
操作系统参数调优
在性能调优过程中,可以根据实际业务情况修改关键操作系统(OS)配置参数,以提升openGauss数据库的性能。
前提条件
需要用户使用gs_check检查操作系统参数结果是否和建议值保持一致,如果不一致,用户可根据实际业务情况去手动修改。
内存相关参数设置
配置“sysctl.conf”文件,修改内存相关参数vm.extfrag_threshold为1000(参考值),如果文件中没有内存相关参数,可以手动添加。
vim /etc/sysctl.conf
修改完成后,请执行如下命令,使参数生效。
sysctl -p
网络相关参数设置
- 配置“sysctl.conf”文件,修改网络相关参数,如果文件中没有网络相关参数,可以手动添加。详细说明请参见表1。
vim /etc/sysctl.conf在修改完成后,请执行如下命令,使参数生效。sysctl -p表 1 网络相关参数参数名参考值说明net.ipv4.tcp_timestamps1表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭,1表示打开。net.ipv4.tcp_mem94500000 915000000 927000000第一个数字表示,当tcp使用的page少于 94500000 时,kernel不对其进行任何的干预。第二个数字表示,当tcp使用的page超过 915000000 时,kernel会进入“memory pressure”压力模式。第三个数字表示,当tcp使用的pages超过 927000000 时,就会报:Out of socket memory。net.ipv4.tcp_max_orphans3276800最大孤儿套接字(orphan sockets)数。net.ipv4.tcp_fin_timeout60表示系統默认的TIMEOUT时间。net.ipv4.ip_local_port_range26000 65535TCP和UDP能够使用的port段。 - 设置10GE网卡最大传输单元(MTU),使用ifconfig命令设置。10GE网卡推荐设置为8192,可提升网络带宽利用率。示例:
#ifconfig ethx mtu 8192#ifconfig ethxethx Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:XXinet addr:xxx.xxx.xxx.xxx Bcast:xxx.xxx.xxx.xxx Mask:xxx.xxx.xxx.0inet6 addr: fxxx::9xxx:bxxx:xxxa:1d18/64 Scope:LinkUP BROADCAST RUNNING MULTICAST **MTU:8192** Metric:1RX packets:179849803 errors:0 dropped:0 overruns:0 frame:0TX packets:40492292 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000RX bytes:17952090386 (17120.4 Mb) TX bytes:171359670290 (163421.3 Mb)
说明:
- ethx为10GE数据库内部使用的业务网卡。
- 第一条命令设置MTU,第二条命令验证是否设置成功,粗体部分为MTU的值。
- 需使用root用户设置。

- 设置10GE网卡接收(rx)、发送队列(tx)长度,使用ethtool工具设置。10GE网卡推荐设置为4096,可提升网络带宽利用率。示例:
# ethtool -G ethx rx 4096 tx 4096# ethtool -g ethxRing parameters for ethx:Pre-set maximums:RX: 4096RX Mini: 0RX Jumbo: 0TX: 4096Current hardware settings:RX: 4096RX Mini: 0RX Jumbo: 0TX: 4096> > > 说明:> - ethx为10GE数据库内部使用的业务网卡。> - 第一条命令设置网卡接收、发送队列长度,第二条命令验证是否设置成功,示例的输出表示设置成功。> - 需使用root用户设置。
> > 说明:> - ethx为10GE数据库内部使用的业务网卡。> - 第一条命令设置网卡接收、发送队列长度,第二条命令验证是否设置成功,示例的输出表示设置成功。> - 需使用root用户设置。
I/O相关参数设置
设置hugepage属性。通过如下命令,关闭透明大页。
复制代码echo never >
/sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
修改完成后,请执行如下命令,使参数生效。
reboot
数据库系统参数调优
为了保证数据库尽可能高性能地运行,建议依据硬件资源情况和业务实际进行数据库系统参数——GUC参数的设置。这里主要介绍GUC参数对性能的影响,关于参数的详细设置方法请参见“管理员指南”。
