
目录
原文大佬的这篇Doris+Flink构建实时数仓的实战文章整体写的很深入,这里直接摘抄下来用作学习和知识沉淀。
本篇文章介绍如何基于Doris和Flink快速构建一个极速易用的实时数仓,包括数据同步、数据集成、数仓分层、数据更新、性能提升等方面的具体应用方案。
一、实时数仓的需求与挑战
** **先介绍一下传统的数据架构如何设计的、又存在哪些痛点问题。下图为传统的数据架构,如果从数据流的角度分析传统的数据处理架构,会发现从源端采集到的业务数据和日志数据,主要分为实时和离线两条链路:

在实时数据部分,通过Binlog方式,将业务数据库中的数据变更(CDC,Change Data Capture)采集到实时数仓。同时,通过Flume -Kafka-Sink对日志数据进行实时采集,当不同来源的数据都采集到实时存储系统后,便可以基于实时存储系统来构建实时数仓。在实时数仓的内部,仍然会遵守传统数仓分层理论,将数据分为 ODS 层、DWD 层、DWS 层、 ADS 层以实现最大程度的模型复用。
在离线数据部分,通过DataX定时同步的方式,批量同步业务库RDS中的数据。当不同来源的数据进入到离线数仓后,便可以在离线数仓内部,依赖Spark SQL 或Hive SQL 对数据进⾏定时处理,分离出不同层级(ODS 、DWD 、ADS 等)的数据,并将这些数据存在⼀个存储介质上,⼀般会采用如 HDFS 的分布式文件系统或者 S3 对象存储上。通过这样的⽅式,离线数仓便构建起来了。与此同时,为了保障数据的一致性,通常需要开启数据清洗任务,使用离线数据对实时数据进行清洗和定期覆盖,保障数据最终的一致性。
从技术架构的角度对传统数据技术栈进行分析,会发现为了迎合不同场景的需求,往往会采用多种技术栈,例如对于 OLAP 场景的多维分析,一般使⽤ Doris 或 Kylin、 Druid。除此之外,为应对半结构化数据的分析需求,例如日志分析与检索场景,通常会使⽤ ES 进行分析;面对高并发点查询的 Data Serving 场景会使⽤ HBase等。其中涉及到的数据组件有数十种,高昂的使用成本和组件间兼容、维护及扩展带来的繁重压力成为企业必须要面临的问题。

从上述介绍即可知道,传统的数据架构存在几个核心的痛点问题:
- 传统数据架构组件繁多,维护复杂,运维难度非常高。
- 计算、存储和研发成本都较高,与行业降本提效的趋势背道而驰。
- 同时维护两套数据仓库(实时数仓和离线数仓)和两套计算(实时数据量和实时计算任务),数据时效性和一致性无法保证。
在此背景下,需要构建⼀个“极速、易用、统一、实时”的数据架构来解决这些痛点:
- 极速:更快的查询速度,最大化提升业务分析人员的效率;
- 易用:对于用户侧的使用和运维侧的管控,都提供了极简的使用体验;
- 统一:异构数据与分析场景的统一,半结构化和结构化数据可以统一存储,多分析场景可以统一技术栈
- 实时:端到端的高时效性保证,发挥实时数据的价值
二、****构建极速易用的实时数仓架构
采取Doris和Flink 来构建极速易用的实时数仓,具体架构如下图所示。多种数据源的数据经过flink cdc 集成或flink job加工件处理后,入库到Doris或者Hive等湖仓中,最终基于Doris提供统一的查询服务。

在数据同步上,通过Flink CDC将RDS的数据实时同步到Doris。通过Routine Load将kafka等消息系统的数据实时同步到Doris,在数仓分层上,ODS层通常选择明细模型构建,DWD层可以通过SQL调度任务,对ODS数据抽取并获取,DWS和ADS层则可以通过物化视图和Rollup进行构建。在数据湖上, Doris ⽀持为 Hive、Iceberg 、Hudi 以及Delta Lake(todo)提供联邦分析和湖仓加速的能⼒。在数据应用上,Apache Doris 既可以承载批量数据加工处理的需求,也可以承载高吞吐的 Ad-hoc(数据探索) 和高并发点查询等多种应⽤场景。
三、解决方案
3.1 如何实现数据的增量与全量同步
3.1.1 增量及全量数据同步
在全量数据和增量的同步上,采取了Flink CDC来实现。其原理非常简答,Flink CDC实现了基于Snapshot的全量数据同步,基于 BinLog的实时增量数据同步。全量数据同步和增量数据同步可以自动切换,因此在数据迁移过程中,只需要配置好同步的表即可。当Flink任务启动时,优先进行历史表的数据同步,同步完成后自动切换成实时同步。

3.1.2 数据一致性保证
如何保证数据一致性是大家重点关注的问题之一,那么在新架构是如何实现的呢?
