
数据仓库概念
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的
数据仓库核心架构
系统数据流程图

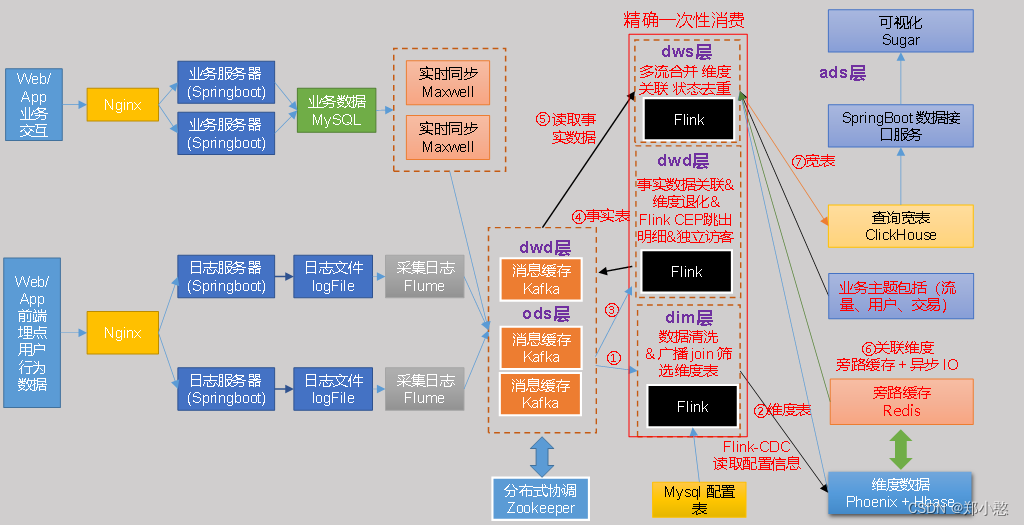
flink实时数仓项目
数据仓库建模的意义
如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑,我们希望城市规划布局合理;如果把数据看作电脑文件和文件夹,我们希望按照自己的习惯有很好的文件夹组织方式,而不是糟糕混乱的桌面,经常为找一个文件而不知所措。
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。
高性能:良好的数据模型能够帮助我们快速查询所需要的数据。
低成本:良好的数据模型能减少重复计算,实现计算结果的复用,降低计算成本。
高效率:良好的数据模型能极大的改善用户使用数据的体验,提高使用数据的效率。
高质量:良好的数据模型能改善数据统计口径的混乱,减少计算错误的可能性4
数据仓库建模方法论
** ER模型**
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
**** 实体关系模型****
实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如学生、班级,关系是指两个实体之间的关系,例如学生和班级之间的从属关系。
**** 数据库规范化****
数据库规范化是使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性。
这一系列范式就是指在设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。
**** 三范式****
**** 第一范式:属性不可切割****
**** 第二范式:不能存在部分函数依赖****
**** 第三范式:不能存在传递性函数依赖****
**** ****下图为一个采用Bill Inmon倡导的建模方法构建的模型,从图中可以看出,较为松散、零碎,物理表数量多
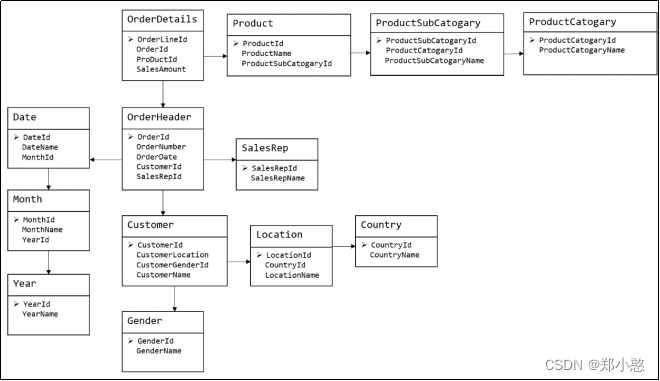
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计
维度模型
数据仓库领域的令一位大师——Ralph Kimball倡导的建模方法为维度建模。维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
注:业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。
下图为一个典型的维度模型,其中位于中心的SalesOrder为事实表,其中保存的是下单这个业务过程的所有记录。位于周围每张表都是维度表,包括Date(日期),Customer(顾客),Product(产品),Location(地区)等,这些维度表就组成了每个订单发生时所处的环境,即何人、何时、在何地下单了何种产品。从图中可以看出,模型相对清晰、简洁
**** ****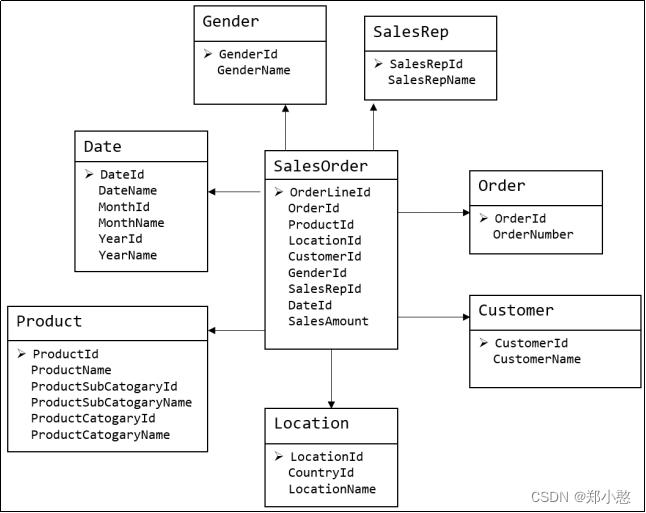
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能
维度建模理论之事实表
事实表概述
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数字类型字段)。
