

本文介绍了数据工作中数据基础和复杂数据查询两个基础技能。

背景
当下,不管是业务升级迭代项目,还是体验优化项目,对于数据的需求都越来越大。数据需求主要集中在以下几个方面:
- 项目数据看板搭建:特别是一些AB实验的看板,能直观呈现项目的核心数据变化
- 数据分析:项目启动前的探索挖掘以及项目后的效果分析但是,眼下存在的一个普遍矛盾是:日益增长的数据需求和落后的数据生产力之前的矛盾
俗话说,求人不如求己,掌握基础的数据技能对于技术同学(尤其是开发岗位的同学)并不是一件难事,只是缺少一个合适的入门指南。本文旨在让想学习数据处理的同学能快速入门。

基础技能
▐** 数据基础**
这一部分先介绍MaxCompute(原odps)平台进行数据处理开发的基础知识。
表基础
表(table)是数据处理的起点和终点,因此能看懂别人的表,会创建自己的表是数据处理技能中最最基础的一环。
表的创建和修改
创建临时表:
-- 临时表命名建议以“tmp_”开头,odps会知道该表是临时表
-- 临时表的生命周期建议按需设置,不要设置太长,避免资源浪费
CREATE TABLE tmp_ut_cart_clk LIFECYCLE 7 AS
SELECT user_id
FROM <用户浏览数据表>
创建正式表:
-- analytics_dw是odps的空间名,后面的是表名
-- 空间名.表名 才能确定唯一的数据表
-- 以下是一个实际案例
CREATE TABLE IF NOT EXISTS analytics_dw.ads_tb_biz_request_opt_1d
(
bucket_id STRING COMMENT '分桶'
,os STRING COMMENT '系统'
,uv BIGINT COMMENT '分桶用户数'
,pv BIGINT COMMENT '页面访问pv'
,page_stay_time BIGINT COMMRNT '页面停留时间(ms)'
...
)
PARTITIONED BY -- 分区
(
ds STRING COMMENT '日期'
)
LIFECYCLE 30
;
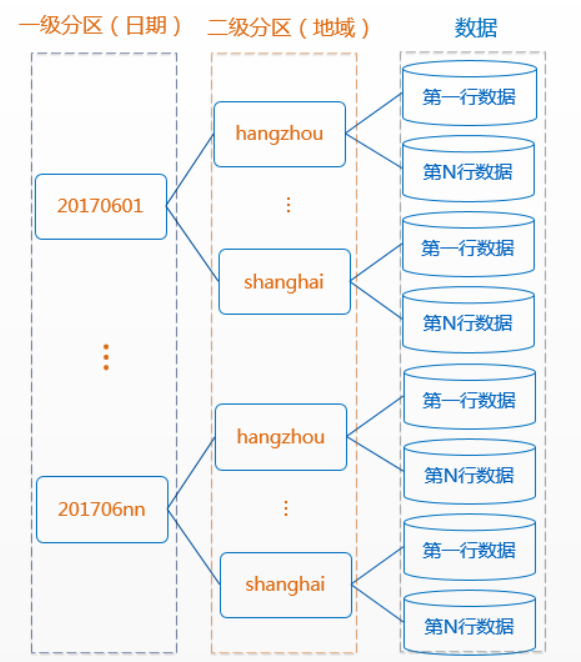
注意 PARTITIONED BY 这是指定分区字段。分区在odps的数据处理中很重要,合理的选择分区会让数据查询速度快非常多。
简单理解 分区 就是文件目录的概念,目录信息越精确,需要查询的原始数据就越少,查询效率自然越高。
表的命名
如果我们计划要做一张需要定期更新并供他人使用的表,那么表的命名必须要符合一定规范。简单提炼下,我们日常数据处理经常遇到的表大概有4种:
类型
命名前缀
说明
维表
dim_xxxx
提供一些维度信息,一般是让其他表关联来补足部分信息
明细表
dwd_xxxx
经过清洗,过滤,字段处理过的表。仅仅是对客观行为的描述。是数据处理分析的基础
轻度汇总表
dws_xxxx
为了方面后续的数据分析,对部分维度进行聚合计算。讲大白话就是对dwd的部分维度进行group by聚合,轻度聚合表会丢失部分不那么重要的信息,能为后续的分析提供便利
应用层表
ads_xxxx
为上层应用提供数据的表。到了这一层,表中的数据基本不具备继续加工处理的能力。这些表中的数据一般都是用来配置报表,或者用来辅助决策的制定
对于开发同学来说,在需要我们自己创建表的情况下一般都是ads类型的表,表的命名可以按照下面的格式:
<空间名>.ads_<业务><二级业务/如有><功能/实验><数据统计周期/1d/7d/30d等等>
基础查询
基础查询是数据处理的基础,这一步的主要工作包括数据的清洗和过滤,字段的加工拓展,为后续的数据处理打好坚实基础
下面是一个非常非常基础的查询sql:
SET odps.sql.mapper.split.size=2048; -- 默认是256(单位M)
SELECT user_id
,page
,time_stamp
...
