
活动地址:CSDN21天学习挑战赛
前言
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
1 selenium环境搭建
官方网址:https://www.selenium.dev/,可以参考官方提供信息来做相对应的操作,此处为学习知识而做的记录。
1.1 下载模块
打开终端,输入下载命令
python -m pip install selenium
,安装
selenium
以及依赖项。
Aion.Liu $ python -m pip install selenium
Collecting selenium
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x103860a90>, 'Connection to files.pythonhosted.org timed out. (connect timeout=15)')': /packages/50/1a/9b92b6be1f6bbcd4e5a5b1d8e5d0c7f8224054c3bf5ea81d371be47122e8/selenium-4.4.3-py3-none-any.whl
Downloading selenium-4.4.3-py3-none-any.whl (985 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 986.0/986.0 kB 7.7 kB/s eta 0:00:00
Requirement already satisfied: certifi>=2021.10.8 in /usr/local/lib/python3.10/site-packages (from selenium)(2022.6.15)
Collecting trio-websocket~=0.9
Downloading trio_websocket-0.9.2-py3-none-any.whl (16 kB)
Collecting trio~=0.17
Downloading trio-0.21.0-py3-none-any.whl (358 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 359.0/359.0 kB 6.1 kB/s eta 0:00:00
Requirement already satisfied: urllib3[socks]~=1.26in /usr/local/lib/python3.10/site-packages (from selenium)(1.26.11)
Collecting async-generator>=1.9
Downloading async_generator-1.10-py3-none-any.whl (18 kB)
Requirement already satisfied: idna in /usr/local/lib/python3.10/site-packages (from trio~=0.17->selenium)(3.3)
Collecting sniffio
Downloading sniffio-1.2.0-py3-none-any.whl (10 kB)
Collecting sortedcontainers
Downloading sortedcontainers-2.4.0-py2.py3-none-any.whl (29 kB)
Collecting outcome
Downloading outcome-1.2.0-py2.py3-none-any.whl (9.7 kB)
Collecting attrs>=19.2.0
Downloading attrs-22.1.0-py2.py3-none-any.whl (58 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.8/58.8 kB 8.1 kB/s eta 0:00:00
Collecting wsproto>=0.14
