
今天是其他的个技术:Logstash+Kibana,中间穿插着讲解Kafka应用
话不多说,直接上正题
一、 Logstash数据采集工具安装和使用
1. 简介
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
而在官网,对于Logstash的介绍更是完整,我这里就展示一下官网的介绍
输入:采集各种样式、大小和来源的数据
过滤器:实时解析和转换数据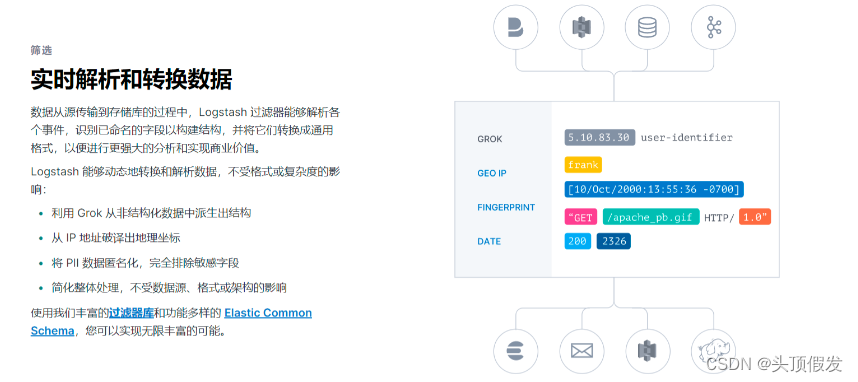
输出:选择你的存储,导出你的数据
而在官网的介绍中,最让我兴奋的就是可扩展性,Logstash 采用可插拔框架,拥有 200 多个插件。您可以将不同的输入选择、过滤器和输出选择混合搭配、精心安排,让它们在管道中和谐地运行。这也就意味着可以用自己的方式创建和配置管道,就跟乐高积木一样,我自己感觉太爽了
好了,理论的东西过一遍就好
ps:不过这也体现出官网在学习的过程中的重要性,虽然都是英文的,但是,现在可以翻译的软件的太多了,这不是问题
2. 安装
所有的技术,不自己实际操作一下是不可以的,安装上自己动手实践一下,毛爷爷都说:实践是检验真理的唯一标准,不得不夸奖一下Logstash的工程师,真的太人性化了,下载后直接解压,就可以了。
而且提供了很多的安装方式供你选择,舒服
3. helloword使用
开始我们今天的第一个实践吧,就像我们刚开始学Java的时候,第一个命令就是helloworld,不知道各位还能不能手写出来呢?来看一下logstash的第一个运行时怎么处理的
通过命令行,进入到logstash/bin目录,执行下面的命令:
input {
kafka {
type => "accesslogs"
codec => "plain"
auto_offset_reset => "smallest"
group_id => "elas1"
topic_id => "accesslogs"
zk_connect => "172.16.0.11:2181,172.16.0.12:2181,172.16.0.13:2181"
}
kafka {
type => "gamelogs"
auto_offset_reset => "smallest"
codec => "plain"
group_id => "elas2"
topic_id => "gamelogs"
zk_connect => "172.16.0.11:2181,172.16.0.12:2181,172.16.0.13:2181"
}
}
filter {
if [type] == "accesslogs" {
json {
source => "message"
remove_field => [ "message" ]
target => "access"
}
}
if [type] == "gamelogs" {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_X" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => [ "message" ]
}
}
}
output {
if [type] == "accesslogs" {
elasticsearch {
index => "accesslogs"
codec => "json"
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
if [type] == "gamelogs" {
elasticsearch {
index => "gamelogs"
codec => plain {
charset => "UTF-16BE"
}
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
}
可以看到提示下面信息(这个命令稍后介绍),输入hello world!
