
1.出现内存泄漏
1.1 事发现场

在风和日丽的一天,本人正看着需求、敲着代码,展望美好的未来。突然收到一条内存使用率过高的告警。
1.2 证人证词
告警的这个项目,老代码是python的,最近一直在go化。随着go化率不断上升,发现内存的RSS使用率越飙越高。最终达到容器内存限制后,进程会自动重启。RSS如下图所示: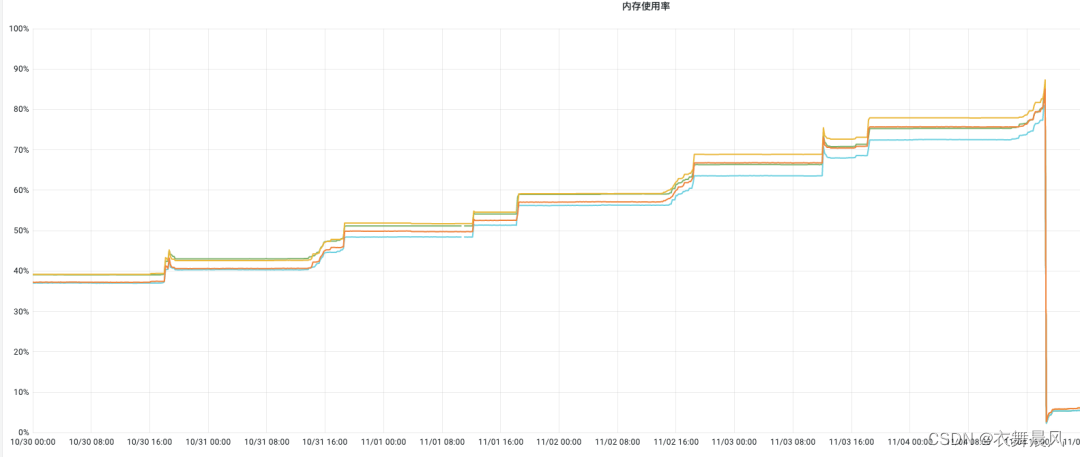
2.排查内存泄露
2.1 分析问题
看到这种不正常的RSS增长,第一反应是:是不是最近上的代码有什么问题?是不是发生了内存泄露?内存泄露可是大事,赶紧查查。于是将时间线拉长,看看是从哪天开始的。结果,现实是很残酷的。从项目刚上线的时候就有这个问题了。由于项目是2周一个版本,以前是还没达到内存限制,所以没有发出告警。
那么问题应该就是在最初的版本里。这个时候就想了想,难道是我们使用的框架本身存在缺陷?但是很快就否定了这个想法,因为我们使用的框架是其他项目已经上线已久的成熟框架。不应该有这个问题。
显然,看代码这种本办法是不可能发现问题的。于是想到了golang的性能分析工具pprof。由于pprof线上环境是不开启的,所以排查我这里只能去预发环境。
2.2 寻找问题
2.2.1 获取内存使用监控
go tool pprof -source_path=/path/to/gopath -inuse_space https://target.service.url/debug/pprof/allocs
- -source_path Search path for source files 是分析代码时,需要用到源码路径,这里就是你自己本地的gopath路径
- /debug/pprof/allocs 用来指定分析的是内存分配
- -inuse_space Same as -sample_index=inuse_space 是监控使用中的内存。因为我们分析的是内存泄露,所以要查看的是实际占用的内存
输入以上命令,会出现以下界面的内容:
2.2.2 分析内存监控
2.2.2.1 获取top10的内存占用
由于我们需要分析内存占用,所以这个时候输入一个**top10 **,看看占用内存前10的都是哪些代码。
(pprof)top10
Showing nodes accounting for145.07MB, 92.64% of 156.59MB total
Dropped 163 nodes (cum <=0.78MB)
Showing top10 nodes out of 157
flat flat% sum% cum cum%
117.36MB 74.95% 74.95% 117.36MB 74.95% github.com/beorn7/perks/quantile.newStream (inline)14.55MB 9.29% 84.25% 134.42MB 85.84% github.com/prometheus/client_golang/prometheus.newSummary
3.53MB 2.25% 86.50% 4.06MB 2.59% compress/flate.NewWriter
2MB 1.28% 87.77% 2MB 1.28% github.com/prometheus/client_golang/prometheus.MakeLabelPairs
1.53MB 0.97% 88.75% 1.53MB 0.97% github.com/rcrowley/go-metrics.newExpDecaySampleHeap
1.50MB 0.96% 89.71% 1.50MB 0.96% go.opentelemetry.io/otel/sdk/trace.(*recordingSpan).snapshot
1.50MB 0.96% 90.67% 1.50MB 0.96% github.com/Shopify/sarama.(*TopicMetadata).decode
1.06MB 0.68% 91.35% 1.06MB 0.68% github.com/valyala/fasthttp/stackless.NewFunc
1.03MB 0.66% 92.00% 1.03MB 0.66% github.com/xdg-go/stringprep.init
1MB 0.64% 92.64% 1MB 0.64% strings.(*Builder).WriteByte
这个时候需要解释一下显示的指标的含义
- flat:函数在内存上的占用
- flat%:函数在内存占用上的占用百分比
- sum%:是从上往下到当前行所有函数累加使用内存的比例
如第二行,sum=84.25=74.95+9.29
- cum:这个函数以及子函数运行所占用的内存,应该大于等于flat
- cum%:这个函数以及子函数运行所占用的内存的比例,应该大于等于flat%
2.2.2.2 查看占用函数调用栈
看完以上返回,明眼人应该就能看出,第一行这个newStream问题很大呀,让我们进去看看他哪行代码出了问题。需要用到一下命令
让我们输入list github.com/beorn7/perks/quantile.newStream一探究竟
(pprof) list:
Output annotated source for functions matching regexp
显示具体调用的代码块并显示相应指标
(pprof) list github.com/beorn7/perks/quantile.newStream
Total: 156.59MB
ROUTINE ======================== github.com/beorn7/perks/quantile.newStream in pkg/mod/github.com/beorn7/[email protected]/quantile/stream.go
