
四、一些调试的实例
在我们前面说了那么多调试的步骤方法快捷键以及每一个窗口的功能之后,那么我们就需要练习几个有问题的代码进行调试修改。
1.实例一
题目:实现代码:求 1!+2!+3! ...+ n! ;不考虑溢出。
代码:
#include<stdio.h> int main() { int i = 0; int sum = 0;//保存最终结果 int n = 0; int ret = 1;//保存n的阶乘 scanf("%d", &n); for (i = 1; i <= n; i++) { int j = 0; for (j = 1; j <= i; j++) { ret *= j; } sum += ret; } printf("%d\n", sum); return 0; }
对于这道题目,我们可以先从简单的例子进行调试,比如说我先看看当n为3的时候是否满足条件,如下图所示,我们惊讶的发现居然算出来是15,可是我们和清楚的知道当n为3的时候,这个阶乘和的值为9。所以这个程序一定有bug。我们需要对其进行调试
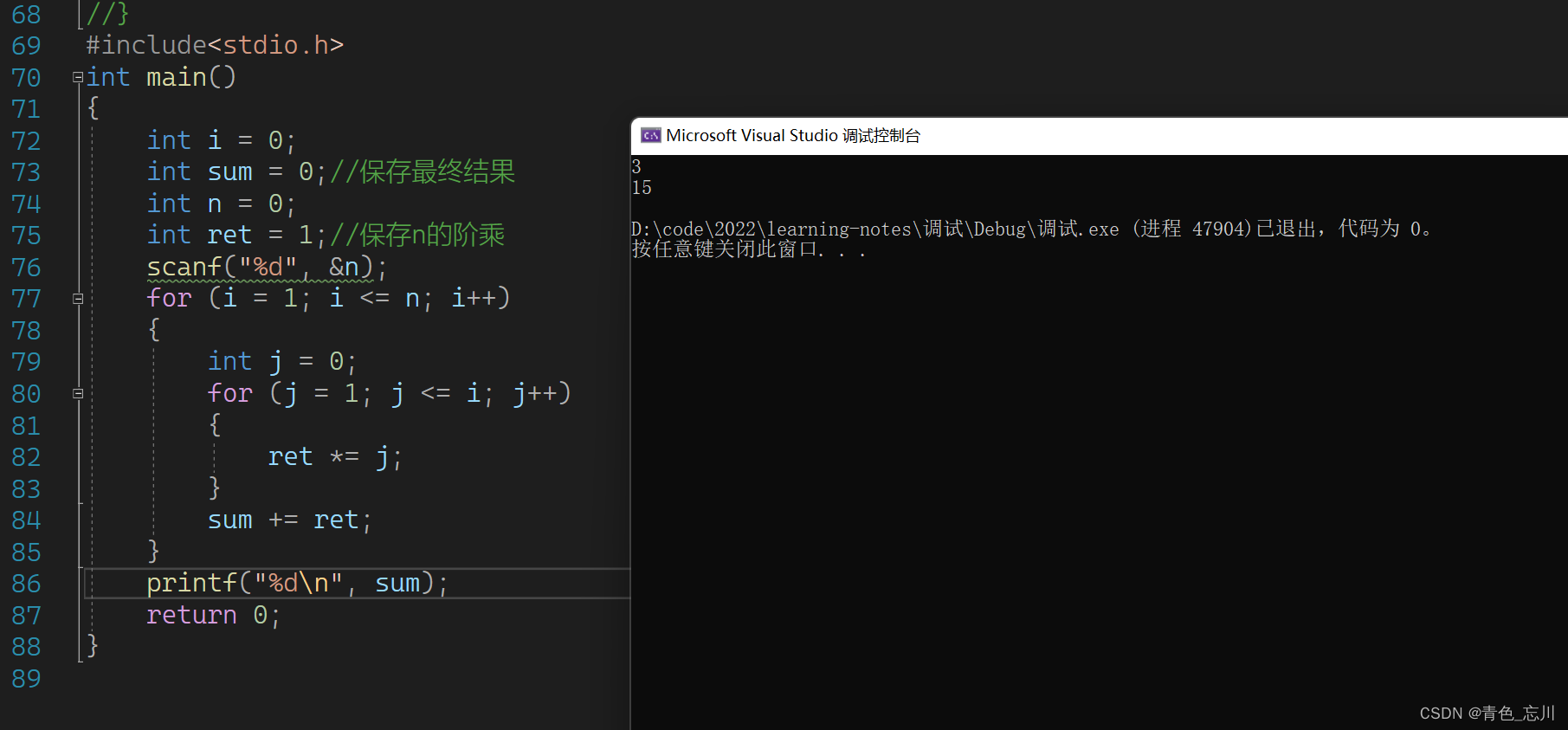
那么我们要对其进行调试,先使用F10,进入调试,然后打开监视窗口,观察每一个值
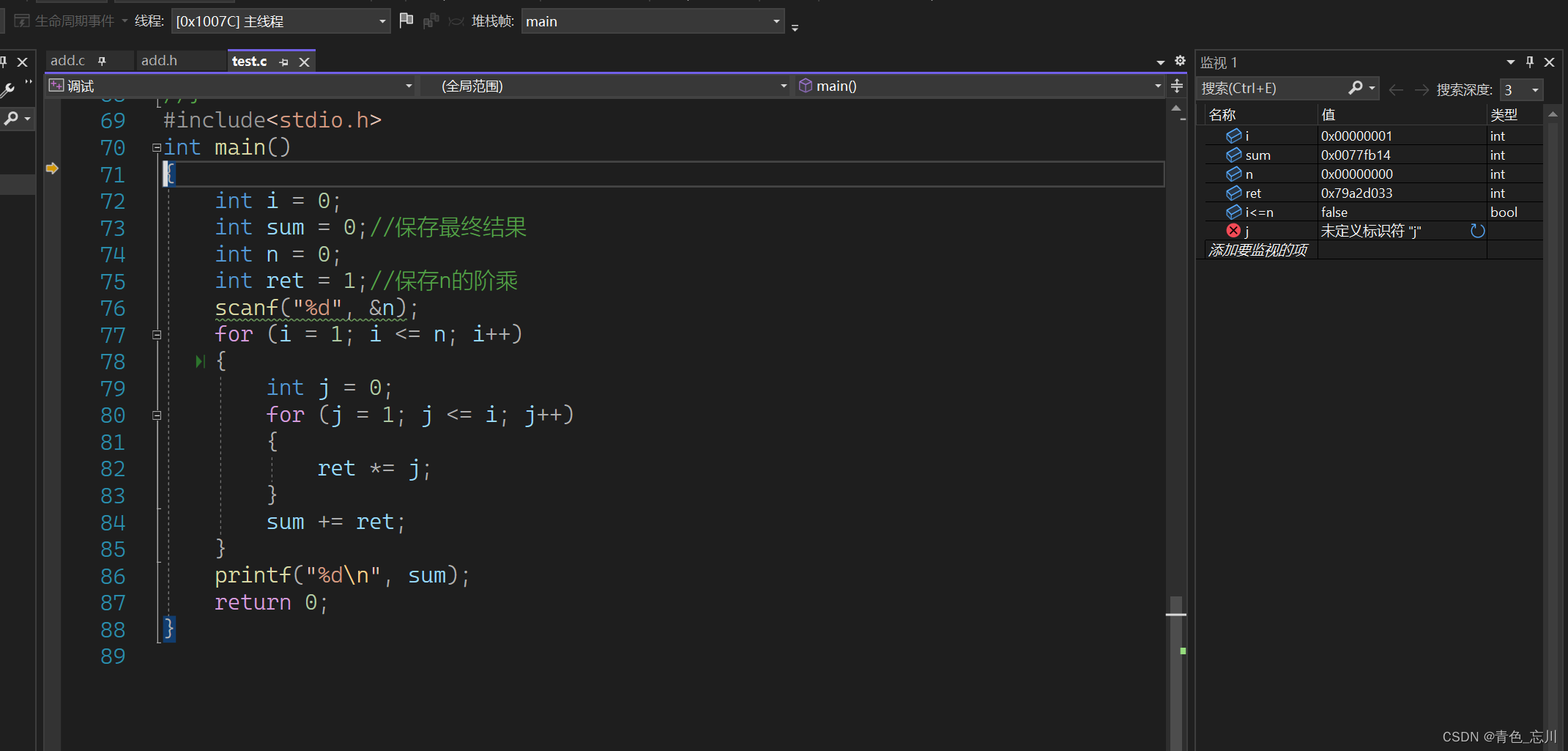
然后我们一步一步使用F11往下走,当我们调试了1层循环以后,我们发现值都符合我们的预期,于是我们就继续往下走
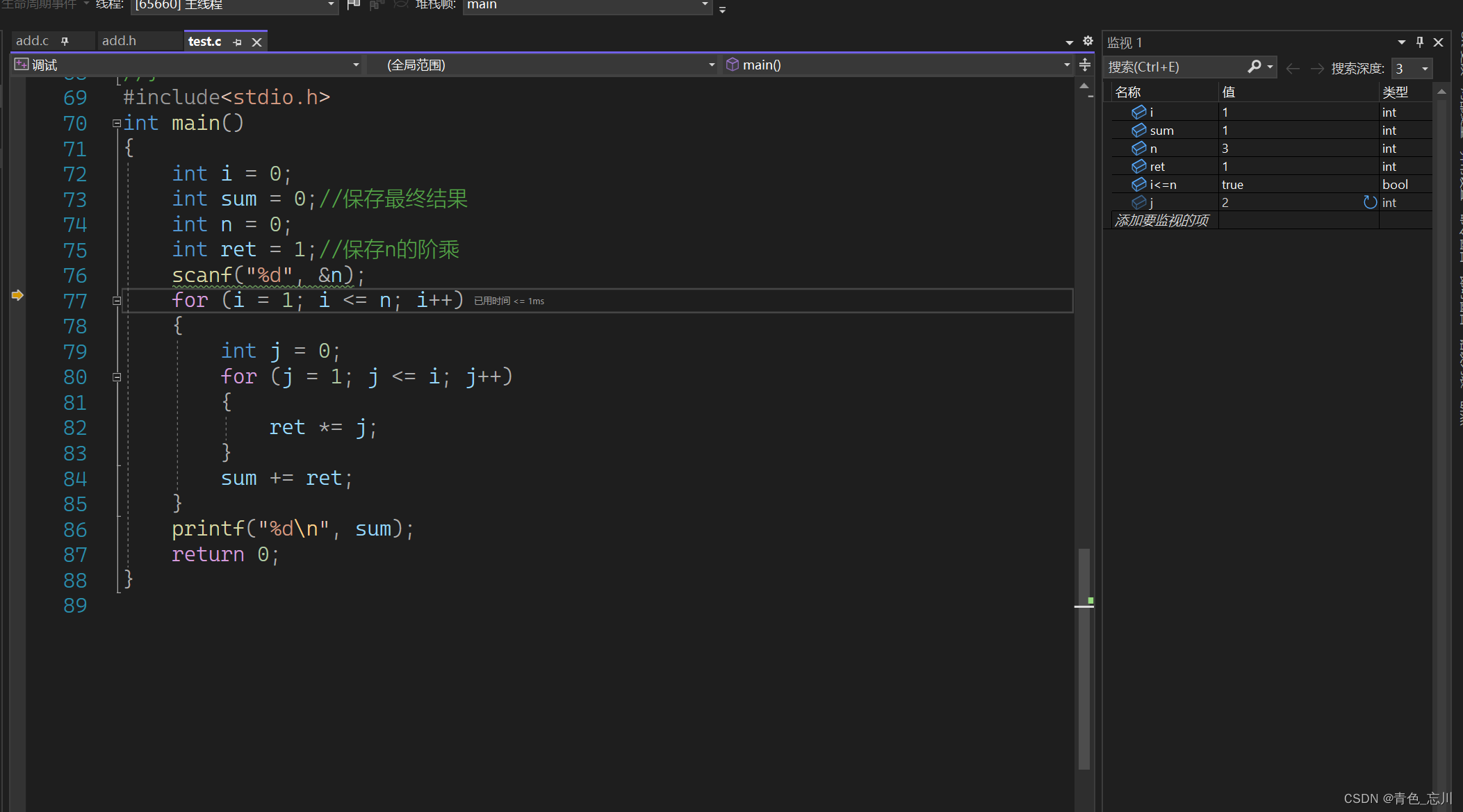
第二次循环的时候,也就是此时已经计算了1!+2!,截至到现在,我们还没有发现任何问题
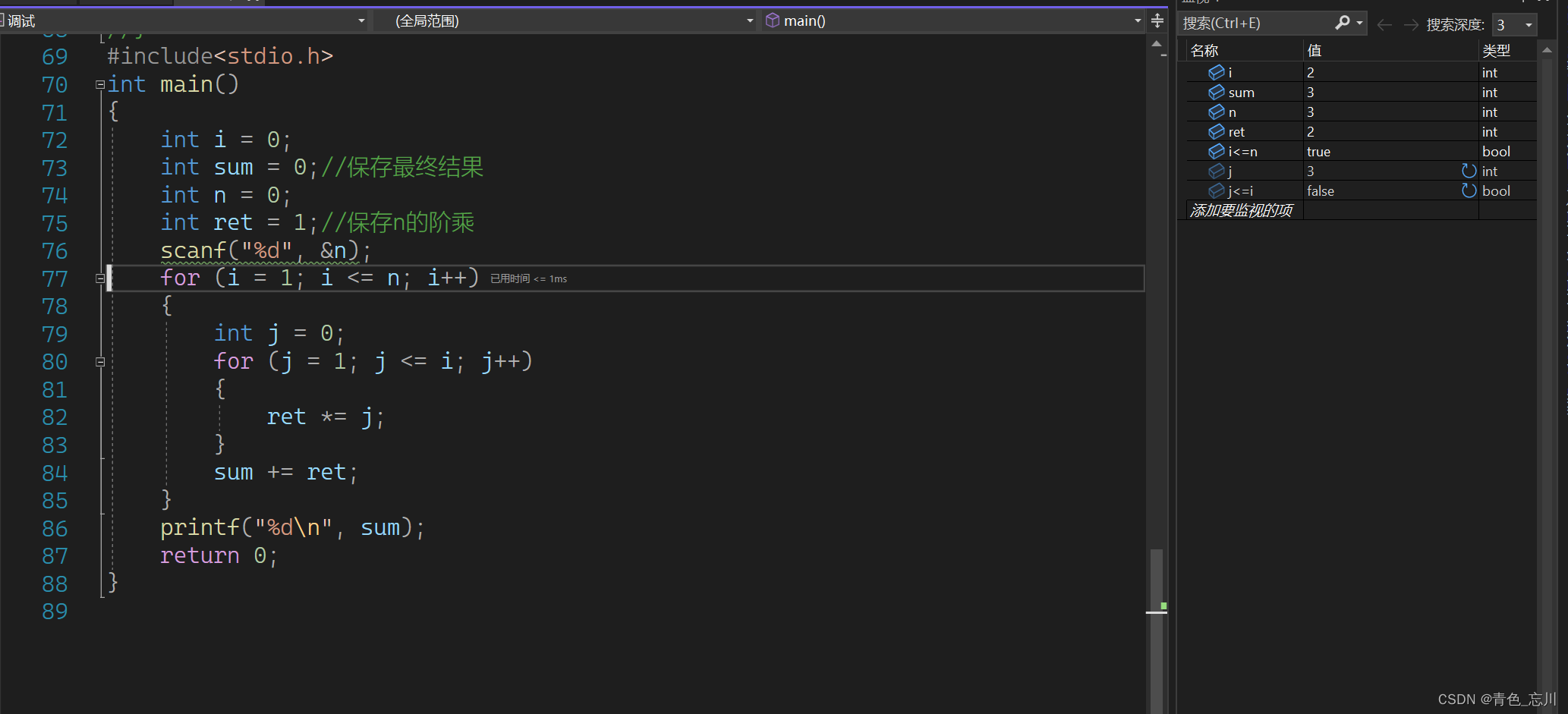
但是当我们进入第三次循环的时候,也就是要计算3!了,此时正在计算3!的值,但是ret值不对劲,此时的ret应该还是为1,因为我们的计算流程是1123,但是他目前计算的是12,那么后面肯定接下来都会出问题的
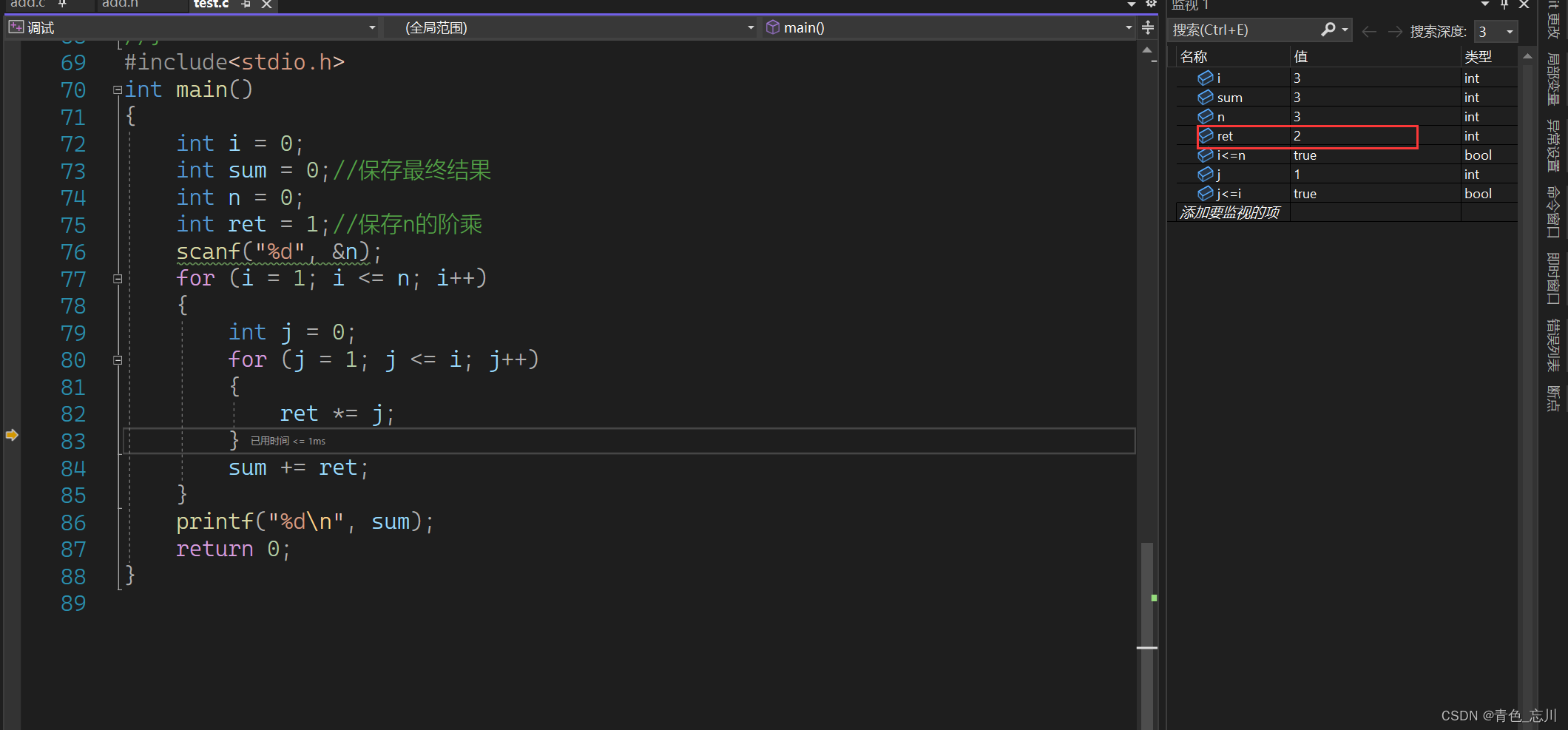
我们可以继续往下走,此时已经变成了122了

