


文章目录
Scala应用 —— JDBC的创建
前言
该文章旨在通过Scala语言实现JDBC的创建,以熟悉Scala语言的使用。
一、JDBC的创建过程
1.初始化连接
1.1 配置驱动
在pom.xml中打入以下依赖,向项目中打入MySQL JDBC驱动
<!-- MySQL 驱动 --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.0.33</version></dependency>
该语句用于加载MySQL JDBC驱动。
Class.forName("com.mysql.cj.jdbc.Driver")
1.2 创建连接对象
参数:
url,username,password
2. 初始化执行器
执行器的创建需要依赖连接对象,因此先初始化连接再初始化执行器。
2.1 创建执行器对象
参数:
sql,parameters
2.2 初始化执行器参数
3. 执行操作并返回结果
- DML:影响数据库的表行数
- DQL:List
- Exception:异常
二、Scala JDBC的基本设计思路
JDBC的创建实际上就是包含了两个操作步骤和一个多返回类型设计的小型化任务。
1. 操作步骤设计
def jdbc(url:String,username:String,password:String)(sql:String,params:Seq[Any]=null):Unit{}
- 多操作过程可以写成柯里化的形式,不仅实现了
参数分组,同时还隐含了一种参数间的依赖关系 params不一定会有,并且可能同时包含多种不同的数据类型。因此可以通过可变参数T*或者序列Seq[T]的方式进行表示。同时,默认情况下不传参,因此指定一个默认值为null。- Any*- Seq[Any]
2. 解决结果差异化
结果类型包括:
- DML:影响数据库的表行数
- DQL:List
- Exception:异常
JDBC的结果类型包含了两种正常类型和一种异常类型,自带的
Option
、
Either
或
Try
都无法满足这种需求,我们的解决方式如下:
- 首先定义了一个名为
ResultType的枚举类型,它包含三个值:EX,DQL和DML。 - 定义了一个抽象类
Three,它包含了一个类型为ResultType.Value的构造参数,这个参数用来表示具体的结果类型。此处选择抽象类是因为需要传递一个构造参数,这种设计允许在继承Three的子类中具体化不同类型的结果处理(差异化处理)。 - 三个样例类(Ex,DML,和 DQL)继承自抽象类 Three,每个样例类都对应一个 ResultType 的值,并封装了与其类型相关的数据。
object ResultType extends Enumeration{val EX,DQL,DML = Value
}abstractclass Three(val rst:ResultType.Value)caseclass Ex(throwable: Throwable)extends Three(ResultType.EX){def ex = throwable
}caseclass DML(affectedRows:Int)extends Three(ResultType.DML){def updated = affectedRows
}caseclass DQL(set: ResultSet)extends Three(ResultType.DQL){/**
* 为什么要将(f:ResultSet=>T)独立为一个方法的参数?
* 减少不必要的类型约束,不需要每次创建DQL对象都需要指定泛型。
* */def generate[T](f:ResultSet=>T)(implicit ct:ClassTag[T])={val buffer:ArrayBuffer[T]= ArrayBuffer()// 遍历结果集(包含由一次查询返回的所有行),用f将结果集的每一行转化为一个实体while(set.next()){
buffer.append(f(set))}
buffer.toArray
}}
3.实现jdbc方法并输出结果
- 基类通过
asInstanceOf[T]的方法实现向具体子类的转化 id = rst.getInt(1)这类语句是通过字段序号代替了字段名称
def jdbc(url:String, username:String, password:String)(sql:String, params: Seq[Any]=null): Three ={def conn(): Connection ={// 1.1 装载驱动
Class.forName("com.mysql.cj.jdbc.Driver")// 1.2 创建连接对象val conn: Connection = DriverManager.getConnection(url, username, password)
conn
}def pst(conn: Connection): PreparedStatement ={// 2.1 创建执行对象val pst: PreparedStatement = conn.prepareStatement(sql)// 2.2 设置sql配置为(序号,参数)的格式if(null!= params && params.nonEmpty){
params.zipWithIndex.foreach {// 设置执行对象对应的SQL语句`?`对应的占位符。case(param, index)=> pst.setObject(index +1, param)}}
pst
}try{val connect: Connection = conn
val statement: PreparedStatement = pst(connect)// 过程级增删改查(数据记录):INSERT DELETE UPDATE SELECT// 对象级增删改查(对象——表、视图、索引):CREATE DROP ALTER SHOW
sql match{case sql if sql.matches("SELECT|select")=> DQL(statement.executeQuery())case sql if sql.matches("INSERT|insert|DELETE|delete|UPDATE|update")=> DML(statement.executeUpdate())// 处理SQL语句异常case _ => Ex(new SQLException(s"illegal sql command:$sql"))}}catch{// 其他异常case e: Exception => Ex(e)}}def main(args: Array[String]):Unit={val dql: DQL = jdbc(
url ="jdbc:mysql://single01:3306/test_db_for_bigdata",
username ="root",
password ="123456")(
sql ="SELECT * FROM test_table1_for_hbase_import LIMIT 20").asInstanceOf[DQL]// 将结果集对应的字段设置为样例类,自动生成getter方法caseclass Test(id:Int, name:String, age:Int, gender:String, phone:String)// 将结果集的每一行转化为一个Test对象val tests: Array[Test]= dql.generate[Test](rst => Test(
id = rst.getInt(1),
name = rst.getString(2),
age = rst.getInt(3),
gender = rst.getString(4),
phone = rst.getString(5)))
tests.foreach(println)}
三、代码汇总与结果
1. 代码
packagerecoveryimportjava.sql.{Connection, DriverManager, PreparedStatement, ResultSet, SQLException}importscala.collection.mutable.ArrayBuffer
importscala.reflect.ClassTag
object JDBCTest2 {object ResultType extends Enumeration{val EX,DQL,DML = Value
}abstractclass Three(val rst:ResultType.Value)caseclass Ex(throwable: Throwable)extends Three(ResultType.EX){def ex = throwable
}caseclass DML(affectedRows:Int)extends Three(ResultType.DML){def updated = affectedRows
}caseclass DQL(set: ResultSet)extends Three(ResultType.DQL){/**
* 为什么要将(f:ResultSet=>T)独立为一个方法的参数?
