
文章目录
一、集群节点类型
查看集群状态时,会显示所有节点的节点类型。RabbitMQ中的每一个节点,不管是单一节点系统或者是集群中的一部分,要么是内存节点,要么是磁盘节点。
- 内存节点(ram),将所有的队列、交换器、绑定关系、用户、权限和vhost的元数据定义都存储在内存中。
- 磁盘节点(disk),则将这些信息存储到磁盘中。
单节点集群中必然只有磁盘类型的节点,否则当重启 RabbiMQ之后,所有关于系统的配置信息都会丢失。搭建多机集群时,可以使用参数–ram来配置部分节点为内存节点,节点加入集群默认是磁盘节点。
1.1 内存节点
1.承接上文,三个节点node1、node2、node3组成集群时没有指定节点类型,所以默认就是磁盘节点。
2.现在将node4节点加入集群中指定参数-ram,以内存节点加入。并开启node4节点的web监控插件。
[root@node4 ~]# rabbitmqctl stop_app
[root@node4 ~]# rabbitmqctl reset
#加入集群时指定ram参数,代表内存节点。
[root@node4 ~]# rabbitmqctl join_cluster rabbitmq_1@node1 --ram
[root@node4 ~]# rabbitmqctl start_app
#开启插件。
[root@node4 ~]# rabbitmq-plugins enable rabbitmq_managent

3.查看node4节点类型为ram节点,磁盘类型。

4.查看web监控,当前集群存在4个节点。

1.2 磁盘节点
搭建集群时,加入节点那一步不指定参数默认就是磁盘节点。但像我们这种集群已经搭建好了,也可以使用命令来切换更改节点类型。
- 命令格式:rabbitmgctl change_cluster_node type{disc,ram)- disc:表示磁盘节点。- ram:表示内存节点。
比如,这里将上面 node4 节点由内存节点转变为磁盘节点。
1.修改前,node4还是内存节点。
2. 修改node4节点类型为磁盘节点。
[root@node4 ~]# rabbitmqctl stop_app
[root@node4 ~]# rabbitmqctl change_cluster_node_type disc
[root@node4 ~]# rabbitmqctl start_app

3.此时再次查看node4节点类型为磁盘节点。
总结:
- RabbitMQ只要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点。 - 若是保证集群信息的高可靠性,建议全部使用磁盘节点。- 若是需要提高集群的高可用性,可以保证至少两个磁盘节点和至少一个内存节点。
为什么要保证集群中至少有两个磁盘节点?
- 当节点加入或者离开集群时,它们必须将变更通知到至少一个磁盘节点。所以如果集群中唯一的磁盘节点崩溃,集群仍然可以保持运行(可以继续发送或者接收消息),但是直到将该节点恢复到集群前,但是不能执行创建队列、交换器、绑定关系、用户,以及更改权限、添加或删除集群节点的操作。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在。
内存节点有元数据信息保存到磁盘吗?是什么信息?
- 当内存节点重启后,它们会连接到预先配置的磁盘节点,下载当前集群元数据的副本。
- 当在集群中添加内存节点时,确保告知其所有的磁盘节点(内存节点唯一存储到磁盘的元数据信息是集群中磁盘节点的地址)。只要内存节点可以找到至少一个磁盘节点,那么它就能在重启后重新加入集群中。
二、集群基础运维
2.1 剔除单个节点
当我们需要让集群规模变小以节省硬件资源,或者替换一个机器性能更好的节点时,需要将某个节点提出当前集群。拿当前集群为例,有node1、node2、node3、node4供4个节点,有两种方法:
- 第一种:- 第一步:先在要踢出取的那个节点上执行命令停止服务,比如我这里就要把node2节点踢出去,则在node2节点上执行rabbitmqctl stop_app 或者 rabbitmqctl stop命令。- 第二步:之后再在node1/node3/node4任意一个节点上执行命令将node2节点踢出去,rabbitmgctl forget_cluster_node rabbitmq_2@node2 。- 这种方式适合踢出去的那个节点不再运行 RabbitMQ的情况。
- 第二种:- 使用rabbitmqctl reset命令重置节点。- 这种方式更适合正常剥离提出,踢出时告知其他磁盘节点我要被踢出去了,不然其他节点会期盼着它醒过来。
2.1.1 集群正常踢出正常节点
1.先停止要踢出的节点服务,比如我这里要踢出node2节点就在node2节点上执行命令。
[root@node2 backup]# rabbitmqctl stop
Stopping and halting node rabbitmq_2@node2 ...
2.在其他任意一个节点上执行踢出命令。这里我是在node1节点上提出的node2节点。
[root@node1 ~]# rabbitmqctl forget_cluster_node rabbitmq_2@node2
Removing node rabbitmq_2@node2 from the cluster
3.查看集群状态,node2节点已被踢出,只剩下node1、node3、node4节点。

2.1.2 服务器异常宕机踢出节点
在关闭集群中的每个节点之后,如果最后一个关闭的节点最终由于某些异常而无法启动,则可以把这个节点踢出集群,不然其他节点都会等待它启动起来后才能运行。
- 命名格式:rabbitmqctl forget_cluster_node {要踢出节点名称} - “- -offline”参数代表,当前节点在非运行状态下可以把要踢出去的节点剥离集群。- 如果不添加这个参数,就需要保证当前节点中的 RabbitMQ 服务处于运行状态。
1.依次停止node1、node3、node4节点,此时如果想要恢复集群需要先启动node4节点,但是我们现在是模拟node4节点异常无法正常启动,则需要把node4节点踢出去。
2.此时在node3或者node1节点上执行踢出命令。我这里是在node3节点上踢出node4节点。
[root@node3 rabbitmq]# rabbitmqctl forget_cluster_node rabbitmq_4@node4 --offline

