
文章目录
一、目的与要求
- 掌握SQL语言的查询功能;
- 掌握SQL语言的数据操作功能;
- 握对象资源管理器建立查询、索引和视图的方法;
二、实验准备
- 了解SQL语言的查改增删四大操作的语法;
- 了解查询、索引和视图的概念;
- 了解各类常用函数的含义。
三、实验内容
使用提供的studentdb数据库文件,先附加到目录树中,再完成下列题目,SQL命令请保存到脚本文件中。
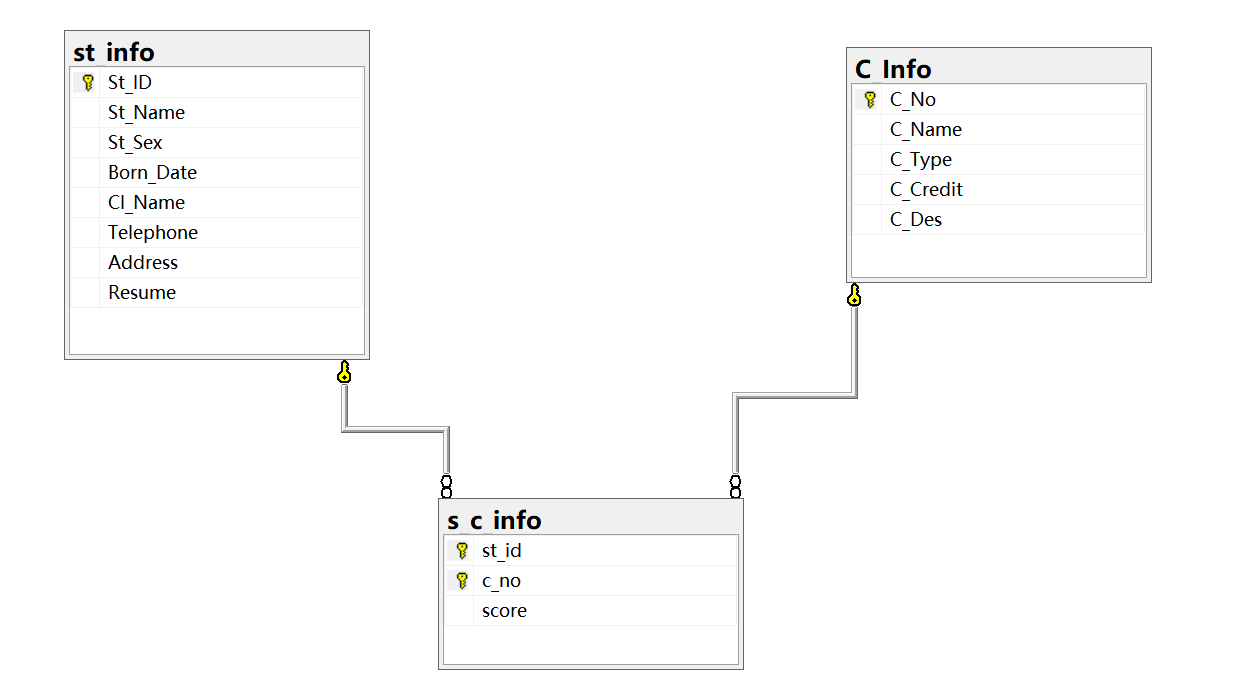
(一)SQL查询功能
1.基本查询
1️⃣ 查询所有姓王的学生的姓名、学号和性别
select St_Name,St_ID,St_Sex
from st_info
where St_Name like'王%';
2️⃣ 查询全体学生的情况,查询结构按班级降序排列,同一班级再按学号升序,并将结果存入新表new中
select St_ID,St_Name,St_Sex,Born_Date,Cl_Name,Telephone,Address,Resume
into new_table
from st_info
orderby Cl_Name desc,St_ID asc;
提醒:
在表查询中,建议明确字段,不要使用 * 作为查询的字段列表,推荐使用SELECT <字段列表> 查询。原因:
- MySQL 在解析的过程中,会通过
查询数据字典将 * 按序转换成所有列名,这会大大的耗费资源和时间。- 无法使用
覆盖索引
3️⃣ 对s_c_info表中选修了“体育”课的学生的平均成绩
🌿 法一:子查询
selectavg(score)from s_c_info
where c_no =(select C_No
from C_Info
where C_Name='体育');
🌿 法二:连接查询(多表查询)
selectavg(score)from s_c_info join C_info
on s_c_info.c_no = C_info.C_No
where C_info.C_Name ='体育';
看一段代码:
selectavg(score)from s_c_info,C_info where s_c_info.c_no = C_info.C_No and C_info.C_Name ='体育';这段代码与法二本质是一样的。
- 法二写的是SQL99的规范,使用
表1 join 表2 on ...来代替表1,表2 where ...。- 这段代码写的是SQL92的规范,即
表1,表2 where ...。
2.嵌套查询
嵌套查询指的是一个查询语块可以嵌套在另外一个查询语句块的where子句或者having子句中,前者为子查询或内查询,后者为父查询或外查询。
1️⃣ 查询其他班级中比“材料科学0601班”的学生年龄都大的学生姓名和年龄
📍 我们可以先查询到“材料科学0601班”中年龄最大(即出生最早)的同学的出生日期
selectmin(Born_Date)from st_info
where Cl_Name='材料科学0601班';
📍 再用这个出生日期去与其他同学比较
