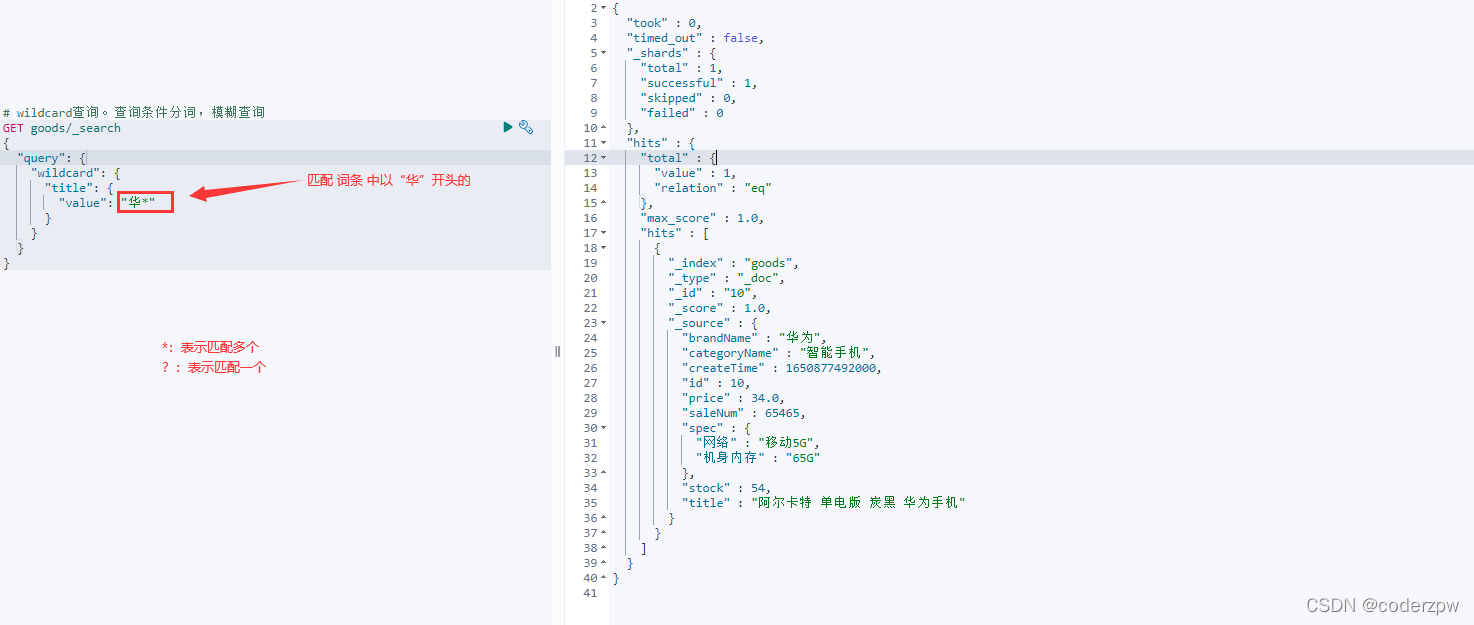
*
:表示匹配多个
?
:表示匹配一个
regexp查询(正则):
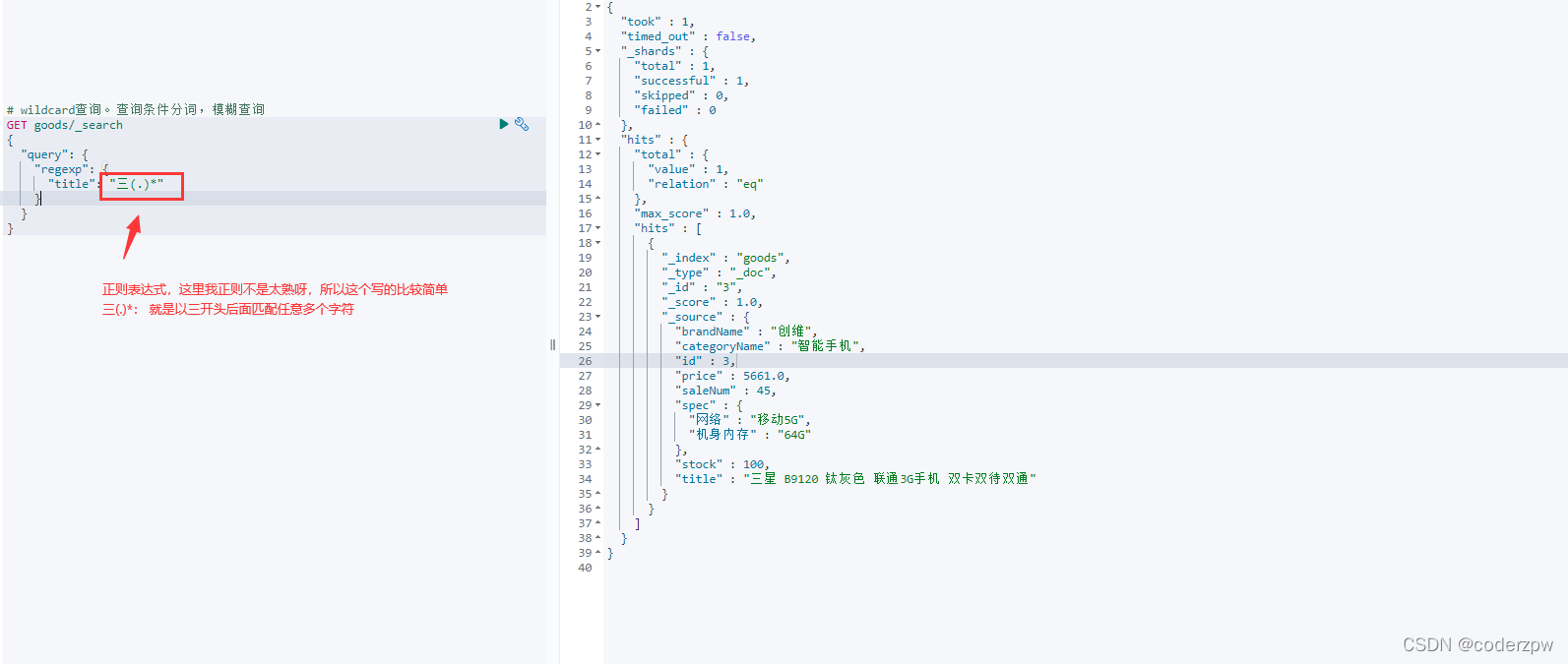
前缀查询:
模糊查询 - JavaAPI:
wildcard查询:
@TestpublicvoidtestWildcardQuery()throwsIOException{SearchRequest searchrequest =newSearchRequest("goods");SearchSourceBuilder sourceBuilder =newSearchSourceBuilder();// wildcard查询WildcardQueryBuilder query =QueryBuilders.wildcardQuery("title","华*");
sourceBuilder.query(query);
searchrequest.source(sourceBuilder);SearchResponse searchResponse = elasticsearchClient.search(searchrequest,RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();// 获取记录数SearchHit[] hits = searchHits.getHits();List<Goods> goodsList =newArrayList<>();for(SearchHit hit: hits){// 获取json字符串格式的数据String jsonStr = hit.getSourceAsString();Goods goods = JSON.parseObject(jsonStr,Goods.class);
goodsList.add(goods);}for(Goods good: goodsList){System.out.println(good);}}
查询结果:
其他两种模糊查询就不演示了,改一下查询类型即可
范围查询
范围查询 - 脚本:
# 范围查询
GET 索引/_search
{"query":{"range":{"查询字段":{"gte": 最低值,"lte": 最高值
}}}}
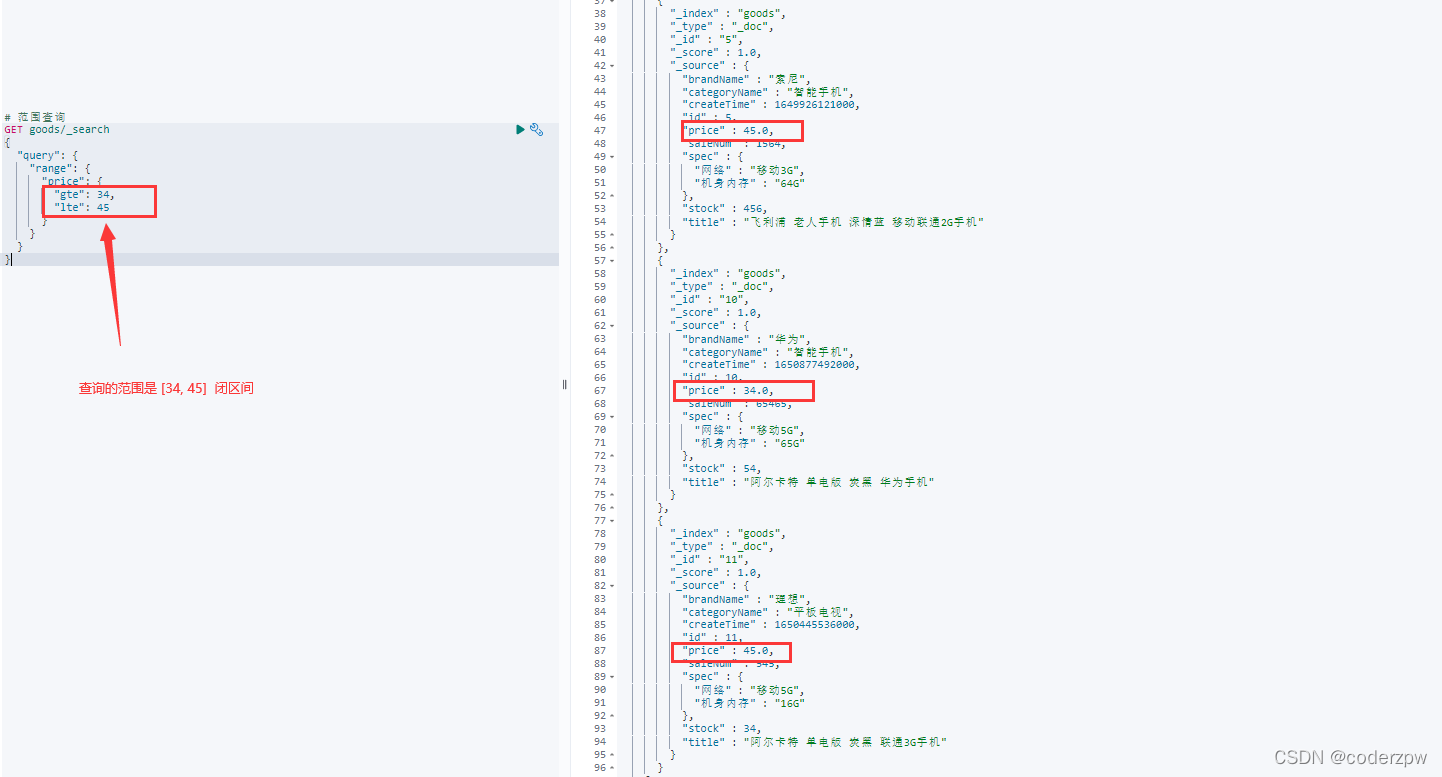
其实上面查询的结果乱序的,那我们如何升序呢?