数据⼀致性⼀般分为“最多⼀次” 、“⾄少⼀次”和“精确⼀次”三种模型。
- 最多⼀次(At-Most-Once):发送⽅仅发送消息,不期待任何回复。在这种模型中,数据的⽣产和消费过程中可能出现数据丢失的问题。
- ⾄少⼀次(At-Least-Once):发送⽅不断重试,直到对⽅收到为⽌。在这个模型中,⽣产和消费过程都可能出现数据重复。
- 精确⼀次(Exactly-Once):能够保证消息只被严格发送⼀次,并且只被严格处理⼀次。这种数据模型能够严格保证数据⽣产和消费过程中的准确⼀致性。
Flink CDC通过Flink Checkpoint 机制结合Doris两阶段提交可以实现端到端的Exactly Once语义,具体过程分为四步:
- 事务开启(Flink Job启动及Doris事务开启):当Flink任务启动后,Doris Sink 会发起 Precommit 请求,随后开启写⼊事务。
- 数据传输(Flink Job的运行和数据传输):在Flink Job运行过程中,Doris Sink不断从上游算子获取数据,并通过 HTTP Chunked 的⽅式持续将数据传输到 Doris。
- 事务预提交:当Flink开始进行Checkpoint时,Flink会发起Checkpoint请求,此时Flink各个算子会进行Barrier对齐和快照保存,Doris Sink发出停止 Stream Load 写⼊的请求,并发起一个事务提交请求到Doris。这步完成后,这批数据已经完全写入Doris BE中,但是BE没有进行数据发布前对用户是不可见的。
- 事务提交:当Flink的Checkpoint完成之后,将通知各个算子,Doris发起一次事务提交到Doris BE,BE对此次写入的数据进行发布,最终完成数据流的写入。
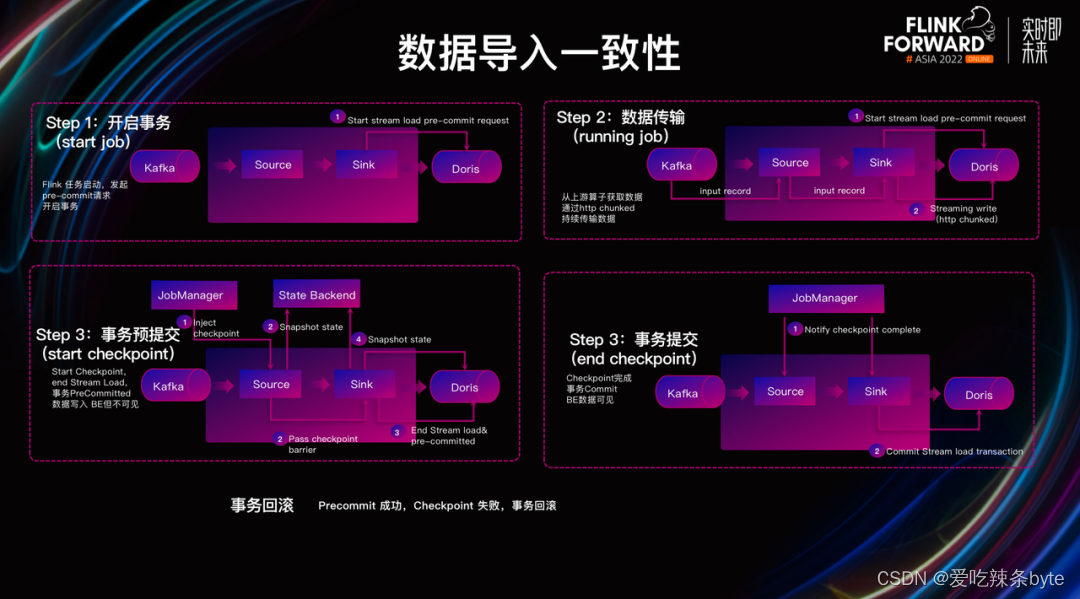
综上可知,利用 **Flink CDC结合Doris 两阶段事务提交保证了数据写入一致性**。需要注意的是,在该过程中可能遇到一个问题:如果事务预提交成功、但 Flink Checkpoint 失败了该怎么办?针对该问题,**Doris 内部支持对写⼊数据进⾏回滚(Rollback),从⽽保证数据最终的⼀致性**。
3.1.3 DDL 和 DML 同步