3.踢出之后再正常启动其他节点,我这里是node1和node3节点。再次查看集群状态显示node1和node3节点存在并正常运行。
#启动其他节点。
[root@node3 ~]# rabbitmq-server -detached
[root@node1 ~]# rabbitmq-server -detached


2.1.3 集群正常重置并踢出节点
1.在要踢出的节点上执行重置命令即可。我这里就是要踢出node3节点。
[root@node3 rabbitmq]# rabbitmqctl stop_app
[root@node3 rabbitmq]# rabbitmqctl reset
[root@node3 rabbitmq]# rabbitmqctl start_app
2.此时分别在node1、node3节点上查看集群状态,各自独为集群。并且node3节点上的所有数据都被清空。


2.2 集群节点版本升级
版本升级要点:
- 需要注意新版本的rabbitmq版本是否兼容之前已经安装好的erlang版本,可以在rabbitmq官网上查。
- 要确保原节点的 Mnesia 中的数据不被变更,且新节点中的Mnesia 路径的指向要与原节点中的相同,就是$HOME/var/lib/rabbitmq/mnesia目录下的数据文件。或者说保留原节点 Mnesia 数据,然后解压新版本到相应的目录,再将新版本的Mnesia 路径指向保留的Mnesia数据的路径。再或者可以直接复制保留的 Mnesia 数据到新版本中相应的目录,最后启动新版本的服务即可。
版本升级流程:
- 使用rabbitmqctl stop命令,关闭所有rabitmq节点服务。
- 保存旧版本rabbitmq各个节点的 Mnesia目录下的数据。
- 解压新版本的rabbitmq到指定的目录。如果不是覆盖旧版本rabbitmq服务目录,则需要更改shell环境变量,不然启动的旧版本的rabbitmq服务。
- 指定新版本的 Mnesia目录路径为步骤 2 中保存的 Mmesia 据路径。
- 启动新版本的服务,注意先重启原版本中最后关闭的那个节点。
我这里就是将RabbitMQ 3.11.4 升级到3.11.5。注意此时我的node1和node2节点类型是磁盘节点,node3和node4节点类型是内存节点。
- 如果最后我们升级成功但是显示的节点类型与现在不一样,说明只是rabbitmq版本升级成功了,大那是之前的数据全部丢失了。
- 当然我们还可以通过升级过后最后的显示用户是否还是qingjun用户,或者现在发送一条消息,与升级过后的查询结果相比就可以判断升级过程过数据是否丢失。


- 进入rabbitmq官网查看要升级的新版本是否兼容已安装的erlang环境版本。所以我要升级到3.11.5版本是符合erlang的25.0版本的。

2.下载新版rabbitmq安装包,并解压到一个新的路劲中,最好不要直接把旧rabbitmq目录覆盖了。

3.依次停止rabbitmq集群,注意停止顺序,到时候启动时是先启动最后一个停止的。我这里依次停止node1、node2、node3、node4节点。
[root@node1 ~]# rabbitmqctl stop
Stopping and halting node rabbitmq_1@node1 ...
[root@node2 ~]# rabbitmqctl stop
Stopping and halting node rabbitmq_2@node2 ...
[root@node3 ~]# rabbitmqctl stop
Stopping and halting node rabbitmq_3@node3 ...
[root@node4 ~]# rabbitmqctl stop
Stopping and halting node rabbitmq_4@node4 ...
4.指定新版本的Mnesia目录下的文件路劲和旧版本路劲一致。
- node1节点

- node2节点

- node3节点

- node4节点

5.修改shell环境变量,指定新版本的启动路径。
[root@node1 rabbitmq]# tail -2 /etc/profile
export RABBITMQ_HOME=/opt/backup/rabbitmq_server-3.11.5
export PATH=$RABBITMQ_HOME/sbin:$PATH
[root@node1 rabbitmq]# source /etc/profile
[root@node2 local]# tail -2 /etc/profile
export ERLANG_HOME=/opt/backup/rabbitmq_server-3.11.5
export PATH=$ERLANG_HOME/sbin:$PATH
[root@node2 local]# source /etc/profile
[root@node3 rabbitmq]# tail -2 /etc/profile
export RABBITMQ_HOME=/opt/backup/rabbitmq_server-3.11.5
export PATH=$RABBITMQ_HOME/sbin:$PATH
[root@node3 rabbitmq]# source /etc/profile
[root@node4 rabbitmq]# tail -2 /etc/profile
export rabbitmq_home=/opt/backup/rabbitmq_server-3.11.5
export PATH=$rabbitmq_home/sbin:$PATH
[root@node4 rabbitmq]# source /etc/profile
6.先启动之前最后停止的那个节点,也就是node4节点。
7.再依次启动其他三个节点。


8.此时再去查看集群状态,是恢复到之前的,且版本升级成3.11.5版本。

9.再依次开启每个节点的监控插件。
[root@node1 ~]# rabbitmq-plugins enable rabbitmq_management
[root@node2 ~]# rabbitmq-plugins enable rabbitmq_management
[root@node3 ~]# rabbitmq-plugins enable rabbitmq_management
[root@node4 ~]# rabbitmq-plugins enable rabbitmq_management
10.验证,任意一个节点查看用户,还是有我们之前创建的qingjun用户,登录web监控查看运行状态。

