
文章目录
前言
JVM 的定位 和 多线程进阶 是一样的,都是 “八股文”。
我们学习它的唯一目的:就是为了应付面试.换句话来说:
在实际工作中,基本不会用到本章节学习的知识。
JVM
本文主要讲解的重点:
1、JVM 内存区域划分
2、JVM 类加载机制
3、JVM 的垃圾回收 【重点】实话说:学习这些东西,对我们的日常工作,没有任何帮助!
除非,你的工作就是开发 JVM 的。
但是呢,开发 JVM 是 C++ 程序员干的事请。
因为我们 Java 底层代码的实现几乎都是基于 C 和 C++ 来实现的。
因此,开发 JVM 这件事,还轮不到我们 Java 程序员。
故:一般情况下,我们java程序员是不需要使用 JVM 内部的东西的。那我们为什么要学?
因为面试要考。有些朋友可能就会产生疑问了:我们又用不到 JVM ,为什么面试要考呢?
大概在10多年前,面试是没有考 JVM 的。
之所以 现在的面试都会考,是因为 一本书!
其实很多东西成为了面试题,不是因为它对于工作帮助非常大。
而是因为一个字:卷!
正是因为我们中国人太卷了!
因此,卷着卷着,就卷出了一些更难的问题!因此,不难想象:在未来的圈子里,一定还会出现更卷的东西!类似于 八股文 这样的东西。
1、JVM 内存区域划分
JVM 运行时数据区(内存区域划分)
JVM 运行时数据区域也叫内存布局,但需要注意的是:它和 Java 内存模型(Java Memory Model,简称JMM)完全不同,属于完全不同的两个概念,
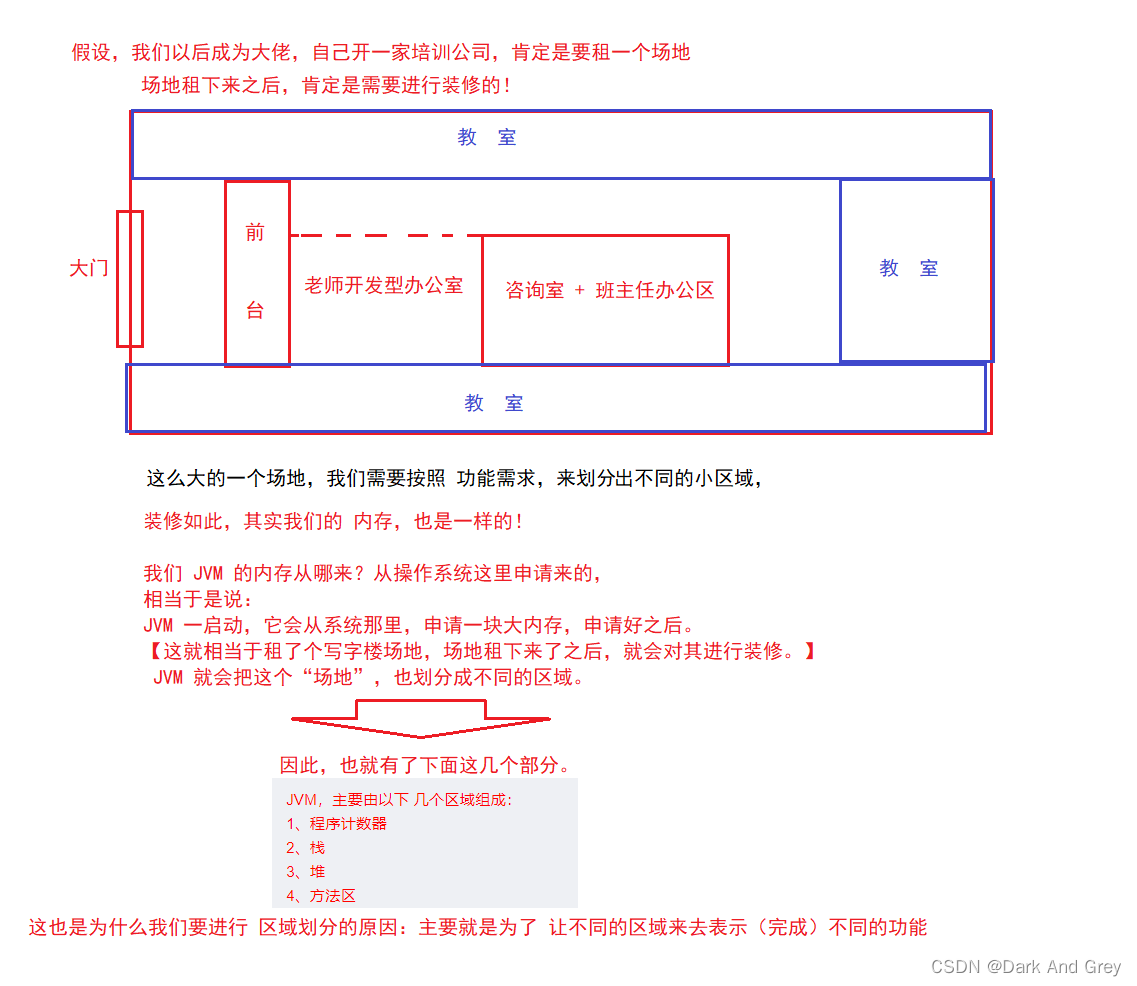
JVM,主要由以下 几个区域组成:
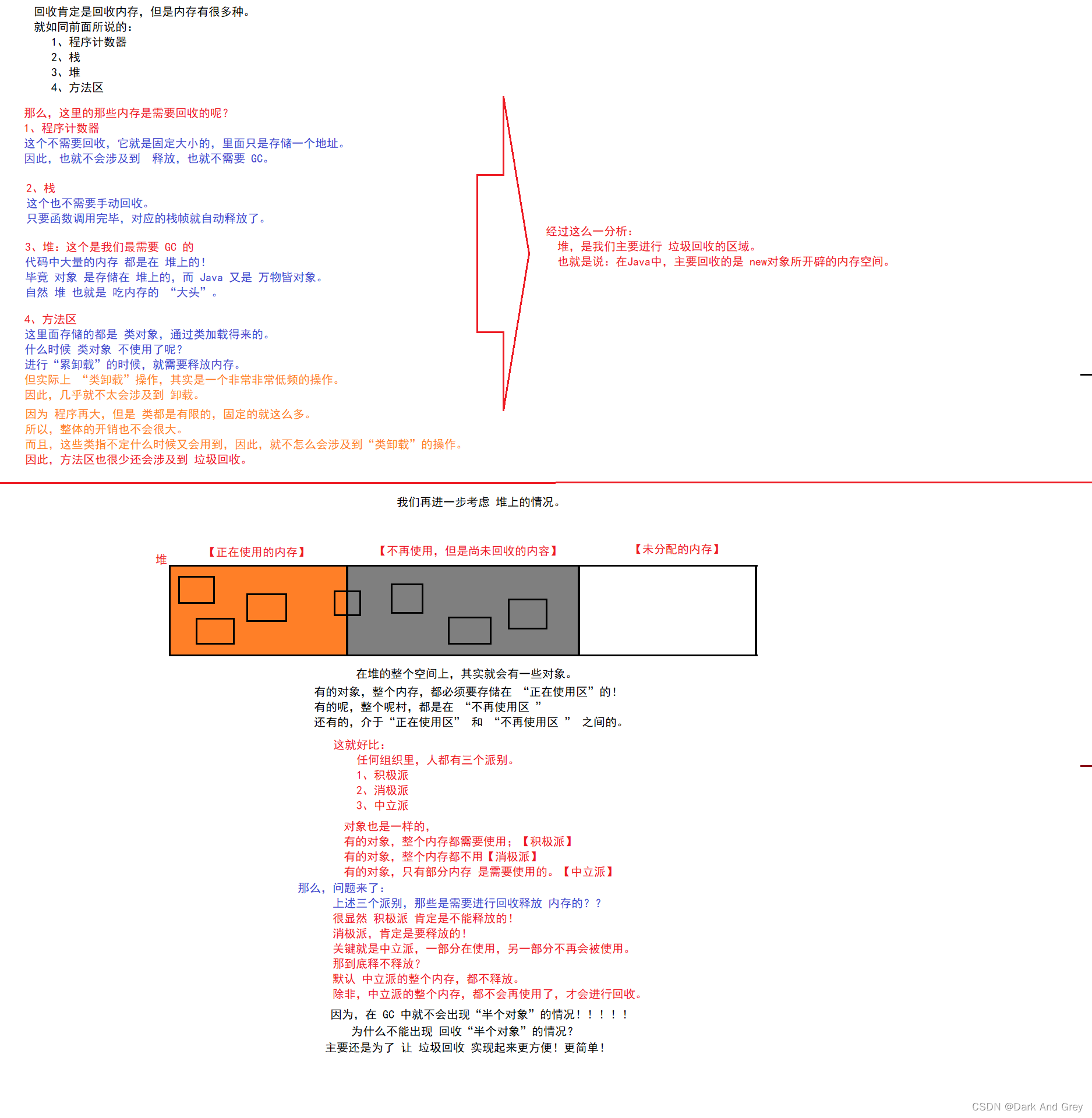
1、程序计数器
2、栈
3、堆
4、方法区这里就有一个问题:为什么要划分出这些区域?
其实,很是很好理解的!
举个例子:
假设我们买了个房子,或者租了一个房子,房子到手,肯定是需要装修的,对不对!
1、程序计数器
程序计数器,这个区域在内存中是最小的一块。
其作用:就是保存了下一条执行的指令的地址在哪。
大家要明确:
指令,就是字节码(就编译产生的字节码文件【后缀 .class】)
程序 要想运行,JVM 就得把 字节码文件 加载起来,放到内存中。
相当于:这些指令都被放在内存中了。放到内存中之后
程序就会把一条条指令,从内存中取出来,放到 CPU 上执行。
也就是说:有一个执行的过程。既然有一个执行的过程,也就需要随时记住,当前执行到哪一条指令了。
另外,再补充一点:
正因为操作系统是以线程为单位进行调度执行的,每个线程都需要记录自己的执行位置。
因此,程序计数器,每个线程都会有一个。需要注意的是:这个东西(程序计数器),我们在编写代码的过程中,是感知不到的。
但是它切切实实存在的!
能够帮助我们的程序进行运行。
比如:
你想把 程序计数器 取出来,看看里面存的是什么?
对不起,我们是做不到!