在查询结果的后面增加
"sort":[{"排序字段":{"order":"desc 或者 asc"}}]
例如:查询 price为 [34,45] 范围内的所有数据 ,按照降序排序:
# 范围查询
GET goods/_search
{"query":{"range":{"price":{"gte":34,"lte":45}}},"sort":[{"price":{"order":"desc"}}]}
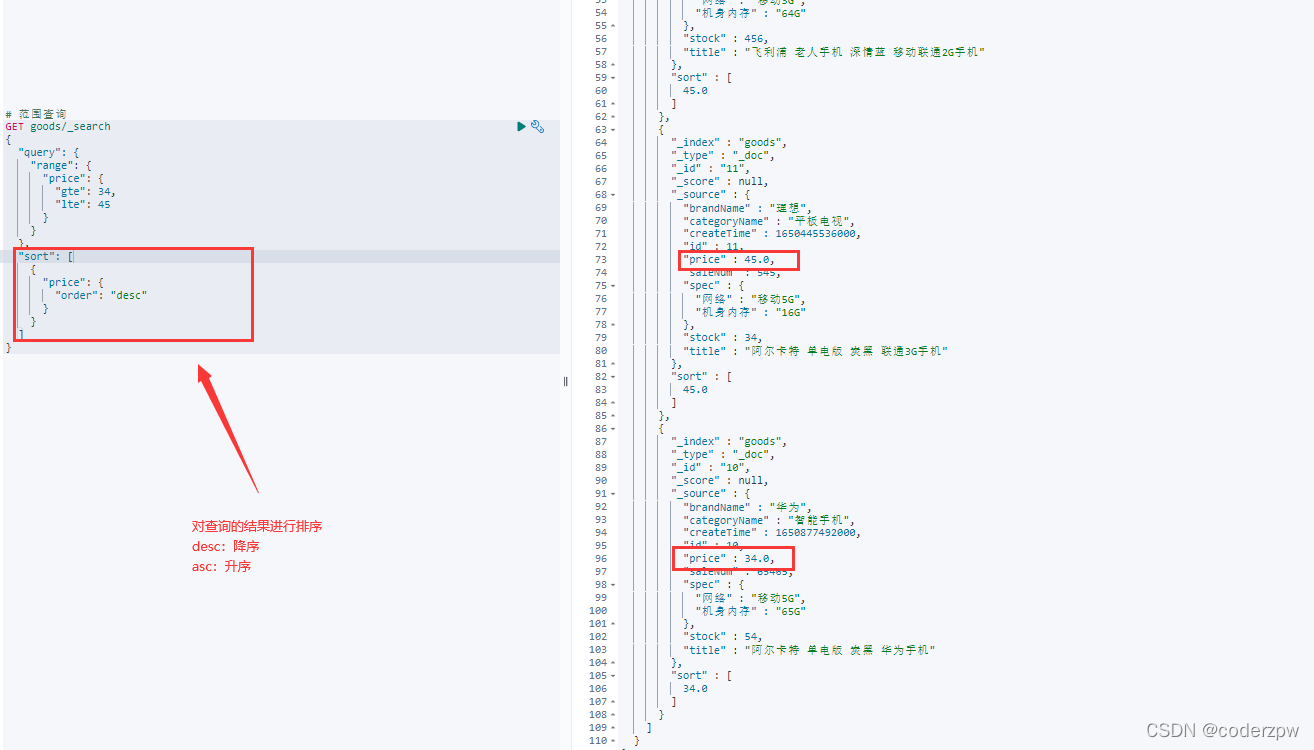
其实所有的查询都可以排序,并非专属于范围查询
范围查询 - JavaAPI:
@TestpublicvoidtestRangeQuery()throwsIOException{SearchRequest searchrequest =newSearchRequest("goods");SearchSourceBuilder sourceBuilder =newSearchSourceBuilder();// 范围查询RangeQueryBuilder query =QueryBuilders.rangeQuery("price");// 指定下限
query.gte(34);// 指定上限
query.lte(45);
sourceBuilder.query(query);// 排序,DESC:降序
