
先说在本机环境下的测试结果,仅供参考,其中单次调用时测试了10次,多次调用时测试了5次:
单次读取时,h5py文件整体平均读取速度最快,pkl文件整体平均读取最慢
多次读取(循环读取同一文件10次,并取平均时间)时,pt文件平均读取速度最快,pkl文件平均读取速度最慢
需要注意的是,每个文件类型读取出的数据类型不同,如果需要特定的数据类型,那么当数据读取后还需要增加数据类型转换时间,比如存储[1000000, 1024]维的数据时,若提取需要的是torch类型数据,那么存储为h5py文件后读取时需要进行数据转换,所以可以在存储数据时直接使用pt文件存储,此时读取时就不需要类型转换。*(我踩的坑,从h5py读取的时又使用了数据类型转换,从而导致读取很慢(读一个文件要几分钟))*
文件类型h5pynpyptpkl读取出的数据类型numpy.ndarraynumpy.ndarraytorch.Tensor写入时的数据类型
以单次运行时间为准(单位:秒,测试10次):
文件类型单次运行时间(最长)单次运行时间(最短)单次运行时间(平均)h5py2.93996381759643552.36473512649536132.56110846996307npy2.8137390613555912.63155817985534672.72723414897918pt3.10110402107238772.74818468093872072.90884675979614pkl4.7227799892425544.3556363582611084.56104216575622
以多次运行(循环读取同一文件10次,并取平均时间)时间为准(单位:秒,测试5次):
文件类型多次运行时间(最长)多次运行时间(最短)多次运行时间(平均)h5py2.883736968040462.549241495132442.74235633373260npy2.825995516777032.585924792289732.70383455276489pt2.630723237991332.412575984001152.53340683937072pkl4.052107238769533.870741105079653.96310455799102
1 前言
使用背景:需要保存通过包括但不限于torch及numpy创建的数据(在这里主要测试的是通过神经网络训练,提取到的图片的特征向量)
数据格式及大小:在这里使用torch创建数据,没有使用GPU(已经是该配置下能运行的最大数据量了,否则会爆内存),几个文件类型存储的data是同一个data
data = torch.Tensor(1000000, 1024)
运行环境:具体参数参考R9000P 2021 3070版本;数据存储在新加的固态上型号是三星1tb 980
测试内容:测试python主要的几种存储数据方式包括:h5py、npy、pkl、pt的读取速度。同时,测试分为单次运行与多次运行(单次运行循环读取10次),其分别在不同的py文件下(需在不同py文件下测试,同时每个文件类型的测试也需要在不同py文件下测试,且同一文件类型不能连续测试,否则会存在缓存影响测试结果)。
2 测试
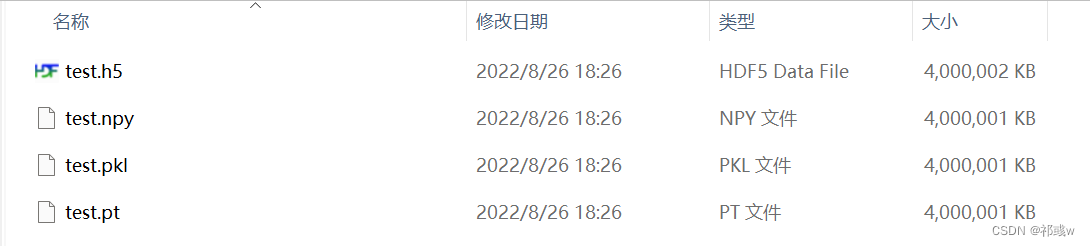
存储文件大小, 几种文件存储大小基本相同
各文件类型单次运行(各文件类型读取时,在不同的py文件中)时,运行速度如下(单位:秒):
测试次数\文件类型h5pynpyptpkl12.93996381759643552.79083347320556642.97623515129089364.64339232444763222.50502777099609382.8137390613555912.78382349014282234.72277998924255432.6480834484100342.7420823574066162.82365822792053224.45490670204162642.49424743652343752.7492535114288332.74818468093872074.35563635826110852.54875588417053222.6962442398071292.99886083602905274.572165727615356462.43211889266967772.71380496025085453.10110402107238774.61289024353027372.495032310485842.63155817985534672.926187276840214.619071483612060582.36473512649536132.7702360153198242.8241739273071294.56833457946777392.52039599418640142.6661517620086673.0058691501617434.478247404098511102.6627240180969242.69843792915344242.90037083625793464.582996845245361平均2.561108469963072.727234148979182.908846759796144.56104216575622
各文件类型多次运行(单次运行时循环读取10次,并取平均)时,其平均运行速度如下(单位:秒):
测试次数\文件类型h5pynpyptpkl12.883736968040462.825995516777032.412575984001153.8707411050796522.549241495132442.635262680053712.569122266769404.0521072387695332.577158784866332.585924792289732.539957523345943.9141227483749342.805909895896912.794499516487122.514655184745783.9607506990432752.895734524726862.677490258216852.630723237991334.01780099868774平均2.742356333732602.703834552764892.533406839370723.96310455799102
2.1 h5py文件存取
# 存储
f = h5py.File('./datasets/test.h5', 'w')
f.create_dataset('features', data=data)
f.close()
"""
单次运行
"""
start = time.time()
f = h5py.File('./datasets/test.h5', 'r')
vecs = f['features'][()]
f.close()
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
f = h5py.File('./datasets/test.h5', 'r')
vecs = f['features'][()]
f.close()
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))
2.2 npy文件存取
# 存储
np.save('./datasets/test.npy', data)
"""
单次运行
"""
start = time.time()
vecs_npy = np.load('./datasets/test.npy')
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
vecs_npy = np.load('./datasets/test.npy')
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))
2.3 pt文件存取
# 存储
torch.save(data, './datasets/test.pt')
"""
单次运行
"""
start = time.time()
vecs_pt = torch.load('./datasets/test.pt')
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
vecs_pt = torch.load('./datasets/test.pt')
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))
2.4 pkl文件存取
# 存储
f = open('./datasets/test.pkl', 'wb')
pickle.dump(data, f)
f.close()
"""
单次运行
"""
start = time.time()
f = open('./datasets/test.pkl', 'rb+')
vecs_pkl = pickle.load(f)
f.close()
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
f = open('./datasets/test.pkl', 'rb+')
vecs_pkl = pickle.load(f)
f.close()
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))
版权归原作者 祁彧w 所有, 如有侵权,请联系我们删除。