但是,并不会影响到 它的存在,也不会影响到它的工作流程。

2、栈
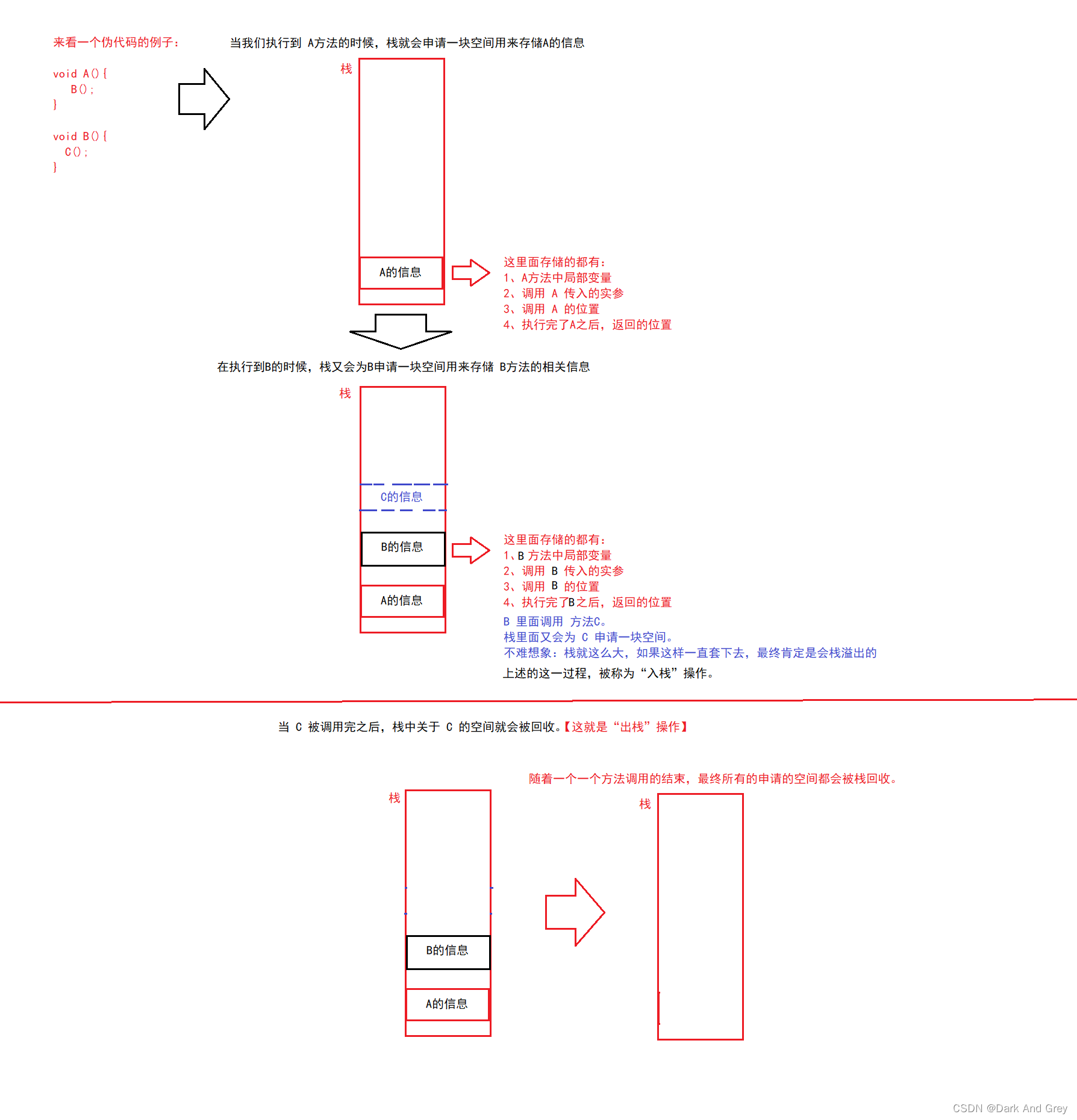
栈里面存储的是:
1、局部变量
2、方法调用信息当我们进行方法调用的时候,每次调用一个新的方法,都会涉及到“入栈”操作。
每次执行完了一个方法,都会涉及到“出栈”操作
需要注意的是:
这里说的栈,虽然值得是 JVM 内存中的一个部分。
但是这里的工作过程是和数据结构中的栈,非常类似的。然后,每个像 方法A 和 B,这样的元素,我们给它起了一个名字。
叫做:栈帧像 idea 在 测试 / 程序抛异常 的时候,它都能让我们看到 当前的调用栈信息。
调用栈信息:方法之间都是怎么调用过来的
这个过程就是靠读取上述的 栈 空间中的数据。就相当于是 JVM,或者说是 idea,这些 调试器,读取了栈里面的信息,然后把信息给我们打印一下。此时,我们就能够看到里面的内容了。
每个栈帧里面,数据是如何排列的,也有一些规则。
入栈,出栈操作,具体是怎么实现的,里面也有一些技巧和细节。
由于我们是 java 方向的,因此本文不做过多介绍。
不过,你们可以参考这篇C语言的[函数栈帧](https://blog.csdn.net/DarkAndGrey/article/details/119826033?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165643327916780357282733%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=165643327916780357282733&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-4-119826033-null-null.article_score_rank_blog&utm_term=%E5%87%BD%E6%95%B0&spm=1018.2226.30 01.4450)
但是! 隔壁 C++ 他们会详细研究这个。在讲的时候,我们说到过:如果一直这样一个方法调用另一个方法,就会在栈上开辟一块有一块的空间,最终就会导致 栈溢出【Stack Overflow】
这是因为 栈的空间,确实比较小。
在 JVM 中可以配置 栈空间的大小,但是一般也就是 几 M 到 几十 M。
栈就这么大,因此栈是很有可能会溢出的!如果你正常写代码,一般是没有事的。
但是!就怕你使用递归,还没有终止条件,它就会一直递归调用方法。
因此,最可能出现 栈溢出 的问题,就是 递归。
3、堆
堆,也是我们最常使用的一块空间。
堆 与 前面讲的 栈 和 程序技术器,不一样!
栈 和 程序计数器,是每一个线程都有一份的。但是!堆 是 一个进程 只有一份,多个线程共用一个堆。
因此,堆也是 JVM内存中 所占空间最大的区域。那么,堆里面主要存储一些什么数据呢?
1、new 出来的对象,就是在堆中
2、对象的成员变量,自然也就在 堆中。另外,堆 与 栈 的资源开销都是特别大的。
栈上开辟一块空间的速度是非常快的。只需要简单改一个计算器的值,进行一个加减法就行了。
而在 堆上 开辟一块内存,就挺麻烦的。
它就需要去操作 系统内核中的一些重要的数据结构。
因此,在堆上开辟空间的开销要更比栈更大一些。
在这里,我们不作过多的讨论。
我们只需要知道:堆的空间比较大,但是操作速度比栈更慢一点。另外,再补充一点。
网上有一种说法:
内置类型的变量,在栈上
引用类型的变量,栈堆上
思考一个问题:这种说法是否正确?
这显然是一个非常错误的说法!!!
正确的说法:
局部变量,在栈上
成员变量 和 new 的对象,在堆上。
大家要明确:
我们的变量,到底是在栈上,还是堆上;和你是不是 内置类型 和 引用类型 无关!
也就是 变量的类型,并不会影响 变量 存储的位置。真正影响变量存储位置的原因: 主要在于 变量 是以 局部变量 形态 出现,还是以 成员变量出现的。
在读的朋友们,可能还有一些朋友不知道为什么 网上的说法是错误的!
这是因为 我们在 看到 引用类型变量的时候,就会联想到对象。
从而会认为 引用类型的变量 是存储在 堆上的。
其实不是的!下面我们就来分析一下

4、方法区
在方法区中,存储的是 “类对象”
类对象,这个我讲过很多次了。
我们的 . java 文件,经过编译器编译之后,会生成一个 .class 文件(二进制字节码)。
在程序被执行的时候,,class文件 会被 加载到 内存中,也就被 JVM 构造成了类对象。
这个加载的过程,我们称为 “类加载”。这里的类对象,就是放到方法区中。
类对象里面都有哪些东西呢?
类对象就描述了 这个类 “长什么样”:
类的名字是什么,里面都有哪些成员,方法;
以及每个成员的名字叫什么,类型是什么,其修饰词是那个(public/private/protect);
每个方法叫什么名字,是什么类型(public/private/protect),方法里面又有哪些指令。
东西还有多,这里就不列举了。
总之,与类相关的信息,都是在这个类对象里 。另外,再补充一点: 类对象里面还有一个很重要的东西:静态成员。
换句话来说:static 修饰的成员(变量/方法),成为了 “类属性”。
而普通的成员,叫做 “实例属性”。
另外,static单词本身的意思 和 “类属性” 无关!!!
这是一个历史遗留问题,这里就不再讨论。
【PS:我好像在前面的那篇文章中讲到过:反正就是 方便去添加新的功能】
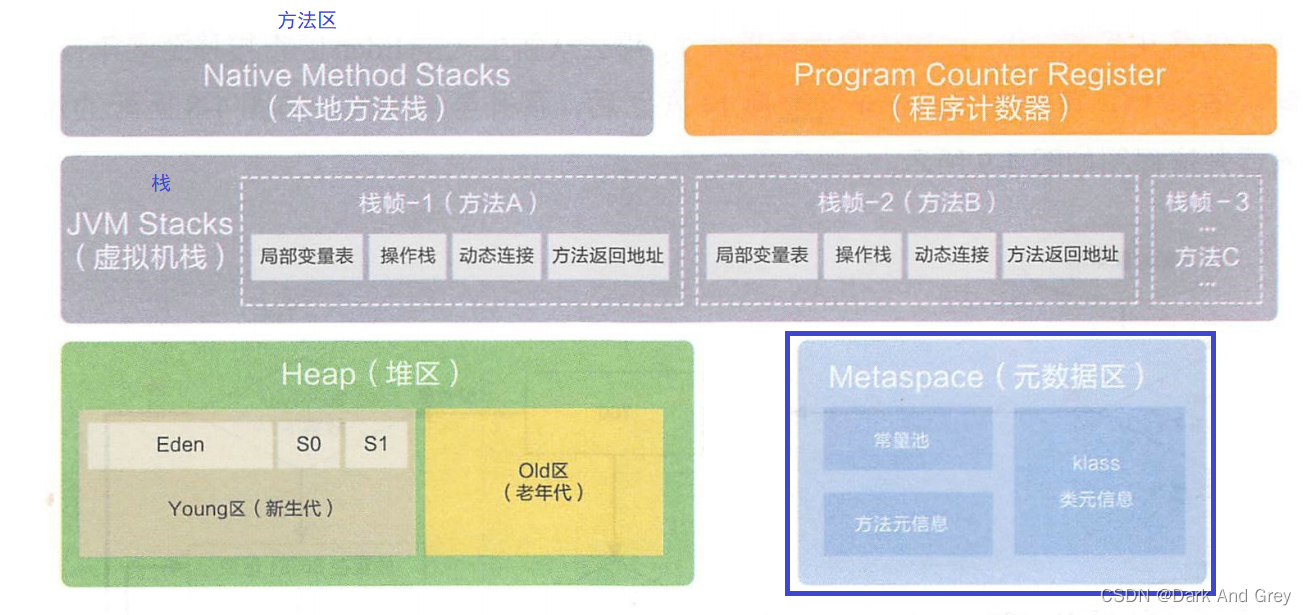
总结: JVM 内存分配总图
这里更详细一些。
多的不再讲,把我前面写的那些,搞清楚就可以了。
至于这里面的有些东西,后面还会在补充图。
比如:
垃圾回收,就会牵扯到 堆里面的东西。另外,上述学习的这个内容区域的划分,不一定是符合实际情况的。
JVM 在实现的时候,具体怎么划分这个区域,不一定完全相同,不同厂商,不同版本的 JVM 实现上可以会存在一些差异。
比如:
上图中的 元数据区,有的 JVM 就没有这一块。
像这里面的常量池,有些 JVM 就可能会把它放在 堆上。
这里就不做深究,除非你是真的要实现一个 JVM,那你课可以继续深究。
我这里就直接略过了。

2、JVM 类加载机制
类加载,其实是设计一个 运行时环境 的 重要的核心功能。
我们这里还是以应付面试为目的!