可以看到logstash为我们自动添加了几个字段:
时间戳:@ timestamp
版本:@ version
输入的类型:type
主机名:host。
4.1. 简单的工作原理
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。
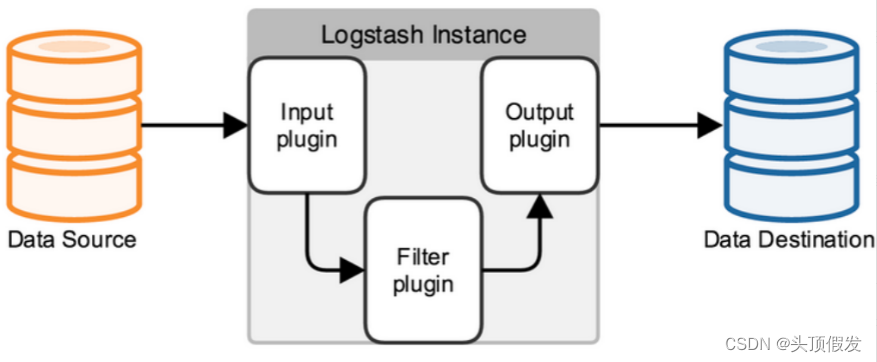
在logstash中,包括了三个阶段:
** 输入input --> 处理filter(不是必须的) --> 输出output**
每个阶段都有很多的插件配合工作,比如file、elasticsearch、redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
4.2. 命令行中常用的命令
** -f:**通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
** -e:**后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
** -l:**日志输出的地址(默认就是stdout直接在控制台中输出)
-t:测试配置文件是否正确,然后退出。
4.3. 配置文件说明
前面介绍过logstash基本上由三部分组成,input、output以及用户需要才添加的filter,因此标准的配置文件格式如下:
input {...}
filter {...}
output {...}
在每个部分中,也可以指定多个访问方式,例如我想要指定两个日志来源文件,则可以这样写:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
类似的,如果在filter中添加了多种处理规则,则按照它的顺序一一处理,但是有一些插件并不是线程安全的。
比如在filter中指定了两个一样的的插件,这两个任务并不能保证准确的按顺序执行,因此官方也推荐避免在filter中重复使用插件。
说完这些,简单的创建一个配置文件的小例子看看:
input {
file {
#指定监听的文件路径,注意必须是绝对路径
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/test.log"
start_position => beginning
}
}
filter {
}
output {
stdout {}
}
日志大致如下:注意最后有一个空行。
1 hello,this is first line in test.log!
2 hello,my name is xingoo!
3 goodbye.this is last line in test.log!
4
执行命令得到如下信息:
5. 最常用的input插件——file。
这个插件可以从指定的目录或者文件读取内容,输入到管道处理,也算是logstash的核心插件了,大多数的使用场景都会用到这个插件,因此这里详细讲述下各个参数的含义与使用。
5.1. 最小化的配置文件
在Logstash中可以在 input{} 里面添加file配置,默认的最小化配置如下:
input {
file {
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*"
}
}
filter {
}
output {
stdout {}
}
当然也可以监听多个目标文件:
input {
file {
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
}
}
filter {
}
output {
stdout {}
}
5.2. 其他的配置
另外,处理path这个必须的项外,file还提供了很多其他的属性:
input {
file {
#监听文件的路径
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