随着业务的发展,部分用户可能存在RDS Schema的变更需求。当RDS表结构发生变更时,用户期望Flink CDC不但能够将数据变化同步到Doris,也希望将 RDS 表结构的变更同步到 Doris,⽤户则无需担⼼ RDS 表结构和 Doris 表结构不⼀致的问题。
Light Schema Change
Apache Doris 1.2.0 已经实现了 Light Schema Change 功能,可满⾜ DDL 同步需求,快速⽀持** Schema 的变更**。
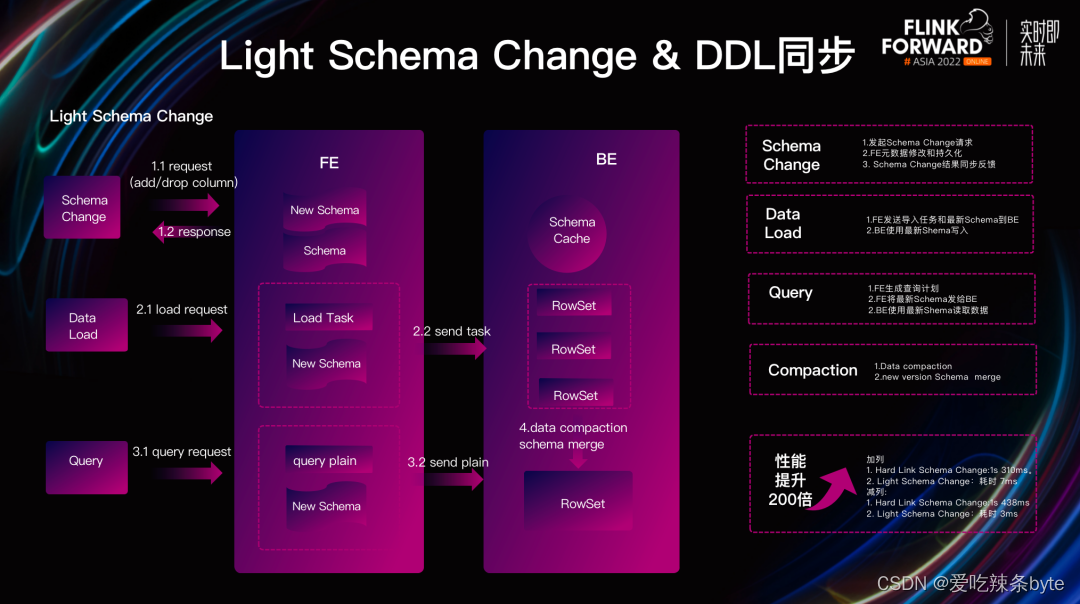
Light Schema Change的实现原理相对简单,对数据表的加减列操作,不再需要同步更改数据文件,仅需要再FE中更新元数据即可,从而实现毫秒级的Schema Change 操作。由于 Light Schema Change 只修改了 FE的元数据,并没有同步给 BE。因此会产⽣ BE 和 FE Schema 不⼀致的问题。为了解决这种问题,我们对 BE 的写出流程进⾏了修改,具体包含三个⽅⾯。
(1)数据写入:FE会将 Schema 持久化到元数据中,当 FE 发起导⼊任务时,会把最新的 Schema 一起发给 Doris BE,BE 根据最新的Schema对数据进⾏写⼊,并与 RowSet 进⾏绑定。将该 Schema 持久化到 RowSet 的元数据中,实现了数据的各⾃解析,解决了写⼊过程中 Schema 不⼀致的问题。
(2)数据读取:FE ⽣成查询计划时,会把最新的 Schema 附在其中⼀起发送给 BE,BE 拿到最新的 Schema 后对数据进⾏读取,解决读取过程中 Schema 发⽣不⼀致的问题。
(3)数据 Compaction:当数据进⾏ Compaction 时,我们选取需要进⾏ Compaction 的 RowSet中最新的Schema作为之后RowSet 对应的 Schema,以此解决不同 Schema 上 RowSet 的合并问题
经过对 Light Schema Change 写出流程的优化后, 单个 Schema Chang 从 310 毫秒降低到了 7 毫秒,整体性能有近百倍的提升,彻底的解决了海量数据的 Schema Change 变化难的问题。
Flink CDC DML 和DDL同步
有了 上述Light Schema Change 的保证,Flink CDC 能够同时⽀持DML 和DDL 的数据同步。那么是如何实现的呢?

