
文章目录
介绍:使用Spark进行特征工程
问题:在“特征工程”中,我们开发了一个自动化特征工程的流水线,使用客户交易和标签时间的数据集。在单个客户分区上运行此流水线需要大约15分钟,这意味着如果一个一个地完成所有功能,则需要几天时间。
解决方案:将数据集分成独立的客户分区,并并行运行多个子集。这可以使用单个机器上的多个处理器或机器集群来完成。
使用PySpark的Spark
第一步是初始化Spark。我们可以使用“findspark”库确保“pyspark”可以在Jupyter Notebook中找到Spark。本笔记本假定Spark集群已经运行。要开始使用Spark集群,请参阅[此指南](https://data-flair.training/blogs/install-apache-spark-multi-node-cluster/)。
(我们将跳过本笔记本中的Featuretools详细信息,但是有关介绍,请参见[本文](https://towardsdatascience.com/automated-feature-engineering-in-python-99baf11cc219)。有关手动和自动特征工程的比较,请参见[本文](https://towardsdatascience.com/why-automated-feature-engineering-will-change-the-way-you-do-machine-learning-5c15bf188b96)。)
# 导入findspark模块import findspark
# 根据你的安装情况进行更新
findspark.init()
设置Spark
SparkContext
是与正在运行的Spark集群交互的接口。我们使用
SparkConf
对象向
SparkContext
传递许多参数。具体来说,我们将打开日志记录,告诉Spark在我们的机器上使用12个核心,并将Spark指向主节点(父节点)的位置。
根据您的集群设置调整参数。我发现这个指南在选择参数方面很有帮助。
# 导入pyspark模块import pyspark
# 根据你的安装更新配置
conf = pyspark.SparkConf()# 启用日志记录
conf.set('spark.eventLog.enabled',True);
conf.set('spark.eventLog.dir','./data/tmp/');# 使用所有机器上的所有核心
conf.set('spark.num.executors',1)
conf.set('spark.executor.memory','12g')
conf.set('spark.executor.cores',12)# 设置父节点
conf.set('spark.master','spark://AMB-R09BLVCJ:7077')# 获取所有配置信息
conf.getAll()
测试Spark
在进行特征工程之前,我们想要测试我们的集群是否正常运行。我们将实例化一个
Spark
集群,并运行一个简单的程序来计算pi的值。
sc = pyspark.SparkContext(appName="pi_calc",
conf = conf)
sc
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/usr/local/Cellar/apache-spark/3.2.1/libexec/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/02/09 16:33:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable

num_samples =100000000import random
definside(p):
x, y = random.random(), random.random()return x*x + y*y <1# Parallelize counting samples inside circle using Spark
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi =4* count / num_samples
print(pi)
sc.stop()
3.14170524
Spark 仪表盘
在从命令行启动 Spark 集群之后,在运行笔记本中的任何代码之前,您可以在 localhost:8080 上查看集群的仪表盘。这显示基本信息,如工作节点的数量以及当前正在运行或已完成的作业。

一旦初始化了
SparkContext
,可以在 localhost:4040 上查看作业。这显示特定的细节,如已完成的任务数量和操作的有向无环图。
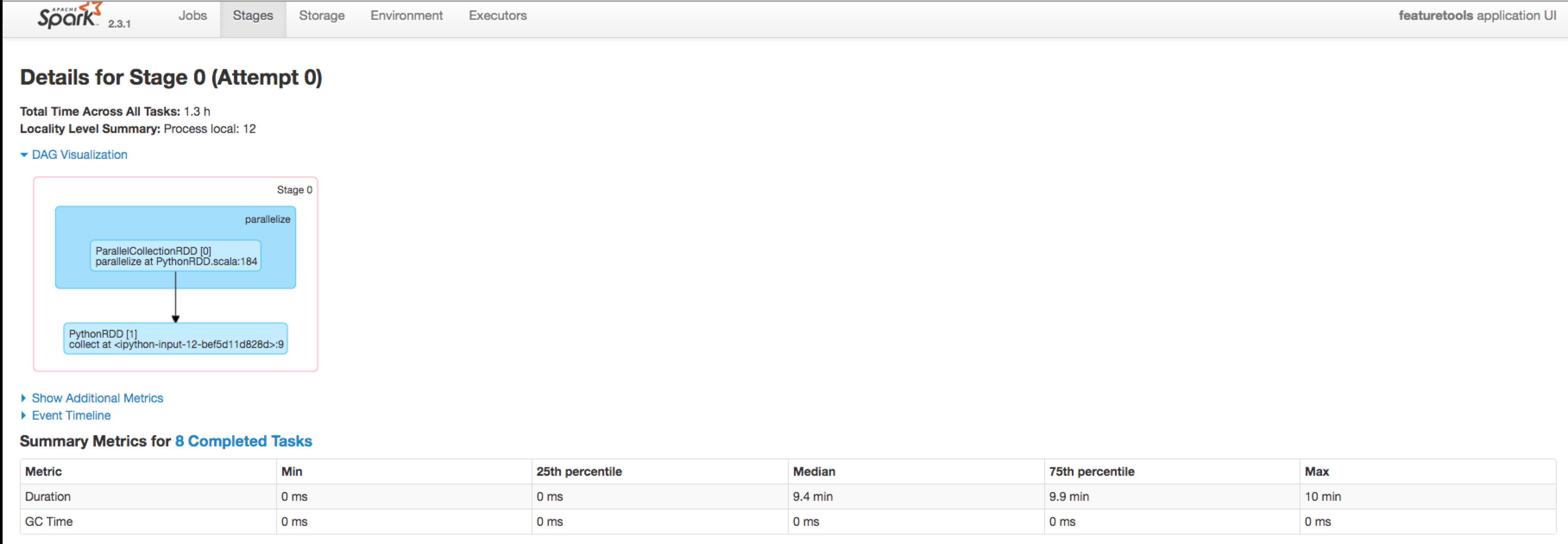
使用 Web 仪表盘可以帮助调试集群。
一旦集群正常运行,我们可以开始进行特征工程。
数据存储
在之前的笔记本中,我们对数据进行了分区,并为前50个分区创建了特征矩阵。通常情况下,运行Spark的所有读写都会通过S3进行,但是在这个示例中,我们将使用本地文件。
# 导入必要的库import os
import pandas as pd