117.36MB 117.36MB (flat, cum)74.95% of Total
..128: sorted bool
..129:}..130:
..131:func newStream(ƒ invariant) *Stream {..132: x :=&stream{ƒ: ƒ}117.36MB 117.36MB 133: return&Stream{x, make(Samples, 0, 500), true}..134:}..135:
..136:// Insert inserts v into the stream.
..137:func (s *Stream) Insert(v float64){..138: s.insert(Sample{Value: v, Width: 1})
2.2.2.3 分析泄露原因
看到这里,应该能看出这个newStream的内存占用,主要是因为生成了一个容量为500的数组。那这个数组是什么样的呢?
type Sample struct {
Value float64 `json:",string"`
Width float64 `json:",string"`
Delta float64 `json:",string"`}
以上结构可以看出,生成一次需要占用的内存是50038字节,那么一次就是12000个字节,差不多是11.72kb。这么看来,应该是有个地方不停的调用,导致数据持续膨胀。看到这里,我们继续往下追。
(pprof) list github.com/prometheus/client_golang/prometheus.newSummary
Total: 156.59MB
ROUTINE ======================== github.com/prometheus/client_golang/prometheus.newSummary in pkg/mod/github.com/prometheus/[email protected]/prometheus/summary.go
14.55MB 134.42MB (flat, cum)85.84% of Total
..220: }..221: s.init(s) // Init self-collection.
..222: return s
..223: }..224:
512.12kB 512.12kB 225: s :=&summary{..226: desc: desc,
..227:
..228: objectives: opts.Objectives,
..229: sortedObjectives: make([]float64, 0, len(opts.Objectives)),
..230:
. 1MB 231: labelPairs: MakeLabelPairs(desc, labelValues),
..232:
7.03MB 7.03MB 233: hotBuf: make([]float64, 0, opts.BufCap),
7.03MB 7.03MB 234: coldBuf: make([]float64, 0, opts.BufCap),
..235: streamDuration: opts.MaxAge / time.Duration(opts.AgeBuckets),
..236: }..237: s.headStreamExpTime = time.Now().Add(s.streamDuration)..238: s.hotBufExpTime = s.headStreamExpTime
..239:
..240: for i := uint32(0); i < opts.AgeBuckets; i++ {.118.86MB 241: s.streams = append(s.streams, s.newStream())..242: }..243: s.headStream = s.streams[0]..244:
..245: for qu := range s.objectives {..246: s.sortedObjectives = append(s.sortedObjectives, qu)
由此看出,还不止使用一次newStream()。通过观看代码,我这里发现,此处的opts.AgeBuckets是等于5的,那么就意味着,循环生成了5个stream,实际上占用的内存是50038*5=60000字节,也就是58.6kb。
2.2.2.4 分析调用链路
那么现在基本追溯完了大概的泄露原因。那怎么样能寻找是具体的调用链的呢,总不能一层一层往上查找调用吧?这个时候pprof提供了一个命令,可以把整体调用生成一张图片展示。命令如下:
go tool pprof -png-source_path=/path/to/gopath -inuse_space https://target.service.url/debug/pprof/allocs > heap.png
只需要在命令中加一个-png,那么就会生成一张图片。当然为了方便寻找,最后可以指定图片生成地址。我这边抓取了和本文有关的一段截图,如下。
根据上图链路,我们大致可以看出。应该是mysql的调用,在OnFinished处,prometheus的上报的地方出现了内存泄露。这个时候我们就可以追一下OnFinished处的代码了,因为之后的都是prometheus的调用,这是一个成熟的三方,理论不应该是他这个点出问题。
2.2.3 寻找泄露代码
OnFinished的代码如下:
label := append([]string{getOperation(db), s.host, s.database, tableName, hasErr, sqlState}, metrics.InjectTagValue(collector.MetricsTitle, db.Statement.Context, attachment)...)