2.3 集群某单节点故障恢复
- 当集群中的单个节点发生了故障,有可能会引起集群服务不可用、数据丢失等异常。
- 单节点故障包括:机器硬件故障、机器掉电、网络异常、服务进程异常。
2.3.1 机器硬件故障
故障情景:
- 单节点机器硬件故障包括,机器硬盘、内存、主板等故障造成的死机,没法在这台服务器上进行软件恢复。这时就要从其他节点入手。
解决思路:
- 在集群中的其他节点中执行 rabbitmgctl forget_cluster_node {node_name} 命令,其中 nodename 表示故障机器节点名称。- 如果集群其他节点都不能运行,可以加上“- -offine”参数。- 示例:踢出node4节点的命令为, rabbitmqctl forget_cluster_node rabbitmq_4@node4 --offline 。具体操作过程可以参考上面的2.1.2章节。
- 如果之前有客户端连接到此故障节点上,在故障发生时会有异常报出,此时需要将故障节点的 IP 地址从连接列表里删除,并让客户端重新与集群中的节点建立连接,以恢复整个应用。
2.3.2 机器掉电
故障情景:
- 机房停电、服务器异常掉电。
解决思路:
- 第一步:先等待电源接通,再重启机器。此时这台服务器上的rabbitmq处于 stop 状态,但是此时不要盲目重启服务,否则可能会引起网络分区。
- 第二步:此时同样需要在其他节点上执行 rabbitmgctl forget_cluster_node {node_name} 命令,将此节点从集群中剔除。
- 第三步:然后删除这台故障服务器的 rabbitmq 中$HOME/var/lib/rabbitmq/mnesia目录下的数据文件,相当于重置,数据丢失。
- 第四步:数据文件删除之后,再重启 rabbitmq服务。
- 第五步:最后再将这个节点作为一个新节点,加入到当前集群中。
2.3.3 网络故障
故障情景:
- 网线松动、网卡损坏。
解决思路:
- 网线松动,无论是彻底断开,还是“藕断丝连”,只要它不降速,RabbitMQ集群就没有任何影响。但是为了保险起见,建议先关闭故障机器的 RabbitMQ进程,然后对网线进行更换或者修复操作,之后再考虑是否重新开启RabbitMQ进程。
- 网卡故障,是极易引起网络分区情况的发生。 - 如果监控到网卡故障而网络分区尚未发生时,需要再第一时间关闭此机器节点上的 RabbitMQ 进程,在网卡修复之前不建议再次开启。- 如果已经发生了网络分区,可以手动恢复网络分区,至于怎么恢复咱们后面再来说这个,东西还是有点多,此章节不多赘述。
2.3.4 服务进程异常
故障情景:
- RabbitMQ进程非预期终止。
解决思路:
- 第一步:可以先看看相关风险是否在可控范围之内。如果风险不可控,可以选择抛弃这个节点。
- 第二步:如果风险可控,就可以抢救一下。重新启动RabbitMQ服务进程,根据日志来排查。
2.4 集群迁移
- 对运维来说, rabbitmq的扩容和迁移是必须要掌握的,前面已经讲过扩容,一般向集群中加入新的集群节点即可,需要注意一点,新加入的节点是没有队列创建的,只有后面新创建的队列才有可能进入这个新的节点中。
- 而集群迁移,是将旧的集群中的数据(包括元数据信息和消息)迁移到新的且容量更大的集群中。rabbitmq中集群迁移更多是用来解决集群故障导致短时间内业务不可恢复的情况,以确保服务的可用性。比如虚拟化全部挂了、IDC 整体停电、网线被挖断等。
- 集群迁移步骤: - rabbitmq集群迁移包括元数据重建、数据迁移,以及与客户端连接的切换。
2.4.1 元数据重建
- 元数据重建是什么?- 是指在新集群中创建原集群的队列、交换器、绑定关系、vhost、用户、权限和 Parameter 等数据信息。元数据重建之后才可将原集群中的消息数据及客户端连接迁移过来。
- 重建方式:- 最老的版本是手工创建,那个时候rabbitmq还没有搞出元数据文件下载功能,非常耗时。现在都是在 Web管理界面元数据JSON文件迁移。
- 注意事项:- 第一,若原集群突发故障导致无法获取元数据JSON文件。一般情况下,我们都是功能测完之后,就打包一个文件带回去,每次更新服务稳定后也要打包一个新文件回去备着。同时也可以写个通用备份任务,在元数据有变更或者达到某个存储周期时将最新的JSON文件备份至另一处安全的地方。- 第二,若新旧集群的rabbitmq版本不一致会出现异常情况。不同版本的加密方式有些区别,而且JSON文件内容也有些不同。一般情况下,高版本的rabbitmq中可以上传低版本的元数据文件。可以将高版本导出的JSON文件里的queues 这一项前面的内容,包括 rabbit_version、users、vhosts、permissions、parameters、global_parameters和policies,这几项内容复制后替换低版本的新集群中。保存后再上传。
- 第三,若是采用上面的方法将元数据在新集群上重建,则所有的队列都只会落到同一个集群节点上,而其他节点处于空置状态,所有的压力将会集中到这单台节点之上。比如新集群由node1、node2、node3 节点组成,其节点的IP 地址分别为 192.168.0.1、192.168.0.2和192.168.0.3。当访问 http://192.168.0.1:15672 页面时,并上传了原集群的元数据JSON文件,那么原集群的所有队列将只会在 node1 节点上重新建立。这个问题只能通过代码层面来解决。
1.在搭建平台时,数据一测通就要顺手保存一份元数据文件,点击下载即可。所以这个json文件一定是旧集群还在正常运行时就要导一份出来的,这也是一个合格运维的防微杜渐意识必须要具备的素质。注意我导出文件的集群版本是3.11.5,而导入的新集群版本是3.11.4。

