
写SQL的21个好习惯
- 写完SQL先explain查看执行计划(SQL性能优化) 日常开发写SQL的时候,尽量养成这个好习惯呀:写完SQL后,用explain分析一下,尤其注意走不走索引。
explainselect*fromuserwhere userid =10086or age =18;
- 操作delete或者update语句,加个limit(SQL后悔药) 在执行删除或者更新语句,尽量加上limit,以下面的这条 SQL 为例吧:
deletefrom euser where age >30limit200;
因为加了limit 主要有这些好处: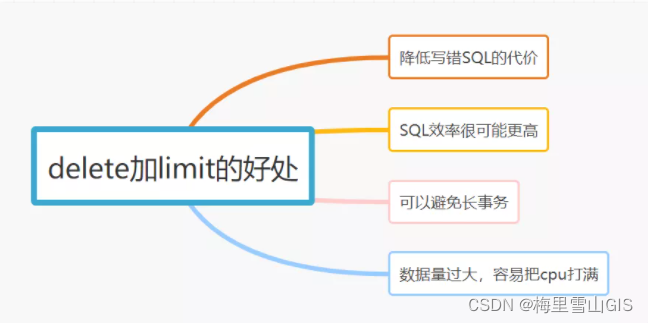
(1)「降低写错SQL的代价」, 你在命令行执行这个SQL的时候,如果不加limit,执行的时候一个「不小心手抖」,可能数据全删掉了,如果「删错」了呢?加了limit 200,就不一样了。删错也只是丢失200条数据,可以通过binlog日志快速恢复的。
(2)「SQL效率很可能更高」,你在SQL行中,加了limit 1,如果第一条就命中目标return, 没有limit的话,还会继续执行扫描表。
(3)「避免了长事务」,delete执行时,如果age加了索引,MySQL会将所有相关的行加写锁和间隙锁,所有执行相关行会被锁住,如果删除数量大,会直接影响相关业务无法使用。
(4)「数据量大的话,容易把CPU打满」 ,如果你删除数据量很大时,不加 limit限制一下记录数,容易把cpu打满,导致越删越慢的。
- 设计表的时候,所有表和字段都添加相应的注释(SQL规范优雅) 这个好习惯一定要养成啦,设计数据库表的时候,所有表和字段都添加相应的注释,后面更容易维护。
CREATETABLE`account`(`id`int(11)NOTNULLAUTO_INCREMENTCOMMENT'主键Id',`name`varchar(255)DEFAULTNULLCOMMENT'账户名',`balance`int(11)DEFAULTNULLCOMMENT'余额',`create_time`datetimeNOTNULLCOMMENT'创建时间',`update_time`datetimeNOTNULLONUPDATECURRENT_TIMESTAMPCOMMENT'更新时间',PRIMARYKEY(`id`),KEY`idx_name`(`name`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=1570068DEFAULTCHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
- SQL书写格式,关键字大小保持一致,使用缩进。(SQL规范优雅)
SELECT stu.name,sum(stu.score)FROM Student stu
WHERE stu.classNo ='1班'GROUPBY stu.name
- INSERT语句标明对应的字段名称(SQL规范优雅)
insertinto Student(student_id,name,score)values('666','捡田螺的小男孩','100');
- 变更SQL操作先在测试环境执行,写明详细的操作步骤以及回滚方案,并在上生产前review。(SQL后悔药) (1)变更SQL操作先在测试环境测试,避免有语法错误就放到生产上了。 (2)变更Sql操作需要写明详细操作步骤,尤其有依赖关系的时候,如:先修改表结构再补充对应的数据。 (3)变更Sql操作有回滚方案,并在上生产前,review对应变更SQL。
- 设计数据库表的时候,加上三个字段:主键,create_time,update_time。(SQL规范优雅)
CREATETABLE`account`(`id`int(11)NOTNULLAUTO_INCREMENTCOMMENT'主键Id',`name`varchar(255)DEFAULTNULLCOMMENT'账户名',`balance`int(11)DEFAULTNULLCOMMENT'余额',`create_time`datetimeNOTNULLCOMMENT'创建时间',`update_time`datetimeNOTNULLONUPDATECURRENT_TIMESTAMPCOMMENT'更新时间',PRIMARYKEY(`id`),KEY`idx_name`(`name`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=1570068DEFAULTCHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