继续往下走,此时变成了122*3了刚好j<=i不满足条件了,而这个3!也被计算成了12,所以最终导致sum计算错误,算成了15
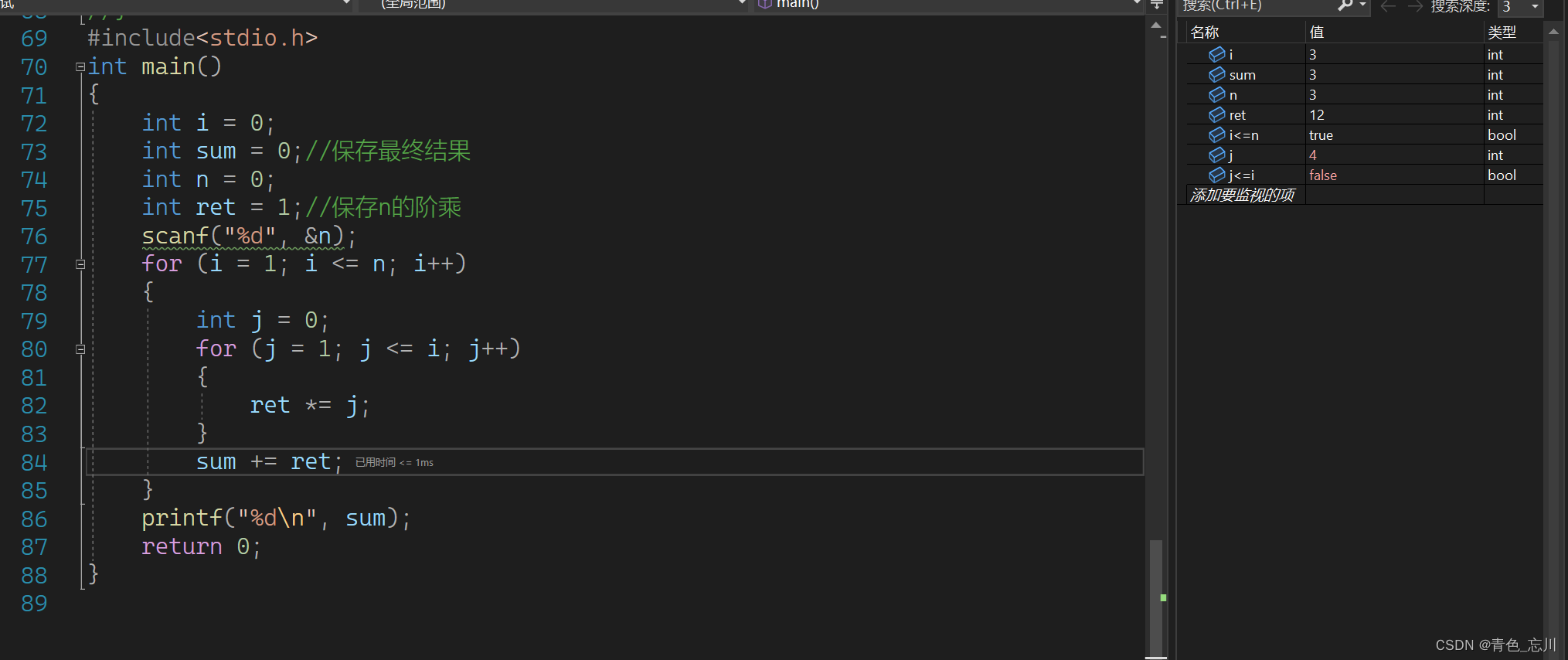
所以这个问题我们也就清楚了,问题的根源就是因为每一次计算一个阶乘的时候,ret没有置为1。所以我们只需要在每一次计算阶乘的时候使ret变为1就可以了
最终修改后的代码如下
#include<stdio.h>
int main()
{
int i = 0;
int sum = 0;//保存最终结果
int n = 0;
int ret = 1;//保存n的阶乘
scanf("%d", &n);
for (i = 1; i <= n; i++)
{
int j = 0;
ret = 1;
for (j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}
运行结果为

当然在这里我们会发现一个问题,就对于循环的调试,我们已经知道前面多少次是没有问题的,我们能不能直接跳到多少层循环呢?当然是可以的,我们可以打一个断点,然后右击断点,选择条件

在这里我们可以加入我们的一个条件,当满足这个条件的时候,断点被触发

比如我们加上条件当i==3时,断点才被触发
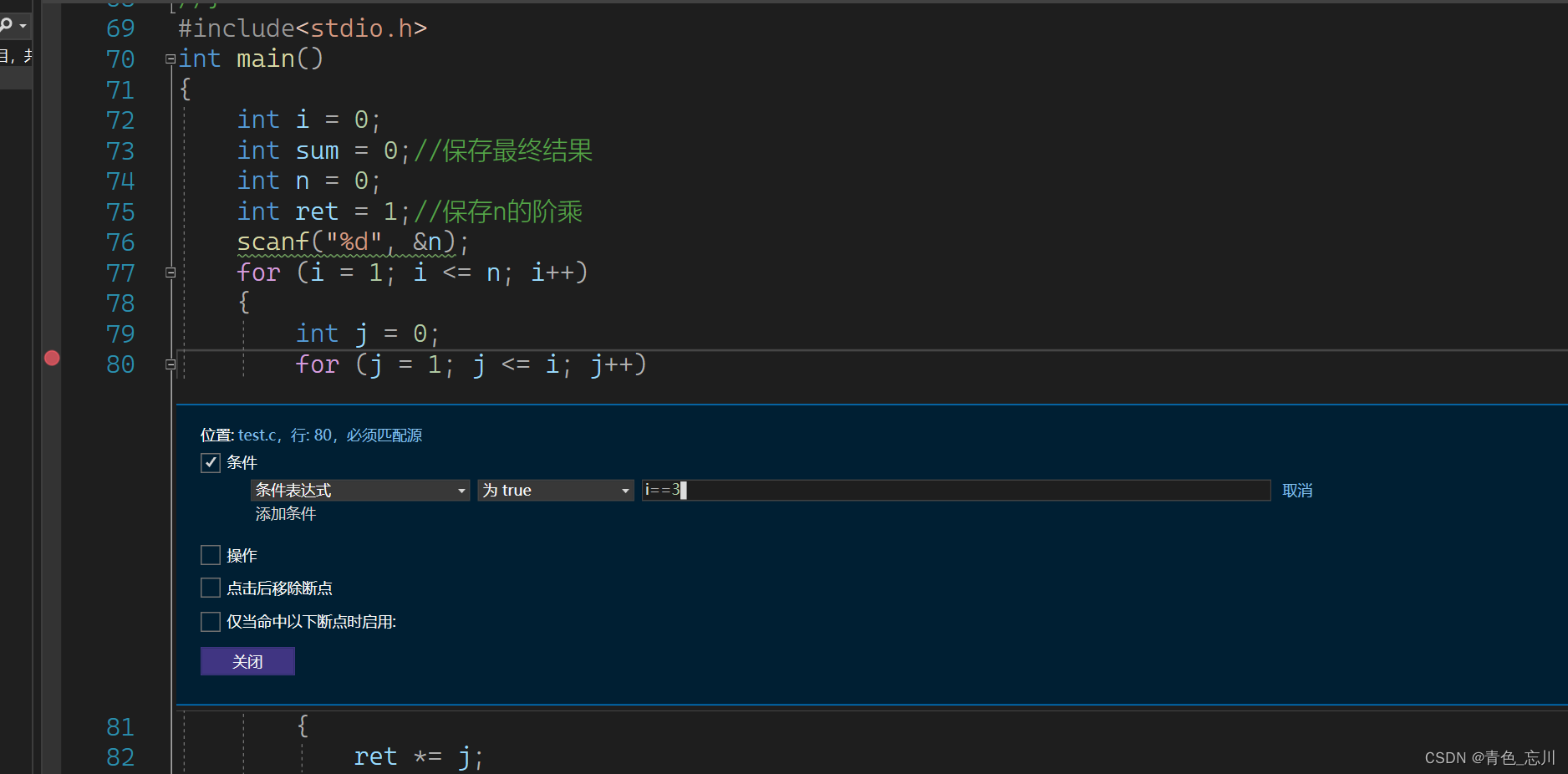
这个时候,我们直接使用F5,就可以直接进入到这个条件时候的断点了

