

你在网上发布了多少关于你自己的信息?好吧,在当今时代可能有很多。我们不断地联系在一起,与很多人分享生活中的瞬间,无论这些人是否认识我们。这很好,只要你决定你想展示什么。但是,如果我告诉你,通过写文章,你所展示出的隐私超过你所意识到的内容呢?

我们可以想象,一个人的写作风格可能与他或她的个性有某种联系。使用“哇”、“拥抱”、“聚会”等词可能表明我们在阅读性格外向的人写的信息。另一方面,也有很直观的内向词汇的集合,例如:“孤独”,“书籍”,“平静”。很明显,这有点夸大了。事实上通过词汇判断性格并不是那么容易。人类要复杂得多,不能仅仅通过人格特征典型的词语来确定个人性格。或者以下图片中的他们可以?

说一个人的个性可以通过写篇文章来预测,就像上图一样
互联网上充斥着各种各样的人格测试。其中一些是用来让你感觉更好并以此说服你付费的。这基本上和测星座一样,没有任何实际价值。但在这片骗子和伪心理学家的海洋中,有一些基于科学研究的有趣测试。在我看来,值得特别注意的是迈尔斯-布里格斯类型指标(MBTI)。对我来说,这个结果非常准确,很多人似乎也有同样的感觉。所以我决定在这个领域进行发掘。在研究过程中,我发现了一个Kaggle数据集,其中包含一篇来自8600多人的帖子,这些帖子根据作者的测试结果标注了作者的个性特征。
什么样的数据是可用的?
上面提到的数据集非常简单。它只有两个专栏,其中一个包含来自Personality Cafe网络论坛的临时帖子,另一个是带有作者MBTI测试结果的标签。
基于此,我们可以就这些数据提出几个有趣的问题:
1, 每个人格特质在论坛用户中的分布情况如何?
2, 每个特质都有最重要的代表词吗?外向者的写作方式和内向者不同吗?或者是那些比较敏感的人在使用情感词汇?
3, 最后:能否根据某人的职位预测其性格类型?
让我们开始这个数据游戏
在我们继续之前,我们应该先解释一下这个神秘的缩写词到底是什么意思。每一个字母代表一个个体的特征。我们可以选择8种不同的类型,四种类型的组合创造了个性类型。

所以让我们试着回答第一个问题并检查数据集中每个人的分布。
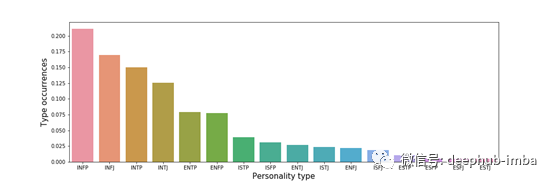
这个世界上似乎有更多的内向者而不是外向者…嗯,经过再三考虑,笔者认为分布似乎不正确。让我们检查一下测试作者的统计数据。
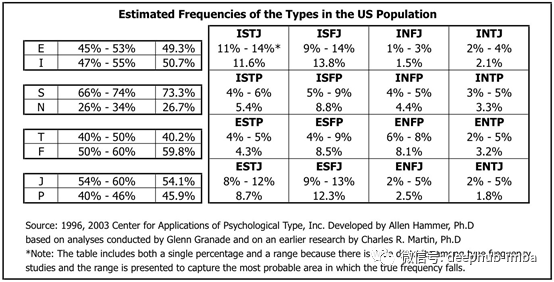
这真是太有趣了!上表中最受欢迎的特征似乎是ISTJ和ISFJ,得分分别为11%、6%和13.8%。这些结果与我在计算Kaggle数据集中的分布时得到的结果完全不同,在Kaggle数据集中,这两种类型的人大约占2-2.5%。
