
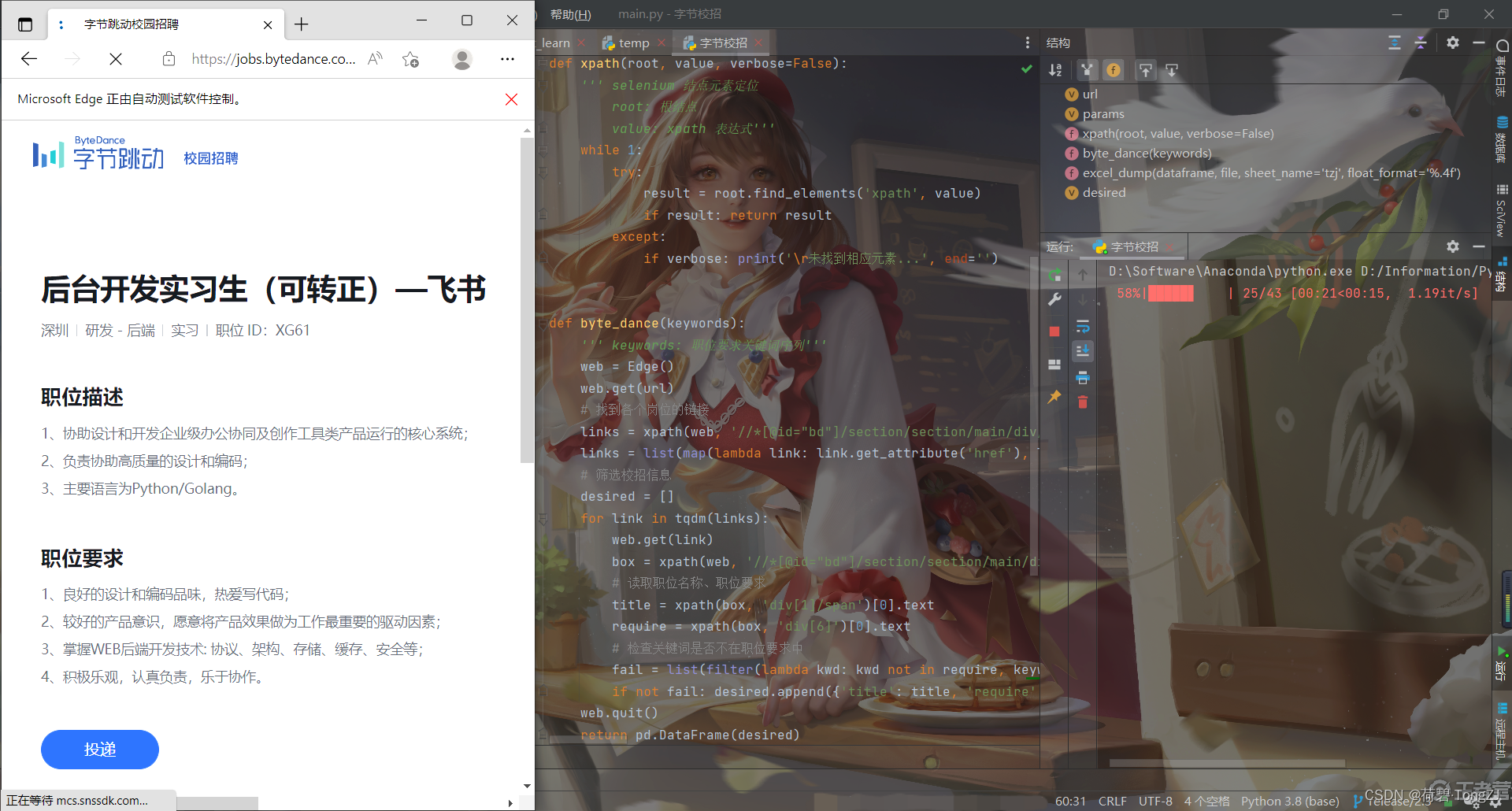
最近常想,Python 可以到哪些岗位就职?
