

本文被 系统学习JavaWeb 收录点击订阅专栏
文章目录
1 xml简介
xml是一种可扩展的标记性语言。其主要作用如下:
- 用以保护数据,且这些数据具有自我描述性;
- 可以作为项目或者模块的配置文件;
- 可以作为网络传输数据的格式(现在以JSON为主)
2 xml入门
2.1 xml示例文件
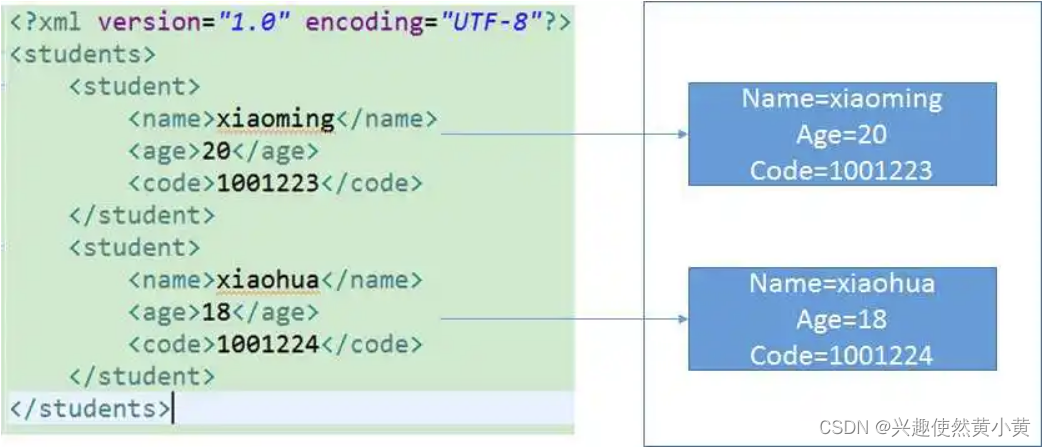
尝试创建一个xml文件来描述学生信息。
- 创建一个xml文件 students.xml

students.xml
<?xml version="1.0" encoding="utf-8" ?><!--
<?xml version="1.0" encoding="utf-8" ?>
以上内容就是xml文件的声明
version表示xml的版本
encoding表示xml文件本身的编码
--><students><!--students 表示多个学生信息--><studentsno="20408010101"><!--student表示一个学生信息 sno表示学号--><name>路飞</name><!--name表示姓名--><age>17</age><!--age表示年龄--></student><studentsno="20408010102"><!--student表示一个学生信息 sno表示学号--><name>娜美</name><!--name表示姓名--><age>16</age><!--age表示年龄--></student></students>
2.2 xml语法介绍
2.2.1 xml注释
xml的注释与html文件的注释格式一样:
<!-- 这里是注释 -->
2.2.2 元素(标签)
在html中,我们学习过,html标签分为单标签和双标签,且标签名对大小写不敏感。当然,标签也具有一些属性,分为基本属性和事件属性。
那么,什么是xml元素呢?
XML元素是指从(且包括)开始标签直到(且包括)结束标签的部分。
元素可包含其他元素、文本或者两者的混合物。元素也可以拥有属性。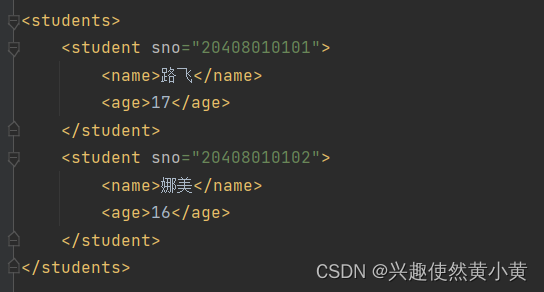
在上图的例子中,
<students>
和
<student>
都拥有元素内容,它们都包含了其他元素。而像
<name>
和
<age>
只包含文本,因此,只有文本内容。
xml 元素遵循以下命名规则:
- 名称可以包含字母、数字和其他字符;
- 名称不能以数字或标点符号开始;
- 名称不能包含空格。
在xml中的元素,也分为单标签和双标签,格式与 html 一致。
2.2.3 xml的属性
xml的标签属性与html的标签属性是非常类似的,属性可以提供元素的额外信息。
一个标签上可以书写多个属性。每个属性的值需要用引号引住。 属性名的命名规范与标签的规则一致。
2.2.4 xml语法规范
- 所有 XML 元素都必须有关闭标签。不闭合就会报错。
- XML 标签 对大小写敏感。
- XML 文档必须有根元素,根元素即没有父标签的元素,且是唯一一个。
- XML 中的特殊字符可以使用 html语法中的,如空格等。
2.2.5 文本区域(CDARA)
xml中提供了一个CDATA语法,可以告诉xml解析器,位于CDATA里的文本内容,只是纯文本,不需要xml语法解析!