import featuretools as ft
import warnings
# 忽略警告信息
warnings.simplefilter('ignore')# 设置分区数和当前工作目录
partition =20
CWD = os.getcwd()# 设置数据文件目录和截断时间文件名
directory =f'{CWD}/data/partitions/p'+str(partition)
cutoff_times_file ='MS-31_labels.csv'# 读取数据文件
members = pd.read_csv(f'{directory}/members.csv',
parse_dates=['registration_init_time'],
infer_datetime_format =True,
dtype ={'gender':'category'})
trans = pd.read_csv(f'{directory}/transactions.csv',
parse_dates=['transaction_date','membership_expire_date'],
infer_datetime_format =True)
logs = pd.read_csv(f'{directory}/logs.csv', parse_dates =['date'])
cutoff_times = pd.read_csv(f'{directory}/{cutoff_times_file}', parse_dates =['time'])
cutoff_times = cutoff_times.drop_duplicates(subset =['msno','time'])
/Users/nate.parsons/dev/open_source_demos/env/lib/python3.8/site-packages/statsmodels/compat/pandas.py:65: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
from pandas import Int64Index as NumericIndex
特征工程
首先,我们将使用单个分区来创建特征集,这样我们就不必为每个分区重新计算它们。这也确保了对于每个客户子集都创建了完全相同的特征。(还可以从磁盘加载计算好的特征。)再次,我跳过了这里正在进行的操作的解释,所以请查看Featuretools文档或一些在线教程。
一个分区的特征
# 创建一个空的实体集
es = ft.EntitySet(id='customers')# 添加成员父表
es.add_dataframe(dataframe_name='members', dataframe=members,
index ='msno', time_index ='registration_init_time',
logical_types ={'city':'Categorical','bd':'Categorical','registered_via':'Categorical'})# 在交易中创建新的特征
trans['price_difference']= trans['plan_list_price']- trans['actual_amount_paid']
trans['planned_daily_price']= trans['plan_list_price']/ trans['payment_plan_days']
trans['daily_price']= trans['actual_amount_paid']/ trans['payment_plan_days']# 添加交易子表
es.add_dataframe(dataframe_name='transactions', dataframe=trans,
index ='transactions_index', make_index =True,
time_index ='transaction_date',
logical_types ={'payment_method_id':'Categorical','is_auto_renew':'Boolean','is_cancel':'Boolean'})# 添加交易有趣的值
es.add_interesting_values(dataframe_name='transactions',
values={'is_cancel':[False,True],'is_auto_renew':[False,True]})# 在日志中创建新的特征
logs['total']= logs[['num_25','num_50','num_75','num_985','num_100']].sum(axis =1)
logs['percent_100']= logs['num_100']/ logs['total']
logs['percent_unique']= logs['num_unq']/ logs['total']# 添加日志子表
es.add_dataframe(dataframe_name='logs', dataframe=logs,