而我们如果想继续跳转多条语句的话,我们可以选择在打一个断点,然后使用F5,这是我们之前就介绍过的方法,当然我们还可以点击绿色的一个比较像二极管的一个箭头,他也可以直接跳转至这条语句。

2.实例二
我们看这样一段代码
#include<stdio.h>
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
printf("hehe\n");
arr[i] = 0;
}
return 0;
}
这段代码我们第一眼看到的就是,这个代码有问题,他的数组越界了。确实是这样的,但是我们想要知道他的运行结果是什么样的,我们先运行一下
如下图所示,结果有点出乎意料。居然陷入了死循环,这又是为什么呢?就算越界了也应该是打印13次就可以了啊,为什么会死循环呢?
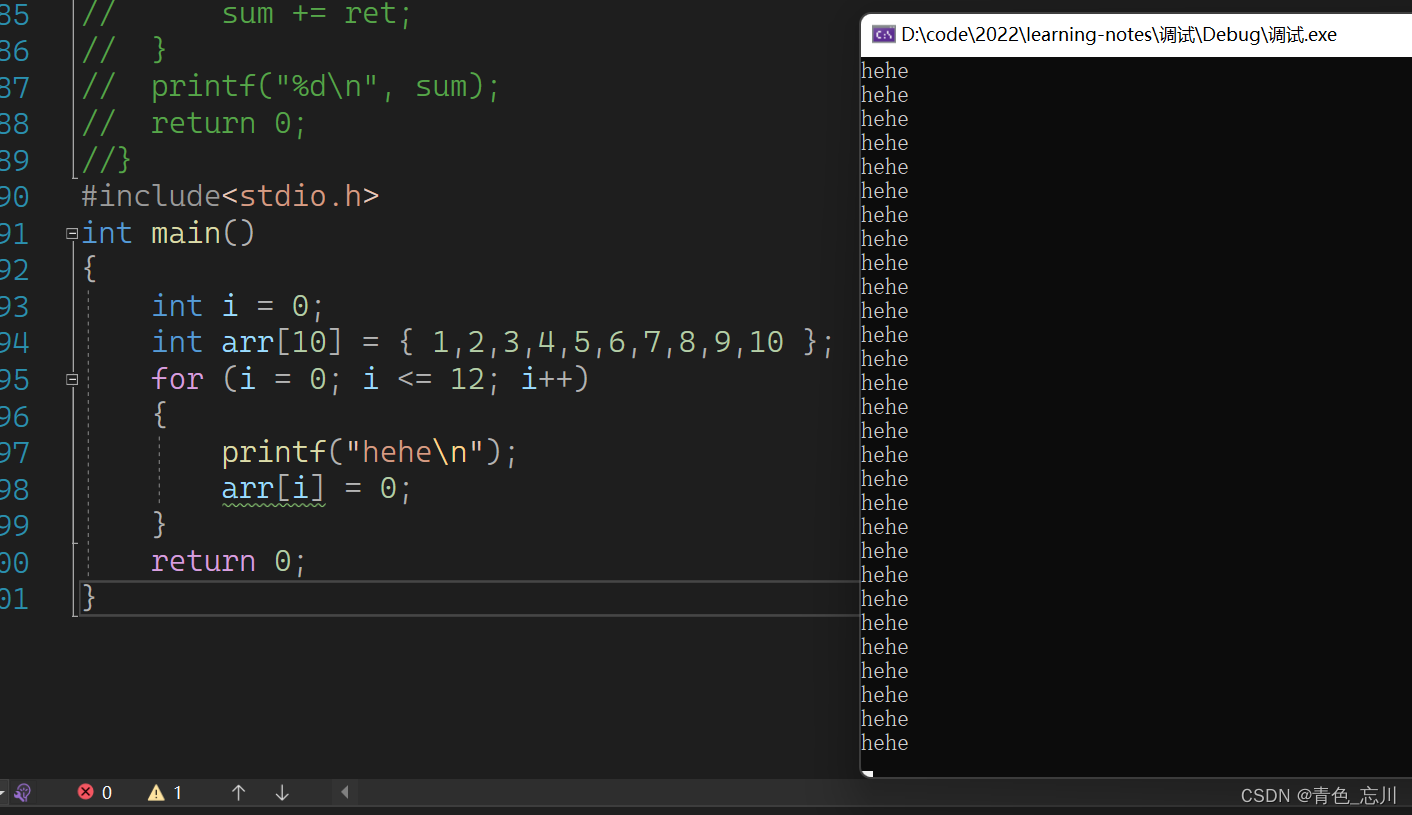
为了寻找问题的根源,我们只能进行调试来进行探究了
如下图所示,我们开始进入调试
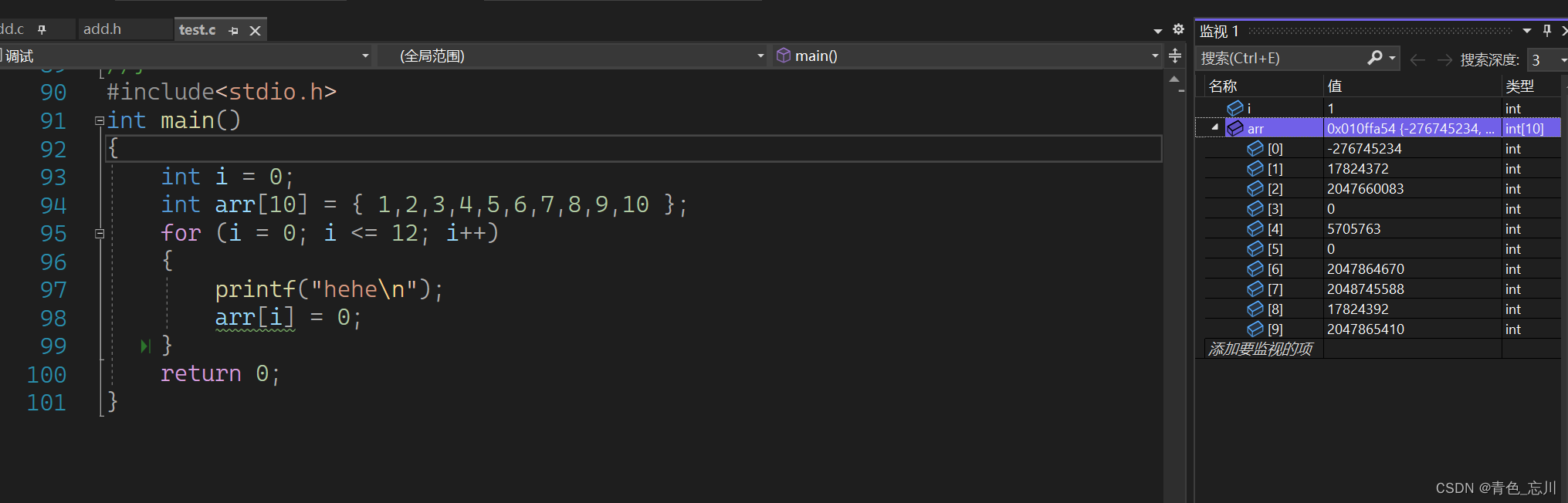
我们使用F11,一步一步往下走
我们该改掉了第一个数组元素,同时也打印出来了一个hehe,似乎没有什么问题

我们继续往下走,直到走到第十个元素,我们都没有发现问题,因为他也打印出来了十个hehe

而我们接下来的话,还会继续进行循环,但是我们的数组是看不到第11,12,13个元素的,所以我们需要在调试窗口输入上这三个元素

然后我们发现,第十一个和第十二个元素都是随机数,但是第十三个元素有点太过于正常了,正常到让我们感觉很奇怪。因为他跟i的值一样,但或许他真的是刚好随机到9了呢,所以我们可以留心一下这个第十三个元素,也就是arr[12]
我们继续往下走,当我将第十一个元素,也就是arr[10]改为0的时候,我们突然发现,arr[12]也变成了10,他跟i似乎同步变化了?也就是改变了i的同时arr[12]也被修改了?与此同时,也打印出来了一个新的hehe
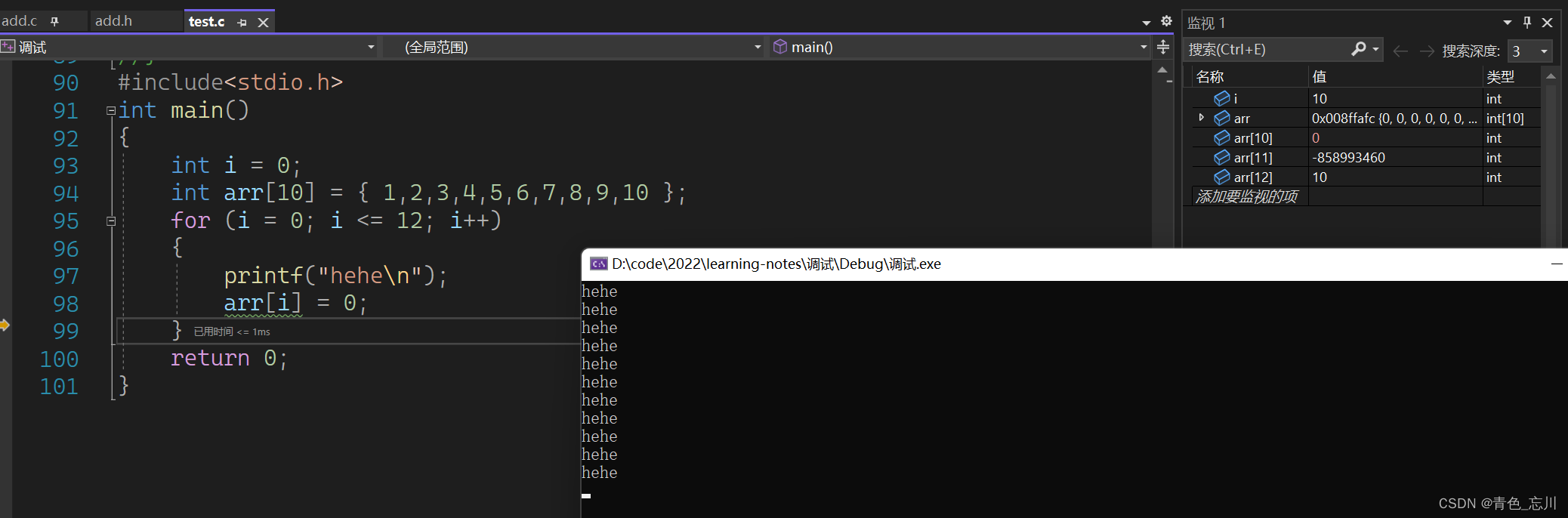
持着怀疑的态度,我们继续往下走,发生了跟刚刚一样的情况。这说明i的地址和arr[12]的地址是一样的,所以才会在修改i的同时修改了arr[12]了。
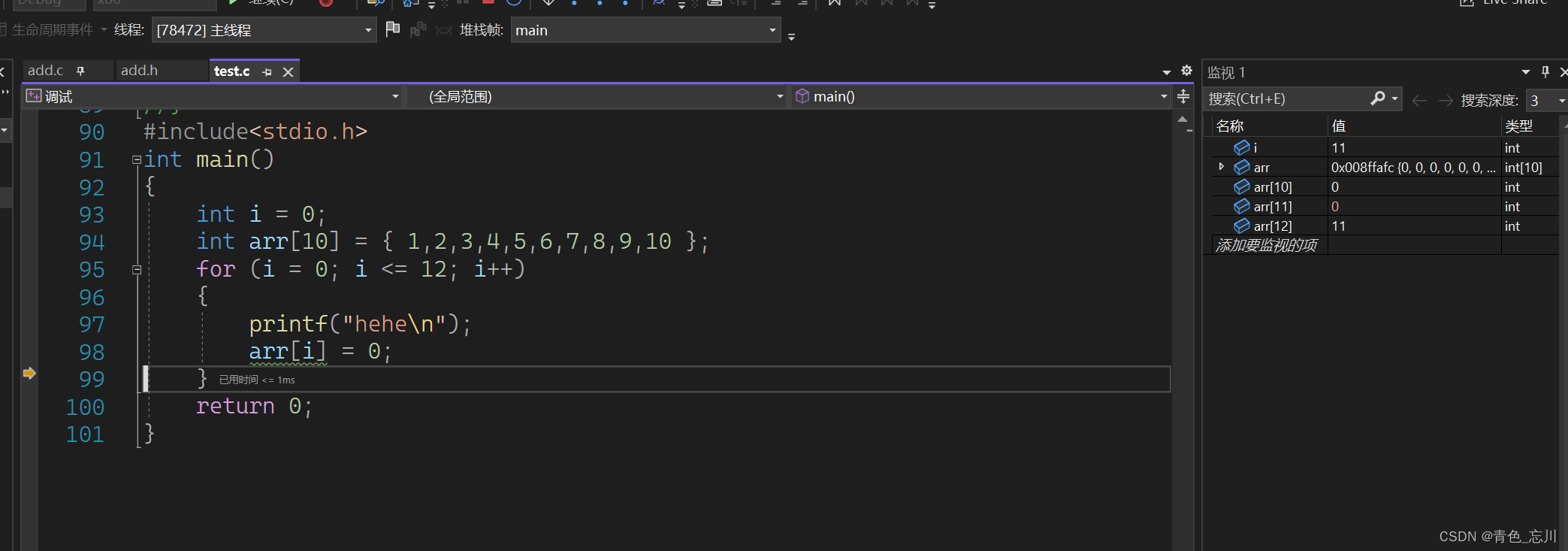
我们就继续往下走,在看看到底还会发生什么,我们惊讶的发现,原来我们让arr[12]变成了0的同时也修改了i的值,而这i等于0了,又满足循环的条件了,所以才会无休止的进行循环下去
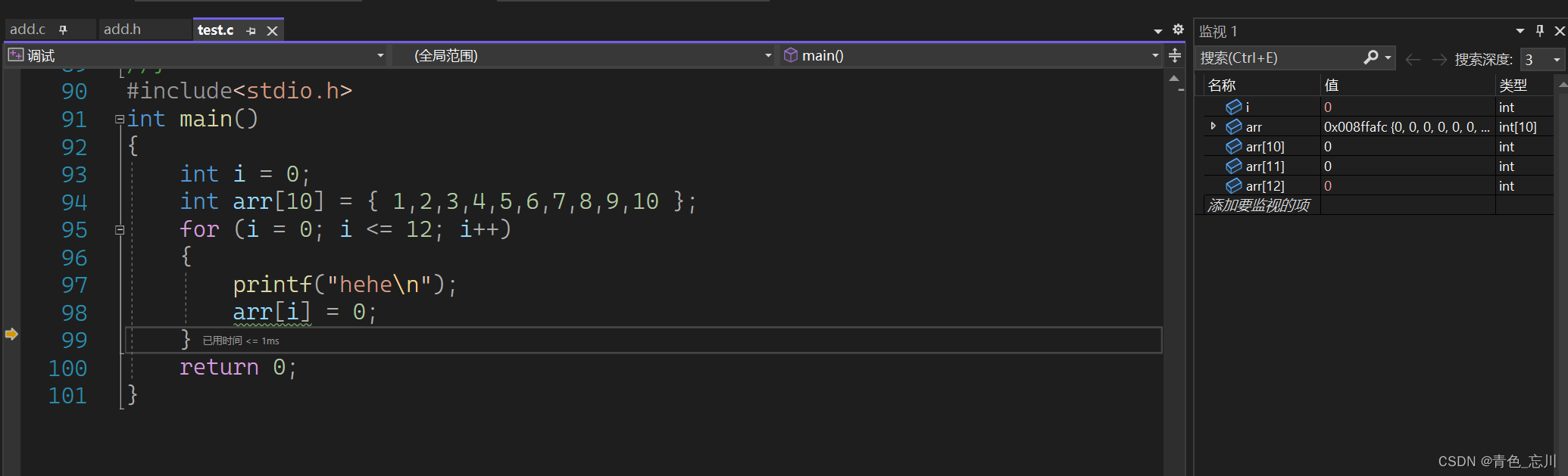
同样我们也可以看一下他们的地址是否一样,如下图所示,果然是一样的。这就是陷入死循环的原因了

