
背景
随着公司业务规模的不断扩大,系统的设计也愈加复杂。当在具有一定应用规模和业务复杂度的系统上进行快速迭代时对系统的鲁棒性、兼容性、测试覆盖率以及实效性也提出了更高的要求。目前业界通常使用一些自动化手段来解决人工全场景回归的效率问题。但是这些自动化回归手段也产生了一些新的问题:
- 自动化用例编写成本高。每次新增功能都需要编写新的自动化测试回归用例。
- 自动化用例维护成本高。随着用例数量的增加,维护成本指数级上升,代码变更,包括关联的代码变更,都可能导致用例失效,需要耗费大量精力重新修正自动化用例。
- 为了降低维护成本,不得已缩减场景覆盖度以及校验深度,从而导致质量保障的效果打了折扣。
- 人工构造流量成本较高,且不拟合生产场景所产生的流量。
为了减缓复杂度之熵对系统迭代造成的影响,我们开始探索如何利用流量回放,将线上真实的数据流转化为覆盖全面的回归测试用例。
技术选型
什么是流量回放
流量回放是系统重构、拆分、版本迭代频繁、系统复杂度较高时重要的自动化回归手段。通过采集可录制流量,在指定环境回放,再逐一对比每个调用和子调用差异来发现接口代码是否存在问题。因为线上流量大、场景全面,可以有效弥补人工评估测试范围的局限性,进而降低业务快速迭代带来的风险。在销售易流量回放平台的建设价值主要有以下三点:
- 降低代码变动对整体系统带来的风险;
- 为压测平台提供拟合生产真实场景的流量;
- 为系统重构保驾护航,加持产品高质量交付,护航产品快速迭代。
调研比对
目前业内比较知名的流量回放工具比对如下:
1. goReplay
基于Go语言实现与Tcpdump一样都是依赖pcap库,主要监听网络接口流量来录制流量,支持在线和离线方式回放流量。
优点:
- 轻量程序基本无需配置,环境准备简单
- 程序资源消耗少,无侵入应用运行环境
- 提供不限制语言的插件机制,方便拓展
- 流量放大回放,模拟压测
2. tcpCopy
TCPCopy是一种请求复制(所有基于tcp的packets)工具,其功能是复制在线数据包,修改TCP/IP头部信息,发送给测试服务器,达到欺骗测试服务器的目的。
优点:
- 流量放大功能,可以利用多种手段构造无限在线压力,满足中小网站压测要求
- 对比实验,同样请求,针对不同或不同版本的程序,可以做性能对比实验
- 利用tcpCopy转发传统压力测试工具发出的请求,可以增加网络延迟,使压力测试更加真实
3. Jvm-sandbox-repeater
使用jvm-sandbox沙箱技术,通过Java agent或者attach方式挂载到Java应用上。repeater模块根据配置的规则录制或回放数据,console模块主要负责触发和数据交互。
优点:
- 通过字节码增强的方式可以直接录制Java方法、子调用
- 对业务代码0侵入
- 模块功能丰富
对 tcpcopy 和 goreplay 而言:
- tcpcopy 部署架构相对复杂,goreplay 相对简单只需启动一个进程;
- tcpcopy 支持的协议比较丰富,goreplay 根据架构特点仅支持 http;
- tcpcopy 和 goreplay 都支持离线和在线录制回放;
