
1. 什么是LLM的复读机问题
- 字符级别重复,指大模型针对一个字或一个词重复不断的生成例如在电商翻译场景上,会出现“steckdose steckdose steckdose steckdose steckdose steckdose steckdose steckdose…”;
- 语句级别重复,大模型针对一句话重复不断的生成例如在多模态大模型图片理解上,生成的结果可能会不断重复图片的部分内容,比如“这是一个杯子,这是一个杯子…”;
- 章节级别重复,多次相同的prompt输出完全相同或十分近似的内容,没有一点创新性的内容,比如你让大模型给你写一篇关于春天的小作文,结果发现大模型的生成结果千篇一律,甚至近乎一摸一样。
- 大模型针对不同的prompt也可能会生成类似的内容,且有效信息很少、信息熵偏低
2. 为什么会出现 LLMs 复读机问题?
- 数据偏差 大型语言模型通常是通过预训练阶段使用大规模无标签数据进行训练的。如果训练数据中存在大量的重复文本或者某些特定的句子或短语出现频率较高,模型在生成文本时可能会倾向于复制这些常见的模式。
- 训练目标的限制 大型语言模型的训练通常是基于自监督学习的方法,通过预测下一个词或掩盖词来学习语言模型。这样的训练目标可能使得模型更倾向于生成与输入相似的文本,导致复读机问题的出现。
- 缺乏多样性的训练数据 虽然大型语言模型可以处理大规模的数据,但如果训练数据中缺乏多样性的语言表达和语境,模型可能无法学习到足够的多样性和创造性,导致复读机问题的出现。
- 模型结构和参数设置 大型语言模型的结构和参数设置也可能对复读机问题产生影响。例如,模型的注意力机制和生成策略可能导致模型更倾向于复制输入的文本。
- 从 induction head[1]机制的影响角度 也就是模型会倾向于从前面已经预测的word里面挑选最匹配的词;在翻译上,由于input和output的天然差异性,你会发现容易出现重复的都是一些复杂度perplexity比较高的文本:也就是说input的句式越不常见,本身重复度越高,翻译结果重复的可能性也越高
3. 如何缓解LLMs复读机
3.1. Unlikelihood Training(相似性损失函数)
在训练中加入对重复词的抑制来减少重复输出,token,本身likelihood training loss是要促使模型学习到原标签中自然的语言逻辑,而修改后的loss不仅要促进模型学习到真实标签的语言自然性,也要通过unlikelihood loss抑制模型,使其尽量不生成集合C中的token。
L
UL-token
t
(
p
θ
(
⋅
∣
x
<
t
)
,
C
t
)
=
−
α
⋅
∑
c
∈
C
t
log
(
1
−
p
θ
(
c
∣
x
<
t
)
)
⏟
unlikelihood
−
log
p
θ
(
x
t
∣
x
<
t
)
⏟
likelihood
\mathcal{L}_{\text {UL-token }}^t\left(p_\theta\left(\cdot \mid x_{<t}\right), \mathcal{C}^t\right)=-\alpha \cdot \underbrace{\sum_{c \in \mathcal{C}^t} \log \left(1-p_\theta\left(c \mid x_{<t}\right)\right)}_{\text {unlikelihood }}-\underbrace{\log p_\theta\left(x_t \mid x_{<t}\right)}_{\text {likelihood }}
LUL-token t(pθ(⋅∣x<t),Ct)=−α⋅unlikelihood c∈Ct∑log(1−pθ(c∣x<t))−likelihood logpθ(xt∣x<t)
一般对于生成式任务,只需要在原模型基础上加入unlikelihood training进行sentence级别finetune即可,不需要通过token级别的unlikelihood和likelihood loss叠加训练。
3.2 引入噪音
在生成文本时,引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。这可以通过在生成过程中对模型的输出进行采样或添加随机性来实现。
3.3 Repetition Penalty(类似于不相似训练)
重复性惩罚方法通过在模型推理过程中加入重复惩罚因子,对原有softmax结果进行修正,降低重复生成的token被选中的概率
p
i
=
exp
(
x
i
/
(
T
⋅
I
(
i
∈
g
)
)
∑
j
exp
(
x
j
/
(
T
⋅
I
(
j
∈
g
)
)
p_i=\frac{\exp \left(x_i /(T \cdot I(i \in g))\right.}{\sum_j \exp \left(x_j /(T \cdot I(j \in g))\right.}
pi=∑jexp(xj/(T⋅I(j∈g))exp(xi/(T⋅I(i∈g))
I
(
c
)
=
θ
I(\boldsymbol{c})=\theta
I(c)=θ if
c
\mathrm{c}
c is True else 1