CDATA格式:
<![CDATA[这里可以把你输入的字符原样显示,不会解析!]]>
2.3 xml解析技术
不论是html文件还是xml文件都是标记型文档,都可以使用w3c组织制定的dom技术来解析。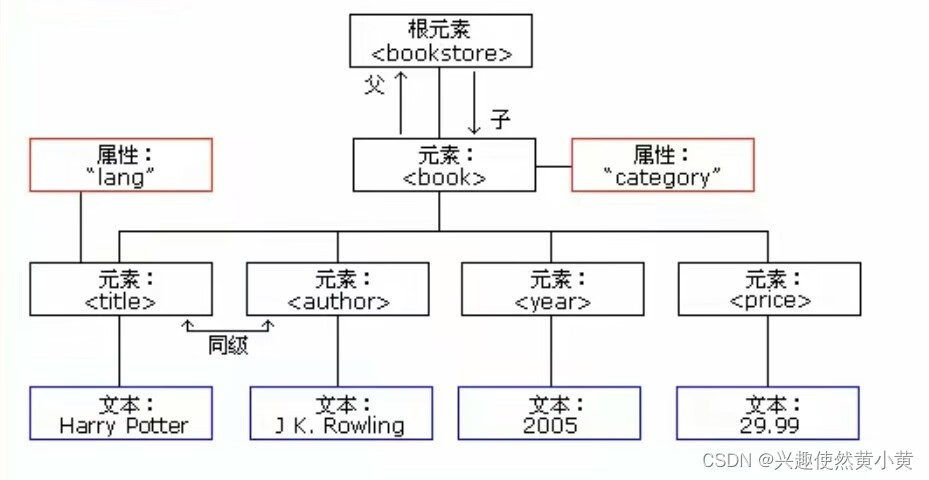
- XML 文档对象模型定义访问和操作 XML文档 的标准方法;
- DOM 将 XML 文档作为一个树形结构,而树叶被定义为节点。
早期JDK提供了两种 xml解析技术——DOM 和sax 简介(了解):
dom 解析技术是 W3C 组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。
Java对 dom 技术解析标记也做了实现。
sun 公司在 JDK5 版本対 dom 解析技术进行升级:SAX ( Simple API for XML )
SAX 解析,它跟 W3C制定的解析不太一样。它是以类似事件机制通过回调告诉用户当前正在解析的内容。
它是一行一行的读取xml 文件内容进行解析的。不会创建大量的dom 对象。
所以它在解析 xml 的时候,在内存的使用上、性能上都优于 Dom 解析。
第三方的解析:
- jdom 在dom 基础上进行了封装
- dom4j 又对jdom 进行了封装。
- pull 主要用在 Android 手机开发,是在跟sax非常类似都是事件机制解析 xml 文件。
Dom4j 它是第三方的解析技术。我们需要使用第三方给我们提供好的类库才可以解析 xml 文件。
3 Dom4j 解析技术
3.1 Dom4j 类库的下载与简介
由于 dom4j 不是 sun公司 的技术,属于第三方公司的技术,因此,想要使用就必须下载 dom4j的jar包。
dom4j的官网是http://www.dom4j.org,截至到目前最新的版本是1.6.1。dom4j是一个易用的、开源的库,应用于Java平台XML、XPath、和XSLT,并且提供了对DOM、SAX和JAXP的完全支持。主要功能包括针对Java平台设计完成支持Java的集合框架;完全的支持JAXP, TrAX, SAX, DOM, and XSLT;为XML文档的简单导航完全集成的XPath支持;基于事件的过程模式完全支持大量的文档或者是XML流;基于Java接口,更加灵活容易扩展和实现;支持XML Schema数据类型支持使用Kohsuke更加优于多模式验证器库。