index ='logs_index', make_index =True,
time_index ='date')# 添加关系
r_member_transactions = ft.Relationship(es,'members','msno','transactions','msno')
r_member_logs = ft.Relationship(es,'members','msno','logs','msno')
es.add_relationships([r_member_transactions, r_member_logs])# 返回实体集
es
自定义基元
以下是我们为此数据集编写的自定义基元(请参见“特征工程”笔记本)。它计算上个月某种数量的总量。
deftotal_previous_month(numeric, datetime, time):"""返回`time`之前一个月的`numeric`列的总和。"""
df = pd.DataFrame({'value': numeric,'date': datetime})
previous_month = time.month -1
year = time.year
# 处理一月份if previous_month ==0:
previous_month =12
year = time.year -1# 过滤数据并计算总和
df = df[(df['date'].dt.month == previous_month)&(df['date'].dt.year == year)]
total = df['value'].sum()return total
# 导入所需的库from featuretools.primitives import make_agg_primitive
from woodwork.column_schema import ColumnSchema
from woodwork.logical_types import Datetime
# 创建一个数值类型的列模式
numeric = ColumnSchema(semantic_tags={'numeric'})# 创建一个日期时间类型的列模式
datetime = ColumnSchema(logical_type=Datetime)# 创建一个聚合原语,接受一个数字和一个日期时间作为输入,返回一个数字作为输出
total_previous = make_agg_primitive(total_previous_month, input_types=[numeric, datetime],
return_type=numeric,
uses_calc_time=True)
运行深度特征合成
第一次创建特征时,我们使用
ft.dfs
函数,传入所选的基元、目标数据帧、关键的
cutoff_time
、要堆叠的特征的深度以及其他几个参数。
# 指定聚合特征
agg_primitives =['sum','time_since_last','avg_time_between','num_unique','min','last','percent_true','max','count']# 指定转换特征
trans_primitives =['is_weekend','cum_sum','day','month','time_since_previous']# 指定where特征
where_primitives =['sum','mean','percent_true']
# 运行深度特征合成# feature_matrix:特征矩阵,包含生成的特征# feature_defs:特征定义,包含生成的特征的详细信息
feature_matrix, feature_defs = ft.dfs(entityset=es, target_dataframe_name='members',
cutoff_time = cutoff_times,
agg_primitives = agg_primitives,
trans_primitives = trans_primitives,
where_primitives = where_primitives,
max_depth =2, features_only =False,
chunk_size =100, n_jobs =1, verbose =1)
Built 316 features
Elapsed: 24:05 | Progress: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████
这些特征定义可以保存在磁盘上。每次我们想要生成完全相同的特征时,只需将它们传递给
ft.calculate_feature_matrix
函数。
# 将特征定义保存到文件中
ft.save_features(feature_defs,f'{CWD}/data/features.txt')
# 加载特征定义文件
feature_defs = ft.load_features(f'{CWD}/data/features.txt')# 打印特征数量print(f'There are {len(feature_defs)} features.')
There are 316 features.