** **事实表特点
事实表通常比较“细长”,即列较少,但行较多,且行的增速快。
事实表分类
事实表有三种类型:分别是事务事实表、周期快照事实表和累积快照事实表,每种事实表都具有不同的特点和适用场景,下面逐个介绍。
** **事务型事实表
** 概述**
事务事实表用来记录各业务过程,它保存的是各业务过程的原子操作事件,即最细粒度的操作事件。粒度是指事实表中一行数据所表达的业务细节程度。
事务型事实表可用于分析与各业务过程相关的各项统计指标,由于其保存了最细粒度的记录,可以提供最大限度的灵活性,可以支持无法预期的各种细节层次的统计需求。
3**.2.2 **设计流程
设计事务事实表时一般可遵循以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
1)选择业务过程
在业务系统中,挑选我们感兴趣的业务过程,业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。通常情况下,一个业务过程对应一张事务型事实表。
2)声明粒度
业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求。
典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项。
3)确定维度
确定维度具体是指,确定与每张事务型事实表相关的维度有哪些。
确定维度时应尽量多的选择与业务过程相关的环境信息。因为维度的丰富程度就决定了维度模型能够支持的指标丰富程度。
4)确定事实
此处的“事实”一词,指的是每个业务过程的度量值(通常是可累加的数字类型的值,例如:次数、个数、件数、金额等)。
经过上述四个步骤,事务型事实表就基本设计完成了。第一步选择业务过程可以确定有哪些事务型事实表,第二步可以确定每张事务型事实表的每行数据是什么,第三步可以确定每张事务型事实表的维度外键,第四步可以确定每张事务型事实表的度量值字段。
** 不足**
事务型事实表可以保存所有业务过程的最细粒度的操作事件,故理论上其可以支撑与各业务过程相关的各种统计粒度的需求。但对于某些特定类型的需求,其逻辑可能会比较复杂,或者效率会比较低下。例如:
1)存量型指标
例如商品库存,账户余额等。此处以电商中的虚拟货币为例,虚拟货币业务包含的业务过程主要包括获取货币和使用货币,两个业务过程各自对应一张事务型事实表,一张存储所有的获取货币的原子操作事件,另一张存储所有使用货币的原子操作事件。
假定现有一个需求,要求统计截至当日的各用户虚拟货币余额。由于获取货币和使用货币均会影响到余额,故需要对两张事务型事实表进行聚合,且需要区分两者对余额的影响(加或减),另外需要对两张表的全表数据聚合才能得到统计结果。
可以看到,不论是从逻辑上还是效率上考虑,这都不是一个好的方案。
2)多事务关联统计
例如,现需要统计最近30天,用户下单到支付的时间间隔的平均值。统计思路应该是找到下单事务事实表和支付事务事实表,过滤出最近30天的记录,然后按照订单id对两张事实表进行关联,之后用支付时间减去下单时间,然后再求平均值。
逻辑上虽然并不复杂,但是其效率较低,应为下单事务事实表和支付事务事实表均为大表,大表join大表的操作应尽量避免。
可以看到,在上述两种场景下事务型事实表的表现并不理想。下面要介绍的另外两种类型的事实表就是为了弥补事务型事实表的不足的。
** 周期型快照事实表**
** 概述**
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,主要用于分析一些存量型(例如商品库存,账户余额)或者状态型(空气温度,行驶速度)指标。