(1)开启 DDL 变更配置:在 Flink CDC 的 MySQL Source 侧开启同步 MySQL DDL 的变更配置,在 Doris 侧识别 DDL 的数据变更,并对其进⾏解析。
(2)识别及校验:当 Doris Sink 发现 DDL 语句后,Doris Sink 会对表结构进⾏验证,验证其是否⽀持 Light Schema Change。
(3)发起 Schema Change :当表结构验证通过后,Doris Sink 发起 Schema Change 请求到 Doris,从⽽完成此次 Schema Change 的变化。
解决了数据同步过程中**源数据⼀致性的保证、全量数据和增量数据的同步以及 DDL 数据的变更**后,一个完整的数据同步⽅案就基本形成了。
3.2 如何基于Flink实现多种数据集成

除了上文中所提及的基于 Flink CDC 进行数据增量/全量同步外,我们还可以基于 Flink Job 和 Doris 来构建多种不同的数据集成方式:
- 将Mysql中两个表的数据同步到Flink后,在Flink内部进行多流Join完成数据打宽,后将大宽表同步到Doris中。
- 对上游的Kafka数据进行清洗,在Flinkjob完成清洗后,通过Doris-Sink写入到Doris中。
- 对Mysql数据和Kafka数据在Flink内部进行多流Join,将Join后的宽表结果写入Doris中。
- 在Doris侧预先创建宽表,将上游RDS中的数据根据Key写入,使用Doris的部分列更新将多列数据写入到Doris的大宽表中。
3.3 如何选择数据模型
Doris针对不同场景,提供了不同的数据模型,分别为明细模型、聚合模型、主键模型。
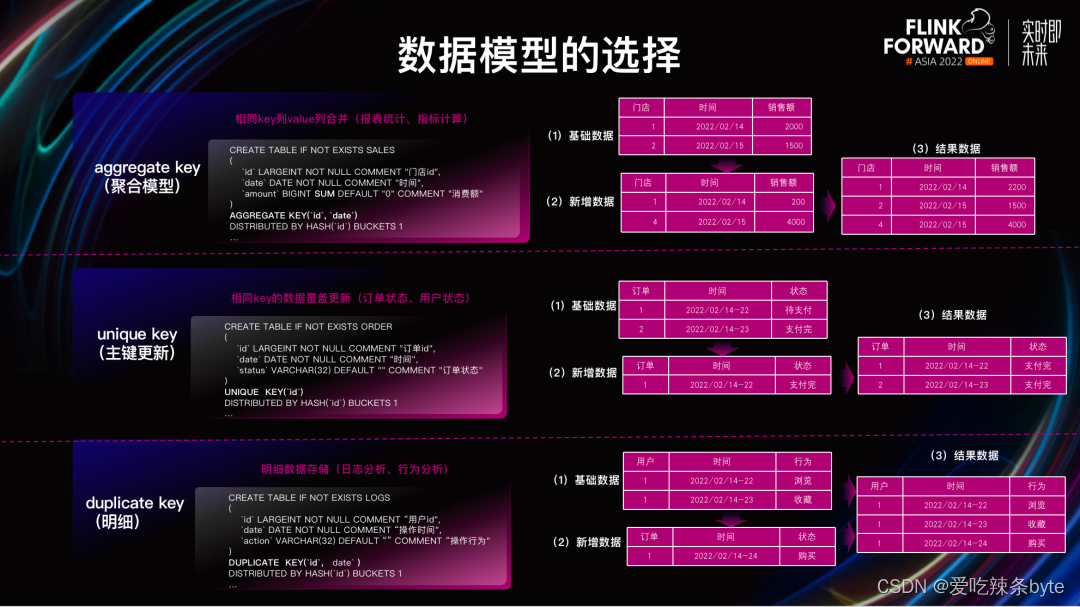
3.3.1 DUPLICATE 明细模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求,Duplicate 数据模型可以满足这类需求。明细模型主要用于需要保留原始数据的场景,如日志分析,用户行为分析等场景。**明细模型适合任意维度的 Ad-hoc 查询(即席查询)**。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
3.3.2 AGGREGATE 聚合模型
在企业实际业务中有很多需要对数据进行**统计和汇总**操作的场景,如需要分析网站和 APP 访问流量、统计用户的访问总时长、访问总次数,或者像厂商需要为广告主提供广告点击的总流量、展示总量、消费统计等指标。在这些不需要召回明细数据的场景,通常可以使用聚合模型,比如上图中需要根据门店 ID 和时间对每个门店的销售额实时进行统计。
3.3.3 UNIQUE KEY 主键模型
在某些场景下用户**对数据更新和数据全局唯一性有去重**的需求,通常使用UNIQUE KEY 模型。在 UNIQUE 模型中,会根据表中的主键进⾏Upsert 操作:对于已有的主键做 Update 操作,更新 value 列,没有的主键做 Insert 操作,比如图中我们以订单id为唯一主键,对订单上的其他数据(时间和状态)进行更新。