Downloading wsproto-1.1.0-py3-none-any.whl (24 kB)
Collecting PySocks!=1.5.7,<2.0,>=1.5.6
Downloading PySocks-1.7.1-py3-none-any.whl (16 kB)
Collecting h11<1,>=0.9.0
Downloading h11-0.13.0-py3-none-any.whl (58 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.2/58.2 kB 9.4 kB/s eta 0:00:00
Installing collected packages: sortedcontainers, sniffio, PySocks, h11, attrs, async-generator, wsproto, outcome, trio, trio-websocket, selenium
Successfully installed PySocks-1.7.1 async-generator-1.10 attrs-22.1.0 h11-0.13.0 outcome-1.2.0 selenium-4.4.3 sniffio-1.2.0 sortedcontainers-2.4.0 trio-0.21.0 trio-websocket-0.9.2 wsproto-1.1.0
关于其他语言或版本,请参考这里:https://www.selenium.dev/downloads/
1.2 安装浏览器驱动WebDriver
WebDriver 以本地方式驱动浏览器,就像用户在本地或使用 Selenium 服务器在远程机器上一样,这标志着浏览器自动化方面的飞跃。
Selenium WebDriver 指的是语言绑定和单个浏览器控制代码的实现。这通常被称为WebDriver。
Selenium WebDriver 是W3C 推荐的。
- WebDriver 被设计为一个更简洁的编程接口。