(1)主键一定要加上的,没有主键的表是没有灵魂的
(2)创建时间和更新时间的话,还是建议加上吧,详细审计、跟踪记录,都是有用的。
阿里开发手册也提到这个点,如图
- 写完SQL语句,检查where,order by,group by后面的列,多表关联的列是否已加索引,优先考虑组合索引。(SQL性能优化)
添加索引
altertableuseraddindex idx_address_age (address,age)
- 修改或删除重要数据前,要先备份,先备份,先备份(SQL后悔药) 如果要修改或删除数据,在执行SQL前一定要先备份要修改的数据,万一误操作,还能吃口「后悔药」
- where后面的字段,留意其数据类型的隐式转换(SQL性能优化)
select*fromuserwhere userid ='123';
因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较,最后导致索引失效
- 尽量把所有列定义为NOT NULL(SQL规范优雅) (1)「NOT NULL列更节省空间」,NULL列需要一个额外字节作为判断是否为 NULL 的标志位。 (2)「NULL列需要注意空指针问题」,NULL列在计算和比较的时候,需要注意空指针问题。
- 修改或者删除SQL,先写WHERE查一下,确认后再补充 delete 或 update(SQL后悔药) 尤其在操作生产的数据时,遇到修改或者删除的SQL,先加个where查询一下,确认OK之后,再执行update或者delete操作
- 减少不必要的字段返回,如使用select <具体字段> 代替 select * (SQL性能优化)
select id,name from employee;
节省资源、减少网络开销。
可能用到覆盖索引,减少回表,提高查询效率。
- 所有表必须使用Innodb存储引擎(SQL规范优雅) Innodb 「支持事务,支持行级锁,更好的恢复性」,高并发下性能更好,所以呢,没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎
- 数据库和表的字符集统一使用UTF8(SQL规范优雅) 统一使用UTF8编码 可以避免乱码问题 可以避免,不同字符集比较转换,导致的索引失效问题
- 尽量使用varchar代替 char。(SQL性能优化)
`deptName`varchar(100)DEFAULTNULLCOMMENT'部门名称'
因为首先变长字段存储空间小,可以节省存储空间。
其次对于查询来说,在一个相对较小的字段内搜索,效率更高。
- 如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。(SQL规范优雅) 这个点,是阿里开发手册中,Mysql的规约。你的字段,尤其是表示枚举状态时,如果含义被修改了,或者状态追加时,为了后面更好维护,需要即时更新字段的注释。
- SQL修改数据,养成begin + commit 事务的习惯(SQL后悔药)
begin;update account set balance =1000000where name ='捡田螺的小男孩';commit;
- 索引命名要规范,主键索引名为 pk_ 字段名;唯一索引名为 uk _字段名 ;普通索引名则为 idx 字段名。(SQL规范优雅) 说明:pk 即 primary key;uk _ 即 unique key;idx _ 即 index 的简称。
- WHERE从句中不对列进行函数转换和表达式计算 假设loginTime加了索引
explainselect userId,loginTime from loginuser where loginTime >= Date_ADD(NOW(),INTERVAL-7DAY);
索引列上使用mysql的内置函数,索引失效
- 如果修改/更新数据过多,考虑批量进行。
for each(200次)
{
deletefrom account limit500;
}
大批量操作会会造成主从延迟。
大批量操作会产生大事务,阻塞。
大批量操作,数据量过大,会把cpu打满。
本文转载自: https://blog.csdn.net/u012685544/article/details/122255605
版权归原作者 梅里雪山GIS 所有, 如有侵权,请联系我们删除。
版权归原作者 梅里雪山GIS 所有, 如有侵权,请联系我们删除。