重点去学习其中的 常见面试题即可。
还是那句话:
JVM 类加载机制,其实是一个大话题。
想要实现 这样的一个运行时环境,像 JVM 这样的一个东西。
要依赖的知识有很多:
1、理解编译器是怎么工作的
2、理解操作系统内核的一些东西
3、理解 CPU 的执行过程
4、还需要对这个语言的语法结构,非常熟悉。
。。。
总之,很麻烦很麻烦!
因此,我们在这里还是简单介绍。
为了面试!cheers!
类加载是干什么的?
把 .class文件,加载到 内存中,然后,构建成类对象
下面,我们来看看 类加载的流程图 / 类的生命周期
参考文献JavaSE的官方文档
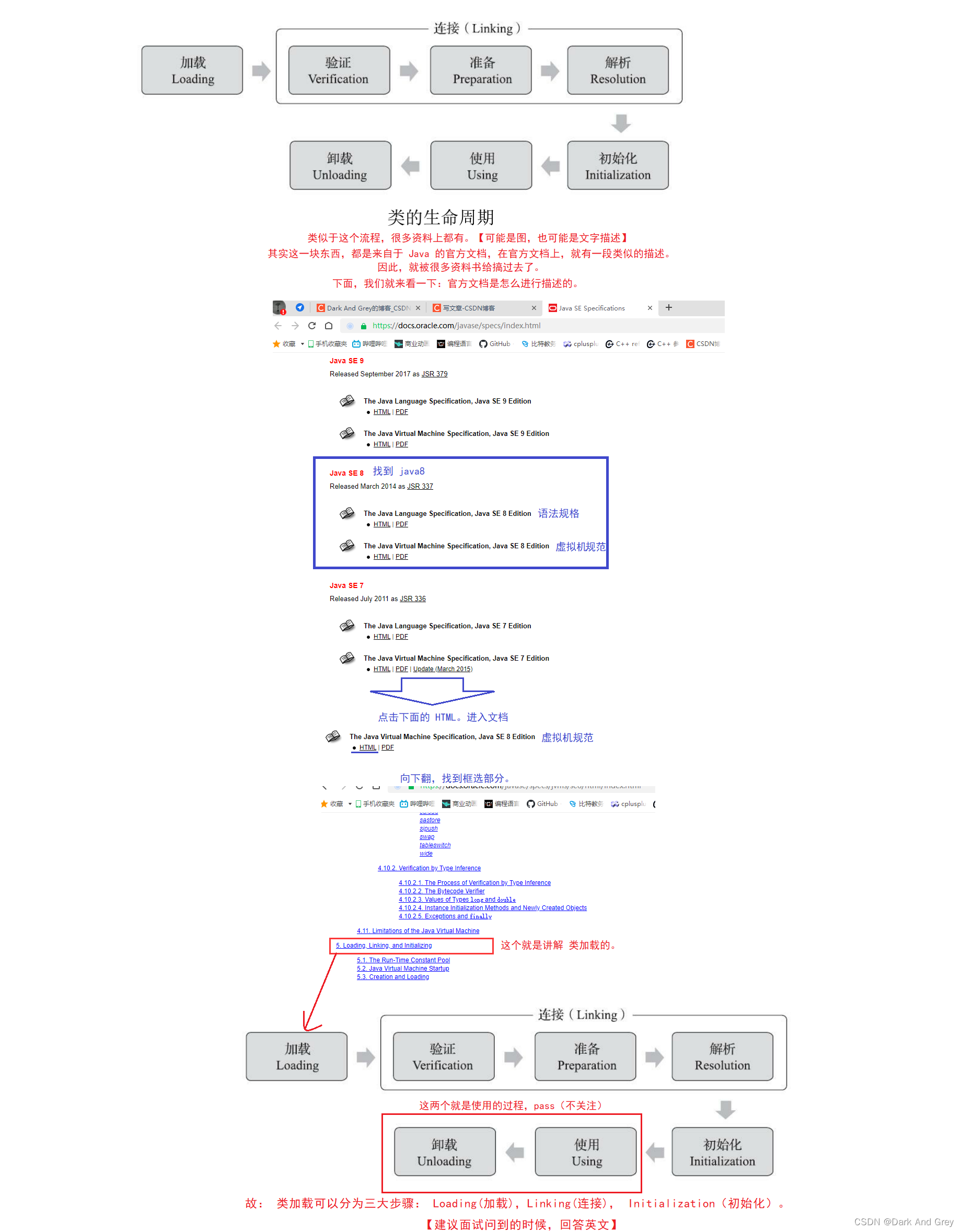
类加载需要经过的几个步骤
1、Loading - 加载
2、Linking - 连接
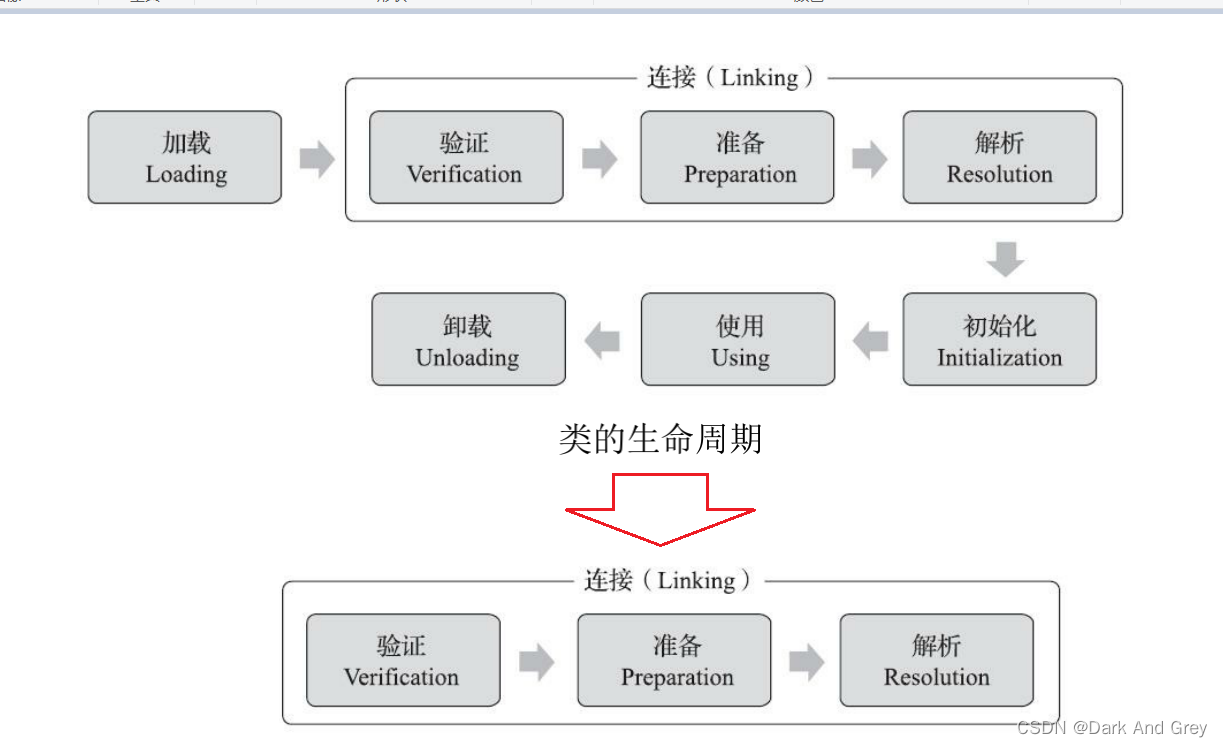
Linking - 连接,一般就是建立好多个实体之间的联系。
这里的实体,你可以暂且理解为 是 类对象 中 常量池中元素的内容。
根据其元素内容(编号),将对应值联系起来。
不仅仅是和 元素结构体,建立关系,更是为了 建立 与 类对象 的关系。
毕竟这些联系起来的数据,最终都是要填入 类对象中的。
3、initialization(初始化)
真正对 类对象 进行初始化,尤其是 针对静态成员。
在前面 Linking 的 preparation(准备)阶段,只是给静态成员分配内存,并给予初始值(默认值),有没有初始化?没有!