对于商品库存、账户余额这些存量型指标,业务系统中通常就会计算并保存最新结果,所以定期同步一份全量数据到数据仓库,构建周期型快照事实表,就能轻松应对此类统计需求,而无需再对事务型事实表中大量的历史记录进行聚合了。
对于空气温度、行驶速度这些状态型指标,由于它们的值往往是连续的,我们无法捕获其变动的原子事务操作,所以无法使用事务型事实表统计此类需求。而只能定期对其进行采样,构建周期型快照事实表。
** 设计流程**
1****)确定粒度
周期型快照事实表的粒度可由采样周期和维度描述,故确定采样周期和维度后即可确定粒度。
采样周期通常选择每日。
维度可根据统计指标决定,例如指标为统计每个仓库中每种商品的库存,则可确定维度为仓库和商品。
确定完采样周期和维度后,即可确定该表粒度为每日-仓库-商品。
2****)确认事实
事实也可根据统计指标决定,例如指标为统计每个仓库中每种商品的库存,则事实为商品库存。
** 事实类型**
此处的事实类型是指度量值的类型,而非事实表的类型。事实(度量值)共分为三类,分别是可加事实,半可加事实和不可加事实。
1)可加事实
可加事实是指可以按照与事实表相关的所有维度进行累加,例如事务型事实表中的事实。
2)半可加事实
半可加事实是指只能按照与事实表相关的一部分维度进行累加,例如周期型快照事实表中的事实。以上述各仓库中各商品的库存每天快照事实表为例,这张表中的库存事实可以按照仓库或者商品维度进行累加,但是不能按照时间维度进行累加,因为将每天的库存累加起来是没有任何意义的。
3)不可加事实
不可加事实是指完全不具备可加性,例如比率型事实。不可加事实通常需要转化为可加事实,例如比率可转化为分子和分母。
** 累积型快照事实表**
** 概述**
累计快照事实表是基于一个业务流程中的多个关键业务过程联合处理而构建的事实表,如交易流程中的下单、支付、发货、确认收货业务过程。
累积型快照事实表通常具有多个日期字段,每个日期对应业务流程中的一个关键业务过程(里程碑)。
订单id
用户id
下单日期
支付日期
发货日期
确认收货日期
订单金额
支付金额
1001
1234
2020-06-14
2020-06-15
2020-06-16
2020-06-17
1000
1000
累积型快照事实表主要用于分析业务过程(里程碑)之间的时间间隔等需求。例如前文提到的用户下单到支付的平均时间间隔,使用累积型快照事实表进行统计,就能避免两个事务事实表的关联操作,从而变得十分简单高效。
** 设计流程**
累积型快照事实表的设计流程同事务型事实表类似,也可采用以下四个步骤,下面重点描述与事务型事实表的不同之处。
选择业务过程→声明粒度→确认维度→确认事实。
1)选择业务过程
选择一个业务流程中需要关联分析的多个关键业务过程,多个业务过程对应一张累积型快照事实表。
2)声明粒度
精确定义每行数据表示的是什么,尽量选择最小粒度。
3)确认维度
选择与各业务过程相关的维度,需要注意的是,每各业务过程均需要一个日期维度。
4)确认事实
选择各业务过程的度量值
维度建模理论之维度表
在电商离线数仓中,普通维度表是通过主维表和相关维表做关联查询生成的。与之对应的业务数表数据是通过每日一次全量同步导入到 HDFS 的,只须每日做一次全量数据的关联查询即可。而实时数仓中,系统上线后我们采集的是所有表的变化数据,这样就会导致一旦主维表或相关维表中的某张表数据发生了变化,就需要和其它表的历史数据做关联。
此时我们会面临一个问题:如何获取历史数据?