2.导入至新集群,需要注意以下两点。我这里就是把可变信息覆盖了,需要用旧集群的账户密码登录。
- 若新集群有数据与导出的JSON文件中的数据相冲突,对于交换器、队列及绑定关系这类非可变对象而言会报错,而对于其他可变对象如 Parameter、用户等则会被覆盖,没有发生冲突的则不受影响。
- 如果过程中发生错误,则导入过程终止,导致JSON文件中只有部分数据加载成功。

3.查看新集群导入元数据信息。检查一下是否导的有问题。

2.4.2 数据迁移和客户端连接的切换
第一步的元数据迁移只是准备工作,数据迁移和客户端连接的切换才是主要工作。
- 客户端连接的切换·:- 第一步,首先需要将生产者的客户端与原rabbitmq集群的连接断开,然后再与新的集群建立新的连接,这样就可以将新的消息流转入到新的集群中。- 第二步,然后就需要考虑消费者客户端的事情了。 - 第一种是等待原集群中的消息全部消费完之后再将连接断开,然后与新集群建立连接进行消费作业。可以通过 Web 页面查看消息是否消费完成。- 第二种是,当原集群服务不可用或者出现故障造成服务质量下降而需要迅速将消息流切换到新的集群中时,此时就不能等待消费完原集群中的消息,这里需要及时将消费者客户端的连接切换到新的集群中,那么在原集群中就会残留部分未被消费的消息,此时需要做进一步的处理。如果原集群损坏,可以等待修复之后将数据迁移到新集群中,否则会丢失数据。
- 数据迁移原理:- 写一个小工具,让其从原集群中将数据消费出来存入一个缓存区中,然后第二个线程读取缓存区中的消息再发布到新的集群中,如此便完成了数据迁移的动作。

