
关于Excel数据处理,Pyhton有pandas库和openpyxl、xlwings 模块模块可以对Excel数据进行处理,下面对pandas和openpyxl处理数据进行简单比对。
1、读取效率
我们采用83*20的数据集(该数据集为稀疏矩阵)进行读取数据的耗时统计。
pandas代码如下:
import time
import numpy as np
import pandas as pd
start_time = time.time()
wb = pd.read_excel('C:/Users/.../职协/职协招新/9_扫楼总工作表(1).xlsx')
print(wb)
end_time = time.time()
print(end_time - start_time)
结果为:

openpyxl代码如下:
# 导入模块,查看属性
import openpyxl
root_path = 'C:/Users/10692/Desktop/职协/职协招新/'
wb = openpyxl.load_workbook(root_path + '9_扫楼总工作表(1).xlsx')
import time
start_time = time.time()
sheet = wb.active
for column in sheet.columns:
for cell in column:
print(cell.value, end=', ')
print()
end_time = time.time()
print(end_time - start_time)
结果为:
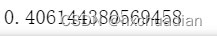
可见在读取方面, openpyxl效率会更快一些。
2、数据整理
pandas读取数据是从头开始,从单元格A1开始连续读取表格,若首行存在缺失值则该位置的标题表头就会变成Unnamed:i (i=1,2...n)
pandas可以轻松地读取和转换Excel数据,但是面对杂乱的表格结构,分散在不同工作表的数据或是范围性数值的数据(如数值为'5-7'),以及表格中分布很乱时,直接使用pandas进行数据清洗相对比较吃力。这时使用openpyxl先对数据简单整理会更为方便。
但是进一步对数据进行探索分析,openpyxl并无法做到,需要pandas对数据进行探索分析。所以,对于数据我们可以先利用openpyxl对数据简单整理再利用pandas对数据进行进一步探索分析效率。
本文转载自: https://blog.csdn.net/hxchuadian/article/details/125826197
版权归原作者 hxchuadian 所有, 如有侵权,请联系我们删除。
版权归原作者 hxchuadian 所有, 如有侵权,请联系我们删除。