对于销售易而言,goreplay显然更适合一些。
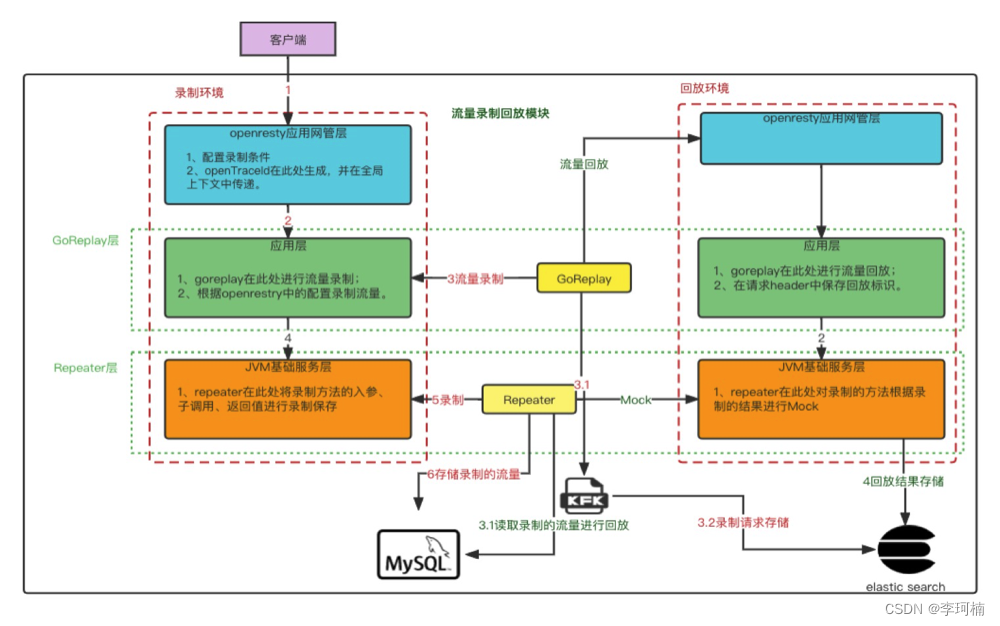
使用goReplay在入口服务录制流量后回放至回放环境会发现由于写操作写库时造成的id不同导致某些查询流量查不到数据,所以为了解决这一问题引入Jvm-sandbox-repeater对生成id的方法进行Mock操作从而解决些操作生成的id不一致问题。所以使用goreplay + Jvm-sandbox-repeater两种工具相结合的方式来研发适合销售易的流量回放平台。
技术架构
goreplay改造
增加了自定义命令参数,如下:
--flow-replay-interval 指定回放间隔时间单位秒
--flow-max-time 最大录制时间
--instance-id 该gor进程心跳对应实例
--heartbeat-url 心跳地址
--flow-task-id 录制任务id
--auto-exit 是否自动停止,此项为true时,需要配置maxnum和maxtime才能生效
--flow-max-num 录制流量上限
Jvm-sandbox-repeater改造
traceId改造
修改原生traceId的生成方式,我们需要一个可以在整条链路中标记唯一流量的traceaId作为标识,即从nginx网关层开始经过中间若干服务,一直到Jvm-sandbox-repeater埋点的服务层全部串联起来,即goreplay和Jvm-sandbox-repeater两个开源工具的关联。在此基础上才可以进行后续的功能开发。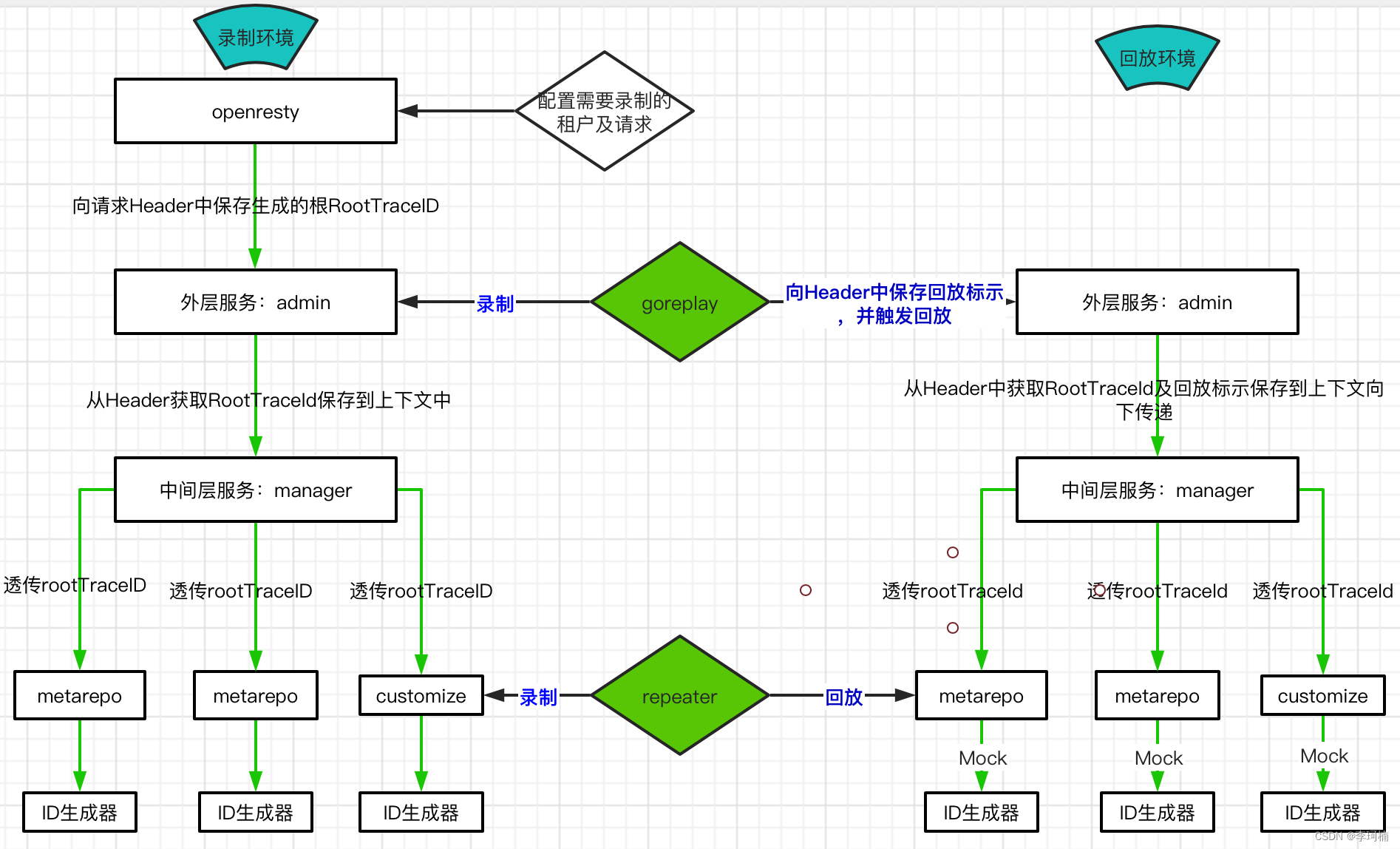
流程概述:
录制
- 通过apps-ingage-console服务配置的需要录制的租户ID及请求,操作Openresty根据配置生成rootTraceId,并保存到上下文中
- goreplay拦截外层web服务根据rootTraceId完成外层录制,外层web服务从Header中获取rootTraceId并保存到上下文中
- 中间层服务只负责传递rootTraceId
- 数据服务层用attach的方式安装repeater,由repeater根据上下文的rootTraceId及录制配置的类名方法名判断是否录制,满足录制条件的请求,ID生成器需根据rootTraceId+类名+方法名+参数值(去除噪音)的MD5值作为repeater自身的traceId,并将java调用中的从ID生成器获取Id的子调用录制,以便回放时mock,录制的片段发送的repeater-console并保存到数据库中,完成录制流程
回放
- 由gorepaly发起回放,回放前需要在所有回放的请求Header中增加回放标示Repeat-Replay-X
- web层服务接受请求后,将请求中原有的rootTraceId及goreplay新增的Repeat-Replay-X从Header中保存到上下文
- 中间层服务透传上述两个属性