三、进阶命令
3.1 集群管理类
3.1.1 节点加入集群(集群扩容)
命令格式:rabbitmqctl join_cluster {cluster_node} [–ram]
- cluster_node,代表加入到哪个集群节点中。
- –ram,可选参数,代表以内存节点类型加入到集群中。不加此参数默认是以磁盘节点加入到集群。
命令使用注意要点:
- 使用此命令前,需要先停止rabbitmq服务应用,并重置该节点,可以参考前文记录。 - 停止rabbitmq服务应用:rabbitmqctl stop_app- 重置该节点:rabbitmqctl reset
3.1.2 显示集群状态
命令格式:rabbitmqctl cluster_status
3.1.3 修改集群节点类型
命令格式:rabbitmqctl change_cluster_node_type {disc|ram}
- disc,表示磁盘节点类型。
- ram,表示内存节点类型。
命令使用注意要点:
- 使用此命令前,需要先停止rabbitmq服务应用,可以参考前文记录。 - 停止rabbitmq服务应用:rabbitmqctl stop_app
3.1.3 删除集群中某节点
命令格式:rabbitmqctl forget_cluster_node {要踢出节点名称} [- -offline]
- “- -offline”参数,表示本节点上的rabbitmq服务可以在离线状态下踢出指定节点。不加该参数则需要保证本机上的rabbitmq服务运行正常。
3.1.4 咨询、并更新集群节点最新信息
命令格式:rabbitmqctl update_cluster_nodes {cluster_node}
- cluster_node:表示当前集群中存活的节点。
命令作用:
- 在集群中的节点应用启动前咨询集群存活节点的最新信息,并更新相应的集群信息。
- 这个和 join_cluster 不同,它不加入集群。
适用情景:
- 比如我这里集群中有node1和node2节点。
- 此时node1节点离线期间,node3和node2组成集群。
- 这时node2节点离线,node3自己独为集群,期间node1节点苏醒会尝试联系node2节点,但是这样会失败,因为node2已经不在集群中了。rabbitmactl update_cluster_nodes {集群中正常节点名称} 命令,可以解决这种场景下出现的问题。
1.node1节点上查看集群,此时集群中有node1和node2节点。
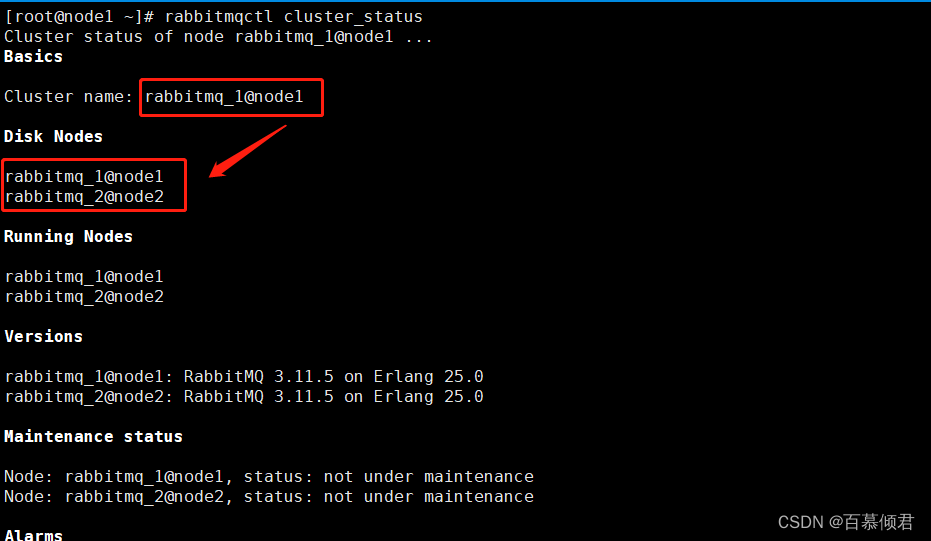
2.关闭node1节点rabbitmq应用服务,同时将node3和node2组成集群。
[root@node1 ~]# rabbitmqctl stop_app
Stopping rabbit application on node rabbitmq_1@node1 ...
node1离线,是剩下node2正常运行。
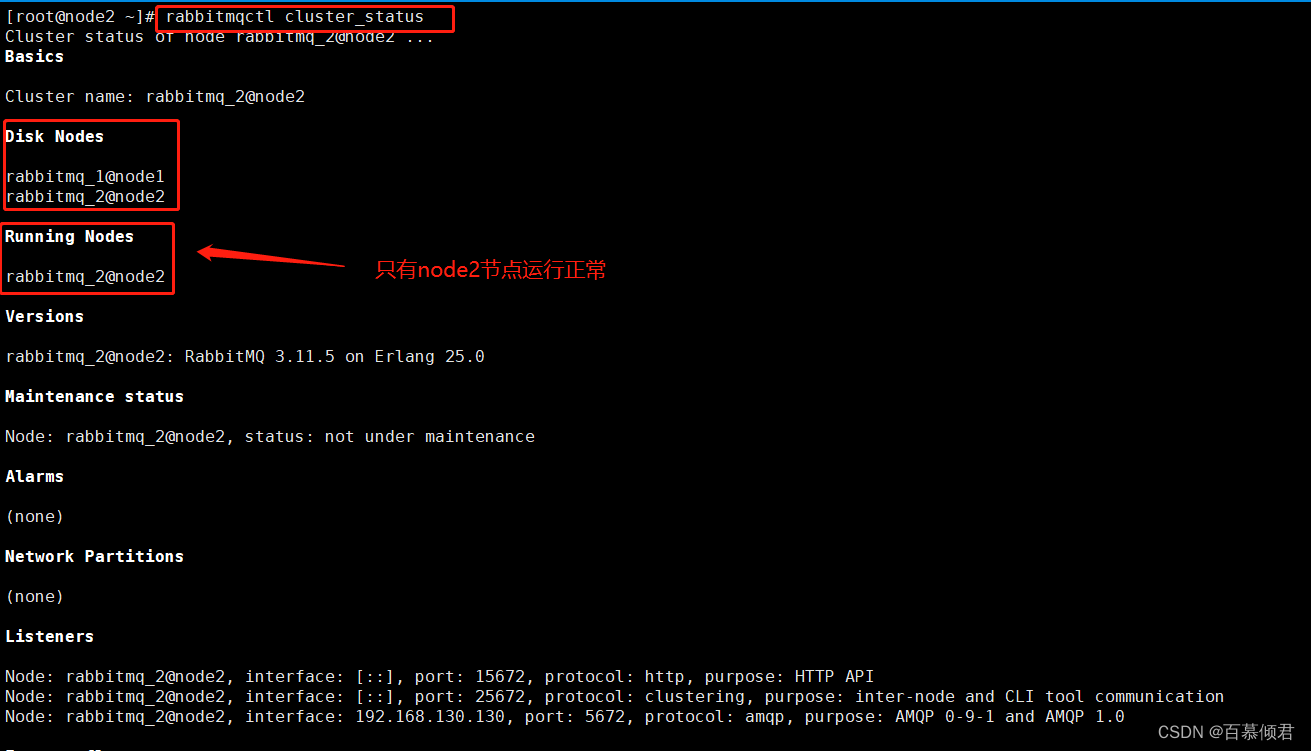
#启动node3服务。
[root@node3 data]# rabbitmq-server -detached
#停止node3服务应用。
[root@node3 data]# rabbitmqctl stop_app
Stopping rabbit application on node rabbitmq_3@node3 ...
#重置node3节点。
[root@node3 data]# rabbitmqctl reset
Resetting node rabbitmq_3@node3 ...
#将node3与node2节点组成集群。
[root@node3 data]# rabbitmqctl join_cluster rabbitmq_2@node2
Clustering node rabbitmq_3@node3 with rabbitmq_2@node2
#启动ndoe3服务应用。
[root@node3 data]# rabbitmqctl start_app
Starting node rabbitmq_3@node3 ...
集群中存在node1、node2、node3节点,但是只有node2和node3正常运行。