我们发现这些差异几乎适用于所有类型。看起来,拥有INFP、INFJ、INTP和INTJ类型的人最有可能在个性类型论坛上发帖。
此外,当我们在提供的图像中重新创建左侧的表时,我们可以看到它也完全不同。字母I、F和P在他们的首字母缩略词中的人将占过多的比例。在我们之后的分析中,我们必须记住这些数据是不平衡的。
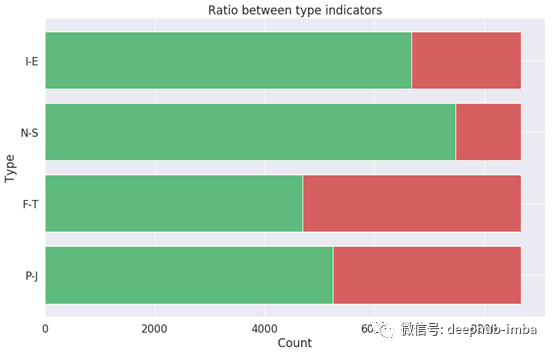
结论
自然而然得出的结论是,更注重分析自己的性格的是内向者,而不是更善于交际的外向者。基于这个原因,我们可以预期,他们将更有可能进行人格测试,并在保证这种匿名性的论坛上谈论自己。一点也不奇怪,情绪化程度更高的人(字母F)会更频繁地写自己。尤其是当它涉及到与内向的联系时,这往往会使这些人难以表达自己。
文本分析
正如我们之前看到的,数据有点混乱。它包含许多大小写混合的字母、标点符号、链接等。在我们开始分析之前,我们应该把它清理干净。我所做的相对简单,包括:
1, 删除链接。
2, 删除所有数字和标点符号。
3, 所有字母小写。
4, 删除休止符。
5, 一开始我使用了单词变体还原,但是它导致了准确度的显著降低,所以在进一步的分析中我放弃了它。
6, 用数字表示替换每个单词。
所有这些点都是非常经典的NLP方法。我不会详细讨论它,因为这篇文章可能会发展到可怕规模的阅读量并拥有很多的技术读者。如果你想知道更多,在Medium上你会发现很多描述自然语言处理方法的精彩文章。
分类
用以上方法处理过的数据已经准备好放入机器学习分类器。我决定使用带有线性核的支持向量分类器,因为除了对文本数据进行高效分类外,它还使我能够获得重要的特征(不同核不可能实现)。
在训练过程中,我选择了四种不同的分类法来决定哪些属性可以分配给作者,这些方法是(I)ntroverts或(E)xtraverts,(J)udgers或(F)eeler。
在第一次训练之后,结果很好……令人难以置信的好。但我并没有止步于此,决定继续发掘哪一个词对每个特质最重要。以下是分类结果:
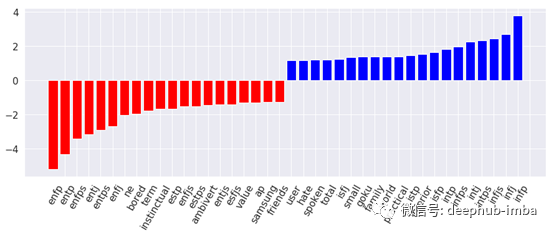
啊…我忘了把贴子上的字体指示器去掉!我们可以看到,对于我们的量词来说,判断作者是否内向(情节蓝色部分的最高条)最有价值的是个性类型本身的词。另一方面,外向者使用的最有价值的词(红色部分的最高但值是负的)是这个四个字母代码中带有“e”的词。这不公平!让我们回到我们的特性工程过程,并删除这些讨厌的字体指示器。