3.4 如何构建数仓分层
由于数据量级普遍较大,如果直接查询数仓中的原始数据,需要访问的表数量和底层文件的数量都较多,不同层级对数据或指标做不同粒度的抽象,通过复用数据模型来简化数据管理压力,利用血缘关系来定位数据链路的异常,同时进一步提升数据分析的效率,在Doris 中可以通过以下多种思路来构建数据仓库分层:
3.4.1 微批调度
通过INSERT INTO SELECT 可以将原始表的数据进行处理和过滤并写入到目标表中,这种SQL抽取数据的行为 一把是以微批形式进行(例如15分钟一次的ETL计算任务),通常发生在从ODS到dwd层数据的抽取过程中,因此需要借助外部的调度工具例如Dolphinscheduler等来对ETL SQL进行调度。
3.4.2 物化视图与Rollup
物化视图本质是一个预先计算的过程,可以在Base表上,创建不同的物化视图或Rollup来对Base表进行聚合计算。通常在明细层到汇总层(例如dwd层到dws层或 dws层到ads层)的汇聚过程中,可以使用物化视图,以此实现指标的高度聚合。同时物化视图的计算是实时进行的,因此站在计算的角度,也可以将物化视图理解为一个单表上的实时计算过程。
3.4.3 多表物化视图
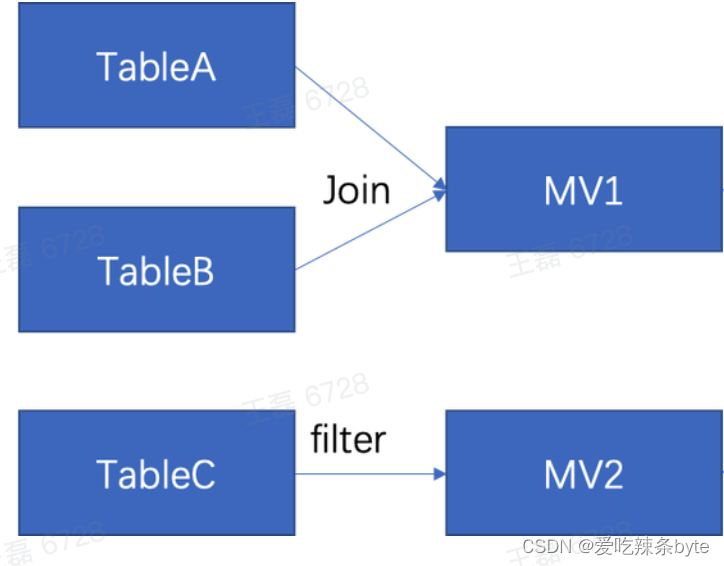
Doris 2.0将实现多表物化视图这一功能,可以将带有 Join 的查询结果固化以供用户直接查询,支持定时自动或手动触发的方式进行全量更新查询结果。基于多表物化视图这一功能的实现,可以做更复杂的数据流处理,比如数据源侧有 TableA、TableB、TableC,在多表物化视图的情况下,用户就可以将 TableA 和 TableB 的数据进行实时Join 计算后物化到 MV1 中。在这个角度上来看,多表物化视图更像一个多流数据实时 Join 的过程。
3.5 如何应对数据更新
在实时数仓构建的过程中,还需面临**高并发写入和实时更新**的挑战,如何在亿级数据中快速找到需要更新的数据,并对其进行更新,⼀直都是大数据领域不断追寻的答案。
3.5.1 高并发数据更新
在Doris中通过Unique Key 模型来满足数据更新的需求,同时通过MVCC多版本并发机制来实现数据的读写隔离。当新数据写入时,如果不存在相同key的数据则会直接写入,如果有相同key的数据则增加版本,此时数据将多个版本的形式存在。后台会启动异步的Compaction进程对历史版本的数据进行清理,当用户在查询时,Doris会将最新版本对应的数据返回给用户,这种设计解决了海量数据的更新问题。

** 在Doris中提供了Merge-on-Read和Merge-on-Write两种数据更新模式。**

在此我们以订单数据的写入为例介绍 Merge-on-Read 的数据写入与查询流程,三条订单数据均以 Append 的形式写⼊ Doris 表中:
数据 Insert:首先写入 ID 为 1,2,3 的三条数据;
数据 Update:当我们将订单 1 的 Cost 更新为 30 时,其实是写⼊⼀条 ID 为 1,Cost 为 30 的新版本数据,数据通过 Append的形式写⼊ Doris;