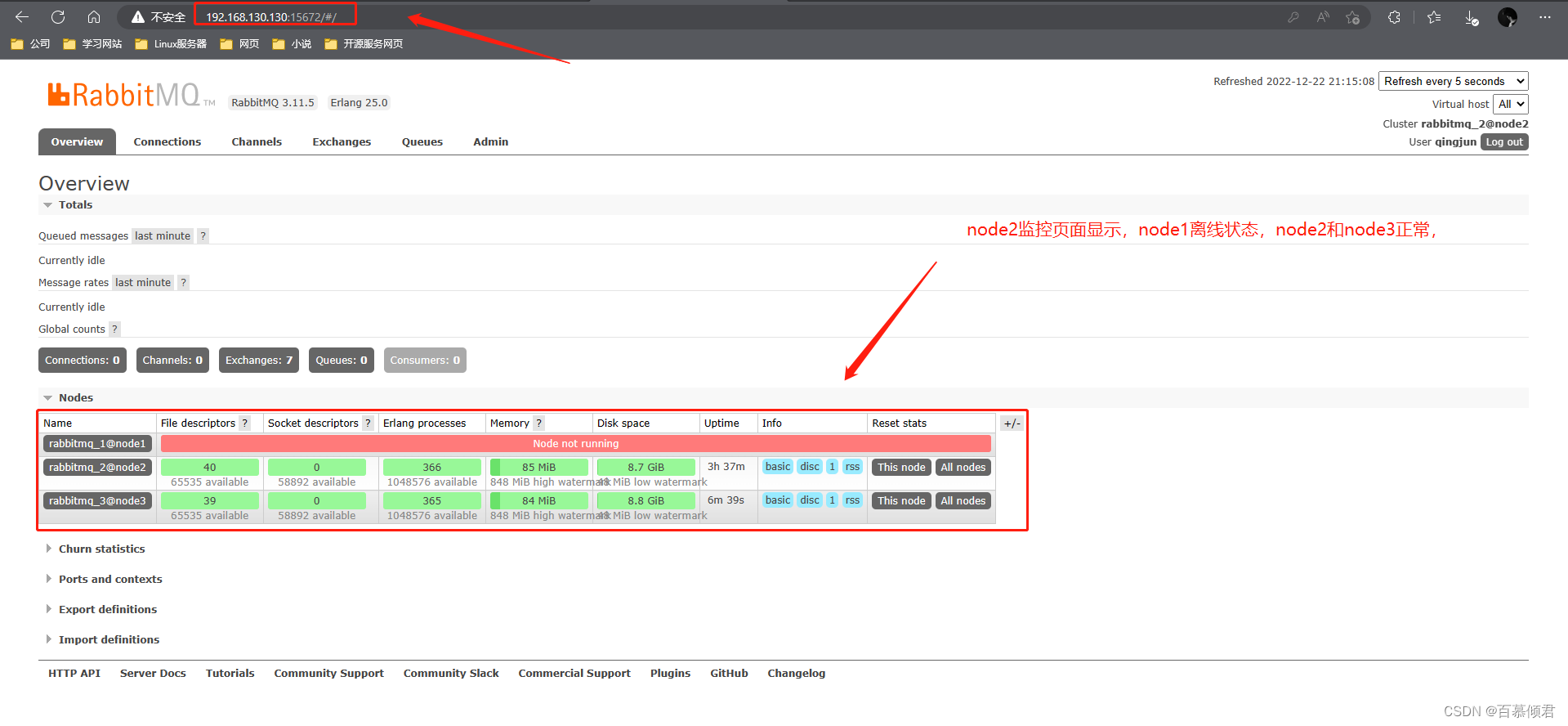
3.关闭node2节点rabbitmq应用服务,同时启动node1节点应用服务,查看集群状态。
[root@node2 ~]# rabbitmqctl stop_app
Stopping rabbit application on node rabbitmq_2@node2 ...
关闭node2节点应用服务后,在node3上查看集群状态,只有node3运行正常。

此时再去启动node1应用服务会发现一直卡着,日志中显示一直尝试联系node2,但此时node2节点是出于离线状态。所以当前集群中只有node3是正常运行的。

4.在node1节点上执行询问命令,询问集群中正常运行的节点node3,并更新信息。
[root@node1 ~]# rabbitmqctl update_cluster_nodes rabbitmq_3@node3

5.node1询问最新信息并更新后,才能正常启动应用服务。
[root@node1 ~]# rabbitmqctl start_app
Starting node rabbitmq_1@node1 ...

此时去查看node1的监控界面,node1、node3节点正常运行,node2还是离线中。

6.最后可以正常启动node2应用服务,集群恢复。
[root@node2 ~]# rabbitmqctl start_app
Starting node rabbitmq_2@node2 ...

3.1.5 无条件启动正在等待最后关闭节点启动的节点
命令格式:rabbitmqctl force_boot
适用情景:
- 当整个集群都掉电,此时所有节点都认为它不是最后一个关闭的。在这种情况下,可以调用 rabbitmqctl force boot 命令,这就告诉这个节点可以无条件地启动节点,不需要再等待那个最后停止运行的节点。
- 确保节点可以启动,即使它不是最后一个关闭的节点。
- 在此节点关闭后,集群的任何变化,它都会丢失。
- 如果最后一个关闭的节点永久丢失了,那么需要优先使用rabbitmqctl forget_cluster_node {要踢出的节点} --offline 命令,因为它可以确保镜像队列的正常运转。
演示操作可以参考上一章节。
3.1.6 修改集群节点名称
命令格式:rabbitmgctl set_cluster_name {name}
- 老版本的一个命令,现在基本用不上,是用来修改节点集群设置集群名称。以前集群名称默认是集群中第一个节点的名称,通过这个命令可以重新设置。
1.修改前

2.修改后
[root@node1 ~]# rabbitmqctl set_cluster_name rabbitmq_1@qingjun
Setting cluster name to rabbitmq_1@qingjun ...

