
1对操作用户进行权限设置 详见下文pg创建流复制账号步骤
2.然后通过命令或者利用代码进行数据库数据的复制
安装flink 实例为1.13.6:
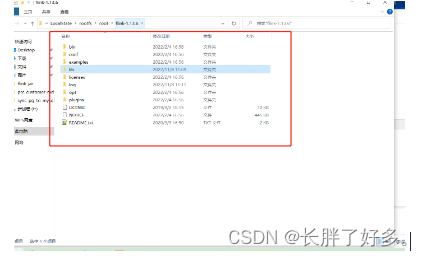
下载版本对应jar包 https://mvnrepository.com/
如果是mysql 就下载mysql对应jar包 pg就下载pg 对应jar包
ps:根据数据源类型以及对应版本号下载对应jar包 jar,版本不对应会造成启动报错以及数据不能同步
通过执行 ./start-cluster.sh
启动flink 打开网址http://localhost:8081 出现自带的flink内置页面
环境准备就绪之后 执行命令 /sql-client.sh
可以通过 finksql来进行数据库的复制 .
进入之后显示:
实例:地址localhost 版本为11.5postgresql 数据下属 postgres 数据库模式名为public 下属的test1 复制到 test1_1
创建库
CREATE DATABASE data_syn;
表结构:
CREATE TABLE “public”.“test1” (
“id” int4 NOT NULL,
“name” varchar(50) COLLATE “pg_catalog”.“default” NOT NULL
)
;
ALTER TABLE “public”.“test1” ADD CONSTRAINT “test1_pkey” PRIMARY KEY (“id”);
----------------------------------分割线---------------------------------------------------------
CREATE TABLE “public”.“test1_1” (
“id” int4 NOT NULL,
“name” varchar(50) COLLATE “pg_catalog”.“default” NOT NULL
)
;
ALTER TABLE “public”.“test1_1” ADD CONSTRAINT “test1_copy2_pkey” PRIMARY KEY (“id”);
----------------------------------flinksql---------------------------------------------------------
CREATE TABLE pgsql_source (
id int,
name STRING
) WITH (
‘connector’ = ‘postgres-cdc’,
‘hostname’ = ‘127.0.0.1’,
‘port’ = ‘5432’,
‘username’ = ‘postgres’,
‘password’ = ‘123456’,
‘database-name’ = ‘postgres’,
‘schema-name’ = ‘public’,
‘debezium.snapshot.mode’ = ‘never’,
‘decoding.plugin.name’ = ‘pgoutput’,
‘debezium.slot.name’ = ‘test3’,
‘table-name’ = ‘test1’
);
CREATE TABLE sink_sql (
id int,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
‘connector’ = ‘jdbc’,
‘url’ = ‘jdbc:postgresql://127.0.0.1:5432/postgres’,
‘table-name’ = ‘test1_1’,
‘username’=‘postgres’,
‘password’=‘123456’
);
insert into sink_sql select id,name from pgsql_source;
执行完毕之后就可以实现表的test1的增加量同步了。
但是增量数据修改的时候会报错:The “before” field of UPDATE/DELETE message is null, please check the Postgres table has been set REPLICA IDENTITY to FULL level. You can update the setting by running the command in Postgres 'ALTER TABLE public.test1 REPLICA IDENTITY FULL
这个是因为pg默认主键的重建操作会影响业务。需要规划空闲窗口。因为主键重建过程中,主库是无法进行delete和update操作的。此时更换一个复制标识代,使用唯一索引代替主键,作为一个中转。即可减少业务的影响。主键重建完成后再修改回来即可。
所以说我们需要在pg命令行执行:
ALTER TABLE public.test1 REPLICA IDENTITY FULL;
这样就可以实现test1至test1_1的CRUD了
package org.example;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class WordSourceFromPsql {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env, settings);
//拼接souceDLL
String sourceDDL =
"CREATE TABLE pgsql_source (\n" +
" id int,\n" +
" name STRING\n" +
") WITH (\n" +
" 'connector' = 'postgres-cdc',\n" +
" 'hostname' = '127.0.0.1',\n" +
" 'port' = '5432',\n" +
" 'username' = 'postgres',\n" +
" 'password' = '123456',\n" +
" 'database-name' = 'postgres',\n" +
" 'schema-name' = 'public',\n" +
" 'debezium.snapshot.mode' = 'never',\n" +