数据 Delete:当我们对订单 2 的数据进行删除时,仍然通过 Append ⽅式,将数据多版本写⼊ Doris ,并将 _DORIS_DELETE_SIGN 字段变为 1 ,则表示这条数据被删除了。当 Doris 读取数据时,发现最新版本的数据被标记删除,就会将该数据从查询结果中进⾏过滤。
Merge-on-Read的特点是写入速度比较快,但是在数据读取过程中由于需要进行多路归并排序,存在着大量非必要的CPU计算资源消耗和IO开销。
在1.2.0 版本中,Doris在原有的Unique Key数据模型上增加了 Merge-on-Write的数据更新模式。Merge-on-Write兼顾了写入和查询性能,在写入过程中引入了Delete Bitmap数据结构,使用Delete Bitmap标记Rowset中某一行是否被删除,为了保持Unique Key原有的语义,Delete Bitmap也支持多版本。另外使用了兼顾性能和存储空间的 Row Bitmap,将Bitmap中的MemTable一起存储在BE中,每个Segment会对应⼀个 Bitmap。

写入流程:
DeltaWriter先将数据Flush到磁盘
批量检查所有 Key,在点查过程中经过区间树,查找到对应的 RowSet。
在 RowSet 内部通过 BloomFilter 和 index进行高效查询。
当查询到 Key 对应的 RowSet 后,便会覆盖 RowSet Key 对应的 Bitmap,接着在 Publish 阶段更新 Bitmap,从而保证批量点查 Key 和更新 Bitmap 期间不会有新的可见 RowSet,以保证 Bitmap 在更新过程中数据的正确性。除此之外,如果某个 Segment 没有被修改,则不会有对应版本的 Bitmap 记录。
** 查询流程:**
当查询某⼀版本数据时, Doris 会从 LRU Cache Delete Bitmap 中查找该版本对应的缓存。
如果缓存不存在,再去 RowSet 中读取对应的 Bitmap。
使⽤ Delete Bitmap 对 RowSet 中的数据进行过滤,将结果返回。
Merge-on-Write该模式不需要在读取的时候通过归并排序来对主键进行去重,这对于高频写入的场景而言,大大减少了查询执行时的额外消耗。此外还能够支持谓词下推,并能够很好利用Doris丰富的索引,在数据IO层面就能够进行充分的数据裁剪,大大减少数据的读取量和计算量,因此在很多场景的查询中都有非常明显的性能提升。在真实场景的测试中,通过 Merge-on-Write可以在保证数万QPS的高频Upsert 操作的同时,可以实现性能 3-10 倍的提升。
3.5.2 部分列更新
部分列更新是一个比较普遍的需求,例如广告业务中需要在不同的时间点对同一个广告行为(展示、点击、转换等)数据的更新。可以通过 Aggregate Key模型的
replace_if_not_null
实现。
3.6 如何进一步提升查询性能
**3.6.1 **智能物化视图
物化视图除了可以作为高度聚合的汇总层外,更广泛的定位是加速相对固定的聚合分析场景。物化视图是指根据预定义的SQL分析语句执行预计算,并将结算结果持久化到另一张对用户透明(用户无感知)但有实际存储的表中,在需要同时查询聚合数据和明细数据以及匹配不同前缀索引的场景,命中物化视图时可以获得更快的查询性能。