FROM <App用户使用明细表>
WHERE ds = '${bizdate}'
AND product = '<App名称>'
AND event_type = '<事件类型:浏览\点击>'
AND page = '<页面标识>'
;
如果查询的数据量巨大,那么查询时可能会遇到下面这个错误:
FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: java.lang.RuntimeException: com.aliyun.odps.lot.cbo.plan.splitting.disruptor.InstExceedLimitException: task:M1 instance count exceeds limit 99999
这是因为odps是根据 数据存储大小/splitSize 来确定需要的实例数,但有个99999的上限,超限了就会报错。这时适当将splitSize调大一点即可(可以每次*2的幅度来调整)
字符串处理
查询过程中常见的字符串处理方法:
-- 单个条件
SELECT IF(page = 'Page_XXX', 'y', 'n') AS is_page_xxx
-- 多个条件
,CASE WHEN hh <= 12 THEN '上午'
WHEN hh > 12 AND hh <= 18 THEN '下午'
ELSE '晚上'
END AS 时间段
-- 超级有用:提取args中的kv
,KEYVALUE(args, ',', '=', 'itemid') AS item_id
-- 分割字符串(value为“a_b_c”这种有规律的字符串可以使用)
,SPLIT(value, '_') AS value_list -- 这个是数组,可以使用索引 value_list[0]
-- 去除空值(使用a,b,c中第一个不为NULL的值,否则用最后的空字符串)
,COALESCE(a, b, c, '') AS xxx
-- 版本比较,超级实用
,IF(bi_udf:bi_yt_compare_version(app_version, '10.24.10') >= 0, 'y', 'n') AS is_target_version
-- 解析JSON,提取目标信息
,GET_JSON_OBJECT(json_str, '$.section.item.name') AS item_name
-- 类型转换
,CAST(user_id AS BIGINT) AS user_id
-- 大小写转换
,TOUPPER(os) , TOLOWER(os)
日期处理
字符串处理中有关于日期时间的处理也比较常见,比如“查询最近7天的数据”,关于日期的常用函数如下:
-- 日期格式描述
yyyy 年,4位
MM 月,2位
dd 日,2位
hh/HH 12小时制/24小时制,2位
mi 分钟,2位
ss 秒,2位
SSS 毫秒,3位
-- 通过上面这些格式就能在转化具体的日期时描述日期的格式:
20230807 yyyyMMdd
2023-08-07 yyyy-MM-dd
20230806 13:22:00 yyyyMMdd HH:mi:si
-- 单纯查询某个日期之前或者之后的数据
ds >= '20230807'
TO_DATE('20230807', 'yyyyMMdd') -- 将日期字符串转为 datetime 实例,日期处理的基础
TO_CHAR(datetime, 'yyyyMMdd') -- 将日期函数处理得到各种datetime转换为字符串
FROM_UNIXTIME(123456789) -- 将unix时间戳转换成datetime对象
-- 日期加减,自动处理进位关系
DATEADD(TO_DATE('20230807', 'yyyyMMdd'), 7, 'dd') -- 20230814
DATEADD(TO_DATE('20230807', 'yyyyMMdd'), -7, 'dd') -- 20230731
-- 2个日期间隔(第一个日期-第二个日期,结果可为负)
DATEDIFF(TO_DATE('20230807', 'yyyyMMdd'), TO_DATE('20230806', 'yyyyMMdd'), 'dd') -- 1
-- 提取指定时间
-- 在希望分小时段统计的场景下很实用
DATEPART(TO_DATE('2023-08-07 12:13:22', 'yyyy-MM-dd hh:mi:ss'), 'hh') -- 12
关联查询