" 'decoding.plugin.name' = 'pgoutput',\n" +
// 复制槽名称
" ‘debezium.slot.name’ = ‘test3’,\n" +
" ‘table-name’ = ‘test7’\n" +
“)”;
// 执行source表ddl
tableEnvironment.executeSql(sourceDDL);
String sink_sql = "CREATE TABLE sink_sql (\n" +
" id int,\n" +
" name STRING,\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:postgresql://127.0.0.1:5432/postgres',\n" +
" 'table-name' = 'test7_copy',\n" +
" 'username'='postgres',\n" +
" 'password'='123456'\n" +
")";
tableEnvironment.executeSql(sink_sql);
String result = "insert into sink_sql select id,name from pgsql_source";
tableEnvironment.executeSql(result).print();
}
}
可以在maven中引入实现在编辑器上直接运行
org.apache.flink
flink-clients_2.11
${flink.version}
同样也可以打成jar包在flink服务上运行: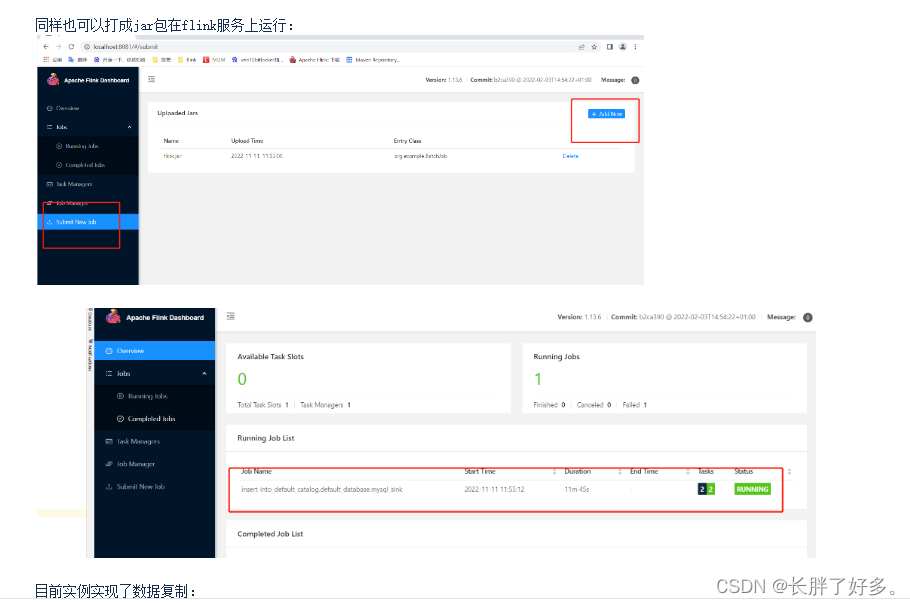
目前实例实现了数据复制:
pg ->elasticsearch
pg ->mysql
pg→pg 单表到单表 多表到单表
远端地址为:
https://gitlab.xpaas.lenovo.com/prc_customer_mdm/prc-customer-mdm-flink.git master分支上
------------------------------------------------------------------------pg新建一个用户来进行复制槽-------------------------------------------------------------------------------------------------
首先登录pg数据库
可以可视化工具
同样也可以用命令行
– 创建数据同步库
CREATE DATABASE database_syn;
– pg新建用户
CREATE USER 用户名称 WITH PASSWORD ‘用户密码’;
– 给用户复制流权限
ALTER ROLE 用户名称 replication;
– 给用户登录数据库权限
grant CONNECT ON DATABASE database_syn to 用户名称;
– 把当前库public下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO 用户名称;
– 把要同步的表进行发布
CREATE PUBLICATION data_syn FOR TABLE 表名;
– 查询哪些表已经发布
select * from pg_publication_tables;
– 给用户读写权限
grant select,insert,update,delete ON ALL TABLES IN SCHEMA public to 用户名称;
上述操作结束之后就可以得到一个可以进行复制槽crud的用户了
下面是一些常用的pg的设置
– pg新建用户
CREATE USER ODPS_ETL WITH PASSWORD ‘odpsETL@2021’;
– 给用户复制流权限
ALTER ROLE ODPS_ETL replication;
– 给用户数据库权限
grant CONNECT ON DATABASE test to ODPS_ETL;
– 设置发布开关
update pg_publication set puballtables=true where pubname is not null;
– 把所有表进行发布
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
– 查询哪些表已经发布
select * from pg_publication_tables;
– 给表查询权限
grant select on TABLE aa to ODPS_ETL;
– 给用户读写权限
grant select,insert,update,delete ON ALL TABLES IN SCHEMA public to bd_test;
– 把当前库所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO ODPS_ETL;
– 把当前库以后新建的表查询权限赋给用户
alter default privileges in schema public grant select on tables to ODPS_ETL;
– 更改复制标识包含更新和删除之前值
ALTER TABLE test0425 REPLICA IDENTITY FULL;
– 查看复制标识
select relreplident from pg_class where relname=‘test0425’;
– 查看solt使用情况
SELECT * FROM pg_replication_slots;
– 删除solt
SELECT pg_drop_replication_slot(‘zd_org_goods_solt’);
– 查询用户当前连接数
select usename, count() from pg_stat_activity group by usename order by count() desc;
– 设置用户最大连接数
alter role odps_etl connection limit 200;
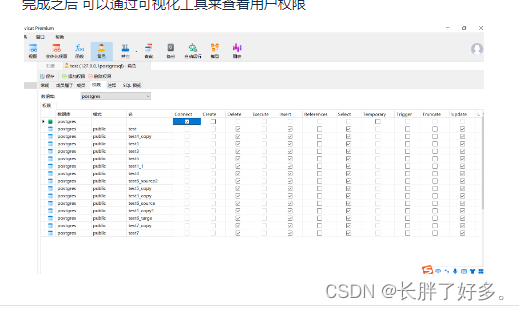
完成之后 可以通过可视化工具来查看用户权限
版权归原作者 长胖了好多。 所有, 如有侵权,请联系我们删除。