- 数据服务层用agent的方式安装repeater,由repeater读取上下文的回放标示,并根据相同的rootTraceId+类名+方法名+参数值的MD5值生成repeater自身的traceId,根据traceId访问repeater-console判断是否存在该片段,如果存在就由repeater-console进行回放,回放时Mock之前录制的获取ID的字调用,再将回放结果的JSON转换成真实的返回值类型完成响应
噪音过滤
在回放的过程中由于匹配子调用是按照类全限定名#方法名参数来进行匹配的,方法参数中类似时间戳的噪音字段会导致子调用不匹配从而使回放失败。在mock方法的配置上新增了噪音字段过滤,可以解决此问题。
租户信息设置上下文
底层服务在执行数据库操作时需要验证上下文中的租户信息,由于回放时和请求原本的线程上下文错开了,所以要在回放的这个上下文中也加入租户信息。在Jvm-sandbox-repeater中使用反射的方式在回放刚抵达此服务时在上下文中加入租户信息。
开源bug
节点刷新会导致回放时重复回放,增加缓存机制,每次刷新时先卸载消息订阅器,然后再清空订阅器,最后重新装载。
管理后台设计
流量回放管理后台主要分为以下几个模块:
系统管理模块
此模块的主要作用是开账号和账号权限管理,对不同需求的用户开启不同权限的账号,保证平台的数据安全性。主要有以下功能:
- 用户管理
- 角色管理
- 菜单管理
- 日志管理,记录用户在流量回放平台上的操作日志
基础配置模块
此模块主要作用是流量回放平台整体的基础配置,在基础配置完成后才可以进行流量的录制和回放。主要有以下功能:
- 环境管理,配置流量回放平台所支持的企业内部环境,如沙盒环境、P17环境、灰度环境
- 服务管理,配置流量回放平台录制哪些服务的流量
- 接口管理,配置流量回放平台录制已配置服务的哪些接口
- 租户管理,配置流量回放平台录制哪些租户的流量
- 噪音管理,配置流量回放平台回放比对过程中的一些噪音干扰
repeater管理模块
- 在线流量,记录Jvm-sandbox-repeater所录制的底层服务接口流量,用于回放时的Mock操作。
- 配置管理,配置Jvm-sandbox-repeater录制哪些方法及方法匹配噪音过滤,用于回放时的Mock操作。
- 在线模块,记录当前哪些服务上启用了Jvm-sandbox-repeater探针。
gor管理模块
- gor指令集,存储了goReplay的一些配置命令,便于配置goReplay的启动参数。
- gor配置模版,配置多套goReplay的启动参数集,便于在不同环境和场景下使用。
- gor代理,和goReplay部署在一起用于控制goReplay运行停止的服务,此服务由admin-service服务下达控制命令。
- gor实例,记录当前哪些服务上正在运行goReplay。
流量任务模块
- 任务管理,用于创建录制和回放任务。
- 流量筛选,根据录制的流量创建流量文件,用于回放任务时使用。
- 比对结果,在回放任务执行后,会生成流量比对结果,此功能就是显示流量回放比对的详细信息。
- 回放文件管理,流量筛选候会生成用于回放的文件,文件的详细信息就可以在此处查看。
架构设计
流量回放平台核心业务流程图如下:
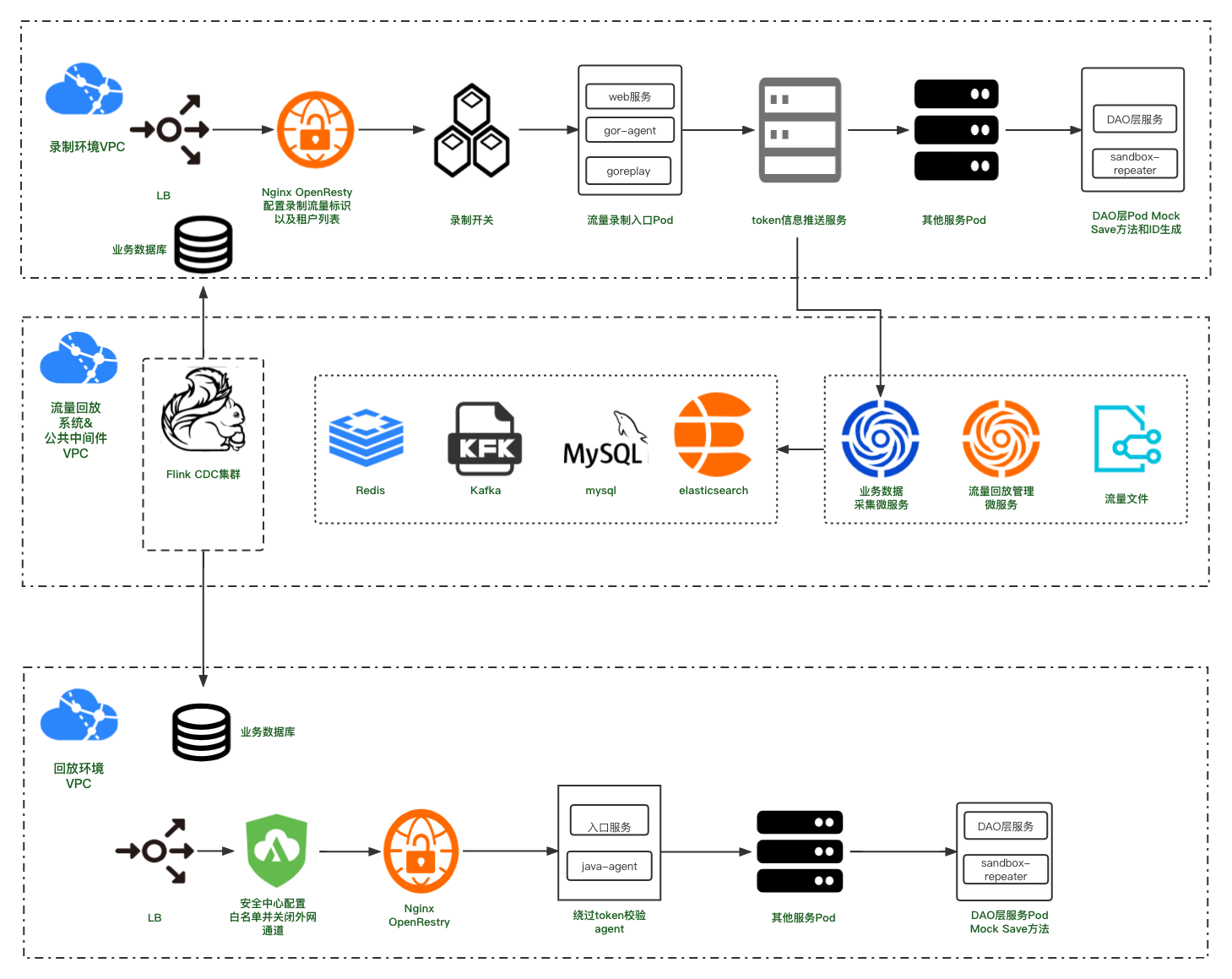
业务环境主要分为录制环境和回放环境
录制环境分为三层:
- openresty应用网关层,全局的traceId就在此处生成。
- 应用层,即是入口服务层,goReplay分别和这一层的服务部署在同一个pod,用已录制此入口服务网络端口的流量。由于crm系统的权限拦截,在此处进行了用户登录候token投递至流量回放管理后台。
- JVM基础服务层,能够做为JVM基础服务的都是java语言写的服务,这些服务使用javaagent命令携带Jvm-sandbox-repeater探针启动,对应用内接口流量进行录制。
回放环境也分为三层:
- openresty网关层,在回放环境的网关层我们没有进行任何的改动,并不需要生成额外的参数进行传递,只作为网关来使用。
- 应用层,回放流量经由网关层抵达应用层,此层更改了入口服务的过滤器,在过滤器中获取请求中的流量回放标识设置在全局上下文中,以便底层服务使用。增加权限拦截器修改探针,使用录制环境的token进行替换,从而绕过全县逻辑的校验。
- JVM基础服务层,repeater在录制环境进行接口流量的录制,在回放环境使用录制的流量对指定接口方法进行Mock操作。
除了录制环境和回放环境外,就是流量回放平台的插件服务,以及存储中间件。
流量回放平台技术架构图如下:
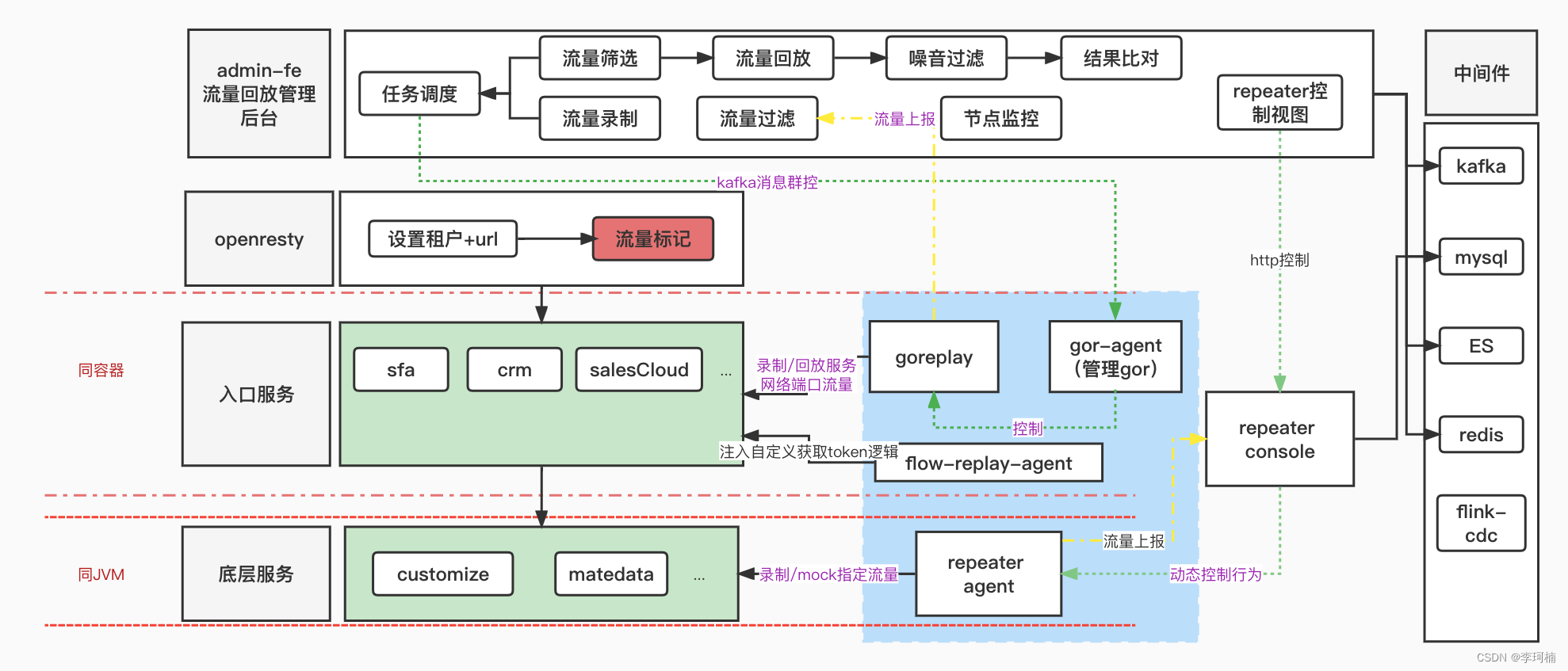
admin-fe流量回放管理后台(admin-service)在上文已有介绍,主要做了插件服务的调度,流量的过滤存储,流量任务的开启关闭以及比对结果的存储。
openresty中对外暴露了指定租户和请求url的接口,openresty会根据以上条件对符合的流量进行traceId的标记,此标记放置在header中,随着请求流转至入口服务。
入口服务曾我们可以看出有sfa、crm、salesCloud等服务,goReplay和gor-agent(goReplay管理器)与各入口服务部署在同一个pod中,gor-agent根据流量回放管理后台下发的命令对goReplay执行相应的操作。goReplay在开启后会对入口服务的启动端口进行监听,录制此端口的所有流量使用消息队列的方式发送至管理后台,管理后台经过处理后落库存储。
底层服务如customize、matedata等java服务启动时使用javaagent方式携带repeater探针启动,对指定的接口流量进行录制,使用http的方式上报至repeater-console控制台,进行处理存储。
左侧是流量回放平台所使用的中间件,其中flink-cdc是基于flink CDC研发的数据库同步工具。
流量回放平台部署架构图如下:
挑战
我们在平台建设中也遇到了挑战,不仅限于技术,下面列举了部分我们在平台建设中踩过的坑和我们想到的解法。包括我们目前还没有很好解决的挑战性问题。
开源版本bug修复
在平台的建设过程中,我们发现了jvm-sandbox的一些bug,对于这些问题我们在使用过程中进行了修复,如回放时重复回放的问题