在使用物化视图时需要建立Base表并基于此建⽴物化视图,同⼀张 Base表可以构建多个不同的物化视图,从不同的维度进⾏统计。如果数据再物化视图中存在会直接查询物化视图,如果在物化视图中不存在才会查询Base表。
在数据写入或更新时,数据会在写入Base表的同时会写入物化视图,从而保证物化视图和Base 表数据的完全⼀致性。

智能路由选择遵循最小匹配原则,只有查询的数据集⽐物化视图集合⼩时,才可能⾛物化视图。如上图所示智能选择过程包括选择最优和查询改写两个部分:
选择最优:
在过滤候选集过程中,被执行的 SQL 语句通过 Where 条件进⾏判断,Where 条件为advertiser=1。由此可⻅物化视图和 Base 表都有该字段,这时的选集是物化视图和 Base 表。
Group By 计算,Group By 字段是 advertiser 和 channel,这两个字段同时在物化视图和 Base 表中,这时过滤的候选集仍然是物化视图和 Base表。
过滤计算函数,比如执⾏ count(distinctuser_id),然后对数据进⾏计算,由于 Count Distinct 的字段 user_id 在物化视图和 Base 表中都存在,因此过滤结果仍是物化视图和 Base 表。
选择最优,通过⼀系列计算,发现查询条件⽆论是 Where 、Group By 还是 Agg Function 关联的字段,结果都有 Base 表和物化视图,因此需要进⾏最优选择。Doris 经过计算发现 Base 表的数据远⼤于物化视图,即物化视图的数据更⼩。
由此过程可⻅,如果通过物化视图进行查询,查询效率更⾼。当我们找到最优查询计划,就可以进⾏⼦查询改写,将 Count Distinct 改写成 Bitmap ,从⽽完成物化视图的智能路由。完成智能路由之后,我们会将 Doris ⽣成的查询 SQL 发送到 BE 进⾏分布式查询计算。
3.6.2 分区分桶裁剪
Doris 数据分为两级分区存储, 第一层为分区(Partition),目前支持 RANGE 分区和 LIST 分区两种类型, 第二层为 HASH 分桶(Bucket),可以按照时间对数据进⾏分区,再按照分桶列将⼀个分区的数据进行 Hash 分到不同的桶⾥。在查询时则可以通过分区分桶裁剪来快速定位数据,加速查询性能的同时实现高并发。
3.6.3 索引查询加速
除了分区分桶裁剪, 还可以通过存储层索引来裁剪需要读取的数据量,仅以加速查询:
- 前缀索引:在排序的基础上快速定位数据
- Zone Map 索引:维护列中 min/max/null 信息
- Bitmap 索引:通过 Bitmap加速去重、交并查询
- Bloom Filter 索引:快速判断元素是否属于集合;
- Invert 倒排索引:支持字符串类型的全文检索;
3.6.4 执行层查询加速
Doris 的MPP查询框架、向量化执行引擎以及查询优化器也提供了许多性能优化方式,在此仅列出部分、不做详细展开:
- 算子下推:Limit、谓词过滤等算子下推到存储层;
- 向量化引擎:基于 SIMD 指令集优化,充分释放 CPU 计算能力;