select St_Name as name,DATEDIFF(DAY,Born_Date,GETDATE())/365as age
from st_info
where Born_Date <(selectmin(Born_Date)from st_info
where Cl_Name='材料科学0601班');
2️⃣ 用exists查询选修了“9710041”课程的学生姓名
select St_Name
from st_info
whereexists(select1from s_c_info
where c_no=9710041and s_c_info.st_id = st_info.St_ID);#相关子查询
3️⃣ 用in查询找出没有选修“9710041”课程的学生的姓名和所在班级。
📍 我们先从
s_c_info表
查询出选修了该课程的学生的 st_id
select st_id
from s_c_info
where c_no=9710041;
📍 再拿这上面的这个筛选出来st_id的
临时表
,去与
st_info表
的每一条记录比较,如果st_info表的某条记录的st_id在临时表中查不到,则显示该记录的学生信息
select St_Name,Cl_Name
from st_info
where St_ID notin(select st_id
from s_c_info
where c_no=9710041);
4️⃣ 查询 选修了 学号为“2001050105”的学生 所选全部课程 的学生姓名。
📍 我们先查询学号为"2001050105"的
学生A
的全部所选课程的课程号,查询结果设置为临时表
t
select c_no
from s_c_info
where st_id='2001050105'
📍 再用
s_c_info表
,取别名为
s表
,与
t表
进行连接查询(多表查询),连接条件为
s.c_no = t.c_no
,目的是查询到所有与学生A选修了一个或多个相同课程的学生选修课程信息。
select sc.st_id
from s_c_info sc,(select c_no
from s_c_info
where st_id='2001050105') t
where sc.c_no = t.c_no
📍 这时候的
sc.st_id
就可能存在重复出现,因为可能有学生与学生A选修了超过一门的相同课程,这是应该如此的,我们不应该使用
distinct
去重。现在就可以仔细想想:
- 如果sc.st_id出现了
1次,说明该st_id代表的学生的选修了的课程,与学生A选修了的课程是有1门相同的 - 如果sc.st_id出现了
2次,说明该st_id代表的学生的选修了的课程,与学生A选修了的课程是有2门相同的 - 如果sc.st_id出现了
3次,说明该st_id代表的学生的选修了的课程,与学生A选修了的课程是有3门相同的
所以如此看来,如果sc.st_id出现的次数与学生A选修的课程数目相同,即可说明该st_id代表的学生与学生A所选修的课程完全相同。
那如何计算次数呢?