那么我们就找到根源了,但是又有一个新的疑问产生了,那就是为什么恰好他们两个的地址是一样的呢?这是巧合吗?还是说是设计好的?其实这个代码是设计好的
我们接下来从内存的角度来思考这个问题
我们在之前已经讲过很多遍内存的大概分区了,如下图所示,内存分为栈区,堆区,静态区
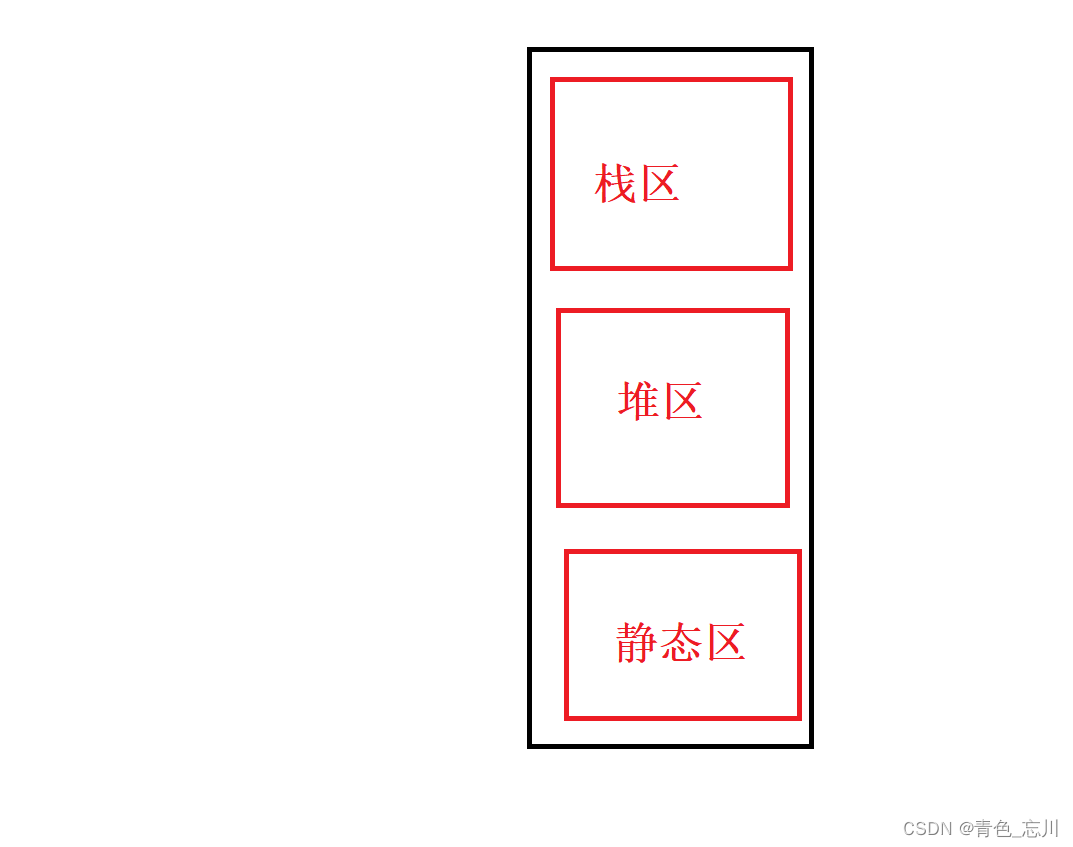
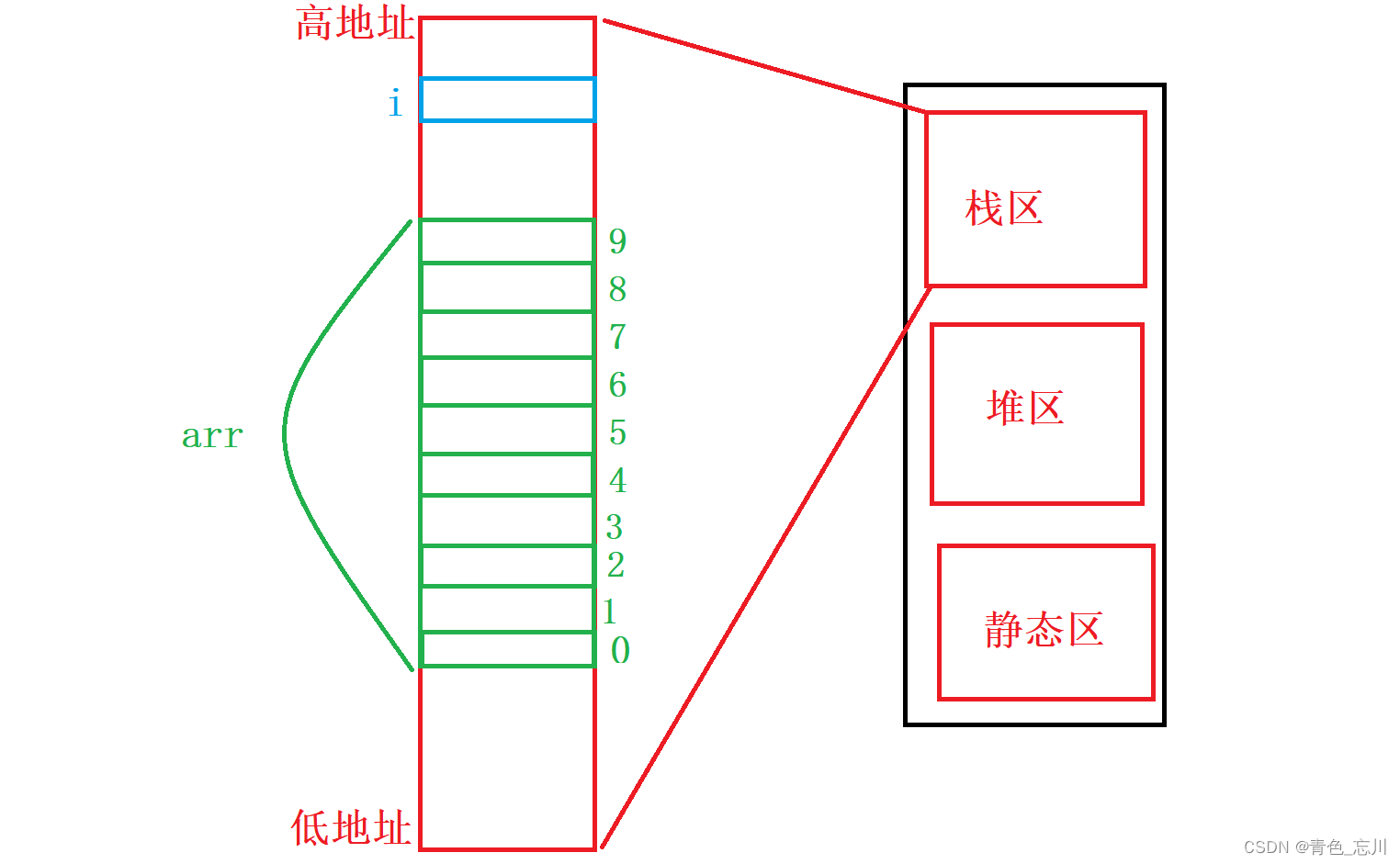
而我们直到栈区是用来存放局部变量等的,而我们这段代码正好就是全是局部变量,所以我们只关心栈区即可,我们将栈区给放大,并假设上方是高地址,下方是低地址
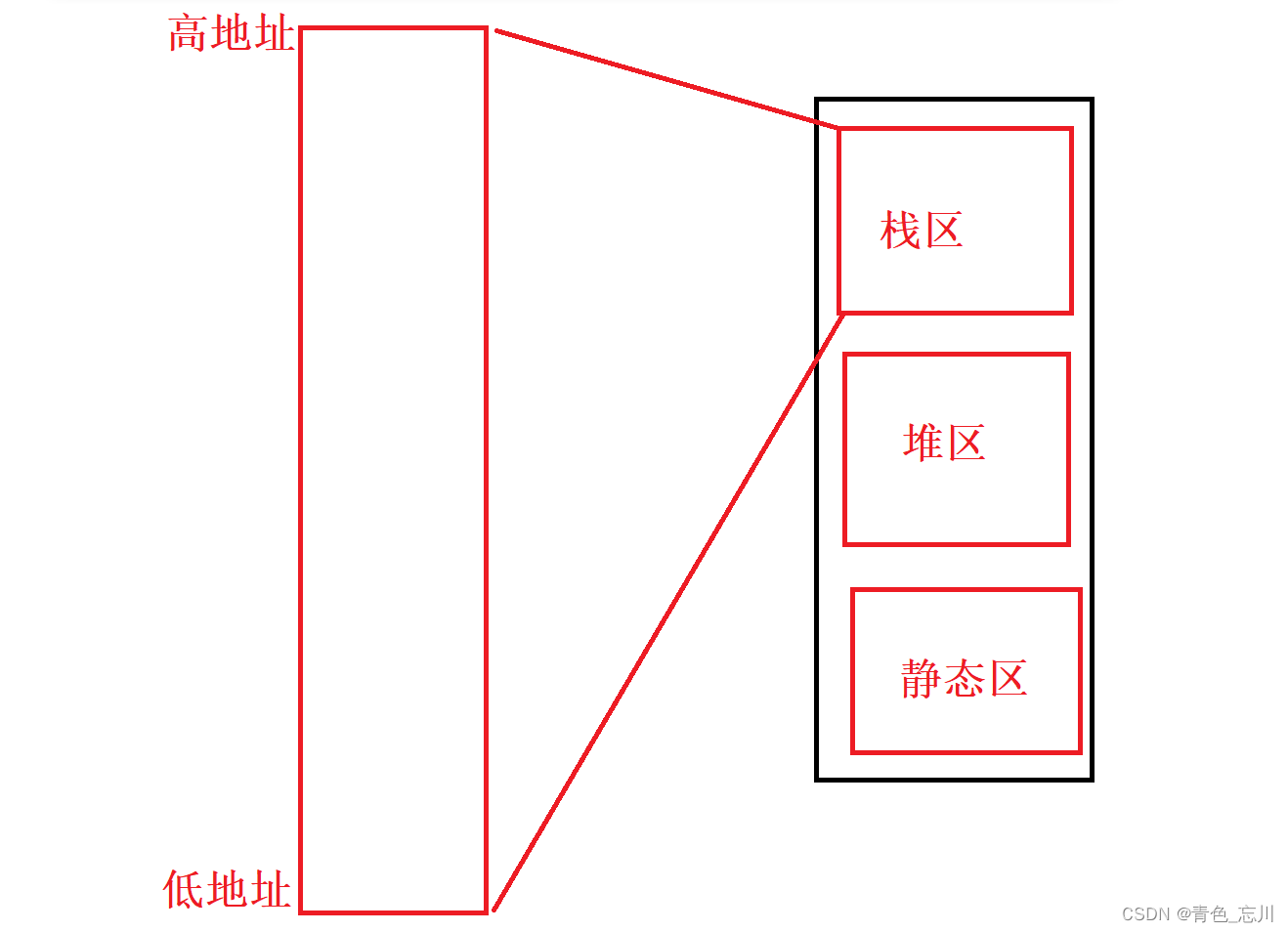
在这里我们先要知道栈区的使用习惯
栈区的使用习惯是,先使用高地址处的空间,然后使用低地址处的空间所以我们现在高地址处创建一个变量i,为他分配四个字节的空间
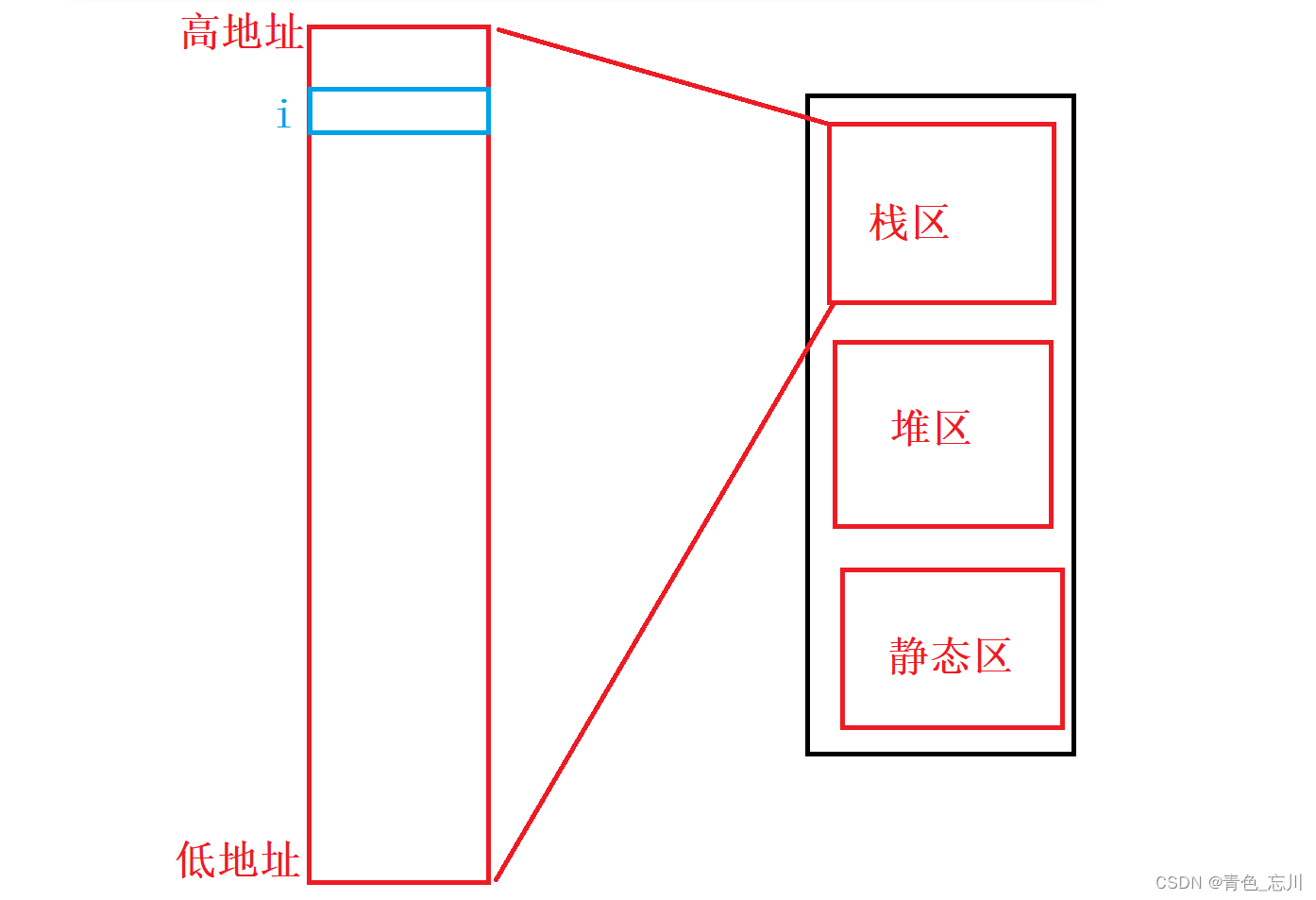
然后接下来我们就该为数组创建空间了,如下绿色部分所示
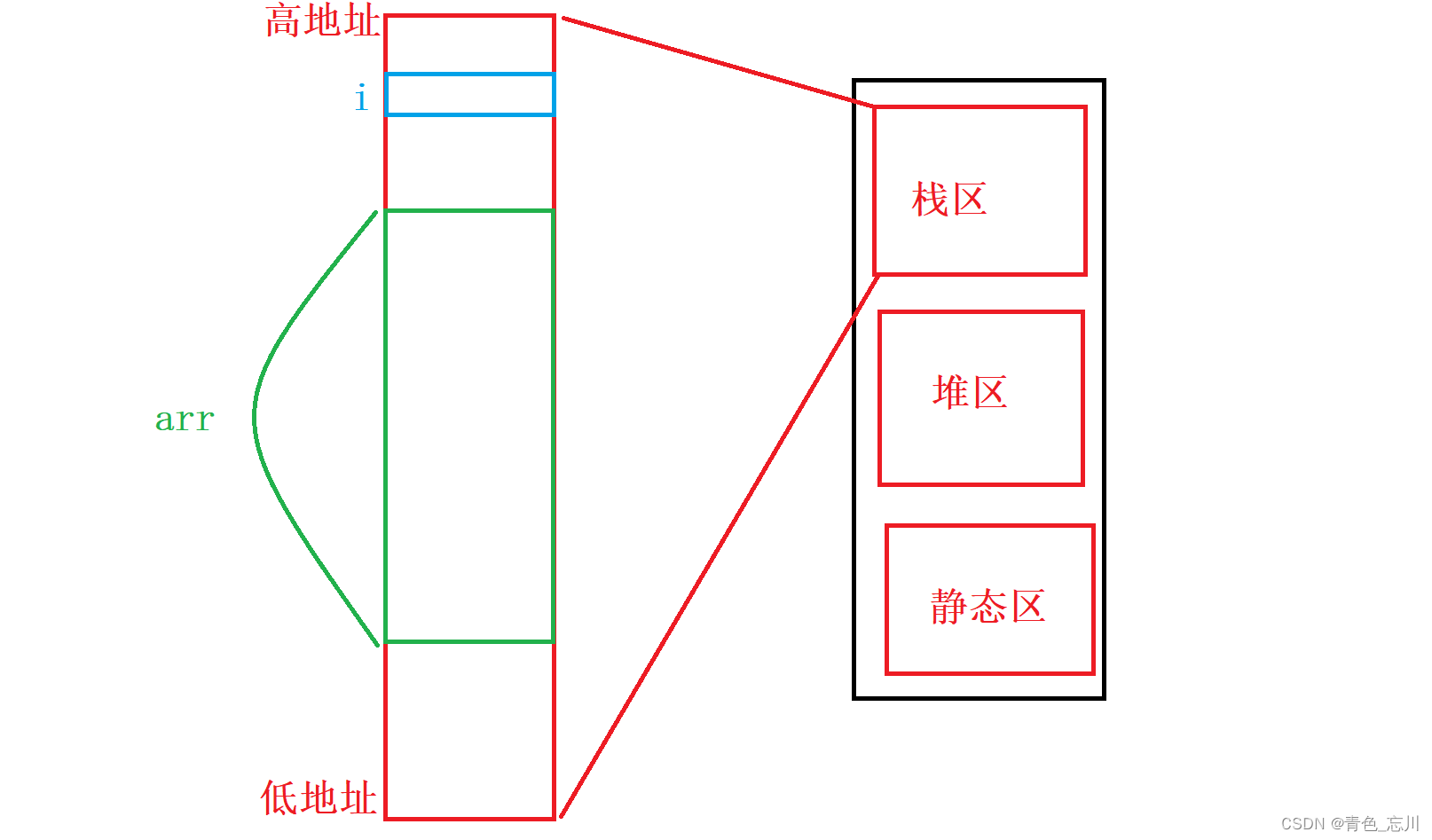
接下来我们将数组中的每一个元素给具体细分,如下图所示,注意,在学习数组的时候,我们就已经提到过,随着数组元素下标的升高,他的地址是不断增大的,所以数组内部是从低地址开始放的
当然,因为我们中间出现了越界,所以我们也把arr[10]和arr[11]也给画上去,如下图所示,就是我们的内存布局了