此时,就需要根据我们所写的代码,把静态变量后面的表达式进行求值;该去new的,就去new,该执行什么方法,就执行什么方法。
最终完成这样的一个初始化过程。
小结
类加载是把 .class 文件 加载到内存中,生成一个 类对象。
其中徐亚经过 3 个步骤:Loading,Linking,initializationLoading(下载)环节: 对class文件进行读取并解析,生成一个“初步简陋”的类对象。(不完成形态)
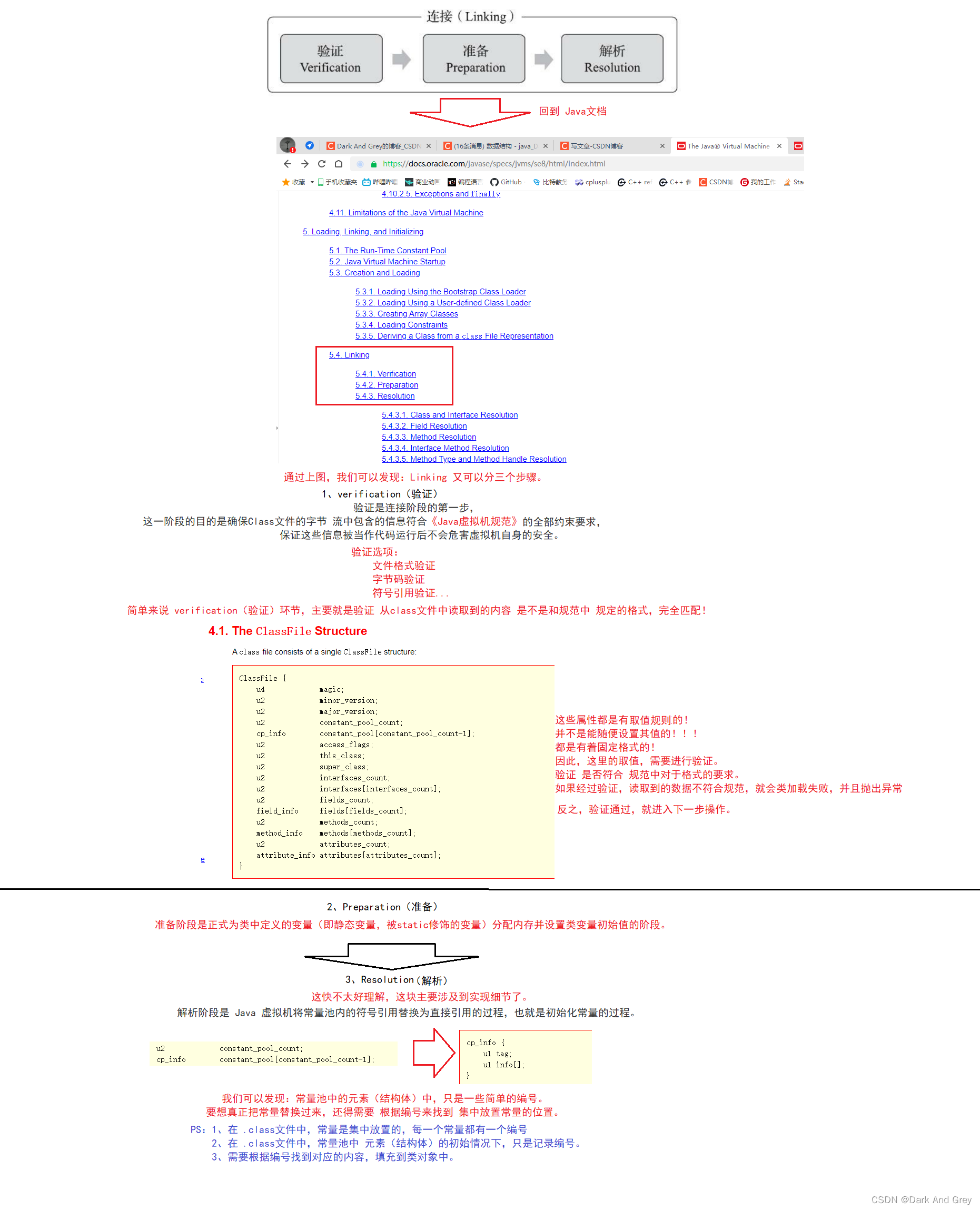
Linking(连接)环节:可以分为三个阶段
Verification(验证):验证 初步生成的类对象 中的数据格式,是否符合 《Java虚拟机规范》中的要求。如果不符合,类加载就会失败,并抛出异常。
反之,通过了验证环节,就会进入下一步。
Preparation(准备):此时,就会针对静态变量进行分配空间,基于 初始值 / 默认值。
resolution(解析):将 常量池的中元素,根据其内容中的编号,找到对应的数据,填入类对象中。
需要注意的是,这里只是分配的空间,找到了对应的数据。
但是还没有进行初始化赋值,只是把数据和内存给准备好了。initialization(初始化):这里才是真正对 静态变量进行初始化赋值
经过上面,这一系列操作,我们就可以得到一个完整的类对象了。
而这个过程,就被称为 类加载。我们学习这块的目的,就是为了 面试 / 笔试 的时候,能够应付一些相关的问题。
大家要能够知道 class文件 最终是如何真正执行起来的。
经典面试题
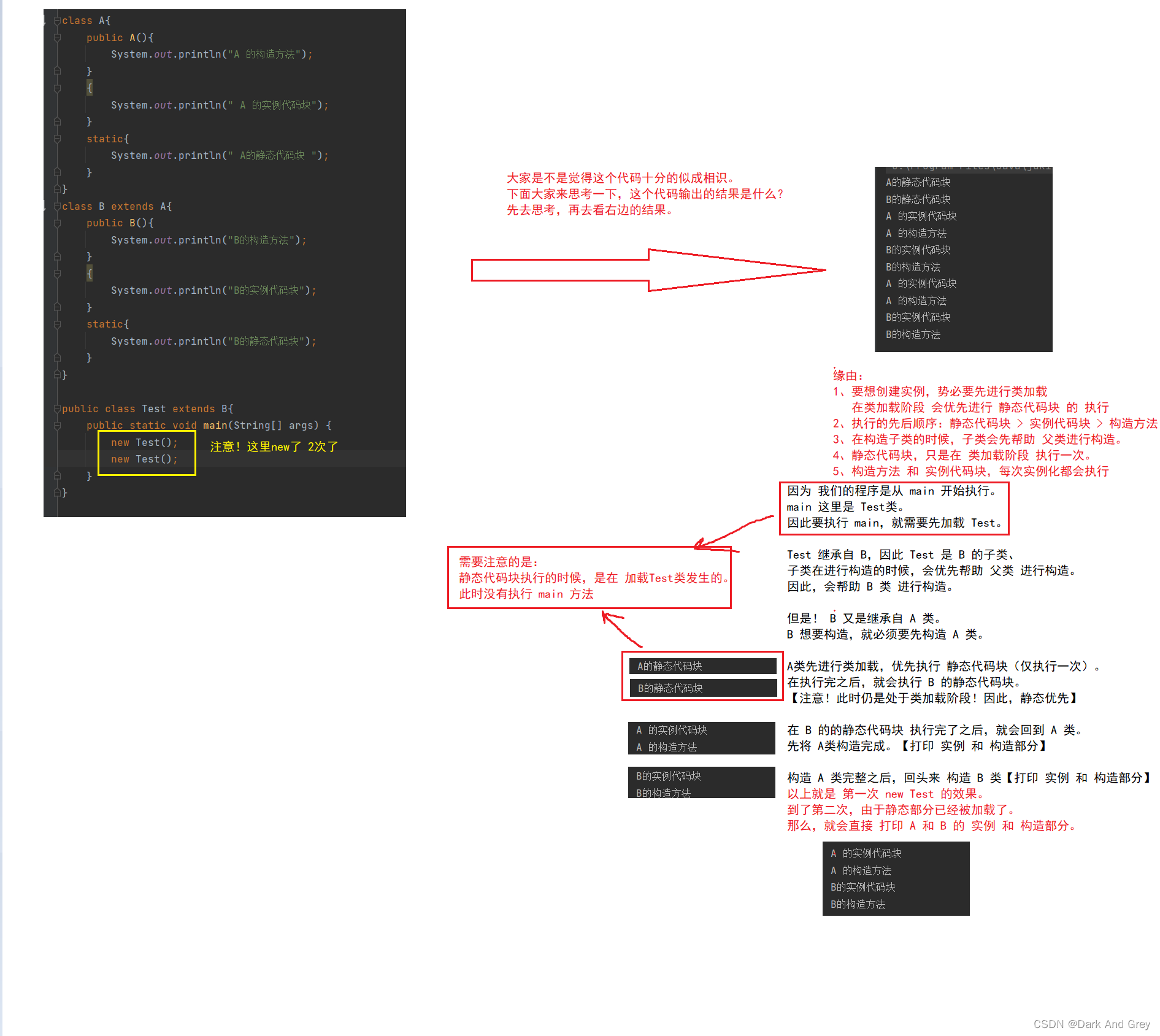
在正式进入面试题讲解之前,我们先来看一个例题。
可以参考[ClassAndObject -类与对象]
大家在做题的时候,一定要认真看!
看这个代码是怎么写的!!!
存在怎样的联系!!!
双亲委派模型
这个!面试特别爱考!!!!
首先,这个东西不重要。
其次,这个东西也不难理解。
再然后,这东西工作中也用不到。
最后,这个东西也没有什么知道意义
那么,为什么还爱考这个呢?
只因为这个东西 有个高大上的名字!!!Java 这个圈子里,是特别喜欢:搞一些 高大上的术语的。
我怀疑 它在 装杯,但是我没有证据!!!
像这样的术语,还有很多!!
比如:
1、自动 拆/装 箱【就是 普通类 与其 对应的包装类 之间,进行的隐式类型转换】
2、Bean
3、IOC,DI,AOP,事务传播机制【spring的内容】
。。。
其实上面的这些东西,并不复杂!理解起来,也并不困难!
但是呢,就喜欢那种 装杯 的感觉。【用一些高大上的名字去表示它们】其实生活中,也有很多这样例子:
1、宫廷玉液酒 – 二锅头 兑 白开水
2、群英荟萃 – 一堆萝卜
。。。。
大家在学习 Java的时候,不要被它的某些词汇给护住了!!!
