

介绍
SQL Gateway 是一种支持远程多个客户机并发执行 SQL 的服务。它提供了一种提交 Flink Job、查找元数据和在线分析数据的简单方法。SQL Gateway 由可插拔 Endpoints 和 SqlGatewayService 组成。SqlGatewayService 是一个被 Endpoints 重用来处理请求的处理器。Endpoints 是允许用户连接的入口点。根据 Endpoints 的类型,用户可以使用不同的工具进行连接。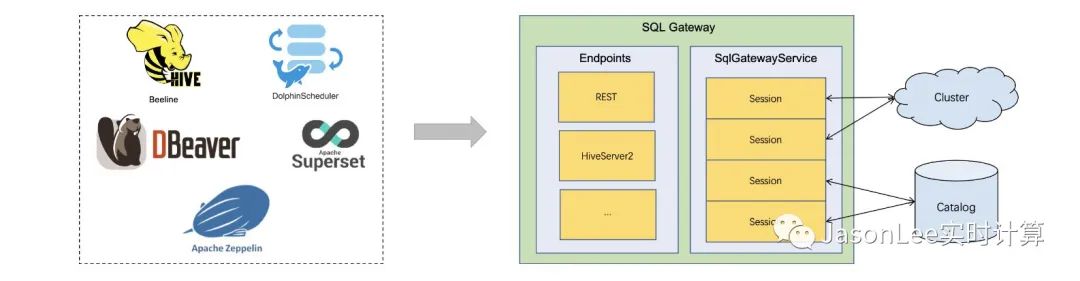
image-20221213103508918
开始
Flink SQL Gateway 是和 Flink 发行版绑定的,因此可以开箱即用,它只需要一个正在运行的 Flink 集群用来执行我们的 SQL 任务,我们可以把任务提交到 standalone 集群或者 yarn 集群,下面以 standalone 为例来介绍一下具体的使用方式。
启动集群
./start-cluster.sh
启动 SQL Gateway
./sql-gateway.sh start -Dsql-gateway.endpoint.rest.address=localhost
sql-gateway.endpoint.rest.address 用来指定 SQL Gateway 服务绑定的地址,这里设置为 localhost 就只能在本机访问。
另外在启动 SQL Gateway 的时候,还可以设置为 start-foreground 这样就会把 SQL Gateway 作为控制台程序运行,这样方便我们查看日志和排查问题。如果是用 start 模式启动的,则需要去 flink/log 下面查看 SQL Gateway 对应的日志。
检查 REST Endpoint 是否可用
curl http://localhost:8083/v1/info
返回的结果为
{"productName":"Apache Flink","version":"1.16.0"}
启动完成后我们可以使用上面的命令查看 Endpoint 是否可用。
运行 SQL 查询
创建 session
在执行之前我们需要先创建一个 session ,可以通过下面的命令。
curl --request POST http://localhost:8083/v1/sessions
返回的结果为
{"sessionHandle":"d9befa48-8b52-42f4-93a0-b8b948552452"}
sessionHandle 表是的是这个 session 的 id,是这个 session 的唯一标识。
执行查询
curl --request POST http://localhost:8083/v1/sessions/d9befa48-8b52-42f4-93a0-b8b948552452/statements/ --data '{"statement": "SELECT 1"}'
在执行查询的时候需要把 URL 中的 ${sessionHandle} 替换成刚才创建 session 返回结果中的 sessionHandle。
返回的结果为
{"operationHandle":"ce3489f5-74a2-41d7-8d83-1caa301d6779"}
SQL Gateway 使用返回结果中的 operationHandle 唯一地标识提交的 SQL。
获取查询结果
curl --request GET http://localhost:8083/v1/sessions/e0eece3e-49b3-42d8-99b5-ede3a565b1a5/operations/db5c72ca-6794-4fc5-b998-95aede435aad/result/0
同样的,这里需要把 URL 中的 和{operationHandle} 都替换为上面返回结果中的 ID。
返回的结果为
{
"results":{
"columns":[
{
"name":"EXPR$0",
"logicalType":{
"type":"INTEGER",
"nullable":false
},
"comment":null
}
],
"data":[
{
"kind":"INSERT",
"fields":[
1
]
}
]
},
"resultType":"PAYLOAD",
"nextResultUri":"/v1/sessions/e0eece3e-49b3-42d8-99b5-ede3a565b1a5/operations/db5c72ca-6794-4fc5-b998-95aede435aad/result/1"
}
如果结果中的 nextResultUri 不为空,则用于获取下一批结果,相当于是一个分页查询的效果。
curl --request GET ${nextResultUri}
配置
SQL Gateway 启动选项
目前,SQL Gateway 脚本有以下可选命令。它们将在后面各段中详细讨论。
$ ./bin/sql-gateway.sh --help
Usage: sql-gateway.sh [start|start-foreground|stop|stop-all] [args]
commands:
start - Run a SQL Gateway as a daemon
start-foreground - Run a SQL Gateway as a console application
stop - Stop the SQL Gateway daemon
stop-all - Stop all the SQL Gateway daemons
-h | --help - Show this help message
对于 “start” or “start-foreground” 命令,可以在命令行下配置 SQL Gateway。
$ ./bin/sql-gateway.sh start --help
Start the Flink SQL Gateway as a daemon to submit Flink SQL.