将分区转换为特征矩阵的函数
本笔记本的主要功能是从单个分区中生成特征。
这个函数
partition_to_feature_matrix
执行以下操作:
- 接收一个分区的名称
- 从分区目录中读取数据
- 从数据中创建一个实体集
- 计算该分区的特征矩阵
- 将特征矩阵保存到分区目录中
请注意,由于时间和磁盘空间的限制,我们只会在前20个分区上运行此函数,而不是在第一个笔记本中创建的全部1000个分区上运行。
# 定义一个常量,表示分区数量
N_PARTITIONS =20# 定义一个基础目录,用于存储分区数据
BASE_DIR =f'{CWD}/data/partitions/'defpartition_to_feature_matrix(partition, feature_defs = feature_defs,
cutoff_time_name ='MS-31_labels.csv', write =True):"""输入一个分区号,创建特征矩阵,并保存到磁盘上
参数
--------
partition (int): 分区号
feature_defs (list of ft features): 分区要创建的特征
cutoff_time_name (str): 截止时间文件的名称
write: (boolean): 是否将数据写入磁盘。默认为True
返回
--------
None: 将特征矩阵保存到磁盘上
"""# 拼接分区目录
partition_dir = BASE_DIR +'p'+str(partition)# 读取数据文件
members = pd.read_csv(f'{partition_dir}/members.csv',
parse_dates=['registration_init_time'],
infer_datetime_format =True,
dtype ={'gender':'category'})
trans = pd.read_csv(f'{partition_dir}/transactions.csv',
parse_dates=['transaction_date','membership_expire_date'],
infer_datetime_format =True)
logs = pd.read_csv(f'{partition_dir}/logs.csv', parse_dates =['date'])# 确保删除重复项
cutoff_times = pd.read_csv(f'{partition_dir}/{cutoff_time_name}', parse_dates =['time'])
cutoff_times = cutoff_times.drop_duplicates(subset =['msno','time'])# 保存所需的截止时间
cutoff_spec = cutoff_time_name.split('_')[0]# 创建空实体集
es = ft.EntitySet(id='customers')# 添加父表members
es.add_dataframe(dataframe_name='members', dataframe=members,
index ='msno', time_index ='registration_init_time',
logical_types ={'city':'Categorical','registered_via':'Categorical'})# 在transactions中创建新特征
trans['price_difference']= trans['plan_list_price']- trans['actual_amount_paid']
trans['planned_daily_price']= trans['plan_list_price']/ trans['payment_plan_days']
trans['daily_price']= trans['actual_amount_paid']/ trans['payment_plan_days']# 添加子表transactions
es.add_dataframe(dataframe_name='transactions', dataframe=trans,
index ='transactions_index', make_index =True,
time_index ='transaction_date',
logical_types ={'payment_method_id':'Categorical','is_auto_renew':'Boolean','is_cancel':'Boolean'})# 添加transactions的有趣值
es.add_interesting_values(dataframe_name='transactions',
values={'is_cancel':[False,True],'is_auto_renew':[False,True]})# 在logs中创建新特征
logs['total']= logs[['num_25','num_50','num_75','num_985','num_100']].sum(axis =1)
logs['percent_100']= logs['num_100']/ logs['total']
logs['percent_unique']= logs['num_unq']/ logs['total']
logs['seconds_per_song']= logs['total_secs']/ logs['total']# 添加子表logs
es.add_dataframe(dataframe_name='logs', dataframe=logs,
index ='logs_index', make_index =True,
time_index ='date')# 添加关系
r_member_transactions = ft.Relationship(es,'members','msno','transactions','msno')
r_member_logs = ft.Relationship(es,'members','msno','logs','msno')
es.add_relationships([r_member_transactions, r_member_logs])# 使用预先计算的特征计算特征矩阵
feature_matrix = ft.calculate_feature_matrix(entityset=es, features=feature_defs,
cutoff_time=cutoff_times, cutoff_time_in_index =True,
chunk_size =1000)if write:# 将特征矩阵写入磁盘
bytes_to_write = feature_matrix.to_csv(None).encode()withopen(f'{partition_dir}/{cutoff_spec}_feature_matrix.csv','wb')as f:
f.write(bytes_to_write)
测试函数
让我们使用2个不同的分区对函数进行测试。
# 导入计时器模块from timeit import default_timer as timer
# 记录开始时间
start = timer()# 调用函数partition_to_feature_matrix,传入参数10、feature_defs、'MS-31_labels.csv',并设置write参数为True
partition_to_feature_matrix(10, feature_defs,'MS-31_labels.csv', write=True)# 记录结束时间
end = timer()# 打印程序运行时间print(f'{round(end - start)} seconds elapsed.')
227 seconds elapsed.