其实,也就是那样。双亲委派模型,是类加载中的一个环节。
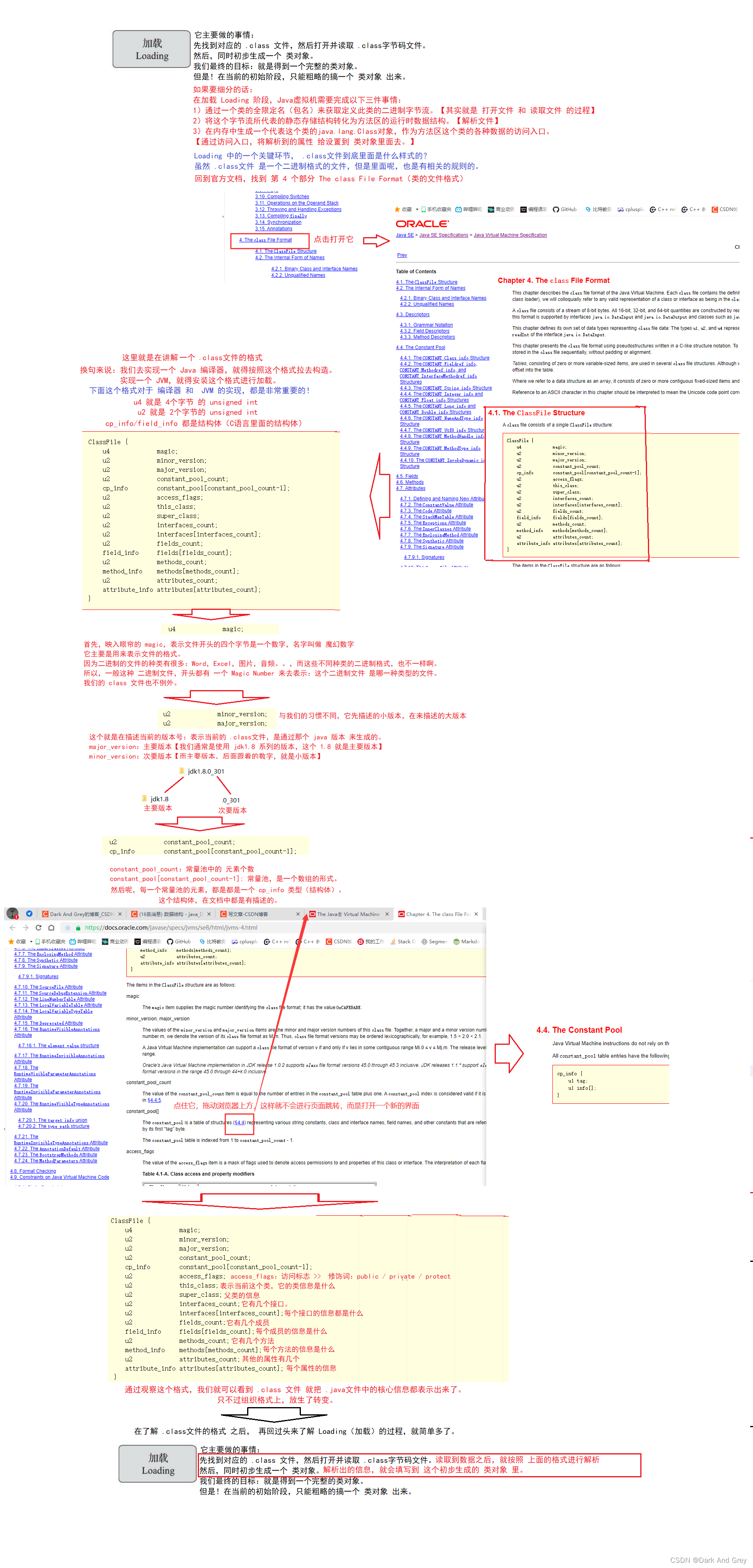
这个环节处于 Loading 阶段 的 比较靠前的部分。Loading环节,主要是先找到对应 class文件,然后打开并读取 class文件,同时初步生成一个类对象。
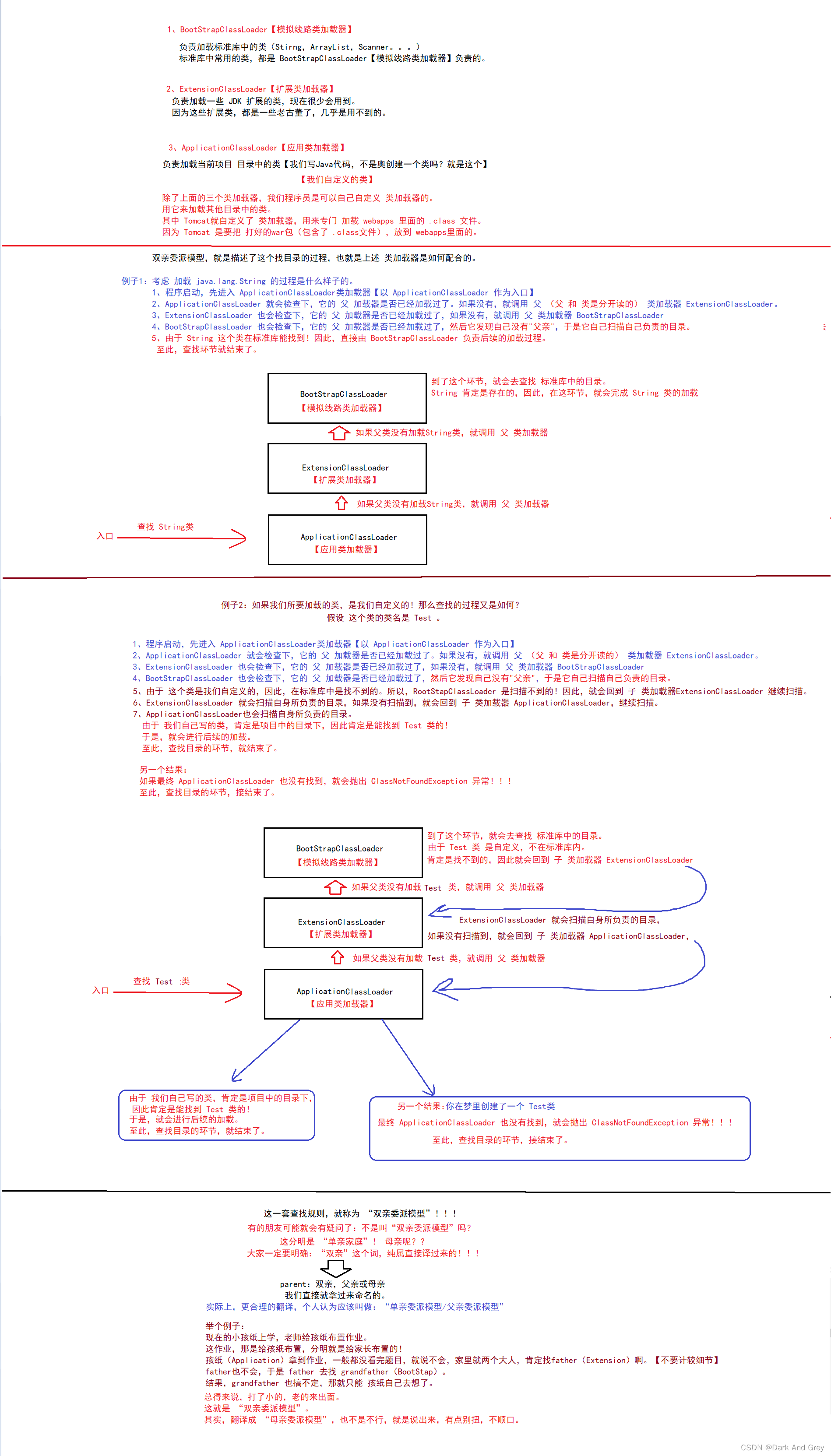
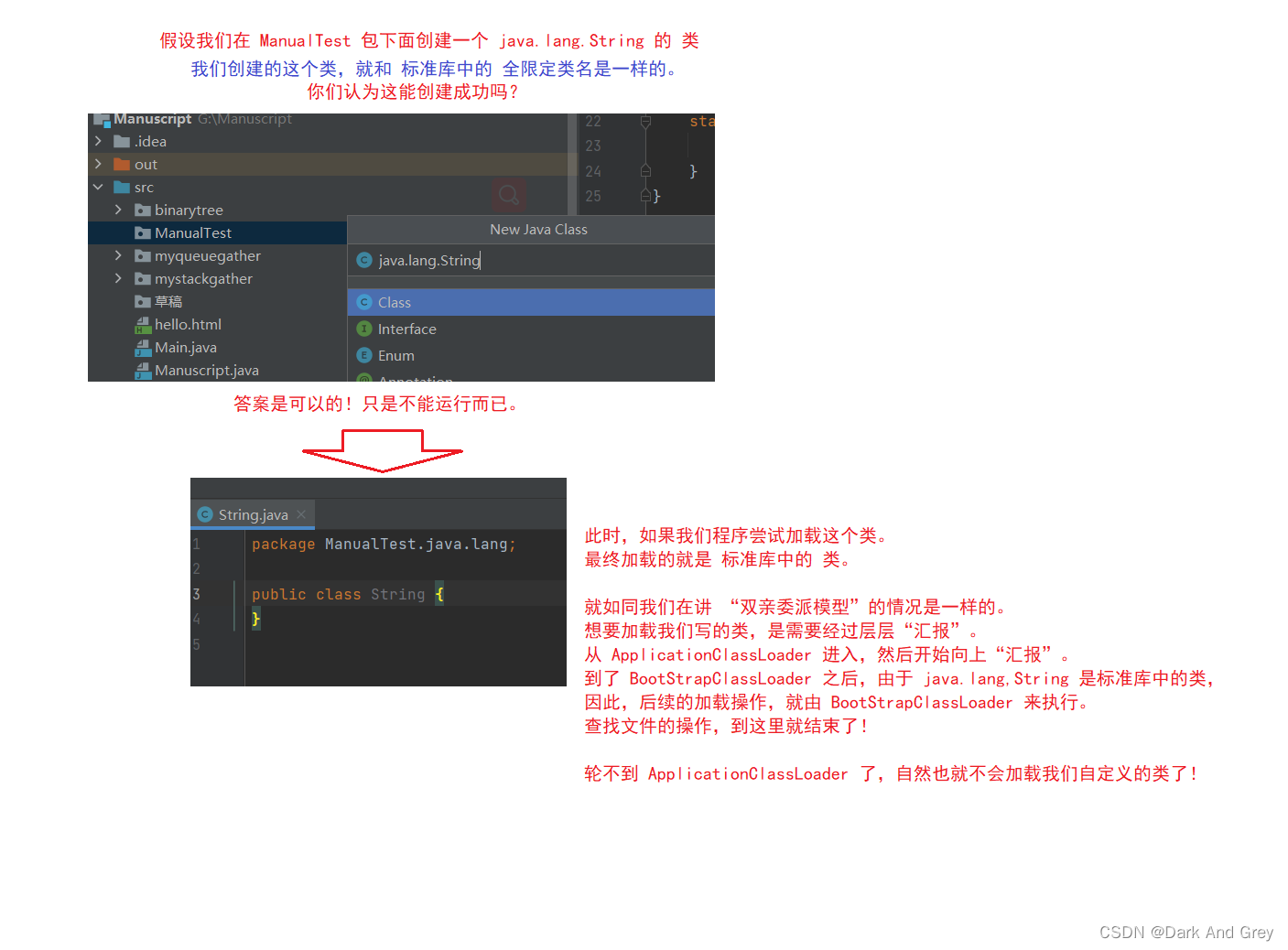
双亲委派模型,它描述的就是:JVM中的类加载器,如何根据类的全限定名(java.lang.String)来找到 .class文件 的过程。
简单来说:双亲委派模型,就是一个找文件的过程。
这个找文件的过程,是一个很小的环节,甚至不属于核心环节。核心环节:解析class文件,构造一个类对象,验证,初始化。。。。这些才是核心环节。
那么,问题来了:具体是怎么去找文件的呢?
在了解找文件的过程之前,我们需要先了解 类加载器。
在 JVM 里 提供了专门的对象,叫做 类加载器。
类加载器,负责进行类加载。
当然找文件的过程也是类加载器负责的。.class 文件,可能放置的位置有很多,有的要放到 jdk 目录里,有的放到项目目录里,还有的在其它特定的位置…
也就是说: .class文件 可以存放的位置有很多。
所以,为了更方便的找到 .class 文件。
于是我们的 JVM 里面提供了 多个类加载器。每个类加载器负责一个片区。
这个类加载亲负责一片区域,那一个类加载负责另一片区域。。。。
简单来说:每个类加载器负责区域是不一样的。默认的类加载,主要与三个:
1、BootStrapClassLoader【模拟线路类加载器】
2、ExtensionClassLoader【扩展类加载器】
3、ApplicationClassLoader【应用类加载器】
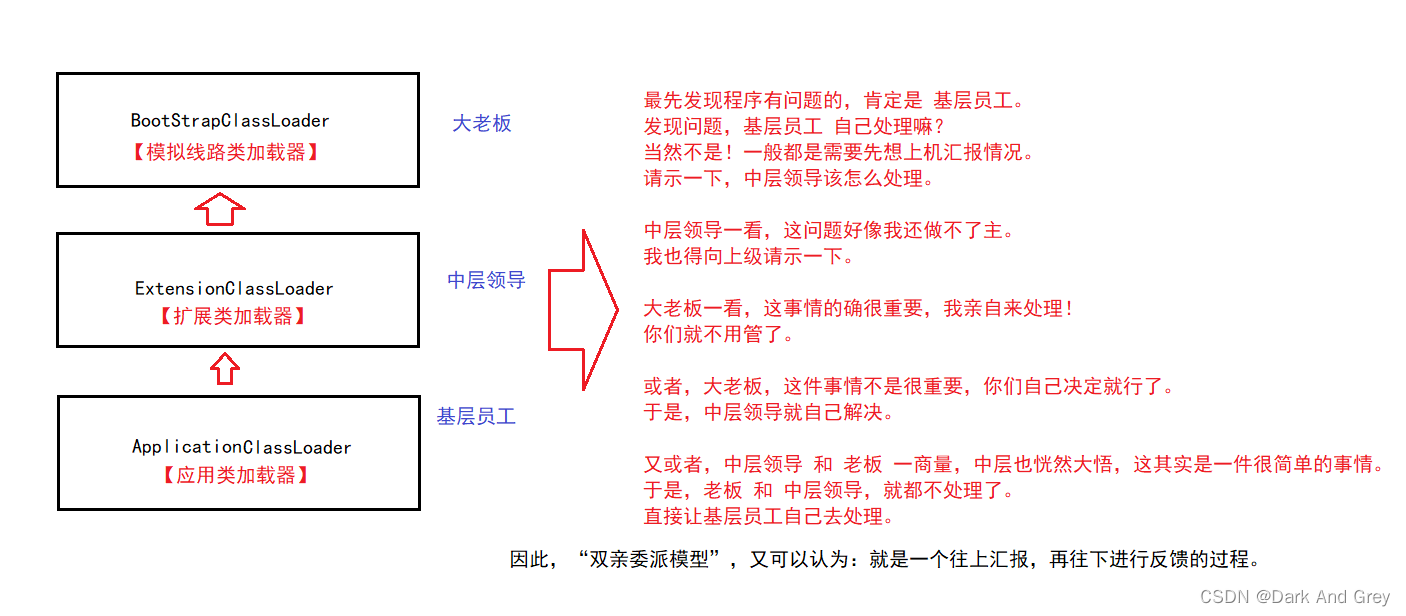
其实,“双亲委派模型” 就跟我们以后在公司工作一样。那么,问题来了:JVM 为什么要这样去设计?