elapsed := time.Since(s.StartTime).Seconds()
collector.DurationReporter.Collector.(prometheus.ObserverVec).WithLabelValues(label...).Observe(elapsed)
看到这里我想大家就应该知道了,go代码会为prometheus创建一个5*500的缓冲池,来记录数据,prometheus会周期性的调用/mertic来拉取对应的内容。那么这里是怎么造成内存泄露的呢?这里就要分析上述代码的这个label了。
func (m *MetricVec) GetMetricWithLabelValues(lvs ...string)(Metric, error){
h, err := m.hashLabelValues(lvs)if err != nil {return nil, err
}return m.metricMap.getOrCreateMetricWithLabelValues(h, lvs, m.curry), nil
}
func (m *MetricVec) hashLabelValues(vals []string)(uint64, error){if err := validateLabelValues(vals, len(m.desc.variableLabels)-len(m.curry)); err != nil {return0, err
}
var (
h = hashNew()
curry = m.curry
iVals, iCurry int
)for i :=0; i < len(m.desc.variableLabels); i++ {if iCurry < len(curry)&& curry[iCurry].index == i {
h = m.hashAdd(h, curry[iCurry].value)
iCurry++
}else{
h = m.hashAdd(h, vals[iVals])
iVals++
}
h = m.hashAddByte(h, model.SeparatorByte)}return h, nil
}
2.3 发现问题(伪)
通过查看函数调用,我这边发现label最终进入的是这个hashLabelValues中,如果已存在就返回对应的metricMap中的内容,如果不一样,则会创建一个新的缓冲池。内存泄露就出在这个创建中。
这个时候我就在想,难道是我们label采集的数据太多了?通过排列组合,我估算了一下内存最大值
getOperation(db)=4(操作类型,增删改查4种)
s.host=1
s.database=3(我们有3个db实例)
tableName=30(表名,保守估计最少30个)
hasErr, sqlState=2 (报错与没报错2个状态)
metrics.InjectTagValue(collector.MetricsTitle, db.Statement.Context, attachment)…
这里面记录的是请求的endpoint和startpoint,保守估计最少40个接口
这样算下来:4133024055008*3=1648mb。再加上程序本身的一些内存开销,感觉和我们碰到的问题能对上了。
2.4 解决问题(伪)
于是一拍脑袋觉得发现了问题,但是又无法解决问题(抓的指标无法修改)。于是屁颠屁颠的升了服务器配置,将4c2g升为了4c4g。
3.解决内存泄漏
3.1 发现问题(真)
没错,当你看到这里的时候,就知道,升配这件事情并没有结束。现实给了我一记响亮的耳光。
因为升配以后总觉得还是哪里有问题。于是还是每天都在不停的观察RSS情况。结果,还真发现问题了。因为内存还在坐火箭,这不科学啊。
当我准备继续深入研究代码的时候,我的一位同事提醒了我,你可以去看下/metrics具体上报了什么。说时迟那时快。于是抓取了/metrics里的上报数据,看到了以下数据:
go_mysql_execute_count_total{command="SELECT",db="db_xxxxxx",endpoint="[DELETE]/url/:id",error="false",host="xxxxxx",main_table="table_xxxxxx",sql_state="0",startpoint="/url/49630"}1
go_mysql_execute_count_total{command="SELECT",db="db_xxxxxx",endpoint="[DELETE]/url/:id",error="false",host="xxxxxx",main_table="table_xxxxxx",sql_state="0",startpoint="/url/49631"}1
go_mysql_execute_count_total{command="SELECT",db="db_xxxxxx",endpoint="[DELETE]/url/:id",error="false",host="xxxxxx",main_table="table_xxxxxx",sql_state="0",startpoint="/url/49668"}1