数据库内存参数调优
数据库的复杂查询语句性能非常强的依赖于数据库系统内存的配置参数。数据库系统内存的配置参数主要包括逻辑内存管理的控制参数和执行算子是否下盘的参数。
逻辑内存管理参数
逻辑内存管理参数为max_process_memory,主要功能是控制数据库节点上可用内存的最大峰值,该参数的数值设置公式参考max_process_memory。
执行作业最终可用的内存为:
max_process_memory – shared memory ( 包括shared_buffers ) – cstore_buffers
所以影响执行作业可用内存参数的主要两个参数为shared_buffers及cstore_buffers。
逻辑内存管理有专门的视图查询数据库节点中各大块内存区域已使用内存及峰值信息。可连接到单个数据库节点,通过“pg_total_memory_detail”查询该节点上内存区域信息;或者连接到数据库主节点,通过“pgxc_total_memory_detail”查询节点上内存区域信息。
参数work_mem依据查询特点和并发来确定,一旦work_mem限定的物理内存不够,算子运算数据将写入临时表空间,带来5-10倍的性能下降,查询响应时间从秒级下降到分钟级。
- 对于串行无并发的复杂查询场景,平均每个查询有5-10关联操作,建议work_mem=50%内存/10。
- 对于串行无并发的简单查询场景,平均每个查询有2-5个关联操作,建议work_mem=50%内存/5。
- 对于并发场景,建议work_mem=串行下的work_mem/物理并发数。
执行算子是否下盘的参数
参数work_mem可以判断执行作业可下盘算子是否已使用内存量触发下盘点。当前可下盘算子有六类(向量化及非向量化共10种):Hash(VecHashJoin)、Agg(VecAgg)、Sort(VecSort)、Material(VecMaterial)、SetOp(VecSetOp)、WindowAgg(VecWindowAgg)。该参数设置通常是一个权衡,即要保证并发的吞吐量,又要保证单查询作业的性能,故需要根据实际执行情况(结合Explain Performance输
数据库并发队列参数调优
数据库提供两种手段进行并发队列的控制,全局并发队列和局部并发队列。
全局并发队列
全局并发队列采用GUC参数max_active_statements控制数据库主节点上运行并发执行的作业数量。采用全局并发队列机制将控制所有普通用户的执行作业,不区分复杂度,即执行语句都将作为一个执行单元,当并发执行的作业数量达到此参数阈值时,将进入队列等待。对于管理员执行的作业,不走全局并发控制逻辑。
设置该GUC参数数值时,需要考虑系统的承受能力,主要关注内存的使用情况及IO的使用情况,综合判断。若普通用户关联资源池,并且资源池中的优先级比例不同,全局并发队列在数据库内部将使用两维队列,即优先级高低排队和同一优先级进行排队。在唤醒时,将优先唤醒高优先级队列的作业。
说明:
- 在事务类大并发业务场景下,参数max_active_statements建议设置为-1,即不限制全局并发数。
- 在分析类查询的场景下,参数max_active_statements的值设置为CPU的核数除以数据库节点个数,一般可以设置5~8个。

局部并发队列
采用资源池局部并发控制机制的目的是控制在数据库主节点上同一资源池内的并发作业数量。局部并发控制机制根据执行作业的cost,控制复杂查询的并发作业数量。
参数parctl_min_cost数值用于判断执行作业是否是复杂作业。
配置SMP
介绍SMP模块的使用限制与适用场景,并给出SMP配置指南。
SMP适用场景与限制
背景信息
SMP特性通过算子并行来提升性能,同时会占用更多的系统资源,包括CPU、内存、I/O等等。本质上SMP是一种以资源换取时间的方式,在合适的场景以及资源充足的情况下,能够起到较好的性能提升效果;但是如果在不合适的场景下,或者资源不足的情况下,反而可能引起性能的劣化。SMP特性适用于分析类查询场景,这类场景的特点是单个查询时间较长、业务并发度低。通过SMP并行技术能够降低查询时延,提高系统吞吐性能。然而在事务类大并发业务场景下,由于单个查询本身的时延很短,使用多线程并行技术反而会增加查询时延,降低系统吞吐性能。
适用场景
- 支持并行的算子:计划中存在以下算子支持并行。- Scan:支持行存普通表和行存分区表顺序扫描 、列存普通表和列存分区表顺序扫描。- Join:HashJoin、NestLoop。- Agg:HashAgg、SortAgg、PlainAgg、WindowAgg(只支持partition by,不支持order by)。- Stream:Local Redistribute、Local Broadcast。- 其他:Result、Subqueryscan、Unique、Material、Setop、Append、VectoRow。