- sc.st_id我们分组查询即可,即将
group by sc.st_id进行分组 - 学生A选修的课程数目,我们使用直接以
st_id = '2001050105'为过滤条件查询s_c_info表课程数目即可
如果满足次数相同(在
having
中完成等值比较),就显示出sc.st_id
select sc.st_id
from s_c_info sc,(select c_no
from s_c_info
where st_id='2001050105') t
where sc.c_no = t.c_no
groupby sc.st_id
havingcount(*)=(selectCOUNT(*)from s_c_info
where st_id='2001050105')
📍 上述查询构建的临时表
x
,即为满足条件的学生st_id,我们就只需要遍历st_info表中每一条记录,满足St_ID在临时表
x
中有等值的
st_id
,我们就显示这个同学的名字。
select St_Name
from st_info
where St_ID in(select sc.st_id
from s_c_info sc,(select c_no
from s_c_info
where st_id='2001050105') t
where sc.c_no = t.c_no
groupby sc.st_id
havingcount(*)=(selectCOUNT(*)from s_c_info
where st_id='2001050105'));
3.连接综合查询及其他
操作前的几点提醒:
- 我们要 控制连接表的数量 。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。阿里的规范手册就强制规范了Join最多不要超过三层,那我们怎么解决这个问题呢?我们可以将原来复杂的多表查询的SQL语句拆分,分成多个小的SQL实现功能。
- 如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
- 一旦涉及到多表查询,如果使用到表的字段,在where、on、having、select等其他无论什么地方,我们必须明确该字段来自哪个表,即
表名.字段名的形式。📝 举个反例:在某业务中,由于多表关联查询语句没有加表的别名(或表名)的限制,正常运行两年后,最近在 某个表中增加一个同名字段,在预发布环境做数据库变更后,线上查询语句出现出1052 异常:Column ‘name’ in field list is ambiguous。提示也很明确,DBMS告诉我们这个name字段摸棱两可,不知道哪个表,这时候就真的蛋糕了,因此你可以看出如果不加表名,是很不利于我们后期的维护的。根据墨菲定律,是极有可能发生的🥀 。
1️⃣ 查询每个学生所选课程的最高成绩,要求列出学号,姓名,课程编号和分数。
📍 我们先查询到每位学生的最高成绩,对这个临时表取个别名
b
select st_id,max(score) score
from s_c_info
groupby st_id
📍 接下来我们就进行多表连接查询,这里采用SQL99的
表1 join 表2 on...
语法,当然也可以使用SQL92的
表1,表2 where ...
语法代替。
首先将
s_c_info表
取别名为
a
,将 表a 与 表b 连接,连接条件是
a.st_id = b.st_id and b.score = a.score
,这样我们就得到了每位学生最高分数对应的学号。那之后就很简单了,在进行一次与st_info表(取别名为
st
)的连接,通过
a.St_ID=st.st_id
即可匹配到对应的学生信息。
select st.St_ID,st.St_Name,a.c_no,b.score
from s_c_info a
join(select st_id,max(score) score
from s_c_info
groupby st_id) b
on a.st_id = b.st_id and b.score = a.score
join st_info st
on a.St_ID=st.st_id;
2️⃣ 查询所有学生的总成绩,要求列出学号、姓名、总成绩,没有选修课程的学生总成绩为空。
📍 我们先查询出s_c_info表中记录的每名学生的总成绩,通过st_id进行分组依据。给查询到的结果设为临时表
sc
select st_id,sum(score) score
from s_c_info
groupby st_id
由于题目给出没有选修课程的学生总成绩为空,因此我们进行外连接。
select st.St_ID,st.St_Name,sc.score
from st_info st leftjoin(select st_id,sum(score) score
from s_c_info
groupby st_id) sc
on st.St_ID = sc.st_id;