com.alibaba.jvm.sandbox.repeater.module.RepeaterModule
private static List <SubscribeSupporter> subscribes = new ArrayList <>();
// 先卸载消息订阅器
subscribes.forEach(subscribe -> subscribe.unRegister());
subscribes.clear();
// 装载消息订阅器
subscribes = lifecycleManager.loadSubscribes();
如java入口的配置动态变更时无法rewatch
com.alibaba.jvm.sandbox.repeater.plugin.java.JavaEntrancePlugin
@Override
public void onConfigChange(RepeaterConfig config) throws PluginLifeCycleException {
if (configTemporary == null) {
super.onConfigChange(config);
} else {
// 此方法被修改过,原方法不能刷新config,可能原因是因为在子调用插件中已经刷新了,所以此处不再刷新(两个java插件一起使用的场景下)
List<Behavior> current = config.getJavaEntranceBehaviors();
List<Behavior> latest = configTemporary.getJavaEntranceBehaviors();
this.config = config;
super.onConfigChange(config);
if (JavaPluginUtils.hasDifference(current, latest)) {
reWatch0();
}
}
}
开源版本功能扩展
goReplay在原先的基础上新增了一些自定义指令。
如flow-max-time、flow-max-num任务停止指令
if dst_type == "*main.KafkaOutput" || dst_type == "*main.HTTPOutput" {
if Settings.FlowMaxNum != 0 {
maxCount++
var count = 0
if Settings.TrackResponse || Settings.OutputHTTPConfig.TrackResponses {
//如果同时录制返回则需要除2.来回算一次
count = maxCount / 2
} else {
count = maxCount
}
fmt.Printf("当前流量录制数量:%d\n", count)
if count >= Settings.FlowMaxNum {
fmt.Printf("当前流量录制数量已到上限:%d,录制结束,立即关闭程序\n", count)
os.Exit(1)
}
}
//根据时间结束
