
提示:文章内容仅供参考!
一、 Spark-SQL是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
二、 Hive and SparkSQL
SparkSQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具。 Hive 是早期唯一运行在 Hadoop 上的 SQL-on-Hadoop 工具。但是 MapReduce 计算过程中大量的中间磁盘落地过程消耗了大量的 I/O,降低的运行效率,为了提高 SQL-on-Hadoop 的效率,大量的 SQL-on-Hadoop 工具开始产生,其中表现较为突出的是:
⚫ Drill
⚫ Impala
⚫ Shark
其中 Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,它修改了内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上。
Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了 10-100 倍的提高。
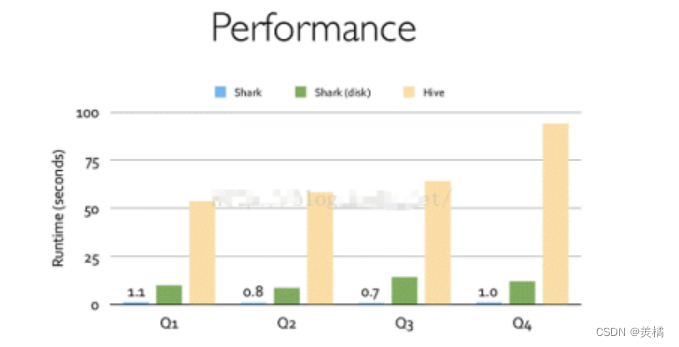
但是,随着 Spark 的发展,对于野心勃勃的 Spark 团队来说,Shark 对于 Hive 的太多依 赖(如采用 Hive 的语法解析器、查询优化器等等),制约了 Spark 的 One Stack Rule Them All 的既定方针,制约了 Spark 各个组件的相互集成,所以提出了 SparkSQL 项目。SparkSQL 抛弃原有 Shark 的代码,汲取了 Shark 的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL 无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步,海阔天空”。
➢ 数据兼容方面 SparkSQL 不但兼容 Hive,还可以从 RDD、parquet 文件、JSON 文件中 获取数据,未来版本甚至支持获取 RDBMS 数据以及 cassandra 等 NOSQL 数据;
➢ 性能优化方面 除了采取 In-Memory Columnar Storage、byte-code generation 等优化技术 外、将会引进 Cost Model 对查询进行动态评估、获取最佳物理计划等等;
➢ 组件扩展方面无论是 SQL 的语法解析器、分析器还是优化器都可以重新定义,进行扩 展。
2014 年 6 月 1 日 Shark 项目和 SparkSQL 项目的主持人 Reynold Xin 宣布:停止对 Shark 的开发,团队将所有资源放 SparkSQL 项目上,至此,Shark 的发展画上了句号,但也因此发展出两个支线:SparkSQL 和 Hive on Spark。
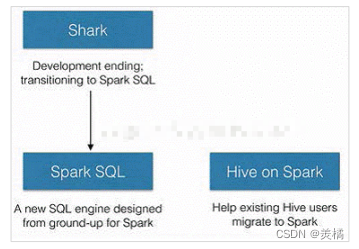
其中 SparkSQL 作为 Spark 生态的一员继续发展,而不再受限于 Hive,只是兼容 Hive;而 Hive on Spark 是一个 Hive 的发展计划,该计划将 Spark 作为 Hive 的底层引擎之一,也就是说,Hive 将不再受限于一个引擎,可以采用 Map-Reduce、Tez、Spark 等引擎。 对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发, 提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD
➢ DataFrame
➢ DataSet
三、Spark-SQL 特点
易整合。无缝的整合了 SQL 查询和 Spark 编程

**统一的数据访问。使用相同的方式连接不同的数据源 **

** 兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL **

** 标准数据连接。通过 JDBC 或者 ODBC 来连接**

四、Spark-SQL连接Hive 的五种方法
Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)、Hive 查询语言(HQL)等。需要强调的一点是,如果要在 Spark SQL 中包含Hive 的库,并不需要事先安装 Hive。一般来说,最好还是在编译 Spark SQL 时引入 Hive支持,这样就可以使用这些特性了。
使用方式分为内嵌Hive、外部Hive、Spark-SQL CLI、Spark beeline 以及代码操作。
1)内嵌的 HIVE
如果使用 Spark 内嵌的 Hive, 则什么都不用做, 直接使用即可。但是在实际生产活动当中,几乎没有人去使用内嵌Hive这一模式。
2)外部的 HIVE
如果想在spark-shell中连接外部已经部署好的 Hive,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
➢ 把 Mysql 的驱动 copy 到 jars/目录下
➢ 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
➢ 重启 spark-shell

3)运行 Spark beeline****
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好 Spark Thrift Server 后,可以直接使用 hive 的 beeline 访问 Spark Thrift Server 执行相关语句。Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore进行交互,获取到 hive 的元数据。如果想连接 Thrift Server,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
➢ 把 Mysql 的驱动 copy 到 jars/目录下
➢ 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
➢ 启动 Thrift Server
sbin/start-thriftserver.sh
➢ 使用 beeline 连接 Thrift Server
*beeline -u jdbc:hive2://node01:10000 -n root*
4)运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
- 将mysql的驱动放入jars/当中;
- 将hive-site.xml文件放入conf/当中;
- 运行bin/目录下的spark-sql.cmd 或者打开cmd,在
D:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql

5)代码操作Hive
- 导入依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.3</version>
</dependency>
可能出现下载jar包的问题:
D:\maven\repository\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde
将hive-site.xml 文件拷贝到项目的 resources 目录中。
代码实现。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("hive")
val spark:SparkSession = SparkSession.builder()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
spark.sql("show databases").show()
spark.sql("create database spark_sql")
spark.sql("show databases").show()
注意:
1.如果在执行操作时,出现如下错误:

可以在代码最前面增加如下代码解决:
System.setProperty("HADOOP_USER_NAME", "node01")
此处的 node01 改为自己的 hadoop 用户名称
*2.在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址: config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse")*
版权归原作者 羙橘 所有, 如有侵权,请联系我们删除。