3️⃣ 查询“大学计算机基础”课程考试成绩前三名的学生姓名和成绩。
📍 我们先得到"大学计算机基础"的课程号
select C_No
from C_Info
where C_Name='大学计算机基础'
📍 我们也可以将
s_c_info
与
st_info
进行连接查询,得到 s_c_info 表中每行记录学号对应的学生姓名
select st_info.St_Name,s_c_info.score
from s_c_info join st_info
on s_c_info.st_id = st_info.St_ID
📍 紧接着利用 第一步的查询结果 筛选出
s_c_info
表中
c_no
等于 大学计算机基础的课程号 的记录
select st_info.St_Name,s_c_info.score
from s_c_info join st_info
on s_c_info.st_id = st_info.St_ID
and s_c_info.c_no =(select C_No
from C_Info
where C_Name='大学计算机基础')
📍 我们对查询到的结果进行依照
score
进行降序排列,目的是为了接下来得到前三名成绩
select st_info.St_Name,s_c_info.score
from s_c_info join st_info
on s_c_info.st_id = st_info.St_ID
and s_c_info.c_no =(select C_No
from C_Info
where C_Name='大学计算机基础')orderby s_c_info.score desc;
📍 最后一步,因为只需要前三名的成绩,而进行降序排列后,最高的三个人的成绩肯定是前三条记录,我们取前三条记录即可,在
select
后面加上
top 3
selecttop3
st_info.St_Name,s_c_info.score
from s_c_info join st_info
on s_c_info.st_id = st_info.St_ID
and s_c_info.c_no =(select C_No
from C_Info
where C_Name='大学计算机基础')orderby s_c_info.score desc;
4️⃣ 将s_c_info中的score列的值转为等级制输出,即60分以下显示为“不及格”,6069分显示“及格”,7079分显示“中等”,8081显示“良好”,90100显示“优秀”。要求输出学号、姓名、课程名、成绩等级。(提示:在select字句中使用case…when…end语句)
case when的两种用法:
- case用于实现简单的 等于 判断,相当于 switch … case … default。
case 字段名when ‘字段值’ then ‘需要返回的值’when ‘字段值’ then ‘需要返回的值’else ‘剩余所有的需要返回的值’end - case还可用于 有条件 的逻辑判断,相当于 if … else if … else。
casewhen 字段名 = ‘字段值’ then ‘需要返回的值’else ‘剩余所有的需要返回的值’end
本题我们就采用第二种用法,同时在
end
后面加上了
score_grade
相当于给 case when 的 结果取的字段名为 score_grade。
select st_info.St_ID,st_info.St_Name,C_Info.C_Name,casewhen s_c_info.score >=90then'优秀'when s_c_info.score >=80then'良好'when s_c_info.score >=70then'中等'when s_c_info.score >=60then'及格'else'不及格'end score_grade
from st_info,s_c_info,C_Info
where st_info.St_ID=s_c_info.st_id
and C_Info.C_No = s_c_info.c_no;
这里我们使用的SQL92语法:
表1,表2 where...
(二)SQL的增删改功能
创建数据库studb,存储属性为默认,在studb数据库中建立数据表。结构如图所示:
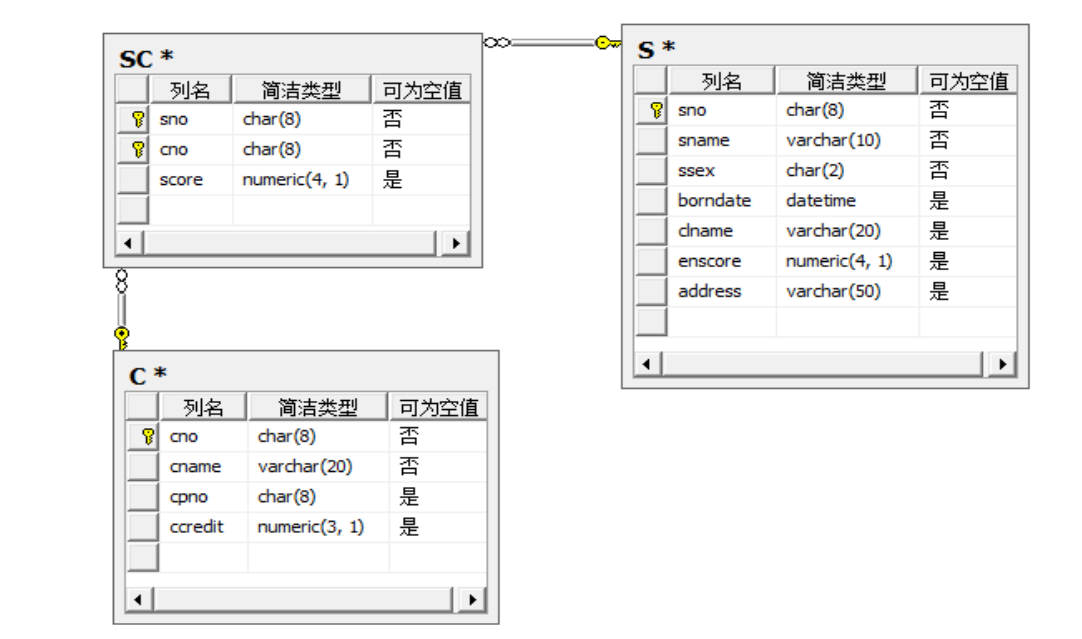
- 创建数据库
#我们先删除数据库,防止由于已经存在 studb 数据库导致我们创建失败dropdatabase studb;#创建数据库createdatabase studb; - 使用数据库
use studb; - 依次创建表