- SMP特有算子:为了实现并行,新增了并行线程间的数据交换Stream算子供SMP特性使用。这些新增的算子可以看做Stream算子的子类。- Local Gather:实现实例内部并行线程的数据汇总。- Local Redistribute:在实例内部各线程之间,按照分布键进行数据重分布。- Local Broadcast:将数据广播到实例内部的每个线程。- Local RoundRobin:在实例内部各线程之间实现数据轮询分发。
- 示例说明,以TPCH Q1的并行计划为例。
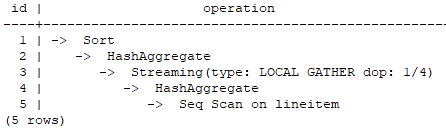 在这个计划中,实现了Scan以及HashAgg算子的并行,并新增了Local Gather数据交换算子。其中3号算子为Local Gather算子,上面标有的“dop: 1/4”表明该算子的发送端线程的并行度为4,而接受端线程的并行度为1,即下层的4号HashAggregate算子按照4并行度执行,而上层的1~2号算子按照串行执行,3号算子实现了实例内并行线程的数据汇总。通过计划Stream算子上表明的dop信息即可看出各个算子的并行情况。
在这个计划中,实现了Scan以及HashAgg算子的并行,并新增了Local Gather数据交换算子。其中3号算子为Local Gather算子,上面标有的“dop: 1/4”表明该算子的发送端线程的并行度为4,而接受端线程的并行度为1,即下层的4号HashAggregate算子按照4并行度执行,而上层的1~2号算子按照串行执行,3号算子实现了实例内并行线程的数据汇总。通过计划Stream算子上表明的dop信息即可看出各个算子的并行情况。
非适用场景
- 索引扫描不支持并行执行。
- MergeJoin不支持并行执行。
- WindowAgg order by不支持并行执行。
- cursor不支持并行执行。
- 存储过程和函数内的查询不支持并行执行。
- 不支持子查询subplan和initplan的并行,以及包含子查询的算子的并行。
- 查询语句中带有median操作的查询不支持并行执行。
- 带全局临时表的查询不支持并行执行。
- 物化视图的更新不支持并行执行。
资源对SMP性能的影响
SMP架构是一种利用富余资源来换取时间的方案,计划并行之后必定会引起资源消耗的增加,包括CPU、内存、I/O等资源的消耗都会出现明显的增长,而且随着并行度的增大,资源消耗也随之增大。当上述资源成为瓶颈的情况下,SMP无法提升性能,反而可能导致集群整体性能的劣化。下面对各种资源对SMP性能的影响情况分别进行说明。
- CPU资源在一般客户场景中,系统CPU利用率不高的情况下,利用SMP并行架构能够更充分地利用系统CPU资源,提升系统性能。但当数据库服务器的CPU核数较少,CPU利用率已经比较高的情况下,如果打开SMP并行,不仅性能提升不明显,反而可能因为多线程间的资源竞争而导致性能劣化。
- 内存资源查询并行后会导致内存使用量的增长,但每个算子使用内存上限仍受到work_mem等参数的限制。假设work_mem为4GB,并行度为2,那么每个并行线程所分到的内存上限为2GB。在work_mem较小或者系统内存不充裕的情况下,使用SMP并行后,可能出现数据下盘,导致查询性能劣化的问题。
- I/O资源要实现并行扫描必定会增加I/O的资源消耗,因此只有在I/O资源充足的情况下,并行扫描才能够提高扫描性能。
其他因素对SMP性能的影响
除了资源因素外,还有一些因素也会对SMP并行性能造成影响。例如分区表中分区数据不均,以及系统并发度等因素。
- 数据倾斜对SMP性能的影响当数据中存在严重数据倾斜时,并行效果较差。例如某表join列上某个值的数据量远大于其他值,开启并行后,根据join列的值对该表数据做hash重分布,使得某个并行线程的数据量远多于其他线程,造成长尾问题,导致并行后效果差。
- 系统并发度对SMP性能的影响SMP特性会增加资源的使用,而在高并发场景下资源剩余较少。所以,如果在高并发场景下,开启SMP并行,会导致各查询之间严重的资源竞争问题。一旦出现了资源竞争的现象,CPU、I/O、内存都会导致整体性能的下降。因此在高并发场景下,开启SMP往往不能达到性能提升的效果,甚至可能引起性能劣化。
SMP 使用建议
使用限制
想要利用SMP提升查询性能需要满足以下条件:
系统的CPU、内存、I/O和网络带宽等资源充足。SMP架构是一种利用富余资源来换取时间的方案,计划并行之后必定会引起资源消耗的增加,当上述资源成为瓶颈的情况下,SMP无法提升性能,反而可能导致性能的劣化。在出现资源瓶颈的情况下,建议关闭SMP。
配置步骤
- 观察当前系统负载情况,如果系统资源充足(资源利用率小于50%),执行2;否则退出。
- 设置query_dop=1(默认值),利用explain打出执行计划,观察计划是否符合SMP适用场景与限制小节中的适用场景。如果符合,进入3。
- 设置query_dop=value,不考虑资源情况和计划特征,强制选取dop为1或value。