对外向者(红色条)和内向者(蓝色条)最具代表性的词:
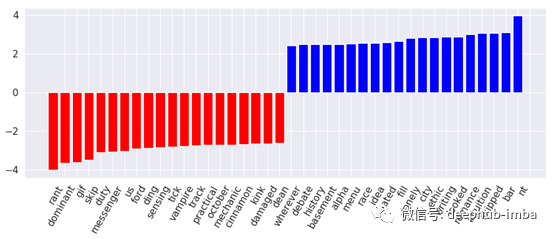
对直觉性人格(红色条)和感官性人格(蓝色条)最具代表性的词汇
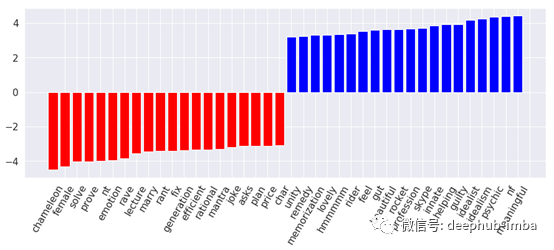
对感受性人格(红色条)和思考性人格(蓝色条)最具代表性的词汇
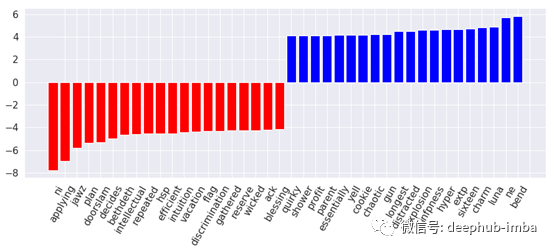
对感知性人格(红色条)和评判性人格(蓝色条)最具代表性的词汇
好吧,这看起来好多了。不像我想象的那么直观,但我必须接受这一结果。似乎外向的人更容易感到无聊和分心。另一方面,内向者似乎更实际,喜欢整理东西,感觉与大自然有某种联系。此外,他们往往喜欢权力的游戏,对这个群体来说,Cersei是一个相当有价值的词。感知者似乎与浪漫和孤独有关。思考者通常是理想主义者,感受者更可能是女性。
正如我们所看到的,这个结果是有真实性的。它可能不那么明显,也不容易解释,但只要稍加想象,你就能看到一些模式。我敢肯定,如果有更大的数据集,它们会更明显。
好吧,是时候找出最有趣的结果,回答第三个问题了。因为我们的数据是非常不平衡的,所以我使用了一种叫做f1分数的测量方法,这样处理在这种情况下是准确的。
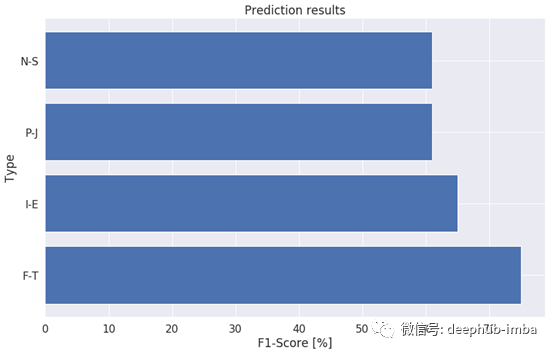
取得的成果并不特别惊人,在大多数情况下,这比随机猜测要好一点。最好的结果是感知者和思考者之间的区别。并不是因为这些类更容易区分,这个类只是最不平衡的。尽管如此,这个类的识别还是很有希望的!该模型实际上已经学会注意到某些特征,这些特征表明了文章作者具有哪些特征的区别。有了更复杂的数据,有了更多的记录,我们就能获得真正有趣的结果。
结果显示,在某些情况下我们可以感受到安全,写文章时不会冒着透露太多关于自己的信息的风险。同时,我强烈建议你参加考试(如果你还没有参加的话)。如果你愿意,你可以分享结果,这将有助于收集数据,以供日后分析!不过,如果你想把它留给自己,那就太可惜了。有几种方法可以让我们处理不平衡的数据,比如SMOTE。
如果你有数据科学的天赋,用我这里的代码可以得到你自己的结果。我想知道你是否会做得更好!
最后,别忘了点赞哦 !
作者:AmadeuszOleszczak
deephub翻译组:tensor-zhang
关注公众号 "deephub-imba" 发送 20200420 获取本篇文章的相关资源连接
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********