理由就是:
一旦程序员自己写的类,和标准库中某个类的全限定类名重复了,也能够顺利的加载到标准库中的类!!!
其目的,就是为了保证 里面 加载类 的 唯一性。还有一个问题:如果是自定义的类加载器,是否也需要遵守“双亲委派模型”?
可以遵守,也可以不遵守。
主要看实际需求!
比如:
像 Tomcat 加载 webapps 中的类,就没有遵守。
因为遵守了,也没有意义!
毕竟,这里的这些类,都是我们程序员写好了的,自己往上面部署的。
如果 自己 当前这个 专属的类加载器 都找不到,你还能指望 标准库中的类加载器 来找到吗?
不现实!
因为,这些类一定是程序员自己定义的,是绝对不可能出现在 标准库中的!!!
所以,Tomcat 就没有做这个多余的动作!
总结
双亲委派模型,只是 JVM 实现中的 一个小小的规则和细节。
只不过说这个东西,有个好名字,于是才火了。类似的规则和细节,在 JVM 中可以说是非常非常多的!
只不过,在面试中,没有被提到。
名字,可能是一个原因。
更主要的是:程序员 对 JVM 的理解 并不深刻!
3、JVM 的垃圾回收 【重点】
垃圾回收,又称 GC(Garbage collector - 垃圾回收器)
我们写代码的时候,经常会申请内存!!!
那什么时候会申请内存?
1、创建变量
2、new 对象
3、加载库的时候
。。。。。。。
这些操作,都是要去申请内存的。
毕竟,我们程序要想运行,离不开硬件上的支持。
而 内存,又是我们整个计算机中最最关键的硬件设备之一。俗话说得好:有借有还,再借不难。
内存从哪里申请呢?从操作系统申请!
但是 你不能一直占这不放,在你不使用这块内存的时候,是要还给操作系统的!我们一般说:
申请内存的时机,一般都是明确的。
而 释放内存的时期,则不是那么清楚的!!
意思就是说:
思考一下,我们一般什么时候申请内存?
在我们需要保存 某个 / 某些 数据的时候,就需要 申请内存。
那什么时候,释放内存?
当这块内存,我们不用了的时候,才会去释放【回收】。
垃圾回收,就是把我们不需要内存空间给回收。但是!问题来了:什么叫做不用了?如何才能判断这块内存已经不需要了,需要进行 “垃圾回收” ?
这个其实不好判断!
我们来举个例子,来了解这其中的意思。
通过对于 内存释放的问题,我们引出了 Java 的 垃圾回收机制。
并且,该机制在大部分主流的语言中,都应用了。有人可能豁然开朗,怪不得 Java 的算法,执行不是很高效。
其实刷过题的朋友
会发现:在牛客 / LeetCode 上,写算法题的时候,不同的编程语言,对于 时间/空间 的要求是不一样的!
话虽如此,但是在这些语言中,Java 在性能上来说,也是相当能打的。
在执行同一个程序的时候:
java执行的时间,一般是 C++ 的 1.5~2 倍。
两者的执行时间,基本非常接近,甚至有的时候,能打平!
两者之间的关系,就好比 12900 KS 和 12900 之间的差别。
相差甚微,都是天花板级别的。但是!像 Python 这种,特别慢!
慢的时候,可能是 C++ 的 100 倍。(这可能就是一个 赛扬的水平。。。)Go 语言执行速度也很快,但是比 Java 慢不少。
但是 比 Python 快不少。
大概 是 C++ 的 10倍 多吧【说不准。。】
Go的优势在于:语法的简洁。
而 Java 有时候 比较啰嗦。
这也是 Go 火的原因。

通过上述的内容,我们知道了 垃圾回收 是干什么的。
下面,我们就来 看看 Java 的垃圾回收,具体是回收什么“垃圾”。
由上述内容,我们可以得出宇哥结论。垃圾回收机制,主要是回收堆上的对象。
回收的单位是:对象(一个完整的对象)这里再补充一点:
GC 会提高程序员的开发效果,但是降低了 程序自身的运行效率。
那么,这里就会有一个问题:是开发效率重要,还是运行效率重要?
那肯定是 开发效率 更重要!
你这么去想:运行效率低,但是是电脑在工作,不是人。
让电脑多做一些事情,那是应该的。
而且 运行效率低,无非就是 执行时间稍微长一点,就是多耗一点电嘛!
而开发效率低了,不但要加班加点,而且,万一项目没有指定时间开发出来,又会扣奖金。
幸福感 直接反向 拉满!!!
下面我们来看一下,垃圾回收具体是怎么回收的、

找垃圾
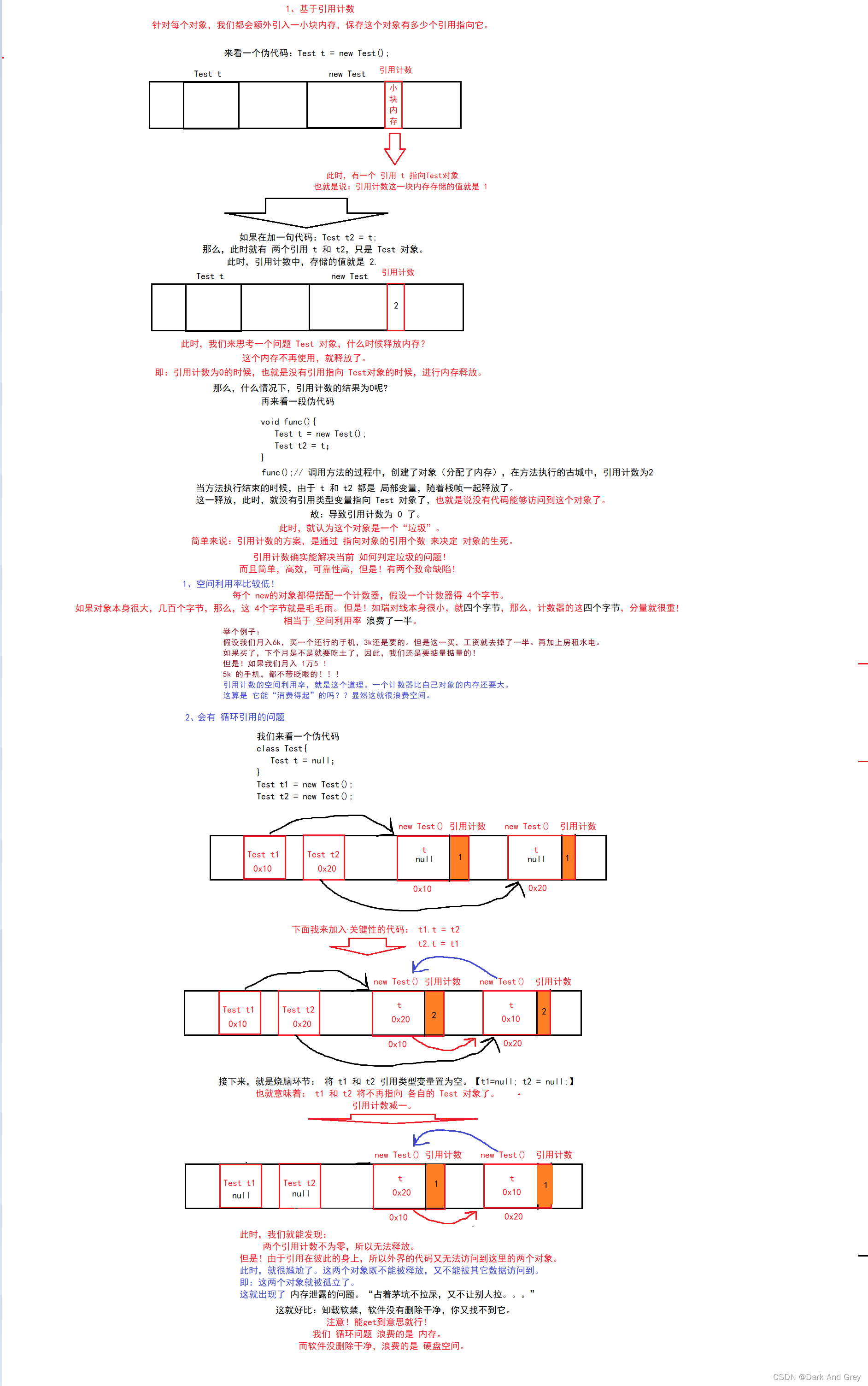
先来看 第一个 垃圾判断方案 : 引用计数
整体来说:
引用计数的方案,确实能够解决问题。
但是 光使用 引用计数,是存在限制的。所以像 Python ,PHP 进行 GC 也不是只考虑 引用计数,还依赖了其它的机制进行配合。
而在 Java中,直接就不使用 引用计数 了!