#排除不想监听的文件
exclude => "1.log"
#添加自定义的字段
add_field => {"test"=>"test"}
#增加标签
tags => "tag1"
#设置新事件的标志
delimiter => "\n"
#设置多长时间扫描目录,发现新文件
discover_interval => 15
#设置多长时间检测文件是否修改
stat_interval => 1
#监听文件的起始位置,默认是end
start_position => beginning
#监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
}
}
filter {
}
output {
stdout {}
}
其中值得注意的是:
1 path
是必须的选项,每一个file配置,都至少有一个path
2 exclude
是不想监听的文件,logstash会自动忽略该文件的监听。配置的规则与path类似,支持字符串或者数组,但是要求必须是绝对路径。
3 start_position
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
4 sincedb_path
这个选项配置了默认的读取文件信息记录在哪个文件中,默认是按照文件的inode等信息自动生成。其中记录了inode、主设备号、次设备号以及读取的位置。因此,如果一个文件仅仅是重命名,那么它的inode以及其他信息就不会改变,因此也不会重新读取文件的任何信息。类似的,如果复制了一个文件,就相当于创建了一个新的inode,如果监听的是一个目录,就会读取该文件的所有信息。
5 其他的关于扫描和检测的时间,按照默认的来就好了,如果频繁创建新的文件,想要快速监听,那么可以考虑缩短检测的时间。
//6 add_field
#这个技术感觉挺六的,但是其实就是增加一个字段,例如:
file {
add_field => {"test"=>"test"}
path => "D:/tools/logstash/path/to/groksample.log"
start_position => beginning
}
6. Kafka与Logstash的数据采集对接
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理。
6.1. Logstash工作原理
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处:
1 生产者的负载与消费者的负载解耦
2 消费者按照自己的能力fetch数据
3 消费者可以自定义消费的数量
另外,由于broker采用了主题topic-->分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader-->followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。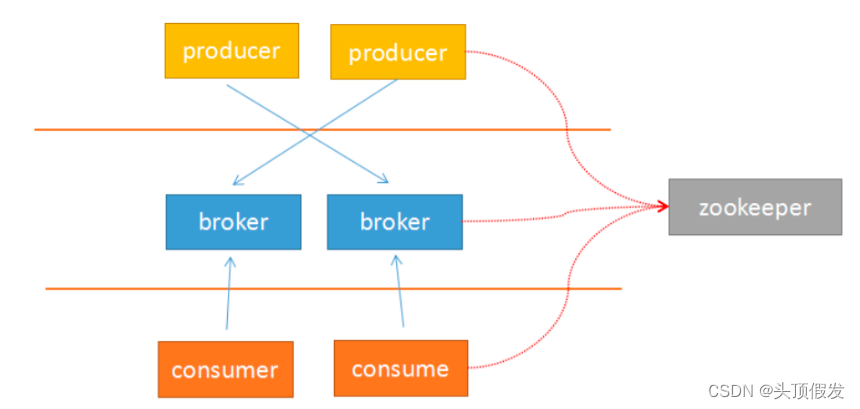
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash-->kafka-->logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。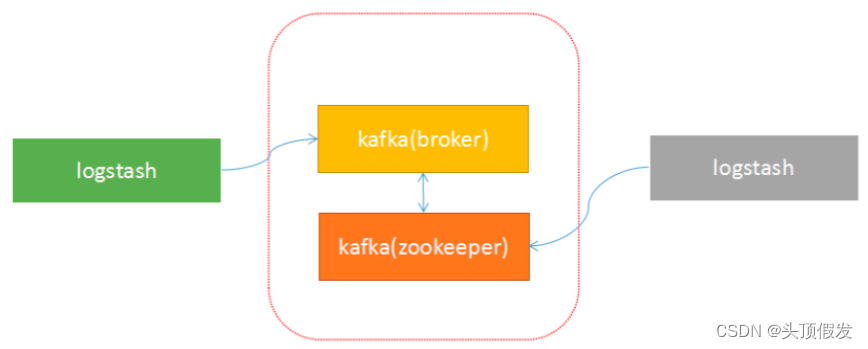
6.2. 启动kafka
##启动zookeeper:
$zookeeper/bin/zkServer.sh start
##启动kafka:
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &
6.3. 创建主题
#创建主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1