if Settings.FlowMaxTime != 0 {
if time.Now().Unix() > Settings.FlowMaxTime {
fmt.Printf("当前流量录制时间已到上限:%s,录制结束,立即关闭程序\n", time.Now().String())
os.Exit(1)
}
}
}
如心跳指令heartbeat-url,上报至流量回放管理后台
func heartbeat(port string) {
url := Settings.HeartbeatUrl
if url == "" {
return
}
fmt.Printf("The %s heartbeat-url is : %s \n", port, url)
body := HeartbeatBody{port}
bodyByte, _ := json.Marshal(body)
req, _ := http.NewRequest("POST", url, bytes.NewBuffer(bodyByte))
req.Header.Set("Content-Type", "application/json")
client := &http.Client{}
var maxRetryNum = 10
for {
resp, err := client.Do(req)
if err != nil {
//控制中心异常时,计数,如果多次中断则停止心跳
fmt.Printf("The port is lose control with admin,begin retry-%d \n", maxRetryNum)
maxRetryNum--
} else {
data, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("The port [%s] service keep-alive...result-%s \n", port, string(data))
maxRetryNum = 10
}
if maxRetryNum == 0 {
fmt.Printf("The port [%s] service lose control!!! \n", port)
return
}
time.Sleep(time.Second * 10)
}
}
Jvm-sandbox-repeater基础上新增了一些便捷的功能。
如方法匹配去噪音策略
private double calcSimilarity(Invocation invocation , MockRequest request, Object[] args) throws SerializeException {
// 子调用去噪音
Set <String> strings = NoiseCache.subInvokeNoiseMap.get(getInvokeClassAndMethod(request.getIdentity().getUri()));
String requestSerialized;
String requestSerializedTarget;