对于这个问题,一种思路是在某张与维度表相关的业务表数据发生变化时,执行一次 maxwell-bootstrap 命令,将相关业务表的数据导入 Kafka。但是这样做又会面临三个问题:a)Kafka 中存储冗余数据;b)maxwell-bootstrap 命令交给谁去执行?必然会面临谁去调度的问题;c)实时数仓中的数据是以流的形式存在的,如果不同流中数据进入程序的机器时间差异过大就会出现 join 不上的情况。如何保证导入的历史数据和变化数据可以关联上?势必要尽可能及时地执行历史数据导入命令且在 Flink 程序中设置足够的延迟。而前者难以保证,后者又会影响整个实时数仓的时效性。
基于上述分析,对业务表做 join 形成维度表的方式并不适用于实时数仓。
因此,在实时数仓中,我们不再对业务数据库中的维度表进行合并,仅对一些不需要的字段进行过滤,然后将维度数据写入 HBase 的维度表中,业务数据库的维度表和 HBase 的维度表是一一对应的。
写入维度数据使用 HBase 的 Phoenix 客户端提供的 upsert 语法,实现幂等写入。当维度数据发生变化时,程序会用变化后的新数据覆盖 Phoenix 维表中相同主键的旧数据。从而保证 Phoenix 表中保存的是一份全量最新的维度数据。
这样做会产生一个问题:实时数仓没有保存历史维度数据,与数仓特征(保存历史数据)相悖。那么,维度表可以按照上述思路设计吗?
数据仓库设计
** 数据仓库分层规划**
优秀可靠的数仓体系,需要良好的数据分层结构。合理的分层,能够使数据体系更加清晰,使复杂问题得以简化。以下是该项目的分层规划。

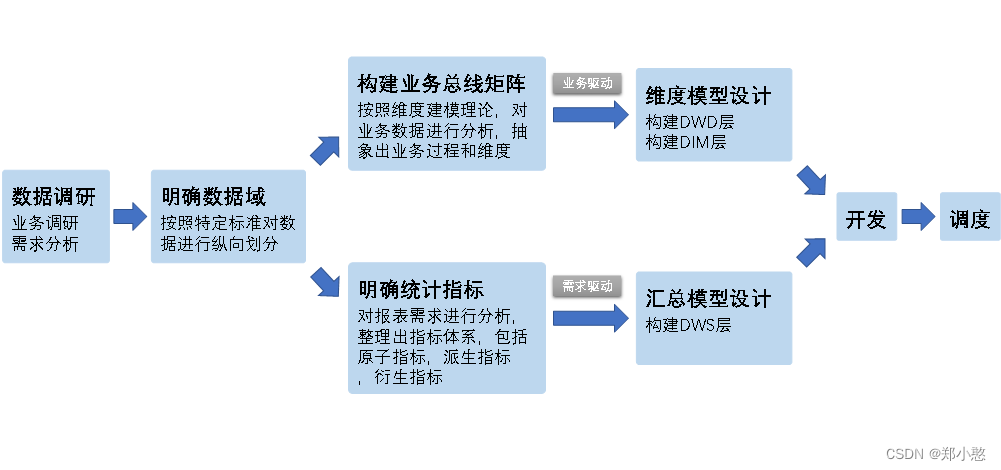
** 数据仓库构建流程**
以下是构建数据仓库的完整流程。
** 数据调研**
数据调研重点要做两项工作,分别是业务调研和需求分析。这两项工作做的是否充分,直接影响着数据仓库的质量。
1)业务调研
业务调研的主要目标是熟悉业务流程、熟悉业务数据。
熟悉业务流程要求做到,明确每个业务的具体流程,需要将该业务所包含的每个业务过程一一列举出来。
熟悉业务数据要求做到,将数据(包括埋点日志和业务数据表)与业务过程对应起来,明确每个业务过程会对哪些表的数据产生影响,以及产生什么影响。产生的影响,需要具体到,是新增一条数据,还是修改一条数据,并且需要明确新增的内容或者是修改的逻辑。