下载压缩包,并解压,取得jar包。 下载地址:https://dom4j.github.io/
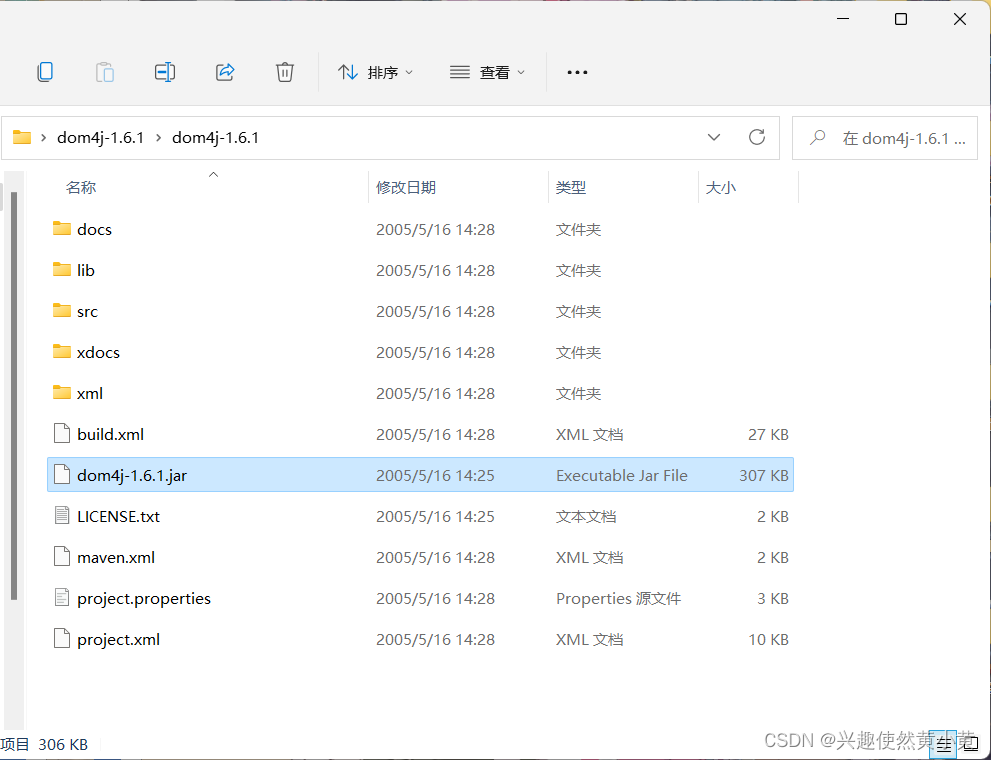
Dom4j目录简介:
- docs是文档目录,点开后,打开index.html,可以查看参考手册。

- lib目录存储了dom4j需要的第三方jar包。

- src目录下是dom4j的源码和一些测试与样例。
3.2 dom4j编程一般步骤
- 先加载xml文件创建Document对象;
- 通过Document对象拿到根元素对象;
- 通过根元素.element(标签名); 可以返回一个集合,集合中存储了所有指定标签名的元素;
- 找到想要修改、删除的子元素,进行相应的操作;
- 保存在硬盘上。
3.3 案例:使用dom4j读取xml文件得到Document对象
需要解析的students.xml文件的内容如下:
<?xml version="1.0" encoding="utf-8" ?><students><studentsno="20408010101"><name>路飞</name><age>17</age></student><studentsno="20408010102"><name>娜美</name><age>16</age></student></students>
解析过程如下:
1️⃣ 首先,将需要解析的xml文件存储到项目的src目录下。
2️⃣ 创建一个包,对照xml文件的内容完成对应Student类的编写。
packagecom.hxh.domxml;/**
* @author 兴趣使然黄小黄
* @version 1.0
* 对照students.xml文件完成Student类
*/publicclassStudent{privateString sno;privateString name;privateint age;publicStudent(){}publicStudent(String sno,String name,int age){this.sno = sno;this.name = name;this.age = age;}@OverridepublicStringtoString(){return"Student{"+"sno='"+ sno +'\''+", name='"+ name +'\''+", age="+ age +'}';}publicStringgetSno(){return sno;}publicStringgetName(){return name;}publicintgetAge(){return age;}publicvoidsetSno(String sno){this.sno = sno;}publicvoidsetName(String name){this.name = name;}publicvoidsetAge(int age){this.age = age;}}
3️⃣ 在该项目模块下,新建一个目录lib,将dom4j.jar包导入,并将包添加到类路径下。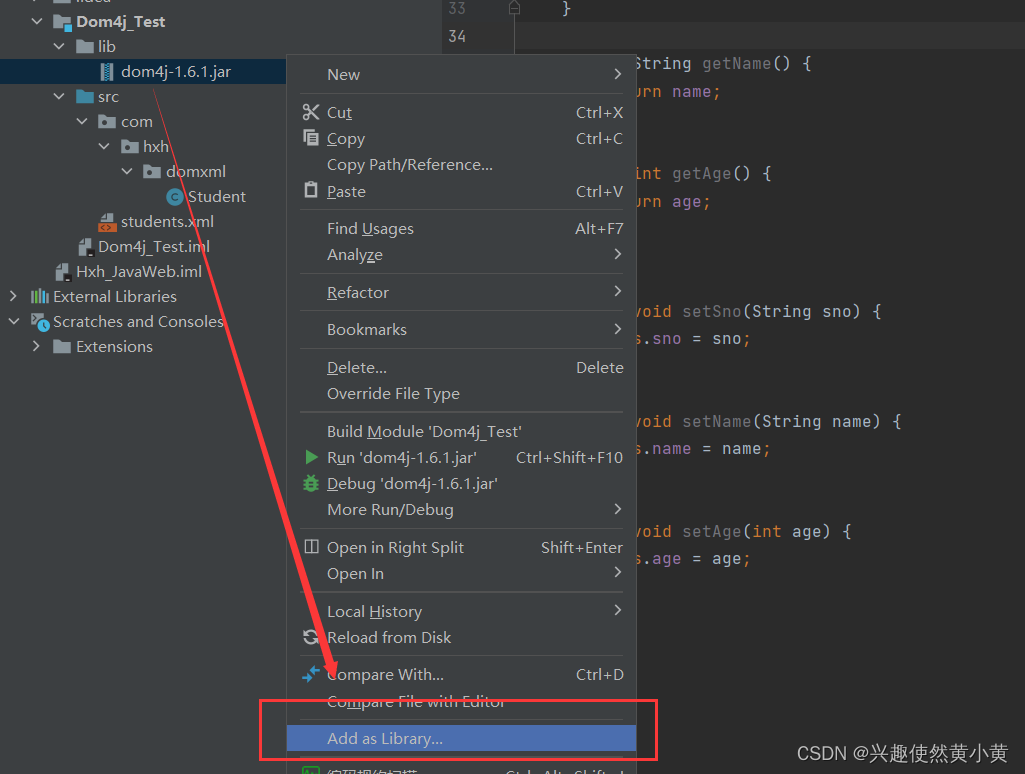
4️⃣ 编写Dom4jTest类,用于实现解析,使用到了JUnit测试技术: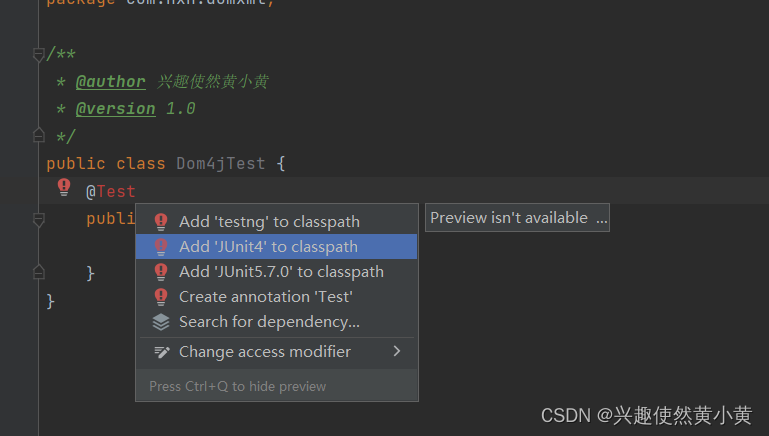
Dom4jTest类的完整代码如下,具体内容解释参考代码注释:
importorg.dom4j.Document;importorg.dom4j.DocumentException;importorg.dom4j.Element;importorg.dom4j.io.SAXReader;importorg.junit.Test;importjava.util.List;/**
* @author 兴趣使然黄小黄
* @version 1.0
*/publicclassDom4jTest{/**
* 读取xml获取document对象的方法
* @throws DocumentException
*/@Testpublicvoidtest01()throwsDocumentException{// 创建一个SaxReader输入流,去读取xml配置文件,生成Document对象SAXReader saxReader =newSAXReader();Document document = saxReader.read("src/students.xml");//测试是否读取System.out.println(document);}/**
* 读取students.xml文件生成Student类
* @throws DocumentException