#创建学生表createtable S( sno char(8)primarykeynotnull, sname varchar(10)notnull, ssex char(2)notnull, borndate datetime, clname varchar(20), enscore numeric(4,1), address varchar(50));#创建课程表createtable C( cno char(8)primarykeynotnull, cname varchar(20)notnull, cpno char(8), ccredit numeric(3,1));#创建学生课程表createtable SC( sno char(8)notnull, cno char(8)notnull, score numeric(4,1),primarykey(sno,cno),foreignkey(sno)references S(sno),foreignkey(cno)references C(cno));> 其实在创建表的过程中,我们可以明白一个事情,>> 学生表>> 与>> 课程表>> 之间的关系是多对多。针对这种情况需要设计一个独立的表来表示,这种表一般称为>> 中间表>> ,也就是我们这里创建的>> 学生课程表>> 。
在以上建立的studb数据库中,写SQL语句实现增删改功能。
1️⃣ 在S表中增加如下记录

insertinto S(sno,sname,ssex,bomdate,clname,enscore,address)values('S3','张明华','男','1995-08-21 00:00:00.000','MA_数学',530.0,'浙江杭州');
【建议】程序端insert语句指定具体字段名称,不要写成 INSERT INTO t1 VALUES(…)
建议的写法:INSERT INTO t1(字段1,字段2,…) values(值1,值2,…)
2️⃣ 在C表中将课程名为“数据库”的学分更改为3
update C set ccredit =3where cname ='数据库';
2️⃣ 删除S表中S2的学生记录,请问是否能删除,为什么,要如何操作。
✏️ 不能删除,外键依赖于主键而存在,必须要删除所有的相关外键约束,即删除SC表中的sno为S2的所有记录才能删除S表的学生记录。
- 第一步:delete from SC where sno = ‘S2’;
- 第二部:delete from S where sno = ‘S2’;
外键约束是有成本的,需要消耗系统资源。对于大并发的 SQL 操作,有可能会不适合。比如大型网站的中央数据库,可能会
因为外键约束的系统开销而变得非常慢。所以, MySQL 允许你不使用系统自带的外键约束,在
应用层面完成检查数据一致性的逻辑。也就是说,即使你不用外键约束,也要想办法通过应用层面的附加逻辑,来实现外键约束的功能,确保数据的一致性。
关于外键约束,阿里规范手册就强制要求不得使用外键与级联,一切外键概念必须从应用层次上解决。
(三)索引
在studb数据库中,分别用对象资源管理器和SQL语言定义索引
索引默认是支持的升序排列。
1️⃣ 在对象资源管理器中,在T表的tname列上中建立聚集索引ix_tname,降序。查看聚集的效果。
CREATECLUSTEREDINDEX ix_tname ON T(tname desc);
2️⃣ 使用SQL语言定义TC表的(tno,cno)列上的复合索引ix_tc,tno列设为升序,cno列设为降序
CREATECLUSTEREDINDEX ix_tc on TC(tno asc,cno desc);
(四)视图
💬 在studb数据库中操作。
1️⃣ 在对象资源管理中建立视图v_s_c,列出所有学生所选课程的成绩:学号,姓名,班级名,课程号,课程名,成绩。
createview v_s_c(sno,sname,clname,cno,cname,score)asselect S.sno,S.sname,S.clname,C.cno,C.cname,SC.score
from SC,S,C
where SC.sno = S.sno
and SC.cno = C.cno;
2️⃣ 使用SQL语言建立视图v_cjtj,列出每位同学的学号,最高成绩,最低成绩,平均成绩和总成绩,按总成绩降序排列。
这里有个非常值得注意的问题,可能对于这个题你会这样写SQL:
createview v_cjtj(sno,max_score,min_score,avg_score,sum_score)asselect sno,max(score),min(score),avg(score),sum(score)from SC
groupby sno
orderbysum(score)desc;
❗️ 这时候就会报错:除非另外还指定了 TOP、OFFSET 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效。
我们再具体解释一下:ORDER BY子句的查询不能用作表的表达式,其中表的表达式包括:视图、内联表值函数、子查询、派生表和共用表达式。select+order by在视图、子查询中的返回值不是表,而且是游标,所以会报错。