而这也就是一开始,我们创建好数组以后,给每一个元素进行赋值
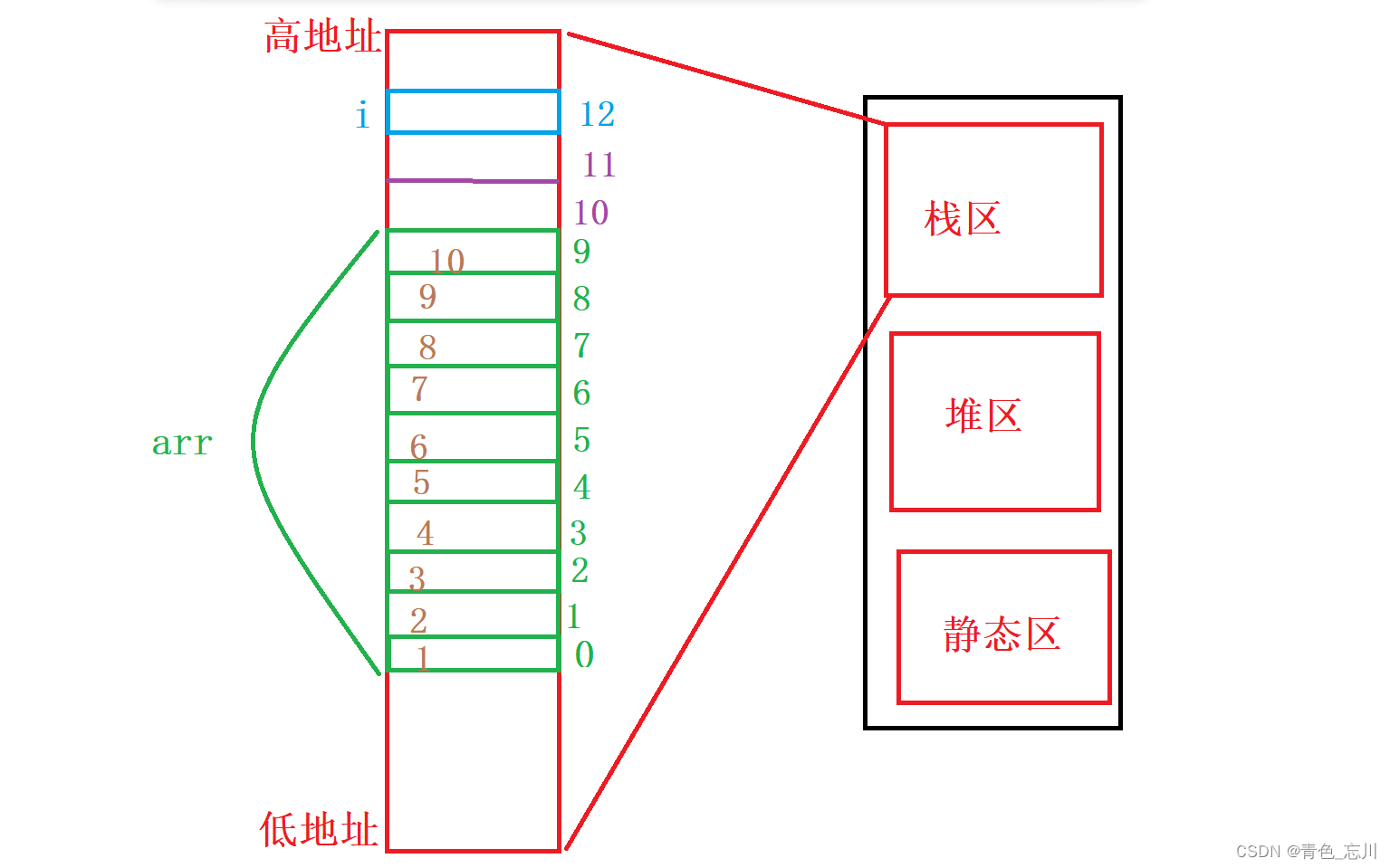
经过我们的十三次循环以后,他就被全部修改为0,而i就是我们的arr[12],所以他也被修改为0,至此,陷入死循环

但是这里又有人产生疑问了,他恰好就是两个整型吗?每一个编译器都是这样的吗?我们说是不一定的
这个例子仅仅只是VS2022在x86环境下的运行结果
比如说在VC6.0的环境下,i和arr之间是没有任何空间的
gcc环境下,i和arr之间有一个整型
而且甚至于在VS2022的x64环境下运行结果都不是死循环,因为x64对这个代码的内存布局跟x86的内存布局是不一样的,有所差异的
我们还需要注意的是,我们在前面提到过debug和release这两种的区别,release是进行了了一些代码优化的,所以在release环境下是不会出现死循环的问题的
我们也可以查看一下他们的地址,正常境况下他应该是i的地址比较大的,但是现在arr的地址是比i大的,所以就算越界了,他也不会产生死循环的