很多时候单一表的数据无法满足我们的需求,需要通过其他表来补充一些信息,这时就需要关联数据。在sql上表现为有Join操作。
常用的关联操作有 LEFT JOIN、RIGHT JOIN、INNER JOIN
-- 基本的join语法如下
SELECT a.user_id
,a.arg1
,a.args
,b.bucket_id
FROM (
SELECT user_id
,arg1
,args
FROM <用户手淘行为表>
) a
LEFT JOIN (
SELECT user_d
,bucket_id
FROM <AB实验分流表>
) b
ON a.user_id = b.user_id
;
-- left join、right join、inner join差别
left join:会保留左表的所有数据(在上面这个例子中左表就是 a,join左边的表),右表中没有匹配的数据将会丢失
right join:和left join相反会保留右表(b)的所有数据,左表中没有匹配的数据会丢失
inner join:最终只有两个表的交集部分会被保留下来
Join操作很容易出错,导致查询结果出错,而且这种错误有时非常隐蔽难以发现。主要原因就是匹配条件遗漏或者关联字段有重复值,出现多对多的情况,导致数据膨胀,进而影响了统计结果。为了避免出现问题,有几个建议:
- a、b表关联前先进行必要的数据清洗和去重,而不是先关联后处理
- 如果a、b表都是数据量很大的表,建议先随机抽取小样本数据生成临时表a'、b',然后对比最终表数据量和a'、b'的数据量大小是否符合预期
特别地,在小表关联大表的情况下,可以使用MapJoin提升效率,比如在一个每日成交表中有商品的类目信息,现在需要关联到对应的行业信息,而类目和行业的映射关系是一个很小的表,这种情况下就可以使用MapJoin提升任务的执行效率。
SELECT /* + mapjoin(J2) */
J1.*
,J2.industry
FROM <订单表> J1
LEFT JOIN
(
SELECT cate_level1_id
,industry
FROM <行业维表>
WHERE ds = '${bizdate}'
) J2
ON J1.cate_level1_id = J2.cate_level1_id
;
聚合查询
聚合就是针对数据中的某些维度(系统、版本等)执行一系列计算返回单一值。一般在sql上体现为有Group By操作。一般我们数据处理(指标计算)的最后几步都离不开聚合操作。
-- 常见聚合函数
AVG(age) AS avg_age ) -- 平均值
SUM(cnt) AS total_cnt -- 求和
MIN(age) AS min_age -- 最小值
MAX(age) AS max_age -- 最大值
COUNT(*) / COUNT(item_id) -- 计数 count(*)不会忽略null,count(xx)会忽略null
COUNT(DISTINCT utdid) -- 去重计数
COLLECT_SET(item_id) -- 将去重后的item_id存在一个数组中
COLLECT_ARRAY(item_id) -- 将item_id存在一个数组中(不去重)
PERCENTILE(duration, 0.95) -- 求分位数
通常,我们在执行聚合时可能会有一些特殊的需求,比如我们想查询每日成交中每个省份的GMV同时还想查询所有省份的整体GMV。正常可能需要这么写:
SELECT province
,SUM(amount) AS gmv
FROM <每日成交表>
GROUP BY province
UNION ALL
SELECT '整体' AS province
,SUM(amount) AS gmv
FROM <每日成交表>
维度少的时候这么写没问题,但考虑下这个需求,我们想看每个省下面的每个城市的gmv,同时也想看这个省整体的gmv,同时也想看所有省份的gmv,这时再用上面的写法就会很繁琐。这时可以考虑使用CUBE或者GROUPING SETS来简化查询逻辑:
SELECT IF(GROUPING(province) == 0, province, 'all') AS province
,IF(GROUPING(city) == 0, city, 'all') AS city
,SUM(amount) AS gmv
FROM <每日成交表>
GROUP BY GROUPING SETS((), (province), (province, city))
-- 下面是CUBE的示例
SELECT IF(GROUPING(province) == 0, province, 'all') AS province
