
Hive基础概念和用途
Hive是Hadoop下的顶级 Apache项目,早期的Hive开发工作始于2007年的 Facebook。
⬛ Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化
数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
⬛ Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
⬛ Hive由Facebook实现并开源。
Hive的优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
Apache Hive架构图
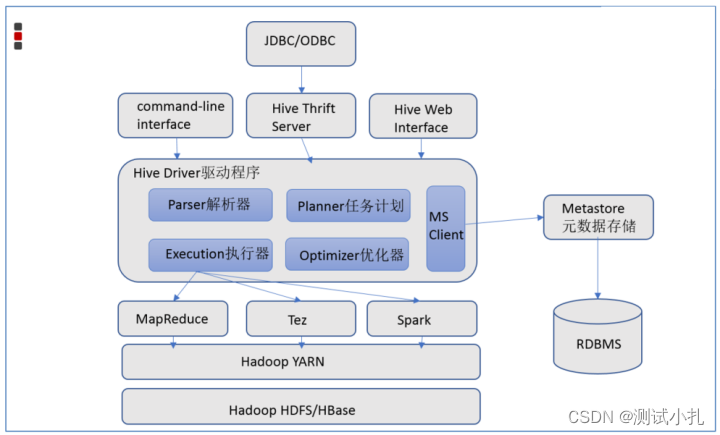
Hive组件
用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
**执行引擎 : **Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
Hive与Hadoop的关系
简单说就是Hive利用HDFS存储数据,利用MapReduce查询分析数据。
⬛ 从功能来说,数据仓库软件,至少需要具备下述两种能力:
存储数据的能力、分析数据的能力
⬛ Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述
两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
⬛ 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,
Hive帮您转换成为MapReduce程序完成对数据的分析。
Apache hive的技术特点
特点:
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
Hive应用场景
总的来说,Hive是十分适合数据仓库的统计分析和Windows注册表文件。 Hive在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS(Hive superimposes structure on data in HDFS),并允许使用类似于SQL语法进行数据查询。 Hive更适合于数据仓库的任务,主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使其成为Hadoop与其他BI工具结合的理想交集。
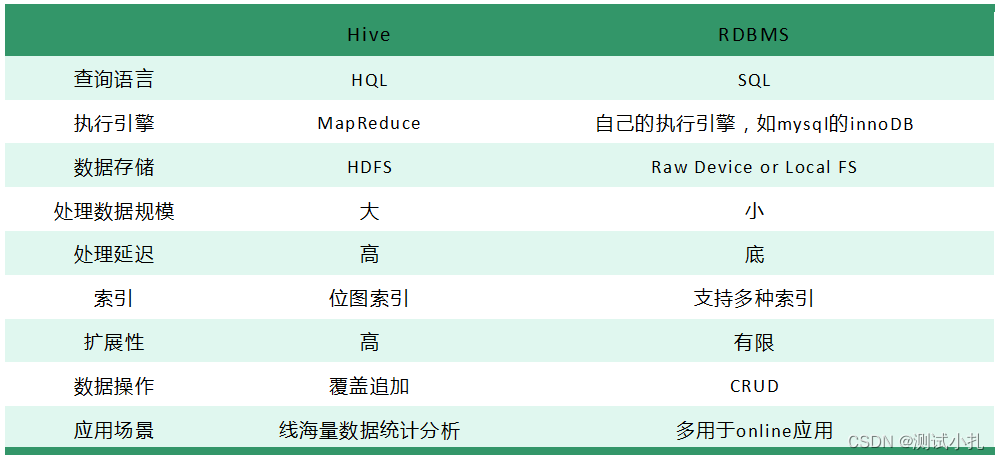
Hive与传统的关系型数据库对比
大规模数据处理的技术了解越多,对操作系统的体会越深。以下是一些基础操作
大数据相关:
Python+大数据开发
Linux入门:
新版Linux零基础快速入门到精通,全涵盖linux系统知识、常用软件环境部署、Shell脚本、云平台实践、大数据集群项目实战等
MySQL数据库:MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
Hadoop入门:大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程
Hive数仓项目:大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
PB内存计算
Python入门:python教程,8天python从入门到精通,学python看这套就够了
Python编程进阶:Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
spark3.2从基础到精通:Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
Hive+Spark离线数仓工业项目实战:全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
大数据面试八股文之Hive篇
01 Hive的三种自定义函数是什么?它们之间的区别是什么?
- UDF:用户自定义函数,user defined function。一对一的输入输出。
- UDTF:用户自定义表生成函数。user defined table-generate function.一对多的输入输出。
- UDAF:用户自定义聚合函数。user defined aggregate function,多对一的输入输出比如count sum等。
02 Hive SQL语句的执行顺序
如果上来就抛给你 “select from where group by having order by” 的执行顺序
平时没有仔细研究过,这题还真不好猜。
实际上,在 hive 和 mysql 中都可以通过 explain+sql 语句,来查看执行顺序。对于一条标准 sql 语句,它的书写顺序是这样的:
select … from … where … group by … having … order by … limit …
(1)mysql 语句执行顺序:
from... where...group by... having.... select ... order by... limit …
(2)hive 语句执行顺序:
from … where … select … group by … having … order by … limit …
**根据执行顺序,平时编写时需要记住以下几点: **使用分区剪裁、列剪裁,分区一定要加 少用 COUNT DISTINCT,group by 代替 distinct 是否存在多对多的关联 连接表时使用相同的关键词,这样只会产生一个 job 减少每个阶段的数据量,只选出需要的,在 join 表前就进行过滤 大表放后面 谓词下推:where 谓词逻辑都尽可能提前执行,减少下游处理的数据量 sort by 代替 order by
03 hive内部表和外部表的区别
未被external修饰的是内部表,被external修饰的为外部表。
区别:
- 内部表数据由Hive自身管理,外部表数据由HDFS管理;
- 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse), 外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
- 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
04 为什么要对数据仓库分层
- 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会 存在大量冗余的数据。如果不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
- 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
05 Hive 小文件过多怎么解决
- 使用 hive 自带的 concatenate 命令,自动合并小文件
- 调整参数减少Map数量
- 减少Reduce的数量
- 使用hadoop的archive将小文件归档
06 Hive有哪些方式保存元数据,各有哪些特点?
Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
- 内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby是内嵌式元存储的默认数据库。
- 在本地模式下,每个Hive客户端都会打开到数据存储的连接并在该连接上请求SQL查询。
- 在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信
07 Hive的函数:UDF、UDAF、UDTF的区别?
- UDF:单行进入,单行输出
- UDAF:多行进入,单行输出
- UDTF:单行输入,多行输出
08 Hive底层与数据库交互原理?
Hive 的查询功能是由 HDFS 和 MapReduce结合起来实现的,对于大规模数据查询还是不建议在 hive 中,因为过大数据量会造成查询十分缓慢。Hive 与 MySQL的关系:只是借用 MySQL来存储 hive 中的表的元数据信息,称为 metastore(元数据信息)。
09 hive中都有哪些join操作?
- left join:以左侧为主表,返回记录与主表记录数相同,关联不上的字段为空。
- right join:以右侧表为主表,返回记录与主表记录数相同,关联不上的字段为空。
- full join:以两个表的记录为基准,返回两个表的记录去重之和,关联不上的字段为null。
- cross join:返回两个表的笛卡尔积结果,不需要指定关联键。
- map join map端连接,与普通连接的区别是这个连接中不会有reduce阶段存在,连接在map端完成。
- common join:普通连接,在sql中不特殊指定连接方式使用的都是这种普通连接。
- skew join:倾斜连接,主要针对数据倾斜的情况优化。
- bucket map join:分桶连接。
10 hive 如何优化?
- join 优化,尽量将小表放在 join 的左边,如果一个表很小可以采用 mapjoin。
- 排序优化,order by 一个 reduce 效率低,distirbute by +sort by 也可以实现全局排序。
- 使用分区,查询时可减少数据的检索,从而节省时间。
版权归原作者 测试小扎 所有, 如有侵权,请联系我们删除。