当然,在这里我们就又想到,如果在debug下我们将i的定义放到arr定义后面,那是不是也可以不会产生问题了呢?答案是正确的,他确实不会陷入死循环,但是他会报错的,说数组越界了,因为这个的根本问题就是数组越界导致产生的问题,数组只要不越界就不会有问题的,但是为什么之前那个死循环情况下不会报错呢?其实这是因为之前是编译器在忙着死循环,没空去报错,只有当他把程序跑完,才会提示报错了
要注意千万不在要这个代码上进行无限放大,因为这个代码本身就是极其依赖于环境的,我们上面的例子仅仅是在vs2022在x86环境下的运行结果,我们说这个例子仅仅只是想解释一下这个调试的流程,思考的方式。而不是深究这道题。
五、如何写出优秀的,易于调试的代码
1.优秀的代码
我们首先要知道,优秀的代码有哪些良好的风格
代码运行正常
bug很少
效率高
可读性高
可维护性高
注释清晰
文档齐全
常用的一些coding技巧
使用assert
尽量使用const
养成良好的编码风格
添加必要的注释
避免编码的陷阱
2.几个经典的例子
(1)模拟实现strcpy函数
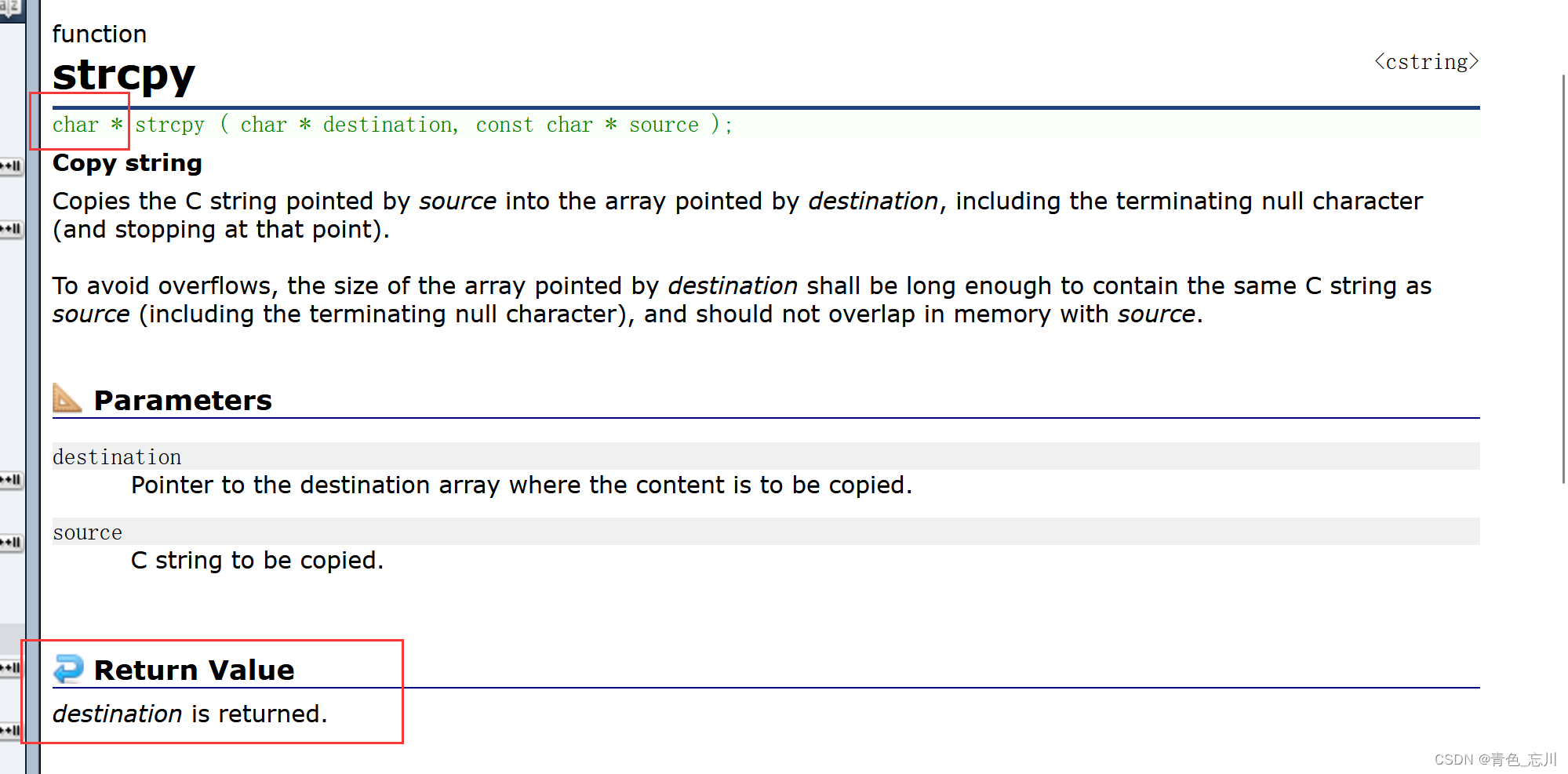
要想模拟实现strcpy函数,那我们得先知道strcpy函数是做什么的,我们打开cplusplus网站,进行查阅
如下图所示,他的意思是,将source所指向的C字符串拷贝到destination上去,包括最后的\0字符

我们先用一下他这个库函数,如下图所示,他将hello world这个字符串拷贝到arr1中去了
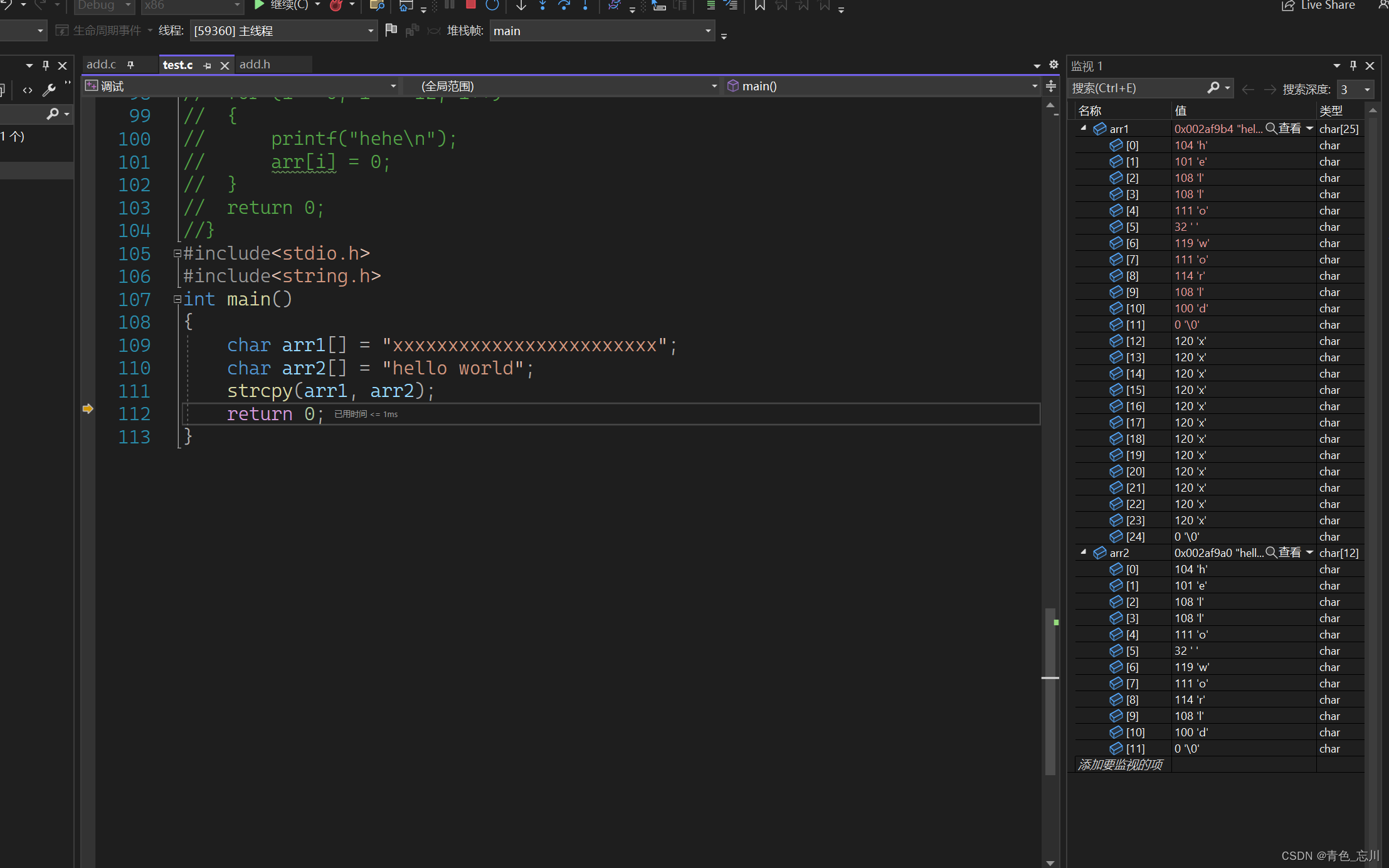
那么既然我们知道了他的功能,那么我们就来实现一下这个函数吧
根据这个使用的功能,我们不难写出这个代码,这段代码接受了两个指针,然后依次遍历他们,一个一个往后赋值,条件就是source最终所指向的内容只要是\0就是字符串结束了,就需要结束循环了,但是此时\0还没有拷贝进去,所以就需要再次拷贝一下,就能实现这个功能
#include<stdio.h>
void my_strcpy(char* dest, char* source)
{
while (*source != '\0')
{
*dest = *source;
dest++;
source++;
}
*dest = *source;
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char arr2[] = "hello world";
my_strcpy(arr1, arr2);
return 0;
}
当然,这样确实是可行的,但是这个函数有点过去啰嗦了,所以我们试着简化一下这个函数,比如说,dest++和source++,能不能合并到解引用那一块呢?我们说是可以的,代码如下
#include<stdio.h>
void my_strcpy(char* dest, char* source)
{
while (*source != '\0')
{
*dest++ = *source++;
}
*dest = *source;
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char arr2[] = "hello world";
my_strcpy(arr1, arr2);
return 0;
}
不过这样的话,中间有两条很相似的语句,我们可不可以也将其优化掉呢,我们说是可以的,代码如下,这样确实是可行的,因为赋值操作符最终的结果就是他的值,而最后一步刚好是将\0赋给了dest,dest也接受了\0,同样也刚好不满足循环的条件了,因此这个代码是没有问题的
#include<stdio.h>
void my_strcpy(char* dest, char* source)
{
while (*dest++ = *source++)
{
;
}
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char arr2[] = "hello world";
my_strcpy(arr1, arr2);
return 0;
}
代码简化是简化了,但是这个代码有没有bug呢?其实是有的,假如说我们在传参数的时候不小心传入了一个空指针,因为空指针是不可以解引用的,所以中间肯定会出现问题的
如下所示,代码已经挂了

而同样当我们进入调试的时候也会显示他有问题
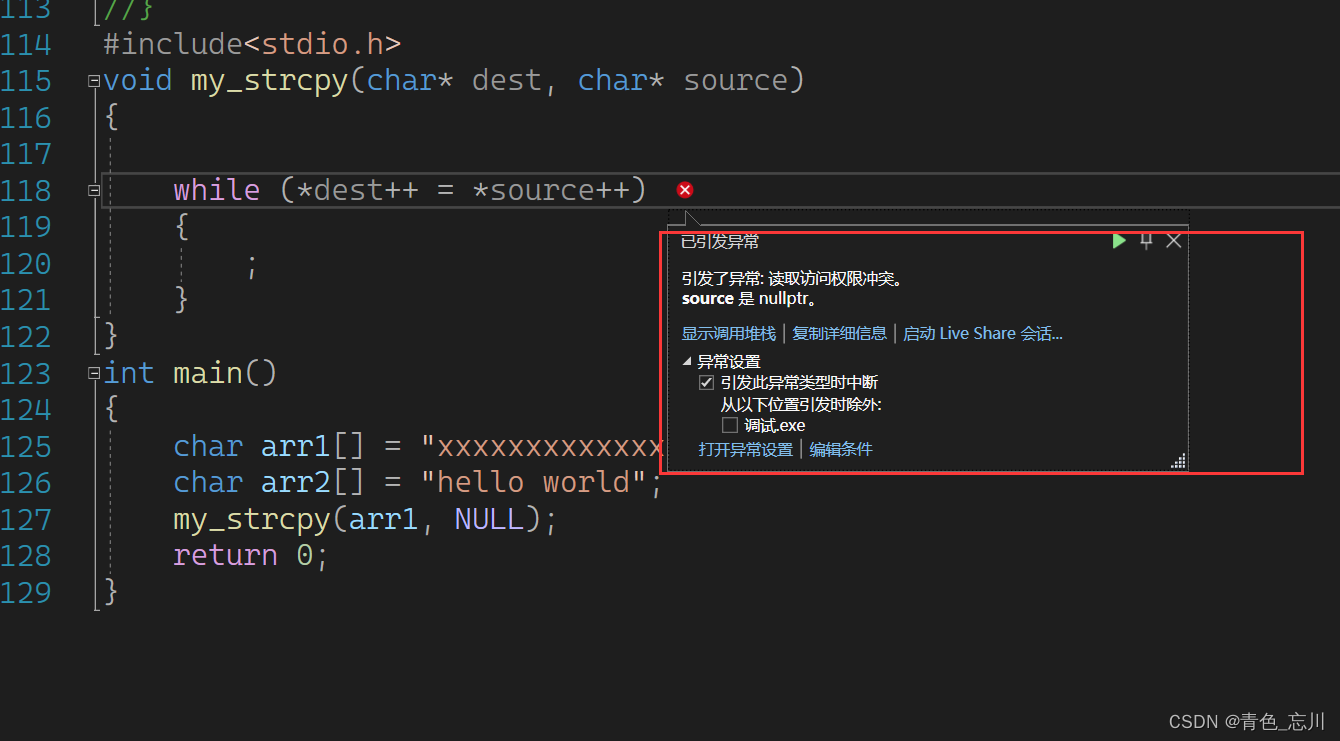
所以我们需要补掉这个漏洞,我们可以使用一种比较温柔一点的方式,只要为空指针就让他不要执行了,直接返回即可,如下代码所示
#include<stdio.h>
void my_strcpy(char* dest, char* source)
{
if (dest == NULL || source == NULL)
{
return;
}
while (*dest++ = *source++)
{
;
}
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char arr2[] = "hello world";
char* p = NULL;
my_strcpy(arr1, p);
return 0;
}
虽然这样确实可以避免程序挂了,但是我们这并不是在解决问题啊,这只是在规避问题。并没有使得问题得到有效的解决,而且在未来写代码量很大的项目时候,一旦出现一个因为没注意的空指针,我们也不清楚问题究竟出现在哪里。所以这种方式虽然是可行的,但是不太好,所以我们就需要进行优化这个方法
在c语言中一个东西叫做断言,assert,在他里面可以放一个表达式,如果表达式为假,则会报错,并显示报错的行数,如果表达式为真,则什么都不发生
所以代码如下所示
#include<stdio.h>
#include<assert.h>
void my_strcpy(char* dest, char* source)
{
assert(dest != NULL);
assert(source != NULL);
while (*dest++ = *source++)
{
;
}
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char arr2[] = "hello world";
char* p = NULL;
my_strcpy(arr1, p);
return 0;
}
运行结果为如下所示,他会给你报出错误的信息和行数,这就能让我很好的去解决问题,而不是规避问题