,IF(GROUPING(city) == 0, city, 'all') AS city
,SUM(amount) AS gmv
FROM <每日成交表>
GROUP BY CUBE(province, city)
-- 说明:
-- GROUPING SETS:按照制定维度组合来做聚合
-- CUBE:按照相关维度的全排列来做聚合
最后再强调一句:数据查询时 一定要指定分区 一定要指定分区 一定要指定分区
▐** **复杂数据查询
很多同学其实是具备sql的基本知识的,但是一旦数据查询稍微变复杂一点,就有点束手无策。这个很正常,因为复杂sql的可读性、可维护性本来就很。和开发思路类似解决这个问题的方法就是将复杂的逻辑的拆解为简单的过程,减少查询的套娃。个人推荐的方法主要有:临时表、odps script、cte表达式三种方式。
临时表(临时查询使用)
将复杂过程的查询过程拆解,每个过程的查询结果保存为一张临时表,直至最终完成整个查询逻辑。这个方法在做数据分析时特别好用。
一般我们都是以天为单位来分析数据,可以按照下面的模板来做:
-- 步骤1 甚至可以写注释方面以后理解
-- 建议将关心的原始数据先清洗处理保存为临时表,方便后面做各种分析使用,提升效率
DROP TABLE IF EXISTS tmp_step1_${bizdate};
CREATE TABLE tmp_step1_${bizdate} LIFECYCLE 3 AS -- 临时表生命周期不要设置太久,避免无意义的资源浪费
SELECT a
,b
,c
FROM <数据表1>
WHERE <筛选条件>
;
-- 步骤2
DROP TABLE IF EXISTS tmp_step2_${bizdate};
CREATE TABLE tmp_step2_${bizdate} LIFECYCLE 3 AS
SELECT a
,b
,c
FROM tmp_step1_${bizdate}
;
-- ....
-- 关注的结果
SELECT *
FROM tmp_stepN_${bizdate}
GROUP BY xxx
;
说明:
- 临时表查询最好能写成无脑一键执行就能获得最终结果,这能节省大量的时间
- ${xxx} odps的参数写法,可以在执行sql前制定对应参数的值,然后替换掉整个sql中的对应参数,本质是字符串替换,一个sql中可以出现多个参数
- 为了让sql能反复执行,建表前需要确保相应的表没有被创建过(DROP TABLE)
ODPS SCRIPT(有局限性,不推荐)
有cte表达式后,不推荐该方法。简单示例如下:
@step1 :=
SELECT XX
FROM XXXX;
@step2 :=
SELECT YY
FROM @step1;
....
SELECT *
FROM @stepN;
CTE表达式(强力推荐,用过都说好)
CTE能让我们将复杂任务拆解,提升SQL的可读性、可维护性。此外CTE不仅可以用于临时查询,也能将任务发布为周期任务。日常的数据处理可以使用下面的模板:
WITH
step1 AS
(
SELECT XX
FROM XXXX
),
step2 AS
(
SELECT YY
FROM step1
),
....
stepN AS
(
SELECT ...
) -- 最后的这括号后面不要加 ,
INSERT OVERWRITE TABLE <存储表名> PARTITION (ds = '${bizdate}') -- 一个WITH只支持一个INSERT
SELECT *
FROM stepN

写在最后
数据处理并不是神秘、难以掌握的技能。每个技术同学、产品同学都是可以学会基本的数据处理技能的。希望本文能帮助有需要的同学叩开数据处理的大门。

团队介绍
我们是大淘宝技术「基础交易终端团队」,主要负责电商核心交易链路业务和平台的研发,包含:淘宝购物车、下单、订单、物流、逆向等电商核心基础能力及创新型业务。这里有世界一流的技术产品,有丰富的业务场景,服务于十亿级的消费者,这里有巨大的挑战等你来。作为阿里的一支明星团队,负责阿里电商平台的核心交易主链路,是阿里移动技术的基石,每年双十一核心链路保障。
现招聘移动端(Android/iOS)开发工程师,有前端开发经验者优先,有意者可以投递简历到:guzhan.pc@taobao.com
¤** 拓展阅读 **¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
版权归原作者 阿里巴巴淘系技术团队官网博客 所有, 如有侵权,请联系我们删除。