于是我便瞄到了字节跳动的校招网站 https://jobs.bytedance.com/campus/position?,想用 requests 模块来爬取 Python 相关的岗位
但众所周知,get 请求爬到网页源代码不是难事,难的地方在找到目标数据对应的 post 请求
为了避开这“蛋疼”的一环,直接在浏览器操作得了 —— 于是 selenium 它来了
 与 requests 不同,selenium 只需要输入一个 get 请求就完事了首先编辑目标的 url 的参数:
与 requests 不同,selenium 只需要输入一个 get 请求就完事了首先编辑目标的 url 的参数:
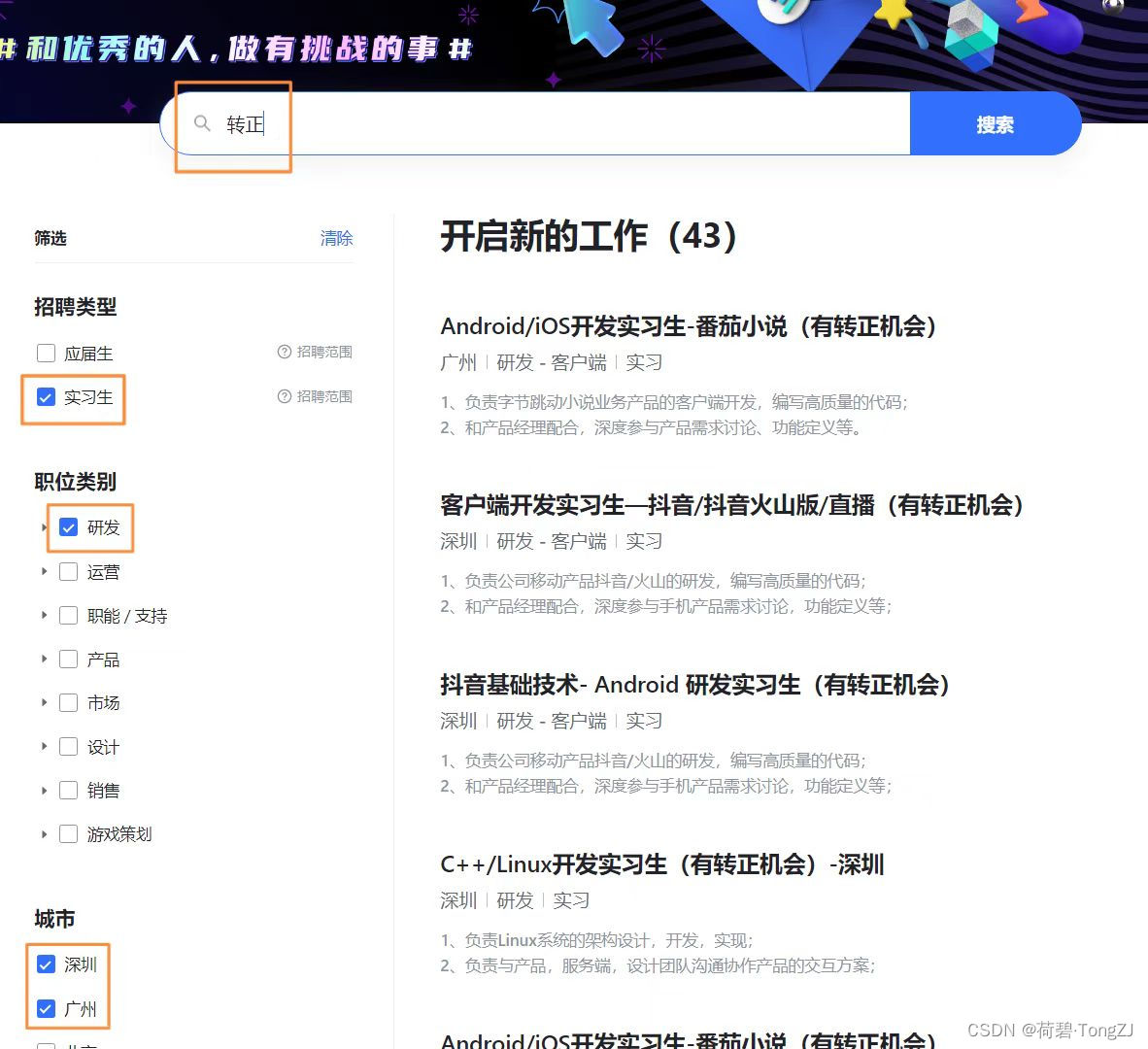
- 在校招网站选中这些选项之后,浏览器顶上的网址会发生变化(先不看职位类别),可以发现“?”后是若干个键值对:
https://jobs.bytedance.com/campus/position?keywords=转正&location=CT_128%2CCT_45&type=3¤t=1&limit=10
- keywords:搜索框的文本
- location:工作城市,简短的代码
- category:职位类型,非常长的代码
- type:3 代表实习生岗位
- current:当前页的编号(可不设置)
- limit:每一页显示的岗位数,为了让筛选后的所有岗位都在第一页,直接设为 10000
解析新的网址中的键值对,并修改代码中 params 字典的 keywords、location、category、type,使用 for 循环即可拼接得到最终的 url
import pandas as pd
from selenium.webdriver import Edge
from tqdm import tqdm
url = f'https://jobs.bytedance.com/campus/position?'