sourceBuilder.sort("price",SortOrder.DESC);
searchrequest.source(sourceBuilder);SearchResponse searchResponse = elasticsearchClient.search(searchrequest,RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();// 获取记录数SearchHit[] hits = searchHits.getHits();List<Goods> goodsList =newArrayList<>();for(SearchHit hit: hits){// 获取json字符串格式的数据String jsonStr = hit.getSourceAsString();Goods goods = JSON.parseObject(jsonStr,Goods.class);
goodsList.add(goods);}for(Goods good: goodsList){System.out.println(good);}}
查询结果:
queryString 查询
queryString:
- 会对查询条件进行分词
- 然后将分词后的查询条件和词条进行等值匹配
- 默认取并集(OR)
- 可以指定多个查询字段
queryString查询 - 脚本:
# queryString查询
GET 索引名称/_search
{"query":{"query_string":{"fields":[字段1,字段2,字段3],"query":"查询的条件(可以 使用 OR 或者 AND 字段来求并集或交集)"}}}
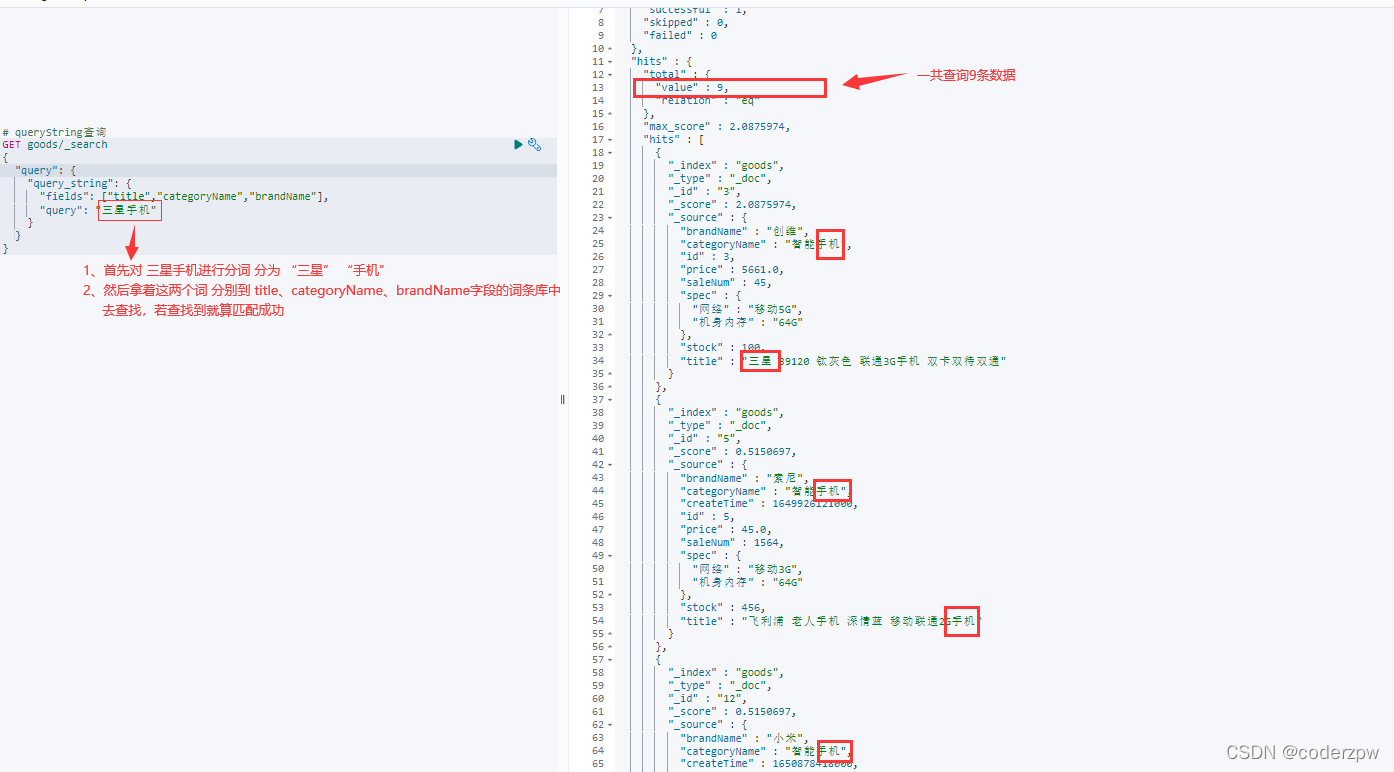
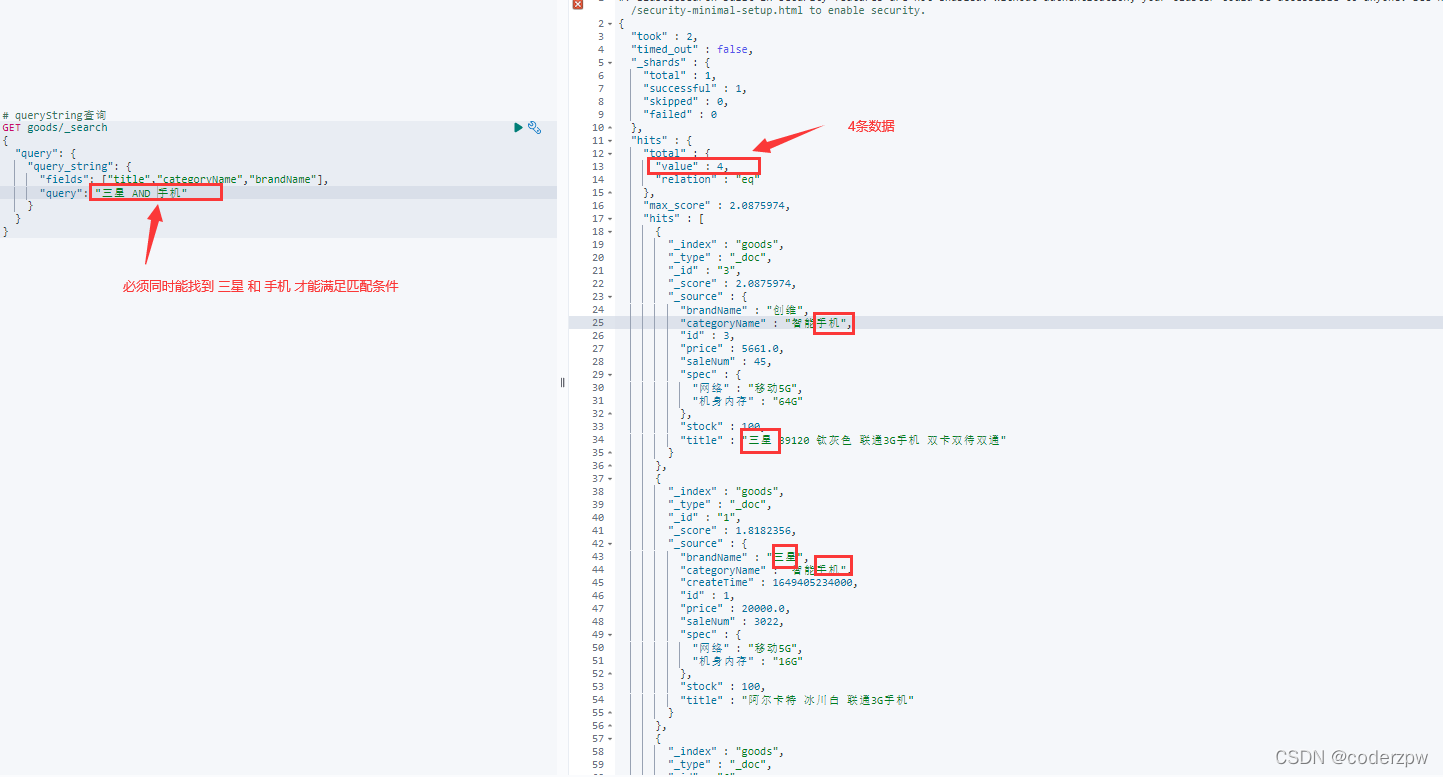
queryString查询 - JavaAPI:
@TestpublicvoidtestQueryStringQuery()throwsIOException{SearchRequest searchrequest =newSearchRequest("goods");SearchSourceBuilder sourceBuilder =newSearchSourceBuilder();// queryString查询QueryStringQueryBuilder query =QueryBuilders.queryStringQuery("三星手机")// 查询的条件// 要查询的几个字段.field("title").field("categoryName").field("brandName").defaultOperator(Operator.AND);// 交集