Syntax: start [OPTIONS]
-D <property=value> Use value for given property
-h,--help Show the help message with descriptions of all
options.
SQL Gateway 配置
当启动 SQL Gateway 时,你可以通过下面的方式配置 SQL Gateway,或任何有效的 Flink 配置项。
$ ./sql-gateway -Dkey=value
KeyDefaultTypeDescriptionsql-gateway.session.check-interval1 minDurationThe check interval for idle session timeout, which can be disabled by setting to zero or negative value.sql-gateway.session.idle-timeout10 minDurationTimeout interval for closing the session when the session hasn't been accessed during the interval. If setting to zero or negative value, the session will not be closed.sql-gateway.session.max-num1000000IntegerThe maximum number of the active session for sql gateway service.sql-gateway.worker.keepalive-time5 minDurationKeepalive time for an idle worker thread. When the number of workers exceeds min workers, excessive threads are killed after this time interval.sql-gateway.worker.threads.max500IntegerThe maximum number of worker threads for sql gateway service.sql-gateway.worker.threads.min5IntegerThe minimum number of worker threads for sql gateway service.
上面的 DEMO 比较简单,而且是通过 CURL 命令工具提交的,下面我们使用代码的方式来提交一个简单的 Flink SQL 任务。
FlinkSqlGatewaySubmitJob
package flink.sql.gateway;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import okhttp3.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class FlinkSqlGatewaySubmitJob {
private static final Logger LOG = LoggerFactory.getLogger(FlinkSqlGatewaySubmitJob.class);
// 创建 session 的 URL
private static final String CREATE_SESSION = "http://localhost:8083/v1/sessions";
// 提交 SQL 的 URL
private static String SUBMIT_SQL =
"http://localhost:8083/v1/sessions/${sessionHandle}/statements/";
// 查询结果的 URL
private static String QUERY_RESULT =