go_mysql_execute_count_total{command="SELECT",db="db_xxxxxx",endpoint="[DELETE]/url/:id",error="false",host="xxxxxx",main_table="table_xxxxxx",sql_state="0",startpoint="/url/49673"}1
这不看不要紧,一看——原来startpoint里上报的是restful风格的请求地址。那么上面的计算缓冲池的算法,就要再乘一个无限膨胀的startpoint。这给多少个G内存也都不够。
于是继续查看代码,看能不能关闭startpoint上报。这一查,果然有:
3.2 解决问题(真)
看到这个设置START_POINT的环境变量,能关闭startpoint上报。于是立马加到生产环境后重启服务器。上线后观察了一段时间,RSS使用量如下图所示:
到此,此次内存泄露问题终于排查并修复完成。真是有惊无险。
4.内存泄露问题总结
这边大致归纳下go语言中有哪些常见的内存泄露。
常见内存泄露
4.1 Goroutine泄漏
goroutine泄露是开发过程中碰到最常见、最频繁的。一般经常碰到的是以下几种,由于网上相关的文章太多了,就不用代码举例了。
4.1.1 协程无法退出
- 锁占用
- channel无法读取或写入
- 协程中逻辑有死循环
4.1.2 协程阻塞
协程业务逻辑时间长,释放速度跟不上生成速度
4.1.3 内存使用不当
持续增长的常驻协程,申请了大量内存空间,由于是常驻的协程,不会释放内存造成泄露
并发申请大量内存后,未达到GC时间或GC阈值,未触发GC,导致内存泄露
4.2 结构使用不当
结构使用不当也是开发中常见的,只是可能并发不高,或者内存泄露的不多,导致使用者容易忽视掉。
4.2.1 字符串、切片截取
func main(){
var str0 ="1234567890"
str1 := str0[:5]}
func main(){
var s0 =[]int{1,2,3,4,5,6,7,8,9,0}
s1 := s0[:5]}
上面两段代码,会有5个字节的泄露,因为字符串和切片的两个变量,底层是共享内存的。只要str1或s1一直在用,str0和s0就不会回收。这样剩下的5个字节或者5个int就会有临时的泄露。这个场景,如果在高并发,并且数据够大的情况下,就算是临时的泄露,也可能对性能有极大的影响。
4.2.2 指针类型
func main(){
var prt0 =[]*int{new(int), new(int), new(int), new(int), new(int)}
ptr1 := prt0[:3]}
指针类型的这段代码,其实和上面字符串、切片的例子很像,指针是指向内存地址的。只要ptr1没释放,前面的指针数组中未被用的指针就不会释放,从而导致临时的内存泄露。
4.2.3 数组传参
func main(){
var arr1 =[3]int{1,2,3}
var arr2 =[3]int{}
arr2 = arr1
fmt.Printf("array address :%p, array : %+v \n", &arr1, arr1)
fmt.Printf("array address :%p, array : %+v \n", &arr2, arr2)
test(arr1)}
func test(arr [3]int){
fmt.Printf("array address :%p, array : %+v \n", &arr, arr)}
打印结果如下:
array address :0xc000122030, array :[12345]
array address :0xc000122060, array :[12345]
array address :0xc0001220f0, array :[12345]
看结果可知,三条打印的地址各不相同,说明数组是值传递的,那这会有什么问题呢?毕竟我们很多代码都是这么写的。
问题在于,只要传递的这个数组足够大,那么调用一次就会生成一个一样大小的新地址,这样会消耗大量内存。如果短时间内无法GC,会产生临时的内存泄露。这种泄露对于高并发是致命的。
4.2.4 定时器
func main(){
chi := make(chan int)
go func(){for{
timer := time.After(10 * time.Second)select{case<-ch:
fmt.Println("get it")case<-timer:
fmt.Println("end")}}}()for i:=1; i<1000000; i++ {
chi <- i
time.sleep(time.Millisecond)}}
以上代码,之所以会造成内存泄露。是因为time.After的底层是实现了一个timer,只要定时器未到时间,这个定时器就不会被gc回收,从而造成临时的内存泄露。如果这里的代码没写好,定时器都是新创建的,那么就会造成永久性的泄露。
其实golang中的内存泄露远不止上文提到的这些。有些可能甚至连查都查不到。这个时候还是要提醒大家,不仅要了解问题,还要学会查找问题。这样不管遇到什么问题,都能发现蛛丝马迹,问题也将迎刃而解。
版权归原作者 衣舞晨风 所有, 如有侵权,请联系我们删除。