注:其中T代表温度,温度越高,生成的句子随机性越强,模型效果越不显著;I就代表惩罚项,c代表我们保存的一个list,一般为1-gram之前出现过的单词,theta值一般设置为1.2,1.0代表没有惩罚。
3.4 Contrastive Search(对贪心搜索的改进)
对比loss通过在原loss基础上添加对比loss,即对比token间相似度的方式去解决生成式模型重复单调问题。
x
t
=
arg
max
v
∈
V
(
k
)
{
(
1
−
α
)
×
p
θ
(
v
∣
x
<
t
)
⏟
model confidence
−
α
×
(
max
{
s
(
h
v
,
h
x
j
)
:
1
≤
j
≤
t
−
1
}
)
⏟
degeneration penalty
}
x_t=\underset{v \in V^{(k)}}{\arg \max }\{(1-\alpha) \times \underbrace{p_\theta\left(v \mid \boldsymbol{x}_{<t}\right)}_{\text {model confidence }}-\alpha \times \underbrace{\left(\max \left\{s\left(h_v, h_{x_j}\right): 1 \leq j \leq t-1\right\}\right)}_{\text {degeneration penalty }}\}
xt=v∈V(k)argmax{(1−α)×model confidence pθ(v∣x<t)−α×degeneration penalty (max{s(hv,hxj):1≤j≤t−1})}
s
(
h
x
i
,
h
x
j
)
=
h
x
i
⊤
h
x
j
∥
h
x
i
∥
⋅
∥
h
z
j
∥
s\left(h_{x_i}, h_{x_j}\right)=\frac{h_{x_i}^{\top} h_{x_j}}{\left\|h_{x_i}\right\| \cdot\left\|h_{z_j}\right\|}
s(hxi,hxj)=∥hxi∥⋅hzjhxi⊤hxj
token间相似度降低即不同token在高维空间表征分离能有效降低模型仅生成个别重复词或字的概率
。
3.5 Beam Search(解决局部最优解的问题)
Beam Search是对贪心策略一种改进。思路简单,就是稍微放宽考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索(Beam Search)就退化成了贪心搜索。Beam Search虽然本质上并没有降低重复率的操作,但是该策略确实在结果上优化了部分生成结果,降低了一定的重复率。
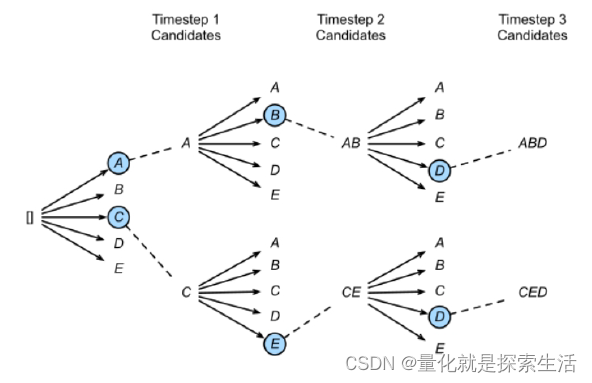
3.6 TopK sampling
TopK通过对Softmax的输出结果logit中最大的K个token采样来选择输出的token,该方法存在的问题是当概率分布很极端时,即模型很确定下一个token时,容易造成生成错误。以下图为例,TopK采样会选择最大的K个token,并通过logit值对K个token进行采样,相比于贪心搜索增添了随机性,相当于同样的输入,多次经过TopK采样生成的结果大概率不会一样。
TopK采样是一种行之有效,能简单暴力的解决1.1节中提出所有重复单调问题的方案之一,当然它存在的最大问题是最后生成的句子存在狗屁不通现象,并不能保证句子的通顺度以及对prompt的忠诚度。
3.7 Nucleus sampler
Nucleus sampler俗称TopP采样,一种用于解决TopK采样问题的新方法,该采样方式不限制K的数目,而是通Softmax后排序token的概率,当概率大于P时停止,相当于当模型很确定下一个token时,可采样的K也会很少,减少异常错误发生的概率。以下图为例,TopP采样会不断选择logit中最大概率的token,放入一个list中,直到list中计算的总概率大于设置的TopP值,后对list中的token概率进行重新计算,最终根据计算出来的概率值对list中的token进行采样。
Nucleus sampler是对简单暴力的TopK采样修改后的方法,也能解决1.1节中提出所有重复单调问题,相比TopK,该方法生成的句子通顺度以及对prompt的忠诚度更佳,一般选择它,而不选择TopK。
3.8 Temperature(温度策略)
Repetition Penalty 中的参数调整
3.9 No repeat ngram size
该方法是一种最暴力抑制重复的方法,通过限制设置的ngram不能出现重复,如果重复,就选概率次大的一个,来强制模型不生成重复的token。该功能一般都会开启,来保证生成的句子不犯很离谱的连续重复问题。
(该方法仅能解决前两种重复问题,无法解决输入多次相同prompt输出单调性的问题)
3.10 重复率指标检测
seq-rep-N,uniq-seq,rep,wrep。通过这些指标的融合,可以对重复生成的结果进行一定程度的监测,并在监测到异常生成结果时,通过加入特殊字符,修改prompt表达等形式来重新生成结果。
通过我们的测试,通过切分或加入特殊字符的方式确实能让本身异常的翻译结果恢复正常,但潜在风险是翻译的语序可能会出现一定的问题。(对其他领域生成结果的影响有待进一步探索)
版权归原作者 量化就是探索生活 所有, 如有侵权,请联系我们删除。