"http://localhost:8083/v1/sessions/${sessionHandle}/operations/${operationHandle}/result/0";
public static void main(String[] args) throws IOException {
// 创建一个 session
String create_session = httpPost(CREATE_SESSION, "");
JSONObject jsonObject = JSON.parseObject(create_session);
// 获取 sessionHandle
String sessionHandle = jsonObject.getString("sessionHandle");
System.out.println(create_session);
SUBMIT_SQL = SUBMIT_SQL.replace("${sessionHandle}", sessionHandle);
String OrdersDDL =
"CREATE TABLE Orders (order_number BIGINT,price DECIMAL(32,2),buyer ROW<first_name STRING, last_name STRING>,order_time TIMESTAMP(3)) WITH('connector'='datagen','rows-per-second'='1')";
String ResultDDL =
"CREATE TABLE Result_table (order_number BIGINT,price DECIMAL(32,2),buyer ROW<first_name STRING, last_name STRING>,order_time TIMESTAMP(3)) WITH('connector'='print')";
String DML = "insert into Result_table select * from Orders";
// 创建 Source Table
String submitSQL1 = httpPost(SUBMIT_SQL, MapToString(OrdersDDL));
System.out.println(submitSQL1);
// 创建 Sink Table
String submitSQL2 = httpPost(SUBMIT_SQL, MapToString(ResultDDL));
System.out.println(submitSQL2);
// 执行 INSERT INTO 语句
String submitSQL3 = httpPost(SUBMIT_SQL, MapToString(DML));
System.out.println(submitSQL3);
JSONObject jsonObject1 = JSON.parseObject(submitSQL3);
String operationHandle = jsonObject1.getString("operationHandle");
QUERY_RESULT =
QUERY_RESULT
.replace("${sessionHandle}", sessionHandle)
.replace("${operationHandle}", operationHandle);
String result = httpGet(QUERY_RESULT);
System.out.println(result);
}
public static String httpPost(String url, String json) throws IOException {
OkHttpClient httpClient = new OkHttpClient().newBuilder().build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, json);
