
(1)在/opt目录下建立 software,module两个文件,software用来下载安装包,下载或的安装包可以解压到module文件。小编下载spark的版本是:spark-2.3.2-bin-hadoop2.7.tgz。所以下载spark版本到software文件后,解压到module文件中,可以用这行代码执行:
tar -zxvf /opt/module/spark-2.3.2-bin-hadoop2.7.tgz -C /opt/module;
到 /opt/module 目录下查看是否已经解压:
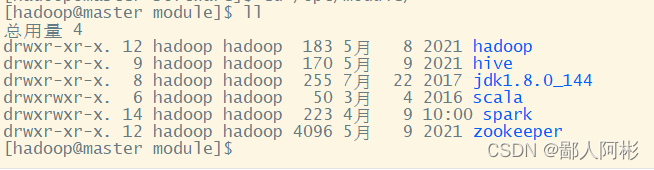
(2)解压后对 spark-2.3.2-bin-hadoop2.7.tgz 修改成 spark(原本是spark-2.3.2-bin-hadoop2.7.tgz ,为了方便后面的使用,所以小编就修改了名称),修改文件名的格式为:
mv 原文件名 新文件名
(3) 修改权限,给解压过来的spark安装包以hadoop权限,具体命令为:
chown -R hadoop:hadoop /opt
(4) 修改配置文件,进入spark/conf目录修改Spark的配置文件spark-env.sh,将spark-env.sh.template配置模板文件复制一份,并命名为spark-env.sh,具体命令如下:
cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件,在文件中添加一下的内容:
export JAVA_HOME=/opt/module/jdk
export SPARK_MASTER_HOST=master
export SPARK_MASTER_POST=7077
(5)在spark/conf目录下复制slaves-template文件,并命名为slaves,具体命令如下:
cp slaves.template slaves
(6)通过“vi slaves”命令编辑slaves配置文件,主要指定Spark集群中的从节点IP,由于在hosts文件中已经配置了IP和主机名的映射关系,因此直接用主机名代替 IP即可。添加内容如下图:

(7)分发文件,修改完成配置文件后,将spark目录分发至slave1和slave2节点,具体命令如下:
scp -r /opt/module/spark/ slave1:/opt/module
scp -r /opt/module/spark slave2:/opt.module
(8)启动Spark集群,直接使用spark/sbin/start-all.sh脚本即可,启动后使用JPS查看如图所示:
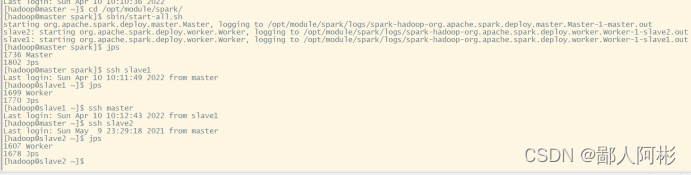
(9)从图中可以看出,当前主机master启动了Master进程,slave1和slave2启动了Worker进程,访问Spark管理页面查看集群状态(主节点),Spark集群管理界面如图所示;
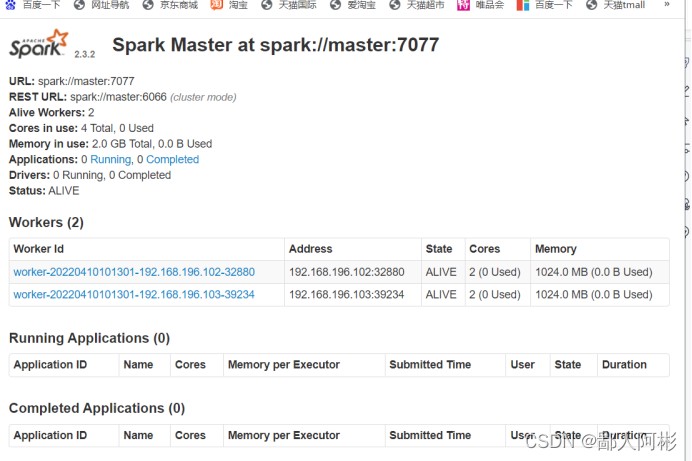
好了,啊彬把Hadoop中spark的集群配置就讲到这里啦,感谢家人们的支持!
版权归原作者 鄙人阿彬 所有, 如有侵权,请联系我们删除。