sourceBuilder.query(query);
searchrequest.source(sourceBuilder);SearchResponse searchResponse = elasticsearchClient.search(searchrequest,RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();// 获取记录数SearchHit[] hits = searchHits.getHits();List<Goods> goodsList =newArrayList<>();for(SearchHit hit: hits){// 获取json字符串格式的数据String jsonStr = hit.getSourceAsString();Goods goods = JSON.parseObject(jsonStr,Goods.class);
goodsList.add(goods);}for(Goods good: goodsList){System.out.println(good);}}
查询结果:
布尔查询
如果我们查询的时候,一次有多个查询条件的话,那么我们可以使用布尔查询。例如京东商城如下界面: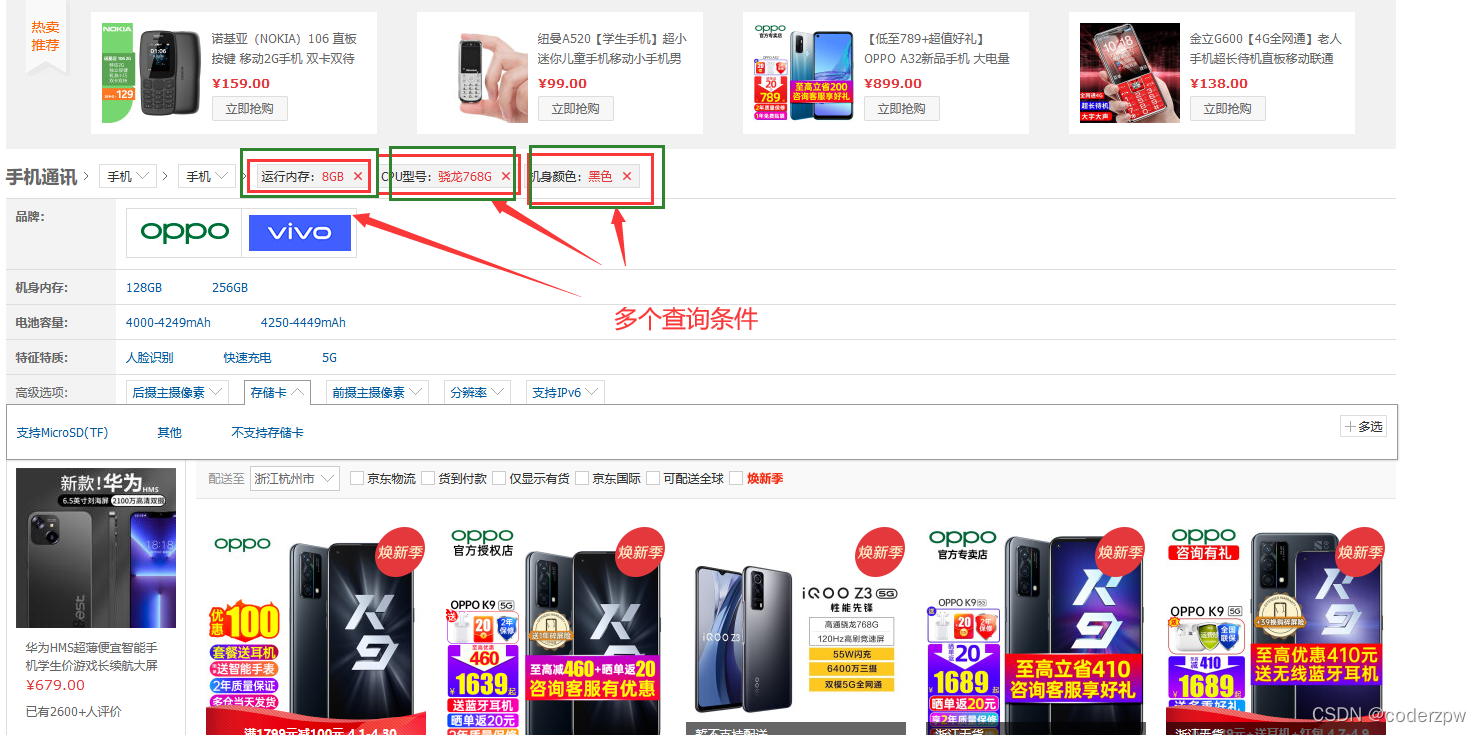
boolQuery:布尔查询,可以对多个查询条件进行连接。
- must(and):条件必须成立
- must_not(not):条件必须不成立
- should(or):条件可以成立
- filter:条件必须成立,性能比must高。不会计算得分
脚本语法:
GET 索引名称/_search
{"query":{"bool":{"must":[{},{}...],"filter":[{},{}...],"must_not":[{},{}...],"should":[{},{}...]}}}
脚本案例:
# boolquery 布尔查询
GET goods/_search
{"query":{"bool":{"must":[{"term":{"brandName":"三星"}}],"filter":[{"term":{"title":"手机"}}]}}}
查询结果: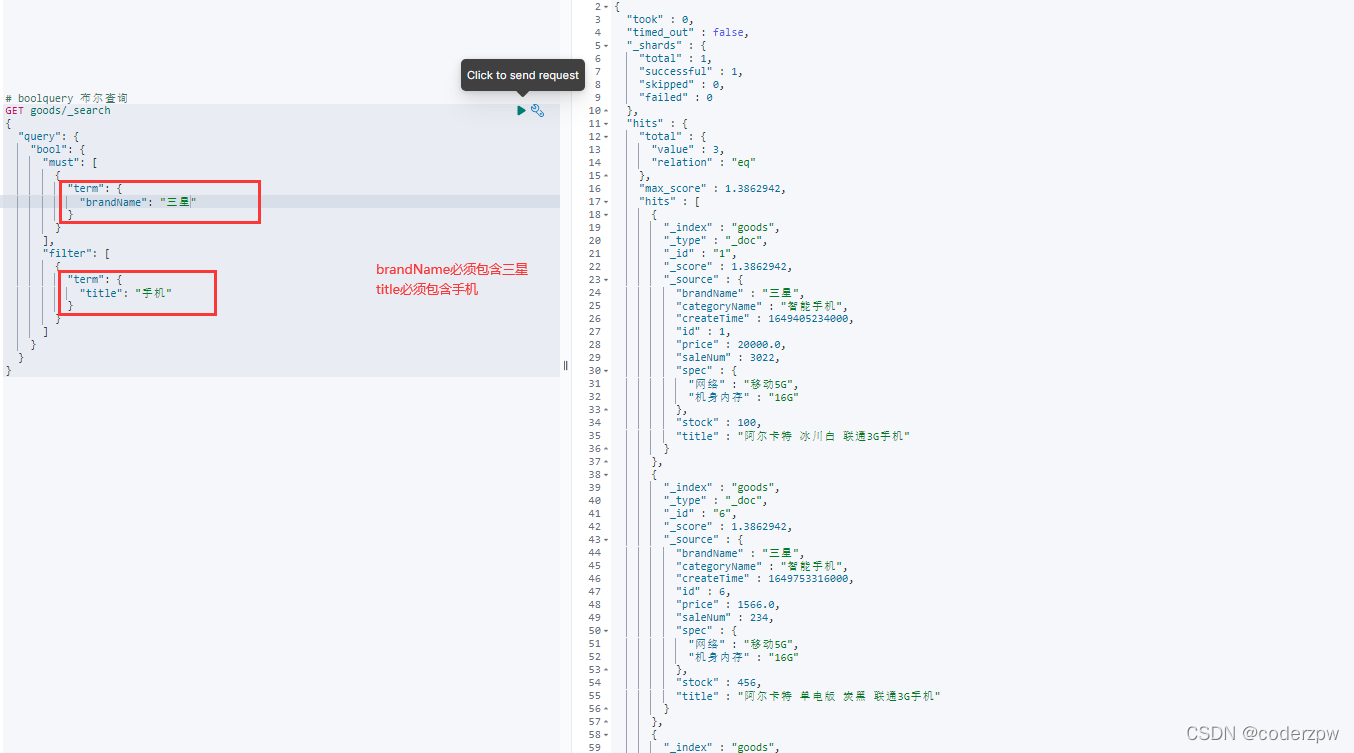
聚合查询
- 指标聚合: 相当于MySQL的聚合函数,max、min、avg、sum等
脚本案例:
# 指标聚合 聚合函数
GET goods/_search