配置LLVM
LLVM(Low Level Virtual Machine)动态编译技术可以为每个查询生成定制化的机器码用于替换原本的通用函数。通过减少实际查询时冗余的条件逻辑判断、虚函数调用并提高数据局域性,从而达到提升查询整体性能的目的。
由于LLVM需要消耗额外的时间预生成IR中间态表示并编译成机器码,因此在小数据量场景或查询本身耗时较少时,可能引起性能的劣化。
LLVM适用场景与限制
适用场景
- 支持LLVM的表达式查询语句中存在以下的表达式支持LLVM优化:1. Case…when… 表达式2. In表达式3. Bool表达式(And/Or/Not)4. BooleanTest表达式(IS_NOT_KNOWN/IS_UNKNOWN/IS_TRUE/IS_NOT_TRUE/IS_FALSE/IS_NOT_FALSE)5. NullTest表达式(IS_NOT_NULL/IS_NULL)6. Operator表达式7. Function表达式(lpad、substring、btrim、rtrim、length)8. Nullif表达式表达式计算支持的数据类型包括bool、tinyint、smallint、int、bigint、float4、float8、numeric、date、time、timetz、timestamp、timestamptz、interval、bpchar、varchar、text、oid。仅当表达式出现在向量化执行引擎中Scan节点的filter,Hash Join节点中的complicate hash condition、hash join filter、hash join target,Nested Loop节点中的filter、join filter,Merge Join节点的merge join filter、merge join target,Group节点中的filter表达式时,才会考虑是否使用LLVM动态编译优化。
- 支持LLVM的算子:1. Join:HashJoin2. Agg:HashAgg3. Sort其中HashJoin算子仅支持Hash Inner Join,对应的hash cond仅支持int4、bigint、bpchar类型的比较;HashAgg算子仅支持针对bigint、numeric类型的sum及avg操作,且group by语句仅支持int4、bigint、bpchar、text、varchar、timestamp类型操作,同时支持count(*)聚集操作。Sort算子仅支持对int4、bigint、numeric、bpchar、text、varchar数据类型的比较操作。除此之外,无法使用LLVM动态编译优化,具体可通过explain performance工具进行显示。
非适用场景
- 不支持小数据量表使用LLVM动态编译优化。
- 不支持生成非向量化执行路径的查询作业。
其他因素对LLVM性能的影响
LLVM优化效果不仅依赖于数据库内部具体的实现,还与当前所选择的硬件环境等有关。
- 表达式调用C-函数个数数据库内部针对表达式计算并未实现全codegen,即在整个表达式计算中部分表达式实现了codegen,部分直接调用原本的C代码。如果整个表达式计算中后者占据了主要部分,使用LLVM动态编译优化,可能会导致性能劣化。通过设置log_min_message的级别为DEBUG1可以查看到哪些表达式直接调用了C代码实现。
- 内存资源LLVM特性的一个重要思想是保障数据的局域特性,即数据应尽可能的存放在寄存器中。同时应减少数据加载,因此在使用LLVM优化时应设置足够大的work_mem,保证对应使用LLVM优化的执行代码整个过程在内存中实现,否则可能引起性能劣化。
- 优化器代价估算LLVM特性实现了简易的代价估算模型,即依据当前参与节点运算的表大小决定当前节点是否考虑使用LLVM动态编译优化。如果优化器低估了实际参与运算的行数,则原本可获得收益的未正常获得收益。反之亦然。
LLVM使用建议
目前LLVM在数据库内核侧已默认打开,用户可结合上述的分析进行配置,总体建议如下:
- 设置合理的work_mem,在允许的条件下尽可能设置较大的work_mem,如果出现大量数据落盘,则建议关闭LLVM动态编译优化(通过设置enable_codegen=off实现)。
- 设置合理的codegen_cost_threshold(默认值为10000),确保小数据量场景下避免使用LLVM动态编译优化。当codegen_cost_threshold的值设定后,因使用LLVM动态编译优化引入性能劣化,则建议增加codegen_cost_threshold的取值。
- 对于表达式计算使用LLVM动态编译优化,如果存在大量的调用C-函数的场景,建议关闭LLVM动态编译优化。>
 > > 说明:> 在资源许可的情况下,数据量越大,可获得的性能提升效果越好。
> > 说明:> 在资源许可的情况下,数据量越大,可获得的性能提升效果越好。
版权归原作者 Gauss松鼠会 所有, 如有侵权,请联系我们删除。