直接采用的 可达性分析 分析 方案。
这也是下面我们要讲的内容
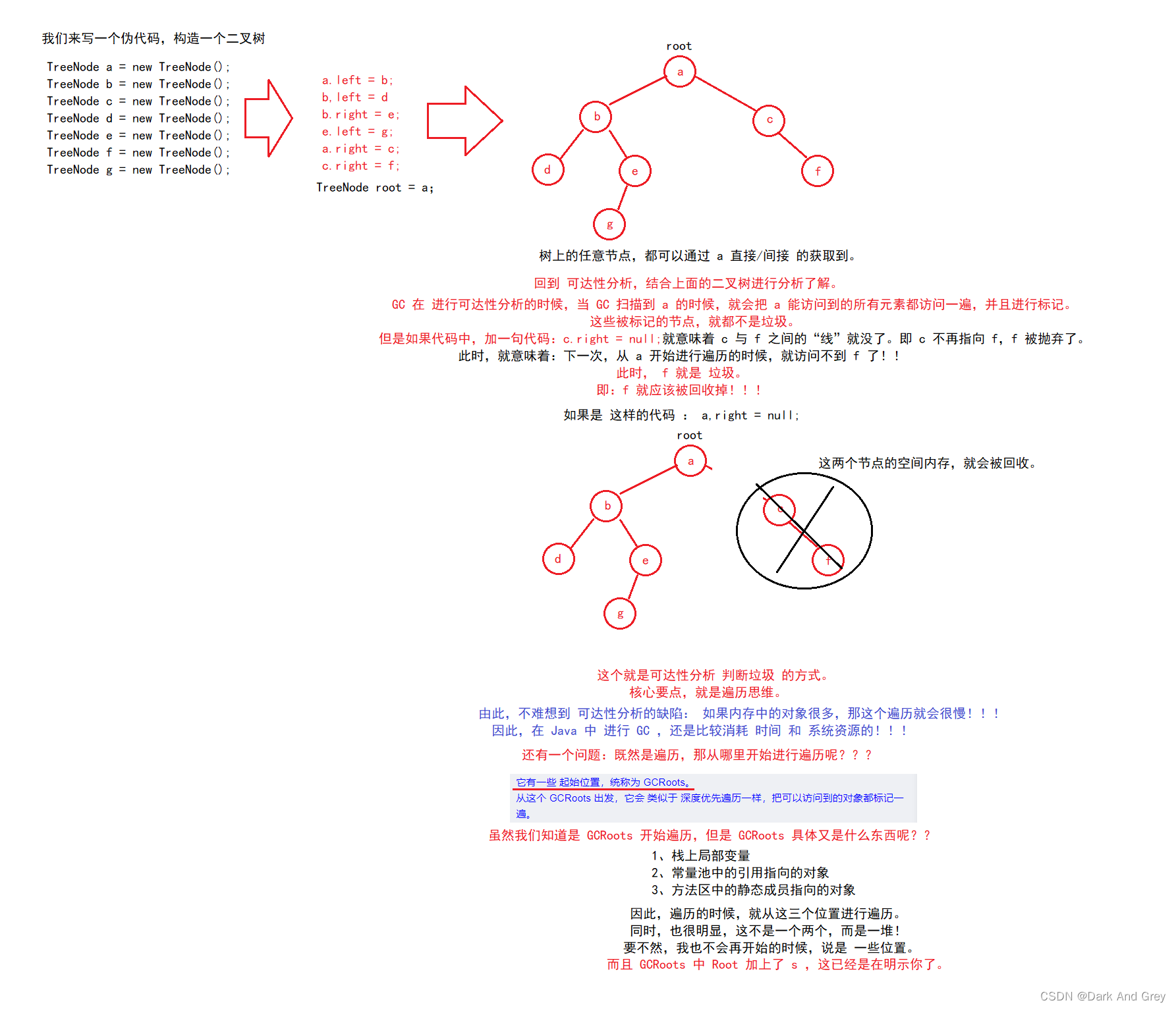
第二种 找垃圾 / 判断垃圾 的方案 : 可达性分析。
PS: Java 所采用的方案。可达性分析是通过 额外的线程,定期的针对整个内存空间的对象进行扫描。
怎么扫描呢?
它有一些 起始位置,统称为 GCRoots。
从这个 GCRoots 出发,它会 类似于 深度优先遍历一样,把可以访问到的对象都标记一遍。
也就是说:带有标记的对象就是 可达的对象。
可达的对象:有引用变量指向它,可通过 引用变量 访问到的对象。反之,没有被标记的对象,就是 不可达的对象,
不可达的对象:没有 引用变量 指向它,无妨被访问到的对象。
此时,这个不可达对象,就是 垃圾。
我们下面来看例子:
可参考文章学习二叉树 这一篇就够了由此,我们可以得出结论:
可达性分析的优点,就是克服了 引用计数的两个缺陷【空间利用率低 和 循环引用】。
同时缺点也很明显!系统开销大,遍历一次可能比较慢。
主要就是因为 标记垃圾,这件事,很拖慢效率。所以,我们后面遇到的大部分 垃圾回收器,很多就是 针对 扫描,这一块进行优化。
总结
找垃圾,核心就是确认这个对象,在未来是否还会被使用?
那么,什么算是不会再使用了?
没有引用指向的对象,就是不会再使用了。
此时,这些对象就是垃圾。无论是 引用计数,还是 可达性分析,都是基于 引用来判断 对象,是不是垃圾。
释放垃圾
确定了垃圾之后,接下来就是回收垃圾了。
就像打扫房间一下,你肯定是需要先确定 垃圾,然后将它清除。
而不是说,不管三七二十一,把房间里的东西一锅端了吧??回收垃圾 ( 释放内存 ) 有三种基本策略:
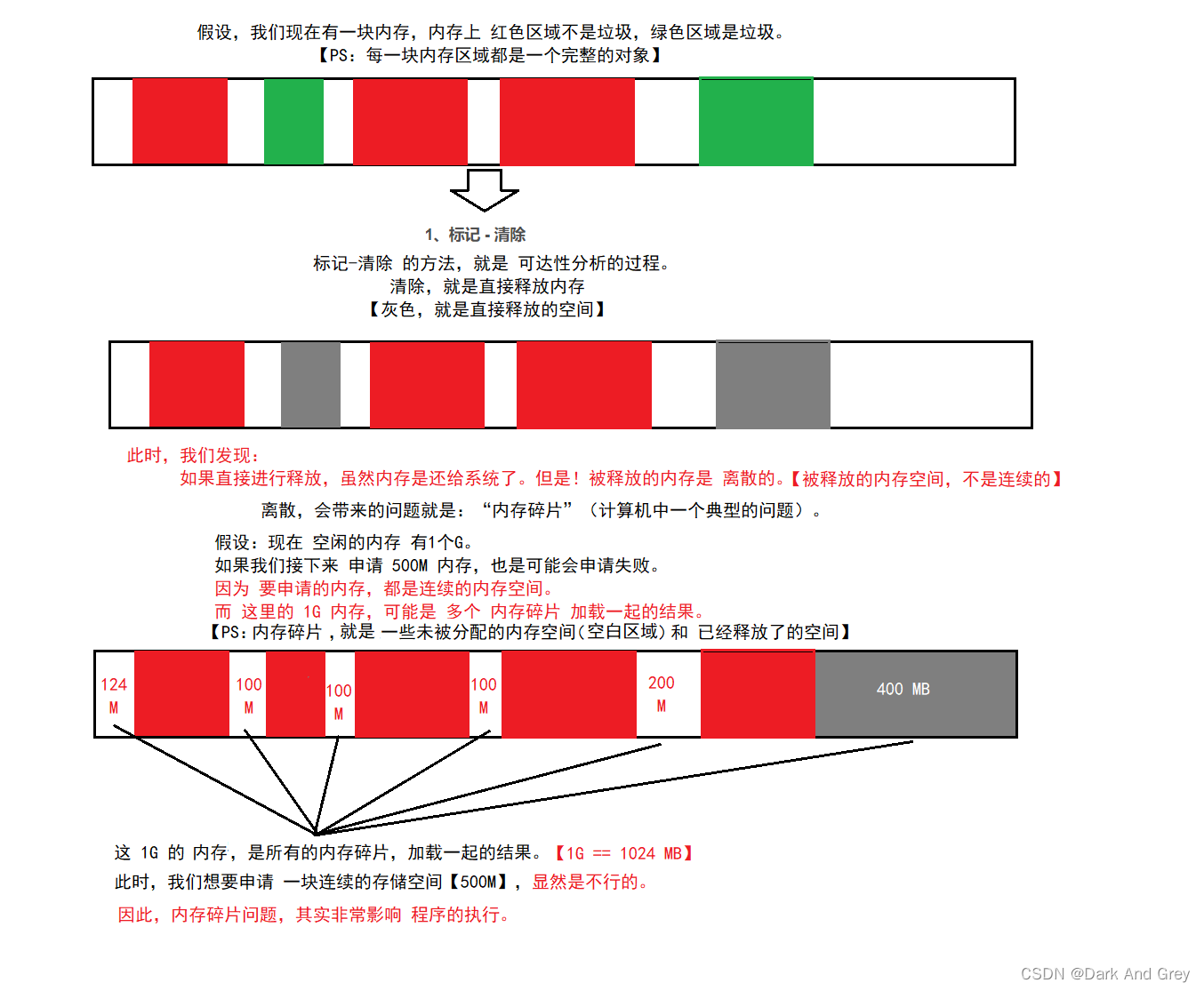
1、标记 - 清除
2、复制算法
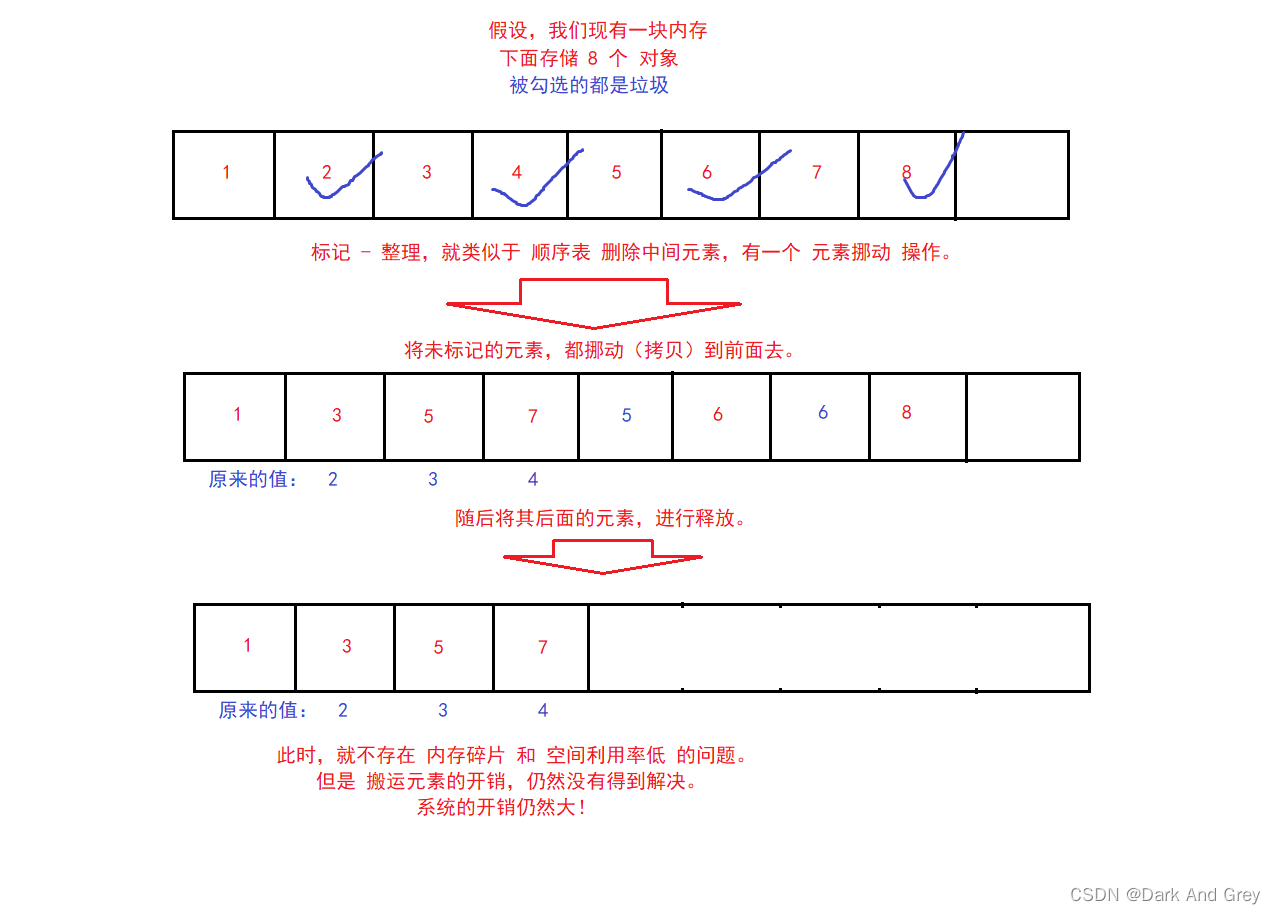
3、标记 - 整理
1、标记 - 清除
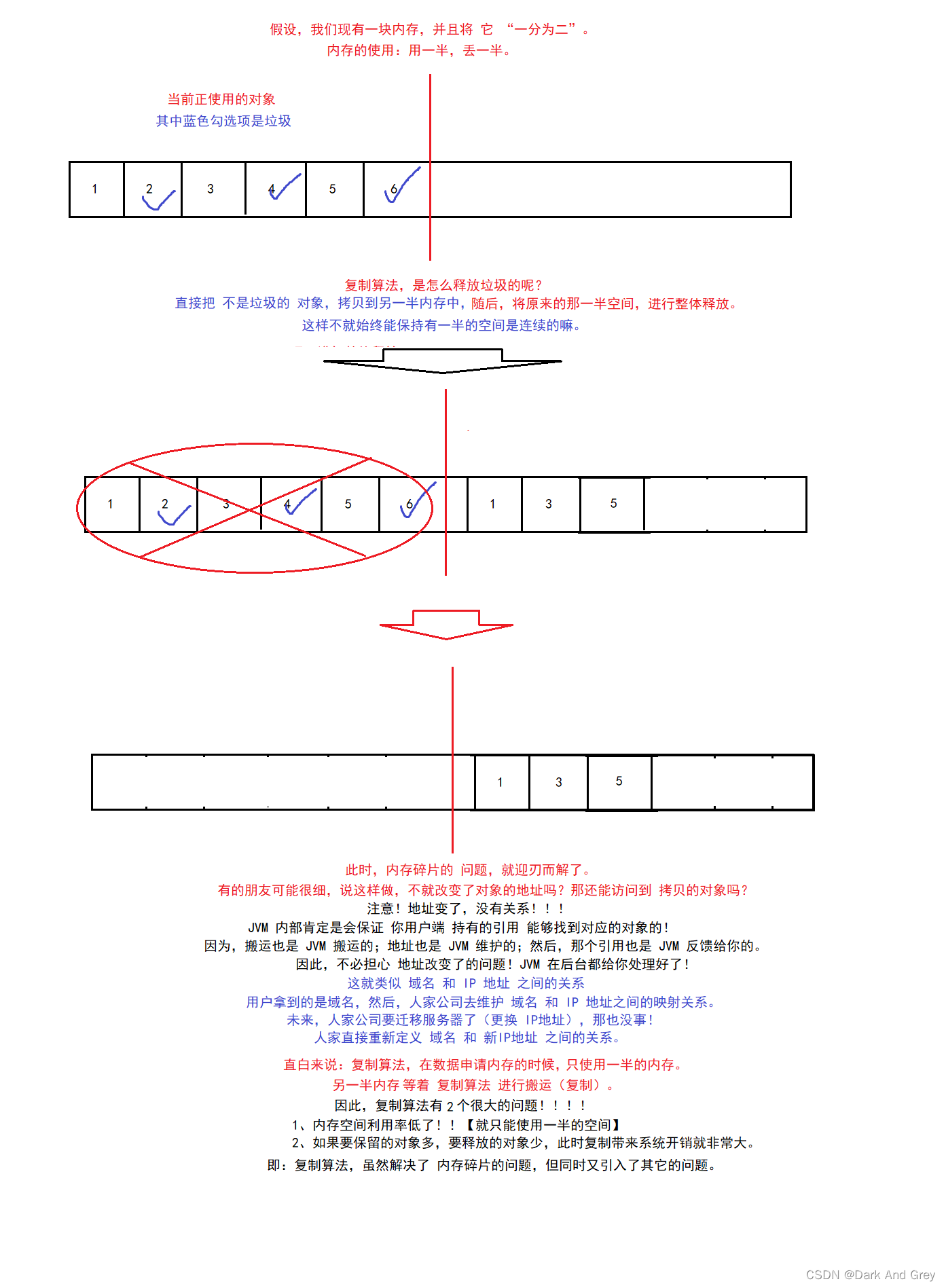