{"query":{"match":{"title":"手机"}},"aggs":{"max_price":{"max":{"field":"price"}}}}
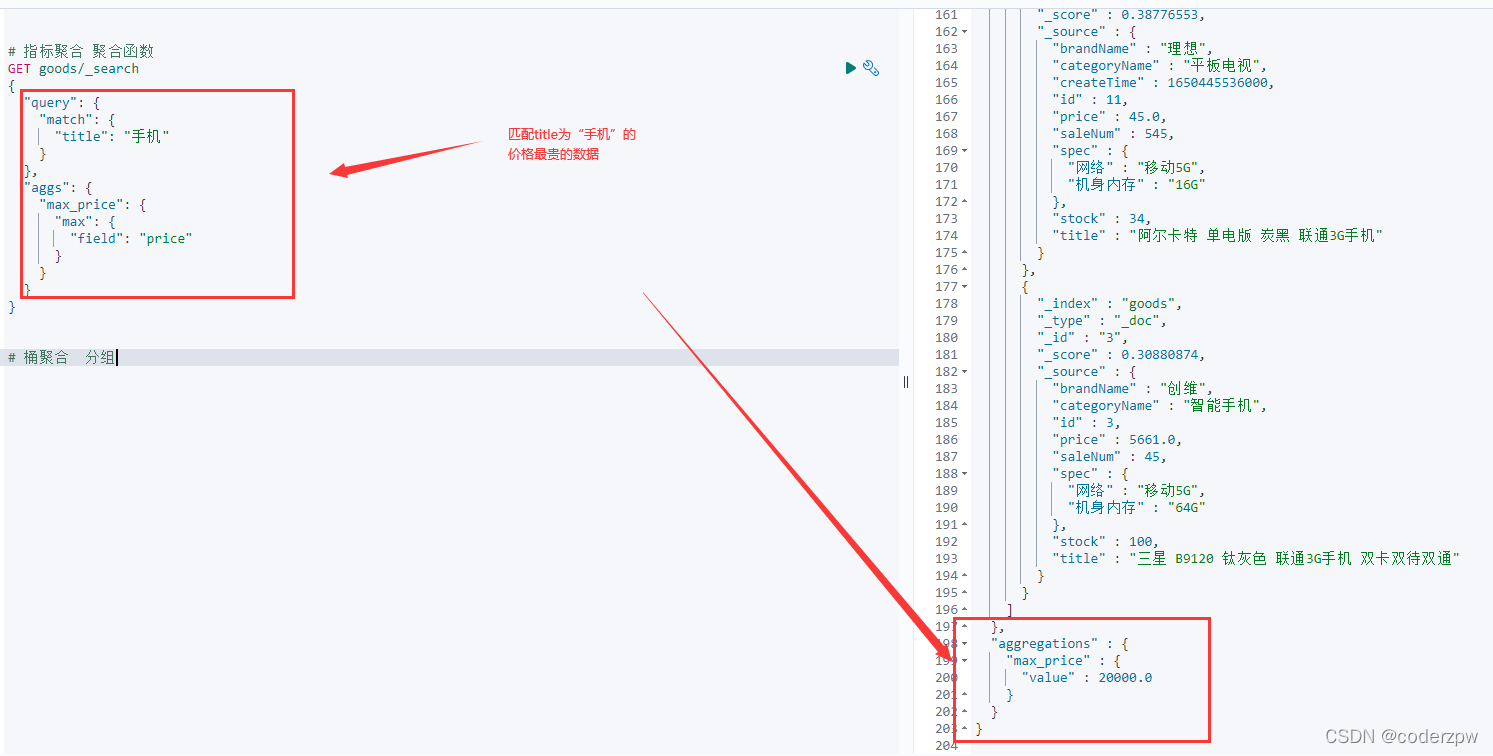
- 桶聚合:相当于MySQL的group by 操作。 不要对text类型的数据进行分组,会失败
脚本案例:
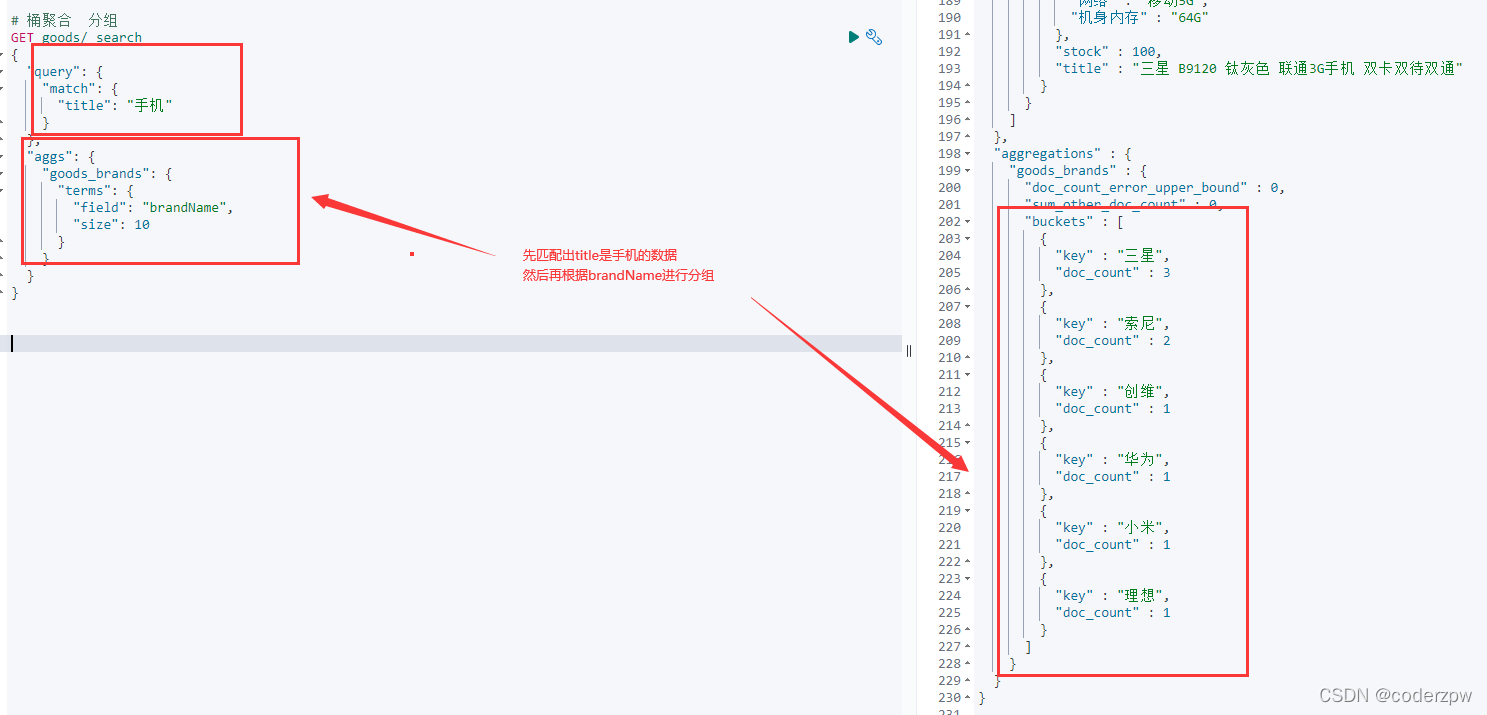
# 桶聚合 分组
GET goods/_search
{"query":{"match":{"title":"手机"}},"aggs":{"goods_brands":{"terms":{"field":"brandName","size":10}}}}
高亮查询
高亮三要素:
- 高亮字段
- 前缀
- 后缀
脚本案例:
# 高亮查询
GET goods/_search
{"query":{"match":{"title":"手机"}},"highlight":{"fields":{"title":{"pre_tags":"<font color='red'>","post_tags":"</font>"}}}}
查询结果: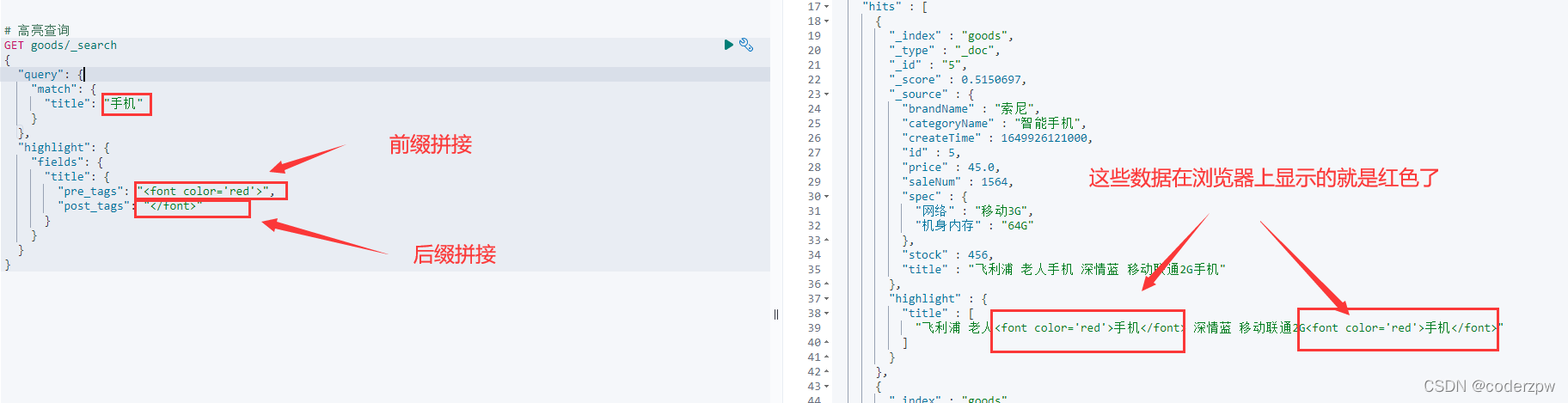
版权归原作者 coderzpw 所有, 如有侵权,请联系我们删除。