下面业务电商中的交易为例进行演示,交易业务涉及到的业务过程有买家下单、买家支付、卖家发货,买家收货,具体流程如下图。
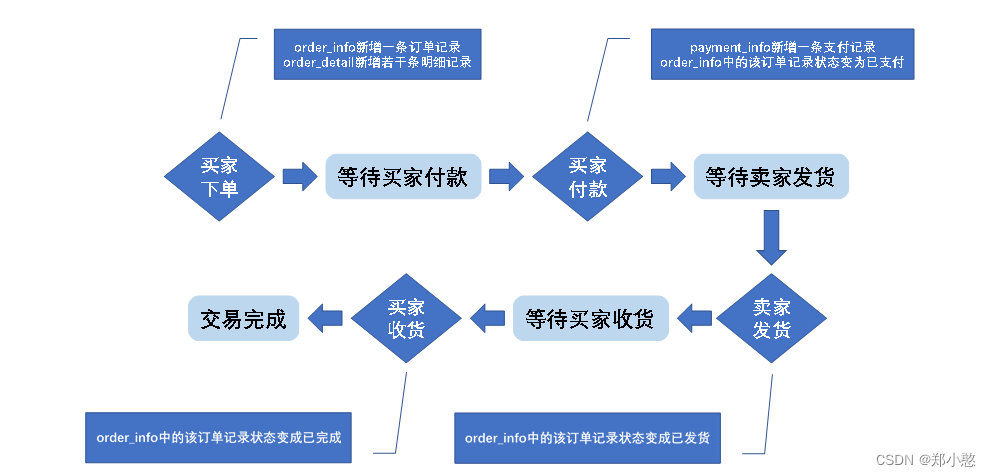
2****)需求分析
典型的需求指标如,最近一天各省份手机品类订单总额。
分析需求时,需要明确需求所需的业务过程及维度,例如该需求所需的业务过程就是买家下单,所需的维度有日期,省份,商品品类。
3)总结
做完业务分析和需求分析之后,要保证每个需求都能找到与之对应的业务过程及维度。若现有数据无法满足需求,则需要和业务方进行沟通,例如某个页面需要新增某个行为的埋点。
** 明确数据域**
数据仓库模型设计除横向的分层外,通常也需要根据业务情况进行纵向划分数据域。
划分数据域的意义是便于数据的管理和应用。
通常可以根据业务过程或者部门进行划分,本项目根据业务过程进行划分,需要注意的是一个业务过程只能属于一个数据域。
下面是本数仓项目所需的所有业务过程及数据域划分详情。
数据域
业务过程
交易域
加购、下单、取消订单、支付成功、退单、退款成功
流量域
页面浏览、启动应用、动作、曝光、错误
用户域
注册、登录
互动域
收藏、评价
工具域
优惠券领取、优惠券使用(下单)、优惠券使用(支付)
** 构建业务总线矩阵**
业务总线矩阵中包含维度模型所需的所有事实(业务过程)以及维度,以及各业务过程与各维度的关系。矩阵的行是一个个业务过程,矩阵的列是一个个的维度,行列的交点表示业务过程与维度的关系。
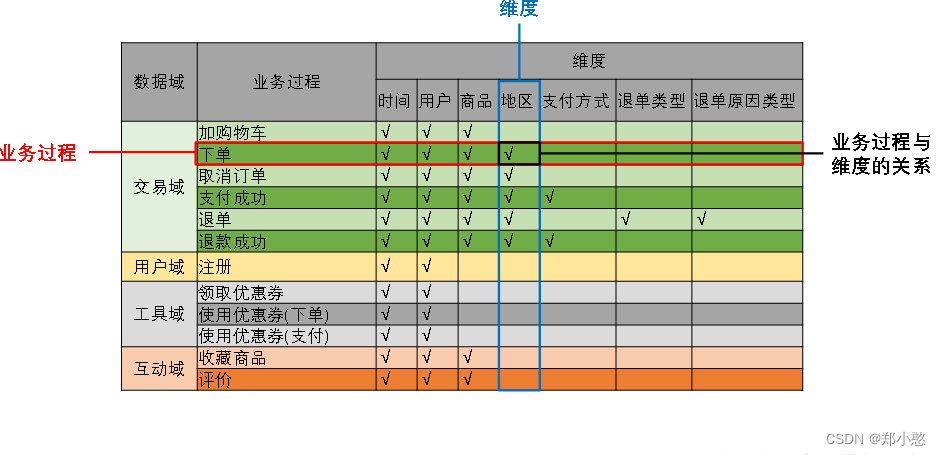
一个业务过程对应维度模型中一张事务型事实表,一个维度则对应维度模型中的一张维度表。所以构建业务总线矩阵的过程就是设计维度模型的过程。但是需要注意的是,总线矩阵中通常只包含事务型事实表,另外两种类型的事实表需单独设计。
按照事务型事实表的设计流程,选择业务过程à声明粒度à确认维度à确认事实,得到的最终的业务
** 明确统计指标**
明确统计指标具体的工作是,深入分析需求,构建指标体系。构建指标体系的主要意义就是指标定义标准化。所有指标的定义,都必须遵循同一套标准,这样能有效的避免指标定义存在歧义,指标定义重复等问题。
1)指标体系相关概念
(1)原子指标
原子指标基于某一业务过程的度量值,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进行了定义。我们可以得出结论,原子指标包含三要素,分别是业务过程、度量值和聚合逻辑。