Request request =
new Request.Builder()
.url(url)
// .addHeader("Authorization", "Basic " + authorization)
.post(body)
.build();
Response response = httpClient.newCall(request).execute();
return response.body().string();
}
public static String httpGet(String url) throws IOException {
OkHttpClient httpClient = new OkHttpClient().newBuilder().build();
Request request = new Request.Builder().url(url).get().build();
Response response = httpClient.newCall(request).execute();
return response.body().string();
}
public static String MapToString(String ddl) {
Map<String, String> paramsMap = new HashMap<>();
paramsMap.put("statement", ddl);
return JSON.toJSONString(paramsMap);
}
}
代码也非常简单,跟上面的流程是一样的,打印的结果为:
{"sessionHandle":"ebdb4f09-fc82-4774-8cff-497be4d60ebe"}
{"operationHandle":"4fbad353-3f69-454c-84a9-ac050e8ba096"}
{"operationHandle":"90015d6a-56e6-4c7e-8638-9ef60bb0288f"}
{"operationHandle":"a452d5a1-8c02-47fc-b83d-15a0c1fceb49"}
{"results":{"columns":[],"data":[]},"resultType":"NOT_READY","nextResultUri":"/v1/sessions/ebdb4f09-fc82-4774-8cff-497be4d60ebe/operations/a452d5a1-8c02-47fc-b83d-15a0c1fceb49/result/0"}
Flink UI
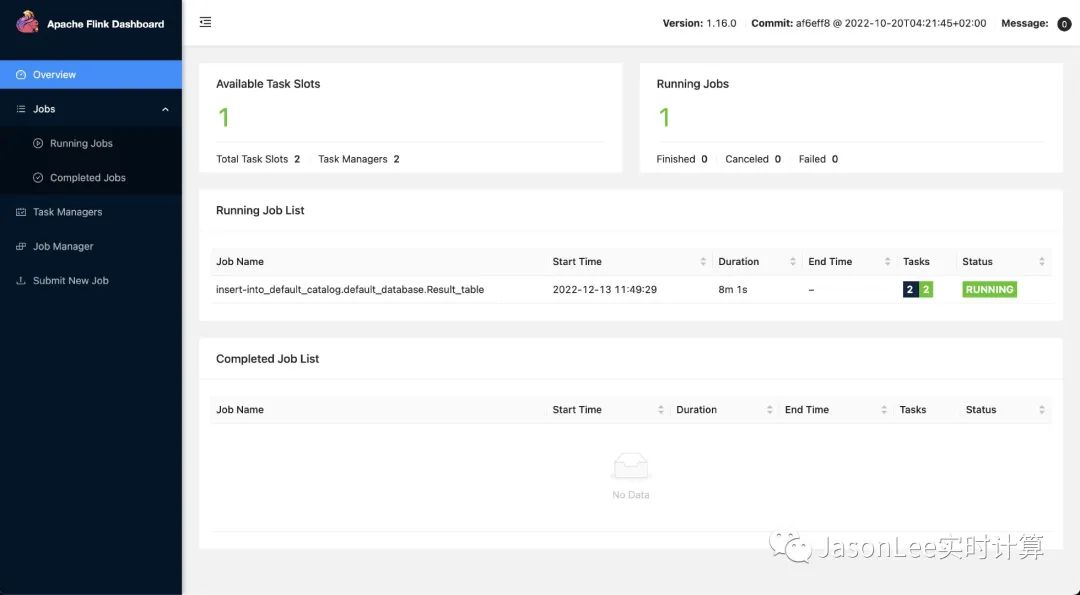
image-20221213115740907
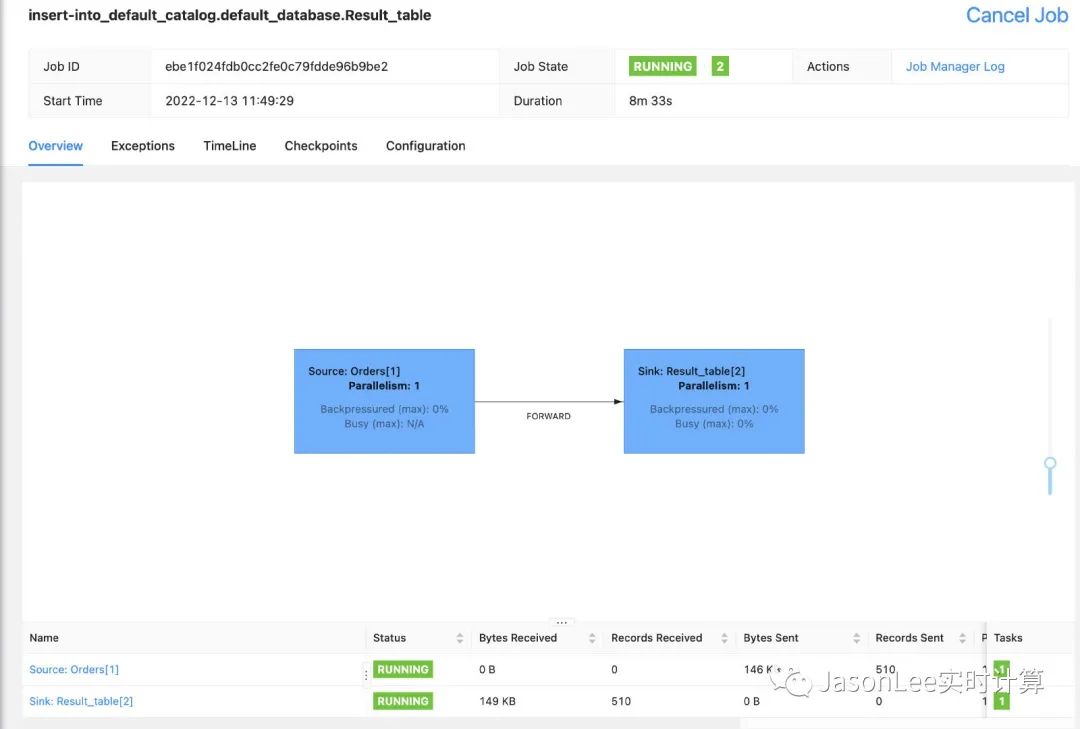
image-20221213115810512
可以看到任务提交成功了,再来看下打印的结果是否正确。
image-20221213115935611
数据也正常打印了。
除了 Rest Endpoint ,Flink 目前还支持 HiveServer2 Endpoint,这个后面有时间再说。今天就先略过了。
推荐阅读
Flink 任务实时监控最佳实践
Flink on yarn 实时日志收集最佳实践
Flink 1.14.0 全新的 Kafka Connector
Flink 1.14.0 消费 kafka 数据自定义反序列化类
Flink SQL JSON Format 源码解析
Flink on yarn 远程调试源码
Flink 通过 State Processor API 实现状态的读取和写入
Flink 侧流输出源码解析
Flink 源码:广播流状态源码解析
Flink 源码分析之 Client 端启动流程分析
Flink Print SQL Connector 添加随机取样功能
如果你觉得文章对你有帮助,麻烦点一下
赞
和
在看
吧,你的支持是我创作的最大动力。
版权归原作者 JasonLee实时计算 所有, 如有侵权,请联系我们删除。