- WebDriver 是一个紧凑的面向对象的 API。
- 它有效地驱动浏览器。
下面在mac中,安装谷歌浏览器WebDriver驱动。
首先按照官方的地址,下载软件,下载地址如下:
Ghrome/Chromium驱动程序下载地址:https://chromedriver.storage.googleapis.com/index.html
FireFox驱动程序下载地址:https://github.com/mozilla/geckodriver/tags
Edge驱动程序下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
IE驱动程序下载地址:https://www.selenium.dev/downloads/
Safari驱动程序下载地址:内置
Opera 驱动程序:不支持 w3c 语法,建议使用 chromedriver 与 Opera 一起工作。
查看自己机器浏览器的版本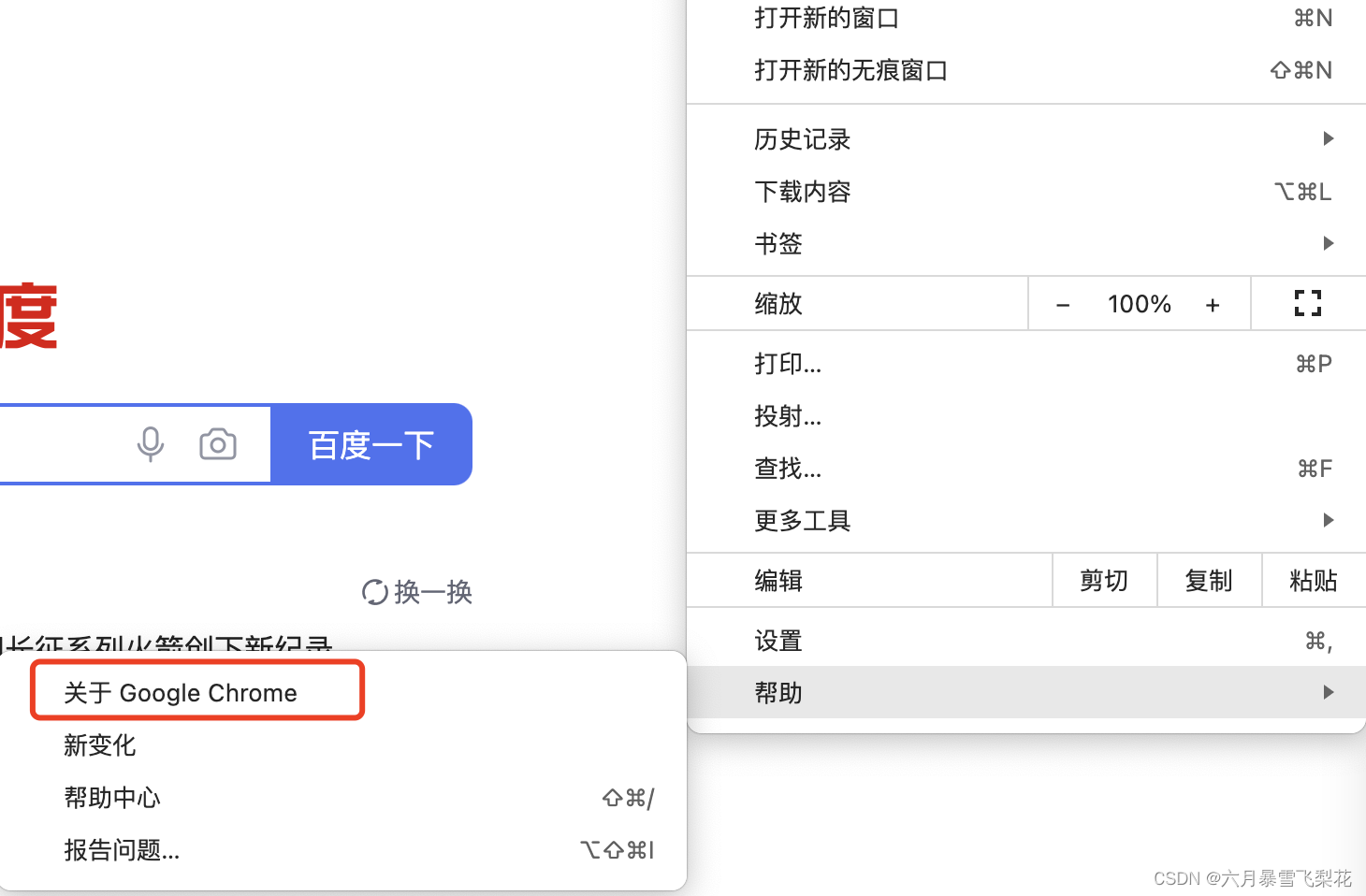
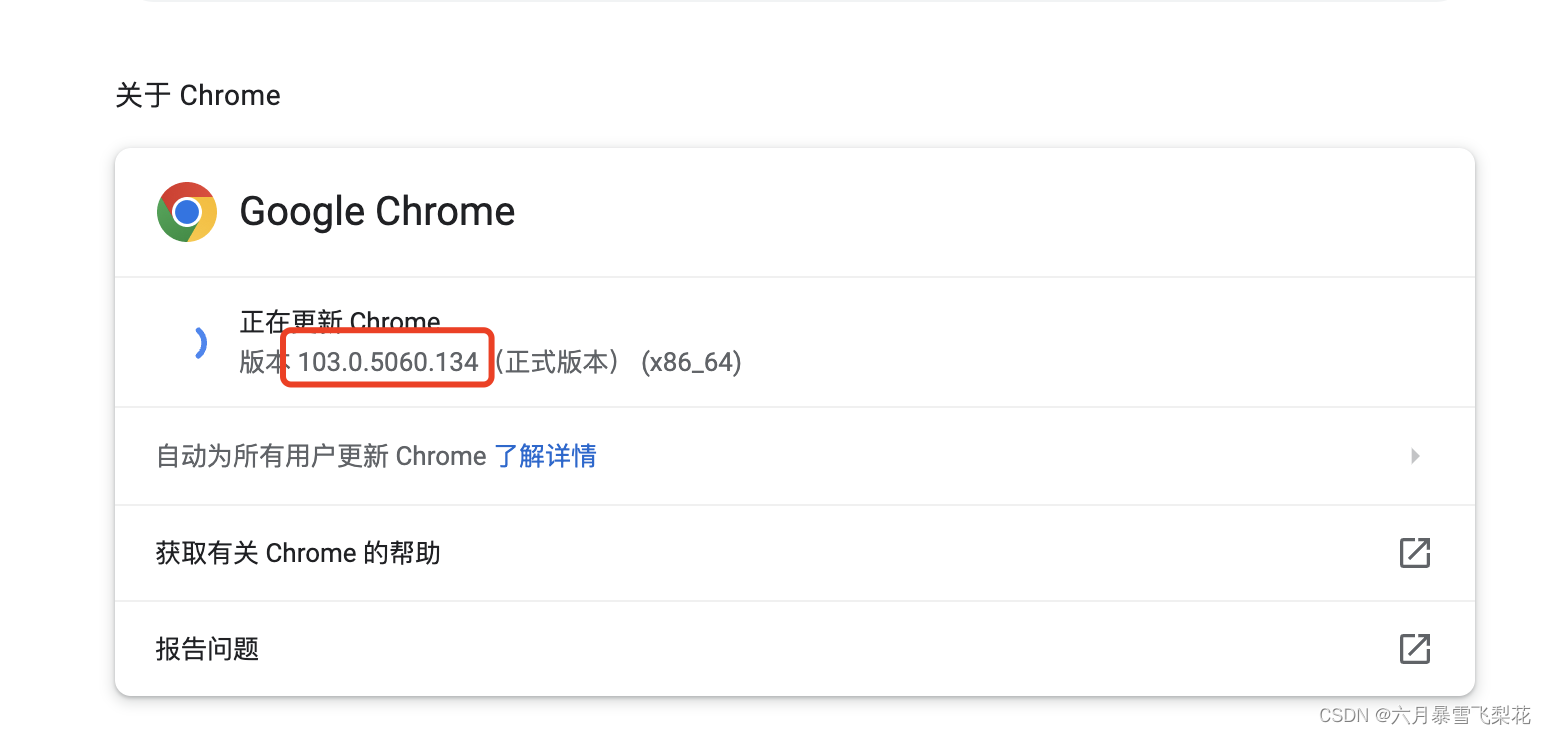
下载WebDriver的版本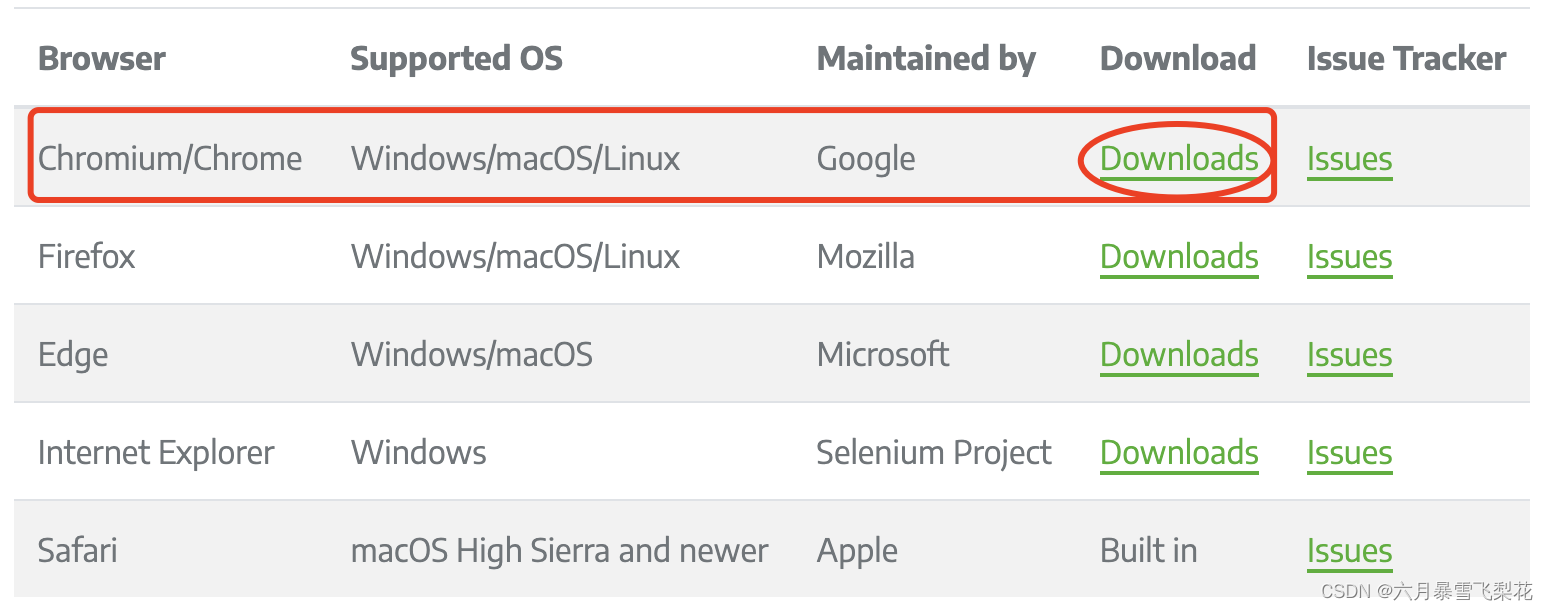
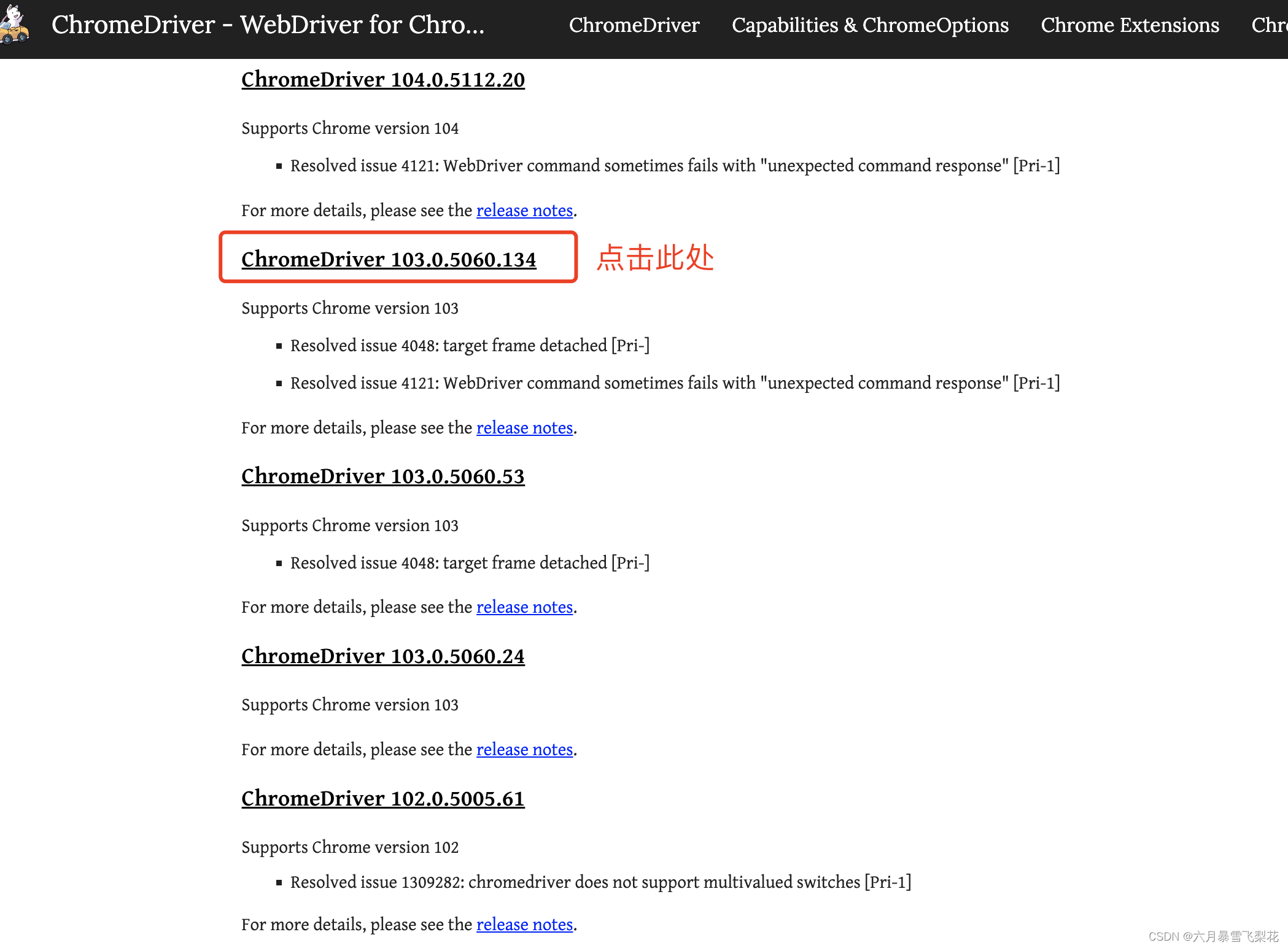
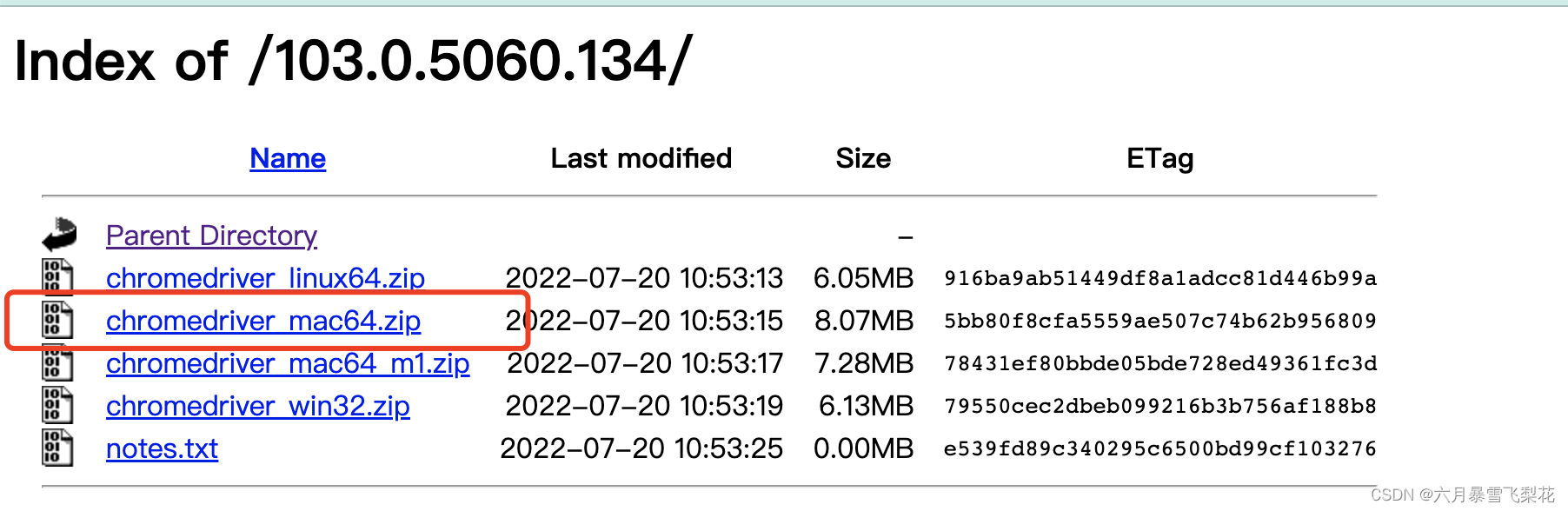
下载相对应的软件程序或者相近的软件程序。
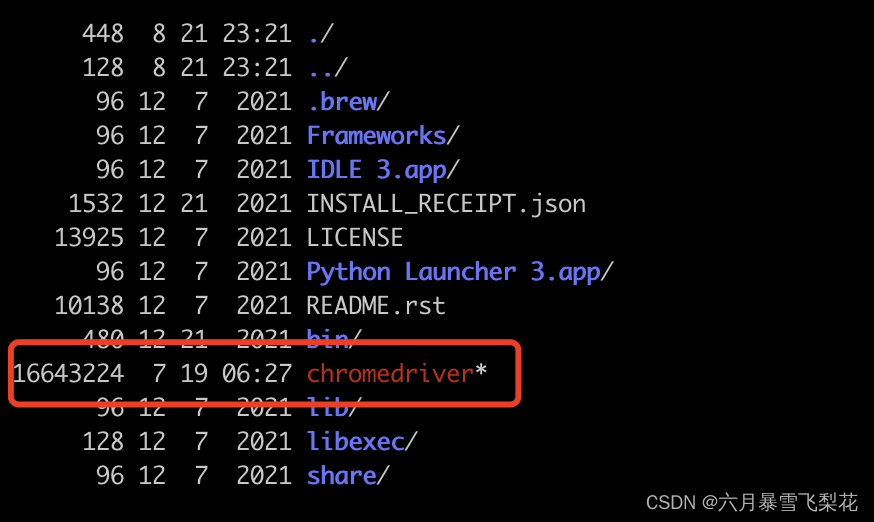
将下载好的软件程序解压,并放在python的安装目录,也就是
Python_HOME/
下,我机器的安装目录是:
$ pwd
/usr/local/Cellar/[email protected]/3.10.1
$ open.
2 使用WebDriver驱动程序
2.1 驱动管理软件