#查看主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe
6.4. 测试环境
#执行生产者脚本:
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
#执行消费者脚本,查看是否写入:
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello
6.5. 向kafka中输出数据
input{
stdin{}
}
output{
kafka{
topic_id => "hello"
bootstrap_servers => "192.168.0.4:9092,172.16.0.12:9092"
# kafka的地址
batch_size => 5
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
}
stdout{
codec => rubydebug
}
}
6.6. 从kafka中读取数据
logstash配置文件:
input{
kafka {
codec => "plain"
group_id => "logstash1"
auto_offset_reset => "smallest"
reset_beginning => true
topic_id => "hello"
zk_connect => "192.168.0.5:2181"
}
}
output{
stdout{
codec => rubydebug
}
}
7. Filter
7.1. 过滤插件grok组件
#日志
55.3.244.1 GET /index.html 15824 0.043
bin/logstash -e '
input { stdin {} }
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output { stdout {codec => rubydebug} }'
7.2. 分割插件split
filter {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_X" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => [ "message" ]
}
}
四、 Kibana报表工具的安装和使用
1. 简介
Logstash 早期曾经自带了一个特别简单的 logstash-web 用来查看 ES 中的数据。其功能太过简单,于是产生了Kibana。不过是用PHP编写,后来为了满足更多的使用需求,懒人推动科技的进步嘛,并且Logstash使用ruby进行编写,所以重新编写Kibana,直到现在,Kibana因为重构,导致3,4某些情况下不兼容,所以出现了一山容二虎的情况,具体怎么选择,可以根据业务场景进行实际分析
在Kibana众多的优秀特性中,我个人最喜欢的是这一个特性,我起名叫包容性
因为在官网介绍中,Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats或第三方技术的数据整合到Elasticsearch,支持的第三方技术包括Apache Flume、Fluentd等。这也就表明我在日常的开发工作中,对于技术选型和操作的时候,我可以有更多的选择,在开发时也能找到相应的开发实例,节省了大量的开发时间
ps:有一次体现了官网的重要性,真的,有时候官网可以帮你解决大多数的问题,有时间可以去看一下官网啊,好了,话不多说,看正题
2. 安装
下载安装包后解压
编辑文件config/kibana.yml ,配置属性:
[root@H32 ~]# cd kibana/config/
[root@H32 config]# vim kibana.yml
//添加:
server.host: "192.168.80.32"
elasticsearch.url: "http://172.16.0.14:9200"
