
海豚调度系列之:任务类型——Flink节点
一、Flink节点
Flink 任务类型,用于执行 Flink 程序。对于 Flink 节点:
- 当程序类型为 Java、Scala 或 Python 时,worker 使用 Flink 命令提交任务 flink run。
- 当程序类型为 SQL 时,worker 使用sql-client.sh 提交任务。
二、创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的 任务节点到画板中。
三、任务参数
任务参数描述程序类型支持 Java、Scala、 Python 和 SQL 四种语言主函数的 ClassFlink 程序的入口 Main Class 的全路径主程序包执行 Flink 程序的 jar 包(通过资源中心上传)部署方式支持 cluster、 local 和 application 三种模式的部署初始化脚本用于初始化会话上下文的脚本文件脚本用户开发的应该执行的 SQL 脚本文件Flink 版本根据所需环境选择对应的版本即可任务名称(选填)Flink 程序的名称jobManager 内存数用于设置 jobManager 内存数,可根据实际生产环境设置对应的内存数Slot 数量用于设置 Slot 的数量,可根据实际生产环境设置对应的数量taskManager 内存数用于设置 taskManager 内存数,可根据实际生产环境设置对应的内存数taskManager 数量用于设置 taskManager 的数量,可根据实际生产环境设置对应的数量并行度用于设置执行 Flink 任务的并行度Yarn 队列用于设置 Yarn 队列,默认使用 default 队列主程序参数设置 Flink 程序的输入参数,支持自定义参数变量的替换选项参数设置Flink命令的选项参数,例如-D, -C, -yt自定义参数是 Flink 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容
四、任务样例
执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。
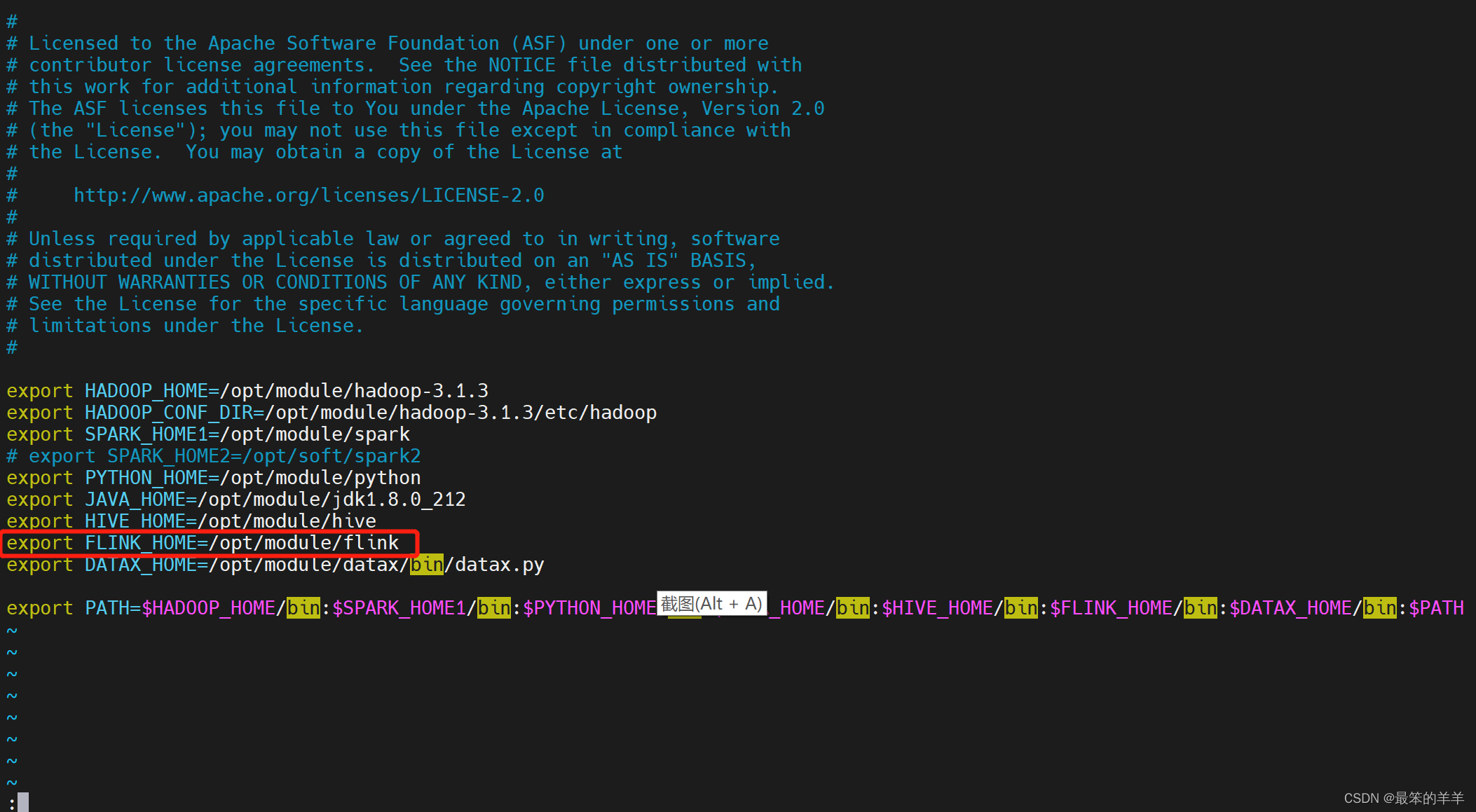
1.在 DolphinScheduler 中配置 flink 环境