3.2 API接口工具
- RabbitMQ Management 插件不仅提供了 Web 管理界面,还提供了 HTTP API 接口来方便调用。比如创建一个队列,就可以通过PUT方法调用/api/queues/vhost/name接口来实现。
- 但是单纯地使用 curl 的方式来调用比较麻烦,官方就推出了rabbitmgadmin 。
- rabbitmgadmin也是 RabbitMQ Management 插件提供的功能,它会包装 HTTP API 接口,使其调用显得更加简洁方便。
3.2.1 安装rabbitmqadmin
- 之前版本的sbin目录下会有rabbitmqadmin,但是它依赖python3环境。现在高版本已经将它移除,需要下载移到这个目录下才能适用。
- python3高版本对openssl版本也有要求,我这里升级到1.1.1k版本。
- python3高版本依赖较多,我使用的是阿里云的yum源,测试没问题。

- 访问地址:IP:15672/cli,下载rabbitmqadmin文件。

2. 上传至rabbitmq安装目录下的sbin目录,并修改权限为777。
[root@node3 sbin]# chmod 777 rabbitmqadmin

3.下载yum源,安装依赖环境。
python3依赖较多,我使用的是阿里云的yum源。阿里云yum源地址
#确保/etc/yum.repos.d目录下的yum不能冲突,若之前有使用其他的源,需要提前备份再下载yun源。
[root@node3 yum.repos.d]# wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
[root@node3 yum.repos.d]# sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
[root@node3 yum.repos.d]# yum clean all
[root@node3 yum.repos.d]# yum makecache
#更新下。
[root@node3 yum.repos.d]# yum update
#安装依赖环境。
[root@node3 yum.repos.d]# yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make
4.下载python3的源码包,解压编译。python官网
[root@node3 backup]# ll
-rw-r--r-- 1 root root 26044345 Dec 23 11:56 Python-3.10.9.tgz
#创建安装目录。
[root@node3 Python-3.10.9]# mkdir /usr/local/python3
#解压,编译安装。
[root@node3 backup]# tar zxf Python-3.10.9.tgz -C ../
[root@node3 backup]# cd ../Python-3.10.9/
[root@node3 Python-3.10.9]# ./configure --prefix=/usr/local/python3

5.修改python3安装目录下Modules/Setup文件内容,指定ssl地址,不然到时候即使python3环境即使安装成功了也会影响rabbitmqadmin的使用。
[root@node3 Modules]# pwd
/opt/Python-3.10.9/Modules
[root@node3 Modules]# vim Setup
......
#这几行取消注释,指定ssl路径为/usr/local/ssl,主要是要能读取其目录下的include里的东西。
OPENSSL=/usr/local/ssl
_ssl _ssl.c \
-I$(OPENSSL)/include -L$(OPENSSL)/lib \
-lssl -lcrypto


- 不修改,即使编译安装成功,也会影响使用。


- 安装
[root@node3 Python-3.10.9]# make && make install

- 这时,安装成功才可以正常使用。

7.测试rabbitmqadmin,能正常使用。
3.3.2 查看所有用户
命令格式:rabbitmqadmin list users
[root@node3 Python-3.10.9]# rabbitmqadmin list users
+---------+--------------------------------+--------------------------------------------------+---------------+
| name | hashing_algorithm | password_hash | tags |
+---------+--------------------------------+--------------------------------------------------+---------------+
| guest | rabbit_password_hashing_sha256 | jAq4X6dB2I7vv8ulTJf4QNgiHkATdJ3ZJHWOtjFBi/S4YR5n | administrator |
| qingjun | rabbit_password_hashing_sha256 | 781RJ2iS9kWNpL69+KuhT5NXvq+h/lvFYjguJJ0Ml0UaQHan | administrator |
+---------+--------------------------------+--------------------------------------------------+---------------+

3.3.3 查看所有用户角色
命令格式:rabbitmqadmin list users name tags
[root@node3 Python-3.10.9]# rabbitmqadmin list users name tags
+---------+---------------+
| name | tags |
+---------+---------------+
| guest | administrator |
| qingjun | administrator |
+---------+---------------+

3.3.4 查看所有交换器
命令格式:rabbitmqadmin list exchanges
[root@node3 Python-3.10.9]# rabbitmqadmin list exchanges
+--------------------+---------+
| name | type |
+--------------------+---------+
| | direct |
| amq.direct | direct |
| amq.fanout | fanout |
| amq.headers | headers |
| amq.match | headers |
| amq.rabbitmq.trace | topic |
| amq.topic | topic |
+--------------------+---------+