* 减少不必要的类型约束,不需要每次创建DQL对象都需要指定泛型。
* */def generate[T](f:ResultSet=>T)(implicit ct:ClassTag[T])={val buffer:ArrayBuffer[T]= ArrayBuffer()// 遍历结果集(包含由一次查询返回的所有行),用f将结果集的每一行转化为一个实体while(set.next()){
buffer.append(f(set))}
buffer.toArray
}}def jdbc(url:String, username:String, password:String)(sql:String, params: Seq[Any]=null): Three ={def conn(): Connection ={// 1.1 装载驱动
Class.forName("com.mysql.cj.jdbc.Driver")// 1.2 创建连接对象val conn: Connection = DriverManager.getConnection(url, username, password)
conn
}def pst(conn: Connection): PreparedStatement ={val pst: PreparedStatement = conn.prepareStatement(sql)if(null!= params && params.nonEmpty){
params.zipWithIndex.foreach {// 设置执行对象对应的SQL语句`?`对应的占位符。case(param, index)=> pst.setObject(index +1, param)}}
pst
}try{val connect: Connection = conn
val statement: PreparedStatement = pst(connect)// 过程级增删改查(数据记录):INSERT DELETE UPDATE SELECT// 对象级增删改查(对象——表、视图、索引):CREATE DROP ALTER SHOW
sql match{case sql if sql.matches("SELECT|select")=> DQL(statement.executeQuery())case sql if sql.matches("INSERT|insert|DELETE|delete|UPDATE|update")=> DML(statement.executeUpdate())case _ => Ex(new SQLException(s"illegal sql command:$sql"))}}catch{case e: Exception => Ex(e)}}def main(args: Array[String]):Unit={val result = jdbc(
url ="jdbc:mysql://single01:3306/test_db_for_bigdata",
username ="root",
password ="123456")(
sql ="SELECT * FROM test_table1_for_hbase_import LIMIT 20;")
result match{case dql: DQL =>caseclass Test(id:Int, name:String, age:Int, gender:String, phone:String)val tests: Array[Test]= dql.generate[Test](rst => Test(
id = rst.getInt(1),
name = rst.getString(2),
age = rst.getInt(3),
gender = rst.getString(4),
phone = rst.getString(5)))
tests.foreach(println)case ex: Ex =>
println("Error occurred: "+ ex.ex.getMessage)}}
2.打开虚拟机服务
start-all.sh # 1.打开Hadoop
zkServer.sh start # 2.打开ZooKeeper
start-hbase.sh # 3.打开HBase
mysql -u root -pPASSWORD# 4.打开 mysql
mysql中的表结构为
--- test_db_for_bigdata
--- test_table1_for_hbase_import
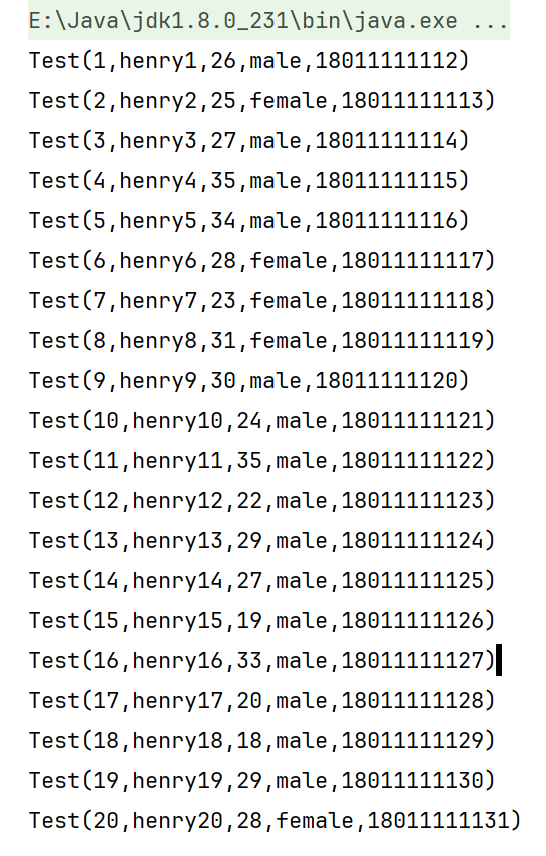
3.结果

本文转载自: https://blog.csdn.net/m0_74120525/article/details/138389803
版权归原作者 Byyyi耀 所有, 如有侵权,请联系我们删除。
版权归原作者 Byyyi耀 所有, 如有侵权,请联系我们删除。