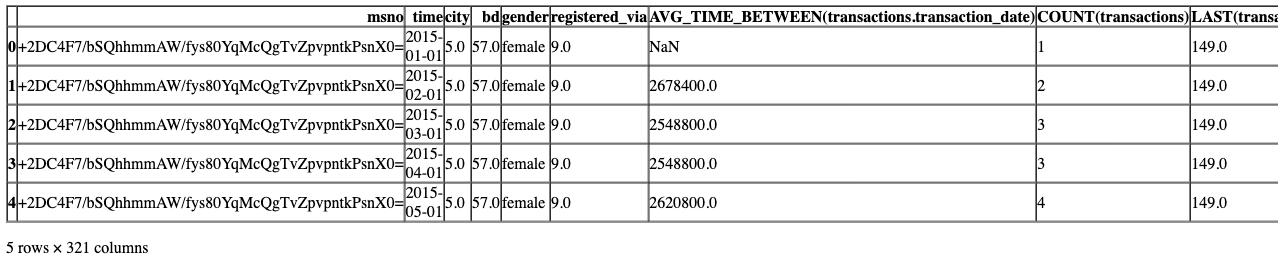
# 读取csv文件并存储在feature_matrix变量中# f'{BASE_DIR}/p10/MS-31_feature_matrix.csv'是文件的路径,BASE_DIR是文件所在的目录# low_memory=False表示不对数据类型进行自动推断,以节省内存
feature_matrix = pd.read_csv(f'{BASE_DIR}/p10/MS-31_feature_matrix.csv', low_memory=False)# 显示feature_matrix的前几行数据
feature_matrix.head()
start = timer()
partition_to_feature_matrix(19, feature_defs,'MS-31_labels.csv', write=True)
end = timer()print(f'{round(end - start)} seconds elapsed.')
269 seconds elapsed.
# 读取csv文件,并将结果存储在feature_matrix变量中
feature_matrix = pd.read_csv(f'{BASE_DIR}/p19/MS-31_feature_matrix.csv', low_memory =False)# 显示feature_matrix的前几行数据
feature_matrix.head()

使用Spark运行
下一个单元格使用Spark并行化进行所有特征工程计算。我们希望将分区映射到函数,并让Spark在执行器之间分配工作,每个执行器都是一台机器上的一个核心。
# 创建分区列表
partitions =list(range(N_PARTITIONS))# 创建Spark上下文 - 根据您的配置进行更新
sc = pyspark.SparkContext(master='spark://AMB-R09BLVCJ:7077',
appName='featuretools', conf=conf)# 并行化特征工程
r = sc.parallelize(partitions, numSlices=N_PARTITIONS).\
map(lambda x: partition_to_feature_matrix(x, feature_defs,'MS-31_labels.csv')).collect()
sc.stop()
以下是集群的整体状态。

以下是关于提交的作业的信息。

合并数据
从这里开始,我们可以读取所有分区的特征矩阵并构建一个单一的特征矩阵,或者如果我们有一个支持增量(也称为在线)学习的模型,我们可以一次训练一个分区。
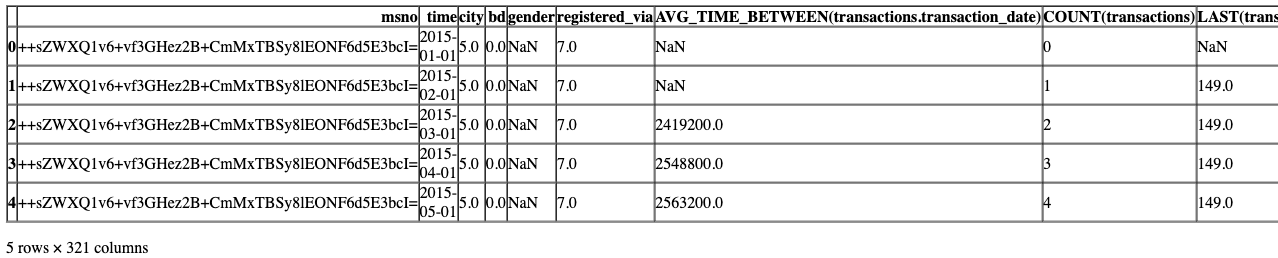
# 读取特征矩阵数据文件
feature_matrix = pd.read_csv(f'{BASE_DIR}/p19/MS-31_feature_matrix.csv', low_memory =False)# 显示特征矩阵的前几行数据
feature_matrix.head()
结论
在这个笔记本中,我们看到了如何使用Spark框架在Featuretools中分布式特征工程。这个大数据处理技术让我们使用多台计算机并行计算,即使在大型数据集上也能实现高效的数据科学工作流程。
基本方法是:
- 将数据分成独立的分区
- 使用不同的工作器并行运行每个子集
- 如有必要,将结果合并在一起
使用Dask和Spark等框架的好处是我们不必改变底层的Featuretools代码。我们在本机Python中编写代码,更改运行计算的后端,并将计算分布在一组机器上。使用这种方法,我们将能够扩展到任何大小的数据集,并解决更令人兴奋的数据科学和机器学习问题。
下一步
机器学习流程的最后一步是构建模型,以预测这些特征。这在“建模”笔记本中实现。
版权归原作者 愤斗的橘子 所有, 如有侵权,请联系我们删除。