那怎样解决这个问题呢?从报错提示中我们其实看出,我们可以使用
TOP
关键字:
- 指定具体数目我们可以用具体的数字里进行限量获取,这个和
mysql的limit关键字有点像。只不过区别是top放在select后面,而limit放在整个sql语句最后。我们举个例子实操一下,比如现在要查询学生表前10条学生记录的学号和姓名:selecttop10 st_id,st_namefrom student; - 指定具体百分比如果我们的sql需要获取全部数据来做过滤,又不知道具体的数目,这个时候就可以用百分比来进行获取,其表达形式为
top N percent,N为百分比数目,百分比值必须介于 0 到 100 之间,不然会报错。我们也举一个例子实操一下,比如现在要查询学生表前一半人的信息,但又不知道这一半人到底是多少人,无法使用top的第一个用法,怎么办呢?就可以使用我们top的第二个作用——百分比的方式解决这个问题:selecttop50percent st_id,st_namefrom student;
我们刚才遇到的SQL报错问题,提到了单独使用order by返回的是游标而不是表,怎么解决呢?就需要使用top的第二个用法,指定
N
为100,即显示百分百全部数据,返回满足条件的所有记录,经过修正之后,SQL如下:
createview v_cjtj(sno,max_score,min_score,avg_score,sum_score)asselecttop100percent
sno,max(score),min(score),avg(score),sum(score)from SC
groupby sno
orderbysum(score)desc;
在SELECT语句中,应始终将一个ORDER BY子句与该TOP子句一起使用,以指定哪些行受过TOP滤器影响。
⚠️但其实当你执行如下语句:select*from v_cjtj;你会发现根本就没有排序,这是为什么呢?
排序无效的原因:创建排序视图的企图本身就是错误的,因为视图表示一个表,而表是不会对行排序的。
四、思考与练习
1.视图和表有何区别?
✏️ 视图是虚拟表,本身不具有和保存数据的,数据真正保存在数据表中,占用很少的内存空间,它是SQL中的一个重要的概念。视图建立在已有表的基础上。视图的本质是select语句,可以将视图理解为存储起来的select语句。
视图,是向用户提供基表数据的另一种表现形式。通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复杂的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。理解和使用起来都非常方便。
2.视图中的列都能更新吗?
✏️ 不一定能更新:
- 当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
- 但也有不能更新的视图,在定义视图的SELECT语句后的字段列表中使用
DISTINCT、聚合函数、GROUP BY、HAVING、UNION等,或使用了数学表达式、子查询等等情况,视图将不支持INSERT、UPDATE、DELETE。
🚩 虽然可以更新视图数据,但总的来说,视图作为
虚拟表,主要用于
方便查询,不建议更新视图的数据。对视图数据的更改,都是通过对实际数据表里数据的操作来完成的。
3.查询年龄最大的教师号和年龄,SQL命令如下:请问为什么报错?如何修改?
题目给的错误SQL命令:
Select tno,max(year(getdate())-year(tbirday))From T
✏️ 在SELECT列表中所有未包含在聚合函数中的列都应该包含在 GROUP BY子句中,很显然上述SQL语句
tno
是没有进行分组的,而
max
又是聚合函数。
❗️ 我们先说一种错误的修改写法:在from T 后加上 group by tno
Select tno,max(year(getdate())-year(tbirday))From T
groupby tno
对 T 表 以 tno 作为分组依据,在对每一组分别求该组的最大年龄,但很显然,在这个表中以Tno作为分组依据,每一组肯定只有一条记录,最终的查询结果不就和直接查询 T 表的所有教师年龄记录是一样的吗? 能达到这道题查询最大年龄以及对应教师号的目的吗?是不能的。
【正确的修改】
📍 我们先查询到 T 表中最大的年龄
Selectmax(year(getdate())-year(tbirday))From T
📍 接着再次查询 T 表,匹配教师年龄中与上述查到的最大年龄相等的记录
select tno,year(getdate())-year(tbirday)from T
whereyear(getdate())-year(tbirday)=(Selectmax(year(getdate())-year(tbirday))From T);
版权归原作者 是谢添啊 所有, 如有侵权,请联系我们删除。