# 导入WebDriver 管理器from webdriver_manager.chrome import ChromeDriverManager
# 获取管理器使用的位置并将其传递给服务类
service = Service(executable_path=ChromeDriverManager().install())# 初始化驱动时使用Service实例
driver = webdriver.Chrome(service=service)
完整的示例请参考:GitHub示例
2.2 加入到环境变量
首先手工下载,然后将路径放在机器环境变量:
echo 'export PATH=$PATH:[WebDriver_HOME]' >> ~/.bash_profile
,其中
【WebDriver_HOME】
是路径地址,如下:
$ echo'export PATH=$PATH:/usr/local/Cellar/[email protected]/3.10.1'>> ~/.bash_profile
$ source ~/.bash_profile
$ chromedriver
Starting ChromeDriver 103.0.5060.134 (8ec6fce403b3feb0869b0732eda8bd95011d333c-refs/branch-heads/5060@{#1262}) on port 9515
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
2.3 在Python中直接引用
这里其实也是手工下载,然后在编码中直接使用。其中
【WebDriver_HOME】
同
步骤2.2
中的一致。
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
service = Service(executable_path="【WebDriver_HOME】")
driver = webdriver.Chrome(service=service)
2.4 打开谷歌(Chrome)浏览器
- 界面模式(Chrome)浏览器