params = {
'keywords': '转正', # 搜索关键词
'location': 'CT_45%2CCT_128', # 工作城市: 广州, 深圳
'category': '6704215862603155720%2C6704215862557018372%2C6704215956018694411%2C6704215886108035339%2C6704215957146962184%2C6704215897130666254%2C6704215958816295181%2C6704215888985327886%2C6704215963966900491%2C6704216109274368264%2C6704217321877014787%2C6704219452277262596%2C6704216635923761412%2C6704219534724696331%2C6704216296701036811%2C6938376045242353957',
# 职位类型: 研发
'type': 3, # 招聘类型: 实习生
'limit': 10000 # 页面职位显示
}
for key in params:
url += f'{key}={params[key]}&'
与 requests 不同的是,selenium 不需要 post 请求,但是需要等待网页加载,所以需要一个 while 循环来等待网页加载完,再使用 xpath 进行结点的定位
def xpath(root, value, verbose=False):
''' selenium 结点元素定位
root: 根结点
value: xpath 表达式
verbose: 输出调试信息'''
while 1:
try:
result = root.find_elements('xpath', value)
if result:
return result if len(result) != 1 else result[0]
except:
if verbose: print('\r未找到相应元素...', end='')
通过网页检查,找到对应岗位链接的位置,拷贝 xpath 再修改一波,就可以得到该页面所有岗位的链接
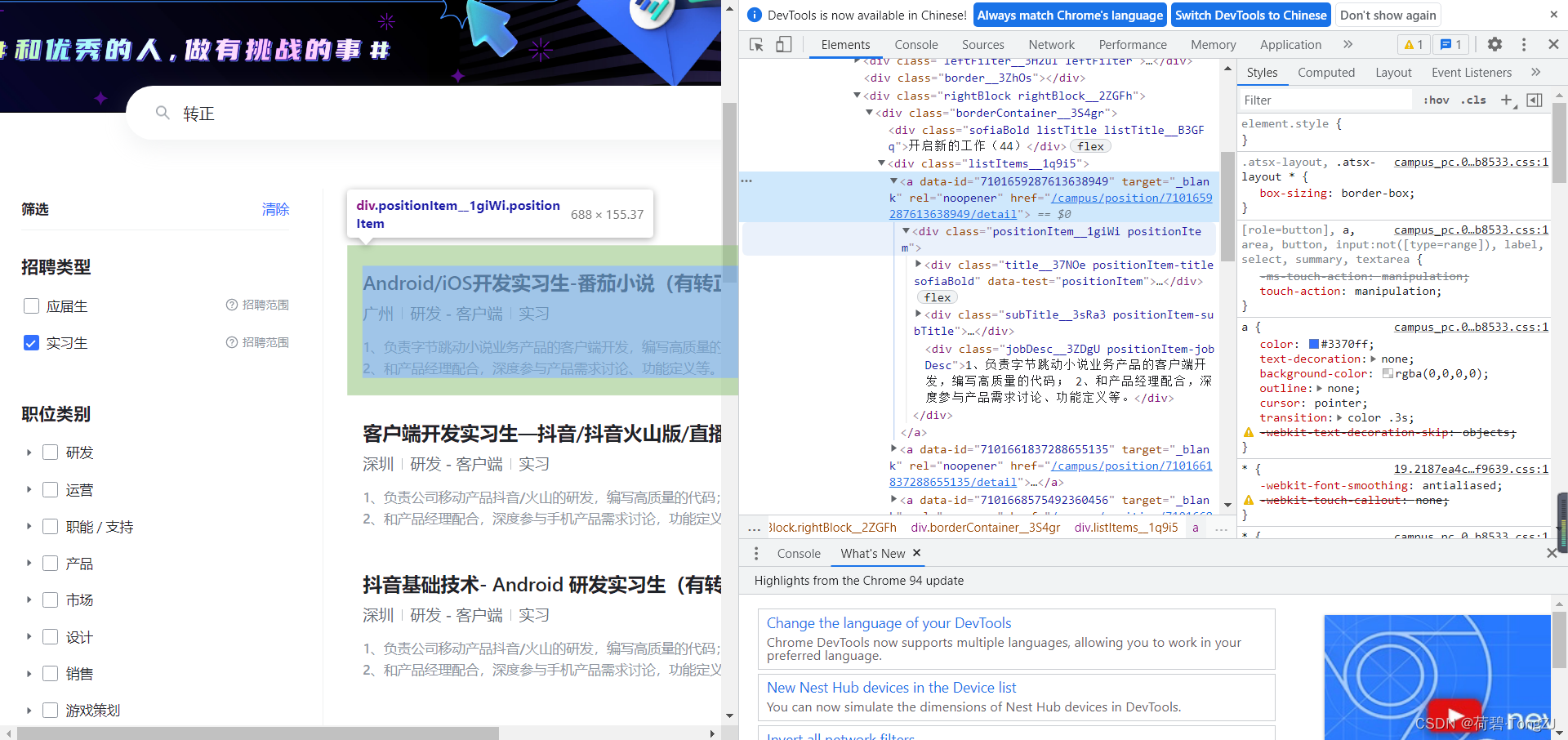
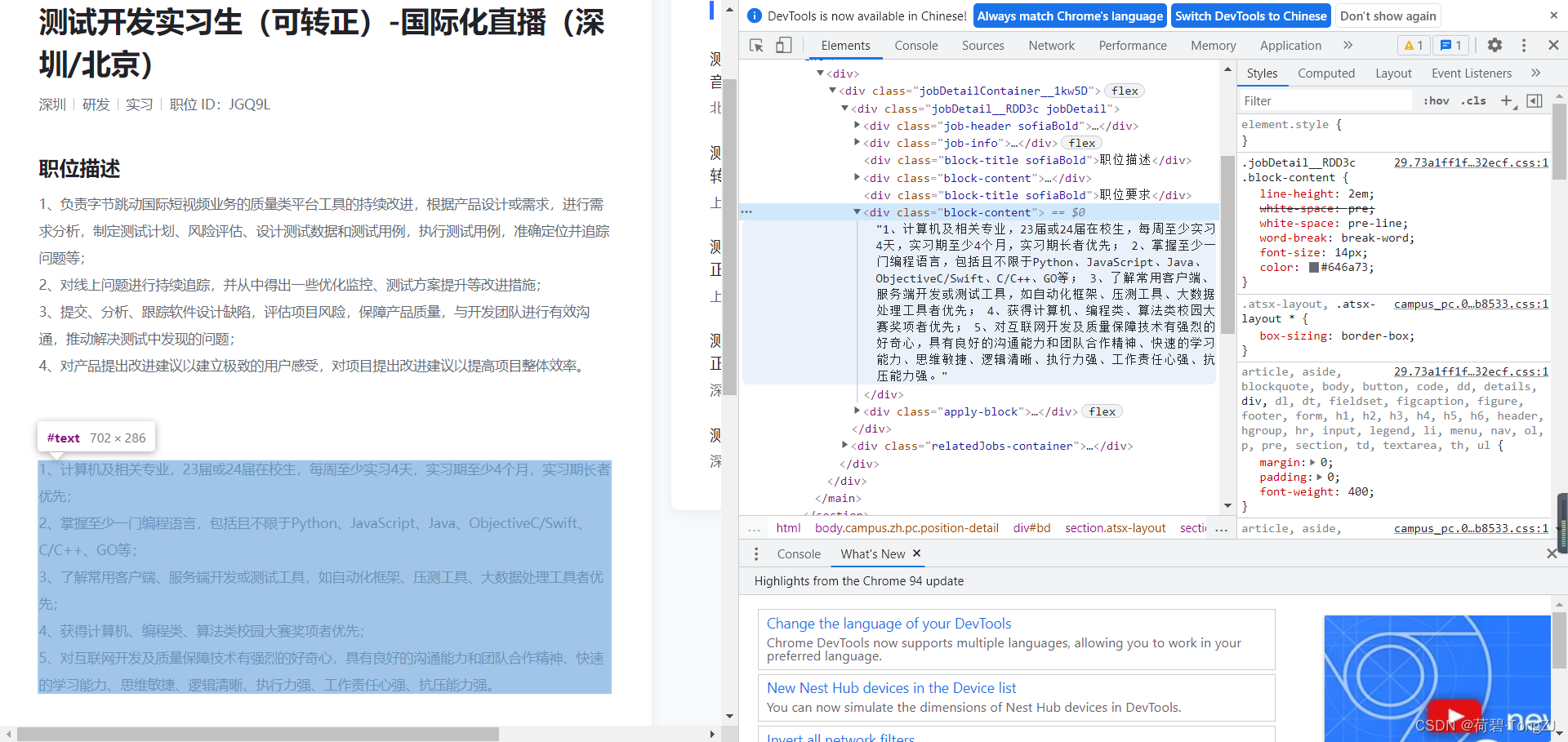
故技重施,再找到岗位连接中“职位要求”的位置(还可以找标题的位置),就可以写出主函数了
def byte_dance(keywords=[], stopwords=[]):
''' keywords: 关键词序列
stopwords: 停用词序列'''
web = Edge()
web.get(url)
# 找到各个岗位的链接
links = xpath(web, '//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a', verbose=True)
links = list(map(lambda link: link.get_attribute('href'), links))
# 筛选校招信息
desired = []
for link in tqdm(links):
web.get(link)
box = xpath(web, '//*[@id="bd"]/section/section/main/div/div/div[1]')
# 读取职位名称、职位要求
title = xpath(box, 'div[1]/span').text
require = xpath(box, 'div[6]').text
# 检查关键词是否不在职位要求中
fail = list(filter(lambda kwd: kwd not in require, keywords)) + \