例如订单总额就是一个典型的原子指标,其中的业务过程为用户下单、度量值为订单金额,聚合逻辑为sum()求和。需要注意的是原子指标只是用来辅助定义指标一个概念,通常不会对应有实际统计需求与之对应。
(2)派生指标
派生指标基于原子指标,其与原子指标的关系如下图所示。
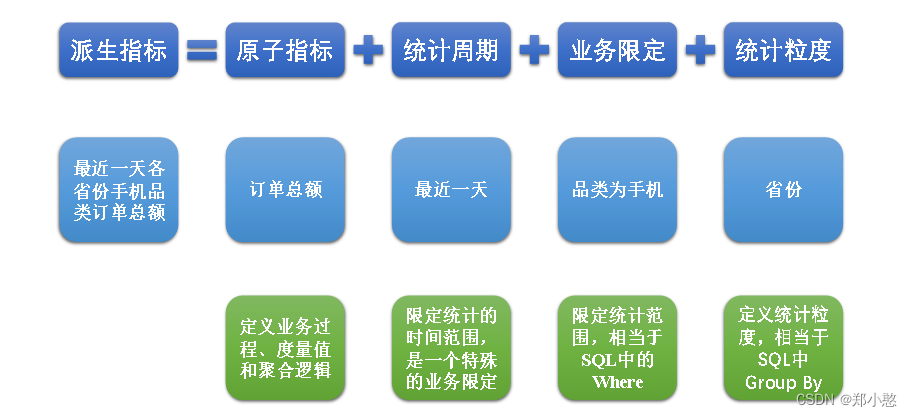
与原子指标不同,派生指标通常会对应实际的统计需求。请从图中的例子中,体会指标定义标准化的含义。
(3)衍生指标
衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的。例如比率、比例等类型的指标。衍生指标也会对应实际的统计需求。

2)指标体系对于数仓建模的意义
通过上述两个具体的案例可以看出,绝大多数的统计需求,都可以使用原子指标、派生指标以及衍生指标这套标准去定义。同时能够发现这些统计需求都直接的或间接的对应一个或者是多个派生指标。
当统计需求足够多时,必然会出现部分统计需求对应的派生指标相同的情况。这种情况下,我们就可以考虑将这些公共的派生指标保存下来,这样做的主要目的就是减少重复计算,提高数据的复用性。
这些公共的派生指标统一保存在数据仓库的DWS层。因此DWS层设计,就可以参考我们根据现有的统计需求整理出的派生指标。
** **** **维度模型设计
维度模型的设计参照上述得到的业务总线矩阵即可。事实表存储在DWD层,维度表存储在DIM层。
** 汇总模型设计**
汇总模型的设计参考上述整理出的指标体系(主要是派生指标)即可。汇总表与派生指标的对应关系是,一张汇总表通常包含业务过程相同、统计周期相同、统计粒度相同的多个派生指标。请思考:汇总表与事实表的对应关系是?
首先,我们要明确:数仓之所以要保存历史数据,是为了运用历史数据做一些相关指标的计算,而实时数仓本就是对最新的业务数据做分析计算,不涉及历史数据,因此无须保存历史数据。
此外,生产环境中实时数仓的上线通常不会早于离线数仓,如果有涉及到历史数据的指标,在离线数仓中计算即可。因此,实时数仓中只需要保留一份最新的维度数据,上述方案是切实可行的。
特别地,对于字典表,我们至多只会用到 dic_code,dic_name 和 parent_code 三个字段,建立单独的维度表意义不大,选择将维度字段退化到事实表中。
版权归原作者 郑小憨 所有, 如有侵权,请联系我们删除。