- Join 优化:Bucket Shuffle Join、Colocate Join 以及 Runtime Filter 等;
四、****行业最佳实践
4.1 跨境电商
基于 Doris 构建实时数仓,上游数据源来自 RDS 业务库、⽂件系统数据以及埋点日志数据。在数据接⼊过程中通过 DataX 进⾏离线数据同步以及通过 Flink CDC 进⾏实时数据同步,在 Doris 内部构建不同的数据分层;最后在上层构建不同的数据应⽤,比如自助报表、数据⼤屏。除此之外,它基于应用平台构建了数据开发与治理平台,完成了源数据管理、数据分析等操作。
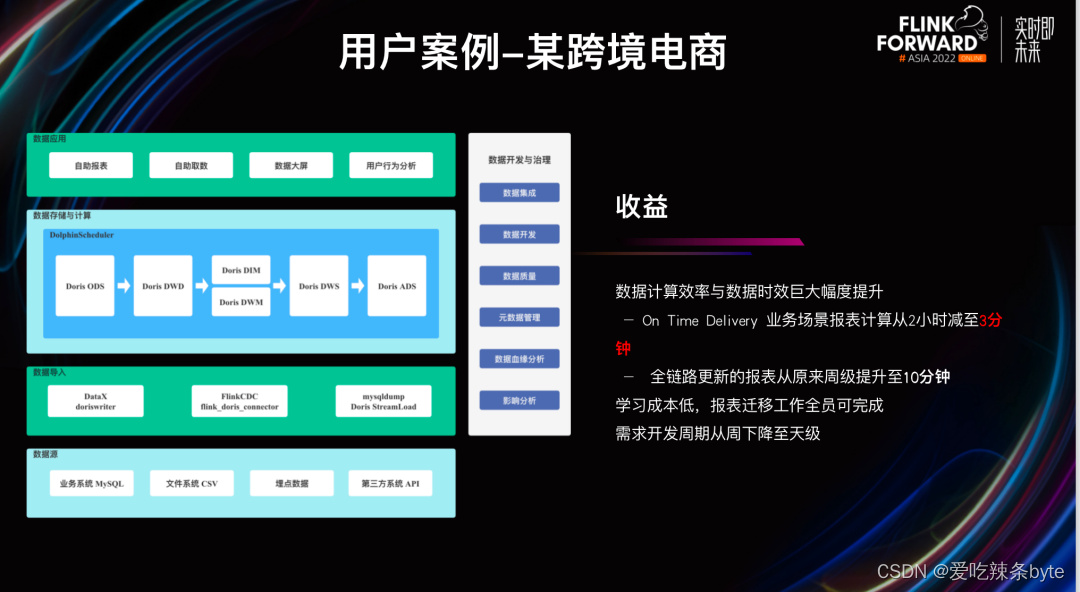
使用收益:
- 业务计算耗时从之前的两⼩时降低到三分钟。
- 全链路的更新报表的时间从周级别更新到⼗分钟级别。
- Doris 高度兼容 MySQL,报表迁移无压力,开发周期从周级别降低至天级别。
4.2 运营服务商
数仓架构是通过 Flink CDC 将RDS的数据同步到 Doris 中,同时通过 Routine Load 直接订阅 Kafka 中接入的日志数据,然后在 Doris 内部构建实时数仓。在数据调度时, 通过开源 DolphinScheduler 完成数据调度;使⽤ Prometheus+Grafana 进⾏数据监控。

使用收益:
采⽤ Flink+Doris 架构体系后,架构简洁、组件减少,解决了多架构下的数据的冗余存储,服务器资源节省了 30%,数据存储磁盘占⽤节省了 60%,运营成本⼤幅降低。基于该数仓架构,在⽤户的业务场景上,可以支持数万次的⽤户在线查询和分析。
4.3 供应链企业
** **在过去该企业采取了 Hadoop 体系,使用组件⽐较繁多,有 RDS、HBase、Hive、HDFS、Yarn、Kafka 等多个技术栈,在该架构下,查询性能无法得到有效快速的提升,维护和开发成本一直居高不下。

使用收益:
引入 Doris 之后,将 RDS 的数据通过 Flink CDC 实时同步到 Doris ⾥,服务器资源成本得到了很⼤的降低。数据的查询时间从 Spark 的 2~5 ⼩时,缩短到⼗分钟,查询效率也⼤⼤提升。在数据的同步过程中,使⽤了 Flink CDC+MySQL 全量加增量的数据同步⽅式,同时还利⽤ Doris 的 Light Schema Change(轻量表结构变更) 特性实时同步 Binlog里的DDL表结构变更,实现数据接⼊数仓零开发成本。
轻量表结构变更Light Schema Change: 在Doris1.2版本中,对数据表的加减列操作,不需要同步更改数据文件,仅需要在FE中更新元数据即可,从而实现毫秒级的Schema Change操作。与此同时,使得Doris在面对上游数据表维度变化时,可以更加快速稳定实现表结构同步,保证系统的高效且平稳运转。通过 Flink CDC,可实现上游数据库到 Doris 的 DML 和 DDL 同步,进一步提升了实时数仓数据处理和分析链路的时效性与便捷性。
参考文章:
如何基于 Apache Doris 与 Apache Flink 快速构建极速易用的实时数仓|解决方案
版权归原作者 爱吃辣条byte 所有, 如有侵权,请联系我们删除。