若生产环境中要是使用到 flink 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
2.任务流程
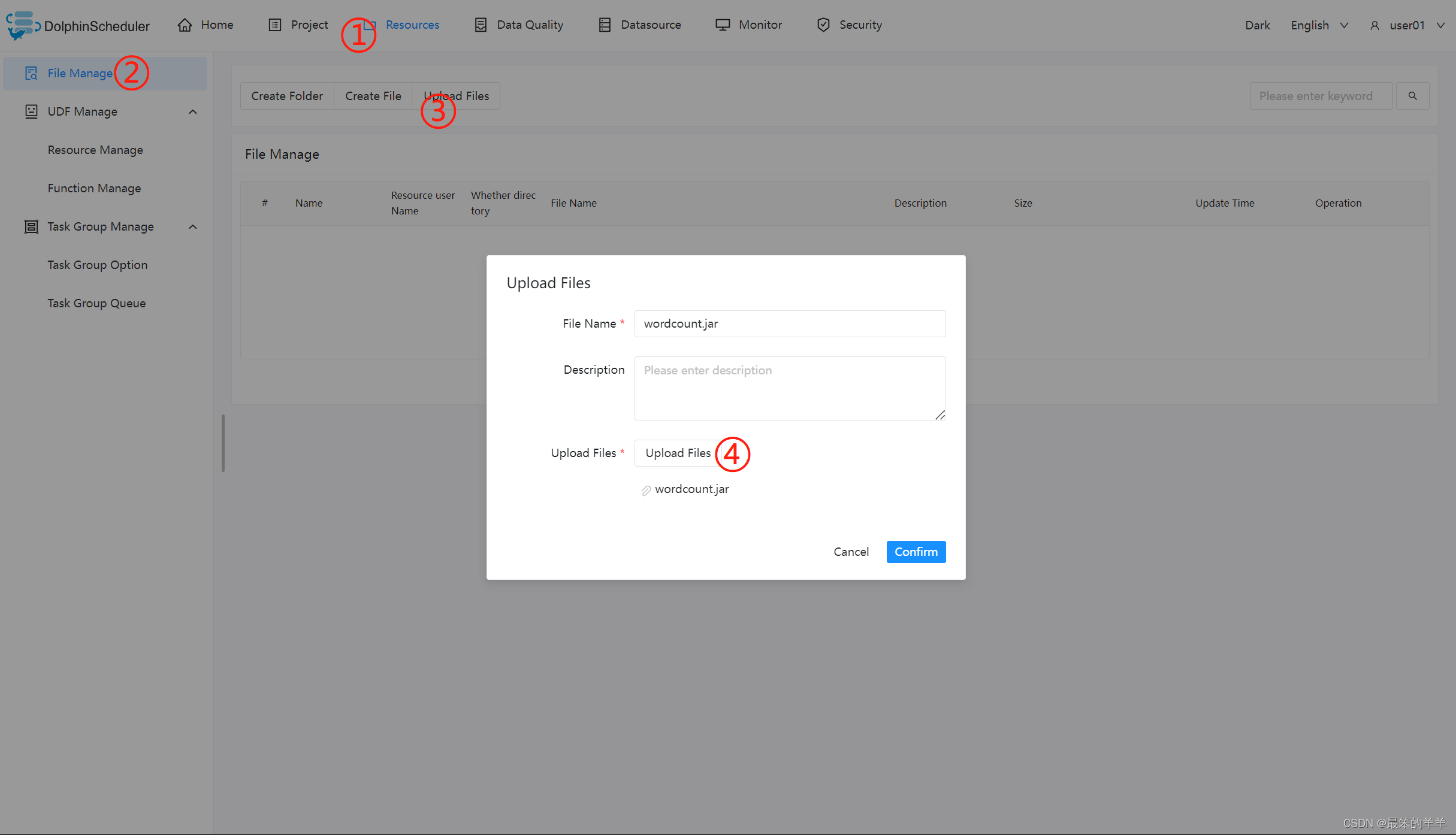
上传主程序包
在使用 Flink 任务节点时,需要利用资源中心上传执行程序的 jar 包。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
配置 Flink 节点
根据上述参数说明,配置所需的内容即可。

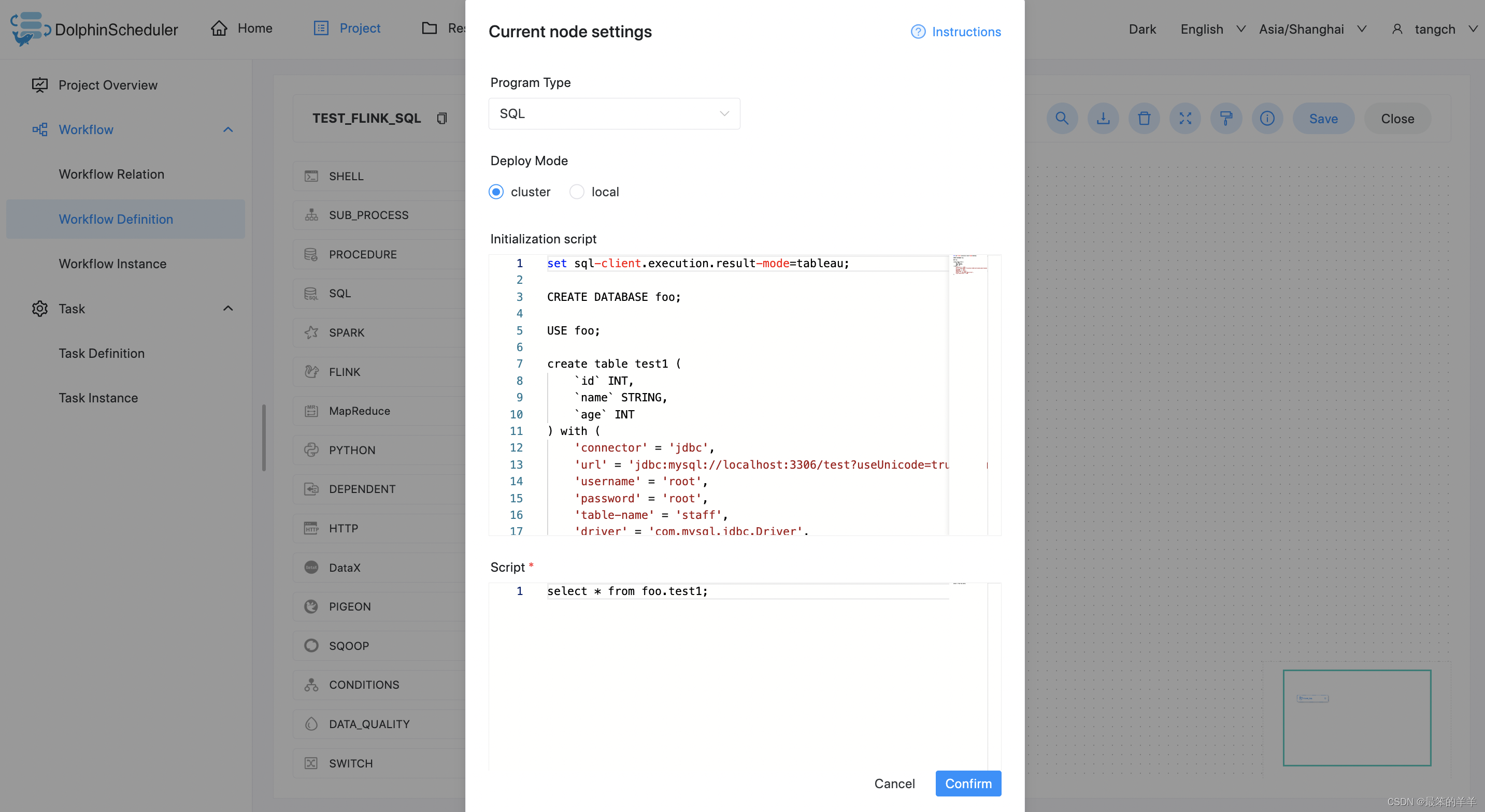
执行 FlinkSQL 程序
根据上述参数说明,配置所需的内容即可。
五、注意事项
- Java 和 Scala 只是用来标识,没有区别,如果是 Python 开发的 Flink 则没有主函数的 class,其余的都一样。
- 使用 SQL 执行 Flink SQL 任务,目前只支持 Flink 1.13及以上版本。
版权归原作者 最笨的羊羊 所有, 如有侵权,请联系我们删除。