当然也可以将这两个表达式合并,使用逻辑与操作符,因为空指针NULL其实就是0
#include<stdio.h>
#include<assert.h>
void my_strcpy(char* dest, char* source)
{
assert(dest && source);
while (*dest++ = *source++)
{
;
}
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char arr2[] = "hello world";
char* p = NULL;
my_strcpy(arr1, p);
return 0;
}
当然这里也要注意一点,assert在release版本是被优化掉的,他没有这个东西,因为在release版本是不需要这个的,他是一个发布版本,而在debug版本中我们肯定是已经找到错误了
那么这样做就万事具备了吗,他不会在出bug了吗,真的没有漏洞了吗?其实不是的,他还有一个漏洞,我们看这样的场景
在这段代码中,我们让p指向一个常量字符串,然后假如说,我们这个程序员喝醉了,我们本来是想让p拷贝到arr1中的,但是他不小心写成了将arr1拷贝到p中去了
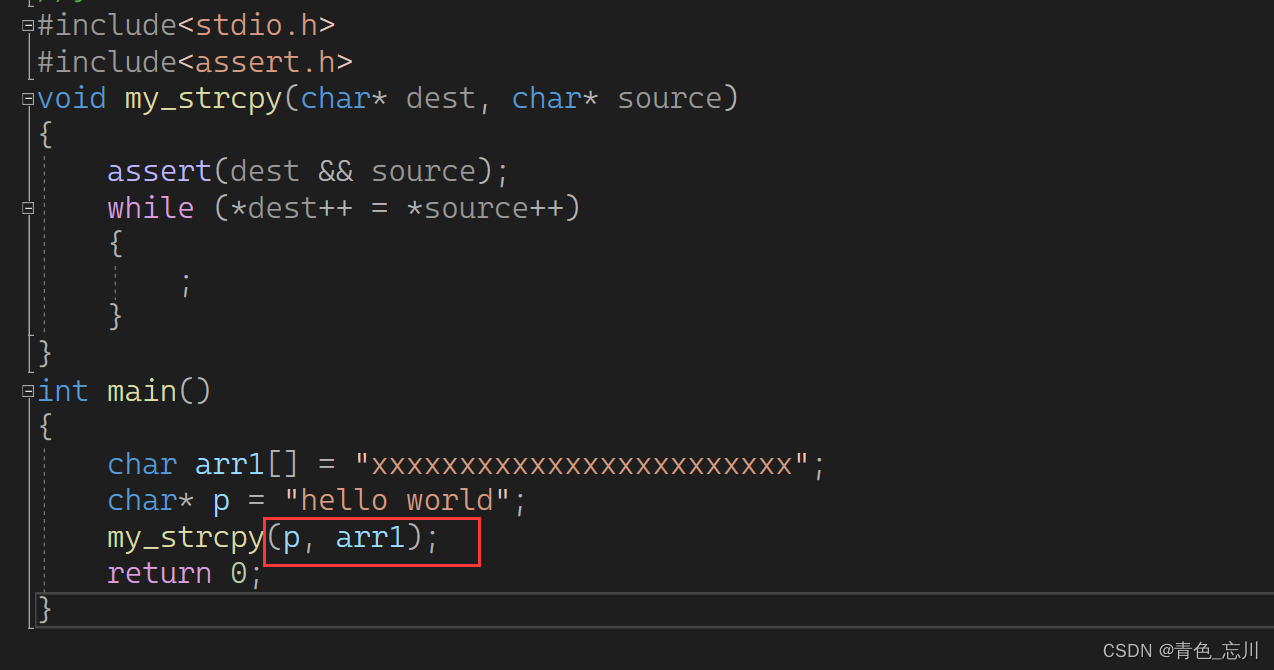
又或者说这里没有写错,但是函数内部的dest和source写反了
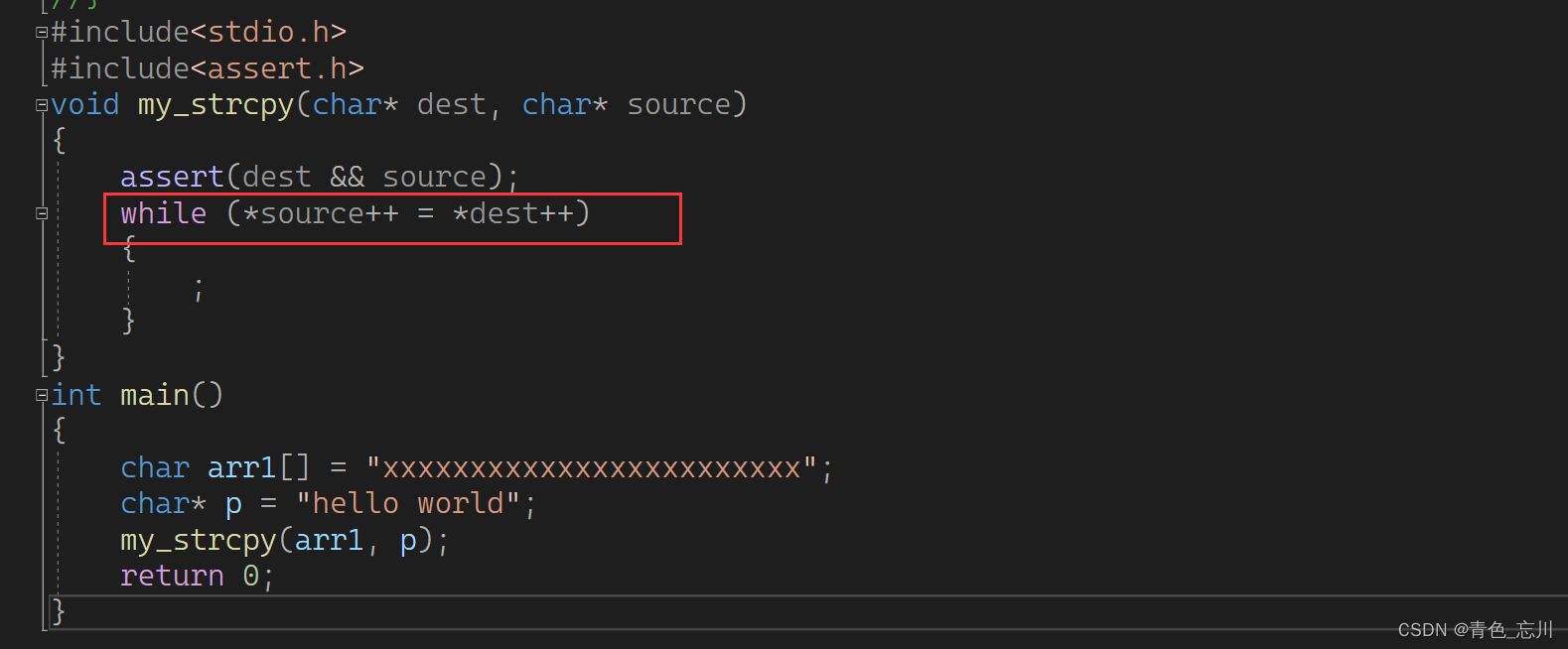
那么我们知道,常量是不可以被修改,这样程序一定会报错的,那么常量是不可以被修改的,我应该如何避开这个漏洞呢?其实只需要在函数中的第二个参数上加上一个const就可以了
代码如下
#include<stdio.h>
#include<assert.h>
void my_strcpy(char* dest,const char* source)
{
assert(dest && source);
while (*source++ = *dest++)
{
;
}
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char* p = "hello world";
my_strcpy(arr1, p);
return 0;
}
报错信息为下图所示,有了报错信息,我们就能够发现问题,去解决掉他了
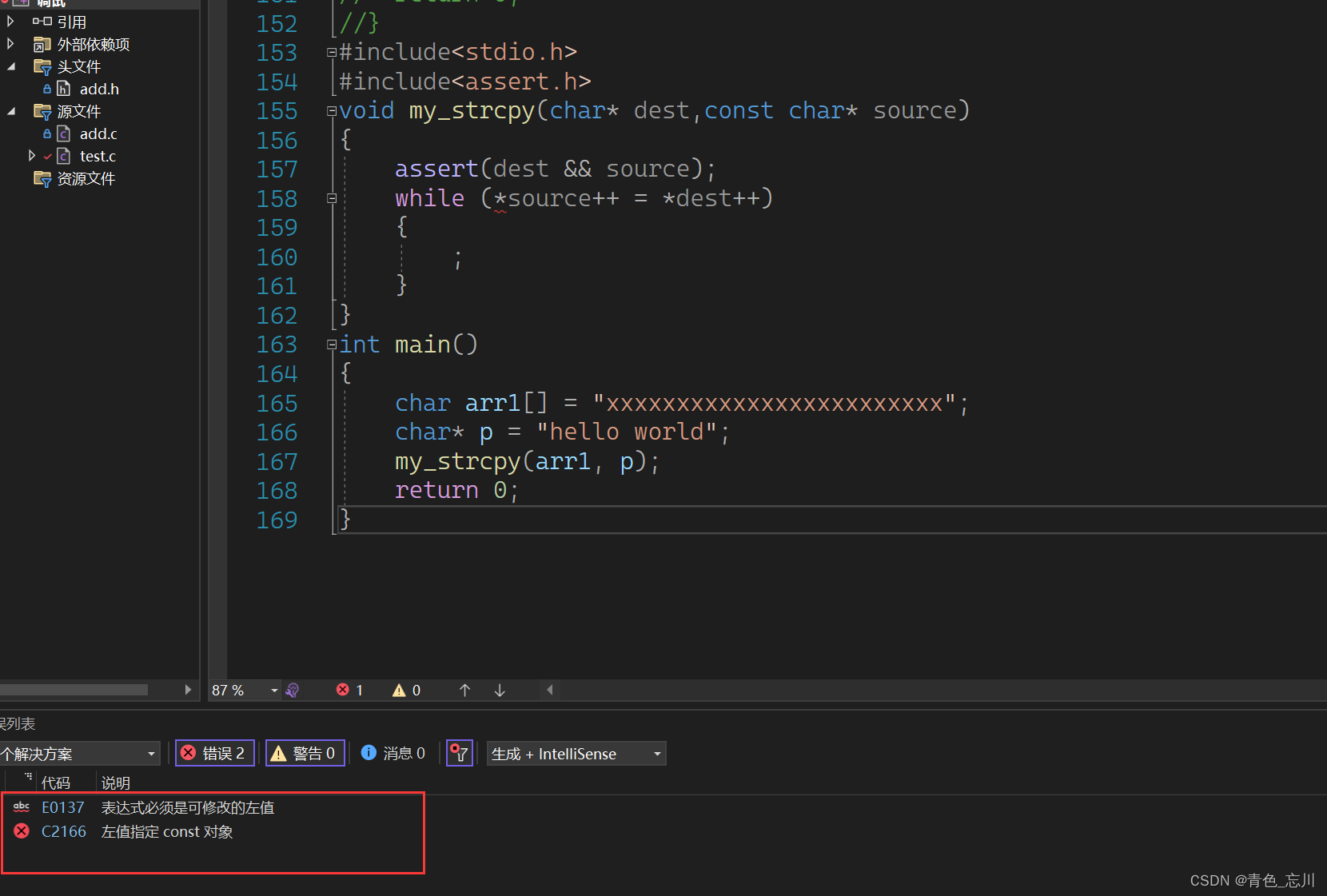
这里问题又来了,为什么加上const就可以了呢?
在这里我们就详细讲解一下const的使用
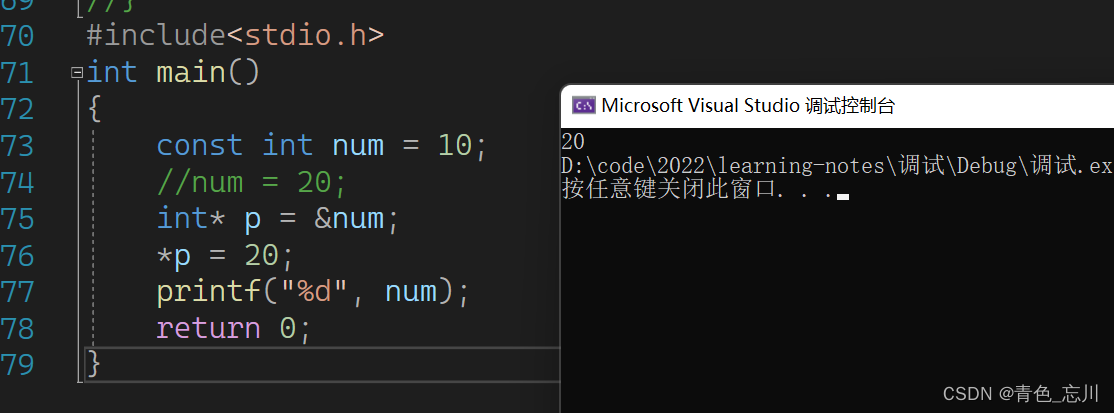
我们首先是知道,相关修改一个变量的值,我们可以通过两种方法来进行修改,一种是直接修改的,另外一种是通过指针来间接进行修改
但是当我们不想让一个值被修改的时候,我们就会使用const来修饰这个变量,我们知道,const可以修饰一个变量,使他获得一个常属性,具有了常量的一些性质,但是他本质上还是一个变量,所以他就不会被修改,如下图所示