if (strings == null || strings.isEmpty()) {
requestSerialized = SerializerWrapper.hessianSerialize(request.getArgumentArray(), request.getEvent().javaClassLoader);
requestSerializedTarget = invocation.getRequestSerialized();
} else {
String jsonArgs = gson.toJson(args);
JsonElement jsonEle = JsonParser.parseString(jsonArgs);
JsonElement jsonElement = JsonUtil.replaceJsonNode(jsonEle, strings);
jsonArgs = gson.toJson(jsonElement);
requestSerialized = SerializerWrapper.hessianSerialize(jsonArgs, request.getEvent().javaClassLoader);
String jsonTarget = gson.toJson(invocation.getRequest());
JsonElement jsonTargetEle = JsonParser.parseString(jsonTarget);
JsonElement jsonTargetElement = JsonUtil.replaceJsonNode(jsonTargetEle, strings);
jsonTarget = gson.toJson(jsonTargetElement);
log.info("子调用: 噪音: {}; 回放入参: {}; 录制入参: {}",strings, jsonArgs, jsonTarget);
requestSerializedTarget = SerializerWrapper.hessianSerialize(jsonTarget,request.getEvent().javaClassLoader);
}
int distance = StringUtils.getLevenshteinDistance(requestSerialized, requestSerializedTarget);
return 1 - (double) distance / Math.max(requestSerialized.length(), requestSerializedTarget.length());
}
基于Flink CDC完成数据库同步工具的研发,最长的实时同步任务已运行40天以上,数据同步速率可以达到25G/h,包括按租户同步等一些定制功能。
在回放比对失败的流量分析提效上也做了许多探索,如多种比对策略同步比对,失败流量一键实时重放,失败流量聚类分析等。
业务系统限制
