
1. bytes字节串类型介绍:
定义一个字节串:
字面量:b=b"he1lo 你好"[默认编码格式ASCII]
类型: b=bytes("字节内容",encoding="utf-8")[默认编码格式ASCII]
Python 3新增了bytes 类型,用于代表字节串,是一一个类型。
由于bytes保存的就是原始的字节(二进制格式)数据,因此bytes对象可用于在网络上传输数据,也可用于存储各种二进制格式的文件,比如图片、音乐等文件。
2. 二进制、十进制、十六进制之间的转换:
二进制:
010101, 是电脑识别的一种格式数据
python解析器,帮助我们把我们输入的python语言解析成二进制的数据,供计算机所识别。
例如:如果我们定义的是十进制,十六进制,等语言,需要先转成二进制后,计算机在进行执行。进行数据传递的过程中如果使用二进制进行数据传递的话执行速度会很快
2.1 二进制转十进制:
把二进制数按权展开、相加即得十进制数

2.2 二进制转十六进制:
十六进制是取四合一。
(注意:四位二进制转成十六进制是从右到左开始转换,不足时补零)

2.3 十进制转二进制:
十进制数除二取余法,即十进制数除二,余数为权位上的数,得到的商值继续除以二,依次步骤继续向下运算直到商为零为止
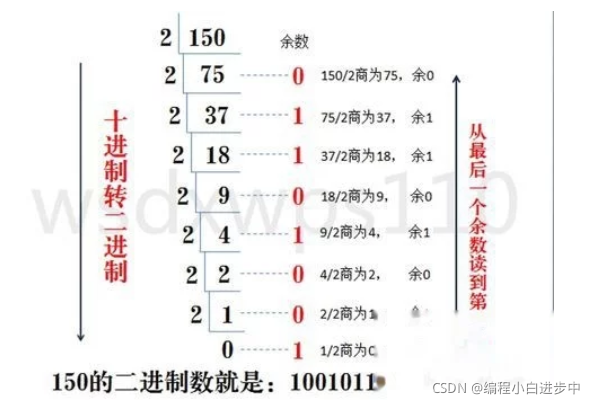
2.4 十进制转十六进制:
间接法:把十进制转成二进制,然后再由二进制转成十六进制
2.5 十六进制转二进制:
十六进制数通过除2取余法,得到二进制数,对每一个十六进制为四个二进制,不足时在最左边补零

2.6 十六进制转十进制:
把十六进制数按权展开,相加即得十进制数

3. 字节串和字符串之间的区别:
bytes和str 除操作的数据单元不同之外,它们支持的所有方法都基本相同,bytes也是不可变序列。
字符串(str) 由多个字符组成,以字符为单位进行操作;
字节串(bytes) 由多个字节组成,以字节为单位进行操作。
4. 字节介绍:
计算机底层有两个基本概念:位(bit) 和字节(Byte) ,其中
bit代表1位,要么是0,要么是1;
Byte代表1字节,1字节包含8位二进制。
定义一个字节串:“123” 里面有三个字节, 每一个字节由8位二进制构成。两个十六进制组成
每4位二进制可以用一个十六进制数表示。(一个字节需要两个十六进制的数)每四位相当于4位二进制数。
b’\xe6\x88\x91 \xe7\x88 \xb1Python\xe7\xbc \x96\xe7\xa8\x8b’,
比如: \xe6 就表示1字节,其中\x表示十六进制,e6就是两位的十六进制数。
5. 字节串和字符串之间的转换:
5.1 如果字符串内容都是 ASCII 字符,则可以通过直接在字符串之前添加b来构建字节串值。
b=b"he1lo"print(b)# 输出: b"he1lo"5.2 调用 bytes()函数(其实是bytes的构造方法)将字符串按指定字符集转换成字节串,
b=bytes("字节内容v,encoding= "utf-8")[默认编码格式ASCII]
b=bytes("he111o字节内容",encoding="utf-8")print(b)# 输出: b' he11lo\xe5\xad\x97\xe8\x8a^ \x82\xe5 \x86\x85\xe5\xae \xb9'5.3 调用字符串本身的encode()方法将字符串按指定字符集转换成字节串(常用)
如果不指定字符集,默认使用UTF-8 字符集。
str="nihao你好"
b=str. encode("utf-8")print(b)#输出: b' nihao\xe4\xbd\xa0\xe5\xa5\xbd'|
6. 将一个bytes对象转换成字符串(decode(“编码类型” ) ):
str="nihao你好"
b=str. encode("utf-8")
str1=b. decode("utf-8")print(str1)# 输出:nihao你好
总结:
encode() 是编码 decode() 是解码
str=b"abc"print(str. decode (encoding="utf-8"))# 输出: abc
str1="聚焦"print(str1.encode (encoding="utf-8"))# 输出: b'\xe8\x81 \x9a\xe7\x84\xa6'
7. 编 码:
Unicode字符集,包括汉字,为两个字节(6位,支持6536个字符编号)。实际使用的UTF-8, UTF-16 GeBK GB2312等其实都属于Unicode字符集。
ASCII码:是用一个字节(8bit 0-255) 中的127个字母表示大小写字母,数字和一些键盘 上有的符号。其余的例如汉字等不能被表示。
为了统各国的编码,减少乱码, 诞生了Unicode, 把所有编码统-到- 套编码中。
为了节约位置以及效率低下等问题。出现了把Unicde编码转化为“可变长编码”的UTF-8编码。
UTF-8编码(针对中文).把-一个Cide字符根据不同的数字大小编码成4-6个字节,常用的英文祖母被编码成了1个字节,汉字是3个字节,只有特别偏僻的字才会被编码成4-6个字节.
如果需要传输的文本包含大量的英文字符,UTF-8就能节省空间。(ASCII码可以看成是UTF-8的一 部分, 所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作)
GBK:只识别中文

8. 开发过程中遇见乱码问题:
8.1你自己创建的文件书写了一些文字保存之后发现乱码考虑编码的问题编码改为utf-88.2数据传递的时候
python端开发的时候C语言项目c----python端传递数据接收到的数据中文乱码了
需要判断
C语言那边数据是不是用utf-8编码和你接收数据的时候是不是也是通过utf-8
标签:
python
本文转载自: https://blog.csdn.net/qq_53755809/article/details/121464982
版权归原作者 编程小白进步中 所有, 如有侵权,请联系我们删除。
版权归原作者 编程小白进步中 所有, 如有侵权,请联系我们删除。