list(filter(lambda swd: swd in require, stopwords))
if not fail: desired.append({'link': link, 'title': title, 'require': require})
web.quit()
return pd.DataFrame(desired)
最后使用 pandas 的 ExcelWriter 把筛选后的数据写入 Excel
def excel_dump(dataframe, file, sheet_name='tzj', float_format='%.4f'):
writer = pd.ExcelWriter(file)
dataframe.to_excel(writer, sheet_name=sheet_name, float_format=float_format)
writer.save()
desired = byte_dance(keywords=['Python'], stopwords=[])
print(desired)
excel_dump(desired, '字节校招.xlsx')
所有“职位要求”中出现“Python”的岗位有:
link测试开发实习生(可转正)-国际化直播(深圳/北京) - 加入字节跳动抖音图形图像算法实习生(可转正) - 加入字节跳动后台开发实习生- 存储(有转正机会) - 加入字节跳动后台开发实习生 - 基础架构 — 有转正机会 - 加入字节跳动后端开发实习生-抖音/火山/国际化视频(有转正机会) - 加入字节跳动后台开发实习生 — 广告系统(可转正) - 加入字节跳动推荐算法实习生-抖音(有转正机会) - 加入字节跳动算法实习生—风控方向 — 有转正机会 - 加入字节跳动测试开发实习生-广告系统(可转正) - 加入字节跳动
版权归原作者 荷碧TongZJ 所有, 如有侵权,请联系我们删除。