在流量回放过程中由与业务系统的复杂性带来的问题也是非常重要的一部分,甚至于大部分时间都花费于此,我们常遇到的问题就是本地demo运行没问题,一到线上就开始出现各种错误,这种错误也就是由于系统的复杂性和特性引起的问题,比如:
token校验问题
最开始测试的录制环境是citest,回放环境是k8s。由于两个环境的数据库用户信息表一致,且只有一个租户,在录制回放的测试过程中从来没有考虑过业务系统权限校验的问题,知道初次上线,由于是线上用户并不知道用户的账号密码,所以在回放的时候几乎所有的流量都被拦在了权限校验这里,后来经过多方讨论最终定下了一个方案,平台组在用户登录时投递token信息至流量回放平台,流量回放组使用ASM代码注入的方式更改权限拦截校验拦截器,在回放时自动替换当前token以通过权限拦截。
全局上下文问题
由于要把goReplay和repeater结合使用,要使repeater能识别此条流量是goReplay标记的流量就需要一个标记来从头到尾的标记此流量。最终的方案是在业务系统中增加过滤器,用一在全局上下文中存放此条流量的标记,使标记随流量的流转一直流转至最底层。在dao层执行数据库操作时也需要在应用上下中加入用户标记,由平台架构的影响此标记只能在repeater探针中使用反射的手段来设置到应用上下文中。
Jvm-sandbox-repeater埋点问题
底层服务的埋点查找也是一个极大的工作量,要深入了解各个底层服务的业务实现逻辑,公司的应用繁多逻辑复杂使得这一任务工作耗时很大,而且要尝试各种不同的埋点方案来确定适用于销售易流量回放平台的最佳埋点方案,每一种埋点方案的探索都是很复杂的。最终使用的埋点方案是在生成主键的方法上进行埋点,从而使录制环境的数据插入和回放环境的数据插入保持一致的我主键id,以兼容更多的回放流量类型。
实践结果
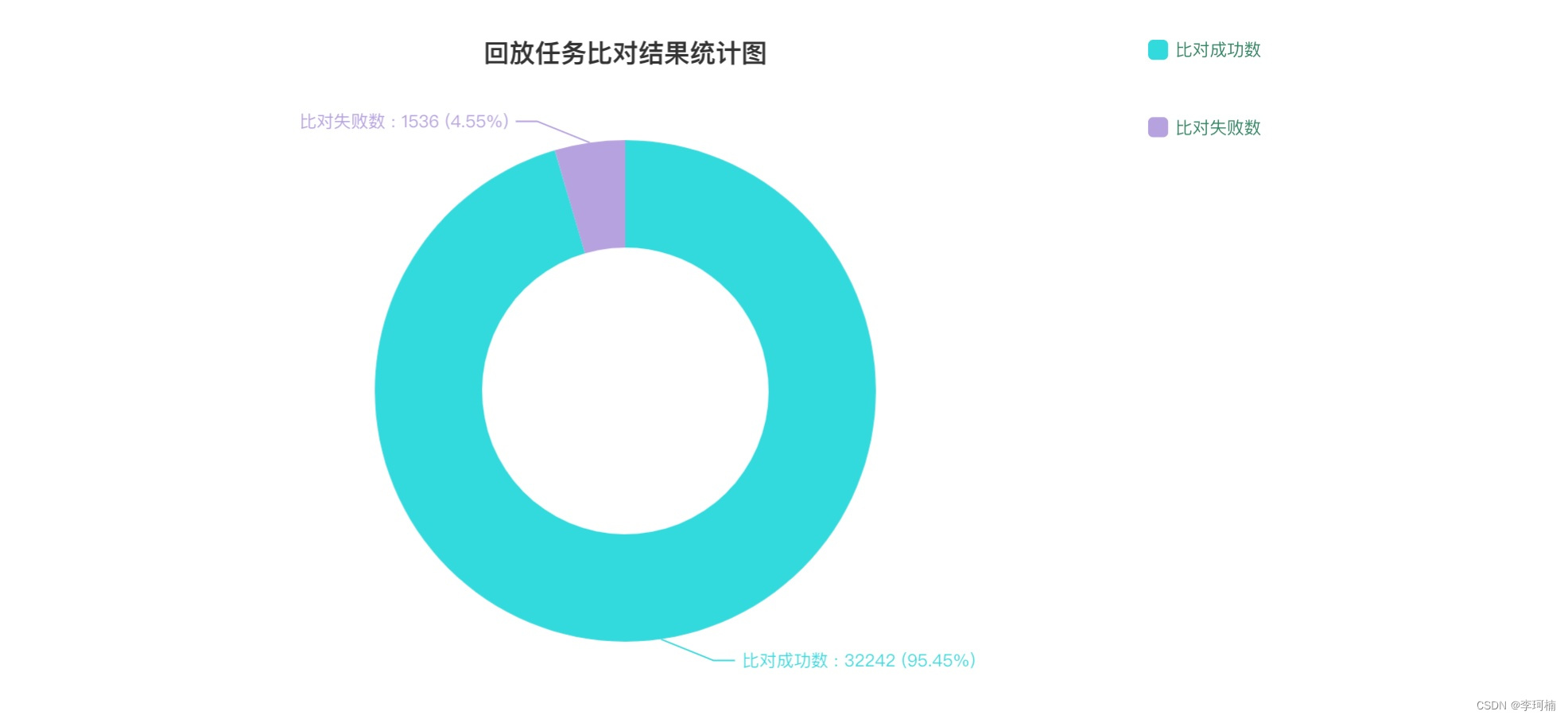
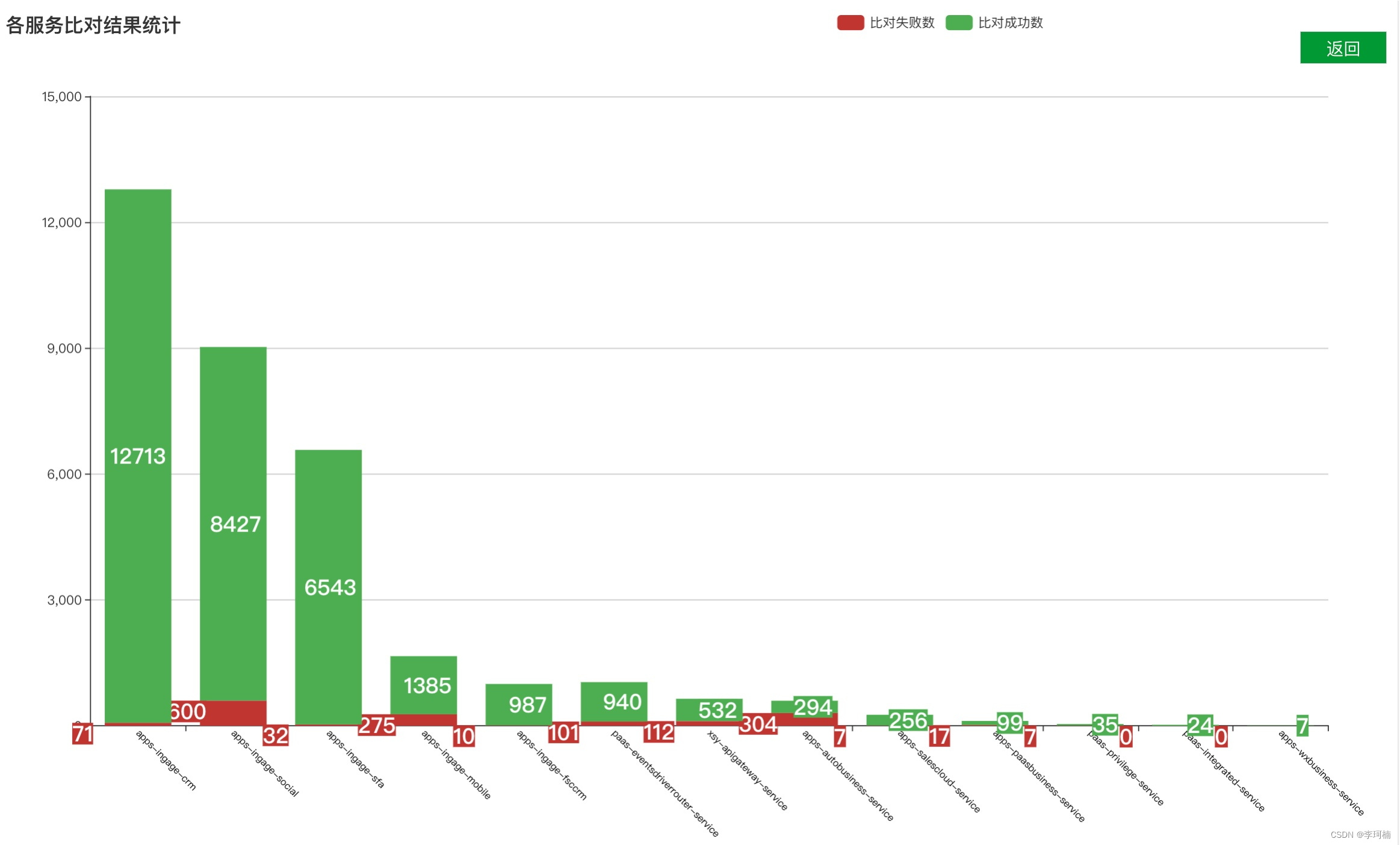
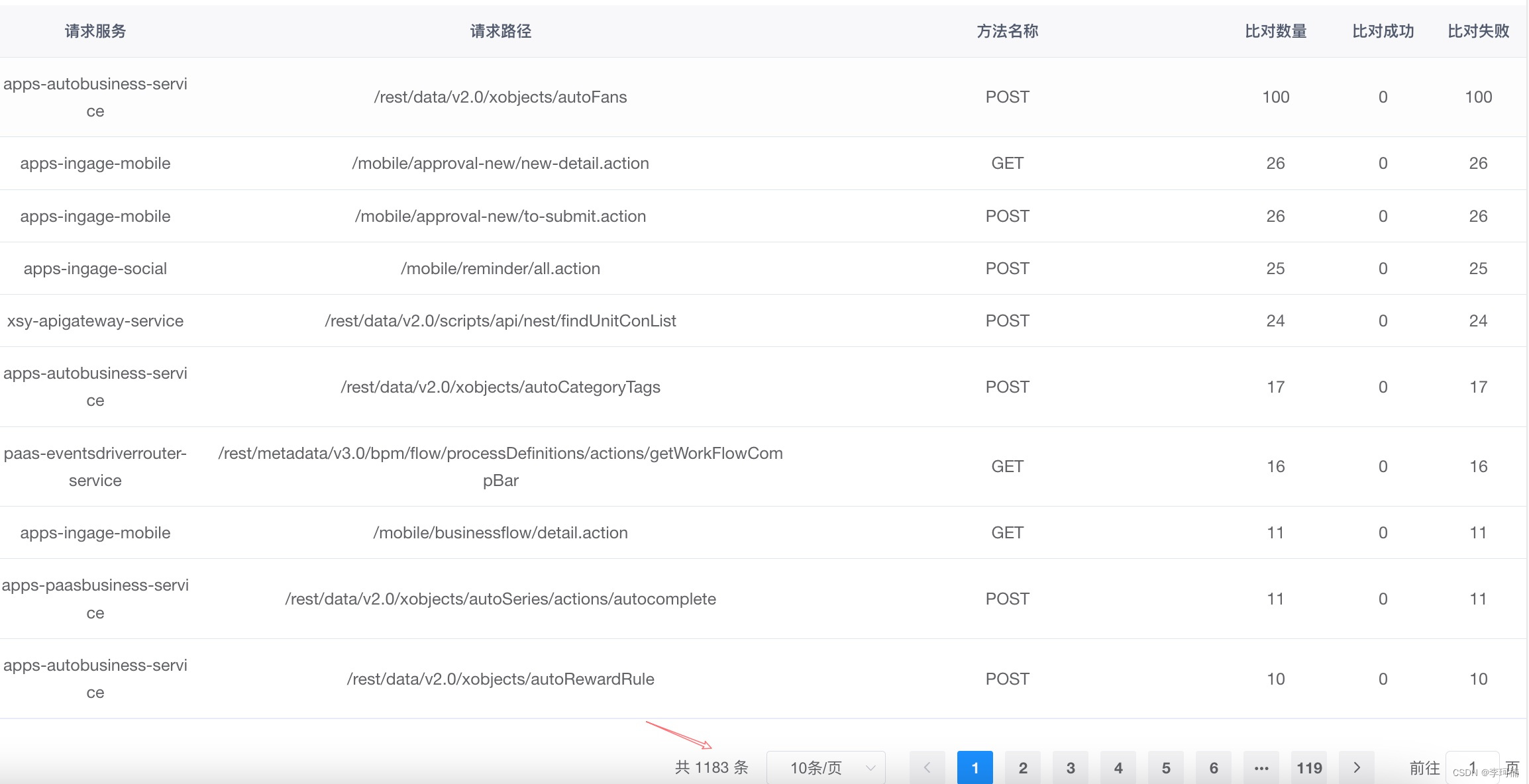
截止目前为止流量回放在沙盒环境上线也有几个月的时间了,也帮助业务排查出了一些问题,在近期也会加入到MR版本升级流程中为保证产品质量保驾护航,以下是流量回放平台的一些回放结果。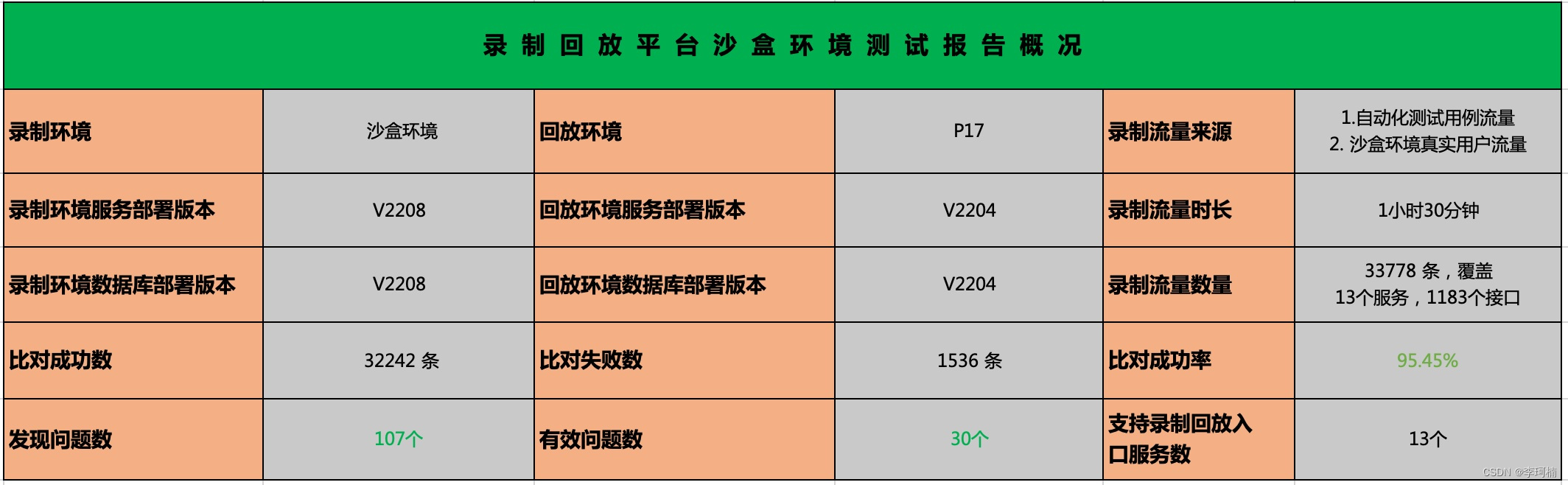
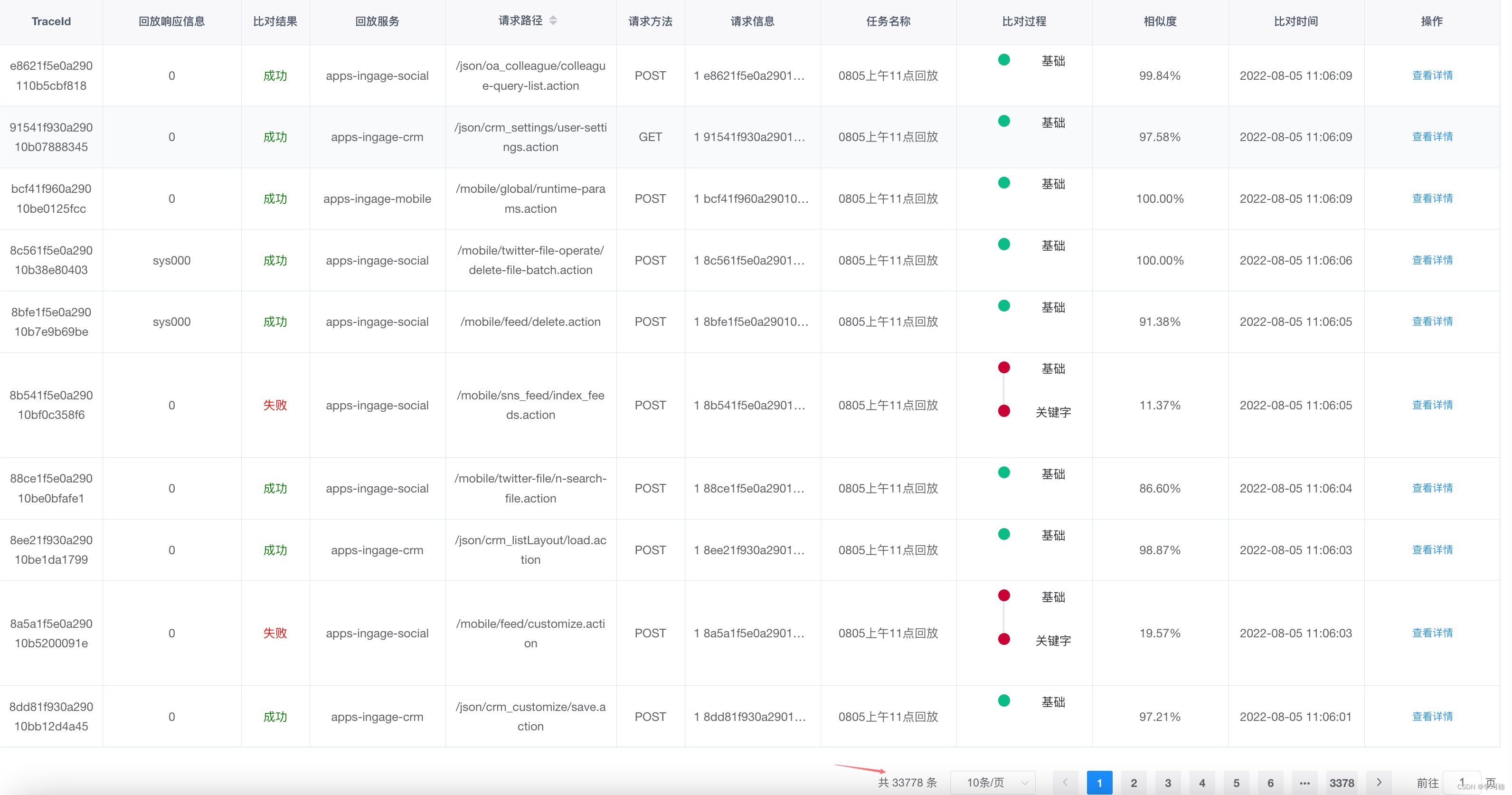
总结
流量录制回放作为测试领域的一个新生事物,在诞生初期就吸引了广大测试同仁的关注,各个公司也对此进行了一些实践。任何一个新平台的探索都是一步一步踩坑填坑逐渐成型的。销售易对流量录制回放的实践还属于比较初期的阶段,一些问题的解法也在探索中 (例如回放流量比对分析如何可以更高效的排查问题)。但是在沙盒环境录制P17环境回放了一段时间,目前已经看到了一些流量录制回放在业务迭代中产生了价值,发现了一些隐藏bug。期望我们能在不断的实践中把得物的流量录制回放体系建设得越来越完善,产生更多的业务价值。
版权归原作者 李珂楠 所有, 如有侵权,请联系我们删除。