from selenium import webdriver
# 浏览器的初始化
browser = webdriver.Chrome()# 发送请求
browser.get('https://www.baidu.com/')# 打印页面的标题print(browser.title)# 退出模拟浏览器
browser.quit()# 一定要退出!不退出会有残留进程
在执行
browser = webdriver.Chrome()
时比较慢,后续就比较快些。我使用这个打开火狐浏览器出现了错误。
- 无界面模式(Chrome)浏览器
from selenium import webdriver
# 1. 实例化配置对象
chrome_options = webdriver.ChromeOptions()# 2. 配置对象添加开启无界面命令
chrome_options.add_argument('--headless')# 3. 配置对象添加禁用gpu命令
chrome_options.add_argument('--disable-gpu')# 4. 实例化带有配置对象的browser 对象
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.baidu.com/')# 查看请求的数据print(browser.page_source)# 查看渲染后的数据,就可以Xpath进行解析获取数据了print(browser.get_cookies())# 查看请求页面后的cookies值print(browser.current_url)# 查看请求url# 关闭页面
browser.close()# 关闭浏览器
browser.quit()
2.5 元素定位
2.6 元素操作
2.7 前进/后退
2.8 执行js脚本
2.9 页面等待
- 页面显示等待(常用模式)
- 页面隐式等待
3 进阶操作
3.1 使用代理IP
3.2 修改请求头
3.3 隐藏指纹特征
版权归原作者 六月暴雪飞梨花 所有, 如有侵权,请联系我们删除。