先启动ES,然后再启动
cd /usr/local/kibana530bin/kibana
注意:
1、kibana必须是在root下运行,否则会报错,启动失败
2、下载解压安装包,一定要装与ES相同的版本
3. 导入数据
我们将使用莎士比亚全集作为我们的示例数据。要更好的使用 Kibana,你需要为自己的新索引应用一个映射集(mapping)。我们用下面这个映射集创建"莎士比亚全集"索引。实际数据的字段比这要多,但是我们只需要指定下面这些字段的映射就可以了。注意到我们设置了对 speaker 和 play_name 不分析。原因会在稍后讲明。
在终端运行下面命令:
curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
我们这就创建好了索引。现在需要做的时导入数据。莎士比亚全集的内容我们已经整理成了 elasticsearch 批量 导入所需要的格式,你可以通过shakeseare.json下载。
用如下命令导入数据到你本地的 elasticsearch 进程中。
curl -XPUT localhost:9200/_bulk --data-binary @shakespeare.json
4. 访问 Kibana 界面
打开浏览器,访问已经发布了 Kibana 的本地服务器。
如果你解压路径无误(译者注:使用 github 源码的读者记住发布目录应该是 kibana/src/ 里面),你已经就可以看到上面这个可爱的欢迎页面。点击 Sample Dashboard 链接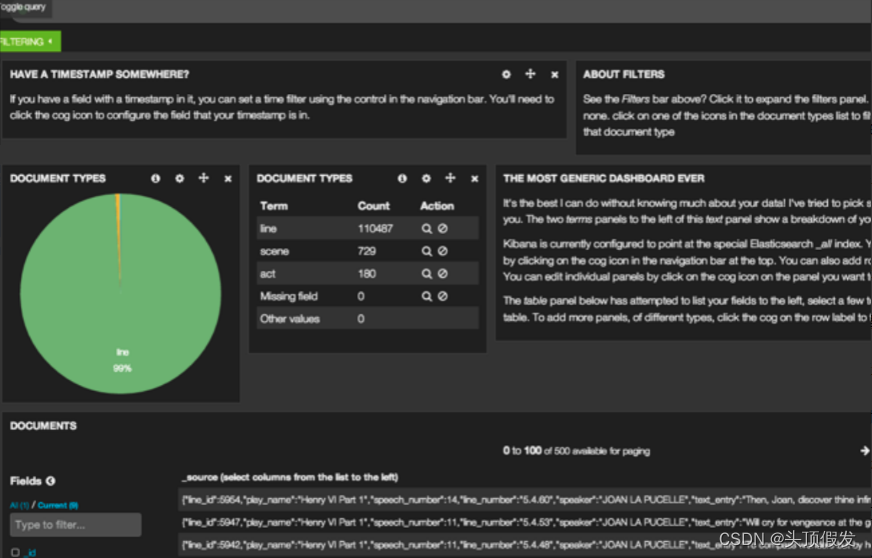
好了,现在显示的就是你的 sample dashboard!如果你是用新的 elasticsearch 进程开始本教程的,你会看到一个百分比占比很重的饼图。这里显示的是你的索引中,文档类型的情况。如你所见,99% 都是 lines,只有少量的 acts 和scenes。
在下面,你会看到一长段 JSON 格式的莎士比亚诗文。
5. 第一次搜索
Kibana 允许使用者采用 Lucene Query String 语法搜索 Elasticsearch 中的数据。请求可以在页面顶部的请求输入框中书写。
在请求框中输入如下内容。然后查看表格中的前几行内容。
friends, romans, countrymen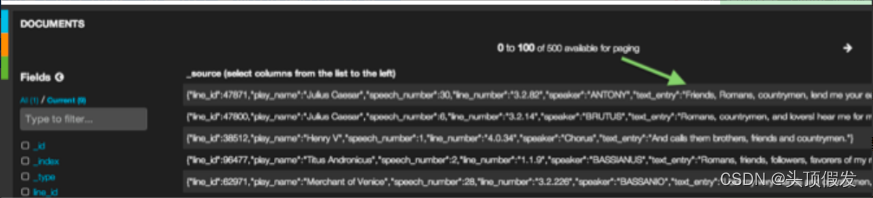
6. 配置另一个索引
目前 Kibana 指向的是 Elasticsearch 一个特殊的索引叫 _all。 _all 可以理解为全部索引的大集合。目前你只有一个索引, shakespeare,但未来你会有更多其他方面的索引,你肯定不希望 Kibana 在你只想搜《麦克白》里心爱的句子的时候还要搜索全部内容。
配置索引,点击右上角的配置按钮: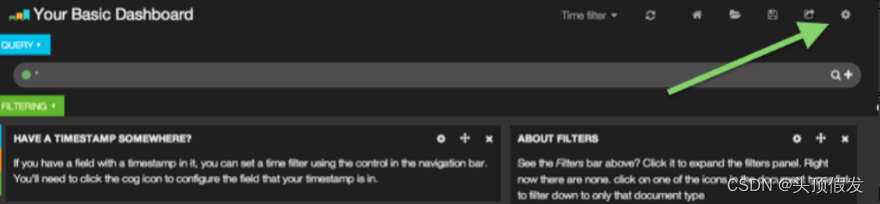
在这里,你可以设置你的索引为 shakespeare ,这样 Kibana 就只会搜索 shakespeare 索引的内容了。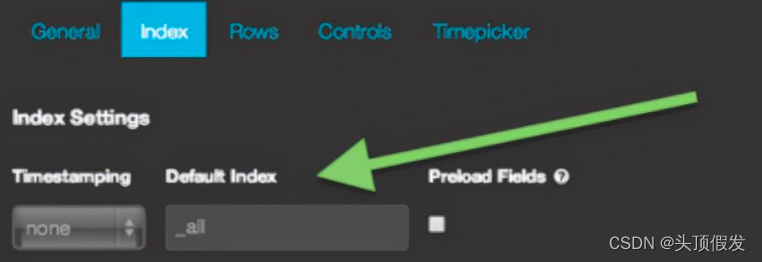

这是因为 ES1.4 增强了权限管理。你需要在 ES 配置文件 elasticsearch.yml 中添加下列配置并重启服务后才能正常访问:
http.cors.enabled: true
http.cors.allow-origin: "*"
记住 kibana3 页面也要刷新缓存才行。
此外,如果你可以很明确自己 kibana 以外没有其他 http 访问,可以把 kibana 的网址写在http.cors.allow-origin 参数的值中。比如:
http.cors.allow-origin: "/https?:\/\/kbndomain/"
好了,到这里就结束了,不知道有没有收获呀,有收获的朋友给我点个赞吧~
版权归原作者 头顶假发 所有, 如有侵权,请联系我们删除。