*/@Testpublicvoidtest02()throwsDocumentException{//1.读取xml文件SAXReader saxReader =newSAXReader();//在Junit测试中,相对路径从模块名算起Document document = saxReader.read("src/students.xml");//2.通过文档对象获取根元素Element rootElement = document.getRootElement();//System.out.println(rootElement);//3.通过根元素获取student标签对象//element()和elements()都是通过标签名查找子元素List<Element> students = rootElement.elements("student");//4.遍历,处理每个student标签转换为Student类System.out.println("|\t\t学号\t\t|\t\t姓名\t\t|\t\t年龄\t\t|");for(Element student :
students){//asXML将标签对象转换为标签字符串//System.out.println(student.asXML());Element nameElement = student.element("name");//获取标签中的文本内容String nameText = nameElement.getText();//也可以直接通过student.elementText()方法一次性得到对应标签的文本内容String ageText = student.elementText("age");//获取标签内的属性String snoText = student.attributeValue("sno");//打印结果System.out.println("\t"+ snoText +"\t\t\t"+ nameText +"\t\t\t\t"+ ageText +"\t\t");}}}
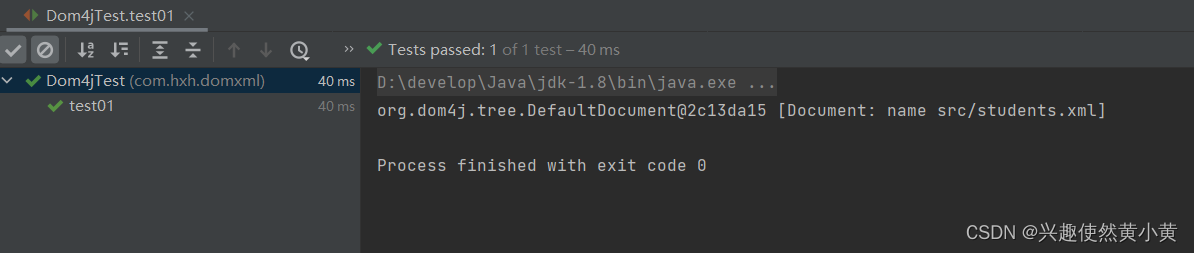
test01的测试结果如下:
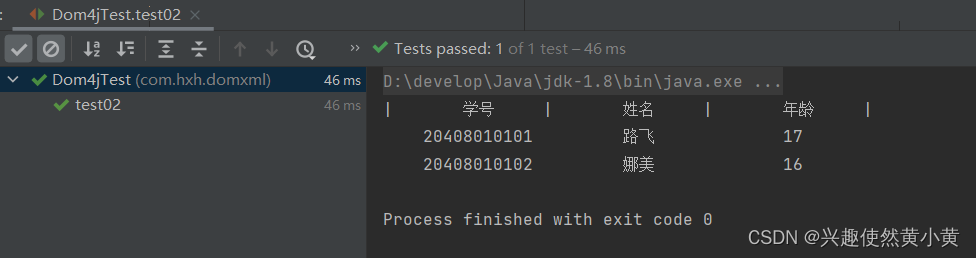
test02的测试结果如下:
版权归原作者 兴趣使然黄小黄 所有, 如有侵权,请联系我们删除。