但是这样的话,有人就会专挑一些漏洞,能不能给他取一个地址,通过指针来修改他呢?如下图所示,我们发现居然是可以的,那这样的话就不符合我们期待的了,我们本来是希望让他不要被修改,但是这样的操作就让他被修改了。这是一个漏洞,我们得避免他。
那么我们该如何解决呢?其实我们可以给指针加上一个const进行修饰,这样的话就无法通过指针来间接修改这个变量了,这个就相当于对*p给了一个枷锁,使得他无法被修改
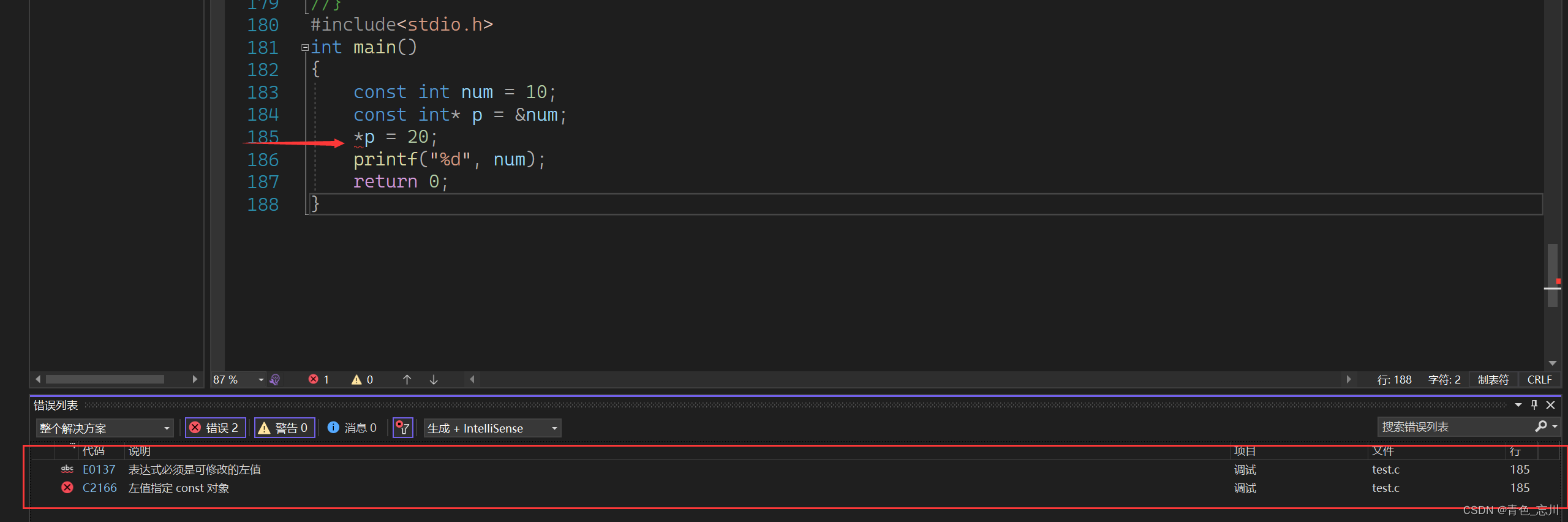
而且我们这个const甚至还能放在int的后面,*的前面
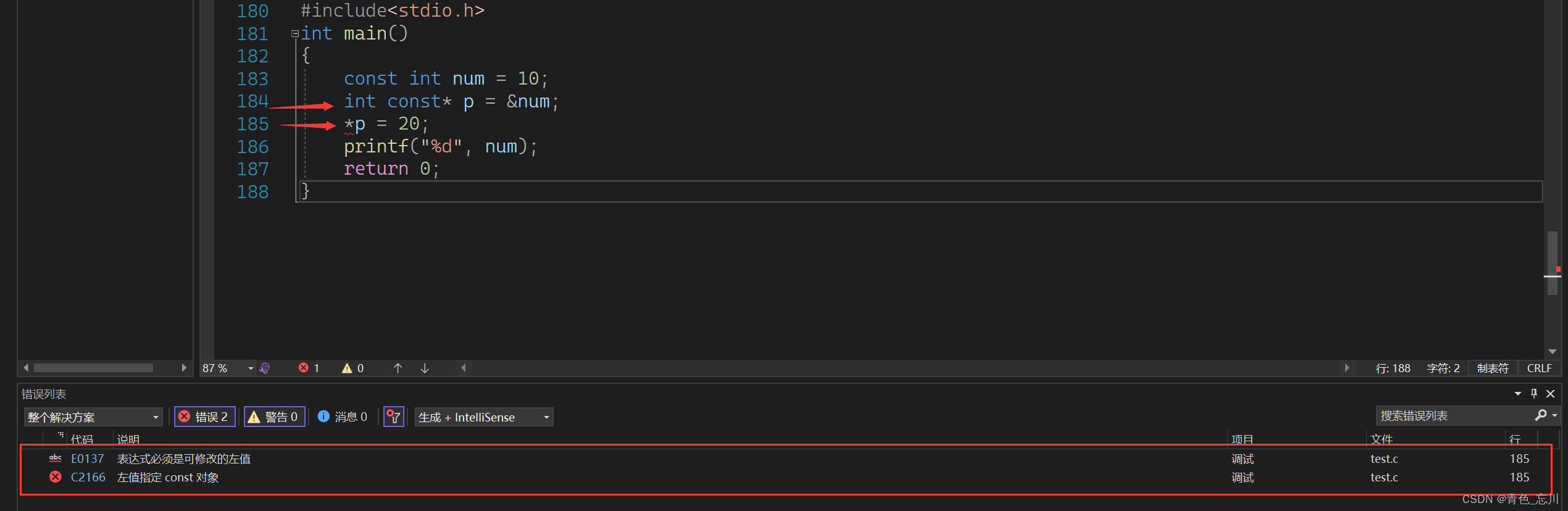
但是这样的话,*p不可以被修改,但是p能被修改吗?答案是可以的,这样做是没有任何问题的

那么如何使得p的值不会被改变呢?我们把const移动到*的后面去,我们就发现了p不能被修改了

由此我们就知道了const的作用了
我们来总结一下const的作用
const修饰指针的时候
1.如果const放在*的左边,那么const修饰的是指针指向的内容,表示指针指向的内容,不能通过指针来修改了,但是指针变量本身可以被修改
2.如果const放在*的右边,那么const修饰的是指针变量本身,表示指针变量本身的内容是不能被修改的,但是指针指向的内容, 可以通过指针来修改
所以我们现在回过头来看我们之前的那个代码,加上const以后,*source就不允许被修改了,一旦被修改,就会像下图所示,进行报错,这时候我们就会发现这个错误,从而修改它
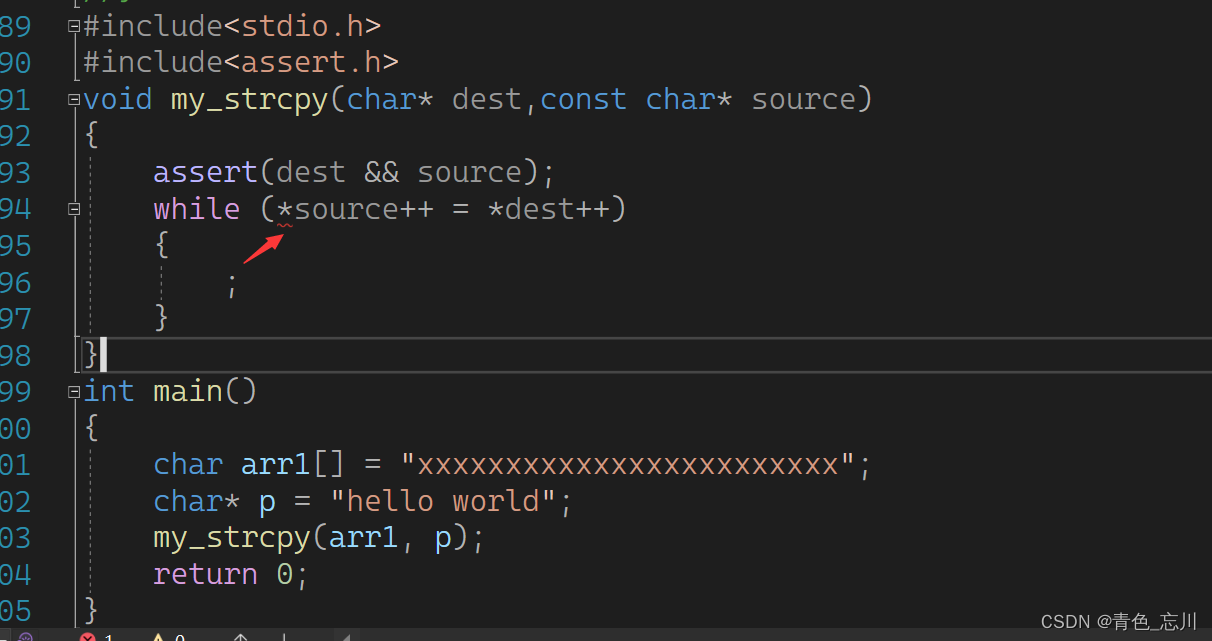
其实这个函数还是有一点点缺陷的,因为我们在之前看库函数的时候,他是有返回类型的,返回类型是char*类型,而且返回的是dest的地址
这个实现其实还是比较容易的,我们将一开始dest的地址记录一下,然后操作完成之后,在返回就是了
代码如下
#include<stdio.h>
#include<assert.h>
char* my_strcpy(char* dest,const char* source)
{
assert(dest && source);
char* ret = dest;
while (*dest++ = *source++)
{
;
}
return ret;
}
int main()
{
char arr1[] = "xxxxxxxxxxxxxxxxxxxxxxxx";
char* p = "hello world";
printf("%s\n", my_strcpy(arr1, p));
return 0;
}
至此,这个函数的功能终于算是比较完整了,相对而言没有那么多bug了。
(2)模拟实现strlen
刚刚我们花费了大量的笔墨去了解了strcpy这个库函数,那么我们现在在回过头来研究一下strlen这个库函数,这个库函数我们之前模拟过几次,但是那都算不上完整。都有一些bug,我们现在了解了const和assert以后能否将其完善一下呢?
我们给出代码,需要注意的是,使用unsigned的原因是,长度不会为负数,所以使用unsigned其实更加合理一些
#include<stdio.h>
#include<assert.h>
unsigned int my_strlen(const char* str)
{
assert(str);
unsigned int len = 0;
while (*str++ != '\0')
{
len++;
}
return len;
}
int main()
{
char arr[] = "abcdef";
printf("%d\n", my_strlen(arr));
return 0;
}
当然在我们的库函数中其实他的返回类型是size_t,size_t其实就是unsigned int,size_t也可以直接应用在这里。
当然我们也可以经常阅读一些源码级的东西,来加深对于这些库函数的理解,搜索源码的方式就是打开everything,然后直接搜索这个库函数,使用vs2022打开就可以了

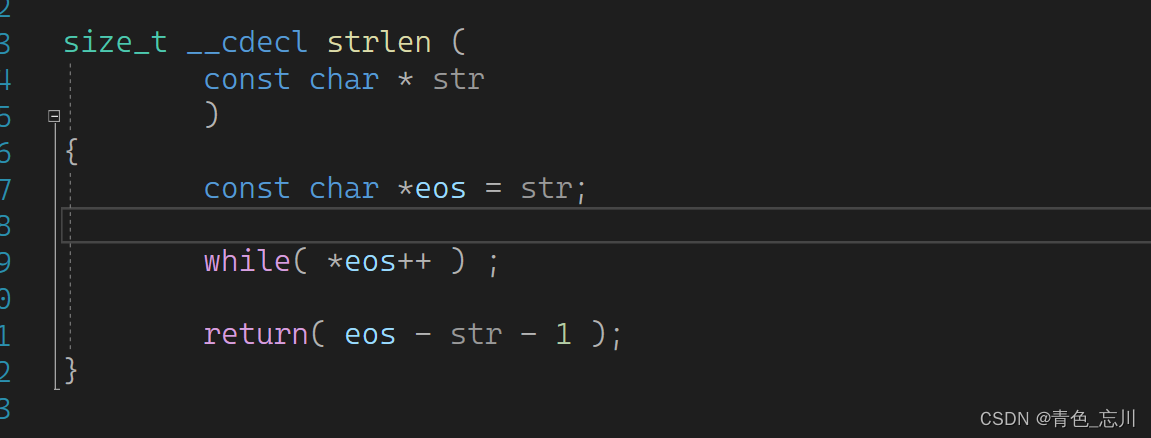
这就是我们搜索源码的方式 ,他这个源码其实是使用指针减去指针的方式来实现的
也可以搜索strcpy的源码,当然搜索他需要去搜索strcat才能搜索到
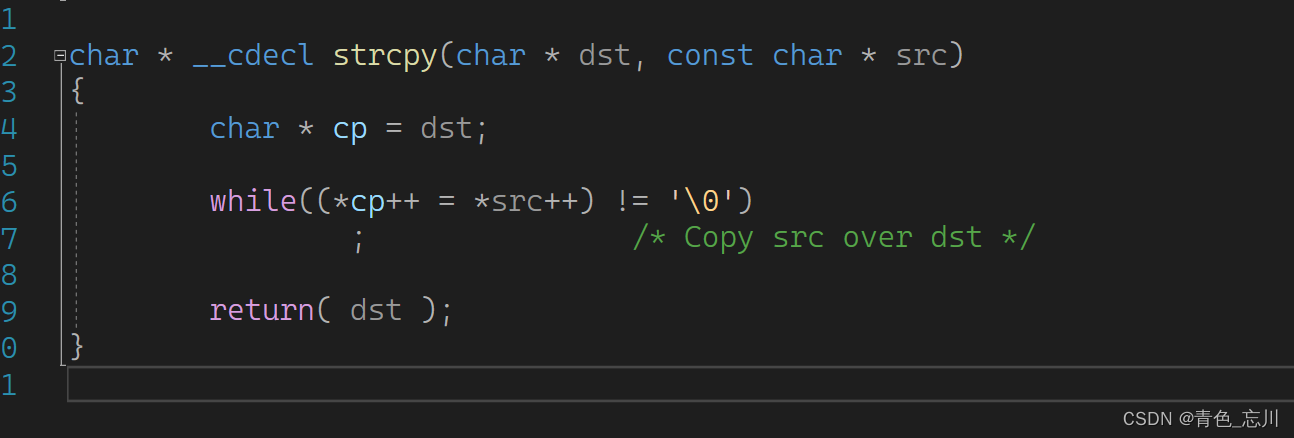
他这个实现思路就和我们的是一样的了
六、编程常见的错误
1.编译型错误
这样的错误编译就根本编不过去
直接看错误提示信息(双击),解决问题。或者凭借经验就可以搞定。相对来说简单。
2.链接型错误
一般都是提示无法解析的外部符号,比如说忘记写了头文件,标识符写错了

我们可以使用crtl+f,来呼出查找功能来查找某一个单词
看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。一般是标识符名不存在或者拼写错误。
3.运行时错误
借助调试,逐步定位问题。最难搞。
总结
本小节主要讲解了两个调试的实例以及两个库函数的模拟,其中介绍了assert的使用,const修饰指针的两种情况
如果对你有帮助,不要忘记点赞加收藏哦!!!
如果想看后续更加精彩更加丰富的文章,记得关注我哦!!!
版权归原作者 青色_忘川 所有, 如有侵权,请联系我们删除。