3.3.5 查看所有队列
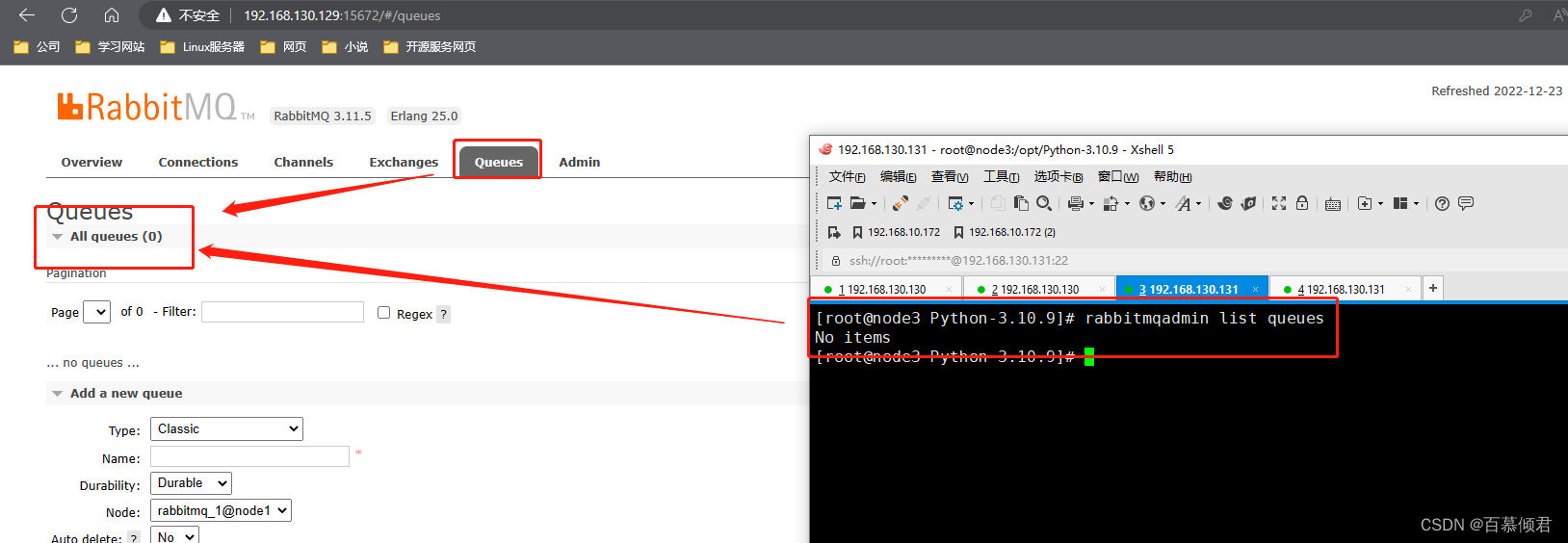
命令格式:rabbitmqadmin list queues
[root@node3 Python-3.10.9]# rabbitmqadmin list queues
No items
3.3.6 创建队列
命令格式:rabbitmqadmin declare queue name={队列名称} [durable=true]
- durable可选参数,true代表持久化打开。
[root@node3 Python-3.10.9]# rabbitmqadmin declare queue name=baimu durable=true
queue declared

3.3.7 创建交换器
命令格式: rabbitmqadmin declare exchange name={交换器名称} type={fanout/direct/topic/headers}
[root@node3 Python-3.10.9]# rabbitmqadmin declare exchange name=qingjun_exchange type=fanout
exchange declared

3.3.8 定义一个binding
命令格式: rabbitmqadmin declare binding source={交换器名称} destination={队列名称} routing_key={自定义绑定键名称}
[root@node3 Python-3.10.9]# rabbitmqadmin declare binding source=qingjun_exchange destination=qingjun routing_key=first_keys
binding declared

3.3.9 命令大全
命令释义命令 解释rabbitmqadmin list users查看所有用户 Userrabbitmqadmin list users name查看所有用户名 Usernamerabbitmqadmin list users tags查看所有用户角色rabbitmqadmin list vhosts查看所有虚拟主机rabbitmqadmin list connections查看所有连接rabbitmqadmin list exchanges查看所有路由交换器rabbitmqadmin list bindings查看所有路由与队列的关系绑定 Bindingrabbitmqadmin list permissions查看所有角色的权限 Permissionrabbitmqadmin list channels查看所有通道 Channelrabbitmqadmin list consumers查看所有消费者 Consumerrabbitmqadmin list queues查看所有消息队列 Queuerabbitmqadmin list nodes查看所有节点 Noderabbitmqadmin show overview概览 Overviewrabbitmqadmin list bindings source destination_type destination properties_key查看所有路由与队列的关系绑定的详细信息 Bindingrabbitmqadmin declare queue name=qingjun durable=true定义一个队列queue,durable=true代表持久化打开。rabbitmqadmin declare exchange name=qingjun.fanout type=fanout定义一个Fanout路由rabbitmqadmin declare exchange name=qingjun.direct type=direct定义一个Direct路由rabbitmqadmin declare exchange name=qingjun.topic type=topic定义一个Topic路由rabbitmqadmin declare binding source=qingjun.fanout destination=qingjun routing_key=first定义 bindingrabbitmqadmin publish routing_key=qingjun payload=“hello world”发布一条消息rabbitmqadmin publish routing_key=my.test exchange=my.topic payload=“hello world”使用路由转发消息rabbitmqadmin get queue=test requeue=true查看消息,不消费rabbitmqadmin get queue=test requeue=false查看消息,并消费rabbitmqadmin purge queue name=test删除队列中的所有消息rabbitmqadmin delete queue name=hello删除消息队列 Queuerabbitmqadmin delete user name=test删除用户 Userrabbitmqadmin delete exchange name=test删除路由器 Exchangerabbitmqadmin delete binding source=‘kk’ destination_type=queue destination=test properties_key=test删除路由器与消息队列的关系绑定 Bindingrabbitmqadmin -f raw_json list usersraw_json 格式化输出rabbitmqadmin -f long list users格式化输出rabbitmqadmin -f pretty_json list userspretty_json 格式化输出rabbitmqadmin -f kvp list users格式化输出rabbitmqadmin -f tsv list users格式化输出rabbitmqadmin -f table list userstable 格式化输出rabbitmqadmin -f bash list usersbash 格式化输出
版权归原作者 百慕倾君 所有, 如有侵权,请联系我们删除。