2、复制算法
为了解决标记-清除 方法 带来的 内存碎片 的问题。
我们引入了 复制算法!
3、标记 - 整理
这里是 针对赋值算法,再做出改进。
总结
关于垃圾回收,我们有三种思路。
但是我们发现,每种思路自身都有着一些缺陷。
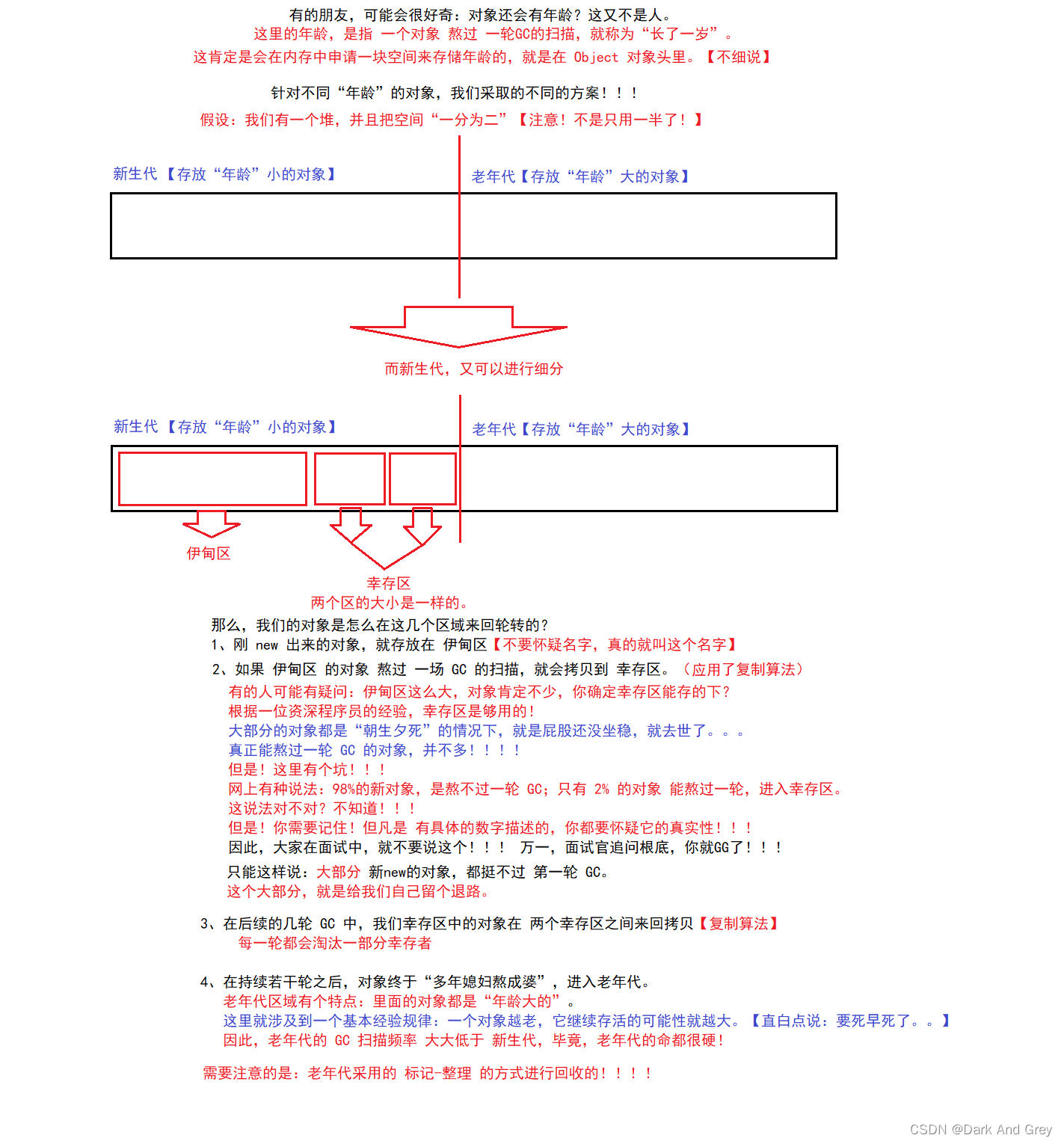
总的来说:在进行垃圾回收的时候,无论单独使用哪种方法,效果都不是很好。实际 JVM 中的实现,会把多种方案结合起来使用。
这个思路,我们称为 “分代回收”。分代回收,是根据 对象的 “年龄”,把 对象分成了不同的类。
上述过程都是面试中的经典问题。
再来给你们举个例子,加深你们对 分代回收 的理解。补充:
在 分代回收 中,还有一个特殊情况!!
有一类对象可以直接进入老年代!
大对象,占有内存多的对象,可以直接进入老年代。
因为 大对象的拷贝开销比较大,不适合 使用 复制算法。
这就好比:大佬,都是名校保送的!!! 是不需要进行高考的!

垃圾回收器 / 垃圾收集器
上面说的 找垃圾 和 释放垃圾,说的都是 算法思维,不是具体落地实现。
在 JVM 里面,真正实现上述算法的模块,称为 “垃圾回收器”。
垃圾回收器,才是真正负责 垃圾回收 的机制。垃圾回收器的种类有很多。
这是因为 垃圾回收,这件事情,一直不停的往前发展。
在接下来 要讲解的几个 垃圾回收器,有一些设计的并不是很合理。
我就简单介绍一下,就跳过。

汇总
本文重心,在于 垃圾回收的算法(引用计数 + 可达性分析 + 标记-清除 + 复制算法 + 标记-整理 + 分代回收)。
至于这些垃圾收集器,大家简答了解一下,即可。
另外, Java 从 11 大版本开始,JVM 就开始使用 G1 了。需要注意的是:这里的G1,并不是完全体!
更高的版本里,还有 ZGC 等等。。。更先进的 垃圾回收器。
垃圾回收机制,这一块是在不断进步中的!!!我们现在使用的 Java8 使用的是 CMS。
版权归原作者 Dark And Grey 所有, 如有侵权,请联系我们删除。